
[ad_1]
Time-series forecasting is an important research area that is critical to several scientific and industrial applications, like retail supply chain optimization, energy and traffic prediction, and weather forecasting. In retail use cases, for example, it has been observed that improving demand forecasting accuracy can meaningfully reduce inventory costs and increase revenue.
Modern time-series applications can involve forecasting hundreds of thousands of correlated time-series (e.g., demands of different products for a retailer) over long horizons (e.g., a quarter or year away at daily granularity). As such, time-series forecasting models need to satisfy the following key criterias:
- Ability to handle auxiliary features or covariates: Most use-cases can benefit tremendously from effectively using covariates, for instance, in retail forecasting, holidays and product specific attributes or promotions can affect demand.
- Suitable for different data modalities: It should be able to handle sparse count data, e.g., intermittent demand for a product with low volume of sales while also being able to model robust continuous seasonal patterns in traffic forecasting.
A number of neural network–based solutions have been able to show good performance on benchmarks and also support the above criterion. However, these methods are typically slow to train and can be expensive for inference, especially for longer horizons.
In “Long-term Forecasting with TiDE: Time-series Dense Encoder”, we present an all multilayer perceptron (MLP) encoder-decoder architecture for time-series forecasting that achieves superior performance on long horizon time-series forecasting benchmarks when compared to transformer-based solutions, while being 5–10x faster. Then in “On the benefits of maximum likelihood estimation for Regression and Forecasting”, we demonstrate that using a carefully designed training loss function based on maximum likelihood estimation (MLE) can be effective in handling different data modalities. These two works are complementary and can be applied as a part of the same model. In fact, they will be available soon in Google Cloud AI’s Vertex AutoML Forecasting.
TiDE: A simple MLP architecture for fast and accurate forecasting
Deep learning has shown promise in time-series forecasting, outperforming traditional statistical methods, especially for large multivariate datasets. After the success of transformers in natural language processing (NLP), there have been several works evaluating variants of the Transformer architecture for long horizon (the amount of time into the future) forecasting, such as FEDformer and PatchTST. However, other work has suggested that even linear models can outperform these transformer variants on time-series benchmarks. Nonetheless, simple linear models are not expressive enough to handle auxiliary features (e.g., holiday features and promotions for retail demand forecasting) and non-linear dependencies on the past.
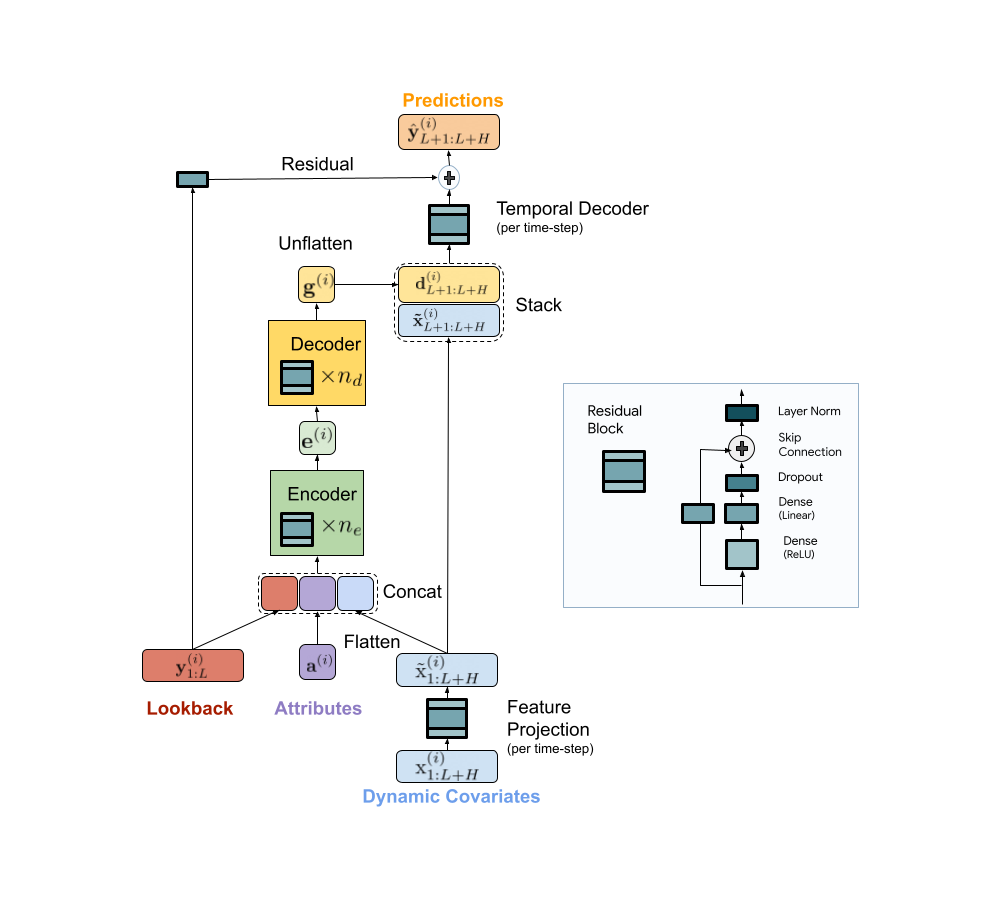
We present a scalable MLP-based encoder-decoder model for fast and accurate multi-step forecasting. Our model encodes the past of a time-series and all available features using an MLP encoder. Subsequently, the encoding is combined with future features using an MLP decoder to yield future predictions. The architecture is illustrated below.
 |
| TiDE model architecture for multi-step forecasting. |
TiDE is more than 10x faster in training compared to transformer-based baselines while being more accurate on benchmarks. Similar gains can be observed in inference as it only scales linearly with the length of the context (the number of time-steps the model looks back) and the prediction horizon. Below on the left, we show that our model can be 10.6% better than the best transformer-based baseline (PatchTST) on a popular traffic forecasting benchmark, in terms of test mean squared error (MSE). On the right, we show that at the same time our model can have much faster inference latency than PatchTST.
 |
| Left: MSE on the test set of a popular traffic forecasting benchmark. Right: inference time of TiDE and PatchTST as a function of the look-back length. |
Our research demonstrates that we can take advantage of MLP’s linear computational scaling with look-back and horizon sizes without sacrificing accuracy, while transformers scale quadratically in this situation.
Probabilistic loss functions
In most forecasting applications the end user is interested in popular target metrics like the mean absolute percentage error (MAPE), weighted absolute percentage error (WAPE), etc. In such scenarios, the standard approach is to use the same target metric as the loss function while training. In “On the benefits of maximum likelihood estimation for Regression and Forecasting”, accepted at ICLR, we show that this approach might not always be the best. Instead, we advocate using the maximum likelihood loss for a carefully chosen family of distributions (discussed more below) that can capture inductive biases of the dataset during training. In other words, instead of directly outputting point predictions that minimize the target metric, the forecasting neural network predicts the parameters of a distribution in the chosen family that best explains the target data. At inference time, we can predict the statistic from the learned predictive distribution that minimizes the target metric of interest (e.g., the mean minimizes the MSE target metric while the median minimizes the WAPE). Further, we can also easily obtain uncertainty estimates of our forecasts, i.e., we can provide quantile forecasts by estimating the quantiles of the predictive distribution. In several use cases, accurate quantiles are vital, for instance, in demand forecasting a retailer might want to stock for the 90th percentile to guard against worst-case scenarios and avoid lost revenue.
The choice of the distribution family is crucial in such cases. For example, in the context of sparse count data, we might want to have a distribution family that can put more probability on zero, which is commonly known as zero-inflation. We propose a mixture of different distributions with learned mixture weights that can adapt to different data modalities. In the paper, we show that using a mixture of zero and multiple negative binomial distributions works well in a variety of settings as it can adapt to sparsity, multiple modalities, count data, and data with sub-exponential tails.
 |
| A mixture of zero and two negative binomial distributions. The weights of the three components, a1, a2 and a3, can be learned during training. |
We use this loss function for training Vertex AutoML models on the M5 forecasting competition dataset and show that this simple change can lead to a 6% gain and outperform other benchmarks in the competition metric, weighted root mean squared scaled error (WRMSSE).
| M5 Forecasting | WRMSSE |
| Vertex AutoML | 0.639 +/- 0.007 |
| Vertex AutoML with probabilistic loss | 0.581 +/- 0.007 |
| DeepAR | 0.789 +/- 0.025 |
| FEDFormer | 0.804 +/- 0.033 |
Conclusion
We have shown how TiDE, together with probabilistic loss functions, enables fast and accurate forecasting that automatically adapts to different data distributions and modalities and also provides uncertainty estimates for its predictions. It provides state-of-the-art accuracy among neural network–based solutions at a fraction of the cost of previous transformer-based forecasting architectures, for large-scale enterprise forecasting applications. We hope this work will also spur interest in revisiting (both theoretically and empirically) MLP-based deep time-series forecasting models.
Acknowledgements
This work is the result of a collaboration between several individuals across Google Research and Google Cloud, including (in alphabetical order): Pranjal Awasthi, Dawei Jia, Weihao Kong, Andrew Leach, Shaan Mathur, Petros Mol, Shuxin Nie, Ananda Theertha Suresh, and Rose Yu.
[ad_2]
Source link
best india pharmacy: india online pharmacy – top online pharmacy india
https://medicinefromindia.store/# top 10 online pharmacy in india
top 10 pharmacies in india
medicine in mexico pharmacies mexican pharmacy mexican pharmacy
п»їbest mexican online pharmacies mexican pharmaceuticals online buying from online mexican pharmacy
best online pharmacies in mexico mexican rx online medicine in mexico pharmacies
Lumiere — новый клубный квартал премиум-класса между Ильинским и Новорижским шоссе, в 9 км от Москвы.
mexico pharmacies prescription drugs mexico drug stores pharmacies mexico pharmacies prescription drugs
reputable mexican pharmacies online п»їbest mexican online pharmacies buying from online mexican pharmacy
mexican border pharmacies shipping to usa mexican online pharmacies prescription drugs mexico drug stores pharmacies
mexican pharmaceuticals online mexico drug stores pharmacies buying from online mexican pharmacy
https://mexicanph.com/# pharmacies in mexico that ship to usa
mexican online pharmacies prescription drugs
reputable mexican pharmacies online mexico pharmacies prescription drugs mexico drug stores pharmacies
mexico drug stores pharmacies п»їbest mexican online pharmacies mexican pharmacy
best online pharmacies in mexico best online pharmacies in mexico mexican border pharmacies shipping to usa
п»їbest mexican online pharmacies buying prescription drugs in mexico mexican border pharmacies shipping to usa
mexico pharmacy pharmacies in mexico that ship to usa buying from online mexican pharmacy
http://mexicanph.shop/# mexican border pharmacies shipping to usa
mexican pharmaceuticals online
mexico drug stores pharmacies mexican pharmacy best online pharmacies in mexico
buying prescription drugs in mexico online mexican drugstore online medication from mexico pharmacy
mexico drug stores pharmacies mexican mail order pharmacies purple pharmacy mexico price list
purple pharmacy mexico price list mexican pharmaceuticals online mexican pharmacy
mexican drugstore online medication from mexico pharmacy п»їbest mexican online pharmacies
mexican mail order pharmacies buying prescription drugs in mexico medicine in mexico pharmacies
п»їbest mexican online pharmacies buying prescription drugs in mexico reputable mexican pharmacies online
п»їbest mexican online pharmacies mexico pharmacy best online pharmacies in mexico
mexican online pharmacies prescription drugs mexican rx online mexican rx online
reputable mexican pharmacies online mexico pharmacy mexico pharmacy
order amoxicillin online: amoxicillin for sale online – amoxicillin online no prescription
stromectol ivermectin tablets: stromectol ivermectin 3 mg – price of ivermectin
http://furosemide.guru/# buy furosemide online
stromectol pill: stromectol xl – ivermectin 1% cream generic
ivermectin over the counter: ivermectin 0.5 lotion india – ivermectin where to buy for humans
generic lisinopril 3973: lisinopril pill 20mg – lisinopril 5mg cost
stromectol nz: stromectol tab price – п»їwhere to buy stromectol online
stromectol tablet 3 mg: stromectol tablets for humans for sale – ivermectin 4
ivermectin nz: stromectol online canada – stromectol south africa
lisinopril 20 mg: buy lisinopril online canada – cheap lisinopril 40 mg
lasix 100 mg: Buy Lasix No Prescription – furosemide 100 mg
ivermectin humans: ivermectin 5 – ivermectin lotion cost
lisinopril cost: zestril 10 mg cost – lisinopril 12.5 tablet
cheap amoxicillin 500mg: generic for amoxicillin – order amoxicillin online
where to buy lisinopril without prescription: lisinopril 1.25 mg – lisinopril 20mg discount
can i buy lisinopril over the counter in canada: lisinopril 120 mg – lisinopril 10 mg
buy furosemide online: Buy Lasix No Prescription – furosemide 100mg
buy zestril: lisinopril 30 mg price – lisinopril brand name cost
lisinopril 20g: zestril 10 mg price – 16 lisinopril
zestril 5 mg price: price for 5 mg lisinopril – lisinopril uk
amoxacillian without a percription: amoxicillin 200 mg tablet – buy cheap amoxicillin
lasix side effects: Buy Furosemide – lasix 100 mg
zestoretic 20 25: lisinopril 20 12.5 mg – zestril discount
prednisone 5mg price: cheapest prednisone no prescription – 200 mg prednisone daily
amoxicillin 500mg tablets price in india: amoxicillin 825 mg – purchase amoxicillin online without prescription
buy amoxicillin 500mg usa: amoxicillin 500mg price in canada – where can you get amoxicillin
canadian pharmacies viagra canadian pharmacies generic ed medication
viagra pharmacy online [url=http://canadianphrmacy23.com/]canadian pharmacies[/url]
cheapest online pharmacy india Online medicine order indianpharmacy com
top 10 pharmacies in india india pharmacy Online medicine home delivery
Online medicine home delivery top 10 online pharmacy in india buy medicines online in india
buy cytotec in usa: buy cytotec over the counter – cytotec buy online usa
diflucan online paypal: diflucan over the counter uk – where to buy diflucan in singapore
tamoxifen pill: tamoxifen buy – nolvadex side effects
Hello, World!
Hey there, mate! Greetings from your favorite surfing capybara!
How’s the surf today?
Ready to catch some gnarly waves together?
https://capybara888.wordpress.com/
Good luck!
ciprofloxacin 500mg buy online: antibiotics cipro – purchase cipro
where to purchase doxycycline: doxycycline monohydrate – doxycycline 100 mg
lana rhoades filmleri: lana rhoades izle – lana rhoades modeli
?????? ????: Angela White video – Angela Beyaz modeli
eva elfie izle: eva elfie – eva elfie
Angela White video: abella danger filmleri – abella danger filmleri
eva elfie filmleri: eva elfie filmleri – eva elfie izle
lana rhoades: lana rhoades modeli – lana rhoades video
Angela White filmleri: abella danger video – Abella Danger
eva elfie video: eva elfie filmleri – eva elfie video
eva elfie modeli: eva elfie filmleri – eva elfie modeli
Angela White filmleri: Angela White izle – ?????? ????
Angela White: abella danger izle – abella danger video
sweeti fox: swetie fox – sweety fox
https://evaelfie.site/# eva elfie full videos
https://sweetiefox.pro/# sweetie fox
https://sweetiefox.pro/# sweetie fox video
http://evaelfie.site/# eva elfie hot
https://miamalkova.life/# mia malkova hd
https://miamalkova.life/# mia malkova full video
http://evaelfie.site/# eva elfie
https://lanarhoades.pro/# lana rhoades boyfriend
lana rhoades pics: lana rhoades videos – lana rhoades pics
https://evaelfie.site/# eva elfie
http://lanarhoades.pro/# lana rhoades pics
http://lanarhoades.pro/# lana rhoades pics
http://evaelfie.site/# eva elfie photo
jogo de aposta: aviator jogo de aposta – jogos que dao dinheiro
https://aviatormocambique.site/# aviator
https://jogodeaposta.fun/# jogo de aposta online
http://aviatorghana.pro/# aviator game
https://pinupcassino.pro/# pin up casino
aviator betano: aviator betano – estrela bet aviator
buy generic zithromax online: over the counter zithromax where can i get zithromax over the counter
zithromax 250 mg: zithromax diarrhea can you buy zithromax over the counter in mexico
zithromax capsules: buy zithromax online fast shipping – zithromax capsules australia
indian pharmacies safe: india pharmacy – reputable indian pharmacies indianpharm.store
canadian online pharmacy: My Canadian pharmacy – canadian pharmacy canadianpharm.store
http://canadianpharmlk.shop/# legitimate canadian mail order pharmacy canadianpharm.store
http://indianpharm24.shop/# online shopping pharmacy india indianpharm.store
http://mexicanpharm24.com/# mexico drug stores pharmacies mexicanpharm.shop
https://indianpharm24.com/# Online medicine home delivery indianpharm.store
http://indianpharm24.com/# online shopping pharmacy india indianpharm.store
http://canadianpharmlk.com/# buy prescription drugs from canada cheap canadianpharm.store
https://indianpharm24.com/# best online pharmacy india indianpharm.store
http://canadianpharmlk.com/# reliable canadian pharmacy canadianpharm.store
http://canadianpharmlk.shop/# vipps approved canadian online pharmacy canadianpharm.store
https://canadianpharmlk.com/# reliable canadian pharmacy canadianpharm.store
https://mexicanpharm24.shop/# pharmacies in mexico that ship to usa mexicanpharm.shop
http://clomidst.pro/# buy generic clomid
https://prednisonest.pro/# prednisone 2.5 mg
http://amoxilst.pro/# where can i buy amoxicillin over the counter
https://amoxilst.pro/# amoxicillin online canada
https://clomidst.pro/# can you buy clomid without insurance
http://prednisonest.pro/# 20 mg prednisone tablet
http://onlinepharmacy.cheap/# legit non prescription pharmacies
http://pharmnoprescription.pro/# buy medications without prescriptions
https://edpills.guru/# cheapest online ed meds
https://edpills.guru/# buy erectile dysfunction treatment
http://edpills.guru/# best ed meds online
http://pharmacynoprescription.pro/# buying prescription drugs online canada
http://canadianpharm.guru/# canadian pharmacies compare
http://indianpharm.shop/# online pharmacy india
https://pharmacynoprescription.pro/# no prescription on line pharmacies
http://indianpharm.shop/# indian pharmacy paypal
https://pharmacynoprescription.pro/# buy medication online without prescription
http://canadianpharm.guru/# canadian world pharmacy
https://pharmacynoprescription.pro/# ordering prescription drugs from canada
https://canadianpharm.guru/# canadian pharmacy
https://canadianpharm.guru/# canadianpharmacymeds
http://indianpharm.shop/# mail order pharmacy india
https://canadianpharm.guru/# my canadian pharmacy review
http://mexicanpharm.online/# mexico pharmacy
https://canadianpharm.guru/# canadian mail order pharmacy
http://indianpharm.shop/# Online medicine order
pin up casino giris: pin up giris – pin up casino giris
pin-up online: pin up giris – pin up
aviator oyna slot: aviator oyunu 50 tl – aviator hilesi ucretsiz
casino slot siteleri: slot casino siteleri – slot siteleri bonus veren
slot kumar siteleri: casino slot siteleri – slot siteleri 2024
gates of olympus demo: gates of olympus demo oyna – gates of olympus demo turkce oyna
slot siteleri: yasal slot siteleri – bonus veren casino slot siteleri
sweet bonanza bahis: sweet bonanza yorumlar – sweet bonanza yasal site
slot siteleri guvenilir: en iyi slot siteleri 2024 – en cok kazandiran slot siteleri
online shopping pharmacy india: Cheapest online pharmacy – best online pharmacy india
best online pharmacies in mexico: Online Pharmacies in Mexico – mexican pharmacy
top online pharmacy india: Healthcare and medicines from India – indian pharmacy
Online medicine home delivery: indian pharmacy – best india pharmacy
https://sildenafiliq.com/# viagra without prescription
https://kamagraiq.shop/# Kamagra 100mg price
http://kamagraiq.shop/# super kamagra
http://sildenafiliq.xyz/# best price for viagra 100mg
Приветствую. Подскажите, где почитатьразные статьи о недвижимости? Пока нашел https://417-017.ru
Приветствую. Подскажите, где почитатьразные статьи о недвижимости? Пока нашел https://aquatopnn.ru
Приветствую. Подскажите, где почитатьразные блоги о недвижимости? Пока нашел https://artem-dvery.ru
Приветствую. Подскажите, где найтиполезные блоги о недвижимости? Сейчас читаю https://asiatreid.ru
Всем привет! Подскажите, где почитатьполезные статьи о недвижимости? Сейчас читаю https://dilerskiy-tsentr-baumit.ru
Приветствую. Может кто знает, где найтиразные блоги о недвижимости? Сейчас читаю https://dompodkluch33.ru
Приветствую. Может кто знает, где найтиразные статьи о недвижимости? Пока нашел https://eniseyburvod.ru
Всем привет! Подскажите, где найтиразные статьи о недвижимости? Пока нашел https://etalon-voda.ru
Всем привет! Может кто знает, где почитатьразные блоги о недвижимости? Пока нашел https://floor-ashton.ru
Всем привет! Может кто знает, где найтиполезные блоги о недвижимости? Пока нашел https://gismt72.ru
Всем привет! Подскажите, где почитатьразные статьи о недвижимости? Пока нашел https://kait-volga.ru
Приветствую. Может кто знает, где найтиразные блоги о недвижимости? Пока нашел https://kaluga-elite.ru
Всем привет! Может кто знает, где почитатьполезные блоги о недвижимости? Пока нашел https://kamenolomnya43.ru
Всем привет! Подскажите, где найтиразные блоги о недвижимости? Сейчас читаю https://kmzperm.ru
Всем привет! Может кто знает, где найтиполезные статьи о недвижимости? Сейчас читаю https://kovry159.ru
Приветствую. Может кто знает, где найтиразные блоги о недвижимости? Сейчас читаю https://krepegmaster.ru
Привет Друзья!
Всегда думал что купить диплом о высшем образовании это миф и нереально, но все оказалось не так, изначально искал информацию про: купить диплом техникума, купить диплом в серове, купить диплом с реестром, купить диплом в новомосковске, купить диплом в белгороде, потом про дипломы вузов, подробнее здесь https://crossbookmark.com/story17260313/%D0%BF%D0%BE%D0%BB%D1%83%D1%87%D0%B8%D0%BB-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC-%D0%BF%D0%BE%D0%B7%D0%B4%D1%80%D0%B0%D0%B2%D0%BB%D1%8F%D1%8E
Оказалось все возможно, официально со специальными условия по упрощенным программам, так и сделал и теперь у меня есть диплом вуза Москвы нового образца, что советую и вам!
Хорошей учебы!
Всем привет! Подскажите, где почитатьполезные блоги о недвижимости? Пока нашел https://kuler-tsentr.ru
Всем привет! Может кто знает, где почитатьполезные статьи о недвижимости? Сейчас читаю https://liem-com.ru
Всем привет! Подскажите, где найтиполезные статьи о недвижимости? Сейчас читаю https://oscltd.ru
Всем привет! Подскажите, где найтиразные статьи о недвижимости? Сейчас читаю https://ppu-odk.ru
Всем привет! Может кто знает, где найтиразные статьи о недвижимости? Сейчас читаю https://redglade-nn.ru
Всем привет! Подскажите, где почитатьполезные блоги о недвижимости? Пока нашел https://santam1.ru
Всем привет! Может кто знает, где почитатьполезные статьи о недвижимости? Сейчас читаю https://sibarit54.ru
Приветствую. Подскажите, где почитатьразные статьи о недвижимости? Пока нашел https://stroyproektm.ru
Приветствую. Может кто знает, где почитатьразные статьи о недвижимости? Пока нашел https://tent44.ru
Всем привет! Может кто знает, где найти разные статьи о недвижимости? Пока нашел https://1eve1.ru
Приветствую. Может кто знает, где почитать разные статьи о недвижимости? Пока нашел https://an72.ru
Приветствую. Может кто знает, где почитать разные блоги о недвижимости? Пока нашел https://armid44.ru
Приветствую. Подскажите, где найти разные статьи о недвижимости? Сейчас читаю https://azimut-irkutsk.ru
Всем привет! Может кто знает, где почитать полезные статьи о недвижимости? Пока нашел https://ecn-novodom.ru
Всем привет! Может кто знает, где найти разные статьи о недвижимости? Пока нашел https://germes-alania.ru
Приветствую. Подскажите, где почитать полезные блоги о недвижимости? Пока нашел https://ilinka2.ru
Всем привет! Может кто знает, где найти полезные блоги о недвижимости? Пока нашел https://kolontaevo-club.ru
Приветствую. Может кто знает, где почитать полезные статьи о недвижимости? Пока нашел https://mcsspb.ru
Всем привет! Может кто знает, где найти разные блоги о недвижимости? Пока нашел https://officesaratov.ru
Приветствую. Подскажите, где найти полезные блоги о недвижимости? Пока нашел https://sintes21.ru
Всем привет! Подскажите, где почитать полезные статьи о недвижимости? Сейчас читаю https://ste96.ru
Приветствую. Подскажите, где найти разные статьи о недвижимости? Пока нашел https://kran-rdk.ru
Всем привет! Подскажите, где найти полезные статьи о недвижимости? Сейчас читаю https://mart-posters.ru
Приветствую. Подскажите, где почитать разные блоги о недвижимости? Сейчас читаю https://tochkacn.ru
Всем привет! Может кто знает, где найти разные статьи о недвижимости? Сейчас читаю https://metrazhi-omsk.ru
Приветствую. Подскажите, где найти разные статьи о недвижимости? Сейчас читаю https://mik-dom.ru
Всем привет! Подскажите, где почитать полезные статьи о недвижимости? Пока нашел https://miro-teh-ural.ru
Всем привет! Может кто знает, где почитать полезные блоги о недвижимости? Пока нашел https://mzhk-stroy.ru
Всем привет! Может кто знает, где найти разные статьи о недвижимости? Пока нашел https://nagaevodom.ru
Всем привет! Может кто знает, где почитать полезные статьи о недвижимости? Пока нашел https://potolkinomer1.ru
Приветствую. Может кто знает, где почитать полезные блоги о недвижимости? Пока нашел https://promresmag.ru
Всем привет! Подскажите, где найти разные блоги о недвижимости? Пока нашел https://santech31.ru
Всем привет! Подскажите, где почитать разные блоги о недвижимости? Сейчас читаю https://santex-expert.ru
Приветствую. Может кто знает, где найти разные статьи о недвижимости? Пока нашел https://schuconvr.ru
Приветствую. Подскажите, где почитать полезные блоги о недвижимости? Сейчас читаю https://simposad.ru
Приветствую. Может кто знает, где найти разные статьи о недвижимости? Сейчас читаю https://smgarant.ru
Всем привет! Может кто знает, где найти разные статьи о недвижимости? Пока нашел https://stilnyjpol.ru
Приветствую. Может кто знает, где почитать полезные статьи о недвижимости? Пока нашел https://tc-all.ru
Всем привет! Подскажите, где найти полезные блоги о недвижимости? Пока нашел https://teplohod-denisdavidov.ru
Всем привет! Может кто знает, где найти разные блоги о недвижимости? Сейчас читаю https://titovloft.ru
Приветствую. Подскажите, где найти полезные статьи о недвижимости? Сейчас читаю https://toadmarket.ru
Всем привет! Может кто знает, где найти разные блоги о недвижимости? Пока нашел https://u-mechanik.ru
Всем привет! Может кто знает, где почитать разные блоги о недвижимости? Пока нашел https://utc96.ru
Приветствую. Может кто знает, где найти разные блоги о недвижимости? Сейчас читаю https://vortex-los.ru
Всем привет! Подскажите, где почитать полезные блоги о недвижимости? Пока нашел https://yah-bomag.ru
Всем привет! Может кто знает, где почитать разные статьи о недвижимости? Сейчас читаю https://yaoknaa.ru
Приветствую. Подскажите, где найти полезные блоги о недвижимости? Пока нашел https://zt365.ru
Приветствую. Подскажите, где найти разные статьи о недвижимости? Сейчас читаю https://astali.ru
Приветствую. Может кто знает, где почитать полезные блоги о недвижимости? Сейчас читаю https://batstroimat24.ru
Всем привет! Подскажите, где почитать полезные блоги о недвижимости? Пока нашел https://bdrsu-2.ru
Приветствую. Может кто знает, где почитать полезные статьи о недвижимости? Сейчас читаю https://centro-kraska.ru
Приветствую. Может кто знает, где найти полезные блоги о недвижимости? Сейчас читаю https://cvetkrovli.ru
Всем привет! Подскажите, где найти разные блоги о недвижимости? Пока нашел https://deon-stroy.ru
Для тех, кто хочет наслаждаться всеми возможностями мобильного беттинга без затрат, скачать Фонбет на айфон бесплатно – отличное решение. Приложение Фонбет предоставляет пользователям удобный интерфейс, быстрый доступ к различным спортивным событиям и возможность делать ставки в любое время и в любом месте. Скачайте Фонбет на айфон бесплатно и получайте удовольствие от ставок.
Всем привет! Может кто знает, где почитать разные статьи о недвижимости? Сейчас читаю https://dom-vasilevo.ru
Всем привет! Может кто знает, где почитать полезные статьи о недвижимости? Сейчас читаю https://2204000.ru
Всем привет! Подскажите, где найти полезные статьи о недвижимости? Пока нашел https://adeldv.ru
Приветствую. Подскажите, где почитать полезные статьи о недвижимости? Пока нашел https://eniseynev.ru
Приветствую. Подскажите, где найти полезные блоги о недвижимости? Сейчас читаю https://fuseitdecore.ru
Приветствую. Подскажите, где почитать разные статьи о недвижимости? Сейчас читаю https://galastroy-sk.ru
Всем привет! Может кто знает, где найти разные блоги о недвижимости? Пока нашел https://ggs45.ru
Всем привет! Может кто знает, где почитать разные блоги о недвижимости? Сейчас читаю https://glwin.ru
Всем привет! Может кто знает, где найти разные статьи о недвижимости? Пока нашел https://gor-bur.ru
Приветствую. Подскажите, где найти разные блоги о недвижимости? Сейчас читаю https://hameleon1.ru
Приветствую. Подскажите, где почитать разные блоги о недвижимости? Пока нашел https://iskrb.ru
Приветствую. Подскажите, где найти полезные блоги о недвижимости? Пока нашел https://juzhnybereg24.ru
Приветствую. Подскажите, где найти полезные статьи о недвижимости? Пока нашел https://klimat-hck.ru
Зарегистрируйтесь на сайте Пари и активируйте БК Пари промокод, чтобы получить эксклюзивные бонусы и скидки на ставки. Увеличьте свои шансы на победу!
Всем привет! Может кто знает, где найти разные статьи о недвижимости? Сейчас читаю https://kolahouse.ru
Всем привет! Подскажите, где найтиразные блоги о недвижимости? Сейчас читаю https://sm70.ru
Приветствую. Подскажите, где найти разные статьи о недвижимости? Сейчас читаю https://komdizrem.ru
Приветствую. Подскажите, где найти полезные блоги о недвижимости? Пока нашел https://konditsioneri-shop.ru
Всем привет! Подскажите, где почитать разные блоги о недвижимости? Пока нашел https://glatt-nsk.ru
Приветствую. Может кто знает, где найти полезные статьи о недвижимости? Пока нашел блог о недвижимости
Приветствую. Подскажите, где почитать полезные блоги о недвижимости? Сейчас читаю https://glatt-nsk.ru
Всем привет! Подскажите, где почитать полезные статьи о недвижимости? Сейчас читаю https://gor-bur.ru
Приветствую. Может кто знает, где найти полезные статьи о недвижимости? Сейчас читаю https://konditsioneri-shop.ru