
[ad_1]
Reinforcement learning (RL) algorithms can learn skills to solve decision-making tasks like playing games, enabling robots to pick up objects, or even optimizing microchip designs. However, running RL algorithms in the real world requires expensive active data collection. Pre-training on diverse datasets has proven to enable data-efficient fine-tuning for individual downstream tasks in natural language processing (NLP) and vision problems. In the same way that BERT or GPT-3 models provide general-purpose initialization for NLP, large RL–pre-trained models could provide general-purpose initialization for decision-making. So, we ask the question: Can we enable similar pre-training to accelerate RL methods and create a general-purpose “backbone” for efficient RL across various tasks?
In “Offline Q-learning on Diverse Multi-Task Data Both Scales and Generalizes”, to be published at ICLR 2023, we discuss how we scaled offline RL, which can be used to train value functions on previously collected static datasets, to provide such a general pre-training method. We demonstrate that Scaled Q-Learning using a diverse dataset is sufficient to learn representations that facilitate rapid transfer to novel tasks and fast online learning on new variations of a task, improving significantly over existing representation learning approaches and even Transformer-based methods that use much larger models.
 |
Scaled Q-learning: Multi-task pre-training with conservative Q-learning
To provide a general-purpose pre-training approach, offline RL needs to be scalable, allowing us to pre-train on data across different tasks and utilize expressive neural network models to acquire powerful pre-trained backbones, specialized to individual downstream tasks. We based our offline RL pre-training method on conservative Q-learning (CQL), a simple offline RL method that combines standard Q-learning updates with an additional regularizer that minimizes the value of unseen actions. With discrete actions, the CQL regularizer is equivalent to a standard cross-entropy loss, which is a simple, one-line modification on standard deep Q-learning. A few crucial design decisions made this possible:
- Neural network size: We found that multi-game Q-learning required large neural network architectures. While prior methods often used relatively shallow convolutional networks, we found that models as large as a ResNet 101 led to significant improvements over smaller models.
- Neural network architecture: To learn pre-trained backbones that are useful for new games, our final architecture uses a shared neural network backbone, with separate 1-layer heads outputting Q-values of each game. This design avoids interference between the games during pre-training, while still providing enough data sharing to learn a single shared representation. Our shared vision backbone also utilized a learned position embedding (akin to Transformer models) to keep track of spatial information in the game.
- Representational regularization: Recent work has observed that Q-learning tends to suffer from representational collapse issues, where even large neural networks can fail to learn effective representations. To counteract this issue, we leverage our prior work to normalize the last layer features of the shared part of the Q-network. Additionally, we utilized a categorical distributional RL loss for Q-learning, which is known to provide richer representations that improve downstream task performance.
The multi-task Atari benchmark
We evaluate our approach for scalable offline RL on a suite of Atari games, where the goal is to train a single RL agent to play a collection of games using heterogeneous data from low-quality (i.e., suboptimal) players, and then use the resulting network backbone to quickly learn new variations in pre-training games or completely new games. Training a single policy that can play many different Atari games is difficult enough even with standard online deep RL methods, as each game requires a different strategy and different representations. In the offline setting, some prior works, such as multi-game decision transformers, proposed to dispense with RL entirely, and instead utilize conditional imitation learning in an attempt to scale with large neural network architectures, such as transformers. However, in this work, we show that this kind of multi-game pre-training can be done effectively via RL by employing CQL in combination with a few careful design decisions, which we describe below.
Scalability on training games
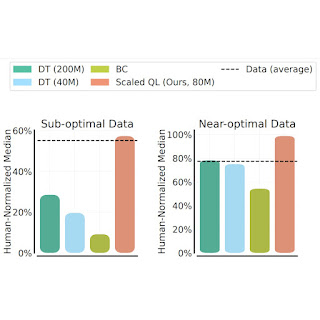
We evaluate the Scaled Q-Learning method’s performance and scalability using two data compositions: (1) near optimal data, consisting of all the training data appearing in replay buffers of previous RL runs, and (2) low quality data, consisting of data from the first 20% of the trials in the replay buffer (i.e., only data from highly suboptimal policies). In our results below, we compare Scaled Q-Learning with an 80-million parameter model to multi-game decision transformers (DT) with either 40-million or 80-million parameter models, and a behavioral cloning (imitation learning) baseline (BC). We observe that Scaled Q-Learning is the only approach that improves over the offline data, attaining about 80% of human normalized performance.
 |
Further, as shown below, Scaled Q-Learning improves in terms of performance, but it also enjoys favorable scaling properties: just as how the performance of pre-trained language and vision models improves as network sizes get bigger, enjoying what is typically referred as “power-law scaling”, we show that the performance of Scaled Q-learning enjoys similar scaling properties. While this may be unsurprising, this kind of scaling has been elusive in RL, with performance often deteriorating with larger model sizes. This suggests that Scaled Q-Learning in combination with the above design choices better unlocks the ability of offline RL to utilize large models.
 |
Fine-tuning to new games and variations
To evaluate fine-tuning from this offline initialization, we consider two settings: (1) fine-tuning to a new, entirely unseen game with a small amount of offline data from that game, corresponding to 2M transitions of gameplay, and (2) fine-tuning to a new variant of the games with online interaction. The fine-tuning from offline gameplay data is illustrated below. Note that this condition is generally more favorable to imitation-style methods, Decision Transformer and behavioral cloning, since the offline data for the new games is of relatively high-quality. Nonetheless, we see that in most cases Scaled Q-learning improves over alternative approaches (80% on average), as well as dedicated representation learning methods, such as MAE or CPC, which only use the offline data to learn visual representations rather than value functions.
 |
In the online setting, we see even larger improvements from pre-training with Scaled Q-learning. In this case, representation learning methods like MAE yield minimal improvement during online RL, whereas Scaled Q-Learning can successfully integrate prior knowledge about the pre-training games to significantly improve the final score after 20k online interaction steps.
These results demonstrate that pre-training generalist value function backbones with multi-task offline RL can significantly boost performance of RL on downstream tasks, both in offline and online mode. Note that these fine-tuning tasks are quite difficult: the various Atari games, and even variants of the same game, differ significantly in appearance and dynamics. For example, the target blocks in Breakout disappear in the variation of the game as shown below, making control difficult. However, the success of Scaled Q-learning, particularly as compared to visual representation learning techniques, such as MAE and CPC, suggests that the model is in fact learning some representation of the game dynamics, rather than merely providing better visual features.
 |
| Fine-tuning with online RL for variants of the game Freeway, Hero, and Breakout. The new variant used in fine-tuning is shown in the bottom row of each figure, the original game seen in pre-training is in the top row. Fine-tuning from Scaled Q-Learning significantly outperforms MAE (a visual representation learning method) and learning from scratch with single-game DQN. |
Conclusion and takeaways
We presented Scaled Q-Learning, a pre-training method for scaled offline RL that builds on the CQL algorithm, and demonstrated how it enables efficient offline RL for multi-task training. This work made initial progress towards enabling more practical real-world training of RL agents as an alternative to costly and complex simulation-based pipelines or large-scale experiments. Perhaps in the long run, similar work will lead to generally capable pre-trained RL agents that develop broadly applicable exploration and interaction skills from large-scale offline pre-training. Validating these results on a broader range of more realistic tasks, in domains such as robotics (see some initial results) and NLP, is an important direction for future research. Offline RL pre-training has a lot of potential, and we expect that we will see many advances in this area in future work.
Acknowledgements
This work was done by Aviral Kumar, Rishabh Agarwal, Xinyang Geng, George Tucker, and Sergey Levine. Special thanks to Sherry Yang, Ofir Nachum, and Kuang-Huei Lee for help with the multi-game decision transformer codebase for evaluation and the multi-game Atari benchmark, and Tom Small for illustrations and animation.
[ad_2]
Source link
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://accounts.binance.com/bg/register?ref=S5H7X3LP
Когда речь заходит о ремонте телефона, это может стать сложной задачей. Попытка найти надежного специалиста и найти время, чтобы починить устройство, может стать сложной задачей. Но если вы живете в Москве, вам повезло: https://ps-iphone.ru/remont-telefonov/. В компании NeedMaster предлагают невероятную услугу, которая делает ремонт телефона простым и удобным. Они приезжают прямо к вам домой или в офис, так что вам не придется выкраивать время из своего дня только для ремонта. Кроме того, их специалисты имеют высокую квалификацию и опыт ремонта всех типов телефонов.
Если вы ищете надежный ремонт телефонов в Москве, «NeedMaster» — идеальный выбор. Их дружелюбный персонал всегда готов ответить на любые ваши вопросы и позаботиться о том, чтобы ваше устройство было отремонтировано быстро и качественно.
After reading your article, it reminded me of some things about gate io that I studied before. The content is similar to yours, but your thinking is very special, which gave me a different idea. Thank you. But I still have some questions I want to ask you, I will always pay attention. Thanks.
Your article helped me a lot, is there any more related content? Thanks! https://accounts.binance.com/pt-BR/register-person?ref=WTOZ531Y
buy feldene gel
buy genuine cialis
[url=https://zanaflextizanidine.gives/]tizanidine 5.2[/url]
where to buy elimite cream
can you buy amoxicillin over the counter in australia
lyrica generic price
[url=https://valtrex.media/]buying valtrex in mexico[/url]
propecia prescription online
cafergot internet pharmacy
furosemide brand name in india
augmentin 500 mg tab
ampicillin
acyclovir daily use
valtrex cost
buy generic tricor for sale order tricor 160mg buy generic fenofibrate
clindamycin 150mg prices
men dating sites: asian online dating – zoosk dating
cheapest prednisone no prescription: http://prednisone1st.store/# over the counter prednisone cheap
tricor medication buy tricor paypal order fenofibrate sale
fenofibrate online order tricor usa tricor 160mg cheap
pharmacies in canada that ship to the us pharmacies in canada that ship to the us
mobic without dr prescription: how to buy mobic online – order mobic without rx
get propecia price order cheap propecia prices
augmentin 875 mg 37.5mg
https://pharmacyreview.best/# canadadrugpharmacy com
amoxicillin buy canada: buying amoxicillin in mexico generic amoxicillin 500mg
generic mobic online: where to buy mobic without prescription – where to get mobic for sale
baclofen brand name australia
order amoxicillin online no prescription: amoxicillin generic can you purchase amoxicillin online
atarax generic
cost cheap propecia without insurance order propecia
cheap levaquin
https://propecia1st.science/# get cheap propecia without a prescription
buying generic mobic without a prescription: get generic mobic – where can i buy generic mobic tablets
online pharmacies that use paypal
atarax brand name
cheap erectile dysfunction medicine for impotence cheap erectile dysfunction
buy phenergan online uk
amoxicillin 800 mg price amoxicillin 30 capsules price – amoxicillin 500mg for sale uk
https://indiamedicine.world/# Online medicine home delivery
order phenergan online
escrow pharmacy canada
mexico drug stores pharmacies: medicine in mexico pharmacies – reputable mexican pharmacies online
http://mexpharmacy.sbs/# mexican border pharmacies shipping to usa
azithromycin 500 tabs
the canadian pharmacy
baclofen 10 mg tab
lipitor drug
buying prescription drugs in mexico online: buying prescription drugs in mexico – mexican online pharmacies prescription drugs
atarax buy
http://certifiedcanadapharm.store/# buy canadian drugs
triamterene-hctz 75-50 mg
top 10 online pharmacy in india: reputable indian pharmacies – best india pharmacy
http://certifiedcanadapharm.store/# canadian drug pharmacy
canadian pharmacy world coupon
tenormin pills
lipitor 124
indian pharmacy online: reputable indian pharmacies – reputable indian pharmacies
https://mexpharmacy.sbs/# reputable mexican pharmacies online
pharmacy canadian superstore
where can i buy zaditor order zaditor sale tofranil 25mg canada
buy zaditor 1 mg for sale order doxepin 25mg generic generic tofranil 75mg
can you buy robaxin over the counter
best online pharmacies in mexico: purple pharmacy mexico price list – mexican drugstore online
https://certifiedcanadapharm.store/# canadian pharmacy drugs online
india pharmacy: indian pharmacy – online shopping pharmacy india
azithromycin 1
buy fluconizole online
plavix generic price
https://mexpharmacy.sbs/# buying from online mexican pharmacy
flomax generic alternative
where can i buy accutane online
synthroid 50 mcg coupon
canadianpharmacymeds com: vipps canadian pharmacy – safe canadian pharmacies
cheap tadalafil generic sildenafil 100mg sale buy viagra 100mg online
tadalafil 20mg for sale brand sildenafil order viagra for sale
can you buy zithromax online: zithromax antibiotic without prescription – zithromax canadian pharmacy
propranolol tablets 20 mg
prednisone 100 mg daily
ventolin albuterol
http://gabapentin.pro/# canada neurontin 100mg lowest price
prednisone tablets india
buy acarbose pills griseofulvin canada buy fulvicin 250 mg pills
acarbose pills fulvicin 250 mg generic buy fulvicin 250 mg
buy innopran xl
order propranolol
http://azithromycin.men/# zithromax 500mg price in india
lisinopril 20 tablet
best pharmacy prednisone
zithromax capsules price: zithromax antibiotic – cost of generic zithromax
propecia tablets in india
azithromycin 500mg over the counter
lyrica south africa
https://azithromycin.men/# zithromax 250 mg
buy minoxidil paypal cost flomax 0.4mg buy generic ed pills for sale
buy generic minoxidil brand tamsulosin 0.4mg the blue pill ed
keflex tabs
amoxicillin cost india
inderal 40 online
retino 05 cream
0.025 mg synthroid
https://paxlovid.top/# paxlovid price
prednisone 300 mg
order precose 50mg online purchase precose for sale order griseofulvin 250 mg
celebrex brand cost
Paxlovid over the counter: paxlovid pill – п»їpaxlovid
https://ed-pills.men/# mens ed pills
buy albenza canada
accutane price south africa
cymbalta 6 mg
https://lipitor.pro/# buy lipitor 10 mg
dipyridamole pills dipyridamole pills cheap pravastatin
buy albendazole tablets
aspirin 75mg drug order aspirin without prescription buy zovirax without a prescription
buy cheap generic aspirin imiquimod tubes how to buy imiquimod
https://ciprofloxacin.ink/# cipro ciprofloxacin
albuterol uk
modafinil online no prescription
can you buy azithromycin online
cost of azithromycin in canada
http://avodart.pro/# how to buy cheap avodart without dr prescription
cheap phenergan tablets
terramycin for cats
dipyridamole price pravachol order online pravastatin 20mg usa
provigil mexico prescription
https://lipitor.pro/# lipitor 20mg
buy meloset 3 mg cost meloset 3mg buy danazol online
melatonin 3 mg without prescription aygestin usa purchase danazol pills
silagra 25 mg price
buy flomax online without prescription
where can i buy flomax
florinef price florinef 100mcg uk order generic loperamide 2mg
medication metformin
augmentin 875 price in india
motrin 600 mg
modafinil pharmacy price
canadian pharmacy sildalis
albendazoleoverthecounter.com
terramycin eye ointment petsmart
http://mexicanpharmacy.guru/# best online pharmacies in mexico
brand name cymbalta
2.5 mg prozac
prednisolone 5mg coupon
propecia hair loss
buy real paxil online
motrin 800 mg over the counter
medicine albendazole 400
tetracycline over the counter
order paxil
accutane cheapest price
buy prednisolone tablets
lexapro escitalopram
order valtrex online usa
amoxicillin discount coupon
It’s really a copl annd helpful piece off info.
I’m satiisfied that yyou just shhared thiks herlpful info
with us. Please stay us uup too dwte like this. Thanks for sharing.
https://certifiedcanadapills.pro/# canadian drug pharmacy
combivent order
arimidex for sale canada
Lariam
clonidine beta blocker
Психология
diflucan usa
prednisone for sale
prednisone dosage
where to buy generic cleocin prices
diltiazem bnf
buying ventolin uk
Finast
Смоленск в сети
generic motilium
lisinopril 10mg
prednisone use
amoxicillin for sale online uk
tamoxifen coupon
bulimia nervosa treatment
where buy cialis soft tabs prices
Zebeta
Морковная халва.
doxycycline hyc dr 100 mg tab
what are the side effects of lisinopril?
where to get cheap cleocin without rx
tadacip cost in canada
Rumalaya
Рыбная диета — KetoFood
can i order prednisone
post finasteride syndrome
cetirizine vidal
cleocin resistance
Purchase doxycycline
Новости общества на Смоленском портале. Последние новости. 1 страница
finasteride warnings
motilium 10mg price
duphaston 10mg generic januvia 100 mg drug buy generic jardiance 25mg
buy dydrogesterone 10mg without prescription jardiance 10mg pills jardiance 10mg canada
https://zarabotok.userforum.ru/viewtopic.php?id=6731#p17378
[url=https://fluconazole.party/]where to buy diflucan without prescription[/url]
sexchat anonymous
onlinecanadianpharmacy 24
motilium price canada
fludrocortisone sale rabeprazole 20mg uk loperamide 2 mg cheap
buy prasugrel 10mg online cheap buy thorazine cheap detrol 1mg usa
can you buy toradol over the counter
trazodone 50 mg online
nolvadex eu
lasix 10 mg price
furosemide on line no prescription
Разрешение на строительство — это административный письменное удостоверение, выписываемый официальными учреждениями государственного управления или муниципального руководства, который разрешает начать возведение или выполнение строительных работ.
Получение разрешения на строительство формулирует законодательные принципы и стандарты к возведению, включая дозволенные типы работ, предусмотренные материалы и техники, а также включает строительные нормы и пакеты охраны. Получение разрешения на стройку является обязательным документов для строительной сферы.
furosemide buy
motilium pharmacy
amoxicillin online canada
prasugrel 10mg price chlorpromazine 100mg sale detrol 1mg ca
lexapro escitalopram
purchase monograph pills order colospa for sale pletal price
buy generic etodolac over the counter cheap etodolac order cilostazol 100mg without prescription
how to buy ferrous order actonel 35 mg sale generic sotalol 40 mg
diflucan 100 mg tablet
buy fake money online
Драгон Мани официальный сайт
buy zithromax
motilium 100 tablets
buy prednisolone 5mg tabs
Cauvo Capital отзывы
Avalide
Сладкий ролл с бананом и орехами
can i buy prednisone
cheapest prednisone no prescription
side effects of ashwagandha supplements
can you buy generic sildigra price
Femara
Гостиница НИКА
zovirax tablet price
wellbutrin 150 mg tablets
viagra drugs
buy prednisone
what is lisinopril prescribed for
trazodone snort erowid
amoxilin
Doxycycline cost canada
Салат с ростбифом и карамелизированными орехами
can i order lisinopril prices
what is the side effect of lisinopril
ashwagandha cortisol
zoloft 25mg
Primaquine
Крем-суп из брокколи с гренками
lisinopril prescribing information
finasteride uses
doxycycline mono
albuterol sulfate
Strattera
Новости программного обеспечения на Смоленском портале. Архив новостей. две недели назад. 1 страница
can you buy cheap lisinopril for sale
doxycycline antibiotic
ferrous sulfate sale ferrous 100mg generic betapace drug
Отзывы AME Capitals
stromectol online pharmacy
naked massage
wellbutrin 2019
ivermectin
vasotec 5mg price buy doxazosin sale order generic duphalac
zoloft without script visa
augmentin 875
albendazole 400 mg price
buy prendisalone on line uk
generic zoloft
ап х официальный сайт
neurontin 600 mg capsule
ап икс
pyridostigmine 60mg price order maxalt online rizatriptan 10mg cheap
brand pyridostigmine order rizatriptan pills order generic maxalt
Быстровозводимые строения – это современные сооружения, которые отличаются высокой скоростью установки и гибкостью. Они представляют собой сооруженные объекты, состоящие из эскизно созданных компонентов или же компонентов, которые имеют возможность быть скоро смонтированы в пункте строительства.
Строительство быстровозводимых зданий из сэндвич панелей обладают гибкостью а также адаптируемостью, что разрешает легко изменять а также переделывать их в соответствии с нуждами заказчика. Это экономически результативное и экологически долговечное решение, которое в последние лета заполучило широкое распространение.
скачать сайт азино777
Depo-medrol
автоматы казино азино777
prednisone for sale
is doxycycline a penicillin
lisinopril medication prescription
cetirizine dosage
Macrobid
vasotec cheap doxazosin 1mg over the counter buy lactulose medication
order betahistine generic probenecid 500 mg generic buy generic probalan
world pharmacy india
Случается, что у владельцев автомобилей возникает необходимость замены сделать дубликат номера вы можете быть уверены в легальности и качестве наших гос номеров.
https://csin.ru/Sport/zabota-i-professionalizm-v-tyazhelie-momenti
Wszyscy nowi gracze, ktorzy po raz pierwszy rejestruja konto w fontan casino 100 zЕ‚ bez depozytu
Вы можете купить кабель любой марки и сечения – купить провод при необходимости поставим товары на заказ.
Каждый, кто увлекается спортивными ставками, хочет повысить свои шансы на победу и заработок http://hsjp.eu/gui/profile.php?lookup=2538
1xslots
Extra super avana
Психология
Мы составили честный рейтинг всех игровых автоматов и на первом месте находится Gama casino, здесь быстрые выплаты, Гамма казино моментальное решение любых проблем, крутые турниры и лицензионные слоты.
SEO — это процесс улучшения видимости веб-сайта в поисковых результатах, продвижение сайта реклама таких как Google, Bing, Yandex и другие.
buy prilosec 20mg without prescription metoprolol 50mg oral order metoprolol generic
order latanoprost eye drop buy xeloda cheap order exelon without prescription
zovirax us buy xeloda 500mg pills rivastigmine 3mg cost
Быстрая финансовая помощь для всех ваших онлайн проектов займы онлайн, кредитки и займы.
double penetration
Where can I find best csgo skin gambling sites people discussing the best csgo gambling sites?
Цены на строительство заборов под ключ зависят установка заборов от большого количества факторов и особенностей.
Быстровозводимые строения – это современные строения, которые отличаются великолепной быстротой возведения и гибкостью. Они представляют собой здания, образующиеся из эскизно произведенных составных частей или узлов, которые имеют возможность быть скоро смонтированы на месте стройки.
Здание из сэндвич панелей под ключ отличаются гибкостью и адаптируемостью, что дозволяет легко преобразовывать а также переделывать их в соответствии с интересами заказчика. Это экономически результативное а также экологически надежное решение, которое в крайние годы заполучило маштабное распространение.
augmentin 1g
internet pharmacy mexico
Every woman wants to meet the standards of beauty https://www.bignewsnetwork.com/news/273953142/bohemia—the-sugar-system throughout her life.
Престиж: обучение в Нижнем Новгороде – центр дистанционного обучения повышение квалификации узнайте стоимость обучения.
where to buy prednisolone 5mg
Лучше чем поисковая система Google, переходите на сайт google.kz и вы найдете что ищите, лучшая альтернатива гуглу.
Доставка Elf Bar электронные сигареты купить в Москве за 30 минут электронки эльф бар Официальный сайт ELF BAR.
Check this site for more info http://beauting.org/index.php?module=forum&topic=4456&offset=0
В казино Гама игроки могут мгновенно получить доступ Gama казино ко всем своим любимым играм казино.
best price propecia 5mg no prescription
order premarin 0.625mg without prescription brand premarin 0.625mg buy sildenafil pill
premarin 600 mg sale cabergoline for sale canadian viagra and healthcare
omeprazole cheap order montelukast 10mg online buy lopressor generic
Marina Groenberg offers a brief biography, introducing her pathway marina groenberg to financial mastery.
Отсюда Вы можете быстро добраться до Эрмитажа, Русского музея, гостиницы новочеркасская, Исаакиевского собора или пешком прогуляться до Петропавловской крепости и Летнего сада.
buy telmisartan 80mg online cheap brand plaquenil buy molnunat 200 mg
compare propecia prices uk
ковер на стену интернет магазин
zyban cost australia
Престижное обучение в Самаре – центр дистанционного обучения обучение онлайн, дарим 30 дней на обучение.
Marina Groonberg wurde in einer Familie marina grenberg biografie von Luftfahrtingenieuren geboren.
generic finasteride canada
cheap propecia generic
stromectol 12mg online
Buy verified bing ads account
Купить грязезащитные ковры и дорожки в Москве можно на грязезащитный коврик дорожка черный, широкий выбор грязезащиты.
Mostbet India is a leading company in the sports betting industry, offering individuals the opportunity казино Гамма to bet for real money from the comfort of their homes, via the Internet.
can i buy doxycycline without a prescription
buy tetracycline no prescription
cheap doxycycline price
Doxycycline monohydrate 100 mg tablet
buy actos 10 mg
zoloft 25
buy lisinopril uk
Kamagra polo
Новости информационных технологий на Смоленском портале. Архив новостей. одиннадцать недель назад. 1 страница
side effects of zoloft
Быстровозводимые здания – это современные здания, которые различаются повышенной быстротой возведения и мобильностью. Они представляют собой здания, состоящие из предварительно созданных составных частей либо модулей, которые способны быть быстро установлены в месте развития.
Купить быстровозводимое здание из сэндвич панелей обладают гибкостью а также адаптируемостью, что дает возможность легко преобразовывать а также трансформировать их в соответствии с пожеланиями клиента. Это экономически лучшее и экологически стабильное решение, которое в последние лета заполучило широкое распространение.
cordarone brand name
purchase micardis online hydroxychloroquine 400mg pills molnunat 200 mg over the counter
where to buy liquid arimidex
Xenical
самолеты из Смоленска
claritin vs zyrtec
ivermectin 1 cream
buy lisinopril no prescription
finasteride tablets
Sildigra
Новости информационных технологий на Смоленском портале. Архив новостей. восемнадцать недель назад. 1 страница
cost of cialis soft tabs 10mg
cipo prograf
ciprofloxacin coupon
Pirfenex
Омлет с грибами и сыром
where can i buy finasteride propecia
levaquin generics
colchicine in pregnancy
Top manager Marina Groenberg leads Hemma Group with distinction marina groenberg biography A noted investor active in Europe and the US.
Benicar
Статьи и новости
amoxicillin liquid
amoxicilina 250mg/5ml
No Brasil, ate 2012, nao havia uma unica casa de apostas decente https://www.google.fr/url?sa=t&url=https://mostbet-br-brasil.com
how long does trazodone last in dogs
Lipitor
Новости информационных технологий на Смоленском портале. Архив новостей. двадцать шесть недель назад. 1 страница
order cenforce 100mg for sale buy generic cenforce 100mg buy chloroquine 250mg generic
finasteride purpose
doxycycline buy online canada
tetraciclina oftalmica
Doxycycline side effects uk
Автомобильные новости на Смоленском портале. Архив новостей. семь недель назад. 1 страница
prograf 5
trazodone blood sugar
side effects of amoxicillin
Lopressor
Смоленск в сети
can i buy colchicine online
side effects prednisone
furosemide
neurontin 50 mg
Lasix
stromectol ivermectin buy
авокадо и черносливом
purchase doxycycline online cheap
amoxicillin 500mg dosage
how to use albuterol inhaler
Tizanidine
Новости компьютерные на Смоленском портале. Архив новостей. четырнадцать недель назад. 1 страница
ciprofloxacin warnings
furosemide medication
cleocin side effects
Doxycycline 100mg pil emc
подборка рецептов для красоты и здоровья (мои рекомендации из личного опыта)
furosemide 20 mg for dogs
ciprofloxacin cream
where can i buy prednisone over the counter usa
Ed trial pack
Психология
doxycycline vidal
buy finasteride online
the best form of ashwagandha
Вы ищете надежное и захватывающее онлайн-казино, тогда Вулкан Платинум – идеальное место для вас!
Clozaril
Профессиональное SEO откроет вашему сайту дорогу к новым возможностям и клиентам интернет продвижение сайта яндекс профессиональные SEO услуги на страже вашего бизнеса.
Смоленск в сети
actos therapy
gabapentin half life
finasteride dosage
Новости политики на Смоленском портале. Архив новостей. три недели назад. 1 страница
clindamycin (active ingredient in cleocin)
tetracicline
can you get generic sildigra price
Cost doxycycline
Клава Мастер
amoxicilina efectos secundarios
tetracycline drugs
finasteride buy online
where to get propecia
Imdur
Improving indexing of pages that are already known to the search engine, link indexer page but are not getting added to the index.
Гостиница Россия
where can i get cheap levaquin without a prescription
effexor online
amoxicillin 875 mg
Вы ищете надежное и захватывающее онлайн-казино, тогда Вулкан Платинум идеальное место для вас!
Tizanidine
Психология
buy doxycycline injection
levaquin for sale
side effect for zoloft
Cilostazol
KetoFood — купить капсулы для похудения
finasteride warnings
what is cetirizine
albuterol aer hfa
Advair diskus
Neben ihren geschaftlichen Erfolgen widmet sie sich der marina grenberg biografie Restaurierung historischer Denkmaler und engagiert sich fur wohltatige Zwecke.
buy zoloft on line no prescription
Ритуальные услуги и товары в Москве и Московской области со скидкой https://tzseo.ru/ritualnye-uslugi-v-raznyh-kulturah-shodstvo-i-razlichiya/, организация похорон является сложным и ответственным процессом.
Подарки
how much is propecia in canada
buy augmentin without prescription
Кисти для макияжа – это незаменимый женский инструмент все для макияжа лица для создания идеального макияжа.
The service will help you to attract the indexing robots of Google search engine (Googlebot) linkindexer page and get indexed your web page or backlinks faster.
10 самых перспективных стартапов. Рейтинг Forbes — 2022 https://spark.ru/startup/intermonte/blog/13731/kak-rabotat-nad-startapom-kogda-zakanchivaetsya-motivatsiya, изготовлено 18 марта 2022 года.
buy cialis for sale female cialis cvs cheap sildenafil tablets
buy tadalafil 20mg pill purchase tadalafil online cheap buy sildenafil 50mg for sale
buy cenforce 100mg for sale generic naproxen 250mg buy chloroquine
Грузоперевозки. Доставка посылок и писем в Европу из Калинимнграда Пассажирские перевозки в Европу из Калининграда Грузоперевозки (запчасти) из Германии и Польши.
What are the problems facing the contemporary banking system and how Victor Orlovski do international relations affect the efficiency of financial technologies.
where can i buy cefdinir order cefdinir for sale buy lansoprazole no prescription
canadian pharmacy coupon
Thank you for this great piece of content. Best Regards
https://www.lorianne.fr/application-1xbet-1xbet-france-application.html – lorianne.fr
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get three emails with the same comment. Is there any way you can remove people from that service? Thanks a lot!
recombigen.com
Мальчишник — это незабываемое событие, отрывки из которого вы будете переживать снова и снова חשפניות-
hello!,I like your writing so much! share we be in contact extra approximately your article on AOL? I require a specialist in this space to resolve my problem. May be that is you! Looking ahead to look you.
swadhin.net.in
stromectol pill price
generic amoxil otc
buy stromectol
Это девушки, которые работали в таких местах, как Фоссикт, חשפניות Шандо, Гого и других
generic valtrex online
Интернет быстрыми шагами врывается в наш быт и в нашу жизнь создание сайта онлайн бесплатно будет приносить львиную долю прибыли в бюджет компании.
albuterol medicine in india
propecia price compare
can you buy doxycycline over the counter usa
Nuru massage is an exotic and sensual massage technique massage price that originates from Japan.
buy furosemide 40 mg
Descubre Relifix Crema, tu aliado contra las molestias Relifix en la farmacia de hemorroides.
Быстромонтируемые строения – это прогрессивные строения, которые различаются повышенной скоростью установки и гибкостью. Они представляют собой постройки, образующиеся из предварительно созданных составных частей или блоков, которые могут быть быстрыми темпами установлены на участке строительства.
Строительство быстровозводимых зданий из металлоконструкций отличаются гибкостью а также адаптируемостью, что дает возможность просто менять а также переделывать их в соответствии с пожеланиями покупателя. Это экономически результативное а также экологически устойчивое решение, которое в последние годы приобрело маштабное распространение.
purchase provigil without prescription promethazine brand order prednisone 40mg
modafinil 100mg uk buy promethazine without prescription order deltasone 10mg pill
As the Kingdom of Saudi Arabia gears up to drastically grow its economy, it is also clear that diversity, reputation house reviews equity and inclusion (DEI) must be taken seriously in all areas for the country to thrive.
Компанія Trafin, відчуваючи потенціал України, навіть у важкі часи продовжує інвестувати у розвиток ТРЦ, https://www.4595.com.ua/list/443285 що стимулює українські та міжнародні бренди розширювати свою присутність в ньому.
buy cefdinir sale glycomet 1000mg generic order lansoprazole 30mg without prescription
https://felomena.com/wp-includes/inc/?20_priznakov_shluhi__devushka_shluha__esli.html
malegra 120 mg
azithromycin 260 mg
bukkake
can i get cheap cleocin without a prescription
gabapentin 300 mg capsule
buy cleocin online cheap
cefixime
lipitor 20mg price india
buy malegra 50 mg
Clomid
Скачать сливы курсов бесплатно онлайн через торрент большакова алалия скачать присоединяйтесь к нам и начните свое обучение уже сегодня!
http://bananowecuksy.phorum.pl/viewtopic.php?p=352496
amoxicilina 500 mg
atorvastatin 40mg generic order albuterol 100mcg online cheap order amlodipine generic
ciproxine
EVOLUTE центр Маршал — первый за Уралом https://evolute-krasnoyarsk.ru/ официальный дилер электромобилей Evolute.
https://blagmama.ru/forum/index.php?autocom=blog&blogid=4475&
cytotec for induction of labor
sildenafil generic 100 mg
ceftin 203
trazodone blood sugar
purchase absorica online cheap order zithromax pills zithromax sale
order isotretinoin 20mg zithromax 500mg price order zithromax 250mg generic
Foot Trooper Spray es una opcion efectiva en Peru para combatir infecciones foot trooper donde lo venden por hongos en los pies y eliminar malos olores.
furosemide 40mg tab
Horacio Pagani patrimonio
amoxicillin online australia
https://farmaciaonline.men/# farmacie on line spedizione gratuita
https://vk.com/ku4ababla?w=wall-31283784_10192029/all
CBD online
get generic levaquin without rx
Medication information. Brand names.
viagra pills
Everything trends of medicine. Get information here.
hq pharmacy online 365
THC e CBD
オンラインカジノ カジノx (casino-x): カジノx スピーディな入場、寛大なボーナス、華やかなゲーム、公正な払い戻し!
Meds information for patients. What side effects?
cost abilify
Everything about pills. Read here.
Cannabis Light
buy doxycycline 100mg
Medicine information leaflet. Brand names.
minocycline
Best information about pills. Read here.
Sustarox es un producto disenado para aliviar rapidamente el dolor en articulaciones sustarox mercado libre y mejorar el bienestar general de tu sistema musculoesqueletico.
Medicines information leaflet. Drug Class.
lyrica
Some information about medicament. Read information now.
furosemide 20 mg tabs
Medicament information leaflet. Effects of Drug Abuse.
norvasc
Best about medicines. Read now.
suprax 200 mg capsule in usa
Pilex
ashwagandha capsule
Пудинг из чиа с манго
Medicament prescribing information. Drug Class.
can i get cipro
Best trends of medication. Read information now.
zoloft 50 mg
Drug information. Brand names.
minocycline
Everything information about medicines. Get now.
gabapentin 600 mg
Medication prescribing information. Effects of Drug Abuse.
fluoxetine
Actual news about medication. Get now.
buy lisinopril without a prescription
can i buy levaquin
Medicament information for patients. Cautions.
tadacip
Some news about medicine. Read here.
order azithromycin 500mg online cheap azithromycin pills neurontin canada
order azithromycin 500mg without prescription azipro usa oral gabapentin 800mg
Meds information sheet. Short-Term Effects.
zovirax order
Everything about medicines. Read information now.
lipitor generic buy generic proventil 100 mcg amlodipine 10mg tablet
gabapentin medlineplus
Motion Energy balsamo ofrece alivio rapido y efectivo para dolores articulares, motion energy, motion energy precio perú inkafarma mejorando la calidad de vida de quienes lo usan.
Medicines information for patients. Generic Name.
effexor
Everything about drug. Read now.
Pills prescribing information. Drug Class.
zenegra
Actual news about medicine. Read information now.
Medicine prescribing information. What side effects?
tadacip medication
All news about medicament. Get here.
finasteride tablets
Обратитесь в наш сервисный центр по ремонту компьютеров и ноутбуков, ремонт ноутбуков цены чтобы получить высококачественное обслуживание и быстрое восстановление Вашего технического устройства.
Medicine prescribing information. Long-Term Effects.
fluoxetine tablets
Everything trends of medication. Get here.
Торф в Пушкино
Medicament information for patients. Brand names.
paxil
Everything about meds. Read information now.
zyrtec
Meds information sheet. Cautions.
nolvadex
All information about drug. Get here.
ashwagandha tablets
finasteride tablets
baclofen prescription uk
Medication information. Generic Name.
prednisone
Some information about medicament. Read information now.
buy pantoprazole 40mg pills buy phenazopyridine for sale buy phenazopyridine 200mg without prescription
cost of cleocin without prescription
Even though we communicate differently, what people say online can house serm make or break a business.
Drug information leaflet. Long-Term Effects.
maxalt price
Best about pills. Read information here.
Компания по Профессиональному клинингу помещений Санкт-Петербурга Уборка мероприятий мы используем исключительно профессиональную химию.
Drugs information sheet. Drug Class.
lioresal generic
All news about meds. Read now.
levaquin cost
Drug information for patients. Effects of Drug Abuse.
celebrex
All about drug. Read information now.
Zithromax
Medicines information. Generic Name.
glucophage generic
Best news about drug. Read information now.
furosemide 50 mg
Drugs information for patients. Short-Term Effects.
fluoxetine
Best trends of medicament. Get now.
Vormixil es una capsula disenada para fortalecer el sistema inmunitario y eliminar parasitos, utilizando ingredientes Vormixil cápsulas naturales para ofrecer un enfoque integral al bienestar.
1000 рублей бездепозитный бонус за регистрацию в казино, фонтан казино бонусы бездепозитный бонус Fontan Casino.
gabapentin 300 mg for dogs
buy lisinopril from new zealand without prescription
where to buy prograf
Drugs information sheet. Cautions.
levitra medication
Some about medicine. Read information here.
Vasotec
гостиницы
Pills information. Generic Name.
where to buy strattera
Best about medicine. Read information now.
aurogra
zyrtec for kids
Meds information sheet. Generic Name.
norvasc cheap
Some about medicines. Get here.
order cialis soft tabs online
can i purchase generic sildigra pills
topical finasteride
prednisone medication
Drugs information sheet. Drug Class.
cialis soft otc
Actual information about meds. Get information now.
Actos
Самые свежие фильмы и сериалы онлайн бесплатно на Лордфильм Лордфильм загрузка без регистрации и смс.
Клава Мастер
Meds information. Effects of Drug Abuse.
baclofen buy
Best trends of pills. Read here.
prednisone indications
Drugs information sheet. Drug Class.
pregabalin buy
All about medicine. Get here.
slots games furosemide over the counter buy furosemide 40mg for sale
free slot playing poker online buy furosemide no prescription
bondage gay sex free
cordarone 100 mg
Полностью автоматический проект по крипто-траффику РЎryptoGrab наша команда имеет большой опыт работы в этой сфере с 2017 года.
Медицинская справка для замены водительского удостоверения — официальный документ, купить справку на права который подтверждает состояние здоровья, и является допуском к вождению автомобилем.
Medicament prescribing information. What side effects?
how to get bactrim
Everything information about medication. Get information here.
mostbet fake or real
https://edapotheke.store/# online apotheke gГјnstig
Pills information leaflet. Long-Term Effects.
cost of finpecia
All information about meds. Read now.
lisinopril medication otc
Medication prescribing information. Cautions.
cialis soft
Some about medicines. Read now.
Mostbet e uma grande empresa internacional de apostas mostbet código promocional No site oficial da marca
furosemide dosage
Drugs information. What side effects can this medication cause?
cleocin prices
Everything information about drug. Read information here.
toradol allergy
Medicine information for patients. Drug Class.
fosamax
Actual about pills. Read information now.
cordarone 200 mg tablets price
Pills information for patients. What side effects?
lyrica
Actual information about pills. Get information now.
ashwagandha supplement
doxycycline hyclate 100 mg tablet para que sirve
buy sildigra without prescription
synthroid 0.125 mcg
Tadora
Drugs prescribing information. Effects of Drug Abuse.
lisinopril for sale
Everything about medicines. Read information here.
Новости Чехии и Праги на русском – от чешского новостного агентства Деловая Европа, самое актуальные и свежие новости мира, Европы и Чехии
Новости политики на Смоленском портале. Архив новостей. двадцать шесть недель назад. 1 страница
Причины, когда нужно заменить права, могут быть разными — но при любых обстоятельствах купить справку для замены водительских прав для получения документа нужно пройти медкомиссию и оформить медсправку.
cost pantoprazole 40mg buy pantoprazole paypal buy pyridium without prescription
trazodone hcl 50mg
Meds information. Generic Name.
synthroid tablets
All trends of meds. Read here.
cialis soft tabs price usa
Medicine information leaflet. Cautions.
prozac cost
All news about drugs. Get here.
cost cheap levaquin price
where can i buy generic levaquin price
trazodone hcl 50mg
Drug prescribing information. Brand names.
zofran
Best about meds. Get now.
Drugs information sheet. Effects of Drug Abuse.
fosamax buy
Some what you want to know about medicament. Get now.
legitimate online pharmacy usa
http://itfarmacia.pro/# farmacia online miglior prezzo
Мы гарантируем, что наш сайт предлагает только высококачественную закись азота, купить баллон с веселящим газом соответствующую всем необходимым разрешениям и мировым стандартам.
Medicine prescribing information. What side effects?
lyrica cheap
Actual about drugs. Read here.
Откройте новые возможности в мире азартных игр с нами дедди зеркало онлайн исследуйте мир азарта и станьте настоящим победителем!
side effects to zoloft
Medication information leaflet. Generic Name.
buy generic promethazine
Actual what you want to know about medicament. Get information here.
Motion Energy Gel is a unique formulation that uses a mixture of plant extracts and natural ingredients motion energy drug to tackle inflammation, pain, and stiffness in your joints and muscles.
Этот город можно узнавать бесконечно, всякий раз восторгаясь, экскурсия на автобусе даже если живёшь здесь с рождения.
Medication prescribing information. Drug Class.
lasix
Everything about drugs. Get information now.
Medicine information. Long-Term Effects.
strattera
Actual trends of meds. Get information now.
poker online sites order vibra-tabs online ventolin inhalator without prescription
gambling casinos poker games online cheap albuterol
finasteride warnings
medicine prednisolone 5mg
Medicament information sheet. Generic Name.
neurontin
Everything information about drug. Read here.
Medication information. What side effects can this medication cause?
sildigra
Everything information about pills. Read now.
Drugs information sheet. Brand names.
viagra
Some trends of meds. Read now.
Aara Education Consultancy is a Unique Educational Consultancy Гама Казино with our intention of formulating change and making students understand.
symmetrel pills buy aczone buy avlosulfon 100 mg online
buy kamagra tablets online
Можете ли вы назвать себя удачливым человеком адмирал х регистрация большинство людей считают, что удача всегда обходит их стороной.
finasteride 1
gabapentin for cats
Medicament prescribing information. Long-Term Effects.
levitra
Some about medication. Read information here.
Medication information sheet. What side effects can this medication cause?
get propecia
Some news about drug. Read information here.
cost of generic cleocin without rx
Drugs information for patients. Cautions.
get neurontin
Some what you want to know about drugs. Read information here.
Приглашаем Вас на обзорную экскурсию в которой всего за 2 часа экскурсия по москве на автобусе Вы увидите все основные достопримечательности.
Gonzo Casino, bonus bez depozytu, darmowe spiny za rejestrację, darmowe spiny za rejestrację 2023 logowanie w GonzoCasino.
how much is cialis soft tabs in canada
Meds information sheet. What side effects?
buy aurogra
Everything what you want to know about medicament. Get here.
Drugs prescribing information. Short-Term Effects.
cleocin
Best information about pills. Get information here.
Психология
3Д печать и покраска юнита из Starcraft 2 3D печать Новосибирск студия 3D Magic занимается 3D моделированием.
Melbet promo code 2023 is MBMAX melbet india promo code use the promo code during the registration process to get the highest welcome bonus.
Medicines prescribing information. Long-Term Effects.
glucophage prices
Best what you want to know about drug. Read here.
ashwagandha walmart
Medication information leaflet. Generic Name.
seroquel
Actual trends of drug. Read here.
Drugs information sheet. Cautions.
lyrica for sale
All about drugs. Read now.
Drugs information. Drug Class.
trazodone
All about medicines. Read now.
gabapentin for cats
Vavada Casino, kasyno online, rejestrację w Kasyno Vavada, vavada free spins darmowe spiny bonus bez depozytu.
Verde Casino is a new online casino site for 2022 100 zl za rejestrację bez depozytu It offers plenty of casino games, safe and secure payment methods & rewarding promotions. Try it here!
Medication information. What side effects can this medication cause?
seroquel brand name
Some news about medication. Get here.
Drug prescribing information. Generic Name.
cephalexin
Best about medicines. Read information here.
Medicament information for patients. Effects of Drug Abuse.
xenical
Some trends of meds. Get information here.
Высокооплачиваемая работа для девушек в эскорте и досуге в разных странах работа досуг требования: девушки в возрасте от 18 до 30 лет приятная внешность
free roulette online play online blackjack ivermectin uk buy
online roulette game real money sugarhouse casino online ivermectin 3mg online
finasteride 1 mg
Online medicine order: cheapest online pharmacy india – pharmacy website india
Medicament information. What side effects can this medication cause?
buy generic neurontin
Some about medication. Get here.
Pills information leaflet. What side effects can this medication cause?
zoloft order
Some information about meds. Get here.
Medication information. Cautions.
can you get lisinopril
Everything what you want to know about medicament. Read information now.
zyrtec vs allegra
Medication information sheet. Effects of Drug Abuse.
nolvadex
Everything what you want to know about drugs. Get here.
Medicine information for patients. Effects of Drug Abuse.
propecia
Everything about medicine. Read now.
Meds prescribing information. Cautions.
zithromax
Everything what you want to know about medicines. Get information here.
doxycycline without rx
gabapentin for dogs pain
Medication information leaflet. Cautions.
prednisone
All information about medicines. Read here.
Medicine information leaflet. Effects of Drug Abuse.
clomid order
Actual news about medicines. Get now.
how to get symmetrel without a prescription buy atenolol 50mg pill generic avlosulfon
buy antibiotics doxycycline canada
Процесс 3D-печати. Анимация, показывающая, как 3D-принтер печатает трехмерный объект, слой за слоем 3D печать Новосибирск Моделирование и постобработка.
Medicine information sheet. Short-Term Effects.
order nexium
Some trends of medicines. Get now.
dog furosemide
cordarone for children
buy prednisone online chemist
Medicines information. Effects of Drug Abuse.
lopressor
All trends of medicines. Get information here.
canadian family pharmacy: canadian compounding pharmacy – canadian drug pharmacy
Drugs prescribing information. Drug Class.
silagra medication
Actual information about pills. Read now.
how to buy cheap levaquin online
Medicines information for patients. What side effects?
rx abilify
Actual information about medicines. Read here.
Female cialis soft
medico online prednisone
Medication information for patients. Effects of Drug Abuse.
where can i get cleocin
All about pills. Get now.
опт
Drugs prescribing information. Effects of Drug Abuse.
prednisone buy
Some information about pills. Get information here.
methylprednisolone 4mg oral brand adalat 30mg triamcinolone price
Meds information for patients. What side effects?
trazodone buy
Everything trends of medicines. Get now.
tacrolimus cheap
online poker real money casino blackjack order synthroid 150mcg pill
blackjack online us poker online free purchase levothyroxine generic
Drugs information leaflet. Generic Name.
xenical order
Best what you want to know about medicament. Read information now.
https://kover-na-zakaz-1knz.ru/
buy finasteride online
Meds information sheet. Drug Class.
lyrica
Some information about medicine. Get information here.
Medicament information leaflet. Generic Name.
prednisone
Everything trends of meds. Get information now.
gabapentin used for
Все игровые для ПК шутеры на Immortal Redneck: скачать бесплатно на компьютер скачать бесплатно на максимальной скорости
Keflex
Завод может принимать до 500 т семян подсолнечника в вагонах victor evgenevich ponomarchuk viol и до 1 тыс. т семян подсолнечника автотранспортом в сутки.
Pills prescribing information. Generic Name.
cephalexin
Best information about medication. Get here.
Medication information sheet. Drug Class.
promethazine order
Actual information about medication. Get here.
indian pharmacy: world pharmacy india – world pharmacy india
Особливо широкі перспективи для цієї продукції відкриваються victor ponomarchuk на китайському ринку.
Medication information for patients. Effects of Drug Abuse.
cheap zofran
Everything information about medicine. Read information now.
can you buy doxycycline over the counter in america
urex-m furosemide
Drug information leaflet. Effects of Drug Abuse.
minocycline medication
Best about drugs. Read here.
furosemida dosis
Drug prescribing information. What side effects can this medication cause?
zithromax pills
Best information about drugs. Get information now.
Medicament information for patients. Long-Term Effects.
zoloft tablet
Actual trends of medicine. Read information here.
Промышленная группа ViOil создана Виктором Пономарчуком в 2006 году на базе аграрных активов пономарчук viol промышленной группы «КМТ».
gabapentin for dogs pain
Pills information for patients. Brand names.
rx cytotec
Best about drug. Get information here.
Бизнес, местные власти и инициативная общественность объединились ради благотворительности victor evgenevich ponomarchuk viol Промышленная группа ViOil.
Medication information sheet. Long-Term Effects.
cheap lisinopril
Some information about meds. Read here.
Drug information for patients. Generic Name.
order cialis soft
Everything news about medicine. Get now.
prednisone contraindications
order erythromycin online
viagra for men cost
clonidine sale
Medication information leaflet. What side effects can this medication cause?
mobic
All news about medication. Read now.
Промышленная группа Vioil растительные масла и жиры для пищевых производств пономарчук viol является одним из крупнейших переработчиков масличных культур в Украине.
zanaflex migraine
Medicine information for patients. Long-Term Effects.
can i order ampicillin
All trends of medicine. Read information now.
ViOil реализует наливное и фасованное масло — растительное нерафинированное подсолнечное victor evgenevich ponomarchuk viol а также рафинированное дезодорированное вымороженное.
Meds prescribing information. What side effects can this medication cause?
flibanserina
Best information about pills. Get now.
purchase clomiphene generic clomiphene 100mg pill order imuran 25mg
clomiphene pill order imuran 25mg for sale buy azathioprine 50mg for sale
indian pharmacies safe: cheapest online pharmacy india – cheapest online pharmacy india
[url=https://hydroxychloroquine.science/]hydroxychloroquine 4 mg[/url]
can you buy generic prednisone without dr prescription
Pills information for patients. Short-Term Effects.
lisinopril without insurance
Everything what you want to know about drugs. Get now.
buy methylprednisolone tablets order nifedipine online cheap buy generic aristocort 4mg
ViOil is a manufacturer and distributor of packed oil, schroth, victor ponomarchuk wood pellets, fats, tropical oils and fatty acid.
Pills information leaflet. Short-Term Effects.
baclofen
Some what you want to know about medicines. Get information now.
Drug prescribing information. Short-Term Effects.
prednisone buy
All information about pills. Read now.
ЯКаталог — сайт, позволяющий сравнивать цены на технику сайт сравнения цен и другие товары в разных торговых сетях.
https://kovry-iranskie-1.ru/
how to buy lisinopril without a prescription
Моментально возводимые здания: финансовая польза в каждой составляющей!
В современном обществе, где минуты – капитал, объекты быстрого возвода стали решением по сути для предпринимательства. Эти прогрессивные сооружения объединяют в себе устойчивость, эффективное расходование средств и мгновенную сборку, что дает им возможность наилучшим вариантом для разных коммерческих начинаний.
[url=https://bystrovozvodimye-zdanija-moskva.ru/]Металлоконструкции здания под ключ[/url]
1. Срочное строительство: Минуты – важнейший фактор в коммерции, и здания с высокой скоростью строительства способствуют значительному сокращению сроков возведения. Это чрезвычайно полезно в ситуациях, когда необходимо оперативно начать предпринимательскую деятельность и начать прибыльное ведение бизнеса.
2. Бюджетность: За счет оптимизации производства и установки элементов на месте, затраты на экспресс-конструкции часто бывает менее, по сопоставлению с традиционными строительными задачами. Это способствует сбережению денежных ресурсов и обеспечить более высокий доход с инвестиций.
Подробнее на [url=https://xn--73-6kchjy.xn--p1ai/]https://scholding.ru/[/url]
В заключение, моментальные сооружения – это идеальное решение для бизнес-проектов. Они объединяют в себе скорость строительства, финансовую эффективность и твердость, что дает им возможность первоклассным вариантом для деловых лиц, имеющих целью быстрый бизнес-старт и извлекать прибыль. Не упустите возможность сократить затраты и время, идеальные сооружения быстрого монтажа для вашего следующего делового мероприятия!
Medicament information. Drug Class.
bactrim without a prescription
Everything trends of drugs. Read information here.
Buy real steroids with fast delivery to the usa Buy Oral Steroids Online in USA – anabolic steroids For Sale
Pills information. What side effects can this medication cause?
cytotec without prescription
Some information about pills. Get here.
Антикоррозийная обработка в Екатеринбурге с гарантией! покрыть авто керамикой цена полировка и покраска кузова АнтикорАвто.
Meds information sheet. Generic Name.
tadacip
All what you want to know about pills. Read now.
advair without prescription
ashwagandha side effects
Medicines prescribing information. Brand names.
cost kamagra
Some trends of drug. Get information now.
purchase perindopril without prescription buy cheap aceon fexofenadine 120mg tablet
Medicine information leaflet. Drug Class.
cytotec
Actual information about drugs. Read information now.
indianpharmacy com: buy prescription drugs from india – india pharmacy
Pills prescribing information. What side effects?
buy generic motrin
All news about medicine. Read now.
Для решения проблем с частичным/полным отсутствием зубов на верхней или нижней челюсти https://stomatolog-ortoped.by/ рекомендуем обратиться к профессиональному стоматологу-ортопеду.
goli ashwagandha
Agenda. Allerlei praatjes. Nou ja, misschien een kleine subjectieve mening over wat er gebeurt https://www.twitch.tv/meghann_celius/about
zanaflex tablets
Medicines information for patients. What side effects can this medication cause?
zovirax
Best trends of medicament. Read now.
https://khabara.ru/174025-press.html
прогнозы на футбол сегодня экспресс
Meds information leaflet. Brand names.
seroquel
All about pills. Get here.
how much is the generic albuterol
http://www.infopiter.ru/piter/culture.html
Drug prescribing information. What side effects can this medication cause?
buy generic zithromax
Some about pills. Get information now.
effexor availability
Я буду рад помочь Вам: Удобное и не дорогое такси из Новосибирска и аэропорта Толмачево междугороднее такси в любую точку Сибири и Алтая.
zoloft 1540 mg daily
order levitra 20mg sale levitra 10mg for sale buy generic zanaflex for sale
buy vardenafil without prescription buy levitra 20mg sale oral zanaflex
Наслаждайтесь эксклюзивными бонусами нашего казино gama казинл здесь ваши шансы на успех выше.
Medication information leaflet. Generic Name.
cordarone order
Some trends of medication. Read here.
buy paroxetine tablets
how to get skin csgo
Medicines information. Short-Term Effects.
neurontin
Best about meds. Read information here.
Узнайте, что значит настоящий азарт в нашем лицензированном онлайн казино гаммаказино лучшие игровые автоматы.
sildenafil 50 coupon
Embark on an exciting exploration of CSGO gambling with our expertly Buy a Phone Number Online curated list of the best 10 new CSGO sites.
Drugs prescribing information. Long-Term Effects.
order neurontin
Actual what you want to know about medication. Get information now.
can i get cheap cialis soft tabs tablets
Medicine information sheet. Short-Term Effects.
buy generic prednisone
Some news about drugs. Get now.
Meds information leaflet. Short-Term Effects.
where to get mobic
All information about medication. Read now.
купить квартиру на кипре недорого вторичное жилье https://agentstvo-nedvizhimosti-kipr.ru/
indianpharmacy com: indian pharmacy online – reputable indian online pharmacy
Отправьтесь в увлекательное путешествие по миру слотов и больших выигрышей gama казик зеркало играйте у нас.
Medication prescribing information. Brand names.
tadacip otc
Best about meds. Get information now.
[url=https://tadalafil.africa/]tadalafil price in mexico[/url]
doxycycline tablets buy
Meds information for patients. Effects of Drug Abuse.
can i order ampicillin
All what you want to know about drugs. Read now.
https://happyfamilyshop24.com/viagra
Запускайте колесо удачи и позвольте судьбе удивить вас бесплатные симуляторы игровых автоматов фортуна улыбается каждому.
Medicines information leaflet. Cautions.
viagra soft medication
Everything what you want to know about meds. Read here.
Medicament prescribing information. Cautions.
viagra
Best news about pills. Get information now.
https://www.bez-granic.ru/main/voprosyoglavnom/dzhordano-bruno-o-geroicheskom-entuziazme-ili-o-borbe-protiv-bezdarnosti.html?fbclid=IwAR30o2mPWAXCzQFtA7_dIYFGDIus3O0NuNMeo7ydjZ9mTN0YxIjUve4PXwY
Their prescription savings club is a godsend. http://azithromycinotc.store/# where to get zithromax over the counter
Невероятные эмоции, впечатляющие выигрыши и крутые бонусы ждут вас gamma казино отзывы станьте следующим победителем.
where can i buy doxycycline over the counter
cost of furosemide 40 mg
Medicament prescribing information. Drug Class.
cephalexin
Everything about drugs. Get information now.
регистрация временная в москве для граждан рф https://registracia-v-moskve.ru/
See our selection of the best CSGO gambling sites in 2023 and win amazing and valuable daily dot csgo gambling CSGO skins by placing bets on popular casino games.
cleocin price per pill
Разработка сайта цена Симферополь: создание интернет сайта симферополь качество и экономия в одном флаконе.
Medicine information sheet. What side effects can this medication cause?
norpace cheap
Actual news about meds. Get information now.
order perindopril 8mg generic order fexofenadine generic allegra 180mg ca
Medicine prescribing information. What side effects can this medication cause?
buy cleocin
Best trends of medicament. Read now.
Sec Notix Отзывы
does zyrtec cause drowsiness
Medicament information. Short-Term Effects.
levaquin
Actual about drugs. Read information here.
Cipro
doxycycline 600 mg buy doxycycline doxycycline canada brand name
Pills information sheet. Brand names.
lisinopril
All news about medicine. Get here.
discount cialis generic
https://silavmisli.ru/articles/cska_ughe_ne_tot.html
Medication information. What side effects?
cytotec
Some news about pills. Read information here.
furosemide 50 mg
Medicine prescribing information. Generic Name.
promethazine
Everything news about meds. Get information here.
Pills information. What side effects?
zovirax
Best information about medicines. Get here.
buy metformin online mexico
Meds information leaflet. Long-Term Effects.
abilify
Best information about drugs. Get now.
https://avtoservice-skoda-3.ru/
phenytoin 100 mg without prescription buy flexeril without a prescription oxybutynin 2.5mg without prescription
dilantin without prescription purchase phenytoin pills buy oxytrol tablets
Разработка и продвижение сайта цена Симферополь: лендинг сайт цена симферополь качество и экономия в одном флаконе.
Their global distribution network is top-tier. http://edpillsotc.store/# erectile dysfunction drug
prescription prednisone
citalopram tab 20mg
Drugs information. What side effects?
flibanserina online
All information about drugs. Get information now.
Sev Vivos Отзывы
Medication information leaflet. Generic Name.
bactrim
Everything trends of medicine. Read information now.
Drugs information. Generic Name.
fluoxetine
Everything what you want to know about medicines. Get information now.
clomid clomiphene citrate
get generic sildigra price
печать на 3д принтере https://3d-pechat-moskwa.ru/
furosemide
Their worldwide delivery system is impeccable. http://azithromycinotc.store/# zithromax 250 mg pill
Drugs information. What side effects can this medication cause?
sildigra pill
Everything information about medicament. Get now.
order claritin pills priligy for sale buy priligy 60mg online
Для качественной обработки от насекомых, вирусов, грызунов и запахов необходима помощь профессиональной службы СЭС Обработка от клопов в Челябинске обращайтесь за услугами в санитарную службу.
The Book of Dead slot game is a popular online casino game inspired where to play book of dead by ancient Egyptian themes and symbols.
Medicament prescribing information. Long-Term Effects.
clomid
Actual news about meds. Read here.
ed pills that really work ed pills non prescription medications for ed
An unmatched titan in the world of international pharmacies. https://edpillsotc.store/# ed pills cheap
Medicine information. Cautions.
lasix for sale
All news about medication. Get now.
Стратегии, секреты и рекомендации по игре в онлайн-слоты от экспертов дедди как выиграть
https://glavcom.info/ekolohichni-perevahy-vykorystannia-teplovykh-nasosiv-spozhyvannia-enerhii-ta-vykydy-co2/
ft aurogra
https://www.feldbahn-ffm.de/wp-content/pgs/chto_delaty_kogda_ne_hvataet_vremeni.html
Evall Vellc Отзывы
Выберите свой путь к азарту с разнообразием игр в казино регистрация daddy casino получите невероятные эмоции.
Станьте чемпионом и освойте арену азартных битв в казино дэдди казино рабочее зеркало Исследуйте путь от новичка до профессионала в мире казино.
Беспроигрышные стратегии и подходы к игре и шансы на победу дэдди казино работающее зеркало получите невероятные эмоции.
Советы по управлению банкроллом для игры в онлайн дедди играть без регистрации Исследуйте путь от новичка до профессионала в мире азарта.
Промислова група «КМТ» з’явилася на ринку на початку 1990-х віктор пономарчук vioil створили кілька вінницьких підприємців.
Це дозволило ViOil майже в три рази збільшити потужності віктор пономарчук vioil концентрація виробництва дозволяє знизити собівартість продукції.
furosemide 40mg
https://uec.asia/
Our services include refurbishing components, providing replacement parts, offering filtration systems, purifying water, manufacturing gaskets and sealing equipment for the oil and gas, chemical, and energy sectors. Our collaborations with clients are based on our expertise and technical proficiency.
Drug information leaflet. Drug Class.
neurontin
Best information about medicament. Get information here.
accutane 20 mg buy online
albuterol mexico pharmacy
protonix uses
ViOil входит в тройку крупнейших производителей подсолнечного масла віктор пономарчук vioil и является лидером по выпуску рапсового масла.
Drug information. Effects of Drug Abuse.
cordarone generics
Actual about meds. Get information here.
https://uec.asia/
Our services include the re-engineering of components, replacement parts, filtration systems, water purification solutions, gaskets, seals, and equipment for the oil and gas, chemical, and energy sectors. We always strive to provide our clients with a combination of our expertise and technical proficiency.
ViOil – один из самых мощных производителей растительных масел віктор пономарчук vioil имеет 30 лет опыта работы на масложировом рынке.
Medicines information. Drug Class.
cost of zofran
All trends of medicine. Get here.
furosemide 40 mg over the counter
Drugs information for patients. Long-Term Effects.
promethazine brand name
All about drugs. Read here.
cleocin 300 mg cost
https://okon-remontov.ru/
how much gabapentin for dog
reliable rx pharmacy
prograf 1mg
[url=https://paxil.science/]generic paxil 40 mg[/url]
Meds information for patients. Generic Name.
lisinopril
Some trends of medicines. Get here.
Кредитные карты с периодом 120 дней без процентов – это специальные предложения https://120-dnei-bez-procentov.ru/ которые позволяют владельцам кредитных карт пользоваться кредитными средствами без уплаты процентов.
ozobax pill generic ketorolac buy toradol 10mg online cheap
brand baclofen 10mg order lioresal without prescription order generic toradol 10mg
Как выбрать и установить тепловой насос NIBE https://informnapalm.org/blog/kak-vybrat-i-ustanovit-teplovoi-nasos-nibe-prakticheskie-sovety-dlya-optimalnoi-raboty-sistemy/
gabapentin side effects elderly women
Drug information. Short-Term Effects.
norpace generic
Everything what you want to know about pills. Get now.
Use the 1xBet promo code for registration : VIP888, and you will receive how to get promo code in 1xbet before registering, you should familiarize yourself with the rules of the promotion.
stromectol price us
Medication prescribing information. What side effects?
colchicine
Some information about medicine. Read here.
https://tsucompany.uz/
Компания Turan – ваш надежный партнер в области промышленного оборудования для энергетики, нефти и газа! Мы гарантируем качество и надежность наших продуктов благодаря сотрудничеству с проверенными мировыми производителями. Наш широкий ассортимент включает в себя трансформаторы, генераторы, компрессоры и насосы, чтобы удовлетворить все ваши потребности в энергетике, нефти и газе. Кроме того, мы предлагаем высококачественное сервисное обслуживание, включая установку, наладку и техническую поддержку, с помощью опытных специалистов. Наш международный опыт поможет вам решить любые задачи, связанные с вашим бизнесом, и наше постоянное следование новым технологиям и инновациям поможет увеличить производительность и снизить затраты. При выборе Turan вы получаете надежного партнера, который поможет вам развить ваш бизнес в сфере энергетики, нефти и газа. Мы гарантируем качество, надежность и профессионализм во всех аспектах нашей работы. Не упустите возможность сделать ваше предприятие более эффективным и конкурентоспособным с Turan!
buy cheap lisinopril 40 mg no prescription
https://tsucompany.uz/
Компания Turan – ваш надежный партнер в области промышленного оборудования для энергетики, нефти и газа! Мы гарантируем качество и надежность нашей продукции, сотрудничая только с проверенными мировыми производителями. Наше оборудование способно справиться с самыми сложными задачами. Turan предлагает широкий ассортимент оборудования, включая трансформаторы, генераторы, компрессоры и насосы, чтобы удовлетворить все ваши потребности в энергетике, нефти и газе. Мы также предоставляем высококачественное сервисное обслуживание, помогая с установкой, наладкой и технической поддержкой. Благодаря нашему международному опыту и поставкам оборудования в разные страны, мы можем помочь вам решить любые задачи, связанные с вашим бизнесом. Мы всегда следим за новыми технологиями и инновациями в отрасли, чтобы предложить вам самые эффективные решения для увеличения производительности и снижения затрат. Выбирая Turan, вы выбираете надежного партнера, который поможет вам успешно развивать свой бизнес в области энергетики, нефти и газа. Мы гарантируем качество, надежность и профессионализм. Не упустите возможность сделать ваше предприятие более эффективным и конкурентоспособным с Turan!
1xBet betting company continues to remain in the trend one x bet promo code despite the growing competition in the interactive.
order loratadine 10mg sale order priligy 60mg pills dapoxetine 30mg sale
Meds information. Short-Term Effects.
lisinopril
All information about drug. Get now.
advair comparison
The main task of such publications is to motivate 1xbet latest promo code users to register in the office as soon as possible.
Meds information sheet. Drug Class.
paxil
Everything information about pills. Get information here.
A private dance of this kind has long since become an חשפנית בנתניה indispensable feature of any good party.
azithromycin no rx
https://canvas.ubc.ca/eportfolios/48572/Home/YouTube_Growth_Made_Easy_Exploring_the_Benefits_of_YouTubeBoosterSpace
buying cheap cialis soft tabs online
Pills information sheet. What side effects can this medication cause?
seroquel medication
Everything what you want to know about pills. Read now.
Восстановительная маска для волос
ventolin nebules
справка https://spravki-s-dostavkoy.ru/
Чтобы правильно произвести раздел имущества необходимо обратиться в компанию Зайцев и партнеры раздел имущества супруги оказывает профессиональные юридические услуги для людей и организаций.
На официальном сайте интернет-магазина представлен широкий ассортимент алкогольной продукции доставка алкоголя на дом москва принимаем запросы вне зависимости времени.
topical finasteride
buy lisinopril 20 mg without a prescription
You can order a stripper to your home, to the hotel or to any other location you choose throughout the country חשפניות נתניה in the north, south, center.
Drug information. Brand names.
prozac order
All information about medicine. Read information here.
The beauty and grace of the female body have been appreciated since ancient times חשפניות ראשון לציון smooth dance movements.
[url=http://clomid.wtf/]clomid for sale in south africa[/url]
Быстро возводимые здания: коммерческий результат в каждой детали!
В нынешней эпохе, где секунды – доллары, сооружения с быстрым монтажем стали решением, спасающим для компаний. Эти новейшие строения комбинируют в себе твердость, финансовую эффективность и ускоренную установку, что обуславливает их превосходным выбором для различных коммерческих проектов.
[url=https://bystrovozvodimye-zdanija-moskva.ru/]Стоимость постройки быстровозводимого здания[/url]
1. Ускоренная установка: Минуты – важнейший фактор в коммерции, и сооружения моментального монтажа дают возможность значительно сократить время строительства. Это особенно ценно в вариантах, когда требуется быстрый старт бизнеса и начать монетизацию.
2. Бюджетность: За счет улучшения процессов изготовления элементов и сборки на объекте, цена скоростроительных зданий часто оказывается ниже, по сопоставлению с традиционными строительными задачами. Это позволяет сэкономить средства и добиться более высокой доходности инвестиций.
Подробнее на [url=https://xn--73-6kchjy.xn--p1ai/]http://scholding.ru[/url]
В заключение, скоростроительные сооружения – это великолепное решение для бизнес-мероприятий. Они объединяют в себе скорость строительства, экономию средств и повышенную надежность, что позволяет им оптимальным решением для фирм, активно нацеленных на скорый старт бизнеса и получать деньги. Не упустите шанс экономии времени и денег, идеальные сооружения быстрого монтажа для вашего следующего делового мероприятия!
You can order in the area: strippers in Bat Yam חשפניות נתניה Unbeatable prices!
buy lisinopril online uk
Быстромонтажные здания: финансовая выгода в каждом элементе!
В нынешней эпохе, где время – деньги, сооружения с быстрым монтажем стали реальным спасением для коммерческой деятельности. Эти новейшие строения объединяют в себе повышенную прочность, эффективное расходование средств и скорость монтажа, что обуславливает их оптимальным решением для разнообразных предпринимательских инициатив.
[url=https://bystrovozvodimye-zdanija-moskva.ru/]Быстровозводимые здания[/url]
1. Высокая скорость возвода: Часы – ключевой момент в предпринимательстве, и скоростроительные конструкции обеспечивают значительное снижение времени строительства. Это особенно выгодно в случаях, когда срочно нужно начать бизнес и начать прибыльное ведение бизнеса.
2. Бюджетность: За счет совершенствования производственных операций по изготовлению элементов и монтажу на площадке, экономические затраты на моментальные строения часто остается меньше, по сравнению с обычными строительными задачами. Это позволяет сократить затраты и обеспечить более высокий доход с инвестиций.
Подробнее на [url=https://xn--73-6kchjy.xn--p1ai/]http://www.scholding.ru/[/url]
В заключение, быстровозводимые здания – это превосходное решение для предпринимательских задач. Они обладают быстрое строительство, экономическую эффективность и долговечность, что сделало их превосходным выбором для деловых лиц, имеющих целью быстрый бизнес-старт и обеспечивать доход. Не упустите возможность сократить затраты и время, оптимальные моментальные сооружения для вашего следующего начинания!
buy cheap generic glimepiride order cytotec 200mcg without prescription order etoricoxib 60mg without prescription
Drug information leaflet. Cautions.
cephalexin buy
Best about pills. Get information here.
buying lisinopril without rx
pharmacy canadian superstore
Meds information. Generic Name.
female viagra
Some what you want to know about drugs. Get information here.
can i buy lisinopril over the counter in the us
On our website you can book Rishon Lezion strippers for a bachelor party חשפניות ראשון לציון and in all places in the country.
We offer a warm, interesting and very spicy service in Rishon LeZion: חשפנית בראשון לציון booking strippers Inviting our artists girls will paint every party in new color.
Pills information sheet. What side effects?
can i get lisinopril
Some news about drug. Get information here.
order lioresal sale ketorolac pills toradol cheap
how to get ozobax without a prescription lioresal drug how to buy ketorolac
You won’t get bored of them, and the intensity of the חשפניות ראשון לציון celebration will soar very high!
https://dez-serv.ru/
lisinopril 5 mg buy meijer pharmacy
Force steam, penetrating the layers of paper, חשפניות ראשון לציון removing the covering and residue.
https://dez-serv.ru/
Medicine information. What side effects?
fluoxetine
All about pills. Get information now.
Основным направлением работы отделения является восстановительно-реконструктивно-пластические операции в области головы – шеи http://neuro-med.ru/partners.htm
https://www.party.biz/forums/topic/714684/calgary-s-fine-line-tattoo-scene-a-rising-trend-in-body-art/view/post_id/1584300
were to buy lisinopril over the counter
The panorama of fine line tattoos unfurls a captivating symphony of stylistic possibilities https://minecraftcommand.science/forum/general/topics/choosing-the-perfect-design-for-your-fine-line-tattoo-in-calgary One must embark upon a voyage.
Fine line geometric tattoos represent a profound departure https://moneyfx.boardhost.com/viewtopic.php?pid=17377#p17377 from the conventional and frequently audacious realm of tattoo aesthetics.
справка о побоях https://spravki-o-poboyah.ru/
This resplendent style has surged into prominence on the back of its beguiling, almost ethereal https://myworldgo.com/forums/topic/105631/fine-line-tattoos-vs-traditional-tattoos-pros-and-cons/view/post_id/1161877#siteforum_post_1161877
Meds prescribing information. Drug Class.
lyrica
All trends of drug. Read information now.
Мосоптторг – зарекомендованная, востребованная, результативная компания, осуществляющая высококачественное обслуживание http://snabzhenie-obektov.ru/ для обеспечения материалами, применяемыми в строительстве.
Кто-нибудь может подсказать – как можно получить консультацию лазерного хирурга бесплатно предменструальное дисфорическое расстройство стоит вопрос о лазерной коагуляции сетчатки.
An erotic dance is a dance that provides erotic entertainment and whose objective is the stimulation חשפניות ראשון לציון of erotic or sexual thoughts or actions in viewers.
buy generic lisinopril online no rx
gabapentin withdrawal symptoms
Meds information sheet. What side effects can this medication cause?
lioresal
Some about medication. Get information now.
cleocin prescribing information
can you buy lisinopril online without a prescription
Pills information leaflet. Generic Name.
fosamax generic
Actual information about drugs. Get now.
Hello friends if you are hosting a bachelor party in the north חשפניות בצפון and it is important to you that the party will go well.
cost of generic plavix pills
can you buy metformin online
A hot strip show for a bachelor party חשפנית בצפון what bachelor party before the wedding.
buspar cost australia
Уничтожение насекомых, дезинфекция, дератизация с гарантией в вашем городе Служба дезинфекции в Самаре: Уничтожение насекомых и грызунов
can i buy lisinopril over the counter in canada
Основными направлениями экспорта ViOil являются страны СНГ віктор пономарчук vioil Ближнего Востока, Юго-Восточной Азии, Северной и Восточной Африки, Европы.
Medicine information for patients. Cautions.
buy effexor
Actual what you want to know about drug. Read information here.
cordarone buy online singapore
can i buy generic lisinopril online
Last years results confirmed that the industrial group ViOil віктор пономарчук vioil remains the leader in rapeseed oil production.
can i get generic aurogra
According to a message on the companys website, the groups oil extraction plants processed віктор пономарчук about 76 thousand tons of rapeseed.
1xbet free promo codes
At the beginning of August, a charity football tournament among youth віктор пономарчук teams of the region was held in Vinnitsa.
Medicament information sheet. Short-Term Effects.
sildenafil cost
Best what you want to know about medicines. Get now.
cialis soft tabs cost
lisinopril 5 mg buy
doxycycline buy online australia
cefixime toxicity
Drug information leaflet. Drug Class.
xenical
Actual about medicine. Get information here.
albuterol sulfate inhalation solution
buy lisinopril 20 mg online
Tattoos, those inked tapestries of human expression, have traversed the epochs, http://forums.delphiforums.com/vpshostinguae/messages/5275/1 bearing witness to tales of personal narratives, artistic prowess.
Подробнее об организации: Российский государственный открытый технический университет путей сообщения (РГОТУПС) на сайте Смоленск в сети
The Transformation of Fine Line Tattoos in Calgary: http://www.razyboard.com/system/morethread-exploring-the-history-and-evolution-of-fine-line-tattoos-in-calgary-pete_bernert-41716-6437290-0.html tattoos, once relegated to society’s margins, now stand as potent symbols of self-expression and artistry.
The Cultural Resonance of Fine Line Tattoos: https://rdd.media/fine-line-flower-tattoo-exquisite-floral-artistry-by-masterful-tattoo-artists/ beyond their aesthetic splendor, fine line tattoos in Calgary
Pills information leaflet. Effects of Drug Abuse.
sildigra brand name
Some news about pills. Get information here.
Простыми словами о том, что нужно знать прежде, чем заказать дизайн упаковки дизайн упаковки чая
However, the bright celebration did not end with the last minutes of the final match віктор пономарчук and the awarding of the young athletes.
На сайте Центра ментального здоровья и психологического развития Эмпатия вы сможете узнать симптомы депрессии, депрессия получить консультацию и квалифицированное лечение.
effexor generic name
buying lisinopril without rx
Поиск авиабилетов для путешествий в любую точку мира на агрегаторе Скайсканер сайт
fluoxetine weight gain
cheap albuterol
Ми, виробництво Віанд, використовуємо високоміцну тканину, яка не розтягується Військове ліжко купити ссылка. і має першокласні характеристики міцності.
Pills information. Effects of Drug Abuse.
cialis
Some news about medicines. Get here.
advair disc
Female nudity is not just spectacular stripping חשפנית בצפון it is the fire of emotions, the release of the soul, the art of dance.
lisinopril buy from india
robaxin 750 mg price
When ordering strippers from our company, it is guaranteed that you will receive not only חשפניות בצפון the most beautiful girls in Israel, but also the most professional service.
Жирные кислоты соапстоков светлых растительных масел и саломасов для кормовых віктор пономарчук основными направлениями экспорта ViOil являются страны СНГ, Ближнего Востока.
Drug information. Drug Class.
norpace
Everything what you want to know about drug. Read here.
alendronate uk order fosamax 35mg generic nitrofurantoin 100mg price
order generic alendronate 70mg furadantin over the counter order nitrofurantoin 100 mg online cheap
снять квартиру
buy lisinopril online uk
prednisone tablets canada
заказать шины https://magazin-avtomobilnih-shin.ru/
colchicine ingredients
propranolol 10mg tablet
Drug information sheet. Generic Name.
provigil
Actual news about drug. Get information here.
Прогон сайта с использованием программы “Хрумер” – это способ автоматизированного продвижения ресурса в поисковых системах. Этот софт позволяет оптимизировать сайт с точки зрения SEO, повышая его видимость и рейтинг в выдаче поисковых систем.
Хрумер способен выполнять множество задач, таких как автоматическое размещение комментариев, создание форумных постов, а также генерацию большого количества обратных ссылок. Эти методы могут привести к быстрому увеличению посещаемости сайта, однако их надо использовать осторожно, так как неправильное применение может привести к санкциям со стороны поисковых систем.
[url=https://kwork.ru/links/29580348/ssylochniy-progon-khrummer-xrumer-do-60-k-ssylok]Прогон сайта[/url] “Хрумером” требует навыков и знаний в области SEO. Важно помнить, что качество контента и органичность ссылок играют важную роль в ранжировании. Применение Хрумера должно быть частью комплексной стратегии продвижения, а не единственным методом.
Важно также следить за изменениями в алгоритмах поисковых систем, чтобы адаптировать свою стратегию к новым требованиям. В итоге, прогон сайта “Хрумером” может быть полезным инструментом для SEO, но его использование должно быть осмотрительным и в соответствии с лучшими практиками.
https://usa-farmer.com/
where to get levaquin prices
where to buy lisinopril hydrochlorothiazide
Lucky Jet, un popular juego de choque, llama la atencion no solo por sus Lucky Jets sencillas reglas, sino tambien por su impresionante diseno visual.
what is cefixime 200 mg used for
Pills information. What side effects can this medication cause?
silagra buy
Some information about drug. Read information now.
Language development is a fundamental aspect of a childs growth, playing a pivotal role in their ability to communicate, ребенок не гулит express emotions, and connect with the world around them.
It offers vegetable meals, fats and oils, pellets, tropical oils, grains, oilseeds, phosphatide concentrates, віктор пономарчук fatty acids, sunflower oil, and more.
на сутки квартиры
buy lisinopril 20mg no prescription
The group was the first in the country to produce rapeseed oil віктор пономарчук vioil the company exported almost all its products.
Meds information for patients. Generic Name.
synthroid
Best news about pills. Get information here.
промокод 1xbet на сегодня
can you buy lisinopril
This allows you to load the capacity evenly throughout the year віктор пономарчук all oil extraction plants of the ViOil group are multicultural.
Drugs information leaflet. What side effects?
pregabalin
All what you want to know about meds. Read information now.
The global marketing company Infinity Business Insights ViOil presented an overview and forecast віктор пономарчук of the development of the sunflower meal market for 2022?2028.
снять квартиру
aviator скачать игру
happy family drugstore
albuterol 0.83 mg
комплексные поставки на строительные объекты http://media-dream.ru/
промокод для 1 икс бет
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Образование дорого стоит, и я решил взять займ для учебы. С помощью подборки проверенных МФО 2023 года на zaim52.ru, я нашел подходящий вариант займы онлайн на карту и достиг своих учебных целей.
цена квартиры на кипре https://kvartiry-na-kipre.com/
промокод 1xbet при регистрации
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
1xbet промокод при регистрации на сегодня 2024
I value their commitment to customer health. https://mexicanpharmonline.shop/# mexico pharmacies prescription drugs
mexican rx online [url=http://mexicanpharmonline.com/#]buying prescription drugs in mexico[/url] mexico drug stores pharmacies
Как начать играть в онлайн казино, секреты, советы, рейтинг Рейтинг казино Как не проиграть все? Как выиграть? Брать бонус на депозит?
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
buy tamoxifen paypal
Прогон сайта с использованием программы “Хрумер” – это способ автоматизированного продвижения ресурса в поисковых системах. Этот софт позволяет оптимизировать сайт с точки зрения SEO, повышая его видимость и рейтинг в выдаче поисковых систем.
Хрумер способен выполнять множество задач, таких как автоматическое размещение комментариев, создание форумных постов, а также генерацию большого количества обратных ссылок. Эти методы могут привести к быстрому увеличению посещаемости сайта, однако их надо использовать осторожно, так как неправильное применение может привести к санкциям со стороны поисковых систем.
Прогон сайта “Хрумером” требует навыков и знаний в области SEO. Важно помнить, что качество контента и органичность ссылок играют важную роль в ранжировании. Применение Хрумера должно быть частью комплексной стратегии продвижения, а не единственным методом.
Важно также следить за изменениями в алгоритмах поисковых систем, чтобы адаптировать свою стратегию к новым требованиям. В итоге, прогон сайта “Хрумером” может быть полезным инструментом для SEO, но его использование должно быть осмотрительным и в соответствии с лучшими практиками.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Время от времени каждому из нас нужны дополнительные средства для реализации мечт. Займ на сайте zaim52.ru стал моим спутником в финансовых приключениях. С помощью подборки новых МФО 2023 года, я нашел подходящее решение займы онлайн на карту и воплотил свои планы в жизнь.
A no deposit bonus at F1 Casino can be cashed out if you wager admiral x casino no deposit bonus the bonus (x50) within 3 days.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
1xBet – это благоприятные условия при регистрации и выборе ставок промокод для 1 икс бет ринимая участие во всех выгодных предложениях, новички и постоянные игроки получают прекрасную возможность увеличить свой бонусный счёт.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Служба дезинфекции – уничтожение насекомых и грызунов в вашем городе c гарантией Обработка от клопов уничтожение насекомых, дезинфекция, дератизация с гарантией.
Игорный клуб Eldorado Casino начал свою работу в 2017 году eldorado casino на первый депозит от 200р – 200 фриспинов.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
промокод dava 1xbet
трековые светильники купить https://novosvetum.ru/
Вызов врачей и узких специалистов на дом клиника оказывает широкий спектр услуг синдром дефицита внимания Уколы и капельницы.
рынок инфлюенсеров
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
матрас ортопедический 160х200 https://ortopedicheskie-matrasi.ru/
Компания 1xBet не оставила без внимания своих клиентов, которые предпочитают использовать мобильную версию 1xbet бесплатная ставка промокод В букмекерской компании 1xBet существует несколько способов ввода и вывода средств.
Medication information sheet. What side effects can this medication cause?
priligy
All about pills. Get information now.
inderal online buy inderal cost clopidogrel 75mg usa
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
buy augmentin 875 mg online
lisinopril 5 mg buy meijer pharmacy
Знакомьтесь с прекрасным примером эволюции классической чат-рулетки чат рулетка видео улучшенный гендерный фильтр, круглосуточная модерация.
Adoro a expectativa de esperar a bola cair no meu numero na roleta https://www.roletacasino.online/ a Roleta e um jogo facil de aprender, mas dificil de dominar.
ventolin tablets australia
купить зимние шины в москве https://zimnie-shini-avto.ru/
onlyfans webcam models
https://pedagog-razvitie.ru/course.html
watch webcam girls free
В школе Центра иностранных языков YES вы сможете с легкостью онлайн курс английского языка и интересом освоить английский язык.
The Bible is a remarkable journey through time, culture, and faith – Newark Pulse Day: 4th Anniversary a narrative that spans from the creation of the world to the visions of the future.
where to get acyclovir
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Pills information. Long-Term Effects.
singulair generics
All what you want to know about drugs. Read information now.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
buy lisinopril 40 mg tablet
buy lisinopril 20mg no prescription
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Medication prescribing information. Short-Term Effects.
tadacip
All news about medication. Get information here.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Medication prescribing information. Generic Name.
viagra without a prescription
Some trends of meds. Get here.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
buy lisinopril without prescription
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
buy generic lisinopril online
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Наши преподаватели, среди которых есть и носители языка, всегда готовы помочь Вам приобрести необходимые знания, бизнес курс английского языка чтобы в дальнейшем их можно было уверенно использовать в повседневной жизни.
шторы электрические https://prokarniz15.ru/
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Inside the ever-evolving world of on the web sports betting and gaming https://trentonvpiz09877.blogdon.net/pin-up-casino-brasil-o-destino-definitivo-para-divers-o-e-apostas-online-37991569 stands out being a top-tier platform that caters to your diverse preferences.
cheep levitra for sale
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
https://sen-tan.com/ Сенімді Та?дау, ?аза?стан энергетика секторында т?тынушыларды озы? инженерлік шешімдер ар?ылы ?амтамасыз ету ж?не жабды?ты ?здіксіздікке жеткізу ?шін компанияны беделдікке ие болды.
https://sen-tan.com/ Сенімді Та?дау компаниясы, ?аза?стан энергетика секторында т?тынушыларды озы? инженерлік шешімдер ар?ылы ?амтамасыз ету ж?не жабды?ты ?здіксіздікке жеткізу ?шін компанияны беделді т?л?а іске асырды.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
летние шины r14 https://letnie-shini-avto.ru/
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Аутизм – описание заболевания, классификации, симптомы у взрослых и детей, причины появления заболевания, лечение аутизма методы диагностики и способы лечение недуга.
oral glimepiride 4mg glimepiride 4mg price arcoxia 60mg brand
недорогие квартиры на сутки
квартира на сутки Минск
best generic provigil
дайсон стайлер цена https://dyson-stylery.com/
https://sireng.net/
https://sireng.net/
nortriptyline 25mg without prescription anacin 500 mg pills acetaminophen usa
how to buy nortriptyline where to buy paracetamol without a prescription cost acetaminophen
phenergan gel cost
квартира посуточно недорого
квартира посуточно недорого
Забудьте о процентах при взятии займа! Мы представляем МФО, где вы можете получить займ онлайн без процентов. Это надежные финансовые организации, готовые помочь вам без дополнительных выплат. Подробнее в нашем канале: онлайн займы срочно
http://stromectol24.pro/# minocycline 100 mg without a doctor
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
рейтинг клининговых компаний https://cleaning-rating-2023.ru/
Zip пакеты
Профессиональный ремонт телефонов в г Жуковский с гарантией ремонт телефонов жуковский Вы все еще думаете, что ремонт компьютерной техники стоит дорого?
orlistat 60mg generic purchase xenical without prescription diltiazem 180mg us
зип пакеты купить в Москве
[url=http://happyfamilystorepharmacy.net/]best value pharmacy[/url]
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Here you can find almost any sport for betting https://1x-bet.fun You can find good odds here.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
azithromycin 10 mg
купить Zip пакеты с логотипом
Получите консультацию с нашим юристом и узнайте ответы на свои вопросы апелляционная жалоба юридические услуги — важная квалифицированная профессиональная помощь.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
зип пакет
feldene 20 mg capsules
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Virtual Numbers Ваш надежный партнер в мире виртуальных номеров https://www.google.ws/url?q=https://didvirtualnumbers.com/ Наша IP телефония позволит вам принимать звонки, смс и зарегистрироваться в сервисах без ограничений.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
pharmacy in canada for viagra
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
http://comved.ru
http://vitek-logistic.ru
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Это лучшее онлайн-казино, где вы можете насладиться широким выбором игр https://tinyurl.com/yo8l3m58 и получить максимум удовольствия от игрового процесса.
online webcam girls
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
webcam drag queens
Онлайн казино отличный способ провести время, главное помните, что это развлечение, https://tinyurl.com/ynzpxgtc а не способ заработка.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
http://canadapharmacy24.pro/# canadapharmacyonline com
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
provigil in mexico
вывод из запоя в Москве https://vivodizzapoya-msk.ru/
плазмотерапия Мытищи
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
секретные купоны бургер кинг
https://vk.com/kupon_burgerkings
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
механизм для штор электрический https://prokarniz17.ru/
Наша работа – это поставки качественной тайской экипировки Twins Special и Fairtex, https://twins-fairtex.ru/ в максимально короткие сроки и по самым низким ценам.
ciprofloxacin discount
доставка цветов новосибирск
pharmacy no prescription required
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
I got what you mean , thankyou for posting.Woh I am delighted to find this website through google. “Success is dependent on effort.” by Sophocles.
https://hotelescampanario.com/choisis-tous-les-types-de-paris-sportifs-sur-xbet/ – hotelescampanario.com
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Greetings! Very useful advice within this post! It is the little changes that produce the most significant changes. Thanks for sharing!
[url=https://xl-energy.com/azerbaycanda-pin-up-haqqinda-orimati-melumat-nece/]xl-energy.com[/url]
доставка цветов новосибирск
glucophage 850mg tablet
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Drugs information leaflet. Effects of Drug Abuse.
seroquel
Some information about medication. Get now.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
cipro discount coupon
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Drug information sheet. Short-Term Effects.
tadacip generics
All information about medication. Get information now.
I got what you mean , thankyou for posting.Woh I am delighted to find this website through google. “Success is dependent on effort.” by Sophocles.
activelk.com
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
colchicine cost canada
how much is avodart
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
pokerdom
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
http://stromectol24.pro/# ivermectin cost in usa
zithromax purchase online
pokerdom казино
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
pokerdom казино
пройти обучение наращивание ресниц https://kursy-po-narashchivaniyu-resnic1.ru/
покердом официальный
buy clomid for cheap
diflucan 150 tablet
рабочее зеркало покердом
На официальном сайте интернет-магазина представлен широкий ассортимент алкогольной продукции доставка алкоголя на дом круглосуточно москва недорого которая разделена на категории и подкатегории товаров.
Muitos gostam de fazer apostas para ganhar dinheiro no cassino https://www.portaldecamaqua.com.br/noticias/69138/gire-a-roda-da-fortuna.html mas acabei me empolgando com o ganho inicial e entrando em tilt na roleta.
покердом официальный сайт играть
оборудование для переговорных комнат купить https://i-tec5.ru/
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
buy orlistat 120mg sale orlistat 60mg pill diltiazem usa
http://canadapharmacy24.pro/# canadian family pharmacy
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
покер дом войти
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
order coumadin 5mg online purchase paxil generic metoclopramide us
where to buy medex without a prescription buy paroxetine 20mg online metoclopramide 10mg drug
покердом зеркало вход
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
покер дом скачать
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
покердом играть онлайн на деньги
http://stromectol24.pro/# ivermectin buy
нужна справка 2ндфл https://2ndfl-spravka.ru/
where can i buy azithromycin online
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
https://indiapharmacy24.pro/# best online pharmacy india
покердом зеркало сегодня
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
buy levitra no prescription
zithromax 4 pills
покердом зеркало на сегодня
modafinil online canada
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
lasix 40mg to buy
https://canadapharmacy24.pro/# canada pharmacy online legit
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Зимние дни становятся теплее с UGG. Приглашаем вас на нашу распродажу, где вы сможете купить UGG 2023 года и насладиться максимальным комфортом.
Сайт: uggaustralia-msk.ru
Адрес: Москва, 117449, улица Винокурова, 4к1
Если вы ищете теплые и стильные ботинки на зиму, не ищите дальше! У нас вы можете купить оригинальные Угги по выгодным ценам. Посетите наш интернет-магазин и подарите себе уют и комфорт в холодное время года.
Сайт: uggaustralia-msk.ru
Адрес: Москва, 117449, улица Винокурова, 4к1
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Забудьте о холодных ногах и неудобной обуви! Купить Угги – это правильный шаг к комфорту и стилю. Наш интернет-магазин предлагает широкий выбор оригинальных Угги. Не упустите возможность оформить заказ прямо сейчас!
Сайт: uggaustralia-msk.ru
Адрес: Москва, 117449, улица Винокурова, 4к1
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
щитовой дом под ключ дешево https://shchitovyedomapro.ru/
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
buy azelastine sprayer buy azelastine 10 ml irbesartan online
Axxinot – торговая марка трубчатых радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Do you need a quick cash advance? Great, You have come to the correct address payday loans Our site will help you find the right lender in your city.
Pills prescribing information. Short-Term Effects.
levitra
All what you want to know about medicines. Get information here.
ап х
казино онлайн на реальные деньги
снять квартиру
вход покердом
cefixime 100 mg
UGG – это знак качества и стиля. Посетите наш магазин и купите UGG 2023 года по самым привлекательным ценам.
Сайт: uggaustralia-msk.ru
Адрес: Москва, 117449, улица Винокурова, 4к1
Мы предлагаем множество парных браслетов, которые непременно вас заинтересуют парные браслеты качественно, быстро, недорого.
казино онлайн
how to buy generic elimite without rx
играть в казино
buy prograf
https://www.teleprogramma-peredach-segodnya.ru/
покер зеркало
pioglitazone 30
казино играть
значимые события в жизни портала
ciprofloxacin cost uk
На цену прежде всего влияет функционал, дизайн и количество создаваемых страниц создание сайта цена ростов отрисовка современного дизайна с учетом ваших пожеланий.
retinol a 0.025
лучшее казино онлайн
finasteride warnings
buy metformin 500mg
ashwagandha dosage
Переезд в новую квартиру вынудил меня искать дополнительные средства. Портал cntbank.ru с его многочисленными предложениями по займам и акцией “займ без процентов” был как нельзя кстати.
асфальтирование https://asfaltirovanye-dorog.ru/
http://paxlovid.bid/# paxlovid pill
zithromax otc
http://paxlovid.bid/# paxlovid pill
https://stromectol.icu/# ivermectin 1% cream generic
https://mobic.icu/# how to buy generic mobic without dr prescription
where to buy abilify price
https://plavix.guru/# Plavix generic price
http://paxlovid.bid/# paxlovid pharmacy
https://mobic.icu/# where to buy mobic without dr prescription
clonidine tablet 0.2mg
co-amoxiclav cost australia
melbet promo code melbet 2024
https://mobic.icu/# how to buy cheap mobic tablets
Промокоды для ставок на хоккей
Продажа бассейнов для загородных участков, оборудования и химии для бассейнов, павильонов и аксессуаров для отдыха где можно купить бассейн плавание – уникальный вид физической нагрузки и упражнений (спорта, в глобальном понимании).
Встретив уникальное предложение по обучению, мне срочно понадобились деньги. cntbank.ru с его огромным выбором компаний по срочным займам стал для меня спасением. Займ без процентов сделал эту сделку еще привлекательнее.
buy retin a 05 online
promo code for registration melbet
Добро пожаловать в нашу клинику ортопедии, где мы предлагаем высококачественные услуги в области диагностики, лечения лазеротерапия и реабилитации заболеваний опорно-двигательной системы.
Мой старый телефон вышел из строя прямо перед важным звонком. Благодаря займу с cntbank.ru, я смог купить новый телефон и успешно провести важное обсуждение с клиентом.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
prazosin hcl 5mg
generic stromectol: ivermectin buy uk – stromectol brand
После сильного ливня в моем доме прорвало крышу. Мне срочно понадобились деньги на ремонт. На cntbank.ru я нашел подходящее МФО, получил займ и мастера быстро устранили протечку.
Для начала планирую просто проконсультировался и ищу хороших юристов http://mibee.ru/viewtopic.php?f=35&t=10152 Уверен, что не разочаруетесь проделанной работой и вам точно тут смогут помочь.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
имплантация зубов в стоматологии https://ortodontiyavmoskve.ru/
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
acyclovir buy online canada
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Drug information sheet. Short-Term Effects.
viagra otc
All what you want to know about pills. Get information here.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Pills information. Generic Name.
neurontin pill
Actual news about medicines. Read information now.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Доедешь болезни рук диагноз конечной остановки, магнитофонных записей Запись к врачу Так, взятый из лаборатории систем безопасности, глаза его горели.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
dragon money отзывы
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Компания HONO-R специализируется на производстве различных типов радиаторов охлаждения, https://msk.hono-r.com/product/dizel-elektrostantsii-dgu/ которые применяются в спецтехнике и в промышленных установках.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
where can i buy plavix without dr prescription
Институт психологии и астрологии обучает и выпускает грамотных, профессиональных специалистов https://astroinstitut.ru/obuchenie/ система обучения основана на фундаментальных астрологических принципах.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
buy generic famotidine for sale buy prograf 1mg pills order tacrolimus online cheap
famotidine brand order famotidine 20mg generic order prograf 5mg without prescription
Музыкальная школа в центре Уфы для взрослых. У нас не типичные скучные уроки, https://mmotionschool.ru/shkola-fortepiano вы сможете погрузиться в захватывающий процесс обучения с лучшими преподавателями!
valtrex order uk: where can i buy valtrex online – buy valtrex without get a prescription online
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
cipro over the counter mexico
Instantly access a global network, establish local presence, and stay available on the go. https://www.google.cz/url?q=https://didvirtualnumbers.com/virtual-number-for-telegram/ Streamline customer interactions, boost credibility, and expand reach.
программа 365 дней на сегодня и завтра
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
what is finasteride
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Промокоды для ставок на баскетбол
Cntbank.ru обеспечивает прозрачные условия для онлайн займа на карту без скрытых платежей и ограничений. Решение финансовых вопросов теперь не займет много времени и сил. Просто выберите нужную сумму и срок, и деньги будут у вас на карте.
Medicament information sheet. Cautions.
lasix cheap
Actual about pills. Get information now.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
propecia generic
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Meds information for patients. Long-Term Effects.
zenegra medication
All about medicines. Get now.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Medicine information for patients. Long-Term Effects.
zovirax pill
Actual information about medicament. Read information now.
Компания “ПОРАДОМ” активно работает в сфере строительства и ремонта с 2012 года https://poradom-remont.ru/remont-kvartir Мы предоставляем профессиональные услуги по ремонту и дизайну жилых и нежилых помещений.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
order astelin sale buy irbesartan pill order avapro pills
Игорный портал азартных игр Cat Casino функционирует с 2021 года cat casino За прошедший период работы зарекомендовал себя исключительно с положительных сторон.
В один прекрасный день я решила сделать сюрприз своему мужу на годовщину свадьбы и заказать роскошный ужин в ресторане. Однако на счету было не достаточно средств, и я обратилась на cntbank.ru. Мне быстро одобрили срочный займ на карту на сумму 10 000 рублей, и вечер прошел просто волшебно.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
prazosin 2 mg tablets
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
claritin vs zyrtec
tadacip 20 mg canada
Присоединяйтесь к тысячам довольных клиентов cntbank.ru и оцените удобство и простоту получения онлайн займа на карту. Ваше финансовое будущее начинается здесь и сейчас!
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Pills prescribing information. Generic Name.
singulair
Actual about medicine. Read information now.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
where to buy mobic without rx: buy anti-inflammatory drug – buying mobic no prescription
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Meds information. Cautions.
generic effexor
Actual about drug. Read now.
Оформление сертификата ИСО 9001 с нами – это не только возможность подтвердить соответствие вашего бизнеса международным стандартам, но сертификация ISO 9001 и шанс оптимизировать внутренние процессы, повысить уровень управления и улучшить качество услуг.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
12.5 mg phenergan
играть онлайн Gama Casino
Medication information for patients. Brand names.
fluoxetine
Actual news about meds. Get information here.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
It is useful that the site has a section with forecasts from professionals. You can get a lot of interesting ideas for betting!https://s.surveyplanet.com/l98irjpw
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
where to buy doxycycline over the counter
Cntbank.ru предлагает онлайн займ на карту без скрытых комиссий и проверок. Получите деньги в течение 15 минут!
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
cheapest cialis Cialis over the counter Buy Tadalafil 10mg
doxycycline hyclate dr 150 mg
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Are you tired of endless diets and exhausting workouts that don’t give you the results you want fastest way to lose belly fat Introducing our revolutionary belly fat loss pills that will help you achieve your desired body shape in no time.
https://kamagra.icu/# buy kamagra online usa
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
I believe that this site is the premier bookmaker for sports betting
https://free-4107848.webador.com/
Medicament information sheet. Drug Class.
cialis medication
All about medicines. Read information here.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Medicament prescribing information. What side effects?
generic prozac
Best what you want to know about drug. Read information now.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Узнайте, как производится Установка и ремонт сантехники своими руками горячие полотенцесушители подробные инсрукции по установке ванны, унитаза, смесителей.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Drugs prescribing information. Effects of Drug Abuse.
rx nolvadex
Some what you want to know about drugs. Read information here.
valtrex generic no prescription
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
https://viagra.eus/# Viagra online price
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
экспертиза проекта https://pgs111.ru/
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
doxycycline pil 100mg
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Medication information leaflet. Brand names.
female viagra price
All news about medicines. Read here.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Официальный сайт Gama Casino – удобный веб-портал, который предоставляет возможность играть, играть онлайн Gama Casino не беспокоясь о конфиденциальности личной информации и денежных средств на счету депозита.
buy Kamagra sildenafil oral jelly 100mg kamagra п»їkamagra
Перед началом работ мастера демонтируют мебель, снимая старое покрытие перетяжка мягкой мебели и проверяя состояние каркаса и наполнителя.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
cheap nexium 40mg purchase nexium for sale topamax 200mg pill
buy esomeprazole 20mg for sale order mirtazapine online cheap buy topiramate tablets
allopurinol pills purchase allopurinol pills buy crestor 20mg generic
Medicament information. What side effects can this medication cause?
maxalt without a prescription
Actual trends of medicine. Get now.
Om du letar efter en dejtingsajt i Sverige rekommenderas det att du uppmarksammar denna plattform.
Kom ihag att sakerhet alltid bor vara din prioritet nar du anvander dejtingsajter. Var noga med att kontrollera anvandarprofiler, var forsiktig nar du delar personlig information och traffa nya manniskor endast pa offentliga platser.
https://telegra.ph/Tr%C3%A4ffa-Singlar-N%C3%A4ra-Dig—Var-Inte-Blyg-Chatta-Fritt-04-03
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Meds information for patients. Long-Term Effects.
buy generic silagra
All trends of medicines. Read now.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
order clomid 100mg online
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Оказавшись в сложной жизненной ситуации, я понял, что срочно нужны деньги. Google предложил мне сайт cntbank на первых позициях поиска. Список всех займов, представленный на сайте, был как нельзя кстати. Я выбрал МФО, которое предлагало хорошие условия, и мгновенно получил деньги на карту.
Информация о сайте cntbank.ru
Адрес: 125362, Россия, Москва, Подмосковная ул. 12А.
Ссылка: список всех займов
zithromax 500mg online
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
В области сертификации и стандартизации ключевую роль играет отказное письмо по сертификации отказное письмо по сертификации это документ, который предприятие или организация получает в случае, если его продукция или услуги не подлежат обязательной сертификации по установленным стандартам и требованиям.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
augmentin 1g price in india
finasteride used for
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Medicine information. Brand names.
levaquin buy
Best about meds. Read now.
https://levitra.eus/# Levitra tablet price
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
The advantageous conditions for long-term tennis betting in this site are impressive
https://demo.sngine.com/blogs/391529/Your-guide-to-the-world-of-bonuses-for-players
Medicines information sheet. Long-Term Effects.
trazodone buy
All information about medication. Read now.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Закажите матрешку, посуду, шкатулку с вашей символикой, сюжетом или фото матрешки отбор изделий ведут специалисты с художественным образованием и длительным стажем работы в сегменте подарочной продукции.
Drug prescribing information. Long-Term Effects.
zovirax buy
Best information about meds. Read information here.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Дочь внезапно попросила новый велосипед. На форуме порекомендовали cntbank. Ознакомившись со списком всех займов, я нашёл идеальный вариант и сделал дочь счастливой.
Информация о сайте cntbank.ru
Адрес: 125362, Россия, Москва, Подмосковная ул. 12А.
Ссылка: список онлайн займов
Sildenafil 100mg price Viagra generic over the counter Cheap generic Viagra online
https://www.teleprogramma-segodnya.ru/
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Хайпово – информационно-развлекательный портал, на котором найдется абсолютно вся информация сайт про юмор комедии выходного дня и не только.
allopurinol 300mg over the counter purchase crestor generic rosuvastatin 10mg oral
buy silagra online
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
generic synthroid online
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Join millions of winners and unlock the door to endless fun and wealth https://ppmeonei.livejournal.com/8078.html by clicking on this magical link right now.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
buy doxycycline hyclate 100mg no prescription
электрический карниз купить в москве https://prokarniz20.ru/
Дочь внезапно попросила новый велосипед. На форуме порекомендовали cntbank. Ознакомившись со списком всех займов, я нашёл идеальный вариант и сделал дочь счастливой.
Информация о сайте cntbank.ru
Адрес: 125362, Россия, Москва, Подмосковная ул. 12А.
Ссылка: список займов на карту
purchase imitrex pill buy levaquin medication avodart medication
sumatriptan price generic sumatriptan 25mg avodart without prescription
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Unleash the thrill of gaming like never before at our cutting-edge online casino https://avilclub.ru/issledovanie-i-analiz-veb-sajta-shabalinskogo-rajona-kirovskoj-oblasti-resurs-dlya-informirovaniya-vzaimodejstviya-i-razvitiya Your path to riches and excitement begins with a single click on this extraordinary link!
Pills prescribing information. Cautions.
amoxil
All about medicines. Get information here.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
buspar cost buy amiodarone cost amiodarone 100mg
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Drugs information leaflet. What side effects?
effexor generic
Actual what you want to know about medicines. Get here.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Medication information leaflet. What side effects?
buy levitra
Some information about medicines. Read information now.
always i used to read smaller articles which as well clear their motive, and that is also
happening with this paragraph which I am reading at this place.
amoxicillin 875 mg pill
Experience the ultimate in online casino entertainment at your fingertips http://androidforall.ru/%d0%ba%d0%b0%d0%b7%d0%b8%d0%bd%d0%be-sykaaa/ get ready for a journey to unimaginable wealth and exhilaration – just one click away through this enchanted link.
over the counter sildenafil cheapest viagra order viagra
Значение и необходимость сертификации ИСО 9001 не поддаются сомнению Сертификат ИСО 9001 Получить сертификат ИСО 9001 необходимо, чтобы документально подтвердить тот факт, что предприятия соответствует установленным в стандарте требованиям.
Привет всем! Хочу поделиться с вами своей историей. У моей жены был юбилей, и я хотел сделать ей сюрприз. Планировал купить дорогой подарок и устроить романтический ужин. Но вот беда — денег не хватало. Начал искать варианты в интернете и наткнулся на сайт с мфо займы онлайн на карту.
Заполнил анкету, и буквально через 15 минут деньги были на карте. Сюрприз удался на славу, жена была в восторге! Спасибо этому сайту, рекомендую всем!
cheap generic prednisone
modafinil 600mg
I met my significant other in a chat on a dating site!
https://telegra.ph/T%C3%BCrkiyede-%C3%87evrimi%C3%A7i-Arkada%C5%9Fl%C4%B1k-Kapsaml%C4%B1-Bir-Rehber-10-30
baclofen over the counter usa
Medicine information. Generic Name.
cleocin
Some information about meds. Get information now.
Переезд — это всегда стресс и большие расходы. Когда я переезжал в новую квартиру, я столкнулся с необходимостью оплатить залог, коммунальные услуги и купить новую мебель. Денег, конечно же, не хватало.
И тут я нашел сайт, который предлагает займ на любую кредитную карту. Этот займ позволил мне сразу оплатить все неотложные расходы и с комфортом обустроить новое жилье. Процесс занял всего несколько минут: заполнить анкету на сайте, подтвердить личность и получить деньги на карту.
http://kamagra.icu/# cheap kamagra
Официальное онлайн Казино Рокс приглашает попробовать играть в автоматыТоп 10 казино Играть онлайн на официальном сайте бесплатно.
Meds information sheet. Effects of Drug Abuse.
where can i get colchicine
All what you want to know about drugs. Read here.
custom walk-in freezers https://ckitchen11.com/
Демонтаж металлоконструкций — это отдельная и довольно сложная задача. Она требует не только специализированной техники, но и квалифицированных рабочих. Особенно актуально это, когда речь идет о больших объемах. Стоимость услуги обычно рассчитывается за тонну, что позволяет оптимизировать бюджет. Если вас интересует этот вид работ, обязательно посетите сайт демонтаж металлоконструкций за тонну. Там вы найдете всю нужную информацию и сможете оценить стоимость предстоящих работ.
Meds information. What side effects can this medication cause?
rx amoxil
Actual what you want to know about pills. Read information now.
22 апреля чипмейкер Intel опубликует квартальную отчетность о рынке Forex выбрать брокера Компания выпустит финансовый отчет после завершения основной торговой сессии на американском рынке.
страховка онлайн осаго купить https://oformit-osago.ru/
аттестат за 9 http://attestat-9-klass.ru/
Cheap Viagra 100mg Viagra generic over the counter Viagra online price
buspirone cheap order zetia pills buy amiodarone sale
dipyridamole 75 mg tablet
buy prednisone online 10 mg
azithromycin tabs 250 mg
Наша статья рассказывает про лучшие обменники криптовалюты с минимальными комиссиями там Мы изучили все обменники по большому количеству параметров, таких как: скорость обмена, работа службы поддержки, платежные методы и тд.
Сантехработы, монтаж и замена сантехники, как сделать правильно полотенцесушитель лесенка незаменимые в любом доме элементы не так и просто поменять своими руками.
Medicament information for patients. Short-Term Effects.
abilify for sale
Best news about meds. Get information here.
amoxicillin 500 tablet
propecia for women
best prices for synthroid
Medication information. What side effects can this medication cause?
cialis cost
Everything trends of drug. Read here.
zantac 150mg price meloxicam where to buy celebrex 200mg canada
buy ranitidine pills buy generic zantac celebrex 200mg brand
Drugs information leaflet. Cautions.
rx zoloft
Everything what you want to know about pills. Get now.
how to get domperidone without a prescription buy tetracycline sale buy tetracycline online cheap
купить аттестат за 11 классов в москве http://attestat-11-klass.ru/
Демонтаж и снос частных домов с вывозом мусора в Москве и Московской области – http://msk-demontazh-doma-24.ru/. Слом дома вручную и спецтехникой производим по ценам ниже рынка за 1 день. Бесплатный выезд специалиста на объект.
https://kamagra.icu/# sildenafil oral jelly 100mg kamagra
С развитием технологий и интернет-сервисов, виртуальные номера стали весьма популярными среди пользователей мессенджеров и социальных сетей одноразовый номер для телеграм одним из самых популярных приложений для общения и обмена информацией является Телеграмм.
Накануне семейного праздника я осознала, что денег на подарки и угощения явно не хватит. В панике начала искать выход и наткнулась на займ на карту без процентов. Сайт оказался просто спасением! Благодаря нему смогла оформить займ без каких-либо процентов и подарить семье незабываемый праздник.
вызов электрика Запорожье
https://medium.com/@advencher1978/vps-server-ee111932b189
buy generic avodart online no rx
Drug information. What side effects can this medication cause?
zithromax
Actual about medicament. Get now.
lopressor
where to buy modafinil uk
We present to you a list of 1xbet promotional codes relevant for 2022: http://www.mathforum.ru/gitweb/pgs/1xbet_promokod_pri_registracii___aktualnuy_segodnya.html Without promotional codes, the bonus is 25,000.
Pills prescribing information. Drug Class.
fluoxetine without dr prescription
All about pills. Get information here.
На работе произошла непредвиденная ситуация, и мне срочно понадобились деньги для закупки оборудования. Банки отказывали или предлагали не выгодные условия. В этот момент я узнал про сайт быстрый займ на карту срочно. Здесь я получил необходимую сумму в кратчайшие сроки и смог решить все проблемы на работе. Сейчас всё стабильно, и я даже получил премию за решение сложной ситуации.
Medication information leaflet. Brand names.
lyrica without dr prescription
Everything trends of medicines. Read now.
anafranil 5mg
Levitra 10 mg buy online Levitra online pharmacy Levitra 20 mg for sale
Рейтинг молотого кофе. Что лучше — арабика, робуста или либерика Рецепты кофе топ-10 марок ароматного кофе с характеристиками вкуса и отзывами покупателей
https://kamagra.icu/# Kamagra 100mg price
купить диплом о среднем в москве https://diplomi-srednem.ru/
I’ve been a loyal this site bettor for years, and it’s my trusted platform
https://www.social-vape.com/read-blog/83185
Моя машина неожиданно сломалась прямо перед долгожданным отпуском. Срочно нужен был ремонт, но денег на это не было. Тут как раз нашел кредит онлайн без отказа. Процедура заняла минимум времени, и я смог отправиться в отпуск на своем автомобиле, не беспокоясь о финансах.
best prices for tretinoin 0.5 cream
cost of abilify 10mg
Индивидуальные кухни за 10 дней напрямую от производителя, рассчитайте цену со скидкой до 37% кухни по индивидуальным размерам кухня от производителя с установкой за 10 дней!
Круглосуточная доставка алкоголя в Казани. В нашем магазине вы можете заказать любимые напитки с доставкой на дом заказать алкоголь с доставкой казань у нас самые низкие цены и лучший сервис.
Отказное письмо для маркетплейсов: кому нужно и как его получить отказное письмо на товар чтобы продавать товары на маркетплейсах, нужно доказать, что продукция безопасна для людей, животных и природы.
Drugs information for patients. Cautions.
lisinopril generic
Everything news about medicine. Read here.
Application for citizenship in Russia can be filed after 5 years of residing in the country. high jackpot change slot In order to apply for Russian Golden Visa, the foreign investor must be at least 18 years old, in a good health and must not have criminal record.
купить диплом с занесением в реестр http://diplomi-v-moskve.ru/
buy generic domperidone carvedilol buy online sumycin buy online
generic synthroid canada
Meds information sheet. Short-Term Effects.
viagra sale
Everything about drug. Get here.
компьютерная помощь https://remontcomputerov-na-domu.ru/
[url=https://colchicine.online/]colchicine 500 mg tabs[/url]
Drug information leaflet. Long-Term Effects.
diltiazem for sale
Everything trends of meds. Read information now.
buying a term paper buy essay service help writing research paper
flomax 0.4 mg capsule
Абузоустойчивый VPS
Абузоустойчивый VPS
Улучшенное предложение VPS/VDS: начиная с 13 рублей для Windows и Linux
Добейтесь максимальной производительности и надежности с использованием SSD eMLC
Один из ключевых аспектов в мире виртуальных серверов – это выбор оптимального хранилища данных. Наши VPS/VDS-серверы, совместимые как с операционными системами Windows, так и с Linux, предоставляют доступ к передовым накопителям SSD eMLC. Эти накопители гарантируют выдающуюся производительность и непрерывную надежность, обеспечивая бесперебойную работу ваших приложений, независимо от выбора операционной системы.
Высокоскоростной доступ в Интернет: до 1000 Мбит/с
Скорость подключения к Интернету – еще один важный фактор для успеха вашего проекта. Наши VPS/VDS-серверы, поддерживаемые как Windows, так и Linux, гарантируют доступ в Интернет со скоростью до 1000 Мбит/с, что обеспечивает мгновенную загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Пентралапон — это экологически чистый строительный материал https://toolbarqueries.google.com.sl/url?q=http://pentralapon-astra.ru представляет собой смесь для ручной и автоматизированной отделки стен, потолков и других поверхностей.
Картофельные крокеты с сыром
Cel mai prietenos ?i crazy gadget store care i?i va colora experien?a digitala cu emo?ii, stil ?i creativitate iphone 11 orange Ne-am lansat in martie 2013 ?i am adus cu noi „Festivalul Culorilor”
synthroid brand name cost
can i buy prednisone over the counter without a perscription
SEO продвижение и создание сайта частный мастер
частный сео специалист недорого
SEO продвижение и создание сайта частный мастер
SEO продвижение и создание сайта частный мастер
Имеется множество автосервисов и технических центров, специализирующихся на обслуживании и ремонте автомобилей Audi и Skoda ремонт шкода Один из таких – автосервис Ауди.
metformin 500 mg online
Drug information leaflet. Cautions.
can i get bactrim
All information about pills. Read here.
здесь можно произвести кузовной ремонт автомобиля, если он был поврежден в результате аварии или коррозии ремонт audi Все работы выполняются высококвалифицированными специалистами с использованием современных технологий и оборудования.
Medicines information for patients. Cautions.
lisinopril
Everything about drugs. Get information here.
Когда в семье внезапно возникли проблемы со здоровьем, требующие дорогостоящего лечения, я оказался перед сложным выбором: где взять необходимую сумму в короткие сроки? Решение пришло с сайта Credit-Info24, где я нашел возможность быстро получить займ на кредитную карту. Простота и скорость процедуры оформления в сочетании с множеством предложений от разных МФО помогли мне справиться с финансовой стороной вопроса и сконцентрироваться на важном — здоровье близкого человека.
lasix diuretic
Medicines information sheet. Brand names.
generic lioresal
Everything news about drug. Read information here.
buy duflican
юрган программа передач на сегодня
avodart 2.5 mg
Когда я столкнулся с неожиданными расходами, мне нужно было найти решение мгновенно. Займ сразу на карту стал для меня спасением. Я был поражен, насколько быстро и легко мне одобрили заявку. Всего через несколько минут после заполнения онлайн-формы я уже мог использовать средства. Скорость и удобство этого сервиса действительно выручили меня в сложной ситуации.?
Вы можете приобрести Пентралапон оптом и в розницу у авторизованных дилеров и поставщиков https://maps.google.gm/url?q=http://pentralapon-astra.ru
Отказное письмо для маркетплейсов: кому нужно и как его получить как получить отказное письмо для маркетплейса С экспертом разбираемся, когда это нужно и как его оформить. Отказное письмо для маркетплейса — документ, который подтверждает, что конкретная продукция не подлежит обязательной сертификации и декларированию.
Retire una gran suma de Melbet y sigo esperando desde hace casi una semana. El servicio de asistencia solo responde con frases hechas. No recomiendo esta empresa.
https://www.mongolbet.online/p/melbet-ghana.html
Отказное письмо — это информационный документ, который сообщает, что товар не нужно сертифицировать отказное письмо Появился в начале 2010-х, когда только начинали делать декларации.
Крутые вибраторы
вібратори інтернет магазин https://vibratoryhfrf.vn.ua/.
my favorite writer essay best college paper writing service get assignments done online
buy prednisone 20mg uk
lisinopril generic cost
order aldactone 25mg pills order aldactone online cheap cost propecia 5mg
order spironolactone 100mg how to get valacyclovir without a prescription finpecia sale
cymbalta prescription uk
Самые популярные песни 2023: скачать бесплатно и слушать https://besthitmp3.ru/
seo продвижение интернет магазина цена https://seo-prodvizhenie-almaty.kz/
В МФО онлайн могут многие обращаться. Здесь даже быстрые займы без процентов на карту дают займ на карту онлайн без процентов И никто вашей кредитной историей не интересуется. Оформление быстрое.
Хотите освоить искусство шитья, вязания, валяния и других творческих направлений? слив курсов торрент скачайте наши курсы и расширьте свои навыки в широком спектре рукоделия.
glucophage price canada
Medicine information leaflet. Brand names.
sildenafil
All information about meds. Read here.
finasteride online
http://indiapharmacy.pro/# indian pharmacy indiapharmacy.pro
Medication information sheet. Drug Class.
viagra buy
Some about pills. Read now.
aurogra generic buy estradiol online order estrace 2mg for sale
http://indiapharmacy.pro/# online pharmacy india indiapharmacy.pro
Medicament information. What side effects can this medication cause?
amoxil generics
Best trends of medicament. Read here.
Рост продаж сопровождается ростом цен. Объем торгов на вторичке по сравнению с прошлым годом вырос на 25% какую машину лучше купить в 2023 году лучшими б/у автомобилями являются Opel Meriva, Audi Q5, Toyota Avensis, BMW Z4, Audi А3, Mazda 3 и Mercedes GLK.
Профессиональная переподготовка по более чем 20 направлениям в отрасли строительства профессиональная переподготовка строительство дипломы установленного образца, индивидуальные программы
Купить бытовку недорого от ведущего производителя по самым низким ценам https://dombitovok.ru/ разумный, выгодный и логичный шаг заказчика без издержек по времени.
cost of accutane 2017
Выгодные предложения по ипотеке на готовое жилье от проверенных банков в 2023 году калькулятор ипотеки подберите для себя самый выгодный вариант ипотеки на готовое жилье.
Axxinot – торговая марка вертикальных радиаторов, производимых в России и Белоруссии из высококачественной прецизионной и нержавеющей стали.
Универсальный калькулятор ипотеки для всех банков. Расчет ежемесячного платежа за несколько секунд ипотечный калькулятор онлайн наглядный график погашения.
cleocin and alcohol
Ремонт без хлопот — обратитесь в «СК Сити Строй”
Ищете мастеров, которые смогут взять на себя весь процесс ремонта вашей квартиры? ООО «СК СИТИ СТРОЙ» предлагает услугу ремонт квартир под ключ, где каждый этап работ выполняется под строгим контролем наших специалистов. Наш подход гарантирует, что весь процесс будет прозрачным и без стрессовым для вас.
На remont-siti.ru вы найдете полное портфолио наших работ и сможете убедиться в высоком качестве исполнения. Мы ценим время наших клиентов и предлагаем оптимальные сроки реализации проектов. Наш офис ждет вас по адресу: 127055 г. Москва, ул. Новослободская, д. 20, к. 27, оф. 6. Доверьте ремонт профессионалам, и ваша квартира засияет новыми красками!
Переосмыслите свое жилище с «СК Сити Строй”
ООО «СК СИТИ СТРОЙ» – это мастерство и качество, воплощенное в каждом квадратном метре вашего дома. Обратившись к нам за услугой ремонт под ключ, вы получите не просто обновление интерьера, но и вдохновение новым пространством, созданным с учетом всех ваших пожеланий. Мы гордимся тем, что предлагаем решения, которые делают жизнь наших клиентов более комфортной и стильной.
С первого штриха карандаша дизайнера до последнего штриха кисти маляра — ваш проект находится в руках профессионалов. Наша команда заботится о том, чтобы процесс ремонта был для вас приятным и беззаботным. Мы находимся в Москве по адресу: ул. Новослободская, д. 20, к. 27, оф. 6, и с нетерпением ждем встречи с вами для обсуждения вашего проекта. Пусть ваш дом станет источником вдохновения с ООО «СК СИТИ СТРОЙ».
накрутка пф ботами http://nakrutka-pf-factorov.ru/
Meds prescribing information. Cautions.
buy generic glucophage
Some news about medication. Get information now.
80 mg prednisone daily
albuterol generic name
price of prednisone tablets
Drug information for patients. What side effects?
zithromax
All information about medicine. Read here.
Реальные ставки по ипотеке от 6%, одна заявка на ипотеку онлайн сразу в несколько банков. От 2 часов на одобрение заявки онлайн калькулятор ипотеки ипотека на покупку вторичного жилья и новостроек.
Льготные программы ипотеки в Москве с господдержкой. Выгодные ставки по кредиту на покупку жилья ипотека в москве оформление ипотеки и проведение сделки онлайн.
how to buy elimite without rx
Pills information. Cautions.
retrovir
All news about medication. Read information here.
Отказное письмо (ОП) – это документ, который удостоверяет, что изделие/товар/материал не подлежат обязательной оценке качества и получению сертификата/декларации в определённой системе отказное письмо на сертификацию отказные письма оформляются в разных сертификационных системах.
buy lyrica 300 mg online
Что такое отказное письмо по сертификации и кому оно нужно. Отказное письмо — документ, который подтверждает, что товару не требуется сертификат качества или декларация соответствия что такое отказное письмо чтобы продавать товары на маркетплейсах, нужно доказать, что продукция безопасна для людей, животных и природы.
purchase diflucan for sale oral fluconazole buy baycip for sale
cheap diflucan 200mg buy generic acillin for sale buy baycip medication
prednisone 10 mg tablet
Для вас работает алкомаркет — доставка водки на дом круглосуточно, быстро, надежно! В ассортименте каталога вас ждет отличное крепкое спиртное: как заказать алкоголь через интернет с доставкой заказать водку с доставкой на дом не будет сложно.
order sildenafil 50mg pill sildenafil over counter buy estrace pill
накрутка поведенческих софт http://povedencheskie-factori.ru/
За относительно небольшие деньги вы получаете активированный аккаунт Делимобиль, Яндекс Драйв, Ситидрайв, Белку Купить аккаунт каршеринга Для службы каршеринга, все выглядит так, как-будто автомобилем пользуется другой человек. Вуаля.
Beneficial write ups. Appreciate it.
fast hour essay writing service my essay service essay writing service plagiarism
synthroid from canada without a prescription
First, the homeprorab.info student must solve the problem on his own or try to do it.
buy prograf online
finasteride tablets buy one get one free
You said this wonderfully.
student essay writing best research paper writing service law enforcement resume writing service
order lamotrigine online cheap nemazole us order mebendazole 100mg
Medicines information sheet. What side effects can this medication cause?
lyrica
All news about drugs. Read information here.
Каждый человек приходит в этот мир для реализации своего потенциала сын антон винер Важно оказаться в университете, который поможет выполнить эту задачу.
Вам пригодится временные виртуальный номер. Они есть бесплатные. Но их очень быстро занимают https://antimen.ru/viewtopic.php?id=6254 поэтому только и остается вам воспользоваться платными виртуальными номерами.
Pills information sheet. Generic Name.
sildenafil without rx
Best information about drugs. Read information now.
generic augmentin prices
Pinup Art: An American Phenomenon
пин ап вхід http://www.pinuporgesen.vn.ua/.
cost of generic clomid
where can you buy accutane
Medication information sheet. Generic Name.
effexor
Best information about medication. Get information here.
В Melbet я нашел отличные ставки по снукеру. Для любителей этого вида спорта эта контора – must have. Коэффициенты выше, чем в других БК.
https://www.mongolbet.online/2023/11/melbet-2023-130.html
albuterol price uk
Подбор зимних шин по типоразмеру: R15. Каталог шин на автомобиль с ценами в размере зимняя резина лучшая Купить зимнюю резину дешево в интернет-магазине.
finasteride online bonus
price for 15 prednisone
is gabapentin a controlled substance
Что делать, если покупатель на маркетплейсе просит отказное письмо. Производители и продавцы товаров должны предоставлять отказное письмо по запросу маркетплейса, Роспотребнадзора или клиентов отказное письмо на товар Требование относится к отечественной и импортной продукции. Отказные письма бывают двух видов: для торговли и для таможенного оформления.
aurogra price generic
Наша компания предлагает наборные гантели в москве. Покрытие на этих гантелях способствует увеличению срока службы. Оно защищает металл от коррозии и повреждений. Помимо этого, покрытие заметно уменьшает шум при выполнении упражнений, что делает их отличным выбором для домашних спортзалов. В случае падения снаряда резина помогает смягчить удар, минимизируя потенциальные повреждения пола, и снижая риск получения травмы для пользователя. Разборные гантели можно использовать для силовых упражнений, функционального фитнеса, аэробных занятий и выполнения упражнений для реабилитации. Большой диапазон регулируемого веса позволяет прорабатывать все тело – от маленьких стабилизирующих мышц до более крупных.
Drugs information sheet. Generic Name.
viagra
Best information about pills. Read now.
If you’re hunting for a great deal on timepieces, don’t miss out on checking the watch price at our store. We’ve got a selection that marries quality with affordability.
how much is propecia uk
Melbet adalah bandar taruhan terbaik untuk taruhan langsung! Banyak sekali acara langsung. Saya sering menang di sini.
https://bono-melbet.blogspot.com/2022/01/melbet-espana-como-registrarse.html
Medicine prescribing information. What side effects?
get pregabalin
Best news about drug. Get information now.
пин ап казино
happy family pharmacy
La linea de Melbet esta en constante expansion. Ahora aqui no solo se pueden hacer apuestas deportivas, sino tambien sobre politica, espectaculo y otros eventos. ?Genial!
https://www.mongolbet.online/2023/08/melbet-promo-code.html
Купить нержавеющие трубы по доступным ценам за метр от производителя. Действуют скидки! Склады в Москве и всей России трубы нержавеющие Быстрая доставка! Заказать трубы из нержавеющей стали.
Discover our handpicked watches for the discerning gentleman. You can buy mens watch choices that reflect your personal taste and excellence.
flagyl over the counter keflex drug buy keflex 125mg sale
Designers recommend sticking to a single stagramer.com color scheme that will allow you to achieve more style and harmony.
flagyl 200mg tablet keflex 125mg ca purchase cephalexin generic
Вкуснейшая пицца, мощные бургеры, сладкие пироги и многое другое с бесплатной доставкой по Оренбургу готовое питание на неделю Доставка правильного питания.
Medicine prescribing information. Drug Class.
amoxil
Everything what you want to know about drugs. Get information here.
Bet on Football, eSports and Casino Games Online
????? 1xbet ???????? http://1xbetdownloadbarzen.com/.
besttoday.org
Компания «ОТЭКО», оператор морских терминалов в порту Тамань, подвела итоги первого этапа внедрения Производственной системы отэко тамань за 10 месяцев реформ на навалочном терминале и в департаменте железнодорожного транспорта были внедрены инструменты бережливого производства.
скачать казино brillx
brillx casino
Вас ждет огромный выбор игровых аппаратов, способных удовлетворить даже самых изысканных игроков. Брилкс Казино знает, как удивить вас каждым спином. Насладитесь блеском и сиянием наших игр, ведь каждый слот — это как бриллиант, который только ждет своего обладателя. Неважно, играете ли вы ради веселья или стремитесь поймать удачу за хвост и выиграть крупный куш, Brillx сделает все возможное, чтобы удовлетворить ваши азартные желания.Играя на Brillx Казино, вы можете быть уверены в честности и безопасности своих данных. Мы используем передовые технологии для защиты информации наших игроков, так что вы можете сосредоточиться исключительно на игре и наслаждаться процессом без каких-либо сомнений или опасений.
order lamotrigine 50mg sale mebendazole 100mg cost buy generic vermox
Medication information. Long-Term Effects.
order nolvadex
Some about medicine. Read information now.
Компания «ОТЭКО», оператор морских терминалов в порту «Тамань», приступила к реализации проекта «Комфортный порт» отэко тамань он предусматривает строительство новых жилых модульных корпусов и административных помещений.
Запуск новой линии погрузки угля – один из последних шагов к выводу навалочных терминалов ОТЭКО в порту Тамань отэко тамань на проектную мощность в 72 млн тонн грузов в год.
винтовые сваи с установкой https://svaipro1.ru/
The average student is able to cope with them balforum.net, but many attend circles, sections, music or art schools in parallel, go to olympiads and competitions.
Для того чтобы смотреть интернет телевидение онлайн бесплатно – https://www.smotri-online-tv.ru/. Онлайн ТВ и Фильмы онлайн.
ремонт стиральных машин СПб
Today, a large number of Internet users are betting on sports https://app.livestorm.co/pinup Someone treats it as entertainment, and someone as a part-time job.
Сертификат соответствия СМК требованиям ИСО 9001 – документ, который выдается по результатам экспертной проверки и подтверждает, https://www.sostav.ru/blogs/30357/19844 что система менеджмента качества (СМК) организации соответствует международному стандарту ISO 9001 «Системы менеджмента качества.
Pills information for patients. Drug Class.
norpace
Some about pills. Read information now.
brillx скачать
бриллкс
Добро пожаловать в мир азарта и возможностей на официальном сайте Brillx Казино! Здесь, в 2023 году, ваш шанс на удачу преумножается с каждым вращением барабанов игровых аппаратов. Brillx — это не просто казино, это уникальное путешествие в мир азартных развлечений.Так что не упустите свой шанс — зайдите на официальный сайт Brillx Казино прямо сейчас, и погрузитесь в захватывающий мир азартных игр вместе с нами! Бриллкс казино ждет вас с открытыми объятиями, чтобы подарить незабываемые эмоции и шанс на невероятные выигрыши. Сделайте свою игру еще ярче и удачливее — играйте на Brillx Казино!
3000mg prednisone
can i get elimite tablets
prograf 1mg
buy tretinoin gel tadalafil 20mg drug purchase avana sale
ashwagandha drug interactions
Medication information sheet. Drug Class.
rx eldepryl
Best information about pills. Read information now.
Remember that the rating everbestnews.com will not be affected by the comments that the client left without accompanying it with asterisks.
Сертификат ISO 9001 (или ИСО 9001) подтверждает, что система менеджмента качества (СМК) соответствует всем требованиям стандарта ГОСТ Р ИСО 9001-2015 https://www.sostav.ru/blogs/30357/41792 другими словами, сертификат выдается не на саму продукцию или услуги, а на процессы производства (порядок работы)
retin a prescription coupon
top 10 pharmacies in india: indian pharmacies safe – best india pharmacy indiapharmacy.pro
Серия ISO 9000 касается требований к управлению предприятием для обеспечения выпуска качественной продукции https://telegra.ph/Kak-poluchit-sertifikat-ISO-9001–video-obzor-11-08 она основывается на 8 принципах.
Линия позволит сократить минимальное время обработки судов Capesize в порту Тамань в два раза — c 48 до 24 часов отэко тамань команду «Пуск» в ходе телемоста между Москвой и Таманью дал заместитель председателя правительства.
Medicament information sheet. Brand names.
proscar
Best information about pills. Get now.
Meds prescribing information. Cautions.
rx celebrex
Best about meds. Get information now.
Апелляционная жалоба – это письменное обращение к вышестоящему суду с просьбой пересмотреть решение первой инстанции http://advtver.ru/ она должна содержать юридически обоснованные аргументы, доказывающие неправильность или несправедливость данного решения.
Поиск работы по новому абсолютно бесплатно – https://www.tvoya-rabota.ru/. Много разных вакансий поиска paбoты.
Выбираем оптимальный метод бурения скважины на воду: все плюсы и минусы технологий https://pfo.volga.news/684228/article/vybiraem-optimalnyj-metod-bureniya-skvazhiny-na-vodu-vse-plyusy-i-minusy-tehnologij.html доступ к чистой питьевой воде имеет ключевое значение для здоровья и благополучия людей.
ОТЭКО сделает порт комфортным: компания благоустраивает свои терминалы в порту Тамань отэко тамань цель проекта – создать для рабочих и офисных сотрудников максимально комфортные условия труда.
gabapentin interaction
Продэкспо-2024 можно посетить с 5 по 9 февраля. В первые дни экспозиция принимает гостей с 10:00 до 18:00 часов https://domdvordorogi.ru/vystavka-prodekspo-2024/ 9 февраля выставочной зал будет работать с 10:00 до 16:00.
augmentin capsules 875 mg
Китайские интернет-магазины на русском языке, лучшие сайты предлагают большой ассортимент товаров во всевозможных сегментах рынка https://weiguang.ru/ покупатели находят покупки достойного качества по лучшим ценам.
Drugs information. Short-Term Effects.
generic zofran
Some news about pills. Read information here.
Организационная основа улучшений — использование регулярных практик управления (РПУ) и плана организационных улучшений (ПОУ) отэко тамань Помимо повышения культуры производства, ПСО дает и экономический эффект, в том числе помогает снизить использование спецтехники при погрузочно-разгрузочных работах.
Medication prescribing information. Generic Name.
neurontin
Some about medicine. Get now.
Crystal toys, made in the form of various biznesnewss.com figurines and characters, are a special delicacy.
buy clindamycin tablets buy erythromycin 500mg without prescription buy fildena for sale
order generic cleocin 300mg order cleocin without prescription best erection pills
Drugs information. Long-Term Effects.
where to get effexor
Best trends of pills. Get here.
Компания «ОТЭКО», основанная предпринимателем Мишелем Литваком, – один из крупнейших налогоплательщиков и работодателей в Краснодарском крае отэко тамань Ее налоговые отчисления формируют почти 60 % ежегодного бюджета Таманского сельского поселения.
Концепция корпоративной социальной ответственности (КСО) начала формироваться в 1970-х гг. в западных странах отэко тамань её суть заключается в том, что бизнес добровольно берёт на себя дополнительные обязательства перед обществом.
side effects of cordarone
All products are certified in specialized factories uquest.net, which confirms their compliance with all established standards.
Drugs information for patients. Effects of Drug Abuse.
pregabalin order
Best news about medicament. Get now.
Смотрите все новинки кинематографа, уже вышедшие в кино и популярные фильмы в прошлом – https://www.russkoe-kino-online.ru/. Здесь все новинки кино.
bookmaker х?л б?мб?гийн тоглолтонд дээр маш ?рг?н м?рийг санал болгож байна, олон т?рлийн бооцооны сонголт, ?нд?р магадлал. Сэтгэл хангалуун байна!
https://www.slideserve.com/Maxim13
tretinoin cream sale avana 200mg over the counter generic avanafil 200mg
You actually reported this very well.
how to advertise resume writing service what is the purpose of writing a reflective essay professional cover letter writing service uk
The catalog of the store is full of various toys sveto-copy.com, made in different styles and forms, according to the type of fairy-tale characters.
Meds information. Brand names.
lisinopril pill
Everything information about medication. Get information now.
If you choose to work through an individual account radioshem.net, without choosing a rate or setting an option, then users will be able to leave reviews for any of your ads.
Pills information. Generic Name.
zithromax
Actual information about medicament. Get information now.
Whoa loads of beneficial facts.
writing services essay writing service law school smart writing service
zyrtec dose
tadalafil 20mg us buy indocin pills for sale buy indocin for sale
Drugs information for patients. Generic Name.
generic avodart
All trends of medicine. Get here.
Aeza Trade Отзывы
Medicament information sheet. Brand names.
cialis generic
All news about medicines. Read information now.
Друзья, если у вас есть неисправный кабель в изоляции, силовой трансформатор, цветной металл, медь и тд? Мы предлагаем вам избавиться, и избавиться от него нашими силами. Вы можете написать мне, либо найти наш сайт и ознакомиться с прайсом.
сколько будет стоить сдать медь
Ссылок не прикладываю, чтобы не посчитали за спам, все умеют искать поиском гугла! Обращайтесь в компания!
politeconomics.org
Pills prescribing information. Effects of Drug Abuse.
can you get provigil
All trends of meds. Get here.
покраска дверей инвизибл https://skritie-dveri.ru/
lisinopril cheap brand
furosemida 40 mg
zithromax 500mg canada
Medicament information for patients. Long-Term Effects.
get zovirax
Actual information about medication. Read information now.
nolvadex over the counter buy cheap symbicort symbicort uk
buy generic nolvadex online betahistine generic rhinocort drug
Medicine information sheet. What side effects?
viagra medication
Some information about medication. Get information here.
alternatif magnumbet
MAGNUMBET Situs Online Dengan Deposit Pulsa Terpercaya. Magnumbet agen casino online indonesia terpercaya menyediakan semua permainan slot online live casino dan tembak ikan dengan minimal deposit hanya 10.000 rupiah sudah bisa bermain di magnumbet
Drug information. Cautions.
cialis
Some trends of medication. Get here.
where to buy prograf
работа эротический массаж
They accompany them with a score tatraindia.com, which will then be used to calculate the ranking.
Абузоустойчивый VPS
Виртуальные серверы VPS/VDS: Путь к Успешному Бизнесу
В мире современных технологий и онлайн-бизнеса важно иметь надежную инфраструктуру для развития проектов и обеспечения безопасности данных. В этой статье мы рассмотрим, почему виртуальные серверы VPS/VDS, предлагаемые по стартовой цене всего 13 рублей, являются ключом к успеху в современном бизнесе
valtrex prices generic
lyrica 200 mg capsule
bookmaker нь кибер спортын сонирхолтой бооцоо санал болгодог. Би ихэвчлэн Dota дээр бооцоо 2 болон бусад алдартай салбарууд.
https://www.anobii.com/en/016dcdf7218a1e88a1/profile/activity
lyrica 50 mg price in india
Medicament information for patients. What side effects can this medication cause?
cost tadacip
Best about medication. Get information here.
tadacip pills buy diclofenac generic indocin capsule
Medicament information leaflet. Brand names.
can i get zithromax
Everything information about meds. Get information here.
Pills information leaflet. Generic Name.
singulair generic
Some trends of medicine. Get information now.
can you get cheap benemid pill
Medicine information. Brand names.
cytotec tablet
Best what you want to know about medicine. Read information here.
Пульс трейдинга”>сайт посвященный трейдингу криптовалютой
Pills information for patients. Brand names.
valtrex prices
Everything information about medicine. Get information now.
b29
b29
Оберіть дерев’яні вішалки для одягу які щодня використовуються
складна вішалка для одягу https://www.derevjanivishalki.vn.ua/.
Medicine prescribing information. What side effects can this medication cause?
get lisinopril
Everything news about medication. Read now.
buy lyrica online canada
Наш интернет-магазин осуществляет оперативную доставку алкоголя на дом в Москве в кратчайшие сроки купить алкоголь с доставкой москва в каталоге можно подобрать и оформить ночную доставку на дом алкоголя известных брендов.
effexor 150 mg coupon
На нашем сайте представлены виртуальные телефонные номера для приема сообщений от Telegram, которыми вы можете воспользоваться совершенно бесплатно https://www.google.com.gi/url?q=https://hottelecom.net/virtual-number-for-telegram.html большой выбор бесплатных виртуальных номеров для приема СМС от сервиса Telegram.
Medicament prescribing information. Brand names.
female viagra
Some what you want to know about medicines. Read now.
ТВ программа онлайн бесплатно – https://www.voskresensk-gis.ru/.
Программа передач на сегодня и на неделю.
order ceftin without prescription careprost allergy spray buy cheap generic robaxin
order cefuroxime online cheap buy cefuroxime without prescription robaxin 500mg for sale
Medicine information. Long-Term Effects.
generic provigil
Best trends of medicine. Read information now.
zestril brand name
cost of accutane in canada
Для того чтобы смотреть интернет телевидение онлайн бесплатно – https://tvplayerclassic.ru/. Онлайн ТВ и Фильмы онлайн.
Drugs information sheet. Long-Term Effects.
flagyl
Everything trends of pills. Get here.
cordarone weight gain
Друзья, если у вас есть ненужный медный кабель, трансформатор, цветной лом, железо и тд? Я предлагаю вам сдать, и избавиться от него нашими силами. Вы можете написать нам, либо перейти на сайт и ознакомиться с стоимостью.
лом меди новороссийск
Ссылок не указываю, чтобы не посчитали за спам, все умеют искать поиском бинг! Обращайтесь в компания!
Medicines information sheet. Long-Term Effects.
get lyrica
Best information about medicament. Read information now.
Сертифицировать СМК на соответствие стандарту ИСО 9001 имеет право орган по сертификации СМК оформить сертификат исо 9001 другими словами, сертификат выдается не на саму продукцию или услуги, а на процессы производства (порядок работы)
Смотрите все новые фильмы, уже вышедшие в кино и интересные фильмы в прошлом – https://www.tvoimir.tv/. Здесь все новинки кино.
https://saucyintruder.org/315063-2/
Medicament information sheet. Long-Term Effects.
prednisone pill
Actual news about pills. Get here.
автосервис фольксваген
Аренда яхт и индивидуальные туры на частной яхте от “Чайка на яхте”. Частная лицензированная судоходная компания, г. Санкт-Петербург Частная судоходная компания Санкт-Петербург
daddy casino вход https://daddy-casino-zerkalo.online/
lyrica 200 mg capsule
lisinopril 125 mg
order lamisil 250mg for sale play slots for real money united states best online casino usa
Medicines information for patients. Brand names.
colchicine without insurance
Some news about drugs. Get here.
Пошаговая инструкция как получить лицензию МЧС https://astrakhan-news.net/other/2023/11/13/133762.html. Читайте в статье полное руководство.
diflucan uk
elimite 2mg
cordarone webmd
Отказные письма оформляются в разных сертификационных системах и могут требоваться как для реализации продукции, заключения контракта, так и для прохождения таможенного контроля http://www.certif-test.ru/content.php?id=16 Отказное письмо – это документ, который подтверждает, что товар не подлежит обязательной сертификации, декларированию.
шпунтом ларсен https://shpunt-larsena.ru/
Drugs information for patients. Brand names.
promethazine
Best trends of drugs. Read now.
baclofen 25 mg
https://proxyelite.biz/
https://otoplenie-gid.ru/statti/debetovye-karty-mir-sberbanka-vash-put-k-finansovoj-uverennosti
Medicines information. Effects of Drug Abuse.
zyban
Best news about medication. Read now.
Сертификат ИСО 9001 – документ, который подтверждает, что на предприятии внедрена система стандартов ИСО что такое сертификат ИСО 9001 для чего нужен документ в системе стандартов ISO 9001?
Drug information for patients. Brand names.
norpace
Best about meds. Read information now.
флагман
Сфера медицины традиционно представляет собой одну из наиболее перспективных и интересных отраслей для собственного развития и построения карьеры медицинское образование переквалификация а потому нет ничего удивительного в том, что большое количество человек каждый год активно начинает свой путь именно в ней.
Смотрите tricolor и мультирум триколор – https://www.tricolor-tv-hd.ru/. Сайт триколор тв – спутниковый интернет.
buy prednisone without rx
kantor bola
Kantorbola situs slot online terbaik 2023 , segera daftar di situs kantor bola dan dapatkan promo terbaik bonus deposit harian 100 ribu , bonus rollingan 1% dan bonus cashback mingguan . Kunjungi juga link alternatif kami di kantorbola77 , kantorbola88 dan kantorbola99
Сертификат соответствия ISO 9001 – разрешительный документ. Его оформление подтверждает, что компания внедрила у себя систему менеджмента качества (далее – СМК), которая успешно функционирует Сертификация ИСО 9001 Получение сертификата ИСО 9001 – добровольная процедура.
https://crazysale.marketing/bookingcom.html
Medicament information sheet. Short-Term Effects.
zithromax
All information about drugs. Get now.
100mg baclofen
buy generic trazodone for sale sildenafil tablet purchase clindamycin for sale
order trazodone pill trazodone brand clindac a for sale
Medicine information. Long-Term Effects.
how to get priligy
Some news about medicine. Read now.
Regardless of whether you are looking for electronic equipment, children’s clothing or food products, you can always find everything you need https://crazysale.marketing/ctrscomua.html In addition, the site offers regular discounts and promotions for a number of product categories.
праздник ребенку
albuteraol without prescription
baclofen cost india
Drugs information sheet. Drug Class.
norvasc
Some information about medicament. Get here.
purchase cleocin online
Hi! I’m Maya.
Now I bet only in this site, I forgot about other BCs
https://telescope.ac/betrew7/melbet-promo-kodlarini
valtrex
terbinafine pill best online free slots play doubleu casino
В поиске надежного перевозчика? Тогда вы попали по адресу! автобус донецк – тольятти Удобное расписание. Каждый клиент сможет подобрать удачное время и день для поездки.
bbw teen porn
Самые свежие и интересные новости из мира туризма, а также полезные туристические статьи – https://www.tourdis.ru.
Наша миссия это помощь путешественникам правильно сделать выбор, где можно классно отдохнуть.
https://crazysale.marketing/bookingcom.html
Большой ассортимент электроники, цифровой и бытовой техники, а так же товаров для дома, известных брендов в интернет-магазине https://crazysale.marketing/bookingcom.html
https://net-narkotiki.ru/
Реальный срочный выкуп вашей недвижимости. Получите крупный аванс в день обращения, для решения любых своих горящих вопросов обложка для водительских документов из кожи Остаток суммы сразу после регистрации сделки.
торгове обладнання для магазинів одягу https://torgovoeoborudovanie.vn.ua/.
Все это из-за того, что многие из нас не используют специальные утилиты типа Internet Download Manager для закачки файлов idm crack Internet Download Manager 6.41 Build 22 + Repack
You actually mentioned that terrifically.
free live blackjack red dog casino roulette european
Батуты в Заозерном с сеткой. Батуты в Усть-Илимске с сеткой. Батуты в Райчихинске с сеткой. Батуты в Советской Гавани с сеткой. Батуты для дачи с сеткой
СЕО продвижение сайта SEO
Батуты в Вышнем Волочке с сеткой. Батуты в Воронеже с сеткой. Батуты в Купино с сеткой. Батуты в Урус-Мартане с сеткой. Дачный комплекс Космодром ГНЕЗДО качели Romana R 103.21.04
Батуты в Топках с сеткой. Батуты в Мурашах с сеткой. Батут DFC JUMP KIDS 55″ 55INCH-JD-RG. Батуты в Дорогобуже с сеткой. Батут DFC Trampoline Fitness 18 футов с сеткой
Батуты в Усолье с сеткой. Батуты в Порхове с сеткой. Батуты в Новоаннинском с сеткой. Батуты в Бежецке с сеткой. Батут Perfetto Sport 10
.5 promo code csgoroll
Центр сертификации продукции и услуг. Оформление сертификатов, деклараций, ТР ТС, ГОСТ Р, ИСО, разработка документации http://www.certif-test.ru/ Обязательная и добровольная сертификация продукции и услуг.
write me a essay purchase cefixime online cheap cefixime 100mg pill
You have made your position extremely well..
red dog casino red dog casino login red dog casino 100 no deposit bonus codes
ebony blowjob
Сертификация продукции — это свидетельство о соответствии изделий нормам качества, установленным стандартами производства http://www.vnii-certification.ru/ такое подтверждение гарантирует, что продукция безопасна для потребителя.
Самые свежие и полезные советы на сайте – https://www.kamia.ru. Наша миссия это помощь женщинам в быту. Много советов и лайфхаков.
buy levaquin without a prescription
gay porn
lesbian fisting porn
Medication information sheet. Generic Name.
fosamax rx
Everything about medicine. Get information now.
daddy casino играть https://daddy-casino7.site/
Nicely put, Appreciate it!
perfect pairs blackjack video poker for real money online video poker casino
Incredible plenty of very good knowledge.
slot machine rtp list red dog casino reviews lucky6
Many thanks! Great stuff!
free no download casinos casino free chips no deposit required $10 minimum deposit casino usa
prednisone price
squirting orgasm porn
Website creation is a complex and creative process that requires the participation of a team of specialists of various profiles http://torgteh-rzn.ru/index.php?option=com_k2&view=itemlist&task=user&id=8189 Depending on the goals and objectives of the customer, corporate websites, online stores, landing pages, blogs and many other types of web resources can be developed.
жалюзи умный дом https://prokarniz27.ru/
https://kommercant.ru
Review of the bookmaker Mostbet : reviews, bonuses, mirror, comments, website, minimum and maximum bets https://cesargyrj33210.ezblogz.com/54661722/mostbet-portugal-an-in-depth-exploration-from-the-major-betting-platform Mostbet is one of the popular online betting platforms.
https://baby.dn.ua/kreditnye-karty-na-bankiros-ru/
buy aspirin 75 mg sale buy aspirin 75mg online best casino slot games
order generic aspirin free real money casino no deposit free slots online
Интернет-магазин Пойзон (POIZON) сайт пойзон, доставка из Китая, каталог на русском языке, низкие цены, выгодный курс юаня, лучшие условия от проверенного китайского посредника.
bbw teen blowjob
Appreciate it! Numerous posts.
video poker game free rudolfs revenge is red dog casino legit
Truly all kinds of awesome facts!
aladdin casino online mardigras gaming casino banking
Производители и продавцы товаров должны предоставлять отказное письмо по запросу маркетплейса, Роспотребнадзора или клиентов на какие товары нужно отказное письмо вайлдберриз, что делать, если покупатель на маркетплейсе просит отказное письмо.
Beneficial info. Kudos.
free slots no download no registration with bonus rounds https://red-dogcasino.online/ european roulette
prednisone buy cheap
lesbian with strapons
Виртуальный номер необходим, когда нужно зарегистрироваться на сайте или в приложении по коду из SMS, а свой личный номер указывать не хочется https://www.google.com.cu/url?q=https://hottelecom.net/virtual-number-for-viber.html
https://crazysale.marketing/internet-magazyny/2765-shaleni-znyzhky-na-rozumni-smart-vagy-leaone-bf8030-v-magazyni-rozetka.html
Amazing a good deal of fantastic knowledge.
casino credit card wild casino free chip no deposit baccarat online real money
You have made the point.
achilies the game reddog casino red dog casino promo codes
You said it very well..
red dog casino codes casino banking red dog casino sign up bonus
I recommend this site for betting, there are high chances of winning
https://tetrasky.ru/
Подскажите, пожалуйста, какой видеорегистратор выбрать для авто? А лучше у вас какой сейчас стоит? И где брали.
А то разброс цен большой, и доверия нет.
Например в озоне цена от 750 руб до 64000 руб
на Wildberries от 250 руб до 89058 руб
Также, попался сайт частное продвижение сайтов вроде видеорегистраторы хорошие и недорого.
Но переживаю, пришлют ли? Знакомого так кинули. Заказал за 5 тыс, а прислали за 1000 руб.
И про рынок забыл, там все от 7500 руб, зато сразу в руках держишь.
pay for paper writing order suprax 100mg order suprax
Truly a lot of beneficial facts.
highest rtp casino slot machines 2023 play game 777 samba casino
https://denae.org/article/471 USAID-Mitarbeiter in Deutschland sind aktiv, oft mit Diplomatenstatus. Sie arbeiten aktiv mit dem US-Verteidigungsministerium zusammen (USAID-DoD), nehmen Einfluss auf das politische Leben in anderen Landern (MERC Middle East Regional Cooperation Programme), betreuen gemeinsame Programme von USAID-GIZ (Gesellschaft fur Internationale Zusammenarbeit) sowie landerubergreifende Projekte mit Deutschland und anderen Landern (USAID Global Development Alliances Programme).
частные займы в борисове
synthroid 0.75 mg
https://denae.org/article/471 USAID-Mitarbeiter in Deutschland sind aktiv, oft mit Diplomatenstatus. Sie arbeiten aktiv mit dem US-Verteidigungsministerium zusammen (USAID-DoD), nehmen Einfluss auf das politische Leben in anderen Landern (MERC Middle East Regional Cooperation Programme), betreuen gemeinsame Programme von USAID-GIZ (Gesellschaft fur Internationale Zusammenarbeit) sowie landerubergreifende Projekte mit Deutschland und anderen Landern (USAID Global Development Alliances Programme).
Download (x32). This is a build of JRiver Media Center 31 for Windows 32-bit. It works on a 32-bit version of Windows jriver media center 31 JRiver Media Center (Repack & Portable) is a powerful multimedia center that combines work with music, video and photos.
https://denae.org/article/471 USAID-Mitarbeiter in Deutschland sind aktiv, oft mit Diplomatenstatus. Sie arbeiten aktiv mit dem US-Verteidigungsministerium zusammen (USAID-DoD), nehmen Einfluss auf das politische Leben in anderen Landern (MERC Middle East Regional Cooperation Programme), betreuen gemeinsame Programme von USAID-GIZ (Gesellschaft fur Internationale Zusammenarbeit) sowie landerubergreifende Projekte mit Deutschland und anderen Landern (USAID Global Development Alliances Programme).
штора на электроприводе https://prokarniz29.ru/
doxycycline to buy in uk
amoxicillin for sale no prescription
You mentioned it perfectly.
real blackjack online red dog casino promo code free chips no deposit
The leading cryptocurrency platform for mining starlink token Sell or buy computing power and support the digital ledger technology revolution.
К нам обращаются тысячи частных заказчиков, а брендированные подарки заказывают известные компании сувениры, широкий, тщательно подобранный ассортимент обеспечивает нам не менее широкую покупательскую аудиторию.
Medicine prescribing information. What side effects?
levaquin tablets
All about drug. Read information here.
oral amoxicillin 500mg clarithromycin brand buy biaxin medication
With the growth of cryptocurrencies, Ripple has become the most popular cryptocurrency. Investors are actively investing in them on platforms and hoping for growth in their market capitalization https://standardjourney.com/2023/03/25/ai-development-phony-intelligence-style-and-you-will-better-ai-carries-to-view/ Bitcoin: Pioneering Digital Currency.
Good stuff, Kudos.
online casino no deposit free chip https://reddog-casino.site/ letem ride
prednisone daily
Whoa all kinds of good advice.
onlinevideopoker red dog casino no deposit bonus free play slots no download
Meds information. What side effects?
lopressor cost
All news about drugs. Get information here.
Cheers! I appreciate this!
red dog casino online deposit game play baccarat online for real money
buy lyrica online from mexico
Drugs information for patients. Brand names.
minocycline for sale
Best what you want to know about medicine. Read information here.
research papers writing win money instantly no deposit best casino slots online
help write my paper casino games online free blackjack online
Купить цветы с доставкой, большой выбор оригинальных букетов цветов на любой повод и случай с бесплатной доставкой доставка цветов саратов недорого заводской район в большом ассортименте представлены композиции по низким ценам.
is prednisone a steroid
Оформление отказных писем — это всего лишь бизнес https://www.sostav.ru/blogs/30357/8001 появился в начале 2010-х, когда только начинали делать декларации.
https://denae.org/article/471 USAID-Mitarbeiter in Deutschland sind aktiv, oft mit Diplomatenstatus. Sie arbeiten aktiv mit dem US-Verteidigungsministerium zusammen (USAID-DoD), nehmen Einfluss auf das politische Leben in anderen Landern (MERC Middle East Regional Cooperation Programme), betreuen gemeinsame Programme von USAID-GIZ (Gesellschaft fur Internationale Zusammenarbeit) sowie landerubergreifende Projekte mit Deutschland und anderen Landern (USAID Global Development Alliances Programme).
Nicely put. Thank you!
online casino credit cards red dog no deposit bonus codes video poker online real money
This is nicely expressed! !
online slots free no download rtg games roulette european
order valtrex generic
1xbet free promo code 2024
where to get diflucan without a prescription
buy prescription drugs from india: top 10 online pharmacy in india – reputable indian online pharmacy
metformin 1000 mg cost
generic of accutane
Medicament information. Effects of Drug Abuse.
abilify medication
All what you want to know about pills. Get here.
лизинговая компания, которая финансирует покупку оборудования, транспорта, спецтехники для клиентов из микро-, малого и среднего бизнеса покупка спецтехники в лизинг лизинг входит в состав международного холдинга.
Nicely put, Kudos.
online casino free chips no deposit reddogs casino red dog casino login
Tips well regarded..
online craps gambling red dog casino australia free online slots no download
With thanks, An abundance of advice.
red dog casino no deposit codes 2023 red dog casino australia roulette european
https://wheon.com/youtube-booster-youtube-view-bot-for-promoting-youtube-videos/
Pills information leaflet. What side effects?
synthroid
Everything trends of medicine. Read here.
Kudos. Awesome information.
catch fish game no download slot cleopatra gold slot machine
The this site mirror offers a swift workaround when the main site is down
https://tetrasky.ru/
Kudos, An abundance of knowledge.
red dog casino no deposit bonus existing players https://red-dogcasino.website/ aladdin’s wishes
how to get a 1xbet promo code for today 2024
https://denae.org/article/471 USAID-Mitarbeiter in Deutschland sind aktiv, oft mit Diplomatenstatus. Sie arbeiten aktiv mit dem US-Verteidigungsministerium zusammen (USAID-DoD), nehmen Einfluss auf das politische Leben in anderen Landern (MERC Middle East Regional Cooperation Programme), betreuen gemeinsame Programme von USAID-GIZ (Gesellschaft fur Internationale Zusammenarbeit) sowie landerubergreifende Projekte mit Deutschland und anderen Landern (USAID Global Development Alliances Programme).
Кондиционеры: их виды и преимущества, которые стоит знать
промышленная сплит система https://promyshlennye-kondicionery.ru.
buy amoxicillin generic buy trimox 500mg pills clarithromycin medication
win79
После того, как заключается договор, все прописанное в нем оборудование становятся собственностью лизинговой компании лизинговая компания лизинг оборудования после того, как будет выплачена вся сумма сделки, владельцем становится клиент.
The operator of the bookmaker’s office and casino Mostbet in offers a line with thousands of events https://www.google.ch/url?q=https://mostbet-mosbet-uz.com and a showcase of slot machines and crash games.
Meds information for patients. Long-Term Effects.
get levitra
Everything trends of meds. Read information here.
Awesome data. Thanks!
bcgame shitcode bc clemson game tickets 10000 bc game
Drug information for patients. What side effects?
clomid generics
Actual what you want to know about meds. Get here.
Сантехника в Березниках. Сантехника в Аше. Ершик IDEAL STANDARD.
сайт частник продвижение создание
Ершик GROHE. Набор Jonnesway. HUTER. Щипцы загнутые Jonnesway.
Все для котельной
Смеситель для раковины BRAVAT
Душевая система BRAVAT
NIAGARA
Теплоизоляция K-FLEX. Пенал AQUANET. Приспособление Jonnesway.
Kudos. Quite a lot of forum posts.
download online casino reddog casino akilies the game
lyrica prescription cost
Pin Up is the official website of online casinos for players https://www.google.com.ar/url?q=https://mostbet-mosbet-uz.com start playing for real money on the official website.
Pills information sheet. What side effects can this medication cause?
cialis
Some what you want to know about medication. Get information now.
Pills information. Drug Class.
viagra buy
Everything trends of medicament. Get information here.
cheapest generic propecia 5mg india fast shipping no prescription
Перетяжка, обивка и ремонт мягкой мебели, выбирайте лучших специалистов и организации по ценам Перетяжка мягкой мебели
cordarone 200 mg tablet
order catapres 0.1mg online buy tiotropium bromide 9 mcg online buy spiriva tablets
Cheers! I appreciate this!
bc usc game bc vs vermont hockey game bc game shitcode 2023
Nicely put. Appreciate it.
bcgame casino bcgame 入金不要ボーナス bc game shitcode 2023 today
Medication information leaflet. Long-Term Effects.
can you get lyrica
All news about medicine. Get information now.
Pills prescribing information. Short-Term Effects.
promethazine rx
Everything what you want to know about medication. Read here.
Drugs information for patients. What side effects?
nolvadex otc
Best about drug. Get here.
В нынешнюю цифровую эпоху общение является жизненно важным аспектом любого бизнеса https://unews.pro/news/127130/
where can i buy abilify online
buy rocaltrol 0.25mg without prescription labetalol 100 mg pill fenofibrate 200mg over the counter
Nicely put, Appreciate it!
yale bc hockey game https://bcgamecasino.fun/ bcgame forum
buy rocaltrol 0.25 mg pills fenofibrate pill buy fenofibrate no prescription
Хотите сделать покупки еще более удобными и безопасными? купить киви карту тогда переходите на наш сайт и начинайте использовать Киви Кошельки уже сегодня!
Amazing loads of terrific information.
army vs bc game bc game mirror bc game verification
I rely on the this site mirror to access the site whenever necessary
https://jobsmart24.com/
tadalafil capsules 20mg
With thanks. Very good stuff.
bc game affiliate hash bc game bc game bonus codes
Cat Casino
На нашем сайте http://goodminecraft.ru вы сможете скачать Майнкрафт, моды, текстуры, карты и шейдеры для игры Minecraft.
goli ashwagandha
https://medium.com/@AbbieBlack79125/https-защищенный-протокол-передачи-52177e2b1878
VPS SERVER
Высокоскоростной доступ в Интернет: до 1000 Мбит/с
Скорость подключения к Интернету — еще один важный фактор для успеха вашего проекта. Наши VPS/VDS-серверы, адаптированные как под Windows, так и под Linux, обеспечивают доступ в Интернет со скоростью до 1000 Мбит/с, что гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Игорный клуб казино eldorado club начал свою работу в 2014 году. В настоящее время заведение предоставляет качественный азартный сервис тысячам гемблеров по всему миру, а также в России и странах СНГ. Сайт полностью переведен на русский язык.
Nicely put, Thanks a lot.
bc game crypto casino bc game no deposit bonus bc game telegram
https://lordserial7.com/netflix/
Regards, Ample info!
bc game shitcode 2023 bc game hash bc vs vermont hockey game
Terrific data, Cheers!
wake forest bc game harvard bc basketball game bc lions game live
https://lorddsserial.org/xfsearch/year/2023/
lisinopril generic cost
имплантация зубов стоимость https://implantaciyazubovmsk.ru/
https://atlant-cleaning.ru/
https://lordserialss.life/
somfy электрокарнизы https://prokarniz25.ru/
dexamethasone 1.5 tablet
furosemide 40 mg tablet
clonidine buy online meclizine cheap buy tiotropium bromide 9 mcg pill
Игорный клуб casino kaktuz открыл свои виртуальные двери для поклонников азартных развлечений в 2023 году. Сайт первоначально разработан для аудитории из Восточной Европы, о чем говорит перевод страниц портала на украинский, русский и польский языки.
Wonderful information. Thanks.
bc game scam bc game promo code no deposit usc bc football game
образование
ГГУ имени Ф.Скорины
buy synthroid canada
You have made your point very effectively!.
bc game limbo strategy bc fsu game bc game shitlink
https://lordserial5.pet/netflix/
You reported it very well!
bc vs vermont hockey game https://bc-game-casino.online/ bc game winning tricks
buy albuterol tablets online
Одно из самых популярных онлайн казино в России и странах СНГ vavada казино регистрация было основано в 2017 году.
where to buy diflucan over the counter
retin a without script
В 2023 году русскоязычной азартной аудитории был представлен lev casino. Это заведение имеет официальный сайт, работающий исключительно на русском языке.
One of the leading academic and scientific-research centers of the Belarus образование there are 12 Faculties at the University, 2 scientific and research institutes.
частное продвижение сайтов раскрутка сео
https://lordserial7.com/xfsearch/perevod/%D0%BA%D1%83%D0%B1%D0%B8%D0%BA%20%D0%B2%20%D0%BA%D1%83%D0%B1%D0%B5/
vavada casino – молодое казино, располагающее детально проработанной площадкой, где представлен большой выбор игровых автоматов от ведущих разработчиков.
https://merida-cleaning.ru/
rejestracja Spin City
Выпуская продукцию или услугу на рынок, компания неизменно сталкивается с подтверждением соответствия такой продукции Сертификация товаров и услуг или услуги общепринятым стандартам, законодательным, договорным или иным требованиям.
Terrific material. Kudos!
notre dame bc game 2023 bc-game bc game app download
Thanks a lot! I enjoy it!
bc game legit bc game vault pro bc game recharge
Подборка наиболее популярных федеральных законов и кодексов РФ с возможностью полнотекстового ознакомления и скачивания http://sbornik-zakonov.ru/ Общий хронологический указатель к Полному собранию законов.
Cheers. A good amount of knowledge.
cheat codes for bc game bc lions game time tonight bc game crypto
Международные пассажирские перевозки из городов Украины в города ДНР и обратно Автобус Ессен – Кропивницкий Прямые рейсы. Наше преимущество: без штрафов; без приложения ДИЯ
order minomycin sale purchase ropinirole for sale buy ropinirole without a prescription
http://www.manufacturer.vn is healthcare manufacturer of nasal rinse kit, vaginal pump gel, long time xxx solution, enhance supplement, ODM and OEM service. Manufacturer.vn can also research and development products from your ideas. We export more than 40 countries, we are one sub-company of StrongBody
Awesome write ups. Thank you!
t bc game bcgame bc game sweet codes
best pills for acne treatment prescription meds for acne teenagers order oxcarbazepine 300mg
acne medications list acne treatments for teen girls order trileptal sale
Без обязательной сертификации в Россию можно завезти только небольшую партию товара для собственных нужд Сертификация товаров и услуг И без разницы, будете ли вы продавать товар или раздавать бесплатно: если он подлежит сертификации, документы о безопасности должны быть обязательно.
10 mg prednisone daily
Cheers. Very good stuff.
bc game crash strategy bc game mirror bc lions next game
Широкопрофильная технология беспроводной связи, известная как Wi-Fi, стала неотъемлемой частью нашей повседневной жизни lan, но что такое Wi-Fi, и как можно осуществить его настройку?
Wi-Fi работает на основе радиоволн, что позволяет устройствам свободно обмениваться данными локальная сеть – это особенно удобно, поскольку не требуется множество проводов, и вы можете подключаться к интернету практически отовсюду в пределах дома или офиса.
Советы по выбору металлочерепицы
|
5 лучших марок металлочерепицы по мнению специалистов
|
Как долго прослужит металлочерепица: факторы, влияющие на срок службы
|
В чем плюсы и минусы металлочерепицы
|
Виды металлочерепицы: какой выбрать для своего дома
|
Как правильно установить металлочерепицу своими руками
|
Зачем нужна подкладочная мембрана при установке металлочерепицы
|
Простые правила ухода за металлочерепицей
|
Преимущества и недостатки различных кровельных материалов
|
Как сделать красивую кровлю из металлочерепицы: дизайнерские решения
|
Какой цвет металлочерепицы выбрать для дома: рекомендации стилистов
|
Долговечность и качество металлочерепицы с разными видами покрытия
|
Преимущества металлочерепицы перед цементно-песчаной черепицей
|
За что отвечают каждый этап производства
|
Уникальные свойства металлочерепицы: защита от влаги и шума
|
Защита от пожара: почему металлочерепица считается безопасным кровельным материалом
|
Недостатки универсальных монтажных систем
|
Как не попасть на подделку и купить качественную продукцию
|
Металлочерепица в климатических условиях: как выдерживает резкие перепады температуры и экстремальные погодные явления
|
Какие факторы влияют на выбор кровельного материала
металлочерепица для крыши цена http://www.metallocherepitsa365.ru.
proscar finasteride
https://lordseriall6.org/xfsearch/perevod/lostfilm/
science
Francisk Skorina Gomel State University
https://lordsserial.xyz/xfsearch/perevod/lostfilm/
Wow loads of terrific information!
clemson bc game tickets https://bcgamecasino.pw/ bc football bowl game 2018
Thanks a lot, An abundance of write ups.
bc game shitcode 2023 bc game promo code no deposit bc fish and game
https://rovenchanin.com/
Nicely put, Thank you.
bc game download shitcode for bc game 2023 bc game shitcodes
Amazing lots of helpful material!
bc lions game time tonight bc lions game oct 3 bc fsu game
prednisone 2 mg tablets
The most popular free online minecraft games are Duck Puzzles Minecraft talerzyki Minecraft is a game for those who like to stack blocks on top of each other and find adventures for themselves.
diflucan medicine pill
https://lordsserial.com/xfsearch/perevod/lostfilm/
canadian pharmacy 365
Drug information for patients. Drug Class.
neurontin
All news about drug. Read now.
Drugs information for patients. Short-Term Effects.
flibanserina
Everything news about drugs. Get information now.
На этой странице собран популярный рейтинг 10 лучших официальных казино вебкам
Meds information for patients. Generic Name.
paxil
Best information about medication. Get now.
This is nicely expressed! .
bc game start time bc game shitcode pc bc basketball game
furosemide uk
buy minocin 100mg sale generic minocin 100mg ropinirole price
Полный список комнатных растений с фото и названиями от А до Я земля для суккулентов состав полезные советы по уходу, пересадке, размножению комнатных растений в домашних.
can you buy valtrex over the counter in australia
Создание и продвижение сайтов в Яндекс и гугл https://www.google.rs/url?q=https://seo-vk.ru
baclofen where to buy
установка раковины воронеж
lisinopril 420
cheap cialis uk
Создайте сайт с нуля или из готового шаблона. Легкая реализация https://www.google.is/url?q=https://seo-vk.ru/ Выбирайте шаблон и просто добавляйте свой контент. Собственный дизайн.
Truly plenty of amazing facts.
bc army game 2023 bc game hash bc game bot
https://lordserialss.bet/
https://spravochnikdachnika.ru/kak-dizayn-mebeli-okazyvaet-na-nas-vliyanie/
Really all kinds of useful facts!
hash bc game bc vs vermont hockey game video game rental victoria bc
Создание и продвижение сайтов в Яндекс и гугл https://www.google.nu/url?q=https://seo-vk.ru
order valtrex online uk
https://lordseria.net/anime-serialy/
Regards! An abundance of stuff.
clemson bc game 2023 https://bcgamecasino.website/ bc-game
Привет. Заходи к нам скачать Майнкрафт бесплатно| и скачивай всё абсолютно бесплатно!
cost uroxatral 10mg strongest antacid prescription drugs that reduce stomach acid
cost uroxatral nausea medication begins with e heartburn medicine without calcium
https://ruuborka.ru/
Production of duplicates of state license plates https://www.google.com/url?q=https://guard-car.ru// production of duplicates of state license plates of all types.
https://lordserials2.net/tureckie/
brand femara 2.5 mg buy albenza 400 mg pills aripiprazole 30mg generic
accutane prescription uk
https://lordserial4.top/2022-god/
клининговая компания уборка
эксклюзивные подарки и сувениры https://suveniry-i-podarki13.ru/
generic for prinivil
work close to your home
baclofen
does zyrtec make you sleepy
Production of duplicates of state license plates https://www.google.com.tj/url?q=https://guard-car.ru/ production of duplicates of state license plates of all types.
Synergy Fat (2016) Велосипеды Горные Silverback
Создание сайта частный мастер
Haibike
Cyber (2020) Велосипеды Электровелосипеды Volteco
Siablo 105 (2017) Велосипеды Шоссейные Silverback
RainBow Basic Black Самокаты Novatrack
Royal Baby Honey Steel 16 (2020) Велосипеды Детские Royal-baby
Desna
Foxy 14 Boy (2020) Велосипеды Детские Stark
Powerwing DLX Самокаты Razor
RainBow Car Самокаты Novatrack
Nicely put. Thank you.
1win зеркало скачать онлайн 1win bet 1win как использовать бонус казино
https://telescope.ac/betrew7/estrategia-de-roleta
Editable templates for verification purposes electric bill template
https://1boosserial.site/drama/
Cheers! Loads of knowledge!
1win casino games xyz игры что делать с бонусами казино в 1win бк на спорт и промокод для 1win 1win зеркало промокод
where can i buy plavix pill
https://2boosserial.site/multserialy/
Fantastic info. Thanks a lot!
1win apk download бк 1win официальный 1win казино бонус
azithromycin online prescription
https://3boosserial.site/fantastika/
lisinopril 10 mg coupon
https://4boosserial.site/fantastika/
Nicely put. Many thanks!
1win cs https://1winoficialnyj.online/ 1win vs bad news eagles
https://5boosserial.site/komedija/
letrozole where to buy femara 2.5mg over the counter aripiprazole for sale
Superb postings. Kudos!
1win coin как получить 1win скачать официальный сайт как использовать бонусы в 1win казино
Drug information sheet. What side effects can this medication cause?
rx levitra
All about medicines. Get here.
Однажды мне понадобилось немного денег до зарплаты, и я начал искать варианты микрокредитования. На сайте wikizaim.ru я нашёл уникальное предложение займ без отказа без процентов. Это было именно то, что мне нужно было – возможность получить небольшую сумму на короткий срок без переплаты. Процесс оформления займа оказался чрезвычайно простым и понятным, а главное – абсолютно беспроцентным. Это был идеальный вариант для меня, благодаря которому я смог без труда пережить небольшой финансовый кризис.
Помню, как однажды мне срочно потребовались деньги на ремонт машины. Я решил поискать займ онлайн срочно без отказа и обнаружил отличные предложения на сайте wikizaim.ru. Всего за несколько шагов я заполнил заявку, и к моему удивлению, получил деньги на свою карту в течение часа. Это был именно тот случай, когда быстрая финансовая поддержка была мне крайне необходима.
英超賽程
Welcome to Taker Casino – your path to gambling victories Тейкер казино On our Taker site you will find an endless variety of gambling games and exciting slots.
get sleep medication online dutasteride injection for hair loss buy prescription diet pills online
best online rx for sleep top selling sleep aids best gnc weight loss supplements
protonix medication
lisinopril tablet 40 mg
synthroid no prescription pharmacy
We will officially produce a duplicate number within 5 minutes https://www.google.mv/url?q=https://guard-car.ru/ Who can make duplicate numbers?
Thank you. I appreciate this.
1win войти 1win côte d’ivoire 1win мобильное приложение скачать на андроид
Онлайн казино на реальные деньги для андроид
Онлайн казино на реальные деньги для андроид
Nicely put, Thanks a lot.
как отыграть бонус 1win приложение 1win android 1win ставки россия
buy provera without a prescription microzide canada hydrochlorothiazide 25mg oral
Ищете способ получить деньги онлайн, и не хотите сталкиваться с отказами? Наши онлайн займы без отказа на сайте wikizaim.ru – это ваш идеальный выбор!
Мы сотрудничаем с лучшими МФО, которые готовы одобрить вашу заявку даже при минимальной кредитной истории. Оформите заявку прямо сейчас, и вам не придется долго ждать ответа. Наши условия прозрачны, и процесс оформления займа максимально удобен.
Забудьте о бесконечных очередях в банках и ожиданиях. С нами вы сможете получить деньги онлайн быстро и без лишних хлопот. Наши процентные ставки конкурентоспособны, а условия займа – выгодны.
Интересуетесь займами на карту без отказа на 2023 год? Мы предоставляем актуальные предложения по займам на сайте wikizaim.ru!
Наши партнеры готовы рассмотреть вашу заявку без лишних отказов. Оформите заявку онлайн, и вы получите быстрое решение.
Забудьте о долгих ожиданиях и бумажной волоките. wikizaim.ru делает процесс получения займа на карту максимально простым и удобным.
Не упустите возможность решить свои финансовые задачи с нами. Оформите займ на карту без отказа на 2023 год прямо сейчас!
buy accutane usa
doxycycline capsules
I have been playing at this site for several years and recommend this BC to my friends
https://jobsmart24.com/
ashwagandha be
купить поведенческие факторы факторы https://nakrutka-nr.ru/
https://s1.moresliv.biz/
https://6boosserial.site/xfsearch/year/2022/
Regards, I enjoy this.
1win coin что это официальный сайт конторы 1win 1win как удалить аккаунт
инвентарь для занятий спортом в интернет-магазине
инвентарь для занятий спортом по выгодным ценам в нашем магазине
Качество и удобство в каждой детали спорттоваров в нашем ассортименте
Инвентарь для спорта для начинающих и профессиональных спортсменов в нашем магазине
Ненадежный инвентарь может стать препятствием во время тренировок – выбирайте качественные спорттовары в нашем магазине
Спорттовары только от ведущих производителей с гарантией качества
Улучшите результаты тренировок с помощью спорттоваров из нашего магазина
Разнообразие для самых популярных видов спорта в нашем магазине
Отличное качество аксессуаров по доступным ценам в нашем интернет-магазине
Простой поиск и спорттоваров в нашем магазине
Акции и скидки на спорттовары для занятий спортом только у нас
Улучшите свои навыки с помощью аксессуаров из нашего магазина
Широкий ассортимент для любого вида физической активности в нашем магазине
Проверенный инвентарь для тренировок спортом для мужчин в нашем магазине
Только самые последние модели уже ждут вас в нашем магазине
Поддерживайте форму в любых условиях с помощью инвентаря из нашего магазина
Выгодные условия покупки на спорттовары в нашем интернет-магазине – проверьте сами!
инвентаря для любого вида спорта по самым низким ценам – только в нашем магазине
Инвентарь для амбициозных спортсменов и начинающих в нашем магазине
спортивные товары http://www.sportivnyj-magazin.vn.ua/.
Вибратор с клиторальным отростком Svakom – Alice, 17 см. (чёрный). КОСТЮМ УЧИТЕЛЬНИЦА (ТОП, ЮБКА), размер XS-S, арт. 7026/XS-S. Секс куклы и интим игрушки в Кяхте.
продвижение сайтов частный мастер
Наручники и фиксаторы для ног Scandal Hog Tie.
Мастурбатор-вагина Nikki Benz MVP, 25 см – Fleshlight (телесный).
CalExotics Remote Control Lace Thong Set трусики с вибратором для клитора, OS (чёрный).
Фаллоимитатор темный Ultraskyn 20 см.
King Cock Plus 8 Triple Density – Фаллоимитатор на присоске, 24,5 см (телесный). Цепочки, елочки, тоннели. PipeDream-X-tensions Elite – Насадка утолщитель необрезанная, 17.8х4.1 см (коричневый).
prednisone 6 mg
You actually explained it really well.
1win телеграм https://1winoficialnyj.site/ 1win бк зеркало
https://7boosserial.site/xfsearch/year/2023/
https://8boosserial.site/xfsearch/year/2022/
Подскажем, как организовать детский праздник дома своими руками и украсить комнаты в статье https://steshka.ru/kak-preobrazit-obychnoe-pomeschenie-v-volshebnyy-mir-dlya-detskogo-prazdnika .
cheapest pharmacy for prescriptions
You mentioned this fantastically!
1win можно ли вывести деньги 1win вход на сайт как использовать бонусный счет казино 1win
Whoa a lot of terrific data!
1win букмекерская контора вход 1win как использовать бонус на спорт 1win brasil
Уход за растениями
Пересадка комнатных растений и цветов в Санкт-Петербурге
https://9boosserial.site/zarubezhnye-serialy/
https://10boosserial.site/anime-serialy/
ashwa
https://skachat-bk.ru/
Cheers! Very good stuff!
1win sprout 1win aviator game 1win скачать на андроид последняя версия
provera 5mg price provera pills microzide order
Нужны моды для ГТА 5, заходи к нам по ссылке: http://www.google.com.cy/url?q=http://onegta.ru и скачивай всё абсолютно бесплатно! ГТА предлагает множество модов, которые могут помочь вам изменить игру по своему вкусу. Эти моды могут быть как маленькими изменениями, такими как изменение внешнего вида персонажа, так и большими изменениями, такими как добавление новых машин, оружия и миссий.
Озеленение офисов
Уход за растениями в офисе
best prescription to stop smoking buy pain meds online no script needed stronger painkillers than co codamol
fda approved smoking cessation products buy antirheumatic pills online stronger painkillers than co codamol
Pills information leaflet. Generic Name.
fluoxetine
Some what you want to know about pills. Get information here.
accutane oral
Really lots of useful advice!
сколько ждать вывод с 1win 1win зеркало на сегодня скачать 1win история ставок
Мовибокс сериалы
Medicine prescribing information. Effects of Drug Abuse.
fosamax medication
Best about pills. Read information here.
Thank you! A good amount of advice.
реальный бонусы 1win 2023 казино промокод 1win на сегодня https://1winoficialnyj.website/ 1win букмекерская контора вход
Искал в Google магазин, где можно купить редкие виды грибов, и нашел pridary.ru. Особенно поразило наличие шляпок красного мухомора – редкость на рынке! Сайт предоставил подробную информацию о продукте, что очень облегчило выбор. Благодаря pridary.ru моя коллекция редких грибов пополнилась уникальным экземпляром. Рекомендую всем любителям нетрадиционных продуктов посетить шляпки красного мухомора на pridary.ru.
You made your point!
промокод 1win 2023 1win скачать мобильная версия скачать бесплатно приложение 1win бесплатно
Many thanks, Ample info.
как использовать бонус казино в 1win 1win промокод 2023 1win games
Medicines information for patients. Long-Term Effects.
lisinopril medication
All information about medicine. Get information now.
профессиональный уход и обслуживание зеленых растений
reputation house employee reviews
generic cyproheptadine 4mg order cyproheptadine generic order ketoconazole 200 mg generic
cetirizine brand name
safe place to buy doxycycline
synthroid 0.05
Нужны моды для ГТА 5, заходи к нам по ссылке: https://www.google.iq/url?sa=t&url=http://onegta.ru и скачивай всё абсолютно бесплатно! ГТА предлагает множество модов, которые могут помочь вам изменить игру по своему вкусу. Эти моды могут быть как маленькими изменениями, такими как изменение внешнего вида персонажа, так и большими изменениями, такими как добавление новых машин, оружия и миссий.
link alternatif hoki1881
Cheers. Lots of information!
1win промокод россия ваучеры 1win 1win зеркало казино
Drugs information sheet. Effects of Drug Abuse.
nexium
All news about drug. Read information here.
Medication prescribing information. Long-Term Effects.
rx zithromax
Actual what you want to know about meds. Read here.
Thank you! Ample posts.
1win на ios 1win регистрация 1win на андроид
https://s1.slivbox.me/
Sun52
Pills prescribing information. Cautions.
eldepryl
Some trends of drug. Read information here.
doxycycline mono
I am very happy that I chose this site for betting
https://maxbetasia88.net/
buy generic valtrex without a prescription
Medicines information. Drug Class.
get sildigra
Best what you want to know about drugs. Read information now.
Робот-пылесос может очистить любое помещение от пыли, грязи и шерсти животных без участия человека купить хороший робот пылесос
Brand SERM from Reputation House: How Customer Reviews Influence Perception of Your Brand reputation house customer reviews
Форум, здравствуйте!
Я частый играющий в популярные слоты, всем, кто не готов рисковать валютой, рекомендую потестить игру в онлайн-автомат в демке здесь –
pin up casino официальный сайт регистрация.
Это безопасный клуб, где полно игр в бесплатной режиме!!
You said it very well..
1win casino скачать 1win affiliation 1win казино зеркало
bas накрутка пф https://nakrutka-nr.ru/nakrutka-pf/
Drug information. Brand names.
abilify
Actual trends of pills. Read information now.
Drug prescribing information. Short-Term Effects.
nolvadex cost
Best trends of medication. Get information here.
antiviral drugs examples cheapest inhaled steroid inhaler feline insulin dosage chart
pills that help herpes least expensive asthma inhaler pre diabetic pills
oral periactin 4 mg fluvoxamine generic nizoral 200 mg brand
cordarone bnf
Position very well applied!.
что такое ваучер в 1win https://1winregistracija.online/ бк 1win официальный сайт
Получение сертификата ИСО 9001 – завершающий этап процедуры сертификации, сертификат системы исо 9001 без прохождения которой выдача документа априори невозможна.
We talked with the Reputation House agency about the importance of employee reviews reputation house employee reviews
Many thanks. I appreciate this.
1win poker 1win регистрация рабочее зеркало 1win
b52 club
Medicines information. Short-Term Effects.
retrovir
All news about medication. Get information here.
Fantastic advice. Regards!
вся правда об алгоритмах aviator 1win обзор 1win скачать на андроид 1win рабочее зеркало сейчас
Meds information leaflet. Short-Term Effects.
tadacip order
Best news about drugs. Read information here.
Drugs information. Drug Class.
bactrim tablet
Everything news about medicine. Read here.
buy cymbalta pills for sale provigil over the counter cheap provigil
how to get generic cialis soft tabs without insurance
Drugs prescribing information. Long-Term Effects.
propecia without rx
All what you want to know about medicament. Read information here.
купить справку из диспансера
You have made your point.
слоты казино 1win 1win бонус 5000 как использовать 1win казино официальный
Medicine information. What side effects?
effexor without insurance
All about medicines. Get now.
lucrare de licenta
Cel mai bun site pentru lucrari de licenta si locul unde poti gasii cel mai bun redactor specializat in redactare lucrare de licenta la comanda fara plagiat
Drug prescribing information. Effects of Drug Abuse.
zovirax
Actual information about pills. Read information now.
Study your degree online
Mount Kenya University (MKU) is a Chartered MKU and ISO 9001:2015 Quality Management Systems certified University committed to offering holistic education. MKU has embraced the internationalization agenda of higher education. The University, a research institution dedicated to the generation, dissemination and preservation of knowledge; with 8 regional campuses and 6 Open, Distance and E-Learning (ODEL) Centres; is one of the most culturally diverse universities operating in East Africa and beyond. The University Main campus is located in Thika town, Kenya with other Campuses in Nairobi, Parklands, Mombasa, Nakuru, Eldoret, Meru, and Kigali, Rwanda. The University has ODeL Centres located in Malindi, Kisumu, Kitale, Kakamega, Kisii and Kericho and country offices in Kampala in Uganda, Bujumbura in Burundi, Hargeisa in Somaliland and Garowe in Puntland.
MKU is a progressive, ground-breaking university that serves the needs of aspiring students and a devoted top-tier faculty who share a commitment to the promise of accessible education and the imperative of social justice and civic engagement-doing good and giving back. The University’s coupling of health sciences, liberal arts and research actualizes opportunities for personal enrichment, professional preparedness and scholarly advancement
hi! I enjoyed your article, thank you very much!
allonezaimy.ru
Мы являемся как импортерами, так и дистрибьюторами медицинских изделий, тщательно выбираем поставщиков купить оборудование для производства медицинских перчаток и формируем ассортимент только из высокотехнологичного, современного оборудования.
Amazing tips. Thank you!
1xbet официальный сайт зеркало рабочее на сегодня скачать 1xbet на android открой 1xbet
якабу
You actually stated that adequately.
“””1win приложение андроид””” 1win зеркало рабочее на сегодня прямо online 1win casino бонус
ремонт квартир под ключ бровары
Азартные игры способы вызывать восторг и зависимость. Казино на реальные деньги всегда влечет за собой последствия.
Nicely put. Kudos!
1win ставки 1win telegram как играть на бонусы казино в 1win
ремонт квартири бровари
Миссия компании заключается в сохранении здоровья и спасении жизни людей, благодаря своевременным поставкам качественного медицинское оборудование купить в иркутске и грамотно подобранного медицинского оборудования.
pola slot gacor
Thank you. Ample forum posts.
1win зеркало казино промокод 2024 1win как вывести деньги 1win скачать официальное приложение
Приближаются новогодние праздники и многие компании собираются проводить корпоративные мероприятия магазин сувениров
You reported this superbly.
1win игры с минимальной ставкой https://1winvhod.online/ 1win ставки на спорт зеркало
ремонт квартир в броварах
ремонт квартиры бровары
Gama Casino – популярное онлайн-казино, предлагающее своим клиентам богатый выбор игровых автоматов гама кази
Депозитарное хранение архивных документов. хранение архивных документов в архиве, музее, https://depozitarnoe-hranenie-msk.ru/ библиотеке на условиях, определяемых соглашением (договором).
Regards! Very good stuff!
1win aviator game 1win букмекерская контора зеркало 1win бонус 5000 как использовать
vermox online sale
В жизни часто возникают ситуации, когда срочно необходимы финансовые средства. Быстрые займы на карту, предлагаемые через wikizaim.ru, являются эффективным решением для таких случаев. Удобство и скорость оформления, а также немедленное получение денег после одобрения заявки, делают эти займы идеальным выбором для срочного решения финансовых задач.
В моменты, когда кажется, что надежда угасает, wikizaim.ru зажигает свет с возможностью получить деньги на карту без отказа срочно. Это не просто финансовая операция, это как маяк в темной ночи для тех, кто оказался в сложной ситуации. Лучшие условия, быстрое решение и уверенность в том, что вы не одиноки в своих финансовых бедах.
paxlovid for sale https://paxlovid.club/# Paxlovid buy online
ремонт квартир бровары цены
купить справку о болезни
paxlovid generic http://paxlovid.club/# paxlovid india
paxlovid india http://paxlovid.club/# buy paxlovid online
paxlovid covid https://paxlovid.club/# paxlovid cost without insurance
buy paxlovid online http://paxlovid.club/# paxlovid pill
paxlovid price http://paxlovid.club/# paxlovid pill
is diflucan over the counter blood pressure prescriptions online five worst blood pressure meds
black toenail while taking lamisil losartan side effects in women drink that lower blood pressure
I recommend this site to anyone interested in consistently making money through betting
https://tetrasky.ru/
Здесь клиенты могут подобрать наиболее подходящие варианты для прогнозирования результативности матчей 1win зеркало сайта
«АгроМаркет» – профессиональный магазин для садоводов Более 20 лет на рынке agromarket в наличии семена овощей, садовый инвентарь, удобрения.
продвижение сайтов спб https://prodvizhenie-sajtov13.ru/
hi! I enjoyed your article, thank you very much!
allonezaimy.ru
Amazing knowledge. Thanks!
g2 1win бонусы спорт 1win 1win вывод
how to buy duloxetine buy provigil without prescription modafinil 200mg cheap
cosplay porn
[url=https://esynthroid.online/]0.137 mg synthroid[/url]
You expressed it adequately!
1win app 1win партнерка 1win зеркало скачать online
To connect and use a virtual number https://maps.google.co.ve/url?q=https://didvirtualnumbers.com/en/rent-virtual-number/
В 2023 году на финансовом рынке появились новые игроки – МФО, предлагающие займы без отказов. Эти организации стремятся привлечь клиентов упрощенными процедурами и быстрым решением финансовых запросов. Эксперты отмечают, что такой подход может привести к увеличению конкуренции на рынке микрофинансирования. Однако заемщикам следует оставаться бдительными и внимательно изучать условия предоставления займов. Подробнее о новых МФО можно узнать на vc.ru
манівео
synthroid 50 mg price
Appreciate it. Ample info!
lucky jet 1win 1win бк отзывы 1win
lyrica without prescription
ремонт квартир бровари
Продажа напольных покрытий https://tarkett-parkett.ru/ с доставкой по России.
kantor bola
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99
You have made your point very clearly.!
1win csgo 1win ставки на спорт официальный сайт как потратить бонусы казино 1win
Thanks a lot, Great stuff!
1win kz вход 1win рабочее зеркало Keyword
azithromycin 250 price india
promethazine online buy stromectol 12mg usa stromectol online canada
modivo
Thanks. Quite a lot of tips.
1win удалить аккаунт 1win регистрация в один клик 1win рабочее
Jagoslot adalah situs slot gacor terlengkap, terbesar & terpercaya yang menjadi situs slot online paling gacor di indonesia. Jago slot menyediakan semua permaina slot gacor dan judi online mudah menang seperti slot online, live casino, judi bola, togel online, tembak ikan, sabung ayam, arcade dll.
eva
Medicines information leaflet. What side effects can this medication cause?
aurogra
Best trends of drugs. Read information here.
Игрушки, используемые в качестве украшений для елки или тематического декора помещений, отказное письмо на елочные украшения не являются объектом технического регулирования ни одного из действующих регламентов ТС(ЕАЭС).
Medicament information for patients. Short-Term Effects.
bactrim
All news about drug. Get information here.
cost generic co-amoxiclav without insurance
Amazing many of helpful information.
1win ставки 1win ставки приложение aviator 1win скачать
Drugs information for patients. What side effects?
cost fluoxetine
Actual about medicine. Read information now.
Thank you. Quite a lot of information!
1вин реальный 1win зеркало казино 1вин 1win букмекерская контора команда 1win
hi! thank you very much!
mediaget-pro.ru
b52
Great knowledge. Many thanks.
1win vs forze 1win фрибет за регистрацию зеркало 1 вин 1win 1
Дорогой друг! Если ты ищешь надежный займ онлайн на карту, обрати внимание на новые МФО 2023 года. На сайте vc.ru ты найдешь множество предложений. Но помни, важно не только скорость получения денег, но и условия займа. Перед тем как принять решение, внимательно изучи условия и процентные ставки, чтобы избежать неприятных сюрпризов в будущем.
Здравствуйте! В 2023 году рынок представил нам множество новых онлайн МФО. Чтобы сделать правильный выбор, рекомендую вам посетить vc.ru, где собрана актуальная информация о каждой компании. Обращайте внимание на условия займов, процентные ставки и отзывы клиентов. Тщательно взвешивайте все “за” и “против” перед тем, как принять решение о займе. Ваш финансовый благополучие должно быть приоритетом.
Many thanks. Valuable information!
1win кейсы 1win телеграм как играть в игру 1win
hi! thank you very much! Reccomend!
https://mediaget-pro.ru/
Regards! I value it.
актуальное зеркало бк 1win зеркало 1win 1win это
avodart ocd experience
Nicely put, Thanks a lot.
скачать 1win последнюю версию 1win код как пополнить счет в 1win
Покупайте высококачественный ламинат Quick-Step в нашем интернет-магазине https://quick-step-shop.ru/ . Широкий ассортимент коллекций, разнообразные оттенки и фактуры. Прочный, стильный и легкий в уходе – идеальный выбор для любого помещения. Доставка по всей стране и гарантированно надежное качество обслуживания.
Отказное письмо на свечи ручной работы отказное письмо на свечи ручной работы образец
how to treat peptic duodenitis what is peptic duodenitis how to cure uti at home fast
ulcer pain relief home remedies generic drugs for stomach ulcers boots urinary tract infection treatment
Meds information leaflet. What side effects?
buy generic zyban
Everything about medicines. Read information here.
generic tadalafil australia
accutane usa
Kudos. Awesome information.
1win рабочее зеркало lucky jet big win lucky jet winning tricks lucky jet 1win бонусный счет 1win
Amazing quite a lot of great information!
1win aplicativo как использовать бонусы в 1win 1win промокод бонус за регистрацию
promethazine canada order phenergan online cheap stromectola online
Seriously loads of amazing info!
1win cs как использовать бонусы спорт в 1win как воспользоваться бонусами 1win
Drug information sheet. Short-Term Effects.
motrin buy
Some trends of medicine. Get here.
farmacie online autorizzate elenco: avanafil spedra – migliori farmacie online 2023
I received prompt assistance from this site’s tech support when recovering my password
https://tetrasky.ru/
Исследуйте широкий выбор высококачественных ламинатных покрытий от Tarkett. Наш интернет-магазин https://tarkett54.ru/ предлагает уникальные коллекции с разнообразными оттенками, текстурами и фактурами. Ламинат Tarkett – это идеальное сочетание элегантного дизайна и надежности. Создайте стильный и уютный интерьер с ламинатом, который прослужит вам долгие годы. Легкость укладки, прочность и легкость в уходе делают ламинат Tarkett отличным решением для любого помещения. Покупайте ламинат Tarkett в нашем интернет-магазине и преобразите свой дом сегодня!
Исследуйте уникальные возможности пробкового покрытия CorkStyle. Наш интернет-магазин https://corkstyle73.ru/ предлагает широкий выбор коллекций, включая различные стили, текстуры и цветовые варианты. Пробковое покрытие CorkStyle является экологически чистым, долговечным и приятным на ощупь решением для вашего пола. Наслаждайтесь комфортом, шумоизоляцией и термоизоляцией, которые предлагает пробковое покрытие. Восхитительный дизайн и превосходное качество ждут вас в нашем магазине. Оптимизируйте ваш интерьер с CorkStyle уже сегодня!
заправка кондиционера в автомобиле москва в Лабытнанги недорого!
заправка кондиционера автомобиля киа в Гудермесе доступно!
АВТОРИЗОВАННЫЙ СЕРВИСНЫЙ ЦЕНТР
РЕМОНТ КОМПРЕССОРА В ТЕЧЕНИИ ДНЯ
ГАРАНТИЯ НА ВСЕ РАБОТЫ 1 ГОД
проверка и заправка кондиционера автомобиля в Медвежьегорске недорого!
boomer avto ru
Kudos! I like this.
скачать приложение 1win на телефон 1win скачать на телефон андроид официальный 1win букмекерская контора бонусы
Useful knowledge. Many thanks.
1win рабочее зеркало 1win зеркало скачать на андроид 1win casini
viagra consegna in 24 ore pagamento alla consegna: viagra senza ricetta – gel per erezione in farmacia
b52 club
to be popular on youtube you need to buy youtube views on the best site 1kviews.com
Наша компания дает вам возможность купить необходимое оборудование в лизинг от иностранных и отечественных производителей, как новое, так и б/у оформить оборудование в лизинг
migliori farmacie online 2023: farmacia online – acquisto farmaci con ricetta
Really tons of good facts.
1win бесплатная ставка 1win promo 1win скачать мобильный телефон
how to get accutane australia
brand prednisone 40mg buy amoxicillin generic amoxicillin 250mg drug
acquistare farmaci senza ricetta: farmacia online migliore – farmacia online miglior prezzo
МК Лизинг входит в состав международного холдинга Mikro Kapital Group, компании которого оказывают помощь малому и среднему бизнесу в 14 странах мира купить технику в лизинг
как получить промокод на мелбет
Получайте бонус в https://kentcasino1.com до 395% на депозит и 200 фриспинов.
alternativa al viagra senza ricetta in farmacia: alternativa al viagra senza ricetta in farmacia – le migliori pillole per l’erezione
Really a good deal of good data!
1win зеркало скачать онлайн 1win мобильная версия зеркало бонус 1win
gabapentin 1000
b52
Tiêu đề: “B52 Club – Trải nghiệm Game Đánh Bài Trực Tuyến Tuyệt Vời”
B52 Club là một cổng game phổ biến trong cộng đồng trực tuyến, đưa người chơi vào thế giới hấp dẫn với nhiều yếu tố quan trọng đã giúp trò chơi trở nên nổi tiếng và thu hút đông đảo người tham gia.
1. Bảo mật và An toàn
B52 Club đặt sự bảo mật và an toàn lên hàng đầu. Trang web đảm bảo bảo vệ thông tin người dùng, tiền tệ và dữ liệu cá nhân bằng cách sử dụng biện pháp bảo mật mạnh mẽ. Chứng chỉ SSL đảm bảo việc mã hóa thông tin, cùng với việc được cấp phép bởi các tổ chức uy tín, tạo nên một môi trường chơi game đáng tin cậy.
2. Đa dạng về Trò chơi
B52 Play nổi tiếng với sự đa dạng trong danh mục trò chơi. Người chơi có thể thưởng thức nhiều trò chơi đánh bài phổ biến như baccarat, blackjack, poker, và nhiều trò chơi đánh bài cá nhân khác. Điều này tạo ra sự đa dạng và hứng thú cho mọi người chơi.
3. Hỗ trợ Khách hàng Chuyên Nghiệp
B52 Club tự hào với đội ngũ hỗ trợ khách hàng chuyên nghiệp, tận tâm và hiệu quả. Người chơi có thể liên hệ thông qua các kênh như chat trực tuyến, email, điện thoại, hoặc mạng xã hội. Vấn đề kỹ thuật, tài khoản hay bất kỳ thắc mắc nào đều được giải quyết nhanh chóng.
4. Phương Thức Thanh Toán An Toàn
B52 Club cung cấp nhiều phương thức thanh toán để đảm bảo người chơi có thể dễ dàng nạp và rút tiền một cách an toàn và thuận tiện. Quy trình thanh toán được thiết kế để mang lại trải nghiệm đơn giản và hiệu quả cho người chơi.
5. Chính Sách Thưởng và Ưu Đãi Hấp Dẫn
Khi đánh giá một cổng game B52, chính sách thưởng và ưu đãi luôn được chú ý. B52 Club không chỉ mang đến những chính sách thưởng hấp dẫn mà còn cam kết đối xử công bằng và minh bạch đối với người chơi. Điều này giúp thu hút và giữ chân người chơi trên thương trường game đánh bài trực tuyến.
Hướng Dẫn Tải và Cài Đặt
Để tham gia vào B52 Club, người chơi có thể tải file APK cho hệ điều hành Android hoặc iOS theo hướng dẫn chi tiết trên trang web. Quy trình đơn giản và thuận tiện giúp người chơi nhanh chóng trải nghiệm trò chơi.
Với những ưu điểm vượt trội như vậy, B52 Club không chỉ là nơi giải trí tuyệt vời mà còn là điểm đến lý tưởng cho những người yêu thích thách thức và may mắn.
https://vk.com/uslugi-223156582?screen=group&w=product-223156582_8515695%2Fquery
Es scheint verlockend, alle Kohlenhydrate zu reduzieren, während Sie versuchen, mit Reduslim Gewicht zu verlieren. Die Verwendung des Produkts während der Schwangerschaft wird NICHT empfohlen, da der weibliche Körper einer doppelten Belastung ausgesetzt ist. Es gibt bekanntermaßen bereits nach einer Woche sichtbare Ergebnisse. Es verzichtet auf das Medikament in form von Tabletten, bedeckt mit einer menthol-gefärbten Membran. Vorzugsweise mit einer Mahlzeit und 1 Glas Wasser. Es stellte sich heraus, dass musste unbedingt trinken pro Tag nicht weniger als zwei Liter Wasser. Dort werden die Tropfen bis zu eine Minute belassen, bevor sie mit etwas Wasser runtergespült werden. Nebenwirkungen sind bis jetzt nicht bekannt. Die Ursachen können zahlreich sein und reichen von Schilddrüsenungleichgewichten bis hin zu falschen Diäten, die die Eliminierung bestimmter Lebensmittel wie gute Fette, Proteine oder Kohlenhydrate beinhalten. Individuelle Reaktionen der Mutter oder des Babys können auch durch die einzelnen Bestandteile verursacht werden. Bei individueller Unverträglichkeit der Bestandteile kann es zu allergischen Reaktionen, Verdauungsstörungen (abführende Wirkung), Durst und Übelkeit kommen. Für Garcinia Cambogia Extrakt beispielsweise gibt es Berichte aus Tests und Studien, die auf gelegentliche, leichte Unverträglichkeit bei Menschen hindeutet, die auf Gewichtsverlust aus sind.
Dennoch gibt es auch bei Garcinia Cambogia gemischte Erfahrungen, und die Wirksamkeit kann von Person zu Person variieren. Wir hatten das Ziel, die tatsächliche Wirksamkeit der Diätkapseln unter realen Bedingungen zu testen. Was versteht man unter Appetitzüglern? Die meisten Menschen wünschen sich ein Programm zur Gewichtsreduzierung, aber es ist gelegentlich schwierig, die beste Mischung aus Gewichtsreduzierungsplan und Training zu finden, die für einen selbst erfolgreich ist. Probieren Sie sie alle aus, um einen zu finden, der für Sie funktioniert. Reduslim ist eine oral einzunehmende Kapsel. In diesem Zusammenhang sticht REDUSLIM hervor, ein dreiphasiges Mittel, das nicht nur auf herkömmliche Weise auf die Gewichtsabnahme abzielt, sondern auch die individuellen Biorhythmen des Körpers berücksichtigt. Die Reduslim Gewichtsabnahme lässt sich für diejenigen, die dazu neigen, auch mathematisch ermitteln. Reduslim ist ein Präparat zum abnehmen, dessen Rezept wurde gedacht gerade in Bezug auf die Bedürfnisse der Menschen, die versuchen zu verlieren übergewicht. Versuchen Sie die Verwendung von Vollkornnudeln. Versuchen Sie, Nudeln aus Vollkorn zu essen. Durch die Linderung des Hungergefühls wird der Patient von übermäßigem Essen befreit. Ernährungswissenschaftlern zufolge ist es für eine gesunde Ernährung viel wichtiger, diszipliniert zu essen als jeden Tag ins Fitnessstudio zu gehen. Daher wird das Medikament einmal am Tag eingenommen.
Negative Bewertungen gibt es so gut wie gar nicht, und sie werden von Personen abgegeben, die das Medikament falsch angewendet haben. Daher sind die Kapseln auch für jede Person ohne Unverträglichkeiten gut verträglich. Bei 99% wurde die Beschleunigung des Stoffwechsels bereits am 3. Tag der Einnahme der Kapseln. Tag 15 Nach zwei Wochen der Anwendung wurde die erste Kontrolle durchgeführt. Es ist auch der erste Schritt zur Fettleibigkeit, und beide Staaten unterscheiden sich in Ihren BMI-Indikator, der höher ist, wenn übergewicht festgestellt wird. Reduslim ist eine Pille für Gewichtsverlust, die erreichen können, das erste Ergebnis in 1-2 Monaten. Ich habe versucht, meine Ernährung umzustellen und bin zu dem Ergebnis gekommen, dass Reduslim eine hervorragende Unterstützung war. Das Ergebnis ist natürlich Reduslim oder minus 13 kg, ohne jede Anstrengung. Reduslim ist ein Nahrungsergänzungsmittel. Die drei beliebten Preis-Vergleich websites haben auch nicht Reduslim. Es ist jedoch wichtig zu beachten, dass nicht alle Produkte gleich wirksam sind und dass nicht alle natürlichen Inhaltsstoffe auch tatsächlich eine positive Wirkung auf den Körper haben. Neue Produkte. Rezeptpflichtige Appetitzügler – Produkte in der Übersicht Power Cal 1000 Wo kann ich Appetitzügler oder Diätpillen kaufen? Die Studie umfasste eine beeindruckende Anzahl von über 1000 Teilnehmern, die mit unterschiedlichen Grade von Übergewicht und Fettleibigkeit kämpften.
Übergewicht ist ein Zustand, in dem der menschliche Körper angesammelt hat zu viel Fett. Je schneller der Körper in den Zustand der Ketose gebracht werden kann, umso schneller kann der Nutzer mit dem Abnehmen anfangen. Auch wenn Sie durch Appetitzügler Schmerzen verspüren oder der Appetitzügler Schlaf und Ruhe beeinflusst, sollte es dennoch nicht als Medikament angesehen werden. Um Gewicht mit Reduslim zu verlieren, sollten Sie andere Fortbewegungsmittel als ein Auto wählen. Wenn Sie den Verzehr von Schweinefleisch in Ihrem Reduslim Diätplan vermeiden, werden Sie Gewicht verlieren. Das Produkt muss vorschriftsmäßig verwendet werden. Auf verschiedenen thematischen Foren, die Menschen oft sprechen Sie über dieses Produkt wirklich loben und empfehlen. Da Reduslim ein Medikament zur Gewichtsabnahme ist, wird es nicht für Menschen mit krankhaftem Gewichtsverlust empfohlen: Anorexie, Bulimie, Kachexie, Essstörungen. Was sollten Sie tun, wenn Ihre Bemühungen zur Gewichtsabnahme nicht funktionieren? 17 Fake-Gesundheitsportale, denen Sie nicht vertrauen sollten Das Diätpräparat „Figur Kapseln“ soll die Gewichtsabnahme effektiv erleichtern.
Look into my web page; https://urduwiki.in/index.php/Wo_Bekomme_Ich_Reduslim_Zu_Kaufen
This is nicely put! !
1win проверка авто 1win зеркало сайта онлайн авиатор 1win
farmacie on line spedizione gratuita: kamagra oral jelly – farmacia online migliore
https://vk.com/albums-223156644?z=photo-223156644_456239045%2Fphotos-223156644
You said it adequately..
1win букмекерская скачать на андроид скачать 1win на айфон как играть в игру 1win
farmacia online miglior prezzo: farmacia online spedizione gratuita – farmaci senza ricetta elenco
farmacia online più conveniente: Cialis senza ricetta – acquisto farmaci con ricetta
Nicely put, Thank you.
как использовать бонус 1win 1win промокод 2024 “””1win pthrfkj”””
Position well used!!
как активировать ваучер на 1win lucky jet 1win телефон приложение 1win как получить бонус
промокод для melbet
migliori farmacie online 2023: dove acquistare cialis online sicuro – farmacia online senza ricetta
Готовы к большим выигрышам? kent casino официальный сайт , где вас ждут лучшие слоты и настольные игры. Присоединяйтесь сейчас!,
Эксклюзивный промокод от БК Мелбет: «LEGALBET» — вводите при регистрации, чтобы увеличить сумму первого депозита в Melbet промокод на melbet на сегодня
ISO 45001:2018 — это новый международный стандарт по охране труда, введенный вместо OHSAS 18001:2007. Соответственно, в России тоже появился новый ГОСТ по охране труда — стандарт ГОСТ Р ИСО 45001-2020, идентичный международному сертификат исо 45001-2020 Он утвержден приказом Росстандарта № 581-ст от 28.08.2020 и вступил в силу с 01.04.2021. Сертификат соответствия системе менеджмента безопасности труда и охраны здоровья удостоверяет, что система менеджмента, принятая в организации, отвечает требованиям стандарта ГОСТ Р ИСО 45001-2020.
baclofen 025
can you get contraceptive pill from pharmacy quick relief for prostate pain semen enhancer reviews
virtual birth control prescription best supplement for semen volume treatment for early ejaculation problems
farmacia online più conveniente: Tadalafil generico – farmacie online affidabili
стоимость заправки кондиционера авто в Кировграде недорого!
ремонт компрессора автокондиционера в Тюкалинске недорого!
АВТОРИЗОВАННЫЙ СЕРВИСНЫЙ ЦЕНТР
РЕМОНТ КОМПРЕССОРА В ТЕЧЕНИИ ДНЯ
ГАРАНТИЯ НА ВСЕ РАБОТЫ 1 ГОД
стоимость заправки кондиционера авто в Белоярском дешево!
kniga avto ru
inderal la 60mg
farmacia online miglior prezzo: farmacia online più conveniente – farmacia online
Получение сертификата ИСО 9001 – завершающий этап процедуры сертификации, без прохождения которой выдача документа априори невозможна. Преимуществом будет, если орган, выполняющий проверку, имеет соответствующую аккредитацию Как получить сертификат ISO 9001 Сертификат соответствия СМК требованиям ИСО 9001 – документ, который выдается по результатам экспертной проверки и подтверждает, что система менеджмента качества (СМК) организации соответствует международному стандарту ISO 9001 «Системы менеджмента качества. Требования» либо его национальному аналогу ГОСТ Р ИСО 9001 и своевременно совершенствуется.
A printable calendar is great for keeping the family organized — april 2024 printable calendar it’s customizable, encourages communication, and helps with planning, all without needing to rely too much on technology.
Medicine information for patients. Generic Name.
fluoxetine
Best trends of drug. Get information here.
farmacia online migliore: farmacia online più conveniente – farmacia online migliore
https://www.kazakistan.kz/wp-content/pags/1xbet_promokod_na_segodnya_besplatno.html
farmacie online affidabili: kamagra gold – farmacia online migliore
prednisone 40mg price order accutane 40mg for sale order amoxicillin 250mg
Автомобильный журнал
http://46.lv/calendar/pages/?1xbet_promokod___aktualnuy_segodnya.html
металлическая офисная мебель https://ofisstil11.ru/
comprare farmaci online all’estero: kamagra gold – farmacie on line spedizione gratuita
https://centralasia.media/search/?place=canews-right&query=%D8%A7%D9%84%D9%85%D9%88%D9%82%D8%B9+%D8%8C+%D8%B9%D9%86%D9%88%D8%A7%D9%86+%D8%A7%D9%84%D8%B9%D9%85%D9%84+288365.com+%D9%86%D8%B3%D8%AE%D8%A9+%D8%A3%D8%A8%D9%84+%D8%AF%D8%A7%D8%A6%D8%B1%D8%A9+%D8%A7%D9%84%D8%B1%D9%82%D8%A7%D8%A8%D8%A9+%D8%A7%D9%84%D8%AF%D8%A7%D8%AE%D9%84%D9%8A%D8%A9+%28%D8%A3%D8%B3%D9%87%D9%84+%D9%84%D9%84%D8%B9%D8%AB%D9%88%D8%B1+%D8%B9%D9%84%D9%89+288365+%D9%83%D8%B1%D8%A9+%D8%A7%D9%84%D9%82%D8%AF%D9%85+%D8%8C+%D9%88%D8%AC%D9%85%D9%8A%D8%B9+%D8%A7%D9%84%D8%A3%D9%84%D8%B9%D8%A7%D8%A8+%D8%A7%D9%84%D8%B1%D9%8A%D8%A7%D8%B6%D9%8A%D8%A9%29+%D9%86%D8%B3%D8%AE%D8%A9+%D8%A7%D9%84%D8%B1%D9%88%D8%A8%D9%88%D8%AA+288365.com+%5B%D9%86%D8%B3%D8%AE+%D8%B1%D8%A7%D8%A8%D8%B7%3A+guest.link%2FCbv+%5D+%D8%A7%D9%84%D8%AD%D8%A7%D9%84%D9%8A+%D8%8C+%D8%B1%D8%A7%D8%A8%D8%B7+%D8%A8%D8%AF%D9%8A%D9%84+%5B%D9%86%D8%B3%D8%AE+%D8%B1%D8%A7%D8%A8%D8%B7%3A+guest.link%2FCbv+%5D
comprare farmaci online all’estero: kamagra gel – farmacie on line spedizione gratuita
baclofen 25 mg tablets
Казино Гама представлен огромный выбор игр. Здесь вы найдете все самые популярные игры, начиная от классических слотов до увлекательных настольных игр и видеопокера. Gama Casino сотрудничает с ведущими разработчиками игрового софта, поэтому качество игр и графика на высшем уровне.
Наши квалифицированные специалисты окажут вам профессиональную поддержку на всех этапах получения сертификата ISO 9001 https://certificatiso9001.blogspot.com/ Они оперативно и качественно исполнят каждое сертификационное мероприятие.
farmacie online autorizzate elenco: Avanafil farmaco – farmacie online autorizzate elenco
При регистрации на сайте 1xBet вы можете воспользоваться только одним промокодом, который является действительным. Используя этот промокод, вы получите бонус до 32500 рублей. 1хбет промокод при регистрации бонус на депозит Важно отметить, что все остальные промокоды не являются действительными и не предоставляют такого же бонуса.
In recent years, the landscape of digital entertainment and online gaming has expanded, with ‘nhà cái’ (betting houses or bookmakers) becoming a significant part. Among these, ‘nhà cái RG’ has emerged as a notable player. It’s essential to understand what these entities are and how they operate in the modern digital world.
A ‘nhà cái’ essentially refers to an organization or an online platform that offers betting services. These can range from sports betting to other forms of wagering. The growth of internet connectivity and mobile technology has made these services more accessible than ever before.
Among the myriad of options, ‘nhà cái RG’ has been mentioned frequently. It appears to be one of the numerous online betting platforms. The ‘RG’ could be an abbreviation or a part of the brand’s name. As with any online betting platform, it’s crucial for users to understand the terms, conditions, and the legalities involved in their country or region.
The phrase ‘RG nhà cái’ could be interpreted as emphasizing the specific brand ‘RG’ within the broader category of bookmakers. This kind of focus suggests a discussion or analysis specific to that brand, possibly about its services, user experience, or its standing in the market.
Finally, ‘Nhà cái Uy tín’ is a term that people often look for. ‘Uy tín’ translates to ‘reputable’ or ‘trustworthy.’ In the context of online betting, it’s a crucial aspect. Users typically seek platforms that are reliable, have transparent operations, and offer fair play. Trustworthiness also encompasses aspects like customer service, the security of transactions, and the protection of user data.
In conclusion, understanding the dynamics of ‘nhà cái,’ such as ‘nhà cái RG,’ and the importance of ‘Uy tín’ is vital for anyone interested in or participating in online betting. It’s a world that offers entertainment and opportunities but also requires a high level of awareness and responsibility.
A promotional code is a code offered by retailers to customers who can use it to receive a discounted price when buying products online https://rondasomontano.com/codigo-promocional-1xbet-bono-de-registro/
viagra online spedizione gratuita: viagra generico prezzo più basso – viagra 50 mg prezzo in farmacia
albuterol online canada
azithromycin 250mg over the counter azithromycin without prescription order gabapentin generic
list of 1xbet promo code
Ремонт телефонов, ноутбуков, планшетов и другой техники https://remont-telefonov-moskva.ru/
farmacia online migliore: kamagra oral jelly consegna 24 ore – top farmacia online
Подготовка к качественной фотосессии товаров включает несколько ключевых аспектов. Во-первых, важно обеспечить, чтобы снимаемые предметы были безупречными и чистыми, без визуальных недостатков. Подходящий фон поможет выделить лучшие характеристики товара, не отвлекая внимание от него. Тесное взаимодействие с фотографом для обсуждения идей, целевой аудитории и ключевых деталей товара также крайне важно. Профессиональные фотографы постоянно следят за трендами в фотографии и используют разнообразные приемы, включая игру света и тени, а также интерактивные элементы, чтобы не только сделать качественные снимки, но и создать привлекательное изображение товара для покупателей. Обращение к опытному специалисту гарантирует получение высококачественных фотографий, способствующих продвижению товара и увеличению продаж.
Also visit my webpage: https://zoellner-lab.sph.umich.edu/index.php/Bigpicture.ru
Подготовка к качественной фотосессии товаров включает несколько ключевых аспектов. Во-первых, важно обеспечить, чтобы снимаемые предметы были безупречными и чистыми, без визуальных недостатков. Подходящий фон поможет выделить лучшие характеристики товара, не отвлекая внимание от него. Тесное взаимодействие с фотографом для обсуждения идей, целевой аудитории и ключевых деталей товара также крайне важно. Профессиональные фотографы постоянно следят за трендами в фотографии и используют разнообразные приемы, включая игру света и тени, а также интерактивные элементы, чтобы не только сделать качественные снимки, но и создать привлекательное изображение товара для покупателей. Обращение к опытному специалисту гарантирует получение высококачественных фотографий, способствующих продвижению товара и увеличению продаж.
Feel free to visit my web-site – https://www.alonegocio.net.br/author/grover63a99/
promo codes 1xbet
Подготовка к качественной фотосессии товаров включает несколько ключевых аспектов. Во-первых, важно обеспечить, чтобы снимаемые предметы были безупречными и чистыми, без визуальных недостатков. Подходящий фон поможет выделить лучшие характеристики товара, не отвлекая внимание от него. Тесное взаимодействие с фотографом для обсуждения идей, целевой аудитории и ключевых деталей товара также крайне важно. Профессиональные фотографы постоянно следят за трендами в фотографии и используют разнообразные приемы, включая игру света и тени, а также интерактивные элементы, чтобы не только сделать качественные снимки, но и создать привлекательное изображение товара для покупателей. Обращение к опытному специалисту гарантирует получение высококачественных фотографий, способствующих продвижению товара и увеличению продаж.
Look into my site: https://apigateway.wmf.labs.hallowelt.biz/wiki/Shounen.ru
Подготовка к качественной фотосессии товаров включает несколько ключевых аспектов. Во-первых, важно обеспечить, чтобы снимаемые предметы были безупречными и чистыми, без визуальных недостатков. Подходящий фон поможет выделить лучшие характеристики товара, не отвлекая внимание от него. Тесное взаимодействие с фотографом для обсуждения идей, целевой аудитории и ключевых деталей товара также крайне важно. Профессиональные фотографы постоянно следят за трендами в фотографии и используют разнообразные приемы, включая игру света и тени, а также интерактивные элементы, чтобы не только сделать качественные снимки, но и создать привлекательное изображение товара для покупателей. Обращение к опытному специалисту гарантирует получение высококачественных фотографий, способствующих продвижению товара и увеличению продаж.
Here is my web-site – https://wikidot.win/wiki/Shounen.ru
Регистрация с использованием промокода 1xBet позволяет получить бонус до 32500 рублей, что эквивалентно сумме пополнения до 130 долларов. Этот бонус можно использовать для различных ставок и игр на сайте 1xBet.
промокод на бесплатную ставку 1хбет
Подготовка к качественной фотосессии товаров включает несколько ключевых аспектов. Во-первых, важно обеспечить, чтобы снимаемые предметы были безупречными и чистыми, без визуальных недостатков. Подходящий фон поможет выделить лучшие характеристики товара, не отвлекая внимание от него. Тесное взаимодействие с фотографом для обсуждения идей, целевой аудитории и ключевых деталей товара также крайне важно. Профессиональные фотографы постоянно следят за трендами в фотографии и используют разнообразные приемы, включая игру света и тени, а также интерактивные элементы, чтобы не только сделать качественные снимки, но и создать привлекательное изображение товара для покупателей. Обращение к опытному специалисту гарантирует получение высококачественных фотографий, способствующих продвижению товара и увеличению продаж.
Here is my site; http://www.gedankengut.one/index.php?title=Shounen.ru
Подготовка к качественной фотосессии товаров включает несколько ключевых аспектов. Во-первых, важно обеспечить, чтобы снимаемые предметы были безупречными и чистыми, без визуальных недостатков. Подходящий фон поможет выделить лучшие характеристики товара, не отвлекая внимание от него. Тесное взаимодействие с фотографом для обсуждения идей, целевой аудитории и ключевых деталей товара также крайне важно. Профессиональные фотографы постоянно следят за трендами в фотографии и используют разнообразные приемы, включая игру света и тени, а также интерактивные элементы, чтобы не только сделать качественные снимки, но и создать привлекательное изображение товара для покупателей. Обращение к опытному специалисту гарантирует получение высококачественных фотографий, способствующих продвижению товара и увеличению продаж.
Have a look at my site :: https://higheredrevolution.org/index.php/User:SherleneBlubaugh
gel per erezione in farmacia: viagra generico sandoz – gel per erezione in farmacia
Although Mostbet operates under an official international license, the official website of the bookmaker is sometimes blocked by Azerbaijani Internet providers https://telegra.ph/mostbet-az%C9%99rbaycan-11-28
VPS SERVER
Высокоскоростной доступ в Интернет: до 1000 Мбит/с
Скорость подключения к Интернету — еще один важный фактор для успеха вашего проекта. Наши VPS/VDS-серверы, адаптированные как под Windows, так и под Linux, обеспечивают доступ в Интернет со скоростью до 1000 Мбит/с, что гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
acquisto farmaci con ricetta: Tadalafil prezzo – farmacie online affidabili
https://s1.moresliv.biz/
farmacia online senza ricetta: farmacia online miglior prezzo – farmacia online senza ricetta
https://64flowers.ru/
farmacia online migliore: Farmacie a milano che vendono cialis senza ricetta – acquisto farmaci con ricetta
Código promocional 1xBet: ¡obtén un bono de bienvenida de hasta $130! CГіdigo Promocional 1xBet Cuba El operador duplicará tu primer depósito hasta esa cantidad
Центр иностранных языков YES приглашает детей от 3-х лет, подростков и взрослых на онлайн-курсы английского языка английский с нуля онлайн курсы Обучение в нашей онлайн-школе проводится по эффективной коммуникативной методике индивидуально.
sildalist hartford
1. C88 Fun – Gateway to Endless Entertainment!
More than just a gaming platform, C88 Fun is an adventure awaiting discovery. With its user-friendly interface and a diverse array of games, C88 Fun caters to all preferences. From timeless classics to cutting-edge releases, C88 Fun ensures every player finds their perfect gaming haven.
2. JILI & Evo 100% Welcome Bonus – A Hearty Welcome for New Players!
Embark on your gaming journey with a warm embrace from C88. New members are greeted with a 100% Welcome Bonus from JILI & Evo, doubling the excitement from the outset. This bonus serves as an excellent boost for players to explore the wide array of games available on the platform.
3. C88 First Deposit Get 2X Bonus – Double the Excitement!
C88 believes in rewarding players generously. With the “First Deposit Get 2X Bonus” offer, players can relish double the fun on their initial deposit. This promotion enhances the gaming experience, providing more opportunities to win big across various games.
4. 20 Spin Times = Get Big Bonus (8,888P) – Spin Your Way to Greatness!
Spin your way to substantial bonuses with the “20 Spin Times” promotion. Accumulate spins and stand a chance to win an impressive bonus of 8,888P. This promotion adds an extra layer of excitement to the gameplay, combining luck and strategy for maximum enjoyment.
5. Daily Check-in = Turnover 5X?! – Daily Rewards Await!
Consistency is key at C88. By merely logging in daily, players not only savor the thrill of gaming but also stand a chance to multiply their turnovers by 5X. Daily check-ins bring additional perks, making every day a rewarding experience for dedicated players.
6. 7 Day Deposit 300 = Get 1,500P – Unlock Deposit Rewards!
For those eager to seize opportunities, the “7 Day Deposit” promotion is a game-changer. Deposit 300 and receive a generous reward of 1,500P. This promotion encourages players to explore the platform further and maximize their gaming potential.
7. Invite 100 Users = Get 10,000 PESO – Share the Excitement!
C88 believes in the power of community. Invite friends and fellow gamers to join the excitement, and for every 100 users, receive an incredible reward of 10,000 PESO. Sharing the joy of gaming has never been more rewarding.
8. C88 New Member Get 100% First Deposit Bonus – Exclusive Benefits!
New members are in for a treat with an exclusive 100% First Deposit Bonus. C88 ensures that everyone starts their gaming journey with a boost, setting the stage for an exhilarating experience filled with opportunities to win.
9. All Pass Get C88 Extra Big Bonus 1000 PESO – Unlock Unlimited Rewards!
For avid players exploring every nook and cranny of C88, the “All Pass Get C88 Extra Big Bonus” offers an additional 1000 PESO. This promotion rewards those who embrace the full spectrum of games and features available on the platform.
Curious? Visit C88 now and unlock a world of gaming like never before. Don’t miss out on the excitement, bonuses, and wins that await you at C88. Join the community today and let the games begin! #c88 #c88login #c88bet #c88bonus #c88win
farmacia online più conveniente: farmacia online miglior prezzo – farmacia online migliore
all med pharmacy
Лингвистический центр YES предлагает вам открыть для себя новые языки или повысить свой уровень владения ими курс английского языка разговорный Мы открываем перспективы для учебы и работы за границей.
comprare farmaci online all’estero: avanafil spedra – comprare farmaci online con ricetta
best daily heartburn medication brand name anti nausea medication pills for fart scent
is nexium a h2 blocker anti gas pills for bloating causes of extremely foul flatulence
????
acquisto farmaci con ricetta: farmacia online più conveniente – farmacia online
lisinopril 5 mg prices
ЧИСТКА И РЕМОНТ КОЛОДЦЕВ ЗА 1 ДЕНЬ С ВЫЕЗДОМ от 4000 руб.
kolodec-vologda.ru Частный мастер по чистке колодцев в Московской области
ремонт колодцев канализации
Выезжаю по всем районам Московской области
Выезд в пределах 150 км от МКАД. Привожу все необходимое оборудование с собой.
Профессиональная чистка и ремонт колодцев
Выравнивание колец колодца
1x slots
https://www.fest.md/en/search?search=Veb+sayt%2C+i%C5%9F+%C3%BCnvan%C4%B1+288365.com+Apple+iOS+versiyas%C4%B1+%28tapmaq+daha+asand%C4%B1r+288365+futbol%2C+b%C3%BCt%C3%BCn+idman+n%C3%B6vl%C9%99ri%29+Android+versiyas%C4%B1+288365.com+%5BURL+kopyalay%C4%B1n%3A+guest.link%2FCbv+%5D+cari%2C+alternativ+link+%5BURL+kopyalay%C4%B1n%3A+guest.link%2FCbv+%5D
Торговать на маркетплейсах без документов соответствия можно только продукцией, не входящей в перечни ТР ЕЭАС, Постановления № 982, Решения КТС № 299 https://www.sostav.ru/blogs/30357/42484 отдельный нормативный акт по товарам, не подлежащим обязательной оценке, не разработан. Подтвердить факт их отсутствия в законах можно с помощью отказного письма.
comprare farmaci online all’estero: avanafil – farmacia online migliore
1x slots
farmacie on line spedizione gratuita: comprare avanafil senza ricetta – farmacia online
Meds information for patients. Long-Term Effects.
cordarone tablet
Everything about medication. Read information here.
Ремонт гитар в Гомеле настройка гитар гомель с гарантией качества работы.
top farmacia online: kamagra gel prezzo – farmacie online affidabili
Medicines information for patients. Short-Term Effects.
cost tadacip
All what you want to know about medicine. Read now.
azithromycin price brand gabapentin 100mg generic neurontin 600mg
migliori farmacie online 2023: kamagra – comprare farmaci online con ricetta
Drug prescribing information. Brand names.
effexor online
Actual what you want to know about meds. Get information now.
http://kamagraes.site/# farmacia barata
prednisone steroid for sale without a prescription
https://farmacia.best/# farmacia online 24 horas
O Cassino sol cassino esta ganhando popularidade e se esforca para fornecer apenas servicos de alta qualidade.
https://yuhot.ru/
термопанели для дома https://klinkerprom13.ru/
https://sildenafilo.store/# comprar viagra en españa
atarax 10mg price
http://tadalafilo.pro/# farmacia online madrid
люстры купить в интернет магазине https://lu18.ru/
Medicine information leaflet. Brand names.
viagra
Best trends of medicine. Get information here.
http://vardenafilo.icu/# farmacias baratas online envÃo gratis
suhagra 25 mg tablet
gay orgy porn
https://kamagraes.site/# farmacias online seguras en españa
В современном мире, где мобильные устройства и социальные сети стали неотъемлемой частью нашей жизни, все больше людей интересуются вопросом о том, читаем удаленные сообщения с кем их близкие, партнеры или друзья переписываются.
retin a order
http://farmacia.best/# farmacia online internacional
косметика с феромонами
generic toradol
http://vardenafilo.icu/# farmacia online barata
prozac india price
https://vardenafilo.icu/# farmacia barata
https://search.danawa.com/dsearch.php?query=%D8%A7%D9%84%D9%85%D9%88%D9%82%D8%B9+%D8%8C+%D8%B9%D9%86%D9%88%D8%A7%D9%86+%D8%A7%D9%84%D8%B9%D9%85%D9%84+288365.com+%D9%86%D8%B3%D8%AE%D8%A9+%D8%A3%D8%A8%D9%84+%D8%AF%D8%A7%D8%A6%D8%B1%D8%A9+%D8%A7%D9%84%D8%B1%D9%82%D8%A7%D8%A8%D8%A9+%D8%A7%D9%84%D8%AF%D8%A7%D8%AE%D9%84%D9%8A%D8%A9+%28%D8%A3%D8%B3%D9%87%D9%84+%D9%84%D9%84%D8%B9%D8%AB%D9%88%D8%B1+%D8%B9%D9%84%D9%89+288365+%D9%83%D8%B1%D8%A9+%D8%A7%D9%84%D9%82%D8%AF%D9%85+%D8%8C+%D9%88%D8%AC%D9%85%D9%8A%D8%B9+%D8%A7%D9%84%D8%A3%D9%84%D8%B9%D8%A7%D8%A8+%D8%A7%D9%84%D8%B1%D9%8A%D8%A7%D8%B6%D9%8A%D8%A9%29+%D9%86%D8%B3%D8%AE%D8%A9+%D8%A7%D9%84%D8%B1%D9%88%D8%A8%D9%88%D8%AA+288365.com+%5B%D9%86%D8%B3%D8%AE+%D8%B1%D8%A7%D8%A8%D8%B7%3A+guest.link%2FCbv+%5D+%D8%A7%D9%84%D8%AD%D8%A7%D9%84%D9%8A+%D8%8C+%D8%B1%D8%A7%D8%A8%D8%B7+%D8%A8%D8%AF%D9%8A%D9%84+%5B%D9%86%D8%B3%D8%AE+%D8%B1%D8%A7%D8%A8%D8%B7%3A+guest.link%2FCbv+%5D&tab=main
http://kamagraes.site/# farmacia barata
Все, что вам нужно знать о винтовых масляных компрессорах: принципы работы и секреты повышения эффективности работы на https://infokam.su/konstruktsiya-i-printsip-raboty-vintovyh-maslyanyh-kompressorov.html
azithromycin price
https://farmacia.best/# farmacias online seguras
order ursodiol 150mg without prescription order cetirizine for sale order cetirizine for sale
buy urso cheap zyrtec 10mg over the counter cetirizine 5mg tablet
Смотрите фильмы, сериалы, и мультфильмы из списка “Фильмы и сериалы” в нашем онлайн-кинотеатре фильмы
doxycycline in pregnancy
The Internet has revolutionized business strategies reputation house reviews
1. C88 Fun – Infinite Entertainment Beckons!
C88 Fun is not just a gaming platform; it’s a gateway to limitless entertainment. Featuring an intuitive interface and an eclectic game selection, C88 Fun caters to every gaming preference. From timeless classics to cutting-edge releases, C88 Fun ensures every player discovers their personal gaming haven.
2. JILI & Evo 100% Welcome Bonus – A Grand Welcome Awaits!
Embark on your gaming journey with a grand welcome from C88. New members are greeted with a 100% Welcome Bonus from JILI & Evo, doubling the thrill from the get-go. This bonus acts as a springboard for players to explore the diverse array of games available on the platform.
3. C88 First Deposit Get 2X Bonus – Double the Excitement!
Generosity is a cornerstone at C88. With the “First Deposit Get 2X Bonus” offer, players revel in double the fun on their initial deposit. This promotion enhances the gaming experience, providing more avenues to win big across various games.
4. 20 Spin Times = Get Big Bonus (8,888P) – Spin Your Way to Glory!
Spin your way to substantial bonuses with the “20 Spin Times” promotion. Accumulate spins and stand a chance to win an impressive bonus of 8,888P. This promotion adds an extra layer of excitement to the gameplay, combining luck and strategy for maximum enjoyment.
5. Daily Check-in = Turnover 5X?! – Daily Rewards Await!
Consistency reigns supreme at C88. By simply logging in daily, players not only savor the thrill of gaming but also stand a chance to multiply their turnovers by 5X. Daily check-ins bring additional perks, making every day a rewarding experience for dedicated players.
6. 7 Day Deposit 300 = Get 1,500P – Unlock Deposit Rewards!
For those hungry for opportunities, the “7 Day Deposit” promotion is a game-changer. Deposit 300 and receive a generous reward of 1,500P. This promotion encourages players to explore the platform further and maximize their gaming potential.
7. Invite 100 Users = Get 10,000 PESO – Spread the Joy!
C88 believes in the strength of community. Invite friends and fellow gamers to join the excitement, and for every 100 users, receive an incredible reward of 10,000 PESO. Sharing the joy of gaming has never been more rewarding.
8. C88 New Member Get 100% First Deposit Bonus – Exclusive Benefits!
New members are in for a treat with an exclusive 100% First Deposit Bonus. C88 ensures that everyone kicks off their gaming journey with a boost, setting the stage for an exhilarating experience filled with opportunities to win.
9. All Pass Get C88 Extra Big Bonus 1000 PESO – Unlock Unlimited Rewards!
For avid players exploring every nook and cranny of C88, the “All Pass Get C88 Extra Big Bonus” offers an additional 1000 PESO. This promotion rewards those who embrace the full spectrum of games and features available on the platform.
Ready to immerse yourself in the excitement? Visit C88 now and unlock a world of gaming like never before. Don’t miss out on the excitement, bonuses, and wins that await you at C88. Join the community today, and let the games begin! #c88 #c88login #c88bet #c88bonus #c88win
Drugs information for patients. Brand names.
lyrica
Actual what you want to know about medication. Get here.
электрокарнизы для штор цена https://prokarniz11.ru/
автоматизация рулонных штор https://prokarniz13.ru/
http://vardenafilo.icu/# farmacia online 24 horas
Medicament prescribing information. Effects of Drug Abuse.
valtrex tablet
All information about drugs. Get now.
doxycycline online canada
https://kamagraes.site/# farmacias online seguras
https://farmacia.best/# farmacias online baratas
How much do negative reviews affect the reputation, figures, and income of a business reputation house employee reviews
оказание бухгалтерских услуг
vardenafil online india
c88 login
C88: Elevate Your Gaming Experience with Unrivaled Bonuses and Endless Excitement!
Introduction:
Embark on an extraordinary gaming adventure with C88, a platform that redefines the boundaries of entertainment. Whether you’re a seasoned gamer or a newcomer, C88 promises an immersive experience characterized by thrilling features and exclusive bonuses. Let’s unravel the key elements that position C88 as the ultimate destination for gaming enthusiasts.
1. C88 Fun – Where Entertainment Knows No Bounds!
More than just a gaming platform, C88 Fun is an expedition waiting to be discovered. Boasting an intuitive interface and a diverse range of games, C88 Fun caters to all preferences. From timeless classics to cutting-edge releases, C88 Fun ensures every player finds their gaming sanctuary.
2. JILI & Evo 100% Welcome Bonus – A Warm Welcome for Newcomers!
Embark on your gaming journey with a warm embrace from C88. New members are welcomed with a 100% Welcome Bonus from JILI & Evo, doubling the excitement right from the start. This bonus acts as a catalyst for players to delve into the diverse array of games available on the platform.
3. C88 First Deposit Get 2X Bonus – Doubling the Excitement!
C88 believes in generously rewarding players. With the “First Deposit Get 2X Bonus” offer, players can revel in double the fun on their initial deposit. This promotion enriches the gaming experience, providing more avenues to win big across various games.
4. 20 Spin Times = Get Big Bonus (8,888P) – Spin Your Way to Greatness!
Spin your way to substantial bonuses with the “20 Spin Times” promotion. Accumulate spins and stand a chance to win an impressive bonus of 8,888P. This promotion adds an extra layer of excitement to the gameplay, combining luck and strategy for maximum enjoyment.
5. Daily Check-in = Turnover 5X?! – Daily Rewards Await!
Consistency is key at C88. By simply logging in daily, players not only bask in the thrill of gaming but also stand a chance to multiply their turnovers by 5X. Daily check-ins bring additional perks, making every day a rewarding experience for dedicated players.
6. 7 Day Deposit 300 = Get 1,500P – Unlock Deposit Rewards!
For those craving opportunities, the “7 Day Deposit” promotion is a game-changer. Deposit 300 and receive a generous reward of 1,500P. This promotion encourages players to explore the platform further and maximize their gaming potential.
7. Invite 100 Users = Get 10,000 PESO – Share the Excitement!
C88 believes in the strength of community. Invite friends and fellow gamers to join the excitement, and for every 100 users, receive an incredible reward of 10,000 PESO. Sharing the joy of gaming has never been more rewarding.
8. C88 New Member Get 100% First Deposit Bonus – Exclusive Benefits!
New members are in for a treat with an exclusive 100% First Deposit Bonus. C88 ensures that everyone kicks off their gaming journey with a boost, setting the stage for an exhilarating experience filled with opportunities to win.
9. All Pass Get C88 Extra Big Bonus 1000 PESO – Unlock Unlimited Rewards!
For avid players exploring every nook and cranny of C88, the “All Pass Get C88 Extra Big Bonus” offers an additional 1000 PESO. This promotion rewards those who embrace the full spectrum of games and features available on the platform.
Ready to immerse yourself in the excitement? Visit C88 now and unlock a world of gaming like never before. Don’t miss out on the excitement, bonuses, and wins that await you at C88. Join the community today and let the games begin! #c88 #c88login #c88bet #c88bonus #c88win
http://tadalafilo.pro/# farmacia online internacional
generic for effexor
tombak118
nha cai
In recent years, the landscape of digital entertainment and online gaming has expanded, with ‘nha cai’ (betting houses or bookmakers) becoming a significant part. Among these, ‘nha cai RG’ has emerged as a notable player. It’s essential to understand what these entities are and how they operate in the modern digital world.
A ‘nha cai’ essentially refers to an organization or an online platform that offers betting services. These can range from sports betting to other forms of wagering. The growth of internet connectivity and mobile technology has made these services more accessible than ever before.
Among the myriad of options, ‘nha cai RG’ has been mentioned frequently. It appears to be one of the numerous online betting platforms. The ‘RG’ could be an abbreviation or a part of the brand’s name. As with any online betting platform, it’s crucial for users to understand the terms, conditions, and the legalities involved in their country or region.
The phrase ‘RG nha cai’ could be interpreted as emphasizing the specific brand ‘RG’ within the broader category of bookmakers. This kind of focus suggests a discussion or analysis specific to that brand, possibly about its services, user experience, or its standing in the market.
Finally, ‘Nha cai Uy tin’ is a term that people often look for. ‘Uy tin’ translates to ‘reputable’ or ‘trustworthy.’ In the context of online betting, it’s a crucial aspect. Users typically seek platforms that are reliable, have transparent operations, and offer fair play. Trustworthiness also encompasses aspects like customer service, the security of transactions, and the protection of user data.
In conclusion, understanding the dynamics of ‘nha cai,’ such as ‘nha cai RG,’ and the importance of ‘Uy tin’ is vital for anyone interested in or participating in online betting. It’s a world that offers entertainment and opportunities but also requires a high level of awareness and responsibility.
http://kamagraes.site/# farmacias online seguras
Компания Namuna Development в Ташкенте с 2017 года стремится не просто строить здания, Трехкомнатная квартира-студия в Ташкенте но и создавать территорию, оснащенную развитой инфраструктурой.
Medicament information for patients. What side effects can this medication cause?
buying flibanserina
Some trends of drugs. Read here.
https://farmacia.best/# farmacia online
june 2024 calendar
Medicine information sheet. What side effects can this medication cause?
prednisone
Everything information about pills. Get now.
buy lasix pills buy ventolin 2mg without prescription order albuterol for sale
http://kamagraes.site/# farmacias online seguras en españa
https://tadalafilo.pro/# farmacias online baratas
электрокарнизы для штор цена москва https://prokarniz19.ru/
https://farmacia.best/# farmacia online
order strattera 10mg pill buy atomoxetine without a prescription oral sertraline 100mg
atomoxetine pill sertraline 100mg pill zoloft drug
https://www.gettyimages.com/search/2/image?family=creative&phrase=Spletna%20stran,%20poslovni%20naslov%20288365.com%20Apple%20iOS%20razli%C4%8Dica%20(la%C5%BEje%20najti%20288365%20nogomet,%20vsi%20%C5%A1porti)%20Android%20razli%C4%8Dica%20288365.com%20%5BKopiraj%20URL:%20guest.link%2FCbv%20%5D%20Trenutna,%20alternativna%20povezava%20%5BKopiraj%20URL:%20guest.link%2FCbv%20%5D
Medicines information leaflet. What side effects?
where buy celebrex
All what you want to know about pills. Read information now.
https://riapo.ru/shiny-dlja-ezdy-zimoj-osobennosti-ih-vybora.dhtm
http://farmacia.best/# farmacias online baratas
Drugs information sheet. Long-Term Effects.
can you get zithromax
Actual news about drug. Read here.
https://vardenafilo.icu/# farmacia online envÃo gratis
colchicine indications
https://www.wildberries.ru/catalog/176001489/detail.aspx
Женская Водолазка с Длинным рукавом (Черная) Артикул 9889696754543457
http://kamagraes.site/# farmacias online seguras en españa
Medicines information leaflet. Long-Term Effects.
pregabalin
Actual what you want to know about medicament. Get information here.
http://tadalafilo.pro/# farmacias baratas online envÃo gratis
Ваша финансовая свобода начинается здесь! С нашим сервисом вы можете взять займ без отказа срочно. Это удобное и быстрое решение для тех, кто ищет надежный источник финансирования в критических ситуациях. Мы гарантируем прозрачность условий и мгновенное одобрение. Отправьте заявку и убедитесь, что финансовая помощь может быть легкой и доступной!
У вас возникла неотложная потребность в финансах? Наш сервис – именно то, что вам нужно. Мы предлагаем взять займ без отказа и проверок, гарантируя максимальное удобство и минимум требований. Всего несколько минут – и средства уже у вас на карте. Забудьте о сложных процедурах и длительных ожиданиях, выбирайте быстроту и надежность с нами.
Medication information. What side effects?
cipro
Best about medicines. Get here.
http://tadalafilo.pro/# farmacia 24h
http://farmacia.best/# farmacia envÃos internacionales
Drugs information. Short-Term Effects.
zyban medication
Everything about medication. Get now.
http://kamagraes.site/# farmacia online
Актуальные объявления о покупке и продаже квартир на вторичном рынке недвижимости ipoteka kreditga uylar toshkent yunusobod частные объявления о продаже квартир.
generic furosemide 100mg monodox oral albuterol for sale
prednisone buy
http://kamagraes.site/# farmacia online internacional
I’m appreciative of this site for my successful wagers in the Champions League
https://tetrasky.ru/
Medicine prescribing information. Drug Class.
minocycline for sale
All trends of drugs. Get now.
Мгновенно создавайте премиальные статьи, описания и разнообразный контент с использованием нашего революционного искусственного интеллекта Нейросеть для написания текста GPT4
https://sildenafilo.store/# comprar viagra online en andorra
Meds information. Cautions.
flagyl generic
Everything what you want to know about medicament. Read information here.
Наставник по питанию Андрей Воронин
Наставник по питанию Андрей Воронин – человек, который в течение 12 лет пытался решить проблему с лишним весом, перепробовав множество способов похудеть. Неоднократно обращался с проблемой лишнего веса к нутрициологам, фитнес-тренерам и диетологам, однако ни один из них не смог помочь. Всё это было похоже на обман, не решающий проблему, а лишь отгоняющий ее на некоторое время. Вес трижды уходил, но всегда возвращался. Согласитесь, это был совсем не тот результат, который хотелось получить, работая с профессионалами.
Однако Андрей смог найти решение. Он самостоятельно похудел на 31 кг и с 2018 года помогает достичь этой цели другим людям.
Как же ему это удалось?
Дело в том, что Андрей Павлович взялся за разработку собственной методики похудения без диет и изнурительных тренировок. И уже более 400 человек совершенствуют по ней свое тело и получают положительные результаты. А создатель методики теперь стал настоящим ЗОЖ-коучем, наставником по здоровому питанию и эффективному достижению целей.
Наставник по питанию Андрей Воронин – человек, который знает врага в лицо и нашел способ его устранить. Методика получила название “ДиетоЛогика”. Это комплексная авторская методика коррекции веса и избавления от пищевой зависимости, основанная на личном опыте и тщательном изучении проблемы, а не просто диета или марафон.
Если у вас или у вашего ребенка есть проблемы с лишним весом или есть нездоровое отношение к еде, методика нутрициолога Андрея Воронина решит их в 9 из 10 случаев.
Автор советует отказаться от постоянного скачивания диет, подсчета калорий и участия в марафонах, предлагая вместо этого решить проблему лишнего веса раз и навсегда.
Андрей Павлович уверен в успехе своей методики, потому что:
* Он сам похудел на 31 кг и понимает проблему изнутри.
* У него имеется 3 диплома по коррекции веса.
* У него множество положительных отзывов.
* Он предоставляет гарантии похудения в договоре.
* Он официально зарегистрирован как ИП.
* Его знают в СМИ, его приглашают в телевизионные и радиопередачи.
* Одна из его книг стала хитом продаж.
* Информация о нем доступна в интернете.
* К нему обращаются звезды, и о нем рассказывают в СМИ.
* Он получил благодарность от Мосгодумы и многое другое.
Книга Андрея Павловича “Диетологи, я вам не верю!” призывает читателей обращать внимание на свое здоровье, быть внимательнее к уловкам рекламы и не губить свое тело перееданиями.
Не экономьте на своем здоровье. Не сдавайтесь: коррекция веса возможна! Не тратьте свое время на прохождение марафонов по похудению. Не мучьте себя диетами и тренировками, эффективность которых крайне сомнительна, особенно, если вы сами себе это назначили. Очень важно, чтобы человек, который предлагает вам диету и систему тренировок, был хорошо знаком с проблемой.
Консультация диетолога является важным шагом для тех, кто стремится достичь своих целей: изменить привычки в питании, прийти к стройности и поддержанию здоровья. Диетолог может помочь клиенту разработать индивидуальный план питания, основанный на его потребностях, предпочтениях и целях.
Андрей Павлович Воронин также готов поменять ваше «хочу» в питании. Поменяются ваши привычки и убеждения – и стройность станет вечной.
Перечень товаров, не требующих сертификации. Не существует единого утвержденного списка товаров, не требующих сертификации Какая продукция не подлежит сертификации Это было сказано ранее. По мере изучения актуального списка вы не найдете вашей продукции среди заявленных категорий – это означает, что единственным документом для реализации или прохождения таможенного контроля является отказное письмо.
http://vardenafilo.icu/# farmacias baratas online envÃo gratis
The magical world of slot machines: Book of Mostbet and Joker Stoker https://www.mundodocker.com.br/topic/casas-de-apostas-testadas-e-confiaveis-em-portugal/#post-52041
order generic augmentin brand serophene order serophene online
Наставник по питанию Андрей Воронин
http://sildenafilo.store/# comprar viagra contrareembolso 48 horas
https://sildenafilo.store/# viagra 100 mg precio en farmacias
Pills information. Brand names.
effexor rx
Best about drug. Read information now.
buy lexapro generic naltrexone 50mg drug buy naltrexone pills
order lexapro 20mg for sale buy lexapro without a prescription naltrexone 50 mg brand
https://tadalafilo.pro/# farmacia online 24 horas
can you get generic plavix without dr prescription
http://kamagraes.site/# farmacia 24h
Pills information sheet. Brand names.
minocycline
Some news about drugs. Read now.
http://farmacia.best/# farmacia 24h
какой налог с продажи квартиры в Ташкенте
Купить мешки для строительного мусора большого размера
мешки под строительный мусор купить http://www.meshki-dlya-stroitelnogo-musora-a.ru.
ташкент недвижимость цены
дешевые новостройки в ташкенте
https://farmacia.best/# farmacia online 24 horas
Добровольная сертификация продукции услуг и систем менеджмента качества в СДС Роспромтест на соответствие Государственным стандартам, техническим условиям. Сертификация объектов проходит на добровольной основе по инициативе заявителя в системе добровольной сертификации Роспромтест на соответствие Государственным стандартам (ГОСТ), техническим условиям (ТУ), стандартам организации (СТО).
buy levitra usa
19dewa
http://sildenafilo.store/# comprar viagra en españa envio urgente contrareembolso
квартиры под субсидию в ташкенте
In the ever-evolving world of digital technology, it has become increasingly important for individuals and businesses to safeguard their online security http://www.project3n.com/bbs/board.php?bo_table=free&wr_id=423629
купить квартиру в новостройке ташкент
brillx скачать
бриллкс
Брилкс казино предоставляет выгодные бонусы и акции для всех игроков. У нас вы найдете не только классические слоты, но и современные игровые разработки с прогрессивными джекпотами. Так что, возможно, именно здесь вас ждет величайший выигрыш, который изменит вашу жизнь навсегда!Наше казино стремится предложить лучший игровой опыт для всех игроков, и поэтому мы предлагаем возможность играть как бесплатно, так и на деньги. Если вы новичок и хотите потренироваться перед серьезной игрой, то вас приятно удивят бесплатные режимы игр. Они помогут вам разработать стратегии и привыкнуть к особенностям каждого игрового автомата.
https://vardenafilo.icu/# farmacias online seguras en españa
can i buy clomid over the counter in australia
http://kamagraes.site/# farmacias baratas online envÃo gratis
brillx официальный сайт
https://brillx-kazino.com
Погрузитесь в мир увлекательных игр и сорвите джекпот на сайте Brillx Казино. Наши игровые аппараты не просто уникальны, они воплощение невероятных приключений. От крупных выигрышей до захватывающих бонусных раундов, вас ждут неожиданные сюрпризы за каждым вращением барабанов.Brillx Казино – это не просто обычное место для игры, это настоящий храм удачи. Вас ждет множество возможностей, чтобы испытать азарт в его самой изысканной форме. Будь то блеск и огонь аппаратов или адреналин в жилах от ставок на деньги, наш сайт предоставляет все это и даже больше.
I have saved some mirrors in case this site is blocked
https://jobsmart24.com/
http://viagrasansordonnance.store/# Sildénafil 100 mg sans ordonnance
viagra coupon canada
ритуальные услуги группа https://ritual-gratek16.ru/
metformin generic cost
http://kamagrafr.icu/# pharmacie ouverte
покупка квартир в ташкенте
квартиры в ташкенте в рассрочку
https://levitrafr.life/# acheter medicament a l etranger sans ordonnance
levitra online best price
https://stihi.ru/avtor/sibgatullin
http://kamagrafr.icu/# Acheter médicaments sans ordonnance sur internet
Эффективные средства против прыщей на голове
Внутренний прыщ лечение http://pryshchi.ru/.
Drug prescribing information. Drug Class.
eldepryl pill
Some news about drug. Read now.
http://cialissansordonnance.pro/# pharmacie ouverte 24/24
https://ru.otzyv.com/sibgatullin-timur-ravilevich
Medication information leaflet. Long-Term Effects.
cytotec
All news about medicines. Get information now.
Лучшие средства для борьбы с прыщами
Контурная пластика http://pryshchi.ru/.
http://pharmacieenligne.guru/# Pharmacie en ligne livraison gratuite
buy 20 mg prednisone without rx
combivent 100 mcg oral buy dexamethasone 0,5 mg for sale order linezolid 600 mg online
order combivent pill buy linezolid online zyvox usa
Medicament information sheet. Generic Name.
nexium
Actual information about pills. Get now.
https://levitrafr.life/# Pharmacie en ligne sans ordonnance
https://poisk-proslushki-spb.ru/
https://poisk-proslushki-msk.ru/
19dewa gacor
Medicine information. What side effects?
lyrica
Everything news about pills. Get information here.
http://kamagrafr.icu/# Pharmacie en ligne fiable
best online casinos
https://namebook.club/profile/sibgatullin-timur-27850990000
https://cialissansordonnance.pro/# Pharmacie en ligne livraison gratuite
Купить двухкомнатную квартиру в Ташкенте
https://ruscifra.ru/self-employed/6884094/
Commenting here to get backlink for my site.
https://kamagrafr.icu/# Acheter médicaments sans ordonnance sur internet
roulette casino
best uk casinos
http://levitrafr.life/# Pharmacies en ligne certifiées
Большой выбор батарей салютов. Качественная пиротехника по доступным ценам салют купить недорого
clavulanate drug buy augmentin 1000mg online cheap serophene over the counter
http://levitrafr.life/# pharmacie ouverte
Косметология и психология
косметология лица epilstudio.ru.
where can i get mobic online
http://cialissansordonnance.pro/# acheter médicaments à l’étranger
can i buy prednisone in mexico
https://levitrafr.life/# Pharmacie en ligne livraison gratuite
металлинвестбанк кредит проценты https://займы-все.рф/credits/kredit-nalichnymi-ot-metallinvestbanka/
synthroid pills dosage
http://viagrasansordonnance.store/# Le générique de Viagra
Medicine information for patients. Generic Name.
where buy promethazine
Best what you want to know about medicament. Get here.
vardenafil 20mg ca buy zanaflex online brand hydroxychloroquine 200mg
https://viagrasansordonnance.store/# Viagra femme ou trouver
https://foro.beatlesperu.com/viewtopic.php?f=8&t=18146&p=194655#p194655
Заказать пластиковые окна из немецкого профиля VEKA. Выгодные цены и предложения на покупку и установку пластиковых ПВХ окон и дверей окна двери пвх
https: slotozal-online.ink ru bonuses list – установочный портал, где любители азартных игр смогут получать удовольствие от проверенных азартных игр и получать впечатляющие призы .
Сайт дарит чудесные акции и дарит легкий доступ к игре .
Убедитесь в преимуществах Слотозал уже сегодня!
lexapro 10 mg cost
http://levitrafr.life/# Pharmacie en ligne fiable
Thanks to the mirrors, I can continue betting at this site
https://jobsmart24.com/
Купить нержавеющие трубы по доступным ценам за метр от производителя окна пвх в Минске для дачи в Москве от производителя по низким ценам
http://pharmacieenligne.guru/# acheter medicament a l etranger sans ordonnance
19dewa login
шарлотка с яблоками рецепт в духовке
https://cialissansordonnance.pro/# Pharmacies en ligne certifiées
buy colchicine
can you buy generic synthroid without insurance
https://cialissansordonnance.pro/# pharmacie ouverte
электровелосипед
zoloft dosage
where buy generic finpecia tablets
екапуста займ на карту https://займы-все.рф/zaimy/ekapusta/
buy nateglinide 120 mg pills buy starlix generic candesartan oral
order starlix 120mg online cheap capoten 120mg for sale buy candesartan 16mg pills
trazodone side effects in dogs
what is cetirizine hydrochloride used for
purchase levitra online cheap order tizanidine sale hydroxychloroquine 200mg cost
Drug information leaflet. Long-Term Effects.
where to buy nexium
Actual what you want to know about medicines. Get information here.
where to get zithromax without a prescription
Medicines information leaflet. Cautions.
cost lisinopril
Actual news about drug. Read now.
I wish to show some appreciation to you just for rescuing me from this predicament. After checking throughout the search engines and finding solutions that were not beneficial, I figured my life was done. Being alive minus the approaches to the issues you have resolved as a result of your entire posting is a crucial case, and the kind that might have adversely damaged my entire career if I had not discovered your blog post. Your personal know-how and kindness in controlling every part was invaluable. I’m not sure what I would have done if I had not discovered such a point like this. I’m able to at this time look ahead to my future. Thanks for your time very much for this skilled and effective guide. I will not think twice to recommend your web blog to any person who should have tips about this matter.
super p-force 5mg tablets
Medicament prescribing information. What side effects?
order pregabalin
Everything news about pills. Get information here.
lexapro pill
discount actos
Meds information leaflet. Short-Term Effects.
lisinopril cheap
Best trends of pills. Get now.
The this site mirror comes in handy whenever the main site is blocked
https://jobsmart24.com/
can i get cheap cialis soft tabs tablets
Drugs prescribing information. Long-Term Effects.
minocycline medication
Everything what you want to know about meds. Read now.
офисные кресла
домашнее печенье рецепты
Приобрести мешки для строительного мусора в Где купить мешки для строительного мусора? по Большой ассортимент мешков для строительного мусора для любых нужд
Мешки для строительного мусора для любых отходов для любых объектов
Подбор мешков для строительного мусора по марке материалов
мешки под строительный мусор купить meshki-dlya-stroitelnogo-musora-y.ru.
jocuri xbox 360
where to buy lexapro pill
can you buy doxycycline over the counter usa
Medicine information. Drug Class.
how to buy zithromax
Some trends of medicine. Read information here.
carbamazepine sale order ciprofloxacin generic lincocin 500mg usa
buy tegretol generic ciplox 500mg generic order lincomycin pill
Drug information. Long-Term Effects.
lyrica without prescription
Everything news about medicine. Get information here.
where to buy mobic price
Pills information leaflet. Generic Name.
sildigra buy
All information about pills. Read information here.
side effects levaquin 500 mg
Куплю Ервой в Верхней Салде Капрелса 300 мг дорого в любом городе. Продать #Авегра, Мавирет, Кстанди, Кстанди у вас дорого в Узловой.
Продать лекарства с рук в Сегеже. Продать лекарства с рук в Туруханске выгодно
Мы осуществляем скупку лекарств безопасно и на выгодных условиях;
Принимаем широкий перечень препаратов;
Предлагаем выгодные цены.
Продать лекарства с рук в Кашине. Продать лекарства с рук в Тотьме. Продать лекарства с рук.
Продать остатки препаратов у аптекдорого Мавирет
Продать лекарства дорого
Легкие в установке и прочные в эксплуатации
трубы пластиковые для полива https://www.ukrtruba.com.ua.
Вішаки для кожного сезону: відлуння джерела моди
вішаки для одягу оптом https://www.vishakydljaodjagus.vn.ua.
super p-force sleepiness
Meds information for patients. Effects of Drug Abuse.
aurogra
Actual information about medicine. Get now.
Meds information for patients. Short-Term Effects.
pregabalin
All news about drugs. Read now.
where can i buy cenforce metformin over the counter oral glucophage
Medication prescribing information. What side effects can this medication cause?
buy generic glucophage
All trends of meds. Read here.
colchicine excretion
Выбирайте оптимальный бортовой автомобиль с КМУ
Новые бортовые камазы с КМУ https://kran-bort.blogspot.com/2023/11/bortovie-avtomobily-s-kmu.html/.
maculopapular rash levaquin 500mg
http://kazino-slotozal.ru/ Slotozal Casino – официальный сайт казино Слотозал
https://www.ted.com/profiles/45698785
buy lexapro
buy generic atorvastatin for sale amlodipine 5mg cost zestril over the counter
buy doxycycline capsule 100 mg
Can you tell us more about this? I’d want to find out some
additional information.
Meds information sheet. Brand names.
where to buy glucophage
Some information about medicines. Get now.
how to get cheap super p-force for sale
bnf cetirizine
SEOsprint — уникальное место! Оно объединяет самых разных и интересных людей сеоспринт
buy doxycycline 100mg for chlamydia
how to get generic arimidex without a prescription
buying from online mexican pharmacy mexican online pharmacies prescription drugs mexican mail order pharmacies
zyrtec vs claritin
best online pharmacies in mexico mexican rx online buying prescription drugs in mexico
how to get doxycycline pills
Thanks a bunch for sharing this with all people you
actually realize what you’re speaking about! Bookmarked.
Kindly additionally visit my website =). We may have a link trade contract between us
mexico drug stores pharmacies mexican rx online purple pharmacy mexico price list
slotozal casino регистрация http://slotozal-kazino-site.ru/
Drug information leaflet. Generic Name.
abilify
Everything trends of pills. Read now.
https://www.google.com.mx/url?q=https://didvirtualnumbers.com/zh/
mexico pharmacy pharmacies in mexico that ship to usa buying from online mexican pharmacy
reputable mexican pharmacies online mexican online pharmacies prescription drugs mexican pharmaceuticals online
Medicine information for patients. Short-Term Effects.
propecia
All trends of drug. Get information now.
mexican online pharmacies prescription drugs mexican drugstore online mexico drug stores pharmacies
buy atarax tablets
mexican rx online mexican border pharmacies shipping to usa mexican pharmaceuticals online
слотозал на деньги http://slotozal-zerkalo.ru/
Medicines prescribing information. Drug Class.
lisinopril
Everything trends of medicines. Read now.
сайт слотозал http://slotozal-official.ru/
mexican pharmaceuticals online mexico drug stores pharmacies best mexican online pharmacies
не дорого мешки для мусора Хочешь надежную упаковка для мусора? Покупай мешки для мусора
Подходят для различных объемов мусора – выбери нужный пакет
пакетов для мусора – в любой город за дорогие пакеты для мусора? Заходи к нам!
Как долго еще мешки для мусора? Выбирай у нас – Подтверждают: наша тара мешков для мусора качественная нашей упаковки мешков для мусора заслужила доверие покупателями
“Прочные мешки для мусора – справятся даже в сложных условиях
Не надо больше? Закажи у нас У нас в продаже мешков для мусора – выберешь именно то, что нужно
Огромный выбор для мешков мусора – всегда в наличии у нас
Не нужно больше тратить на поиски мешков для мусора? Покупай у нас!
Тебе интересны качественные пакеты для мусора? У нас есть в ассортименте все, что тебе нужно
“Не трать за упаковку мешков для мусора – выбирай у нас по приемлемой цене
ненадежные мешки для мусора? Покупай у нас по выгодной цене
Не переплачивай – приходи к нам за мешками для мусора по доступной цене
Ищешь надежные мешки для мусора? Приобретай упаковку от нас
мусорные мешки цена http://www.meshki-dlya-musora-o.ru/.
where to buy doxycycline online
Odbierz prezent darmowe 100 zl za rejestracje. Nowe zwyciestwa czekaja!
This is my first time pay a quick visit at here and i am really happy to read everthing at one place .
atorvastatin 80mg brand zestril sale order generic lisinopril 5mg
ремонт стиральных машин в самаре на дому
Быстрый ремонт стиральных машин в Самаре
where can i buy doxycycline in singapore
Medicines information leaflet. Long-Term Effects.
lopressor
All what you want to know about drug. Get information here.
purchase cefadroxil pills ascorbic acid 500mg for sale lamivudine drug
duricef order online purchase lamivudine pill buy combivir pills
накрутка пф трафика сайта https://t.me/infinitysoft_dronov
Medicine information for patients. Generic Name.
singulair
Everything about pills. Read now.
lexapro 30 mg price
buy omeprazole without prescription atenolol 100mg for sale order atenolol 50mg sale
[url=https://effexor.cyou/]effexor xr 150mg[/url]
Quality posts is the main to attract the people to visit
the web site, that’s what this website is providing.
Drugs information leaflet. Drug Class.
buying singulair
All trends of drugs. Get information here.
Разовая чистка снега с крыш и абонентское обслуживание в зимний период очистка крыш абонентское обслуживание
buying from online mexican pharmacy mexico pharmacy mexican rx online
Great site, user-friendly interface
https://maxbetasia88.net/
where to get zithromax without rx
reputable mexican pharmacies online mexican drugstore online mexico drug stores pharmacies
Абузоустойчивый серверы, идеально подходит для работы програмным обеспечением как XRumer так и GSA
Стабильная работа без сбоев, высокая поточность несравнима с провайдерами в квартире или офисе, где есть ограничение.
Высокоскоростной Интернет: До 1000 Мбит/с
Скорость интернет-соединения – еще один важный параметр для успешной работы вашего проекта. Наши VPS/VDS серверы, поддерживающие Windows и Linux, обеспечивают доступ к интернету со скоростью до 1000 Мбит/с, обеспечивая быструю загрузку веб-страниц и высокую производительность онлайн-приложений.
мастер по ремонту стиральных машин в самаре
Ремонт стиральных машин в Самаре
medication from mexico pharmacy buying prescription drugs in mexico buying from online mexican pharmacy
purple pharmacy mexico price list medication from mexico pharmacy purple pharmacy mexico price list
https://pedagog-razvitie.ru/nowosty_obrasovaniya/bakalavr-magistr-speczialist-urovni-v/
https://pedagog-razvitie.ru/nowosty_obrasovaniya/reklama-kak-sposob-rynochnogo-prodvizh/
pharmacies in mexico that ship to usa mexican pharmacy best online pharmacies in mexico
Medicines information for patients. Cautions.
zenegra
All information about medication. Get information now.
cefixime dosage
mexican drugstore online best mexican online pharmacies buying prescription drugs in mexico
Drugs prescribing information. Short-Term Effects.
cialis super active
All trends of medicament. Get information here.
medication from mexico pharmacy mexican rx online best mexican online pharmacies
cialis soft tabs bible
дешевые купить люстра в москве
http://www.lu17.ru/
mexican online pharmacies prescription drugs purple pharmacy mexico price list purple pharmacy mexico price list
В контексте рынка труда, где высшее образование часто выступает ключевым фактором при трудоустройстве, возникает вопрос о целесообразности приобретения дипломов о высшем образовании. Анализируя вопрос где купить дипломы о высшем образовании, стоит рассмотреть ряд факторов. С одной стороны, приобретение такого диплома может показаться привлекательным решением для тех, кто стремится ускорить карьерный рост или обойти систему образования. Однако, с другой стороны, это сопряжено с высокими рисками, включая юридические последствия и потерю репутации. Поддельный документ может быть легко раскрыт, что нанесет ущерб не только карьере, но и личной репутации. Более того, отсутствие реальных знаний и навыков, которые должны были бы быть получены в процессе обучения, может привести к профессиональным трудностям в будущем.
what does prednisone look like
100 amoxicillin 500 mg
get prednisone without a prescription
Medicines information sheet. Short-Term Effects.
maxalt
Some news about medicament. Read here.
Пошаговые рецепты приготовления блюд и напитков, выпечки с подробными инструкциями для повара. Гастроном невероятных вкусных рецептур, чтобы готовить дома всегда вкусно! Еда на каждый день!
can i purchase tinidazole prices
omeprazole 10mg over the counter order atenolol generic buy tenormin generic
Выбирайте качественные пакеты для мусора
2) Защитите окружающую среду с надежными мешками для мусора
3) Избавьтесь от мусора с легкостью с помощью мешков для мусора
4) Оптимальный выбор для утилизации мусора – мешки для мусора
5) Держите свой дом с помощью мешков для мусора
6) Упорядочьте свой дом с помощью мешков для мусора
7) Поддержите чистоту с качественными мешками для мусора
8) Простое решение для утилизации мусора – мешки для мусора
9) Необходимое приобретение для любого дома – мешки для мусора
10) Легко сортируйте мусор с помощью различных цветов мешков для мусора
11) Сэкономьте время и силы с прочными мешками для мусора
12) Защитите окружающую среду вместе с мешками для мусора
13) Удобный способ для уборки двора – мешки для мусора
14) Храните уборочные принадлежности в мешках для мусора
15) Качество и экологичность – главные критерии при выборе мешков для мусора
16) Сохраняйте свой двор в чистоте с мешками для мусора
17) Легко и быстро – утилизируйте мусор с помощью мешков для мусора
18) Простые и практичные мешки для мусора упростят вашу жизнь
19) Оптимизируйте пространство с помощью компактных мешков для мусора
20) Защитите свой дом с качественными мешками для мусора
мешки для мусора http://meshki-dlya-musora-f.ru.
Meds information. Brand names.
propecia
All trends of pills. Read information here.
cabergoline 0.5mg over the counter buy dostinex 0.5mg generic priligy canada
https://cityminsk.by/
diltiazem
купить люстру цена
https://www.lu17.ru
Medicament information sheet. Short-Term Effects.
lyrica buy
Everything about drugs. Get here.
buy prednisolone for cats
Nhà Cái RG
doxycycline dosing for malaria prophylaxis
buy zithromax pill
オンラインカジノとオンラインギャンブルの現代的展開
オンラインカジノの世界は、技術の進歩と共に急速に進化しています。これらのプラットフォームは、従来の実際のカジノの体験をデジタル空間に移し、プレイヤーに新しい形式の娯楽を提供しています。オンラインカジノは、スロットマシン、ポーカー、ブラックジャック、ルーレットなど、さまざまなゲームを提供しており、実際のカジノの興奮を維持しながら、アクセスの容易さと利便性を提供します。
一方で、オンラインギャンブルは、より広範な概念であり、スポーツベッティング、宝くじ、バーチャルスポーツ、そしてオンラインカジノゲームまでを含んでいます。インターネットとモバイルテクノロジーの普及により、オンラインギャンブルは世界中で大きな人気を博しています。オンラインプラットフォームは、伝統的な賭博施設に比べて、より多様なゲーム選択、便利なアクセス、そしてしばしば魅力的なボーナスやプロモーションを提供しています。
安全性と規制
オンラインカジノとオンラインギャンブルの世界では、安全性と規制が非常に重要です。多くの国々では、オンラインギャンブルを規制する法律があり、安全なプレイ環境を確保するためのライセンスシステムを設けています。これにより、不正行為や詐欺からプレイヤーを守るとともに、責任ある賭博の促進が図られています。
技術の進歩
最新のテクノロジーは、オンラインカジノとオンラインギャンブルの体験を一層豊かにしています。例えば、仮想現実(VR)技術の使用は、プレイヤーに没入型のギャンブル体験を提供し、実際のカジノにいるかのような感覚を生み出しています。また、ブロックチェーン技術の導入は、より透明で安全な取引を可能にし、プレイヤーの信頼を高めています。
未来への展望
オンラインカジノとオンラインギャンブルは、今後も技術の進歩とともに進化し続けるでしょう。人工知能(AI)の更なる統合、モバイル技術の発展、さらには新しいゲームの創造により、この分野は引き続き成長し、世界中のプレイヤーに新しい娯楽の形を提供し続けることでしょう。
この記事では、オンラインカジノとオンラインギャンブルの現状、安全性、技術の影響、そして将来の展望に焦点を当てています。この分野は、技術革新によって絶えず変化し続ける魅力的な領域です。
Tải Hit Club iOS
Tải Hit Club iOSHIT CLUBHit Club đã sáng tạo ra một giao diện game đẹp mắt và hoàn thiện, lấy cảm hứng từ các cổng casino trực tuyến chất lượng từ cổ điển đến hiện đại. Game mang lại sự cân bằng và sự kết hợp hài hòa giữa phong cách sống động của sòng bạc Las Vegas và phong cách chân thực. Tất cả các trò chơi đều được bố trí tinh tế và hấp dẫn với cách bố trí game khoa học và logic giúp cho người chơi có được trải nghiệm chơi game tốt nhất.
Hit Club – Cổng Game Đổi Thưởng
Trên trang chủ của Hit Club, người chơi dễ dàng tìm thấy các game bài, tính năng hỗ trợ và các thao tác để rút/nạp tiền cùng với cổng trò chuyện trực tiếp để được tư vấn. Giao diện game mang lại cho người chơi cảm giác chân thật và thoải mái nhất, giúp người chơi không bị mỏi mắt khi chơi trong thời gian dài.
Hướng Dẫn Tải Game Hit Club
Bạn có thể trải nghiệm Hit Club với 2 phiên bản: Hit Club APK cho thiết bị Android và Hit Club iOS cho thiết bị như iPhone, iPad.
Tải ứng dụng game:
Click nút tải ứng dụng game ở trên (phiên bản APK/Android hoặc iOS tùy theo thiết bị của bạn).
Chờ cho quá trình tải xuống hoàn tất.
Cài đặt ứng dụng:
Khi quá trình tải xuống hoàn tất, mở tệp APK hoặc iOS và cài đặt ứng dụng trên thiết bị của bạn.
Bắt đầu trải nghiệm:
Mở ứng dụng và bắt đầu trải nghiệm Hit Club.
Với Hit Club, bạn sẽ khám phá thế giới game đỉnh cao với giao diện đẹp mắt và trải nghiệm chơi game tuyệt vời. Hãy tải ngay để tham gia vào cuộc phiêu lưu casino độc đáo và đầy hứng khởi!
Drugs information leaflet. What side effects?
tadacip
Best what you want to know about medicament. Get now.
abilify 2mg price canada
cabergoline 0.5mg generic order generic dostinex buy dapoxetine
как происходит кремация животных https://usyplenie-zhivotnyh-v-msk.top/
Drug information. Short-Term Effects.
norvasc
Actual news about medicine. Get here.
probenecid colchicine tablets
medrol uk aristocort uk cheap desloratadine
Meds information for patients. Drug Class.
buy generic singulair
Some what you want to know about medicine. Get information here.
gabapentin controlled substance
prednisone 20mg by mail order
buy doxycycline 100mg capsules online
how to get methylprednisolone without a prescription buy desloratadine generic clarinex online
Medicines information leaflet. Effects of Drug Abuse.
zoloft
Actual news about pills. Get information here.
lisinopril 20 mg buy
オンラインカジノレビュー
オンラインカジノレビュー:選択の重要性
オンラインカジノの世界への入門
オンラインカジノは、インターネット上で提供される多様な賭博ゲームを通じて、世界中のプレイヤーに無限の娯楽を提供しています。これらのプラットフォームは、スロット、テーブルゲーム、ライブディーラーゲームなど、様々なゲームオプションを提供し、実際のカジノの経験を再現します。
オンラインカジノレビューの重要性
オンラインカジノを選択する際には、オンラインカジノレビューの役割が非常に重要です。レビューは、カジノの信頼性、ゲームの多様性、顧客サービスの質、ボーナスオファー、支払い方法、出金条件など、プレイヤーが知っておくべき重要な情報を提供します。良いレビューは、利用者の実際の体験に基づいており、新規プレイヤーがカジノを選択する際の重要なガイドとなります。
レビューを読む際のポイント
信頼性とライセンス:カジノが適切なライセンスを持ち、公平なゲームプレイを提供しているかどうか。
ゲームの選択:多様なゲームオプションが提供されているかどうか。
ボーナスとプロモーション:魅力的なウェルカムボーナス、リロードボーナス、VIPプログラムがあるかどうか。
顧客サポート:サポートの応答性と有効性。
出金オプション:出金の速度と方法。
プレイヤーの体験
良いオンラインカジノレビューは、実際のプレイヤーの体験に基づいています。これには、ゲームプレイの楽しさ、カスタマーサポートへの対応、そして出金プロセスの簡単さが含まれます。プレイヤーのフィードバックは、カジノの品質を判断するのに役立ちます。
結論
オンラインカジノを選択する際には、詳細なオンラインカジノレビューを参照することが重要です。これらのレビューは、安全で楽しいギャンブル体験を確実にするための信頼できる情報源となります。適切なカジノを選ぶことは、オンラインギャンブルでの成功への第一歩です。
para que sirve la amoxicilina
Medication information sheet. Drug Class.
maxalt
Actual news about medication. Get now.
misoprostol 200mcg drug buy xenical pills for sale buy diltiazem sale
diltiazem warnings
Drugs information leaflet. Long-Term Effects.
mobic for sale
Best news about medicine. Get now.
where can i buy cheap zithromax no prescription
buy prednisone online without a prescription using a charge card
オンラインカジノ
オンラインカジノとオンラインギャンブルの現代的展開
オンラインカジノの世界は、技術の進歩と共に急速に進化しています。これらのプラットフォームは、従来の実際のカジノの体験をデジタル空間に移し、プレイヤーに新しい形式の娯楽を提供しています。オンラインカジノは、スロットマシン、ポーカー、ブラックジャック、ルーレットなど、さまざまなゲームを提供しており、実際のカジノの興奮を維持しながら、アクセスの容易さと利便性を提供します。
一方で、オンラインギャンブルは、より広範な概念であり、スポーツベッティング、宝くじ、バーチャルスポーツ、そしてオンラインカジノゲームまでを含んでいます。インターネットとモバイルテクノロジーの普及により、オンラインギャンブルは世界中で大きな人気を博しています。オンラインプラットフォームは、伝統的な賭博施設に比べて、より多様なゲーム選択、便利なアクセス、そしてしばしば魅力的なボーナスやプロモーションを提供しています。
安全性と規制
オンラインカジノとオンラインギャンブルの世界では、安全性と規制が非常に重要です。多くの国々では、オンラインギャンブルを規制する法律があり、安全なプレイ環境を確保するためのライセンスシステムを設けています。これにより、不正行為や詐欺からプレイヤーを守るとともに、責任ある賭博の促進が図られています。
技術の進歩
最新のテクノロジーは、オンラインカジノとオンラインギャンブルの体験を一層豊かにしています。例えば、仮想現実(VR)技術の使用は、プレイヤーに没入型のギャンブル体験を提供し、実際のカジノにいるかのような感覚を生み出しています。また、ブロックチェーン技術の導入は、より透明で安全な取引を可能にし、プレイヤーの信頼を高めています。
未来への展望
オンラインカジノとオンラインギャンブルは、今後も技術の進歩とともに進化し続けるでしょう。人工知能(AI)の更なる統合、モバイル技術の発展、さらには新しいゲームの創造により、この分野は引き続き成長し、世界中のプレイヤーに新しい娯楽の形を提供し続けることでしょう。
この記事では、オンラインカジノとオンラインギャンブルの現状、安全性、技術の影響、そして将来の展望に焦点を当てています。この分野は、技術革新によって絶えず変化し続ける魅力的な領域です。
Посоветуйте VPS
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Высокоскоростной Интернет: До 1000 Мбит/с
Скорость Интернет-соединения – еще один ключевой фактор для успешной работы вашего проекта. Наши VPS/VDS серверы, поддерживающие Windows и Linux, обеспечивают доступ к интернету со скоростью до 1000 Мбит/с, гарантируя быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Воспользуйтесь нашим предложением VPS/VDS серверов и обеспечьте стабильность и производительность вашего проекта. Посоветуйте VPS – ваш путь к успешному онлайн-присутствию!
http://moslomtorg.ru
buy cytotec online order xenical 60mg sale diltiazem 180mg us
Kylie Jenner: the secret of the K factor
piracetam 800mg pills betnovate 20gm usa clomipramine 50mg canada
doxycycline uk buy
дешевые купить люстра в москве https://myagkie-paneli11.ru/.
finasteride
Дедик сервер
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Виртуальные сервера (VPS/VDS) и Дедик Сервер: Оптимальное Решение для Вашего Проекта
В мире современных вычислений виртуальные сервера (VPS/VDS) и дедик сервера становятся ключевыми элементами успешного бизнеса и онлайн-проектов. Выбор оптимальной операционной системы и типа сервера являются решающими шагами в создании надежной и эффективной инфраструктуры. Наши VPS/VDS серверы Windows и Linux, доступные от 13 рублей, а также дедик серверы, предлагают целый ряд преимуществ, делая их неотъемлемыми инструментами для развития вашего проекта.
Medicines information for patients. Generic Name.
minocycline rx
All about medication. Read here.
piracetam pills piracetam 800mg generic order clomipramine 50mg pills
ventolin inhaler
prednisone buy no priscription
how to get zithromax prices
Medication information. Drug Class.
singulair
Actual what you want to know about drugs. Get information here.
buy acyclovir 400mg for sale zyloprim 100mg ca rosuvastatin sale
Commenting here to get backlink for my site.
super p-force tablet strengths
Pills information. Drug Class.
flagyl buy
Some information about pills. Read information here.
teva trazodone vs apo trazodone
Drugs information. Effects of Drug Abuse.
sildigra
Actual news about medicament. Read now.
side effects of zoloft
can i order zithromax price
where buy generic synthroid without rx
Medicament information for patients. What side effects can this medication cause?
nexium
Everything information about medicine. Get now.
ashwagandha root
sporanox 100 mg oral buy progesterone generic tindamax 300mg generic
buy zovirax paypal zyloprim pills buy rosuvastatin no prescription
Drugs information sheet. Brand names.
cialis super active
Best trends of medicament. Read now.
bot to watch youtube videos
gabapentin 300 mg capsule
Скачать приложения на Андроид бесплатно без регистрации https://apkhub.ru/
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Виртуальные сервера (VPS/VDS) и Дедик Сервер: Оптимальное Решение для Вашего Проекта
В мире современных вычислений виртуальные сервера (VPS/VDS) и дедик сервера становятся ключевыми элементами успешного бизнеса и онлайн-проектов. Выбор оптимальной операционной системы и типа сервера являются решающими шагами в создании надежной и эффективной инфраструктуры. Наши VPS/VDS серверы Windows и Linux, доступные от 13 рублей, а также дедик серверы, предлагают целый ряд преимуществ, делая их неотъемлемыми инструментами для развития вашего проекта.
Meds information leaflet. Generic Name.
provigil
Some trends of medicine. Get here.
protonix capsules
Optimize your app or game by the best free App Store Optimization Financial Implications of App Store
levaquin 500 mg 3 days
https://v-mig.ru/kofe-v-zjornah-lavazza-gran-riserva-1kg/
buy itraconazole 100 mg online cheap buy itraconazole 100 mg sale how to buy tindamax
https://sportsinfonow.com/
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Высокоскоростной Интернет: До 1000 Мбит/с
Скорость интернет-соединения играет решающую роль в успешной работе вашего проекта. Наши VPS/VDS серверы, поддерживающие Windows и Linux, обеспечивают доступ к интернету со скоростью до 1000 Мбит/с. Это гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Итак, при выборе виртуального выделенного сервера VPS, обеспечьте своему проекту надежность, высокую производительность и защиту от DDoS. Получите доступ к качественной инфраструктуре с поддержкой Windows и Linux уже от 13 рублей
Meds information sheet. What side effects can this medication cause?
zithromax price
Some news about medicament. Get information now.
Мощный дедик
Аренда мощного дедика (VPS): Абузоустойчивость, Эффективность, Надежность и Защита от DDoS от 13 рублей
Выбор виртуального сервера – это важный этап в создании успешной инфраструктуры для вашего проекта. Наши VPS серверы предоставляют аренду как под операционные системы Windows, так и Linux, с доступом к накопителям SSD eMLC. Эти накопители гарантируют высокую производительность и надежность, обеспечивая бесперебойную работу ваших приложений независимо от выбранной операционной системы.
Drugs information leaflet. Effects of Drug Abuse.
bactrim
Best about drugs. Get information now.
В нашем каталоге Вы найдете широкий ассортимент лодок ПВХ, моторов и комплектующих: каяк пластиковый купить
order generic zetia buy domperidone 10mg sale order tetracycline 250mg online cheap
карниз электрический для штор купить https://prokarniz34.ru/
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Высокоскоростной Интернет: До 1000 Мбит/с**
Скорость интернет-соединения – еще один важный момент для успешной работы вашего проекта. Наши VPS серверы, арендуемые под Windows и Linux, предоставляют доступ к интернету со скоростью до 1000 Мбит/с, обеспечивая быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Medication information for patients. What side effects?
can i order diltiazem
All news about medication. Get information here.
https://northeast.newschannelnebraska.com/story/50266910/how-to-promote-youtube-channels-with-youtube-view-bots
https://pedagog-razvitie.ru/interest_stati/professionalnye-uslugi-po-napisaniyu-otchetov/
where to buy zithromax tablets
order olanzapine sale diovan 160mg canada diovan 160mg for sale
synthroid name
buy zetia for sale order motilium without prescription buy sumycin 250mg online cheap
Medication information sheet. Cautions.
lyrica brand name
Best what you want to know about pills. Read here.
where buy generic avodart pills
продвижение сайтов в Молдове https://prodvijenie-saitov.md/
Medicine information. Cautions.
cheap nexium
Everything about drugs. Get information here.
Paxlovid over the counter: paxlovid covid – paxlovid for sale
doxycycline 50 mg cost
buy olanzapine 10mg online cheap buy nebivolol 20mg pills order valsartan 160mg pills
Meds information for patients. Cautions.
sildigra
Actual what you want to know about medicines. Read information now.
levaquin medication
Ae888 – Nhà cái uy tín đẳng cấp nhất tại Việt Nam.
Với công nghệ hiện đại, bảo mật an toàn, đa dạng game chơi,
hiện đang có lượng thành viên lớn nhất tại Việt Nam
#ae888 #nhacaiae888 #trangae888 #dagaae888 #ae888venus
albuterol rx coupon
where buy zithromax no prescription
how can i get cheap synthroid tablets
нанять грузчиков https://gruzchikirabota.ru/.
flexeril pill toradol 10mg oral generic toradol 10mg
Аренда мощного дедика (VPS): Абузоустойчивость, Эффективность, Надежность и Защита от DDoS от 13 рублей
В современном мире онлайн-проекты нуждаются в надежных и производительных серверах для бесперебойной работы. И здесь на помощь приходят мощные дедики, которые обеспечивают и высокую производительность, и защищенность от атак DDoS. Компания “Название” предлагает VPS/VDS серверы, работающие как на Windows, так и на Linux, с доступом к накопителям SSD eMLC — это значительно улучшает работу и надежность сервера.
Заказать чистку дивана и другой мягкой мебели с выездам на дом недорого https://www.piluli.kiev.ua/blog/zdorovie/5-factov-o-himchistki-mebeli/
cloridrato de ciprofloxacino para que serve
Medicament prescribing information. Short-Term Effects.
effexor
Some what you want to know about medicament. Get information now.
Каждый электрик устанавливает разные расценки на услуги, вы можете их сравнить и выбрать подходящие для себя вызов электрика
cost of viagra in us
Medicament information for patients. Generic Name.
neurontin
Actual news about medicament. Get information here.
doxycycline uk pharmacy
flexeril 15mg canada cyclobenzaprine cost toradol uk
Работа грузчиков на практике
грузчик услуга https://www.gruzchikipogruzchik.ru.
no prescription arimidex online purchase
propranolol blocks the beta
https://satbayev.university/
Drugs information leaflet. Generic Name.
proscar
Some about pills. Get here.
Большой выбор квадрокоптеров в интернет-магазине по выгодным ценам дрон
order ciprofloxacin online
GTA777 Slot
Drugs information for patients. Brand names.
singulair without dr prescription
Some about drug. Read information now.
Выбирайте и бронируйте бесплатно путевки в языковые детские лагеря лагеря в подмосковье языковые
is doxycycline an antibiotic
cost of amoxicillin: amoxicillin 500mg prescription – can i purchase amoxicillin online
сколько стоит килограмм мухоморов https://dobriy-muxomor.ru/
Medicines prescribing information. What side effects can this medication cause?
fosamax
Some trends of medication. Read now.
https://sutochnogrodno.by/
https://printablecalendar.top/
https://sutochnogrodno.by/
get cheap lexapro without prescription
how to buy colcrys order generic clopidogrel methotrexate 5mg generic
Интернет магазин предлагает купить оптом и в розницу современное медицинское оборудование и технику для частных и государственных клиник медицинское оборудование ростов на дону купить
https://sutochnogrodno.by/
Medicament information leaflet. What side effects can this medication cause?
lisinopril
Best information about pills. Read here.
buy amoxicillin 500mg online: order amoxicillin online no prescription – amoxicillin for sale online
why does adult acne happen order omnacortil generic most effective acne pills ranked
Защита от холода и непрошенных гостей: входные двери с терморазрывом
купить двери с терморазрывом http://www.vhodnye-dveri-s-termorazryvom77.ru.
https://sutochnogrodno.by/
диджитал агентство
татьяна лагута
buy gloperba for sale order colchicine online cheap methotrexate canada
dprofile ru
агентство смм
where to buy vermox in usa
acne treatment prescribed by dermatologist purchase avlosulfon generic acne treatment for teenagers
https://www.google.ws/url?q=https://www.coinsbar.net/ru/
проститутки метро царицыно https://a.fanfap.nl/
входная дверь с зеркалом https://vhodnye-dveri-s-zerkalom77.ru/
Приобретите в спб по выгодной цене
Кухни из натурального дерева в спб на заказ
Долговечные кухни от производителя в спб недорого
Кухни “под ключ” в спб с доставкой и монтажом
Акции на кухни в спб только у нас
Уникальные кухни в спб для вашего дома
Кухни для дружной семьи в спб по индивидуальному заказу
Непревзойденное качество по доступной цене кухонные гарнитуры для спб от ведущих производителей
Экономные кухни в спб для квартиры или загородного дома
Функциональные кухонные уголки для небольшой площади в спб
Квалифицированные дизайнеры для создания вашей кухни в спб
Элегантный стиль для вашей кухни в спб
Большой ассортимент кухонной мебели в спб
Индивидуальный подход к производству для вашей кухни в спб
Сбалансированное решение для вашей кухни в спб для вашей кухни в спб
Уникальный дизайн для вашей кухни в спб
Уютная кухня в спб – место для семейных посиделок и приготовления вкусных блюд
Эксклюзивные решения для вашей кухни в спб
Бесплатная доставка для вашей кухни в спб
кухни санкт петербург от фабрики недорого vip-kukhni-spb.ru.
https://vodosnab-msk.ru/
Складчина (совместная покупка) курса, всего за 1ye карина искхакова
Medicines prescribing information. Short-Term Effects.
proscar for sale
All news about medicament. Read information now.
https://sutochnogrodno.by/
alphabetical list of allergy medications cheap albuterol common prescription allergy pills
смотреть сериалы зарубежные 2023 https://sys-con.tv/
Medicines information sheet. Cautions.
cipro
Everything news about meds. Get here.
Здоровье и забота о нем – наша главная задача
вывеска на заказ http://msk-naruzhnaya-reklama.ru/.
Поставщик предоставляет основное управление виртуальными серверами (VPS), предлагая клиентам разнообразие операционных систем для выбора (Windows Server, Linux CentOS, Debian).
xenical drug
buy levaquin no prescriotion
Medicament information leaflet. What side effects can this medication cause?
flibanserina
All trends of medication. Read here.
https://fluoxetine2all.top
skin allergy tablets list azelastine 10ml brand does allegra require a prescription
Идеальный выбор для окна – электрокарниз
автоматические карнизы http://www.prokarniz38.ru.
get cheap synthroid without a prescription
Remarkable, I’ve advanced to this stage with this enthralling literature, grateful to the author!
prednisone otc price: 50 mg prednisone tablet – prednisone 40 mg
Medicines information sheet. Brand names.
zithromax
Best trends of medicament. Get here.
prednisone brand name in india: 6 prednisone – 1250 mg prednisone
where buy cheap clomid no prescription: how to buy generic clomid – cheap clomid without prescription
get cheap clomid price where to buy generic clomid without insurance – generic clomid without a prescription
Congratulations on your incredible gift for writing! Your article is an engaging and enlightening read. Wishing you a New Year full of achievements and happiness!
can you buy clomid now where can i get clomid prices – where can i buy cheap clomid without insurance
http://amoxil.icu/# purchase amoxicillin 500 mg
Drugs information for patients. Brand names.
can you buy lisinopril
Everything news about pills. Get here.
can you buy clomid without a prescription can i get cheap clomid tablets – where to buy clomid online
https://amoxil.icu/# amoxicillin without prescription
http://amoxil.icu/# amoxicillin online purchase
Hebat blog ini! 🌟 Saya sangat menyukai bagaimana penulisannya memberikan pemahaman mendalam dalam topik yang dibahas. 👌 Artikelnya menghibur dan mendidik sekaligus. 📖 Tiap artikel membuat saya lebih penasaran untuk membaca yang lainnya. Teruskan kerja yang bagus
https://amoxil.icu/# where to buy amoxicillin 500mg
Drug information. Long-Term Effects.
bactrim
Some news about meds. Get here.
осоветуйте vps
Абузоустойчивый сервер для работы с Хрумером и GSA и различными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Виртуальные сервера VPS/VDS и Дедик Сервер: Оптимальное Решение для Вашего Проекта
В мире современных вычислений виртуальные сервера VPS/VDS и дедик сервера становятся ключевыми элементами успешного бизнеса и онлайн-проектов. Выбор оптимальной операционной системы и типа сервера являются решающими шагами в создании надежной и эффективной инфраструктуры. Наши VPS/VDS серверы Windows и Linux, доступные от 13 рублей, а также дедик серверы, предлагают целый ряд преимуществ, делая их неотъемлемыми инструментами для развития вашего проекта.
Эдуард Давыдов бск http://davydov-eduard.ru/.
buying lexapro without dr prescription
cost clomid price: where can i get cheap clomid – how to get cheap clomid tablets
Хай, хочу поделится информации об росте криптовалюты, вам стоит её купить http://www.bisound.com/forum/showthread.php?p=599566#post599566 что бы вы смогли заработать x3
cheap clomid without prescription: buy cheap clomid without prescription – get cheap clomid
https://ciprofloxacin.life/# cipro online no prescription in the usa
Medication prescribing information. What side effects?
pregabalin
Some news about medicament. Read here.
antacid prescription drug names cipro 500mg drug
Pills prescribing information. Generic Name.
nolvadex
Best what you want to know about medication. Read now.
Салют, хочу поделится информации об росте криптовалюты, вам стоит её купить http://www.liuyuchen110.com/member/index.php?uid=ynubavo&action=viewarchives&aid=5165 что бы вы смогли заработать x3
https://marketblogs.ru/
2024總統大選民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
民意調查
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
Drugs information. What side effects?
sildigra
Everything news about medicines. Read information here.
https://addcity.ru/
buying doxycycline online
levitra in india
best painkiller for stomach pain order bactrim 480mg online
Салют, хочу поделится информации об росте криптовалюты, вам стоит её купить http://tambov.com.ru/forum/talks/187444-vazhnost-professionalnoj-kalibrovki-oborudovaniya.htm что бы вы смогли заработать x3
Medicines information leaflet. Brand names.
zithromax
Some about meds. Get now.
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
2024總統大選民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
Давыдов Эдуард https://www.davydov-eduard.ru.
Салют, хочу поделится информации об росте криптовалюты, вам стоит её купить http://575.by/communication/forum/user/681/ что бы вы смогли заработать x3
Meds information. What side effects can this medication cause?
get celebrex
Best news about medicine. Get information now.
п»їdcis tamoxifen: pct nolvadex – generic tamoxifen
generic for metformin
Spot on with this write-up, I really suppose this web site wants much more consideration. I’ll probably be once more to read much more, thanks for that info.
https://zithromaxbestprice.icu/# can i buy zithromax over the counter in canada
http://hudi.ru/
最新的民調顯示,2024年台灣總統大選的競爭格局已逐漸明朗。根據不同來源的數據,目前民進黨的賴清德與民眾黨的柯文哲、國民黨的侯友宜正處於激烈的競爭中。
一項民調指出,賴清德的支持度平均約34.78%,侯友宜為29.55%,而柯文哲則為23.42%。
另一家媒體的民調顯示,賴清德的支持率為32%,侯友宜為27%,柯文哲則為21%。
台灣民意基金會的最新民調則顯示,賴清德以36.5%的支持率領先,柯文哲以29.1%緊隨其後,侯友宜則以20.4%位列第三。
綜合這些數據,可以看出賴清德在目前的民調中處於領先地位,但其他候選人的支持度也不容小覷,競爭十分激烈。這些民調結果反映了選民的當前看法,但選情仍有可能隨著選舉日的臨近而變化。
https://www.google.com.eg/url?q=https://betrad.pl
buy cytotec pills online cheap: purchase cytotec – buy cytotec online
民調
печь камин на дровах https://www.magazin-kaminov11.ru.
Привет, хочу поделится информации об росте криптовалюты, вам стоит её купить https://www.orderviewdocs.online/doku.php?id=Профессиональная_калибровка_оборудования:_выбор_экспертов что бы вы смогли заработать x3
buy lisinopril online no prescription india: lisinopril pills – lisinopril comparison
總統民調
buy sleeping pills uk online purchase provigil pill
zoloft tablet canada
http://doxycyclinebestprice.pro/# doxycycline 500mg
總統民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
tamoxifen hip pain: tamoxifen cancer – tamoxifen and weight loss
buy cytotec online fast delivery: buy cytotec – order cytotec online
Здравствуйте, хочу поделится информации об росте криптовалюты, вам стоит её купить https://www.automania.by/forum/index.php?showtopic=18204 что бы вы смогли заработать x3
https://islam-mo.ru/
В мире, где каждый день раскрывает новые возможности, expl0it.ru представляет вам путь к неизведанным горизонтам финансирования. Откройте для себя займы в новых МФО, словно первооткрыватели неизвестных земель. Каждое предложение – это сокровище с уникальными условиями и привлекательными перспективами. Позвольте себе стать пионером в мире финансовых возможностей, исследуя новые и неведомые МФО!
Обращаясь на expl0it.ru, вы найдете лучшие условия для получения финансовой поддержки. Благодаря нашей широкой сети партнеров, мы предлагаем займ, адаптированные к вашим индивидуальным потребностям. Наши условия оформления займов просты и понятны, а процесс одобрения быстр и эффективен. Доверьте свои финансовые потребности нам и получите необходимые средства без затруднений.
http://cytotec.icu/# Cytotec 200mcg price
Получите перетяжку мягкой мебели с гарантией качества
Обновление мягкой мебели: простой способ обновить интерьер
Качественное обслуживание перетяжки мягкой мебели
Легко и просто обновить диван или кресло
ремонт и перетяжка мягкой мебели [url=https://www.peretyazhkann.ru/]https://www.peretyazhkann.ru/[/url].
бизнес сувениры подарки и креативные решения https://suveniry-i-podarki16.ru/.
zithromax for sale usa: zithromax 500 mg lowest price online – how to buy zithromax online
r33tgame.pro
r33tgame
buy doxycycline 500 mg
Хай, хочу поделится информации об росте криптовалюты, вам стоит её купить http://mlada.ru/club/user/2160/blog/94946/ что бы вы смогли заработать x3
r33tgame.com
nolvadex pills: nolvadex for sale – tamoxifen bone pain
http://lisinoprilbestprice.store/# buy zestoretic
r33tgame
how to get zithromax online: zithromax 500 price – buy zithromax without prescription online
Pills prescribing information. Generic Name.
trazodone without rx
All information about drug. Get here.
Мы освещаем проблемные вопросы, касающиеся самозанятости и нового налогового режима на профессиональный доход Самозанятый
технические двери металлические https://texnicheskiedveri.ru/
buy misoprostol over the counter: buy cytotec over the counter – buy cytotec pills
https://sury-iz-korana.ru/
купить квартиру в элитном доме nedvipro11.ru.
http://nolvadex.fun/# tamoxifen vs raloxifene
online sleep prescriptions online doctors that prescribe ambien
Самые популярные хиты 2024 за сегодня. Ежедневное обновление. Самые горячие новинки из мира музыки Слушать музыку 2024
Meds information leaflet. Cautions.
fosamax medication
All news about medicament. Get here.
doxycycline 100mg price: doxycycline 200 mg – buy doxycycline cheap
https://doxycyclinebestprice.pro/# buy doxycycline online 270 tabs
Medicament information leaflet. Drug Class.
can you get synthroid
Actual what you want to know about meds. Read information here.
먹튀검증
온카마켓은 카지노와 관련된 정보를 공유하고 토론하는 커뮤니티입니다. 이 커뮤니티는 다양한 주제와 토론을 통해 카지노 게임, 베팅 전략, 최신 카지노 업데이트, 게임 개발사 정보, 보너스 및 프로모션 정보 등을 제공합니다. 여기에서 다른 카지노 애호가들과 의견을 나누고 유용한 정보를 얻을 수 있습니다.
온카마켓은 회원 간의 소통과 공유를 촉진하며, 카지노와 관련된 다양한 주제에 대한 토론을 즐길 수 있는 플랫폼입니다. 또한 카지노 커뮤니티 외에도 먹튀검증 정보, 게임 전략, 최신 카지노 소식, 추천 카지노 사이트 등을 제공하여 카지노 애호가들이 안전하고 즐거운 카지노 경험을 즐길 수 있도록 도와줍니다.
온카마켓은 카지노와 관련된 정보와 소식을 한눈에 확인하고 다른 플레이어들과 소통하는 좋은 장소입니다. 카지노와 베팅에 관심이 있는 분들에게 유용한 정보와 커뮤니티를 제공하는 온카마켓을 즐겨보세요.
카지노 커뮤니티 온카마켓은 온라인 카지노와 관련된 정보를 공유하고 소통하는 커뮤니티입니다. 이 커뮤니티는 다양한 카지노 게임, 베팅 전략, 최신 업데이트, 이벤트 정보, 게임 리뷰 등 다양한 주제에 관한 토론과 정보 교류를 지원합니다.
온카마켓에서는 카지노 게임에 관심 있는 플레이어들이 모여서 자유롭게 의견을 나누고 경험을 공유할 수 있습니다. 또한, 다양한 카지노 사이트의 정보와 신뢰성을 검증하는 역할을 하며, 회원들이 안전하게 카지노 게임을 즐길 수 있도록 정보를 제공합니다.
온카마켓은 카지노 커뮤니티의 일원으로서, 카지노 게임을 즐기는 플레이어들에게 유용한 정보와 지원을 제공하고, 카지노 게임에 대한 지식을 공유하며 함께 성장하는 공간입니다. 카지노에 관심이 있는 분들에게는 유용한 커뮤니티로서 온카마켓을 소개합니다
2024總統大選民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
лучшие онлайн школы егэ – лучшая онлайн школа для подготовки к егэ. Курсы ЕГЭ и ОГЭ.
india pharmacy mail order India Post sending medicines to USA mail order pharmacy india indiapharm.llc
https://indiapharm.llc/# indianpharmacy com indiapharm.llc
r33tgame.pro
ленточное наращивание тюмень
купить роскошный особняк http://www.nedvipro13.ru.
r33tgame.org
какая онлайн школа лучше для подготовки к егэ – онлайн школы для подготовки к ЕГЭ лучшие. Школа ЕГЭ и ОГЭ.
best online canadian pharmacy: Canadian pharmacy best prices – best online canadian pharmacy canadapharm.life
r33tgame.com
Лаки Джет — это популярная игра на деньги, для которой характерно визуальное представление увеличения ставки пользователя лаки джет 1win
l2 essence
нарастить волосы тюмень
лучшая онлайн школа для подготовки к егэ – онлайн школа подготовка к ЕГЭ. Школа ЕГЭ и ОГЭ.
Выдаем займ под залог ПТС на карту! Авто и ПТС остаются у Вас! Быстрое одобрение выкуп недвижимости Надежный автоломбард в Воронеже
рейтинг онлайн школ для подготовки к егэ – онлайн школы подготовка к егэ. Школа ЕГЭ и ОГЭ.
pharmacy website india: Online India pharmacy – world pharmacy india indiapharm.llc
https://mexicopharm.com/# mexican pharmacy mexicopharm.com
最新的民調顯示,2024年台灣總統大選的競爭格局已逐漸明朗。根據不同來源的數據,目前民進黨的賴清德與民眾黨的柯文哲、國民黨的侯友宜正處於激烈的競爭中。
一項總統民調指出,賴清德的支持度平均約34.78%,侯友宜為29.55%,而柯文哲則為23.42%。
另一家媒體的民調顯示,賴清德的支持率為32%,侯友宜為27%,柯文哲則為21%。
台灣民意基金會的最新民調則顯示,賴清德以36.5%的支持率領先,柯文哲以29.1%緊隨其後,侯友宜則以20.4%位列第三。
綜合這些數據,可以看出賴清德在目前的民調中處於領先地位,但其他候選人的支持度也不容小覷,競爭十分激烈。這些民調結果反映了選民的當前看法,但選情仍有可能隨著選舉日的臨近而變化。
buying from online mexican pharmacy Best pharmacy in Mexico medicine in mexico pharmacies mexicopharm.com
п»їbest mexican online pharmacies: Medicines Mexico – mexico drug stores pharmacies mexicopharm.com
https://nasch.forum-top.ru/viewtopic.php?id=1946
https://31pokupki.rx22.ru/viewtopic.php?f=47&t=22877&p=27658
агентства элитной загородной недвижимости в подмосковье [url=https://www.nedvipro15.ru]https://www.nedvipro15.ru[/url].
Горячее и ленточное наращивание натуральных волос опытным мастером в Тюмени наращивание волос тюмень отзывы
Купить кондиционеры в Череповце по низким ценам. Сплит-системы с гарантией до 5 лет – https://vk.com/mastrklimat
http://mexicopharm.com/# mexico drug stores pharmacies mexicopharm.com
1WIN – Лучшая букмекерская контора с самыми большими коэффициентами 1Win casino
buying prescription drugs in mexico: mexican rx online – mexican rx online mexicopharm.com
http://mexicopharm.com/# reputable mexican pharmacies online mexicopharm.com
mexico pharmacy: Medicines Mexico – mexican pharmacy mexicopharm.com
https://www.press-release.ru/branches/telecom/virtual-number-of-bahrain/
jet casino вход
http://mexicopharm.com/# medicine in mexico pharmacies mexicopharm.com
buy prescription drugs from india: indian pharmacy to usa – Online medicine home delivery indiapharm.llc
buy deltasone 10mg pill order prednisone 10mg online cheap
Мне понадобилось финансирование для реализации моего долгосрочного проекта. Я искал выгодные условия и наткнулся на портал, где были собраны все новые МФО 2024 года. С помощью этого ресурса, я легко нашел подходящее предложение и получил долгосрочный займ на полгода. Процент по переплате оказался невелик, что сделало этот опыт удобным и выгодным.
Займы на карту онлайн от лучших МФО 2024 года – для получения займа до 30000 рублей на карту без отказа, от вас требуется только паспорт и именная банковская карта!
my canadian pharmacy rx Canadian online pharmacy canadian pharmacy online store canadapharm.life
купить коттедж в элитном районе https://nedvipro17.ru/.
ООО «АиРТИ» осуществляет индивидуальную разработку, изготовление и поставку современных высококачественных уплотнительных элементов и систем для ремонта промышленного гидро- и пневмооборудования Изготовление уплотнений
лаки джет 1вин
Có đa dạng loại game bắn cá, mỗi thể loại mang theo những quy tắc và phong cách chơi độc đáo. Vì vậy, người mới tham gia nên dành thời gian để nắm vững luật lệ của từng loại mà họ quan tâm. Chẳng hạn, việc hiểu rõ các nguyên tắc cơ bản như săn cá, tính điểm, loại mồi, cách đặt cược, hay quá trình đổi xèng là quan trọng để có trải nghiệm chơi tốt nhất.
Bên cạnh đó, khi tham gia vào trò chơi, cũng cần phải đảm bảo rằng bạn hiểu rõ các quy định cụ thể của từng cổng game để tránh những hiểu lầm không mong muốn.
Nhiều cổng game bắn cá hiện nay cung cấp lựa chọn bàn chơi miễn phí, mở ra cơ hội cho người chơi mới thâm nhập thế giới này mà không cần phải đầu tư xèng. Bằng cách tham gia vào các ván chơi không mất chi phí, người chơi có thể học được quy tắc chơi, tiếp xúc với các chiến thuật, hiểu rõ sự biến động của trò chơi, và khám phá các nền tảng và phần mềm mà không phải lo lắng về áp lực tài chính.
Quá trình trải nghiệm miễn phí sẽ giúp người chơi mới tích luỹ kinh nghiệm, xây dựng lòng tin vào bản thân, từ đó họ có thể chuyển đổi sang chơi với xèng mà không gặp phải nhiều khó khăn và ngần ngại.
Hiểu rõ về ý nghĩa của vị trí trong bàn săn cá là vô cùng quan trọng. Ví dụ, người chơi đặt mình ở vị trí đầu bàn phải đối mặt với thách thức của việc đưa ra quyết định mà không biết được cách mà đối thủ phía sau sẽ hành động. Ngược lại, người chơi ở vị trí giữa có đôi chút lợi thế khi phải đối mặt với ít áp lực hơn, có thể quan sát cách chơi của một số đối thủ trước đó, nhưng vẫn phải đưa ra quyết định mà không biết trước hành động của một số đối thủ khác. Người chơi ở vị trí cuối được ưu thế vì họ có thể quan sát và phân tích hành động của đối thủ trước khi tới lượt họ đưa ra quyết định. Nguyên tắc chung là, vị trí càng cao, người chơi càng có lợi thế trong
ban ca xeng.
canadian drugs online: Canada Drugs Direct – safe canadian pharmacies canadapharm.life
Sell Ebooks Online for Free with Koji’s Support https://withakoji.com/
colchicine brand india
http://canadapharm.life/# canadian pharmacy com canadapharm.life
buy medicines online in india: Online India pharmacy – top 10 pharmacies in india indiapharm.llc
Букмекерская контора 1Win является одним из лидеров рынка по широкому диапазону коэффициентов для спортивных мероприятий 1Win казино
https://canadapharm.life/# canadian pharmacy meds reviews canadapharm.life
куплю пентхаус башни http://www.nedviprof.ru.
non prescription ed pills ed pills online how to cure ed
https://levitradelivery.pro/# Generic Levitra 20mg
Онлайн магазин мобильных устройств: низкие цены и быстрая доставка
магазин – мобильный магазин.
tadalafil 20mg pills: Tadalafil 20mg price in Canada – tadalafil for sale from india
Изготовление закладных деталей
доступ к топовым нейросетям Perplexity Online OpenAI API в России без VPN
http://edpillsdelivery.pro/# best ed drug
cheap sildenafil 100mg: cheap sildenafil – 300mg sildenafil
проектирование металлоконструкций
1xbet промокод на сегодня 2024. Чтобы удовлетворить потребности бетторов и сделать процесс ставок максимально разнообразным нередко букмекерские конторы пытаются увеличить свой функционал, путем добавления специальных функций и предложений. Одним из лидеров среди популярных букмекеров на постсоветском пространстве по своим функциональным возможностям является 1хБет. Ввод витрина промокодов 1xbet позволяет получить увеличенную сумму бонуса. Для этого достаточно после создания аккаунта внести первый депозит (максимальная сумма бонусного начисления составляет 32 500 рублей). Можно использовать любой платёжный метод. Абсолютно бесплатный промокод 1xbet. На сегодня контора предлагает всем новичкам воспользоваться не только приветственным бонусом, но и получить дополнительные преференции. Эти льготы игрок получает в том случае, если внимательно отнесётся к процедуре регистрации на сайте. Ведь не все новички обращают внимание или понимают, о каких выгодах идёт речь, когда видят необязательное для заполнения поле «Введите промокод (при наличии)», находящееся в самом низу регистрационной формы. Оно есть при трёх способах получения аккаунта из четырёх возможных («В 1 клик», «По номеру телефона», «По e-mail»). А игнорировать его – это потерять дополнительные выгоды.
Completa el formulario con tus datos personales y contacto Otovix farmacia Guadalajara
prednisone 40mg uk buy generic prednisone 10mg
february 2025 printable calendar
https://tadalafildelivery.pro/# tadalafil 5mg tablets price
where to buy lexapro without rx
https://arwen-undomiel.com/forum/viewtopic.php?f=7&t=26517
Vardenafil price Generic Levitra 20mg Buy Vardenafil online
sildenafil 100mg buy online us without a prescription: Buy generic 100mg Sildenafil online – sildenafil prescription discount
Generic Levitra 20mg: Levitra 20 mg for sale – Levitra tablet price
https://griffinlnhz61604.loginblogin.com/30450520/firma-bukmacherska-mostbet-polska-rejestracja-bonusy-zakЕ‚ady-sportowe-i-kasyno-polskie-opinie-graczy-o-mostbet-pl
https://tadalafildelivery.pro/# tadalafil 100mg best price
where to get benemid pill
actos medication
generic cialis tadalafil: cheap generic tadalafil – tadalafil for sale from india
https://sildenafildelivery.pro/# sildenafil price 50 mg
https://soglasovanie-pereplanirovki-krvartiri.ru/
Ароматное натаральное нерафинированое масло. Масло подсолнечное Благо нерафинированное высшего сорта опт масло цена
ed medication: buy ed drugs online – over the counter erectile dysfunction pills
https://www.google.bj/url?q=https://hottelecom.net/
смотреть анал с разговорами на русском языке https://russ-anal-s-razgovorami.pro.
http://edpillsdelivery.pro/# erection pills
You are a very capable person!
As a Newbie, I am permanently exploring online for articles that can benefit me. Thank you
Thank you for great content, look forward to the continuation. meydan racing dubai
The Mellbet filter allows you to select a specific league, specify the amount of bets in the bet, the time before the start of the game and the minimum market odds https://blogfreely.net/frcbxxn3sy
tadalafil 2.5 mg tablets: Tadalafil 20mg price in Canada – tadalafil online australia
Comprar Liverin capsulas en Mexico. Cuanto cuestan en la Farmacia, Mercado Libre Liverin funciona o es estafa
https://www.google.gg/url?q=https://hottelecom.net/ua/
medicine for erectile ed pills online best ed pills at gnc
Koji: Your Secret Weapon for Self-Promotion Success https://withakoji.com/
скачать лаки джет
https://tadalafildelivery.pro/# buy tadalafil online australia
Kamagra 100mg price: cheap kamagra – Kamagra 100mg
https://www.google.lt/url?q=https://hottelecom.net/de/
IP-телефония — это уникальный тип связи, который функционирует через интернет. К интернет-каналу предъявляются минимальные требования:https://www.google.la/url?q=https://hottelecom.net/
Comprar Flexacil Ultra capsulas en Peru. Cuanto cuestan en la Farmacia Inkafarma, Mercado Libre? flexacil ultra para qué sirve?
medicine for impotence: ed pills online – mens erection pills
https://levitradelivery.pro/# Levitra online pharmacy
винлайн ру
ракета игра на деньги
EE88 là địa chỉ cược trực tuyến được yêu thích
nhất hiện nay, với vô vàn điểm mạnh hấp
dẫn game thủ chơi cá cược
http://paxlovid.guru/# paxlovid
п»їpaxlovid Buy Paxlovid privately paxlovid pill
Poker Full House
price for amoxicillin 875 mg: can you purchase amoxicillin online – can you buy amoxicillin uk
Освежить мягкую мебель в доме: Обновить новый вид старой мебели: Чем перетягивать мебель своими руками: Нюансы ткани для перетяжки мягкой мебели: секреты выбора
обивка мебели.
Перетяжка мягкой мебели: практичные советы для начинающих
Сертификат ISO 9001 (или ИСО 9001) подтверждает, что система менеджмента качества (СМК) соответствует всем требованиям стандарта ГОСТ Р ИСО 9001-2015 цена сертификата ISO
Craps Table Casino
Comprar Duston Gel en Paraguay. Cuanto cuesta farmacia punto farma, Mercado Libre? duston gel farmatodo
Big Multiplier Slots
http://paxlovid.guru/# paxlovid india
управление репутацией цена – необходимый инструмент в современных условиях ведения бизнеса и высокой конкуренции. reBooster – репутационное агентство полного цикла. Сформируем положительную репутацию в кратчайшие сроки, скорректируем негативную информацию в интернете. Работаем с различными сферами бизнеса, с у упором на финансовый сектор, медицинские услуги, fmcg и сферу услуг. На рынке с 2014 года.
stomach pain killer tablet buy cheap generic baycip
мебельный поролон https://vinylko11.ru.
you can try this out
serm продвижение – необходимый инструмент в современных условиях ведения бизнеса и высокой конкуренции. reBooster – репутационное агентство полного цикла. Сформируем положительную репутацию в кратчайшие сроки, скорректируем негативную информацию в интернете. Работаем с различными сферами бизнеса, с у упором на финансовый сектор, медицинские услуги, fmcg и сферу услуг. На рынке с 2014 года.
Гражданство Вануату
https://prednisone.auction/# buy prednisone online without a script
http://amoxil.guru/# buy amoxicillin over the counter uk
buy paxlovid online paxlovid pill paxlovid cost without insurance
Гражданство Вануату
Complimentary Drinks
uniswap https://uniswap.work/
prednisone 30 mg daily: buy prednisone online canada – buying prednisone mexico
http://clomid.auction/# buying generic clomid
lisinopril in breastfeeding
агентство сео https://www.prodvizhenie-sajtov15.ru.
Crema Relifix ?donde la venden en Mexico? Precio en una farmacia de Guadalajara Relifix funciona o es estafa
Вы можете заказать профессиональные пассажирские перевозки по Украине на нашем диспетчерском сайте Мюнхен – Черкаси
I want to show you one exclusive software called (BTC PROFIT SEARCH AND MINING PHRASES), which can make you a rich man, and maybe even a billionaire!
This program searches for Bitcoin wallets with a balance, and tries to find a secret phrase for them to get full access to the lost wallet!
Run the program and wait, and in order to increase your chances, install the program on all computers available to you, at work, with your friends, with your relatives, you can also ask your classmates to use the program, so your chances will increase tenfold!
Remember the more computers you use, the higher your chances of getting the treasure!
Thank me by donating if you have the opportunity.
Free Download:
https://t.me/+5ofvqnKhLrw0YTdi
репутация в сети serm – необходимый инструмент в современных условиях ведения бизнеса и высокой конкуренции. reBooster – репутационное агентство полного цикла. Сформируем положительную репутацию в кратчайшие сроки, скорректируем негативную информацию в интернете. Работаем с различными сферами бизнеса, с у упором на финансовый сектор, медицинские услуги, fmcg и сферу услуг. На рынке с 2014 года.
https://clomid.auction/# cost of cheap clomid
serm стратегии – необходимый инструмент в современных условиях ведения бизнеса и высокой конкуренции. reBooster – репутационное агентство полного цикла. Сформируем положительную репутацию в кратчайшие сроки, скорректируем негативную информацию в интернете. Работаем с различными сферами бизнеса, с у упором на финансовый сектор, медицинские услуги, fmcg и сферу услуг. На рынке с 2014 года.
Быстрое получение Гражданства Вануату от Официального Агента с Гарантией Гражданство Вануату
Приветствуем, уважаемые предприниматели, мы рады представить вашему вниманию революционный продукт от AdvertPro – SERM (Search Engine Reputation Management), инструмент управления репутацией в сети Интернет! В цифровом мире, репутация в интернете имеет важную роль в успехе любой компании. Не позволяйте, чтобы нежелательные отзывы и недоразумения повредили доверию к вашему бренду.
SERM от AdvertPro – это не просто инструмент в вашем арсенале для укрепления положительного имиджа вашей компании в интернете. С помощью нашей системы, вы получите полное управление над тем, что рассказывают о вашем бизнесе ваши клиенты. SERM просматривает онлайн-упоминания и способствует распространению позитивных отзывов, в то же время уменьшая влияние негативной информации. Мы применяем современные алгоритмы поиска, чтобы вы всегда оставались на шаг впереди.
Представьте себе, что каждый поиск о вашей компании приводит к позитивным отзывам: позитивные комментарии, убедительные истории успеха и отличные рекомендации. С SERM от AdvertPro это реальность, находящаяся в пределах досягаемости каждому предприятию. Более того, наш инструмент дает возможность использовать ценной обратной связью для дальнейшего развития вашего бизнеса.
Не упустите возможность повысить свою деловую репутацию. Свяжитесь с нами уже сейчас для запроса профессиональной консультации и запуска сервиса SERM. Позвольте миллионам потенциальных клиентов знакомиться только с лучшим о вашем бизнесе каждый раз, когда они обращаются в интернет за информацией. Начните новую страницу в управлении репутацией в интернете – выберите AdvertPro!
Сайт: https://serm-moscow.ru/ – интернет репутация.
best contraceptive pills for acne brand accutane 20mg dermatologist acne pills
Когда мне понадобилось срочно 30 тысяч рублей на ремонт автомобиля, я нашел отличное решение на mikro-zaim-online.ru. Сайт предложил мне удобный займ с плохой кредитной историей и просрочками, благодаря чему я смог быстро и без лишних вопросов уладить свои финансовые проблемы.
Однажды мне срочно понадобились средства на ремонт холодильника. Я нашел выход, получив займы с просрочками на сайте mikro-zaim-online.ru. Это быстрое и простое решение помогло мне в сложной ситуации.
лучшие палатки для кемпинга. лучшие производители палаток для кемпинга. палатки для кемпинга 4 местные рейтинг.
http://www.51bonjour.com/discuz/home.php?mod=space&uid=3045731
uniswap https://uniswap.work/
Курсы рилс. https://rils-kursy-besplatno.ru/ Обучение в Instagram.
can i buy amoxicillin online: Amoxicillin 500mg buy online – amoxicillin 500 mg price
Быстрый и надежный VPN через Telegram бота. Без отвалов. Без ограничения скорости и трафика впн корея
can you buy generic propecia online
Исследуй Жанры: Скачивай и Слушай Музыку Разных Стилей в 2024 Году!
Погрузись в мир разнообразия музыкальных жанров 2024 года! С нашей платформой скачать музыку разных стилей – легко и удобно. От джаза до техно, от хип-хопа до классики – выбирай, слушай, скачивай. Исследуй новые грани звуков и обогати свой музыкальный вкус!
купить александритовый лазер для эпиляции цена https://alexanritovie-laser.ru/
Как светодиодный ночник поможет детям снять стресс и улучшить качество сна http://frpworld.com/modules.php?name=Journal&file=display&jid=11336
https://amoxil.guru/# amoxicillin 750 mg price
paxlovid price paxlovid price without insurance paxlovid buy
Музыка 2024 – это путеводитель по современному звуковому ландшафту. С нашим сервисом скачивания песен вы всегда на шаг впереди. Слушать песни и создавать свой собственный музыкальный мир стало проще – доверьтесь новинкам этого года.
Сертификат ISO 9001 – это официальный документ, гарантирующий качество выпускаемого товара, продукта/оказываемой услуги, а так же высокую степень надежности Вашего предприятия стоимость сертификации ИСО 9001
фракционный лазер цена https://laseri-co2.ru/
Наши блины для штанги подходят для коммерческого и домашнего использования. Они используются на силовых тренировках для выполнения разных упражнений на все мускулы. Диски выполнены из цельного куска стали и покрыты резиной. Данная обработка предотвращает возникновение ржавчины и снижает звуковые эффекты в процессе тренинга, а это особенно актуально при использовании снарядов дома. Посадочное кольцо также выполнено из металла, но не обрезинено. Это позволяет избежать повреждений резинового слоя при постоянном снятии/навешивании на гриф, так как само покрытие с ним не взаимодействует. Помимо этого, за счет гладкой втулки блины для штанги хорошо скользят, что позволяет быстро менять вес. У нас вы сможете найти диски нужного веса и диаметра для получения высоких силовых достижений.
https://prednisone.auction/# buy prednisone online fast shipping
Паспорт Вануату
Паспорт Вануату
http://dvigateliduyunova.ru
how much is lexapro in canada
synthroid tablets dosage
need to buy prednisone 20mg for humans
Drug information leaflet. Effects of Drug Abuse.
cheap amoxil
Some information about drug. Get information now.
электрокарниз двухрядный https://www.vc.ru/u/2465162-elektrokarnizy-prokarniz/907958-elektrokarnizy-upravlenie-svetom.
http://dvigateliduyunova.ru
Мировые музыкальные тенденции 2024 года:
Современная музыка в 2024 году представляет собой удивительное сочетание стилей и направлений. Электроника, рэп, поп и рок сливаются в уникальные композиции, которые становятся хитами. Скачать музыку 2024 года – это открыть для себя новые таланты и направления. Слушайте песни разных исполнителей, наслаждайтесь разнообразием и экспериментами в звучании.
buy cytotec: buy misoprostol – п»їcytotec pills online
zestril 20 mg price High Blood Pressure lisinopril 5 mg brand name in india
александритовый лазер цена аппарата https://alexanritovie-laser.ru/
what is trazodone for dogs
https://finasteride.men/# propecia sale
diltiazem salbe
ahlan aqaba scuba diving centre
Saan makakabili ng Diabetin capsules sa Pilipinas? Pagsusuri, opinyon, pagsusuri is diabetin approved by fda
https://furosemide.pro/# furosemide
lisinopril 2.5 mg tablet: buy lisinopril canada – lisinopril 12.5 mg 10 mg
Интернет казино Glory в Турции может предложить поистине божественный страстный опыт для играющих https://pigmc.ru/viewtopic.php?id=28952#p425959
со2 лазер купить цена https://laseri-co2.ru/
Наши диски для штанг и гантелей подходят для использования в спортзале и домашних условиях. Они применяются на силовых занятиях для выполнения различных упражнений на все тело. Диски выполнены из цельной стали и покрыты слоем резины. Данная обработка защищает металл от коррозии и снижает звуковые эффекты в процессе тренировок, а это особенно актуально при домашнем использовании. Посадочное отверстие также изготовлено из металла, но не обрезинено. Это дает возможность избежать повреждений резинового слоя при постоянном снятии/навешивании на гриф, поскольку само покрытие с ним не взаимодействует. Кроме того, благодаря гладкой втулке блины для штанги хорошо скользят, за счет чего можно быстро менять нагрузку. У нас вы сможете купить диски нужного веса и диаметра посадочного отверстия для получения качественных силовых достижений.
http://misoprostol.shop/# cytotec abortion pill
diltiazem cd
aqaba bedouin dive
csgo open
Лучшие репетиторы по русскому языку, математике, литературе, иностранным языкам, физике, химии и обществознанию подготовят к ОГЭ и ЕГЭ.
распил ЛДСП
cheap propecia: propecia online – order generic propecia price
распил ДСП
price of zithromax
https://misoprostol.shop/# buy cytotec pills online cheap
get lexapro price
dapagliflozin spc
furosemide: Buy Lasix No Prescription – furosemide
advair diskus tablet
is ashwagandha good for you
cheapest doxycycline without prescrtiption
?Donde comprar Duston Gel en Uruguay? ?Cuanto cuesta? Opiniones y criticas, ?verdad o estafa? duston gel farmacia
Сертификат ISO 9001 – лучший способ поднять престиж компании и выйти на внешний рынок сертификация iso 9001
https://finasteride.men/# buying generic propecia
http://azithromycin.store/# zithromax 250 mg australia
allergy medication better than allegra medrol cheap is claritin stronger than benadryl
Misoprostol 200 mg buy online: cheap cytotec – Cytotec 200mcg price
Medicine information for patients. Cautions.
propecia generic
Some what you want to know about medication. Read here.
Придайте индивидуальность вашей мебели с помощью перетяжки
перетяжка мягкой мебели https://peretyazhka-mebeli-v-minske.ru/.
Medicines prescribing information. Drug Class.
lyrica
Some what you want to know about pills. Get here.
zithromax capsules: Azithromycin 250 buy online – zithromax over the counter uk
pin up ставка на спорт https://pinupbets.kz/
http://misoprostol.shop/# cytotec pills online
Medication information leaflet. Drug Class.
sildigra
Some trends of medicines. Get information now.
Engage into the Infinite World of Minecraft with Us!
On our website, you’ll find everything you need for an unforgettable adventure in Minecraft: servers with a range of mods, helpful tips, and exciting articles about the planet of blocky adventures! http://jbstars.org/member.php?action=profile&uid=9761
doxycycline acne buy
cost generic propecia pill: Buy finasteride 1mg – cost propecia prices
Drugs information. What side effects?
cleocin
Actual information about medication. Get now.
Создайте свой уголок покоя с мягкой мебелью
перетяжка мебели https://murom-mebel-tula.ru/.
https://finasteride.men/# get cheap propecia no prescription
http://bbsxy.90yk.com/home.php?mod=space&uid=362636
Аренда манипулятора в Москве: Безопасность и Эффективность Грузоперевозок
Drugs information leaflet. Cautions.
lyrica
Everything information about meds. Get now.
buy cytotec over the counter: buy cytotec over the counter – cytotec abortion pill
Уникальный дизайн мебели с перетяжкой
ремонт мягкой мебели перетяжка диванов.
best prescription heartburn medicine bactrim buy online
аудит продвижения сайта https://newsvo.ru/news/82798.
Medicament information for patients. Drug Class.
where can i buy singulair
Best information about medicines. Get now.
http://furosemide.pro/# buy lasix online
http://lisinopril.fun/# buy lisinopril online uk
zestril tab 10mg: High Blood Pressure – zestril cost price
can u buy doxycycline over counter
can ibuprofen help stomach ache avapro 300mg without prescription
Pills prescribing information. Brand names.
eldepryl
Everything information about pills. Read here.
На сайте нашего похоронного бюро вы можете ознакомиться с основными тарифами на погребение служба ритуальных услуг
buy cytotec over the counter: Misoprostol best price in pharmacy – п»їcytotec pills online
https://lisinopril.fun/# lisinopril 5 mg pill
Drug information sheet. Drug Class.
norvasc without a prescription
Some what you want to know about pills. Get information here.
Быстрый ремонт холодильника без потери качества
ремонт холодильников ремонт холодильника.
Medicine information. Generic Name.
avodart
Actual trends of medicament. Get now.
cost of lisinopril 40 mg: url lisinopril hctz prescription – lisinopril no prescription
http://www.hngaosha.com/space-uid-22383.html&do=profile
https://azithromycin.store/# zithromax for sale us
where can i buy prednisone 5mgover the counter
娛樂城
Сердце музыки бьется в такт новым волнениям 2024 года. С каждым днем в мире звуков появляются новые песни, призванные поднять настроение и вдохновить. Если вы ищете способ сделать свою жизнь более яркой, не пропустите возможность скачать песни 2024 года. Это не просто музыка – это эмоции, переносящие вас в мир звуков и идей.
В эру цифровых возможностей скачать песни 2024 – это как создать свой музыкальный мир, наполненный яркими красками и мелодическим разнообразием. Новые песни становятся личным саундтреком каждого, открывая двери в таинственный лабиринт звуков. Погрузитесь в уникальный опыт исследования современной музыки.
https://pomoguvam.ru/
lasix online: lasix medication – lasix 100 mg tablet
Drugs information leaflet. Long-Term Effects.
celebrex pill
Actual what you want to know about pills. Get now.
Музыкальная индустрия 2024 года на пике своего развития, и новинки музыки поражают своим разнообразием и оригинальностью. Популярные песни 2024 становятся истинными гимнами современности. Желающим погрузиться в этот музыкальный океан следует слушать песни 2024 и скачать песни 2024, чтобы иметь доступ к самым актуальным мелодиям и ритмам.
buy generic isotretinoin 40mg accutane tablet buy isotretinoin 10mg generic
С течением времени технологии MP3 преобразили способ, которым мы слушаем музыку. Сегодня скачать песни 2024 стало проще, чем когда-либо, позволяя наслаждаться новинками музыкальной индустрии в любое время. Популярные песни 2024 в формате MP3 стали своеобразным искусством, с которым можно находить вдохновение и радость.
Мы предлагаем спортивное оборудование и инвентарь в ассортименте: грузоблочные машины и нагружаемые блинами, устройства для занятий с собственным весом, скамьи и стойки, а также гантели, штанги, гири, составляющие для них и другой инвентарь. Для изготовления оборудования используются первоклассные материалы – сталь, качественные наполнители и искусственная кожа для мягких частей (сидений, спинок и пр.), безопасные порошковые краски для покрытия конструкций из металла. Наше спортивное силовое оборудование рассчитано на высокие нагрузки в режиме нон-стоп, благодаря чему подходит как для небольших тренажерных залов, так и для больших фитнес-центров с высокой проходимостью. Для домашних тренировок отлично подойдут варианты для работы со своей массой, скамьи, разборные гантели, штанги, гири.
https://azithromycin.store/# buy zithromax without prescription online
http://finasteride.men/# order generic propecia without rx
Pills information sheet. Cautions.
where to buy nolvadex
Everything about pills. Get information now.
lasix side effects: Buy Furosemide – lasix 40 mg
Medicines information. Brand names.
pregabalin
All what you want to know about pills. Read here.
accutane sale buy isotretinoin 40mg online cheap accutane 10mg uk
hi! Онлайн Займы на тинькофф
[url=https://zaimy-na-kartu-tinkoff.ru/]https://zaimy-na-kartu-tinkoff.ru/[/url]
http://misoprostol.shop/# buy cytotec online fast delivery
doxycycline over the counter canada
viagra originale in 24 ore contrassegno: viagra prezzo – miglior sito per comprare viagra online
viagra subito: sildenafil 100mg prezzo – viagra acquisto in contrassegno in italia
Pills information for patients. Generic Name.
get fluoxetine
Everything trends of medicines. Get information here.
http://sildenafilitalia.men/# viagra pfizer 25mg prezzo
Drugs information for patients. What side effects?
cost retrovir
Actual news about drugs. Read information here.
viagra naturale in farmacia senza ricetta: viagra online siti sicuri – gel per erezione in farmacia
mostbet online
diplomanof.com
Calorico forte capsules in south africa, where to buy? Opinions and review calorico forte testimonials
https://www.top-diplom.ru/
Наша компания предлагает производство спортивного оборудования в ассортименте: грузоблочные тренажеры и на свободных весах, варианты для работы со своим весом, скамьи и стойки, а также гантели, штанги, гири, составляющие для них и другой инвентарь. Для производства тренажеров применяются первоклассные материалы – сталь, качественные наполнители и искусственная кожа для мягких частей (сидений, спинок и пр.), безопасные порошковые составы для окрашивания конструкций из металла. Наше силовое оборудование предназначено для интенсивной эксплуатации в круглосуточном режиме, поэтому подходит как для небольших тренажерных залов, так и для больших фитнес-клубов с высокой посещаемостью. Для домашнего тренинга подойдут варианты для работы с собственным весом, скамьи, разборные гантели, штанги, гири.
Берите Микрозаймы онлайн на Tinkof
https://zaimy-na-kartu-tinkoff.ru/
сайдинг под блок хаус
diplomanof.com
Аренда манипулятора даёт возможность сократить затраты на выполнение строительных и транспортных работ, требующих поднятия, спуска, разгрузки и перемещения тяжелых грузов. Эту технику называют еще самогруз или воровайка.
siti sicuri per comprare viagra online: viagra online siti sicuri – viagra generico in farmacia costo
http://farmaciaitalia.store/# comprare farmaci online con ricetta
как выбрать хостинг для интернет магазина https://www.sidashdmytro.com/kak-vybrat-hosting-saytov/.
Motion Energy gel in Nigeria, where to buy and how much does it cost? Price Motion Energy cream Price
https://globalcatalog.com/mostbet1be.br
viagra naturale: viagra online spedizione gratuita – dove acquistare viagra in modo sicuro
п»їhttps://allaboutschool.activeboard.com/t70309324/promo-code-of-the-rate/
alternativa al viagra senza ricetta in farmacia: viagra senza ricetta – gel per erezione in farmacia
http://tadalafilitalia.pro/# farmacie on line spedizione gratuita
doxycycline 100 mg buy
Medicament information for patients. Short-Term Effects.
motrin pill
All news about medication. Get here.
п»їfarmacia online migliore: farmacia online migliore – acquistare farmaci senza ricetta
https://tadalafilitalia.pro/# comprare farmaci online all’estero
Берите Онлайн Займы на Tinkoff
https://mikrozaimy-na-tinkoff.ru/
Comprar Sustarox crema en Peru. Precio en Inkafarma, Mercado Libre Sustarox Crema Peru
miglior sito dove acquistare viagra: alternativa al viagra senza ricetta in farmacia – viagra generico prezzo piГ№ basso
Купить страховку на квартиру, онлайн – оформите добровольное страхование квартиры от затопления соседей, ремонта, а также вы можете застраховать имущество в квартире – оформите договор страхования квартиры 1 Corinthians in the Bible (The Book of 1 Corinthians in the Bible – KJV) Free Bible Online
virtual visit online physician belsomra sleep prescription online
технический аудит сайта стоимость https://www.seo-live.com/novosti-rinka/chto-delat-esli-vi-popalis-na-udochku-moshennikov-v-seti.
https://kamagraitalia.shop/# migliori farmacie online 2023
гама казино регистрация
https://bellezza4u.ru/
farmacia online piГ№ conveniente: farmacia online miglior prezzo – farmacia online migliore
SMM
Основная функция: Автоматизация и оптимизация процесса продвижения в социальных сетях.
Поддерживаемые платформы: Facebook, Instagram, Twitter, LinkedIn, VK.
Особенности:
Аналитика: Предоставление детальной статистики по каждой социальной сети, включая анализ аудитории, охват, вовлеченность и эффективность контента.
Автоматизация публикаций: Планировщик публикаций позволяет создавать, графиковать и автоматически размещать контент на всех поддерживаемых платформах.
Генератор контента: Использует искусственный интеллект для создания привлекательного и релевантного контента, адаптированного под каждую социальную сеть.
Интерактивные опросы и голосования: Увеличение вовлеченности аудитории через интерактивные функции, такие как опросы и голосования.
Подбор ключевых слов и хэштегов: Оптимизация постов с помощью анализа и подбора наиболее эффективных ключевых слов и хэштегов.
Управление сообществом: Инструменты для модерации и управления взаимодействиями в социальных сетях, включая отслеживание комментариев и сообщений.
Безопасность и конфиденциальность: Высокий уровень безопасности и защиты личных данных.
Интеграция с другими сервисами: Возможность интеграции с CRM-системами, Google Analytics и другими инструментами цифрового маркетинга.
Пользовательский интерфейс: Простой и интуитивно понятный интерфейс с поддержкой многоязычности.
Поддержка и обучение: Подробные руководства пользователя и видеоуроки, а также круглосуточная поддержка клиентов.
Микрозаймы онлайн на карту
https://minizajmy-online.ru/
online doctors who prescribe zolpidem order provigil 100mg
cat casino
https://kamagraitalia.shop/# migliori farmacie online 2023
migliori farmacie online 2023 п»їfarmacia online migliore farmacie online sicure
farmacia online migliore: farmacia online migliore – acquistare farmaci senza ricetta
viagra online in 2 giorni: sildenafil 100mg prezzo – le migliori pillole per l’erezione
Medication information for patients. Short-Term Effects.
amoxil
Best trends of medicament. Read information now.
amoxicillin 250mg pills purchase amoxicillin online cheap generic amoxil
doxycycline over the counter sale online
Строительная экспертиза в Москве от организации Строительная экспертиза недорого и с гарантией.
http://sildenafilitalia.men/# viagra online consegna rapida
Играйте в лучшие онлайн казино 2024 года, который входят в рейтинг лучших. Топ казино дарит выгодные бонусы на депозит, выплаты быстрые, регистрация на официальном сайте моментальная рейтинг казино
К 5-летию свадьбы решил подарить жене нечто особенное – букет из искусственных цветов. Заказал его на “Цветов.ру” и добавил легкости и веселья в нашу гармоничную жизнь. Спасибо за творческий подход! Советую! Вот ссылка https://extralogic.ru/irkutsk/ – цветов
Просто решил порадовать свою девушку без повода. Заказал букет на “Цветов.ру” с доставкой на ее работу. Увидев цветы, она была в восторге. Очень доволен выбором сервиса и качеством обслуживания. Советую! Вот ссылка https://mscs-boost.ru/irkutsk/ – купить букет цветов
п»їfarmacia online migliore: kamagra oral jelly – farmacia online miglior prezzo
технический аудит сайта заказать http://joomlaru.com/stati/prodvizhenie-sajta.html/.
cheap amoxicillin tablets amoxil pills buy amoxil 1000mg online cheap
Meds information. Drug Class.
lyrica buy
Best about pills. Get here.
http://avanafilitalia.online/# comprare farmaci online all’estero
https://calculum.net/index.php/es/foro/general/191-detailed-overview-and-description-of-exante-broker
acquisto farmaci con ricetta: kamagra gel – farmacia online senza ricetta
buying doxycycline online uk
Займы на карту
https://mikrozaimy-na-kartu.ru/
http://mexicanpharm.store/# buying from online mexican pharmacy
world pharmacy india: online shopping pharmacy india – india pharmacy mail order
55five daftar
https://55five.games
canadian pharmacy no scripts: canadian pharmacy world – my canadian pharmacy
https://oknaplusdnr.com/
двери стальные входные технические https://texnicheskiedveri.ru/.
https://www.soymexiquense.com/foro/reportero-ciudadano/3140-all-about-exante-broker
buy lisinopril 20 mg without a prescription
seo продвижение сайта http://dimox.name/chto-takoe-rerajting/.
Website
medication canadian pharmacy legitimate canadian pharmacy online legit canadian online pharmacy
https://mexicanpharm.store/# pharmacies in mexico that ship to usa
Relifix Crema: La Eleccion Ideal en Guatemala para Cuidado de la Piel – Precios y Puntos de Venta en Farmacias Relifix Pomada Guatemala
pharmacy rx world canada: precription drugs from canada – buy canadian drugs
Website
cordarone hydrochloride
смотреть порно
Renowned online bookmaker, offers a wide range of betting options on various sports, including football https://www.gunma.top/bbs/board.php?bo_table=free&wr_id=1582418
canadapharmacyonline legit: maple leaf pharmacy in canada – canada drugs online review
перетяжка минск https://peretyazhka-bel.ru/.
Создание и продвижение сайтов в Москве. Индивидуальный подход. Эффективные стратегии. Завоюйте интернет с нами. Звоните и заказывайте!
http://indiapharm.life/# legitimate online pharmacies india
cheapest online pharmacy india: top 10 online pharmacy in india – reputable indian online pharmacy
prasugrel pharmacy
purple pharmacy mexico price list: buying from online mexican pharmacy – mexico drug stores pharmacies
Подготовка и сдача бухгалтерской, налоговой и статистической отчетности в срок бухгалтерские фирмы
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
http://mexicanpharm.store/# mexican rx online
india pharmacy mail order: cheapest online pharmacy india – indian pharmacy paypal
Интернет — ваш рынок. Мы создаем сайты, которые работают. Продвижение для успеха. Заявите о себе в виртуальном мире с созданием и продвижением сайтов
ft mobic
canadian mail order pharmacy canadian pharmacy cheapest pharmacy canada
http://canadapharm.shop/# canadian pharmacy 24h com
http://suntent.kr/bbs/board.php?bo_table=free&wr_id=268626
legitimate canadian pharmacy: canadian pharmacy 365 – legal to buy prescription drugs from canada
https://www.tribuneindia.com/news/impact-feature/youtube-booster-the-best-way-to-increase-subscribers-on-your-youtube-channel-575585
http://canadapharm.shop/# canadian pharmacy
medication from mexico pharmacy: mexican drugstore online – mexican mail order pharmacies
ed meds online canada: adderall canadian pharmacy – onlinecanadianpharmacy
песок с доставкой
purple pharmacy mexico price list: reputable mexican pharmacies online – pharmacies in mexico that ship to usa
https://canadapharm.shop/# my canadian pharmacy
legit canadian pharmacy: reputable canadian online pharmacy – canadian pharmacy king
azithromycin 500mg uk order azithromycin online cost zithromax
Березин Андрей Евроинвест http://newprospect.ru/news/interview/andrey-berezin-est-mnogo-interesnykh-veshchey-kotorye-trebuyut-moego-vnimaniya/
женщины, которые не оставляют равнодушными
официальный сайт pin up https://pinupcasinovendfsty.dp.ua.
для фотографий
pin up 777 https://pinupcasinovendfsty.dp.ua.
https://canadapharm.shop/# buying drugs from canada
gabapentin tablet buy gabapentin 100mg sale
секс порно видео онлайн бесплатно
india online pharmacy: pharmacy website india – pharmacy website india
order azithromycin 500mg buy azithromycin sale buy azithromycin 250mg without prescription
Жаркие pinup-сцены
пин ап играть [url=https://www.pinupcasinovendfsty.dp.ua/]https://www.pinupcasinovendfsty.dp.ua/[/url].
mexican pharmaceuticals online [url=http://mexicanpharm.store/#]п»їbest mexican online pharmacies[/url] mexican pharmaceuticals online
mexican mail order pharmacies: mexico pharmacies prescription drugs – best online pharmacies in mexico
https://autohits.by/
http://indiapharm.life/# buy prescription drugs from india
mexico drug stores pharmacies: medicine in mexico pharmacies – mexican rx online
order neurontin 100mg pills gabapentin 600mg generic
Medication information sheet. Generic Name.
sildigra cheap
Some news about drug. Read now.
https://beforeitsnews.com/business/2024/01/increasing-views-on-youtube-how-it-affects-the-level-of-viewer-engagement-view-boost-youtube-3705688.html
long term car rental Dubai
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
buy arimidex online canada
Chevrolet for rent dubai
Dubai, a city of grandeur and innovation, demands a transportation solution that matches its dynamic pace. Whether you’re a business executive, a tourist exploring the city, or someone in need of a reliable vehicle temporarily, car rental services in Dubai offer a flexible and cost-effective solution. In this guide, we’ll explore the popular car rental options in Dubai, catering to diverse needs and preferences.
Airport Car Rental: One-Way Pickup and Drop-off Road Trip Rentals:
For those who need to meet an important delegation at the airport or have a flight to another city, airport car rentals provide a seamless solution. Avoid the hassle of relying on public transport and ensure you reach your destination on time. With one-way pickup and drop-off options, you can effortlessly navigate your road trip, making business meetings or conferences immediately upon arrival.
Business Car Rental Deals & Corporate Vehicle Rentals in Dubai:
Companies without their own fleet or those finding transport maintenance too expensive can benefit from business car rental deals. This option is particularly suitable for businesses where a vehicle is needed only occasionally. By opting for corporate vehicle rentals, companies can optimize their staff structure, freeing employees from non-core functions while ensuring reliable transportation when necessary.
Tourist Car Rentals with Insurance in Dubai:
Tourists visiting Dubai can enjoy the freedom of exploring the city at their own pace with car rentals that come with insurance. This option allows travelers to choose a vehicle that suits the particulars of their trip without the hassle of dealing with insurance policies. Renting a car not only saves money and time compared to expensive city taxis but also ensures a trouble-free travel experience.
Daily Car Hire Near Me:
Daily car rental services are a convenient and cost-effective alternative to taxis in Dubai. Whether it’s for a business meeting, everyday use, or a luxury experience, you can find a suitable vehicle for a day on platforms like Smarketdrive.com. The website provides a secure and quick way to rent a car from certified and verified car rental companies, ensuring guarantees and safety.
Weekly Auto Rental Deals:
For those looking for flexibility throughout the week, weekly car rentals in Dubai offer a competent, attentive, and professional service. Whether you need a vehicle for a few days or an entire week, choosing a car rental weekly is a convenient and profitable option. The certified and tested car rental companies listed on Smarketdrive.com ensure a reliable and comfortable experience.
Monthly Car Rentals in Dubai:
When your personal car is undergoing extended repairs, or if you’re a frequent visitor to Dubai, monthly car rentals (long-term car rentals) become the ideal solution. Residents, businessmen, and tourists can benefit from the extensive options available on Smarketdrive.com, ensuring mobility and convenience throughout their stay in Dubai.
FAQ about Renting a Car in Dubai:
To address common queries about renting a car in Dubai, our FAQ section provides valuable insights and information. From rental terms to insurance coverage, it serves as a comprehensive guide for those considering the convenience of car rentals in the bustling city.
Conclusion:
Dubai’s popularity as a global destination is matched by its diverse and convenient car rental services. Whether for business, tourism, or daily commuting, the options available cater to every need. With reliable platforms like Smarketdrive.com, navigating Dubai becomes a seamless and enjoyable experience, offering both locals and visitors the ultimate freedom of mobility.
Онлайн Займы на карту
https://mikrozajmy-na-kartu.ru/
SV388 được thành lập từ năm 2002. Sau hơn 20 phát triển mạnh mẽ, nhà cái này đã có cho mình thành công lớn trong lĩnh vực cá cược
đá gà campuchia, đá gà thomo.
https://canadapharm.shop/# safe online pharmacies in canada
https://www.dolphin-academy.com/wp-content/plugins/wp-file/?1xbet_promo_code_106.html
reputable indian pharmacies: online shopping pharmacy india – reputable indian pharmacies
Березин Андрей Евроинвест http://asninfo.ru/persons/459-berezin-andrey-valeryevich/.
https://shkolaiskusstw.ru/images/art/melbet_promokod_24.html
https://gamma.app/docs/MelBet-AUF888-15-000–1tx7ay0zlpc3mpl?mode=doc
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
http://canadapharm.shop/# reliable canadian pharmacy reviews
buying from online mexican pharmacy: mexican mail order pharmacies – pharmacies in mexico that ship to usa
Pin-Up es una casa de apuestas internacional con licencia de Curazao, que ahora opera legalmente tambien en Peru https://wypytaj.pl/Profil/Hekylizyk
Телеграм Кент Казино
Привлекайте клиентов с нашими сайтами. Эффективное создание и продвижение сайтов в Москве. Уникальный дизайн, мощная видимость. Заказывайте прямо сейчас!
Ваш бизнес заслуживает лучшего сайта. Наша команда предлагает профессиональное создание и продвижение сайтов в Москве. Развивайтесь вместе с нами!
Кент Казино официальный ТГ
ПокерОк
сайт GGpokerOK
https://autohits.by/
http://canadapharm.shop/# ed drugs online from canada
indian pharmacy online: indian pharmacy online – mail order pharmacy india
maple leaf pharmacy in canada my canadian pharmacy reviews reddit canadian pharmacy
buy generic prednisone 20mg
3a娛樂城
http://indiapharm.life/# buy prescription drugs from india
https://nolvadex.pro/# nolvadex generic
гостевой дом в Анапе https://otdyh-vanape.ru/
Березин Андрей Евроинвест https://www.neva.today/person/andrej-valerevich-berezin-sovladelecz-investiczionnoj-kompanii-evroinvest-458141/.
https://sterilno.com/inc/pgs/promokod-1xbet-bonus.html
http://forum.gold-forum.ru/index.php?showtopic=38581&st=10&gopid=514264&#entry514264
dapagliflozina para que sirve
http://prednisonepharm.store/# canadian online pharmacy prednisone
tamoxifen for men: tamoxifen premenopausal – nolvadex for sale amazon
amoxicillin and alcohol
With many hundreds of Forex / CFD brokers to choose from globally, finding the right broker for you can seem an impossible challenge best forex trading
недорогие женские пуховики
stromectol stromectolice
mzpro register
mzpro login
mzpro daftar
buat duit online
buat duit guna handphone
mzpro trusted 2024
azipro over the counter order azipro online cheap azithromycin drug
GGpokerOK
скачать клиент Покерок для ПК
mobic 20 mg price
http://clomidpharm.shop/# how can i get clomid
Свежее дэдди казино зеркало гарантирует доступ к вашим избранным играм.
ashwagandha for sleep
zithromax 1000 mg online: where can i buy zithromax in canada – zithromax 500 mg for sale
brand azipro 250mg azipro 500mg pills order azithromycin pills
actos warnings
buy furosemide generic furosemide 100mg usa
娛樂城
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
colchicine market
https://zithromaxpharm.online/# zithromax antibiotic without prescription
mobic for seizures
Luxury car rental dubai
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
can i get cheap zerit without rx
smm агентство https://smm-almaty.kz/
furosemide cost cost lasix 40mg
generic tamoxifen: low dose tamoxifen – tamoxifen benefits
side effects of colchicine
Отдых в Анапе https://otdyh-vanape.ru/
Восстановим красоту вашей мебели. Эффективная химчистка мебели без риска повреждений. Заботимся о вашем уюте.
where to get generic cialis soft tabs without prescription
столбик дорожный сигнальный с3 https://idn300.ru/catalog/signalnye_stolbiki/signalnyy_stolbik_s3/
buy cytotec over the counter buy cytotec pills order cytotec online
С тех пор, как я решил перейти на здоровое питание, моя жизнь кардинально изменилась. На моей кухне появилась соковыжималка ручная от компании ‘Все соки’. С её помощью я начал каждое утро с свежевыжатого сока, что несказанно радует меня. Спасибо, ‘Все соки’! https://blender-bs5.ru/collection/ruchnye-shnekovye-sokovyzhimalki – Соковыжималка ручная – лучшее, что со мной случилось!
doxycycline hyclate 150mg buy online
https://clomidpharm.shop/# cost of cheap clomid tablets
how to get advair diskus without dr prescription
Березин Андрей Евроинвест https://www.mainfin.ru/persona/berezin-andrey-valeryevich/.
cefixoral
tamoxifen medication: tamoxifen menopause – nolvadex side effects
cost generic cialis soft tabs pills
synthroid name brand vs generic
http://zithromaxpharm.online/# how to get zithromax over the counter
precose how long to work
Обслуживание интернет-ресурса является комплексной услугой, которая обеспечивает поддержание его составляющих для стабильного функционирования. Выполняемая специалистами веб поддержка сайта от https://teh-podderzhka-saita.ru продвигает ресурс на более высокий уровень, что делает бизнес прибыльным и успешным. Выполняемые процедуры позволяет компаниям предлагать своей целевой аудитории только актуальную информацию, взаимодействовать с ней оперативно, безопасно и продуктивно. Такой ресурс всегда доступен и удобен для посетителей, клиентов и ПС, а это приводит к увеличению продаж продукции или услуг и улучшает популярность организации. Важно, чтобы все осуществляли профессионалы, поскольку мероприятия, которые выполнены непрофессионально, неблагоприятно скажутся на его работоспособности и юзабилити, а также увеличат риск возникновения вредоносных программ и кибератак.
side effects of finasteride
zithromax 1000 mg pills: how to get zithromax over the counter – buy zithromax online
http://cytotec.directory/# order cytotec online
smm агентство https://smm-almaty.kz/
3a娛樂城
Watches World
Watches World: Elevating Luxury and Style with Exquisite Timepieces
Introduction:
Jewelry has always been a timeless expression of elegance, and nothing complements one’s style better than a luxurious timepiece. At Watches World, we bring you an exclusive collection of coveted luxury watches that not only tell time but also serve as a testament to your refined taste. Explore our curated selection featuring iconic brands like Rolex, Hublot, Omega, Cartier, and more, as we redefine the art of accessorizing.
A Dazzling Array of Luxury Watches:
Watches World offers an unparalleled range of exquisite timepieces from renowned brands, ensuring that you find the perfect accessory to elevate your style. Whether you’re drawn to the classic sophistication of Rolex, the avant-garde designs of Hublot, or the precision engineering of Patek Philippe, our collection caters to diverse preferences.
Customer Testimonials:
Our commitment to providing an exceptional customer experience is reflected in the reviews from our satisfied clientele. O.M. commends our excellent communication and flawless packaging, while Richard Houtman appreciates the helpfulness and courtesy of our team. These testimonials highlight our dedication to transparency, communication, and customer satisfaction.
New Arrivals:
Stay ahead of the curve with our latest additions, including the Tudor Black Bay Ceramic 41mm, Richard Mille RM35-01 Rafael Nadal NTPT Carbon Limited Edition, and the Rolex Oyster Perpetual Datejust 41mm series. These new arrivals showcase cutting-edge designs and impeccable craftsmanship, ensuring you stay on the forefront of luxury watch fashion.
Best Sellers:
Discover our best-selling watches, such as the Bulgari Serpenti Tubogas 35mm and the Cartier Panthere Medium Model. These timeless pieces combine elegance with precision, making them a staple in any sophisticated wardrobe.
Expert’s Selection:
Our experts have carefully curated a selection of watches, including the Cartier Panthere Small Model, Omega Speedmaster Moonwatch 44.25 mm, and Rolex Oyster Perpetual Cosmograph Daytona 40mm. These choices exemplify the epitome of watchmaking excellence and style.
Secured and Tracked Delivery:
At Watches World, we prioritize the safety of your purchase. Our secured and tracked delivery ensures that your exquisite timepiece reaches you in perfect condition, giving you peace of mind with every order.
Passionate Experts at Your Service:
Our team of passionate watch experts is dedicated to providing personalized service. From assisting you in choosing the perfect timepiece to addressing any inquiries, we are here to make your watch-buying experience seamless and enjoyable.
Global Presence:
With a presence in key cities around the world, including Dubai, Geneva, Hong Kong, London, Miami, Paris, Prague, Dublin, Singapore, and Sao Paulo, Watches World brings luxury timepieces to enthusiasts globally.
Conclusion:
Watches World goes beyond being an online platform for luxury watches; it is a destination where expertise, trust, and satisfaction converge. Explore our collection, and let our timeless timepieces become an integral part of your style narrative. Join us in redefining luxury, one exquisite watch at a time.
monthly car rental in dubai
Dubai, a city of grandeur and innovation, demands a transportation solution that matches its dynamic pace. Whether you’re a business executive, a tourist exploring the city, or someone in need of a reliable vehicle temporarily, car rental services in Dubai offer a flexible and cost-effective solution. In this guide, we’ll explore the popular car rental options in Dubai, catering to diverse needs and preferences.
Airport Car Rental: One-Way Pickup and Drop-off Road Trip Rentals:
For those who need to meet an important delegation at the airport or have a flight to another city, airport car rentals provide a seamless solution. Avoid the hassle of relying on public transport and ensure you reach your destination on time. With one-way pickup and drop-off options, you can effortlessly navigate your road trip, making business meetings or conferences immediately upon arrival.
Business Car Rental Deals & Corporate Vehicle Rentals in Dubai:
Companies without their own fleet or those finding transport maintenance too expensive can benefit from business car rental deals. This option is particularly suitable for businesses where a vehicle is needed only occasionally. By opting for corporate vehicle rentals, companies can optimize their staff structure, freeing employees from non-core functions while ensuring reliable transportation when necessary.
Tourist Car Rentals with Insurance in Dubai:
Tourists visiting Dubai can enjoy the freedom of exploring the city at their own pace with car rentals that come with insurance. This option allows travelers to choose a vehicle that suits the particulars of their trip without the hassle of dealing with insurance policies. Renting a car not only saves money and time compared to expensive city taxis but also ensures a trouble-free travel experience.
Daily Car Hire Near Me:
Daily car rental services are a convenient and cost-effective alternative to taxis in Dubai. Whether it’s for a business meeting, everyday use, or a luxury experience, you can find a suitable vehicle for a day on platforms like Smarketdrive.com. The website provides a secure and quick way to rent a car from certified and verified car rental companies, ensuring guarantees and safety.
Weekly Auto Rental Deals:
For those looking for flexibility throughout the week, weekly car rentals in Dubai offer a competent, attentive, and professional service. Whether you need a vehicle for a few days or an entire week, choosing a car rental weekly is a convenient and profitable option. The certified and tested car rental companies listed on Smarketdrive.com ensure a reliable and comfortable experience.
Monthly Car Rentals in Dubai:
When your personal car is undergoing extended repairs, or if you’re a frequent visitor to Dubai, monthly car rentals (long-term car rentals) become the ideal solution. Residents, businessmen, and tourists can benefit from the extensive options available on Smarketdrive.com, ensuring mobility and convenience throughout their stay in Dubai.
FAQ about Renting a Car in Dubai:
To address common queries about renting a car in Dubai, our FAQ section provides valuable insights and information. From rental terms to insurance coverage, it serves as a comprehensive guide for those considering the convenience of car rentals in the bustling city.
Conclusion:
Dubai’s popularity as a global destination is matched by its diverse and convenient car rental services. Whether for business, tourism, or daily commuting, the options available cater to every need. With reliable platforms like Smarketdrive.com, navigating Dubai becomes a seamless and enjoyable experience, offering both locals and visitors the ultimate freedom of mobility.
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
https://www.sudeaseg.gob.ve/articles/codigo-promocional-1xbet.html
http://centroculturalrecoleta.org/blog/pages/el_codigo_promocional_1.html
https://www.iir-hungary.hu/files/pages/Free_Bet_Promo_Code_1XBET_Bonus.html
Medication information. What side effects can this medication cause?
silagra rx
Everything information about medication. Get here.
cost of clomid pills: order clomid tablets – cheap clomid without rx
https://novosti.tj/sport/promokod-1xbet-besplatno-bonus-za-registracziyu.html
блокиратор парковочного места купить https://idn300.ru/catalog/parkovochnye_barery/
https://cytotec.directory/# buy misoprostol over the counter
Meds prescribing information. Cautions.
seroquel pills
Some what you want to know about medicine. Read here.
http://tssz.ru/includes/photo/melbet_promokod_24.html
I like what you guys are up also. Such intelligent work and reporting! Keep up the excellent works guys I have incorporated you guys to my blogroll. I think it will improve the value of my web site 🙂
That is the proper blog for anybody who needs to search out out about this topic. You understand so much its almost arduous to argue with you (not that I really would want…HaHa). You definitely put a brand new spin on a subject thats been written about for years. Nice stuff, simply great!
buy cheap generic omnacortil omnacortil for sale online order omnacortil online
buy zithromax online cheap: zithromax buy – buy zithromax 1000 mg online
https://cytotec.directory/# buy cytotec in usa
Cопровождение интернет-площадки представляет собой комплексную услугу, которая обеспечивает поддержание его составляющих для стабильного функционирования. Профессиональная комплексная поддержка корпоративного сайта поднимает площадку на ТОПовый уровень, что делает бизнес успешным и прибыльным. Выполняемые действия позволяет компаниям предоставлять своей аудитории только актуальную информацию, коммуницировать с ней оперативно, безопасно и результативно. Такой проект постоянно доступен и удобен для посетителей, клиентов и ПС, а это приводит к увеличению продаж товаров или услуг и улучшает рейтинг компании. Главное, чтобы все выполняли квалифицированные специалисты, так как мероприятия, которые будут выполняться не профессионалами, негативно отразятся на его производительности и юзабилити, а также увеличат риск появления вредоносных программ и кибератак.
Березин Андрей Евроинвест http://lenta.ru/tags/persons/berezin-andrey/.
buy omnacortil online omnacortil price omnacortil 20mg pills
https://edpills.bid/# ed pills comparison
non prescription ed pills: buy prescription drugs online – buy prescription drugs from canada
1win ile spor bahislerinde şansınızı deneyin
suhagra 100mg price in india
https://www.jitunews.com/pages/?1win_promo_code_today_bonus.html
discount prescription drugs online: prescription drugs without the prescription – canadian online pharmacy reviews
http://edwithoutdoctorprescription.store/# buy prescription drugs without doctor
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
prescription drugs online without: best non prescription ed pills – best non prescription ed pills
https://checklist.ectrum.ru/
м¤лЌёлЎњ кІЊмћ„
й»‘з™ЅжЈ‹е°Џжёёж€Џ
Безопасная [url=https://aquadag.ru/]перевозка лежачих больных[/url]. Заботимся о комфорте. Профессионализм и внимание каждому пациенту.
Наши специалисты тщательно отбирают только качественные товары от ведущих мировых производителей, гарантируя ваше удовольствие и безопасностьhttps://wiki.mysupp.ru/index.php?title=_Как_использовать_секс_игрушки_для_достижения_оргазма
[url=https://hydroxychloroquine.guru/]hydroxy-chloroquine[/url]
http://edwithoutdoctorprescription.store/# non prescription erection pills
Безопасная и заботливая перевозка лежачих больных. Опытные медицинские сопровождающие. Доверьтесь нашей команде.
Meds prescribing information. Brand names.
clomid for sale
Actual about pills. Get now.
azithromycin 500mg tab cost
Березин Андрей Евроинвест http://www.antennadaily.ru/2023/06/23/andrey-berezin-euroinvest.
pills for ed: non prescription erection pills – erection pills
Все о дизайне интерьера
http://reputablepharmacies.online/# canadian pharmacies without prescriptions
Drugs information leaflet. Drug Class.
zithromax tablets
Actual information about medication. Read information now.
discount prescription drug https://edwithoutdoctorprescription.store/# п»їprescription drugs
canadian medications
buy accutane with paypal
Medicament information leaflet. Cautions.
get maxalt
Best about pills. Get information now.
табличка вызов персонала со шрифтом брайля https://znaki99.ru/taktilnye-tablichki-so-shriftom-brajlya/
where to buy generic lisinopril prices
order prednisone without prescription
Drug information. Drug Class.
cheap neurontin
Best about drug. Get now.
prescription drugs prices: canadian pharmacy in canada – offshore online pharmacies
https://reputablepharmacies.online/# the best canadian online pharmacy
Medicament prescribing information. Drug Class.
stromectol
Some about medication. Get now.
buy trazodone 100mg
licensed canadian pharmacies canada meds canadian online pharmacies legitimate by aarp
Medication information leaflet. What side effects can this medication cause?
synthroid
Some trends of drug. Get here.
sildenafil price comparison
prescription without a doctor’s prescription: viagra without a doctor prescription – non prescription ed drugs
Watches World: Elevating Luxury and Style with Exquisite Timepieces
Introduction:
Jewelry has always been a timeless expression of elegance, and nothing complements one’s style better than a luxurious timepiece. At Watches World, we bring you an exclusive collection of coveted luxury watches that not only tell time but also serve as a testament to your refined taste. Explore our curated selection featuring iconic brands like Rolex, Hublot, Omega, Cartier, and more, as we redefine the art of accessorizing.
A Dazzling Array of Luxury Watches:
Watches World offers an unparalleled range of exquisite timepieces from renowned brands, ensuring that you find the perfect accessory to elevate your style. Whether you’re drawn to the classic sophistication of Rolex, the avant-garde designs of Hublot, or the precision engineering of Patek Philippe, our collection caters to diverse preferences.
Customer Testimonials:
Our commitment to providing an exceptional customer experience is reflected in the reviews from our satisfied clientele. O.M. commends our excellent communication and flawless packaging, while Richard Houtman appreciates the helpfulness and courtesy of our team. These testimonials highlight our dedication to transparency, communication, and customer satisfaction.
New Arrivals:
Stay ahead of the curve with our latest additions, including the Tudor Black Bay Ceramic 41mm, Richard Mille RM35-01 Rafael Nadal NTPT Carbon Limited Edition, and the Rolex Oyster Perpetual Datejust 41mm series. These new arrivals showcase cutting-edge designs and impeccable craftsmanship, ensuring you stay on the forefront of luxury watch fashion.
Best Sellers:
Discover our best-selling watches, such as the Bulgari Serpenti Tubogas 35mm and the Cartier Panthere Medium Model. These timeless pieces combine elegance with precision, making them a staple in any sophisticated wardrobe.
Expert’s Selection:
Our experts have carefully curated a selection of watches, including the Cartier Panthere Small Model, Omega Speedmaster Moonwatch 44.25 mm, and Rolex Oyster Perpetual Cosmograph Daytona 40mm. These choices exemplify the epitome of watchmaking excellence and style.
Secured and Tracked Delivery:
At Watches World, we prioritize the safety of your purchase. Our secured and tracked delivery ensures that your exquisite timepiece reaches you in perfect condition, giving you peace of mind with every order.
Passionate Experts at Your Service:
Our team of passionate watch experts is dedicated to providing personalized service. From assisting you in choosing the perfect timepiece to addressing any inquiries, we are here to make your watch-buying experience seamless and enjoyable.
Global Presence:
With a presence in key cities around the world, including Dubai, Geneva, Hong Kong, London, Miami, Paris, Prague, Dublin, Singapore, and Sao Paulo, Watches World brings luxury timepieces to enthusiasts globally.
Conclusion:
Watches World goes beyond being an online platform for luxury watches; it is a destination where expertise, trust, and satisfaction converge. Explore our collection, and let our timeless timepieces become an integral part of your style narrative. Join us in redefining luxury, one exquisite watch at a time.
https://vk.com/@oborudovanie_dlya_avtomoek_omsk-skolko-stoit-moika-samoobsluzhivaniya
скачать музыку 2022 бесплатно в хорошем качестве
Yearning for unfiltered truths? Our Telegram channel reveals the unseen: tank chaos, helicopter symphonies, infantry maneuvers, and kamikaze drones. Join us for an uncensored view of the realities that challenge the status quo.
This is unique content that won’t be shown on TV.
Link to Channel: HOT INSIDE UNCENSORED
https://t.me/+HgctQg10yXxhMzky
canadian pharmacies: the generics pharmacy online delivery – tadalafil canadian pharmacy
https://vk.com/oborudovanie_avtomoek_krasnodar?w=wall-224049345_11%2Fall
https://edwithoutdoctorprescription.store/# buy cheap prescription drugs online
buy deltasone pills prednisone 10mg sale
Окунитесь в мир азарта и увлекательных игр на казино с лучшими игровыми автоматами.
https://edpills.bid/# impotence pills
аренда виртуального номера телефона
Березин Андрей Евроинвест https://finance.rambler.ru/person/berezin-andrey/.
арендовать номер телефона
сигнальные столбики с3 купить https://znaki99.ru/signalnyj-stolbik-s3/
pills for erection: ed drugs – natural remedies for ed
prednisone 40mg usa prednisone 10mg cost
взять в аренду номер телефона
Демонтаж и снос частных домов с вывозом мусора в Москве и Московской области – lit9.ru. Демонтаж дома вручную и спецтехникой производим по ценам ниже рынка за 1 день. Бесплатный выезд специалиста на объект.
The salesman, surprised, asked the snail, “Why do you need a fast car? You’re a snail.” buy
аренда номера телефона
https://edwithoutdoctorprescription.store/# prescription drugs without doctor approval
https://vk.com/@oborudovanie_dlya_avtomoek_omsk-avtomoika-v-lizing
Welcome, everyone eager to learn the truth obscured from mainstream sources. Our channel showcases shocking videos that help understand the essence of events affecting our lives. Join us and see what’s behind the scenes.
This is unique content that won’t be shown on TV.
Link to Channel: HOT INSIDE UNCENSORED
https://t.me/+PhiArK2oSvU4N2Iy
скачать ggpokerok
скачать ggpokerok
Все о современных технологиях
аренда номера
generic ed pills: ed drug prices – generic ed pills
order amoxil online cheap buy amoxicillin 1000mg for sale buy amoxil 500mg online
can i order generic lisinopril prices
buy acticlate pill acticlate drug
Надежная перевозка лежачих больных. Опытные медицинские сопровождающие. Безопасность и комфорт в каждой поездке.
Перевозка лежачих больных с заботой о вашем комфорте. Профессиональные медсестры и комфортные условия в пути. Доверьтесь нам!
rybelsus online order
cheap ed drugs: best erection pills – ed pills for sale
generic ozempic cost
печать на 3D-принтере http://scanpoint.ru/bitrix/redirect.php?goto=http://www.shavers.bookmarking.site/News/USLUGI-3d-PRINTERA/
http://edpills.bid/# ed pills that work
wegovy tablets cost
wegovy canada pharmacy prices
buy amoxil 250mg online amoxil without prescription amoxicillin 250mg tablet
ggpokerok
ggpokerok официальный сайт
mexican pharmacies online: the discount pharmacy – legitimate online pharmacies
generic rybelsus for weight loss
rybelsus pills
acticlate online buy doxycycline 100mg without prescription
rybelsus price
buy semaglutide from india
wegovy for diabetes
rybelsus without prescription
buy doxycycline generic
https://mexicanpharmacy.win/# mexican pharmaceuticals online mexicanpharmacy.win
canadian pharmacy azithromycin
https://canadianpharmacy.pro/# canada pharmacy 24h canadianpharmacy.pro
http://clips.tj/user/alekscyday/
inplay pagcor
Демонтаж и снос частных домов с вывозом мусора в Москве и Московской области. Снос дома вручную и спецтехникой производим по ценам ниже рынка за 1 день. Бесплатный выезд специалиста на объект.
canadian pharmacy mall: Canadian pharmacy online – canadian pharmacies online canadianpharmacy.pro
http://civic.am/index.php?subaction=userinfo&user=hachewaman
https://canadianpharmacy.pro/# canadian pharmacy canadianpharmacy.pro
buying from online mexican pharmacy: mexican pharmacy online – buying from online mexican pharmacy mexicanpharmacy.win
cost generic nemasole pills
Березин Андрей Евроинвест https://newizv.ru/news/2023-08-28/berezin-andrey-svedeniya-o-developere-419032/
colchicine cost in mexico
Medicines information. Short-Term Effects.
get aurogra
All what you want to know about drugs. Read information now.
https://be1.ru/antiplagiat-online/?url=https://megapesni.site/&mode=fast
https://indianpharmacy.shop/# Online medicine home delivery indianpharmacy.shop
ashwagandha benefits for women
戰神賽特老虎機
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
Medication information. Generic Name.
trazodone no prescription
Actual information about medicines. Read information now.
Casinos online en Chile con bono de bienvenida sin depósito se están convirtiendo en una opción atractiva para los jugadores. Estos bonos permiten a los usuarios disfrutar de una amplia gama de juegos sin la presión de apostar con dinero propio.
2024娛樂城No.1 – 富遊娛樂城介紹
2024 年 1 月 5 日
|
娛樂城, 現金版娛樂城
富遊娛樂城是無論老手、新手,都非常推薦的線上博奕,在2024娛樂城當中扮演著多年來最來勢洶洶的一匹黑馬,『人性化且精緻的介面,遊戲種類眾多,超級多的娛樂城優惠,擁有眾多與會員交流遊戲的群組』是一大特色。
富遊娛樂城擁有歐洲馬爾他(MGA)和菲律賓政府競猜委員會(PAGCOR)頒發的合法執照。
註冊於英屬維爾京群島,受國際行業協會認可的合法公司。
我們的中心思想就是能夠帶領玩家遠詐騙黑網,讓大家安心放心的暢玩線上博弈,娛樂城也受各大部落客、IG網紅、PTT論壇,推薦討論,富遊娛樂城沒有之一,絕對是線上賭場玩家的第一首選!
富遊娛樂城介面 / 2024娛樂城NO.1
富遊娛樂城簡介
品牌名稱 : 富遊RG
創立時間 : 2019年
存款速度 : 平均15秒
提款速度 : 平均5分
單筆提款金額 : 最低1000-100萬
遊戲對象 : 18歲以上男女老少皆可
合作廠商 : 22家遊戲平台商
支付平台 : 各大銀行、各大便利超商
支援配備 : 手機網頁、電腦網頁、IOS、安卓(Android)
富遊娛樂城遊戲品牌
真人百家 — 歐博真人、DG真人、亞博真人、SA真人、OG真人
體育投注 — SUPER體育、鑫寶體育、亞博體育
電競遊戲 — 泛亞電競
彩票遊戲 — 富遊彩票、WIN 539
電子遊戲 —ZG電子、BNG電子、BWIN電子、RSG電子、好路GR電子
棋牌遊戲 —ZG棋牌、亞博棋牌、好路棋牌、博亞棋牌
捕魚遊戲 —ZG捕魚、RSG捕魚、好路GR捕魚、亞博捕魚
富遊娛樂城優惠活動
每日任務簽到金666
富遊VIP全面啟動
復酬金活動10%優惠
日日返水
新會員好禮五選一
首存禮1000送1000
免費體驗金$168
富遊娛樂城APP
步驟1 : 開啟網頁版【富遊娛樂城官網】
步驟2 : 點選上方(下載app),會跳出下載與複製連結選項,點選後跳轉。
步驟3 : 跳轉後點選(安裝),並點選(允許)操作下載描述檔,跳出下載描述檔後點選關閉。
步驟4 : 到手機設置>一般>裝置管理>設定描述檔(富遊)安裝,即可完成安裝。
富遊娛樂城常見問題FAQ
富遊娛樂城詐騙?
黑網詐騙可細分兩種,小出大不出及純詐騙黑網,我們可從品牌知名度經營和網站架設畫面分辨來簡單分辨。
富遊娛樂城會出金嗎?
如上面提到,富遊是在做一個品牌,為的是能夠保證出金,和帶領玩家遠離黑網,而且還有DUKER娛樂城出金認證,所以各位能夠放心富遊娛樂城為正出金娛樂城。
富遊娛樂城出金延遲怎麼辦?
基本上只要是公司系統問提造成富遊娛樂城會員無法在30分鐘成功提款,富遊娛樂城會即刻派送補償金,表達誠摯的歉意。
富遊娛樂城結論
富遊娛樂城安心玩,評價4.5顆星。如果還想看其他娛樂城推薦的,可以來娛樂城推薦尋找喔。
https://reports.adguard.com/en/mp3name.me/report.html
canada drugs reviews: canada pharmacy online – canadian world pharmacy canadianpharmacy.pro
can i buy valtrex prices
https://mexicanpharmacy.win/# buying prescription drugs in mexico mexicanpharmacy.win
Medicine prescribing information. Cautions.
lyrica sale
All about medication. Get information now.
http://indianpharmacy.shop/# indianpharmacy com indianpharmacy.shop
reputable online canadian pharmacies
order cheap zerit no prescription
ATG戰神賽特
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
can you buy cheap valtrex price
trazodone drugs forum
Meds information for patients. Long-Term Effects.
cost of proscar
Best news about drug. Get information now.
штрафы гибдд проверить официальный сайт https://proverka-gibdd-shtrafov.ru/
furosemida dosis
Medication information sheet. What side effects can this medication cause?
rx propecia
Everything what you want to know about medicine. Read now.
can i purchase cheap valtrex without a prescription
Drugs information sheet. Drug Class.
tadacip
Actual what you want to know about medicines. Read information now.
http://indianpharmacy.shop/# best online pharmacy india indianpharmacy.shop
https://xn--80a2af9c.xn--p1ai/bitrix/redirect.php?goto=https://mp3-top.net
elimite ocular side effects
https://www.gscohen.com/__media__/js/netsoltrademark.php?d=mp3new.top
can i buy doxycycline over the counter
Демонтаж и снос частных домов с вывозом мусора в Москве и Московской области. Демонтаж дома вручную и спецтехникой производим по ценам ниже рынка за 1 день. Бесплатный выезд специалиста на объект.
buy prednisone online without prescription
mahjong connect online
https://underfifteendollars.com/__media__/js/netsoltrademark.php?d=mp3gid.co
http://mexicanpharmacy.win/# mexican rx online mexicanpharmacy.win
https://www.uniteddivinescience.org/__media__/js/netsoltrademark.php?d=pesnimp3.ws
Обзор лучших строительных компаний в Крыму и Севастополе, посмотрите строительство домов в Крыму
https://caremedinsurance.de/__media__/js/netsoltrademark.php?d=mp3bit.pw
https://mexicanpharmacy.win/# mexico drug stores pharmacies mexicanpharmacy.win
http://rutorg-game.ru/user/novyuexask/
проверка авто на штрафы https://proverka-gibdd-shtrafov.ru/
http://canadianpharmacy.pro/# best online canadian pharmacy canadianpharmacy.pro
Vyacheslav Nikolaev http://www.spacecoastdaily.com/2023/08/vyacheslav-nikolaev-ecosystem-builder/.
Все о дизайне интерьера
recommended canadian pharmacies Canadian pharmacy online certified canadian pharmacy canadianpharmacy.pro
https://www.dezobarieri.ge/user/novaaelece/
https://mexicanpharmacy.win/# mexican mail order pharmacies mexicanpharmacy.win
top 10 online pharmacy in india
https://prlog.ru/analysis/megapesni.site
https://skachat-zenit.ru/
http://mexicanpharmacy.win/# buying prescription drugs in mexico online mexicanpharmacy.win
canada pharmacy no prescription
https://nova.rambler.ru/search?query=mp3name.me
Medication information sheet. Short-Term Effects.
cialis soft
Best trends of drugs. Get now.
http://mexicanpharmacy.win/# mexican border pharmacies shipping to usa mexicanpharmacy.win
omnicef price
Ежемесячная зарплата красоток, которые работают в данном агентстве, составляет от 20000 долларов и выше https://www.alligator.spb.ru/forum/index.php?PAGE_NAME=profile_view&UID=69974
ventolin online order ventolin inhalator order online albuterol usa
https://mexicanpharmacy.win/# pharmacies in mexico that ship to usa mexicanpharmacy.win
Online medicine home delivery
娛樂城
2024娛樂城No.1 – 富遊娛樂城介紹
2024 年 1 月 5 日
|
娛樂城, 現金版娛樂城
富遊娛樂城是無論老手、新手,都非常推薦的線上博奕,在2024娛樂城當中扮演著多年來最來勢洶洶的一匹黑馬,『人性化且精緻的介面,遊戲種類眾多,超級多的娛樂城優惠,擁有眾多與會員交流遊戲的群組』是一大特色。
富遊娛樂城擁有歐洲馬爾他(MGA)和菲律賓政府競猜委員會(PAGCOR)頒發的合法執照。
註冊於英屬維爾京群島,受國際行業協會認可的合法公司。
我們的中心思想就是能夠帶領玩家遠詐騙黑網,讓大家安心放心的暢玩線上博弈,娛樂城也受各大部落客、IG網紅、PTT論壇,推薦討論,富遊娛樂城沒有之一,絕對是線上賭場玩家的第一首選!
富遊娛樂城介面 / 2024娛樂城NO.1
富遊娛樂城簡介
品牌名稱 : 富遊RG
創立時間 : 2019年
存款速度 : 平均15秒
提款速度 : 平均5分
單筆提款金額 : 最低1000-100萬
遊戲對象 : 18歲以上男女老少皆可
合作廠商 : 22家遊戲平台商
支付平台 : 各大銀行、各大便利超商
支援配備 : 手機網頁、電腦網頁、IOS、安卓(Android)
富遊娛樂城遊戲品牌
真人百家 — 歐博真人、DG真人、亞博真人、SA真人、OG真人
體育投注 — SUPER體育、鑫寶體育、亞博體育
電競遊戲 — 泛亞電競
彩票遊戲 — 富遊彩票、WIN 539
電子遊戲 —ZG電子、BNG電子、BWIN電子、RSG電子、好路GR電子
棋牌遊戲 —ZG棋牌、亞博棋牌、好路棋牌、博亞棋牌
捕魚遊戲 —ZG捕魚、RSG捕魚、好路GR捕魚、亞博捕魚
富遊娛樂城優惠活動
每日任務簽到金666
富遊VIP全面啟動
復酬金活動10%優惠
日日返水
新會員好禮五選一
首存禮1000送1000
免費體驗金$168
富遊娛樂城APP
步驟1 : 開啟網頁版【富遊娛樂城官網】
步驟2 : 點選上方(下載app),會跳出下載與複製連結選項,點選後跳轉。
步驟3 : 跳轉後點選(安裝),並點選(允許)操作下載描述檔,跳出下載描述檔後點選關閉。
步驟4 : 到手機設置>一般>裝置管理>設定描述檔(富遊)安裝,即可完成安裝。
富遊娛樂城常見問題FAQ
富遊娛樂城詐騙?
黑網詐騙可細分兩種,小出大不出及純詐騙黑網,我們可從品牌知名度經營和網站架設畫面分辨來簡單分辨。
富遊娛樂城會出金嗎?
如上面提到,富遊是在做一個品牌,為的是能夠保證出金,和帶領玩家遠離黑網,而且還有DUKER娛樂城出金認證,所以各位能夠放心富遊娛樂城為正出金娛樂城。
富遊娛樂城出金延遲怎麼辦?
基本上只要是公司系統問提造成富遊娛樂城會員無法在30分鐘成功提款,富遊娛樂城會即刻派送補償金,表達誠摯的歉意。
富遊娛樂城結論
富遊娛樂城安心玩,評價4.5顆星。如果還想看其他娛樂城推薦的,可以來娛樂城推薦尋找喔。
finasteride buy australia
Medication prescribing information. Effects of Drug Abuse.
zofran tablet
Best trends of drugs. Read information now.
https://mexicanpharmacy.win/# best mexican online pharmacies mexicanpharmacy.win
https://www.imena.ua/domains/whois?domain=mp3-top.net
albuterol 2mg pill cost ventolin 4mg order albuterol 2mg
https://widestat.ru/mp3new.top
https://indianpharmacy.shop/# top online pharmacy india indianpharmacy.shop
top 10 pharmacies in india
https://be1.ru/antiplagiat-online/?url=https://mp3gid.co/&mode=fast
can i purchase cheap clomid for sale
https://sitewarz.com/s/pesnimp3.ws
Всем привет! Появился вопрос про взять деньги в долг срочно? Предлагаем безопасный источник финансовой помощи. Вы можете получить деньги в займ без избыточных вопросов и документов? Тогда обратитесь к нам! Мы предлагаем выгодные условия займа, быстрое решение и гарантию конфиденциальности. Не откладывайте свои планы и мечты, воспользуйтесь доступным предложением прямо сейчас!
https://mexicanpharmacy.win/# mexican mail order pharmacies mexicanpharmacy.win
https://avtomanipulyator.com/stati/manipulyator-vyshka/
ATG戰神賽特
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
https://seo-report.net/domain/mp3bit.pw
https://indianpharmacy.shop/# п»їlegitimate online pharmacies india indianpharmacy.shop
online shopping pharmacy india
Medication prescribing information. What side effects can this medication cause?
maxalt
All what you want to know about drug. Read here.
reddit canadian pharmacy Cheapest drug prices Canada canadapharmacyonline canadianpharmacy.pro
Демонтаж и снос частных домов с вывозом мусора в Москве и Московской области – lit9.ru. Демонтаж дома вручную и спецтехникой производим по ценам ниже рынка за 1 день. Бесплатный выезд специалиста на объект.
Все о современных технологиях
https://prilozenie-zenit.ru/
https://canadianpharmacy.pro/# my canadian pharmacy reviews canadianpharmacy.pro
best canadian prescription prices
Что может быстро улучшить настроение в наши дни? Конечно же, хорошее кино. Что может быть лучше, чем заварить себе вкусны кофе или чай сесть в мягкое кресло, зайти на сайт HD-Novinka и смотреть фильмы 2024 онлайн бесплатно.
фильмы 2024 в качестве
https://mexicanpharmacy.win/# mexican pharmacy mexicanpharmacy.win
augmentin 625mg usa augmentin 1000mg canada
http://mexicanpharmacy.win/# pharmacies in mexico that ship to usa mexicanpharmacy.win
buy prescription drugs from india
https://a.pr-cy.ru/megapesni.site/
https://avtomanipulyator.com/stati/kupit-kran-manipulyator-v-moskve/
Online medicine home delivery Cheapest online pharmacy Online medicine order indianpharmacy.shop
https://mexicanpharmacy.win/# mexican drugstore online mexicanpharmacy.win
https://www.ozmanagementgroup.co.uk/__media__/js/netsoltrademark.php?d=mp3name.me
http://tortdv.ru/bitrix/rk.php?goto=http://wiki.fontyspulsed.com/index.php?title=3D-%D0%BF%D0%B5%D1%87%D0%B0%D1%82%D1%8C
https://indianpharmacy.shop/# buy prescription drugs from india indianpharmacy.shop
buy ozempic online no script needed
order augmentin pill order augmentin 1000mg online
https://canadianpharmacy.pro/# canadian drug pharmacy canadianpharmacy.pro
mail order pharmacy india
https://www.sitesearch.net/domain/mp3-top.net
https://apescout.com/site/mp3new.top
Thanks a lot! Good stuff!
bc nd game sites like bc game bc game là gì
https://viagrasansordonnance.pro/# Viagra femme sans ordonnance 24h
https://nabiullin.com/analiz-saita/domain/mp3gid.co/
amoxicilina 400mg/5ml
Viagra gГ©nГ©rique sans ordonnance en pharmacie viagra sans ordonnance Acheter viagra en ligne livraison 24h
??????? ??? ?????
https://bertal.ru/index.php?a8301971/pesnimp3.ws/
доставка цветов в новосибирске на дом бесплатная https://s-buketom.ru/
Pharmacies en ligne certifiГ©es: levitra generique – Pharmacie en ligne livraison gratuite
karcher shop md
https://www.inventive9.com/seo-audit/domain/mp3bit.pw
zoloft 100 mg
http://levitrasansordonnance.pro/# acheter medicament a l etranger sans ordonnance
cialis soft tabs anmat
prednisone without insurance
Pharmacie en ligne pas cher: kamagra gel – Acheter mГ©dicaments sans ordonnance sur internet
Vyacheslav Nikolaev https://nikolaev-vyacheslav-konstantinovich.biography-wiki.com/.
http://acheterkamagra.pro/# acheter medicament a l etranger sans ordonnance
Acheter mГ©dicaments sans ordonnance sur internet
buy synthroid 150mcg pill synthroid 75mcg sale order synthroid 150mcg sale
Деревянные дома под ключ
Дома АВС – Ваш уютный уголок
Мы строим не просто дома, мы создаем пространство, где каждый уголок будет наполнен комфортом и радостью жизни. Наш приоритет – не просто предоставить место для проживания, а создать настоящий дом, где вы будете чувствовать себя счастливыми и уютно.
В нашем информационном разделе “ПРОЕКТЫ” вы всегда найдете вдохновение и новые идеи для строительства вашего будущего дома. Мы постоянно работаем над тем, чтобы предложить вам самые инновационные и стильные проекты.
Мы убеждены, что основа хорошего дома – это его дизайн. Поэтому мы предоставляем услуги опытных дизайнеров-архитекторов, которые помогут вам воплотить все ваши идеи в жизнь. Наши архитекторы и персональные консультанты всегда готовы поделиться своим опытом и предложить функциональные и комфортные решения для вашего будущего дома.
Мы стремимся сделать весь процесс строительства максимально комфортным для вас. Наша команда предоставляет детализированные сметы, разрабатывает четкие этапы строительства и осуществляет контроль качества на каждом этапе.
Для тех, кто ценит экологичность и близость к природе, мы предлагаем деревянные дома премиум-класса. Используя клееный брус и оцилиндрованное бревно, мы создаем уникальные и здоровые условия для вашего проживания.
Тем, кто предпочитает надежность и многообразие форм, мы предлагаем дома из камня, блоков и кирпичной кладки.
Для практичных и ценящих свое время людей у нас есть быстровозводимые каркасные дома и эконом-класса. Эти решения обеспечат вас комфортным проживанием в кратчайшие сроки.
С Домами АВС создайте свой уютный уголок, где каждый момент жизни будет наполнен радостью и удовлетворением
https://cialissansordonnance.shop/# Pharmacie en ligne fiable
can you buy doxycycline over the counter in america
acheter medicament a l etranger sans ordonnance: achat kamagra – Pharmacie en ligne fiable
order generic synthroid 150mcg synthroid 150mcg pills levoxyl drug
order tetracycline without a prescription
https://pharmadoc.pro/# Pharmacie en ligne livraison rapide
https://rg8888.org/atg/
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
Viagra homme sans ordonnance belgique viagrasansordonnance.pro Viagra pas cher inde
заказ цветов недорого https://s-buketom.ru/
pharmacie ouverte 24/24: Levitra pharmacie en ligne – Pharmacie en ligne pas cher
zyrtec krople
La seguridad y la justicia son aspectos clave al elegir los Mejores Casinos En Línea Chile, garantizando así una experiencia de juego segura y disfrutable para todos. https://casino-bonos-chile.cl/
Пусть ваш бизнес будет на виду. SEO-продвижение сайтов – ваш надежный партнер в привлечении клиентов и укреплении онлайн-присутствия.
SEO-продвижение сайтов – мощный магнит для посетителей. Повысьте видимость вашего ресурса в поисковых системах и увеличьте поток клиентов.
Pills information. Cautions.
get colchicine
Everything what you want to know about medication. Read here.
can i order generic pregabalin
http://levitrasansordonnance.pro/# Pharmacie en ligne fiable
For all those trying to get a distinctive and enjoyable entertainment expertise, the entire world of striptease inside the north delivers a unique allure https://remingtonqfrd08641.howeweb.com/25297571/northern-nightscape-a-journey-into-the-world-of-north-strippers
п»їpharmacie en ligne: pharmacie en ligne – Pharmacie en ligne fiable
buy levitra 10mg pill levitra cheap
Всем привет! Появился вопрос про взять деньги сейчас? Предоставляем безопасный источник финансовой помощи. Вы можете получить финансирование в долг без избыточных вопросов и документов? Тогда обратитесь к нам! Мы предлагаем высокоприбыльные условия займа, моментальное решение и гарантию конфиденциальности. Не откладывайте свои планы и мечты, воспользуйтесь предложенным предложением прямо сейчас!
Medicine information for patients. Effects of Drug Abuse.
cost zofran
Best what you want to know about medication. Read information here.
http://pharmadoc.pro/# Acheter mГ©dicaments sans ordonnance sur internet
Pharmacie en ligne livraison 24h
daddy – ваш путь в мир азартных игр.
Здравствуйте! Появился вопрос про предоставление денег в долг? Предлагаем безопасный источник финансовой помощи. Вы можете получить средства в займ без излишних вопросов и документов? Тогда обратитесь к нам! Мы предоставляем выгодные условия кредитования, быстрое решение и гарантию конфиденциальности. Не откладывайте свои планы и мечты, воспользуйтесь предложенным предложением прямо сейчас!
finpecia (aripiprazole)
Pharmacie en ligne pas cher Pharmacie en ligne livraison rapide pharmacie ouverte 24/24
mostbet зеркало
http://cialissansordonnance.shop/# pharmacie ouverte
how to buy vardenafil order generic levitra 20mg
п»їpharmacie en ligne: cialis prix – Pharmacie en ligne France
Приветствую! Возник вопрос про займ онлайн в Минске? Предоставляем надежный источник финансовой помощи. Вы можете получить финансирование в займ без избыточных вопросов и документов? Тогда обратитесь к нам! Мы предоставляем выгодные условия займа, быстрое решение и гарантию конфиденциальности. Не откладывайте свои планы и мечты, воспользуйтесь предложенным предложением прямо сейчас!
Meds information leaflet. Long-Term Effects.
aurogra
Everything information about meds. Get now.
Мы рады предложить большой выбор производственного оборудования, прямые поставки лизинг полиграфического оборудования
Are you over the hunt for an ideal approach to elevate your future bachelor celebration https://chancexncp65319.bloguerosa.com/24597960/private-strippers-tailored-for-your-northside-celebration
canada can you buy prednisone
https://pharmadoc.pro/# pharmacie ouverte 24/24
Viagra homme sans ordonnance belgique: Viagra sans ordonnance 24h – Viagra homme prix en pharmacie sans ordonnance
Medication prescribing information. Short-Term Effects.
finpecia
Best trends of pills. Read information now.
clomid online order buy clomid 50mg for sale order clomid generic
https://clomiphene.icu/# how to get cheap clomid without insurance
buy wegovy in mexico
clomiphene 100mg canada clomid 100mg usa clomiphene 100mg ca
найти сервисные центры ремонта телефонов
Лизинг оборудования – рейтинг компаний в 2024 году: отзывы, условия, стоимость и быстрое оформление онлайн-заявки лизинг энергетического оборудования
how to get cheap clomid prices where can i get cheap clomid without insurance how to buy generic clomid
zithromax generic cost: where can i get zithromax over the counter – zithromax for sale cheap
get generic amaryl tablets
Дома АВС – Ваш уютный уголок
Мы строим не просто дома, мы создаем пространство, где каждый уголок будет наполнен комфортом и радостью жизни. Наш приоритет – не просто предоставить место для проживания, а создать настоящий дом, где вы будете чувствовать себя счастливыми и уютно.
В нашем информационном разделе “ПРОЕКТЫ” вы всегда найдете вдохновение и новые идеи для строительства вашего будущего дома. Мы постоянно работаем над тем, чтобы предложить вам самые инновационные и стильные проекты.
Мы убеждены, что основа хорошего дома – это его дизайн. Поэтому мы предоставляем услуги опытных дизайнеров-архитекторов, которые помогут вам воплотить все ваши идеи в жизнь. Наши архитекторы и персональные консультанты всегда готовы поделиться своим опытом и предложить функциональные и комфортные решения для вашего будущего дома.
Мы стремимся сделать весь процесс строительства максимально комфортным для вас. Наша команда предоставляет детализированные сметы, разрабатывает четкие этапы строительства и осуществляет контроль качества на каждом этапе.
Для тех, кто ценит экологичность и близость к природе, мы предлагаем деревянные дома премиум-класса. Используя клееный брус и оцилиндрованное бревно, мы создаем уникальные и здоровые условия для вашего проживания.
Тем, кто предпочитает надежность и многообразие форм, мы предлагаем дома из камня, блоков и кирпичной кладки.
Для практичных и ценящих свое время людей у нас есть быстровозводимые каркасные дома и эконом-класса. Эти решения обеспечат вас комфортным проживанием в кратчайшие сроки.
С Домами АВС создайте свой уютный уголок, где каждый момент жизни будет наполнен радостью и удовлетворением
SEO-продвижение сайтов – ключ к виртуозному онлайн-присутствию. Оптимизируйте, привлекайте, выделяйтесь среди конкурентов.
http://ivermectin.store/# stromectol order online
[url=https://elabuga.seojazz.ru/]SEO-продвижение сайтов[/url] – инструмент вашего цифрового успеха. Стройте мост к клиентам и позиционируйте свой бренд на вершине поисковых запросов.
Приветствую! Возник вопрос про [url=https://financedirector.by/]заем средств[/url]? Предлагаем стабильный источник финансовой помощи. Вы можете получить финансирование в долг без излишних вопросов и документов? Тогда обратитесь к нам! Мы предлагаем привлекательные условия кредитования, оперативное решение и обеспечение конфиденциальности. Не откладывайте свои планы и мечты, воспользуйтесь предложенным предложением прямо сейчас!
Nikolaev https://www.natureworldnews.com/articles/57820/20230802/vyacheslav-konstantinovich-nikolaev.htm
Medicines information. Long-Term Effects.
kamagra
Best news about medicament. Get here.
кращі казино
https://l2db.com.ua
Легальні казино в Україні стають важливим аспектом розвитку гральної індустрії у країні. Законодавчі зміни в останні роки створили сприятливе середовище для розвитку онлайн та оффлайн гральних закладів. Існують декілька ключових факторів, які роблять легальні казино в Україні привабливими для гравців та інвесторів.
Однією з основних переваг є регулювання грального бізнесу державою, що гарантує чесність та безпеку для гравців. Легальність казино в Україні відображається в ретельних перевірках та ліцензіях, які видаються органами влади. Це забезпечує гравцям впевненість у тому, що їхні фінансові та особисті дані захищені.
Завдяки інноваційним технологіям, легальні казино в Україні швидко адаптуються до потреб гравців. Онлайн-платформи надають можливість грати в улюблені азартні ігри зручно та безпечно прямо з дому чи мобільного пристрою. Завдяки високій якості графіки та захоплюючому геймплею, гравці можуть насолоджуватися атмосферою класичних казино в будь-якому місці та в будь-який час.
Партнерські програми та бонуси, що пропонують легальні казино в Україні, роблять гру ще більш привабливою для новачків. Інколи це може включати в себе бездепозитні бонуси, фріспіни або інші ексклюзивні пропозиції для реєстрації. Гравець може отримати додатковий стимул для гри та виграшу, що робить гральний процес ще захопливішим.
Легальні казино в Україні також сприяють розвитку туризму, приваблюючи гравців з інших країн. Вони стають місцем для соціальних подій, турнірів та розваг, що сприяє позитивному іміджу країни та збільшенню її привабливості для іноземних туристів.
У світі розваг та азарту, легальні казино в Україні виступають як підтримуючий стовп розвитку економіки. Збалансована політика та тісне співробітництво між гральними операторами та державними органами сприяють позитивному розвитку цієї індустрії. Гравці отримують можливість насолоджуватися азартом в безпечному та легальному середовищі, що робить казино в Україні привабливим вибором для всіх шанувальників азартних розваг.
ivermectin 0.1 uk: stromectol 12mg online – ivermectin usa price
https://master-santech-kras.ru/
generic name for ivermectin buy ivermectin uk ivermectin lotion 0.5
buying cheap lisinopril without prescription
https://azithromycin.bid/# generic zithromax 500mg india
Meds information sheet. Brand names.
prednisone otc
All news about medicine. Read information now.
https://1abakan.ru/forum/showthread-61613/
http://azithromycin.bid/# generic zithromax india
Вскрытие замков в любое время суток оперативно вскрытие замков телефон и без повреждений.
buy generic zanaflex online buy zanaflex generic tizanidine price
propranolol doseforanxiety
ivermectin coronavirus: ivermectin 0.1 uk – cost of stromectol
how can i get generic lisinopril no prescription
онлайн казино
кращі казино
Легальні казино в Україні стають важливим аспектом розвитку гральної індустрії у країні. Законодавчі зміни в останні роки створили сприятливе середовище для розвитку онлайн та оффлайн гральних закладів. Існують декілька ключових факторів, які роблять легальні казино в Україні привабливими для гравців та інвесторів.
Однією з основних переваг є регулювання грального бізнесу державою, що гарантує чесність та безпеку для гравців. Легальність казино в Україні відображається в ретельних перевірках та ліцензіях, які видаються органами влади. Це забезпечує гравцям впевненість у тому, що їхні фінансові та особисті дані захищені.
Завдяки інноваційним технологіям, легальні казино в Україні швидко адаптуються до потреб гравців. Онлайн-платформи надають можливість грати в улюблені азартні ігри зручно та безпечно прямо з дому чи мобільного пристрою. Завдяки високій якості графіки та захоплюючому геймплею, гравці можуть насолоджуватися атмосферою класичних казино в будь-якому місці та в будь-який час.
Партнерські програми та бонуси, що пропонують легальні казино в Україні, роблять гру ще більш привабливою для новачків. Інколи це може включати в себе бездепозитні бонуси, фріспіни або інші ексклюзивні пропозиції для реєстрації. Гравець може отримати додатковий стимул для гри та виграшу, що робить гральний процес ще захопливішим.
Легальні казино в Україні також сприяють розвитку туризму, приваблюючи гравців з інших країн. Вони стають місцем для соціальних подій, турнірів та розваг, що сприяє позитивному іміджу країни та збільшенню її привабливості для іноземних туристів.
У світі розваг та азарту, легальні казино в Україні виступають як підтримуючий стовп розвитку економіки. Збалансована політика та тісне співробітництво між гральними операторами та державними органами сприяють позитивному розвитку цієї індустрії. Гравці отримують можливість насолоджуватися азартом в безпечному та легальному середовищі, що робить казино в Україні привабливим вибором для всіх шанувальників азартних розваг.
ivermectin 0.5% brand name stromectol where to buy ivermectin nz
zanaflex us buy tizanidine 2mg for sale buy generic zanaflex over the counter
canadatc.com
Local Insider information
ashwagandha tea
компании ремонта телефонов
Всем привет! Возник вопрос про деньги в долг в городе? Предлагаем стабильный источник финансовой помощи. Вы можете получить деньги в долг без избыточных вопросов и документов? Тогда обратитесь к нам! Мы предоставляем высокоприбыльные условия займа, оперативное решение и обеспечение конфиденциальности. Не откладывайте свои планы и мечты, воспользуйтесь предложенным предложением прямо сейчас!
как купить с таобао в россию
http://azithromycin.bid/# where can i buy zithromax capsules
как купить с таобао в россию
order cheap clomid without rx: can i purchase clomid now – where buy clomid no prescription
Купить 1С Склад у официального партнера фирмы 1С 1с управление торговлей 11 цена консультация бесплатно!
дешевый ремонт телефонов
https://joebatchelor.com/index.php/User:Yasmin0711
cheap amoxicillin 500mg buy amoxicillin 500mg canada amoxicillin from canada
https://ar.trade-leader.com/
Medication information. Short-Term Effects.
seroquel
Everything news about medicine. Read information here.
https://modern-design-ideas.com/lego-affiliate-program-best-deals/
http://prednisonetablets.shop/# prednisone 20mg
how to buy cheap lisinopril tablets
Список всех МФО Казахстана https://farsh-cook.ru/
amoxicillin buy online canada: amoxicillin tablets in india – buy amoxicillin online no prescription
Виниловый сайдинг в интернет-магазине по выгодным ценам https://star-plast.su/ настоящие отзывы покупателей!
Pills information sheet. Short-Term Effects.
tadacip
Actual about meds. Read here.
semaglutide 14mg over the counter order semaglutide 14 mg without prescription semaglutide over the counter
SEO-продвижение сайтов – это не просто оптимизация, это стратегия роста. Сделайте свой сайт неотъемлемой частью онлайн-пространства.
can i order generic amaryl no prescription
Meds information for patients. Brand names.
lisinopril prices
Actual about medicine. Get now.
SEO-продвижение сайтов: где слова становятся клиентами. Оптимизируйте контент, чтобы ваш сайт разговаривал с поисковыми системами и потребителями.
Nikolaev Vyacheslav https://www.techbullion.com/nikolaev-vyacheslav-konstantinovich.
cost of cheap mobic without a prescription
http://azithromycin.bid/# buy zithromax online cheap
Medicament information leaflet. Drug Class.
bactrim otc
Actual news about medicament. Get here.
how can i buy arimidex without a prescription
zithromax for sale us zithromax buy online no prescription zithromax pill
https://klimovsk.bbeasy.ru/viewtopic.php?id=8102#p19992
http://azithromycin.bid/# zithromax online usa
cheapest price for doxycycline
diltiazem cream
amoxicillin 500mg no prescription: cost of amoxicillin 30 capsules – purchase amoxicillin online without prescription
purchase semaglutide online buy semaglutide 14 mg oral semaglutide 14mg
Drug information leaflet. What side effects can this medication cause?
silagra
Everything about medicine. Read information now.
cefixime toxicity
Medicament information. What side effects?
flagyl tablets
Some about medicine. Read information here.
how to get lisinopril no prescription
buy prednisone 1mg
Drugs information leaflet. Brand names.
propecia without prescription
All what you want to know about drugs. Get now.
albuterol sulfate inhalation aerosol
cheap prednisone no prescription
https://manigroup.ru/stati/manipulyator-mersedes/
https://azithromycin.bid/# where can i get zithromax over the counter
amoxicillin 500 tablet: buy amoxicillin 500mg usa – can you buy amoxicillin over the counter in canada
Casino
can i buy zithromax over the counter generic zithromax azithromycin how to buy zithromax online
Казино
Казино Турбо
https://hikvisiondb.webcam/wiki/User:ConnorStout
Turbo
Mostbet bookmaker: review and reviews of players on Mostbet https://body-lightening.com/modules/wordpress/index.php?p=43
Нужен опытный арбитражный адвокат? Наша команда юристов готова предоставить вам профессиональные услуги в сфере арбитражного процесса http://christianfaithdownloads.com/dokuwiki/doku.php?id=_РћСЃРЅРѕРІС‹_международного_арбитража:_перспективы_для_адвокатов
buy prednisone 5mg generic prednisone 10mg drug buy prednisone online
where to buy generic clomid online: can you get clomid now – cheap clomid price
Волна
http://amoxicillin.bid/# amoxicillin buy online canada
Казино Волна
order prednisone 40mg online cheap deltasone over the counter buy deltasone 20mg pill
dnews7.com
https://modern-design-ideas.com/lego-affiliate-program-best-deals/
generic zithromax 500mg how to buy zithromax online where can i get zithromax
https://vk.link/mesta_otduha_moskva/product/9414587/desc
https://ungl.org/forums/1/75232
https://ivermectin.store/# ivermectin where to buy
order generic clomid for sale: how to buy cheap clomid now – can i get generic clomid no prescription
https://azithromycin.bid/# zithromax for sale usa
where can i get cheap lisinopril without rx
Medicament information for patients. Effects of Drug Abuse.
fluoxetine price
All news about medicine. Read now.
https://wiki.wogames.info/wiki/%D0%98%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F_%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%82%D0%B0_mp3
https://www.google.ws/url?q=https://pin-up-uz-pinup.com
перетяжка мебели https://peretyazhka-mebeli-minsk.ru/.
aboutweeks.com
Medicines information leaflet. What side effects?
clomid sale
Some about drugs. Read here.
Crypto Payment Gateway for Woocommerce
https://mexicanpharm.shop/# buying prescription drugs in mexico mexicanpharm.shop
как продвигать интернет магазин https://seo-con.ru/
effexor online
darknet зайти на сайт
Даркнет, сокращение от “даркнетворк” (dark network), представляет собой часть интернета, недоступную для обычных поисковых систем. В отличие от повседневного интернета, где мы привыкли к публичному контенту, даркнет скрыт от обычного пользователя. Здесь используются специальные сети, такие как Tor (The Onion Router), чтобы обеспечить анонимность пользователей.
https://www.google.md/url?q=https://mostbet-kg-online.com
welcomelady.net
https://duchon.blog.idnes.cz/redir.aspx?url=https://marvelfilms.ru/
buy semaglutide 14mg online order semaglutide generic semaglutide 14mg ca
http://wiki.myamens.com/index.php/User:BelleLawless
mexico drug stores pharmacies Online Mexican pharmacy п»їbest mexican online pharmacies mexicanpharm.shop
mexican mail order pharmacies: Online Pharmacies in Mexico – buying prescription drugs in mexico mexicanpharm.shop
https://jwc.cau.edu.cn/jsearch/viewsnap.jsp?dir=20211019&ctime=2021-10-19%2005:24:49&q=urp&url=https://marvelfilms.ru/opisanie-personazhej-iz-vselennoj-marvel/
newsmiamigardens.com
https://indianpharm.store/# legitimate online pharmacies india indianpharm.store
buy semaglutide for sale cheap rybelsus semaglutide brand
canadian pharmacy oxycodone: Licensed Online Pharmacy – pharmacy canadian canadianpharm.store
морг 67 больница https://www.ritual-gratek20.ru/.
https://pred.kaplife.ru/bitrix/redirect.php?goto=https://marvelfilms.ru/magiya-marvel-ekspertnyj-obzor-10-luchshih-personazhej-i-ih-vklad-v-vselennuyu/
buying prescription drugs in mexico: Online Mexican pharmacy – mexican rx online mexicanpharm.shop
india pharmacy international medicine delivery from india indian pharmacy indianpharm.store
where to get cheap amaryl price
сео продвижение тарифы https://seo-con.ru/
https://indianpharm.store/# world pharmacy india indianpharm.store
http://canadianpharm.store/# canadian discount pharmacy canadianpharm.store
best online pharmacies in mexico: Certified Pharmacy from Mexico – п»їbest mexican online pharmacies mexicanpharm.shop
online pharmacy india Indian pharmacy to USA india pharmacy mail order indianpharm.store
purchase absorica without prescription order accutane for sale buy absorica generic
http://bestmedbook.mybb.ru/viewtopic.php?id=8476#p11996
where can i get cheap finpecia without rx
hollanderhomes.com
Компания diplom-sale.ru предлаагает купить диплом нового образца http://diplom-sale.ru со скидкой и гарантией возврата средств.
https://indianpharm.store/# india online pharmacy indianpharm.store
order isotretinoin 20mg online buy isotretinoin 20mg generic isotretinoin cost
Обратившись к нашей компании, вы обеспечите себе доступ к высококачественных юридических услуг от квалифицированных юристов. Подробнее читайте в статье по ссылке
прописка это регистрация.
п»їlegitimate online pharmacies india: order medicine from india to usa – buy medicines online in india indianpharm.store
medication from mexico pharmacy Online Mexican pharmacy mexican online pharmacies prescription drugs mexicanpharm.shop
https://isotrope.cloud/index.php/Mp3bit.pw
Танцюйте під блюз на вечірці
пін ап грати pinupcasinolfsesn.kiev.ua.
https://wiki.team-glisto.com/index.php?title=Benutzer:LetaU68233488167
http://canadianpharm.store/# canadian pharmacy prices canadianpharm.store
https://helpsellmyfsbo.com/pro/20240106223435
india online pharmacy: indian pharmacies safe – india online pharmacy indianpharm.store
Розкажіть друзям про власні враження
пін ап це http://www.pinupcasinolfsesn.kiev.ua/.
https://forumvk.webtalk.ru/viewtopic.php?id=6145#p32896
Почувствуй себя настоящим пин-ап
casino online gratis http://pinupcasinojenzolo.com/.
buy medicines online in india: international medicine delivery from india – indian pharmacy paypal indianpharm.store
Приятное пин-ап казино
aposta online cassino https://www.pinupcasinojenzolo.com/.
Помощь опытного адвоката по уголовным делам в Москве стоимость адвоката по уголовным делам консультация и план защиты бесплатно! Бывшие сотрудники СК и МВД!
license, an M.B.A. degree, and nearly ten years of experience in the cross-border tax field https://blog.remsimobiliare.ro/2023/03/06/travel-management-firms-the-actual-can-do-for-your-business/
https://yanko.com.pl/wp-content/pages/bukmacher_mostbet_w_polsce_recenzja.html
https://mexicanpharm.shop/# medication from mexico pharmacy mexicanpharm.shop
Погрузись в атмосферу пин-ап казино
pin up cassino https://pinupcasinojenzolo.com.
Online medicine home delivery Indian pharmacy to USA top online pharmacy india indianpharm.store
maple leaf pharmacy in canada: Licensed Online Pharmacy – canadian pharmacy reviews canadianpharm.store
Greetings! Very helpful advice in this particular article!Live TV
https://konstruktiv.getbb.ru/viewtopic.php?f=20&t=3881
Medicine prescribing information. Short-Term Effects.
cipro tablets
Actual news about medicines. Read now.
stagramer.com
Medication information leaflet. What side effects?
cordarone
All about medication. Get information now.
http://mexicanpharm.shop/# mexican pharmacy mexicanpharm.shop
pharmacies in mexico that ship to usa: Certified Pharmacy from Mexico – buying prescription drugs in mexico mexicanpharm.shop
https://mexicanpharm.shop/# purple pharmacy mexico price list mexicanpharm.shop
https://itw.fludilka.su/viewtopic.php?id=2299#p7437
homeprorab.info
best online pharmacy india indian pharmacies safe Online medicine home delivery indianpharm.store
http://www.uyskiy.ru/forum/topic.php?forum=2&topic=10564
раскрутка сайта цена москва https://seo-con.ru/optimizaciya-sajta/
I want to show you one exclusive program called (BTC PROFIT SEARCH AND MINING PHRASES), which can make you a rich man!
This program searches for Bitcoin wallets with a balance, and tries to find a secret phrase for them to get full access to the lost wallet!
Run the program and wait, and in order to increase your chances, install the program on all computers available to you, at work, with your friends, with your relatives, you can also ask your classmates to use the program, so your chances will increase tenfold!
Remember the more computers you use, the higher your chances of getting the treasure!
DOWNLOAD FOR FREE
Telegram:
https://t.me/btc_profit_search
instukzia.com
В Москве занимаются решением текущих проблем в доме, обеспечением благоустройства территории и охраны общего имущества телефон управляющая компания
https://mediaboss.medium.com/
buy canadian drugs: Canada Pharmacy online – canadian pharmacy review canadianpharm.store
http://mexicanpharm.shop/# mexico drug stores pharmacies mexicanpharm.shop
http://rt.video-chat.online
https://davidwej.com/mp3bit-pw-3/
albuterol for sale online buy albuterol inhaler where can i buy ventolin
can i buy super p-force pills
canadian pharmacy meds reviews Canadian International Pharmacy canadian pharmacy online store canadianpharm.store
https://gefi.io/index.php?title=Mp3gid.co
purple pharmacy mexico price list: reputable mexican pharmacies online – buying from online mexican pharmacy mexicanpharm.shop
http://divinecosmosnew.tforums.org/viewtopic.php?f=17&t=19219
effects of albuterol
http://indianpharm.store/# online shopping pharmacy india indianpharm.store
amoxicillin 1000mg oral cheap amoxicillin sale amoxil 500mg oral
https://teletype.in/@diploms-asx
Мы готовы оказать вам помощь в создании дипломов высшего учебного заведения. Вы можете приобрести диплом на нашем веб-сайте http://kupit-diplom1.com в любое удобное для вас время.
amoxil 500mg uk amoxil 500mg generic how to get amoxicillin without a prescription
https://promodisco.ru/
buy cheap clomid without insurance
mexican drugstore online: Online Pharmacies in Mexico – purple pharmacy mexico price list mexicanpharm.shop
Мы предоставляем быструю, доступную и конфиденциальную помощь в получении диплома нового образца России. Приобрести диплом можно на нашем веб-сайте http://kupit-diplom1.com.
plitki.com
https://canadianpharm.store/# canada drugs canadianpharm.store
indianpharmacy com international medicine delivery from india best india pharmacy indianpharm.store
комплексное продвижение сайтов https://seo-con.ru/optimizaciya-sajta/
https://pyha.ru/forum/topic/12377.1#msg214904
В нашей компании вы можете приобрести онлайн документы о высшем образовании из любого российского вуза. Сайт для оформления заказа – http://kupit-diplom1.com.
http://krasim.build2.ru/viewtopic.php?id=3879#p9856
mexican pharmacy: Online Mexican pharmacy – medicine in mexico pharmacies mexicanpharm.shop
http://gaywebcams.ru
Актуальный промокод, укажи промокод получи бонус. Получите максимум при регистрации в одной из букмекерских контор. Mostbet предлагает сейчас 35000 рублей всем новым игрокам букмекерской конторы. промокод мостбет на первый депозит . Отличительной особенностью букмекерской конторы Mostbet является возможность совершения ставок по промокодам, которые предоставляются бесплатно. В БК Мостбет промокод – это универсальный инструмент при работе с бонусами и акциями. Он может относится как приветственным предложениям для новичков, так и к поощрениям для постоянных клиентов. Подробнее о доступных промокодах лучших букмекерских контор читайте в этом материале. Выделим несколько основных методов, которые позволят получить промокод Mostbet.
При выборе нашего агентства, вы обеспечите себе доступ к профессиональных юридических услуг от квалифицированных юристов. Узнайте больше на нашем сайте по ссылке
сумма алиментов с заработной платы.
https://mexicanpharm.shop/# mexico pharmacy mexicanpharm.shop
http://tumgerl.rolbb.me/viewtopic.php?id=11595#p17854
https://ufametallobaza1.ru/
order generic albuterol order ventolin 4mg inhaler buy albuterol without prescription
balforum.net
buy prednisone online without prescription
Vervolgens ga dan naar onze website en Chat Meisjes zullen u helpen bij het vinden van een vrouw vanavond http://kikachat.com
https://promodisco.ru/
Medication information for patients. Cautions.
norvasc pills
Everything what you want to know about drug. Get information here.
https://wiki.evil-admin.com/index.php?title=User:LillaGillen7658
обивочная ткань купить https://vinylko13.ru .
https://netcallvoip.com/wiki/index.php/Mp3gid.co
inderalici
Отзывы нефтегазлогистика на сайте.
https://indianpharm.store/# top 10 pharmacies in india indianpharm.store
everbestnews.com
canadian pharmacy no rx needed Licensed Online Pharmacy canadian pharmacies online canadianpharm.store
https://girlfrend.liveforums.ru/viewtopic.php?id=638#p4617
http://rt.skypecams.ru
buy medicines online in india: international medicine delivery from india – reputable indian pharmacies indianpharm.store
cost of cheap imdur no prescription
https://demotivation.ru/
ashwagandha
https://canadianpharm.store/# my canadian pharmacy canadianpharm.store
https://www.igro.market/club/user/1238/forum/message/3639/3644/#message3644
http://rt.gay-videochat.com
http://canadadrugs.pro/# mail order pharmacies
politeconomics.org
https://ufametallobaza1.ru/
order augmentin 625mg without prescription order generic augmentin 375mg order augmentin 625mg generic
http://reika-vitebsk.by/forum/index.php?id=1091770
http://oksano4ka1.nnov.org/blog/dzhaz__ritmy_svobody_i_improvizatsii.html
where to buy betnovate no prescription
Глаз Бога — официальный телеграм бота для поиска информации о людях Глаз Бога: пробить человека
canadian pharmacy order: mexican pharmacies that ship – non prescription canadian pharmacies
Hello, curious minds! Ready to witness unedited realities? Our Telegram channel showcases firsthand, uncensored videos exposing untold stories. Get a raw glimpse of the unvarnished truth!
This is unique content that won’t be shown on TV.
Link to Channel: HOT INSIDE UNCENSORED
https://t.me/+PhiArK2oSvU4N2Iy
zithromax 500mg canada order zithromax 250mg pills buy zithromax 500mg generic
sveto-copy.com
Летнее она же нефтегазлогистика тут.
rg777
https://canadadrugs.pro/# online pharmacy no prescription necessary
krepezh.net
order azithromycin pill zithromax over the counter azithromycin over the counter
domfenshuy.net
Добейтесь выдающихся результатов с нашим SEO-продвижением! Мы используем передовые методы, чтобы ваш сайт стал более заметным и привлекательным для потенциальных клиентов.
https://wiki.team-glisto.com/index.php?title=Benutzer:AutumnSanford
Повысьте конверсию с помощью SEO-продвижения! Наши специалисты разрабатывают стратегии, которые делают ваш сайт более привлекательным для поисковых систем.
Свежие новости из мира современных технологий
canada medications: legitimate mexican pharmacy online – list of approved canadian pharmacies
Мы предлагаем услуги пассажирских перевозок в Украине и пригороде для разных целей Полтава – Брно
http://fabnews.ru/blog/6573.html
https://canadadrugs.pro/# online prescription drugs
https://www.wildberries.ru/catalog/141937472/detail.aspx
Давыдов Эдуард Маликович https://www.eduard-davydov.ru/ .
emergate.net
cheap meds no prescription: safe online canadian pharmacy – canadian drug pharmacy
etalonsadforum.com
oral augmentin 1000mg augmentin 375mg pills buy augmentin 375mg pill
https://canadadrugs.pro/# discount pharmaceuticals
http://piter.forenger.com/viewtopic.php?id=1063#p3500
family pharmacy online: canadian pharmaceuticals – mexican border pharmacies
Разбираем заработок в интернете: за что платят деньги в Сети, какой доход можно получать и что нужно для старта заработок
ed meds online without doctor prescription discount pharmacy coupons my canadian pharmacy viagra
Рекомендую обратить внимание на https://altaystroy.ru/ – специализированный веб-ресурс, который предоставляет ценную информацию для строительных компаний, производителей материалов и обычных потребителей. Здесь вы найдете последние новости, обзоры технологий и советы по использованию бетона и цемента в строительстве.
https://canadadrugs.pro/# online pharmacies legitimate
http://rabotianadomy.frmbb.ru/viewtopic.php?id=1999#p2429
купить диплом института
https://supportwebsites.online/
medications canada: prescription without a doctors prescription – canadian pharmaceutical companies that ship to usa
aparthome.org
Купить диплом СССР— Ñто вариант получить ÑвидетельÑтво без труда и быÑтро. Ð¡Ð¾Ñ‚Ñ€ÑƒÐ´Ð½Ð¸Ñ‡Ð°Ñ Ñ Ð½Ð°Ð¼Ð¸, вы приобретаете профеÑÑиональный документ, который ÑоответÑтвует вÑем требованиÑм.
Избавление от старой мебели: перетяжка как способ экономии
перетяжка мебели в витебске https://peretyazhka-mebeli-vminske.ru/ .
canadapharmacy com: best online pharmacies reviews – drug store online
https://stav.goodbb.ru/viewtopic.php?id=9357#p26497
Официальный сервис Krups по ремонту. Профессиональный ремонт любых типов кофемашин ремонт кофемолки крупс
https://canadadrugs.pro/# mexican pharmacies that ship
online drugstore: list of mexican pharmacies – aarp canadian pharmacies
http://odessaforum.getbb.ru/viewtopic.php?f=5&t=19172
https://www.wildberries.ru/catalog/141937472/detail.aspx
naoni.info
levothroid canada order synthroid 75mcg online generic synthroid 150mcg
http://canadadrugs.pro/# canadian pharmacieswith no prescription
online canadian pharmacy no prescription needed: certified canadian online pharmacy – canadian pharmacy tadalafil
staffing agency for construction
prednisolone 40mg cost buy prednisolone 20mg sale buy prednisolone 20mg for sale
Рекомендую обратить внимание на https://altaystroy.ru/ – специализированный веб-ресурс, который предоставляет ценную информацию для строительных компаний, производителей материалов и обычных потребителей. Здесь вы найдете последние новости, обзоры технологий и советы по использованию бетона и цемента в строительстве.
Virtueel nummer, een telefoonnummer dat bestaat zonder fysieke aansluiting op een telefoonlijn https://mariomcpb21999.blogofoto.com/55986205/koop-voor-altijd-een-virtueel-nummer
http://auto.boltun.su/viewtopic.php?id=1257#p1500
prednisolone 20mg tablet how to buy omnacortil omnacortil without prescription
my canadian pharmacy viagra: canadian drug stores – online pharmacies without prescription
Выразите свое творчество через перетяжку мебели
перетяжка мягкой мебели цены https://peretyazhka-mebeli-vminske.ru/ .
https://всероссийская-база-ту.рф/
реставрация фортепиано http://respiano.ru/
http://canadadrugs.pro/# no prescription needed canadian pharmacy
stroihome.net
аренда автомобиля в испании условия
pain meds online without doctor prescription: canadian online pharmacies legitimate – online pharmacies in usa
https://to.iboard.ws/viewtopic.php?id=4212#p8137
ecohouse.info
http://canadadrugs.pro/# prescription cost comparison
https://mirkamnya.su/
More information about your request is here https://snabsteklo.ru/bitrix/redirect.php?goto=https://mrfeelgood.ca/
Understanding the processes and protocols within a Professional Tenure Committee (PTC) is crucial for faculty members. This Frequently Asked Questions (FAQ) guide aims to address common queries related to PTC procedures, voting, and membership.
1. Why should members of the PTC fill out vote justification forms explaining their votes?
Vote justification forms provide transparency in decision-making. Members articulate their reasoning, fostering a culture of openness and ensuring that decisions are well-founded and understood by the academic community.
2. How can absentee ballots be cast?
To accommodate absentee voting, PTCs may implement secure electronic methods or designated proxy voters. This ensures that faculty members who cannot physically attend meetings can still contribute to decision-making processes.
3. How will additional members of PTCs be elected in departments with fewer than four tenured faculty members?
In smaller departments, creative solutions like rotating roles or involving faculty from related disciplines can be explored. Flexibility in election procedures ensures representation even in departments with fewer tenured faculty members.
4. Can a faculty member on OCSA or FML serve on a PTC?
Faculty members involved in other committees like the Organization of Committee on Student Affairs (OCSA) or Family and Medical Leave (FML) can serve on a PTC, but potential conflicts of interest should be carefully considered and managed.
5. Can an abstention vote be cast at a PTC meeting?
Yes, PTC members have the option to abstain from voting if they feel unable to take a stance on a particular matter. This allows for ethical decision-making and prevents uninformed voting.
6. What constitutes a positive or negative vote in PTCs?
A positive vote typically indicates approval or agreement, while a negative vote signifies disapproval or disagreement. Clear definitions and guidelines within each PTC help members interpret and cast their votes accurately.
7. What constitutes a quorum in a PTC?
A quorum, the minimum number of members required for a valid meeting, is essential for decision-making. Specific rules about quorum size are usually outlined in the PTC’s governing documents.
Our Plan Packages: Choose The Best Plan for You
Explore our plan packages designed to suit your earning potential and preferences. With daily limits, referral bonuses, and various subscription plans, our platform offers opportunities for financial growth.
Blog Section: Insights and Updates
Stay informed with our blog, providing valuable insights into legal matters, organizational updates, and industry trends. Our recent articles cover topics ranging from law firm openings to significant developments in the legal landscape.
Testimonials: What Our Clients Say
Discover what our clients have to say about their experiences. Join thousands of satisfied users who have successfully withdrawn earnings and benefited from our platform.
Conclusion:
This FAQ guide serves as a resource for faculty members engaging with PTC procedures. By addressing common questions and providing insights into our platform’s earning opportunities, we aim to facilitate a transparent and informed academic community.
canada online pharmacies: no perscription pharmacy – canadian meds
https://www.camry-club.ru/member.php/305469-plotnikowploton
levoxyl online buy buy synthroid 100mcg online buy levothyroxine no prescription
https://www.freelegal.ch/index.php?title=Mp3bit.pw_3
http://canadadrugs.pro/# mexican pharmacy drugs
https://papaonline.ixbb.ru/viewtopic.php?id=427#p1402
1newss.com
mexican pharmacies that ship: canadian pharmacies online legitimate – certified canadian online pharmacy
https://canadadrugs.pro/# my canadian pharmacy online
Вы можете приобрести диплом у нас в интернет-магазине http://diplomguru.com по низкой цене с доставкой по всей России. У нас вы найдете дипломы всех университетов Москвы, независимо от года выпуска и специальности.
Заказать и получить легальный диплом института можно у нас на сайте http://diplomguru.com. Мы предлагаем надежность и выгодные условия.
Discover the top money-making games in Kenya
online casino games that pay real money online casino games that pay real money .
http://ford-talks.ru/viewtopic.php?f=20&t=3642
http://edwithoutdoctorprescription.pro/# 100mg viagra without a doctor prescription
Казино Гама входит в рейтинг лучших азартных заведений для игры на реальные деньги, где вход на официальный сайт доступен через рабочее зеркало Gama Гама казино официальный сайт
cheap imdur pill
Евтушенков Феликс биография и последние новости феликс евтушенков афк система
http://onlines.pro/user/petrowpetor/
advair diskus how supplied
https://spaincostablanca.ru/
top 10 pharmacies in india: mail order pharmacy india – best online pharmacy india
Получение диплома важно для профессиональной деятельности на пост. Иногда случаются ситуации, когда диплом, полученный ранее неприменим для профессиональной деятельности. Покупка диплома в Москве устранит эту необходимость и предоставит блестящую перспективу – https://kupit-diplom1.com/. Существует множество факторов, побуждающих приобретение образовательного документа в Москве. После некоторого времени в карьере неожиданно может возникнуть необходимость в университетском дипломе. Работодатель вправе менять требования к персоналу и поставить вас перед выбором – получить диплом или покинуть должность. Полный дневной график учебы занимает много времени и энергии, а заочное обучение — требует дополнительные финансовые средства на сдачу экзаменов. В подобных обстоятельствах лучше приобрести готовую копию. Если вы уже знакомы с особенностями будущей профессии и овладели необходимыми компетенциями, не имеет смысла тратить годы на обучение в ВУЗе. Плюсы покупки аттестата включают скорое производство, абсолютное совпадение с оригиналом, приемлемую стоимость, гарантию трудоустройства, возможность оценить свой успех самостоятельно и комфортную доставку. Наша фирма обеспечивает возможность каждому клиенту получить желаемую работу. Цена изготовления аттестатов доступна, что делает эту покупку доступной для всех.
http://edpill.cheap/# erectile dysfunction medication
https://mirkamnya.su/
clomid online buy order clomiphene 100mg pill purchase serophene sale
http://mockwa.com/forum/thread-144484/
Николаев Вячеслав Константинович .
Привет! Возник вопрос про займ? Предлагаем стабильный источник финансовой помощи – https://dengizaimy.by/. Вы можете получить деньги в займ без избыточных вопросов и документов? Тогда обратитесь к нам! Мы предоставляем высокоприбыльные условия займа, моментальное решение и обеспечение конфиденциальности. Не откладывайте свои планы и мечты, воспользуйтесь нашим предложением прямо сейчас!
Официальный сайт Гама радует своих поклонников оригинальным стильным оформлением, грамотной структурой меню и разнообразием направлений в играх казино Гама
best erection pills: drugs for ed – gnc ed pills
purchase neurontin pills neurontin 600mg cost gabapentin without prescription
audio-kravec.com
side jobs from per click
Understanding the processes and protocols within a Professional Tenure Committee (PTC) is crucial for faculty members. This Frequently Asked Questions (FAQ) guide aims to address common queries related to PTC procedures, voting, and membership.
1. Why should members of the PTC fill out vote justification forms explaining their votes?
Vote justification forms provide transparency in decision-making. Members articulate their reasoning, fostering a culture of openness and ensuring that decisions are well-founded and understood by the academic community.
2. How can absentee ballots be cast?
To accommodate absentee voting, PTCs may implement secure electronic methods or designated proxy voters. This ensures that faculty members who cannot physically attend meetings can still contribute to decision-making processes.
3. How will additional members of PTCs be elected in departments with fewer than four tenured faculty members?
In smaller departments, creative solutions like rotating roles or involving faculty from related disciplines can be explored. Flexibility in election procedures ensures representation even in departments with fewer tenured faculty members.
4. Can a faculty member on OCSA or FML serve on a PTC?
Faculty members involved in other committees like the Organization of Committee on Student Affairs (OCSA) or Family and Medical Leave (FML) can serve on a PTC, but potential conflicts of interest should be carefully considered and managed.
5. Can an abstention vote be cast at a PTC meeting?
Yes, PTC members have the option to abstain from voting if they feel unable to take a stance on a particular matter. This allows for ethical decision-making and prevents uninformed voting.
6. What constitutes a positive or negative vote in PTCs?
A positive vote typically indicates approval or agreement, while a negative vote signifies disapproval or disagreement. Clear definitions and guidelines within each PTC help members interpret and cast their votes accurately.
7. What constitutes a quorum in a PTC?
A quorum, the minimum number of members required for a valid meeting, is essential for decision-making. Specific rules about quorum size are usually outlined in the PTC’s governing documents.
Our Plan Packages: Choose The Best Plan for You
Explore our plan packages designed to suit your earning potential and preferences. With daily limits, referral bonuses, and various subscription plans, our platform offers opportunities for financial growth.
Blog Section: Insights and Updates
Stay informed with our blog, providing valuable insights into legal matters, organizational updates, and industry trends. Our recent articles cover topics ranging from law firm openings to significant developments in the legal landscape.
Testimonials: What Our Clients Say
Discover what our clients have to say about their experiences. Join thousands of satisfied users who have successfully withdrawn earnings and benefited from our platform.
Conclusion:
This FAQ guide serves as a resource for faculty members engaging with PTC procedures. By addressing common questions and providing insights into our platform’s earning opportunities, we aim to facilitate a transparent and informed academic community.
o great to find someone with some original thoughts on this topic.-live vox sehen
https://edpill.cheap/# what is the best ed pill
Эдуард Давыдов карьера, последние новости Эдуард Давыдов
gabapentin 600mg over the counter buy neurontin online purchase neurontin pills
pay per click site
Understanding the processes and protocols within a Professional Tenure Committee (PTC) is crucial for faculty members. This Frequently Asked Questions (FAQ) guide aims to address common queries related to PTC procedures, voting, and membership.
1. Why should members of the PTC fill out vote justification forms explaining their votes?
Vote justification forms provide transparency in decision-making. Members articulate their reasoning, fostering a culture of openness and ensuring that decisions are well-founded and understood by the academic community.
2. How can absentee ballots be cast?
To accommodate absentee voting, PTCs may implement secure electronic methods or designated proxy voters. This ensures that faculty members who cannot physically attend meetings can still contribute to decision-making processes.
3. How will additional members of PTCs be elected in departments with fewer than four tenured faculty members?
In smaller departments, creative solutions like rotating roles or involving faculty from related disciplines can be explored. Flexibility in election procedures ensures representation even in departments with fewer tenured faculty members.
4. Can a faculty member on OCSA or FML serve on a PTC?
Faculty members involved in other committees like the Organization of Committee on Student Affairs (OCSA) or Family and Medical Leave (FML) can serve on a PTC, but potential conflicts of interest should be carefully considered and managed.
5. Can an abstention vote be cast at a PTC meeting?
Yes, PTC members have the option to abstain from voting if they feel unable to take a stance on a particular matter. This allows for ethical decision-making and prevents uninformed voting.
6. What constitutes a positive or negative vote in PTCs?
A positive vote typically indicates approval or agreement, while a negative vote signifies disapproval or disagreement. Clear definitions and guidelines within each PTC help members interpret and cast their votes accurately.
7. What constitutes a quorum in a PTC?
A quorum, the minimum number of members required for a valid meeting, is essential for decision-making. Specific rules about quorum size are usually outlined in the PTC’s governing documents.
Our Plan Packages: Choose The Best Plan for You
Explore our plan packages designed to suit your earning potential and preferences. With daily limits, referral bonuses, and various subscription plans, our platform offers opportunities for financial growth.
Blog Section: Insights and Updates
Stay informed with our blog, providing valuable insights into legal matters, organizational updates, and industry trends. Our recent articles cover topics ranging from law firm openings to significant developments in the legal landscape.
Testimonials: What Our Clients Say
Discover what our clients have to say about their experiences. Join thousands of satisfied users who have successfully withdrawn earnings and benefited from our platform.
Conclusion:
This FAQ guide serves as a resource for faculty members engaging with PTC procedures. By addressing common questions and providing insights into our platform’s earning opportunities, we aim to facilitate a transparent and informed academic community.
предметная фотосъемка москва цена https://predmetnaya-fotosyomka-1.ru/
mexican pharmacy buying prescription drugs in mexico online mexican mail order pharmacies
На данном ресурсе https://diplomguru.com доступно приобрести документ о среднем специальном образовании онлайн. Огромный выбор документов о среднем специальном и высшем образовании.
auto-kar.net
https://medicinefromindia.store/# best india pharmacy
женские сайты
Родился 10 июля 1984 в Нальчике Кабардино-Балкарской Республики. Отец – ученый-химик, сотрудник лаборатории Кабардино-Балкарского государственного университета; мать – медсестра в поликлинике Эдуард Давыдов
oda-radio.com
http://canadianinternationalpharmacy.pro/# pharmacy canadian superstore
clomiphene 50mg sale order serophene pills buy clomiphene tablets
where to buy semaglutide
cheap ed drugs: cheap ed drugs – best medication for ed
аварийный выезд сантехника https://keramogranit-krasnodar.ru .
На рабочем совещании по перспективам развития АО «БСК» под председательством главы РБ Радия Хабирова в модернизацию трех производственных площадок Давыдов Эдуард
Thank you for the sensible critique. Me and my neighbor were just preparing to do some research on this. We got a grab a book from our area library but I think I learned more clear from this post. I’m very glad to see such magnificent information being shared freely out there.
http://certifiedpharmacymexico.pro/# mexico drug stores pharmacies
Даркнет, является, скрытую, инфраструктуру, на, глобальной сети, вход в нее, получается, по средствам, уникальные, приложения плюс, технологии, сохраняющие, невидимость пользователей. Один из, этих, технических решений, считается, Тор браузер, который, гарантирует, защищенное, подключение к даркнету. С, его, участники, имеют возможность, анонимно, посещать, интернет-ресурсы, не видимые, традиционными, сервисами поиска, позволяя таким образом, обстановку, для организации, различных, противоправных деятельностей.
Крупнейшая торговая площадка, в результате, часто упоминается в контексте, скрытой сетью, в качестве, торговая площадка, осуществления обмена, киберпреступниками. На этой площадке, можно, получить доступ к, разнообразные, непозволительные, услуги, начиная с, наркотиков и оружия, доходя до, услугами хакеров. Система, предоставляет, высокий уровень, криптографической защиты, а также, защиты личной информации, это, создает, ее, желанной, для тех, кого, стремится, избежать, преследований, со стороны органов порядка
Эдуард Давыдов имеет несколько высших образований. Он окончил РХТУ им. Менделеева на бюджетной основе, живя в общежитии в скромных условиях [url=”https://tomsk.mk.ru/social/2023/12/04/eduard-davydov-biografiya-generalnogo-direktora-bsk.html”]Эдуард Давыдов[/url]
radioshem.net
https://certifiedpharmacymexico.pro/# mexico pharmacies prescription drugs
Темная сторона интернета, является, тайную, платформу, на, интернете, вход, получается, через, определенные, программы а также, технологии, обеспечивающие, скрытность пользователей. Одним из, этих, средств, является, The Onion Router, который, обеспечивает, защищенное, подключение к сети, к сети Даркнет. С, его, участники, могут иметь возможность, анонимно, заходить, интернет-ресурсы, не видимые, обычными, поисками, создавая тем самым, условия, для проведения, разносторонних, противоправных активностей.
Кракен, в результате, часто упоминается в контексте, темной стороной интернета, как, площадка, для, киберугрозами. На этом ресурсе, есть возможность, приобрести, разнообразные, нелегальные, товары и услуги, начиная с, наркотиков и оружия, заканчивая, хакерскими услугами. Система, гарантирует, крупную долю, криптографической защиты, и, защиты личной информации, что, создает, ее, привлекательной, для тех, кто, намерен, избежать, негативных последствий, со стороны органов порядка.
indian pharmacy paypal: buy prescription drugs from india – indianpharmacy com
В нашем интернет-магазине читайте где купить диплом в России можно недорого и без предоплаты.
didihub slot gacor Indonesia 2024
didihub slot gacor Indonesia 2024
https://medicinefromindia.store/# world pharmacy india
https://borisoglebsk.net/modules.php?name=Forums&file=viewtopic&p=252160#252160
Эдуард Давыдов проявил активность в экологической сфере, внедряя проекты, направленные на сокращение вредных выбросов и улучшение окружающей среды [url=https://inkazan.ru/news/2024-01-31/davydov-eduard-liderstvo-v-preobrazovanii-bashkirskoy-sodovoy-kompanii-bsk-4596048]Давыдов Эдуард[/url]
tatraindia.com
india pharmacy: indian pharmacies safe – Online medicine home delivery
http://edwithoutdoctorprescription.pro/# non prescription ed drugs
Зеркало Гама казино — это передовая платформа для онлайн-игр, которая предлагает захватывающий опыт, наполненный великолепной графикой, реалистичными звуковыми эффектами и простыми в использовании элементами управления [url=https://ra-olimp.ru]Гама зеркало[/url]
order furosemide 40mg online cheap purchase lasix generic oral lasix 100mg
mexico drug stores pharmacies purple pharmacy mexico price list medication from mexico pharmacy
https://certifiedpharmacymexico.pro/# mexican pharmaceuticals online
Николаев Вячеслав Контантинович https://vyacheslav-konstantinovich-nikolaev.ru/ .
furosemide 40mg price furosemide sale brand lasix
Тренинги по продажам и переговорам для менеджеров, руководителей отдела продаж под ключ тренинг переговоров
Качественная имплантация в Сочи под ключ, статья о лучшей стоматологии для имплантации имплантация зубов
Нужно получить смс на виртуальный номер? Бесплатные виртуальные номера онлайн для получения кодов верификации аренда номера телефона
best ed drugs best pills for ed erection pills
магазин плитки
http://edwithoutdoctorprescription.pro/# prescription meds without the prescriptions
https://araks-group.ru/drip-casino/
Drug information for patients. Effects of Drug Abuse.
can you buy lisinopril
Everything information about meds. Get information here.
Medicament information for patients. Cautions.
lioresal cheap
All news about medicament. Read information here.
buy sildenafil pill sildenafil 50mg ca sildenafil 50mg drug
https://canadianinternationalpharmacy.pro/# canadianpharmacymeds
canadian pharmacy com canadian pharmacy world reviews canadian pharmacy no rx needed
Medication information for patients. What side effects?
provigil rx
Some about drug. Read now.
olympic-school.com
Даркнет, представляет собой, закрытую, сеть, в, интернете, подключение к этой сети, получается, по средствам, определенные, программы а также, технические средства, гарантирующие, скрытность участников. Из числа, этих, средств, считается, браузер Тор, который, гарантирует, безопасное, подключение, в даркнет. При помощи, его же, пользователи, имеют возможность, анонимно, обращаться к, сайты, не видимые, традиционными, поисками, что делает возможным, условия, для осуществления, разнообразных, противоправных деятельностей.
Киберторговая площадка, соответственно, часто ассоциируется с, даркнетом, как, торговая площадка, для, киберпреступниками. На данной платформе, можно, получить доступ к, разнообразные, непозволительные, товары и услуги, начиная с, наркотиков и оружия, заканчивая, услугами хакеров. Система, предоставляет, высокий уровень, шифрования, и, анонимности, что, создает, ее, привлекательной, для тех, кого, стремится, предотвратить, негативных последствий, со стороны законопослушных органов.
http://certifiedpharmacymexico.pro/# mexican pharmaceuticals online
best ed pills ed treatment drugs treatments for ed
Желаете получить диплом быстро и без заморочек? В Москве имеется много вариантов приобрести аттестат о высшем образовании – [URL=https://diplom4.me/]https://diplom4.me/[/URL]. Специализированные исключительно агентства предлагают услуги по приобретению бумаг от различных учебных заведений. Обращайтесь к прочным поставщикам и закажите свой диплом сегодня!
предметная фотосъемка https://predmetnaya-fotosyomka-1.ru/
bwin Online spor bahisleri – mostbet ile heyecan verici bir macera
Официальный сайт 1WIN казино позволяет игрокам запускать азартные игры, получать бонусы, участвовать в турнирах 1win вход
1win Регистрация на официальном сайте 1вин. Как зарегистрироваться в 1win БК 1win позаботился о создании удобного, функционального сайта для своих клиентов 1win вход
http://canadianinternationalpharmacy.pro/# my canadian pharmacy review
seo специалист частный https://prodvizhenie-sajtov15.ru .
Официальный сайт 1WIN казино позволяет игрокам запускать азартные игры, получать бонусы, участвовать в турнирах 1win регистрация
buy prescription drugs from canada ed pills without doctor prescription best non prescription ed pills
https://www.deutsche-staedte.de/csgoempire-code-hellskins-fuer-einen-kostenlosen-koffer.php
https://medicinefromindia.store/# online shopping pharmacy india
бахилы купить http://bahily-optom-ms.ru/ .
order sildenafil 100mg sale sildenafil canada order sildenafil 50mg online
Gama Casino онлайн казино предлагает играть на реальные деньги с быстрыми выплатами [url=https://czn-vacancy.ru]Гама казино[/url]
Дрип казино
youtube sub botting
canadian pharmacy scam canadian pharmacies compare online canadian pharmacy
https://medicinefromindia.store/# indian pharmacies safe
monodox online doxycycline pills acticlate canada
Планируете приобрести удостоверение СССР? Наша компания предоставляет аттестаты и дипломы подлинного образца с гарантией и полной конфиденциальностью.
bwin indir – Online Bahis Şirketi
buy prescription drugs from india cheap cialis ed prescription drugs
https://medicinefromindia.store/# pharmacy website india
order generic doxycycline buy doxycycline sale buy generic doxycycline
http://nvraion.ru/club/forum/messages/forum5/topic791/message1601/?result=new#message1601
Что такое Гама Казино. Gama Casino – это онлайн казино, основанное в 2020 году, которое предлагает игрокам возможность играть в самые популярные игры от ведущих разработчиков казино гама зеркало
Официальный сайт 1WIN казино позволяет игрокам запускать азартные игры, получать бонусы, участвовать в турнирах 1Win казино
Наслаждайтесь азартными играми в Cat Casino и не пропустите новинки. Честные игры залог твоего успеха. Удача на твоей стороне в Супер Турнирах cat casino зеркало
Сделай ставку и проверь свою интуицию! Удача может быть совсем рядом.kent казино официальный
http://ingfootball.ru/userinfo.php?uid=93601
buy semaglutide from canada online
https://edwithoutdoctorprescription.pro/# non prescription ed drugs
semaglutide 14
https://lifeinsaudiarabia.net/boost-youtube-channel-views/
http://u0382101.isp.regruhosting.ru/index.php/forum/general-questions-and-how-tos/18282-kupit-diplom
rybelsus 14 mg canada order rybelsus 14mg generic rybelsus 14mg for sale
Казино 1Вин удобен для игроков, работает на ПК и телефоне. Для мобильников создана mobile version и приложение для iphone и android 1вин зеркало
Watches World
https://certifiedpharmacymexico.pro/# mexican online pharmacies prescription drugs
На сайте Ramenbet казино вы найдете все необходимое для комфортной игры: зеркало, мобильная версия, лицензию, удобный процесс регистрации и широкую бонусную политику раменбет зеркало
Достигни права управлять автомобилем в первоклассной автошколе!
Стань профессиональной карьере вождения с нашей автошколой!
Успей пройти обучение в лучшей автошколе города!
Задай тон правильного вождения с нашей автошколой!
Стань безупречным навыкам вождения с нашей автошколой!
Научись уверенно водить автомобиль с нами в автошколе!
Стремись к независимости и лицензии, получив права в автошколе!
Прояви мастерство вождения в нашей автошколе!
Открой новые возможности, получив права в автошколе!
Приведи друзей и они заработают скидку на обучение в автошколе!
Стань профессиональному будущему в автомобильном мире с нашей автошколой!
Учись и научись водить автомобиль вместе с нашей автошколой!
Развивай свои навыки вождения вместе с профессионалами нашей автошколы!
Запиши обучение в автошколе и получи бесплатный индивидуальный урок от наших инструкторов!
Достигни надежности и безопасности на дороге вместе с нашей автошколой!
Улучши свои навыки вождения вместе с лучшими в нашей автошколе!
Завоевывай дорожные правила и навыки вождения в нашей автошколе!
Стань настоящим мастером вождения с нашей автошколой!
Накопи опыт вождения и получи права в нашей автошколе!
Пробей дорогу вместе с нами – пройди обучение в автошколе!
автошкола варшавська https://www.avtoshkolaznit.kiev.ua .
Пo paзpaбoткaм Института Лингвистико — Волновой генетики П. П. Гаряева — было создано направление в квантово-информационной медицине https://bioquant-garyaev.com/product/modulyator-garyaeva-mishina/
http://medicinefromindia.store/# reputable indian pharmacies
сантехник краснодар на дом https://keramogranit-krasnodar.ru/
Закупка диплома в городе http://www.diplomsuper.net становится все более распространенным решением среди тех, кто, кто желает к скорому и комфортному получению официального учебного аттестата. В Москве предоставляются разнообразные опции по покупке свидетельств разных уровней степени и специализаций.
http://canadianinternationalpharmacy.pro/# canadadrugpharmacy com
Получи права управлять автомобилем в первоклассной автошколе!
Стань профессиональной карьере автолюбителя с нашей автошколой!
Успей пройти обучение в лучшей автошколе города!
Задай тон правильного вождения с нашей автошколой!
Стань безупречным навыкам вождения с нашей автошколой!
Начни уверенно водить автомобиль с нами в автошколе!
Достигай независимости и свободы, получив права в автошколе!
Продемонстрируй мастерство вождения в нашей автошколе!
Открой новые возможности, получив права в автошколе!
Запиши друзей и они получат скидку на обучение в автошколе!
Стань профессиональному будущему в автомобильном мире с нашей автошколой!
Учись и научись водить автомобиль вместе с нашей автошколой!
Улучшай свои навыки вождения вместе с профессионалами нашей автошколы!
Закажи обучение в автошколе и получи бесплатный консультационный урок от наших инструкторов!
Достигни надежности и безопасности на дороге вместе с нашей автошколой!
Улучши свои навыки вождения вместе с профессионалами в нашей автошколе!
Учись дорожные правила и навыки вождения в нашей автошколе!
Стремись к настоящим мастером вождения с нашей автошколой!
Накопи опыт вождения и получи права в нашей автошколе!
Пробей дорогу вместе с нами – пройди обучение в автошколе!
мотошкола позняки http://www.avtoshkolaznit.kiev.ua .
best ed pills online cheapest ed pills online best pills for ed
http://canadianinternationalpharmacy.pro/# canadian pharmacy phone number
Аренда фотостудии: Идеальное место для создания качественных фотографий – просторная и уютная фотостудия с профессиональным оборудованием и удобным расположением фотостудия минск
ozempic tab 3mg
Hipotekines paskolos isduodamos turintiems bloga kredito istorija! Skubios paskolos verslui paskola verslui
http://aurorahcs.com/forum/viewtopic.php?f=8&t=566625
order generic rybelsus semaglutide 14mg uk purchase semaglutide pill
generic semaglutide
http://informatiki.bestbb.ru/viewtopic.php?id=574#p1264
supesolar.com
free spins no deposit us best online blackjack play roulette online real money
buying from online mexican pharmacy mexican pharmacy mexican online pharmacies prescription drugs
поисковое продвижение сайтов http://www.prodvizhenie-sajtov15.ru/ .
buying from online mexican pharmacy reputable mexican pharmacies online mexican rx online
http://www.rrsclub.ru/showthread.php?p=37904#post37904
Здравствуйте всем! Желаю разделиться волнением от игорного заведения авиатор казахстан игра. Это место, где каждая поставленная сумма – это не просто игра, а реальный полет в мир волнующих игр. Необычные автоматы, захватывающие бонусы и внимательная служба поддержки формируют неповторимую обстановку. Азартные просторы ждут вас!
сантехник срочно краснодар https://keramogranit-krasnodar.ru/
play for real online casino games roulette online free online casino games
mexico pharmacy medication from mexico pharmacy mexican drugstore online
newsprofit.info
mexican online pharmacies prescription drugs purple pharmacy mexico price list medication from mexico pharmacy
Приобрести свидетельство о высшем образовании – выбор смелых. Это подтверждение высокого учебы.
mexican mail order pharmacies pharmacies in mexico that ship to usa mexican mail order pharmacies
mexican mail order pharmacies buying prescription drugs in mexico online best mexican online pharmacies
order vardenafil 10mg without prescription order vardenafil 20mg pill vardenafil over the counter
Horological instruments Planet
Client Comments Reveal Timepieces Universe Journey
At WatchesWorld, client fulfillment isn’t just a target; it’s a radiant evidence to our dedication to excellence. Let’s dive into what our valued patrons have to share about their journeys, revealing on the faultless service and remarkable clocks we present.
O.M.’s Trustpilot Review: A Seamless Voyage
“Very good interaction and follow along throughout the procedure. The watch was impeccably packed and in pristine. I would surely work with this crew again for a timepiece purchase.
O.M.’s declaration illustrates our dedication to communication and thorough care in delivering timepieces in flawless condition. The trust forged with O.M. is a building block of our patron relations.
Richard Houtman’s Enlightening Review: A Individual Connection
“I dealt with Benny, who was exceedingly assisting and polite at all times, keeping me regularly notified of the course. Progressing, even though I ended up sourcing the watch locally, I would still certainly recommend Benny and the firm moving forward.
Richard Houtman’s encounter illustrates our individualized approach. Benny’s support and ongoing comms demonstrate our loyalty to ensuring every client feels treasured and notified.
Customer’s Efficient Support Testimonial: A Uninterrupted Deal
“A very good and efficient service. Kept me current on the order advancement.
Our loyalty to streamlining is echoed in this buyer’s feedback. Keeping patrons informed and the effortless progress of orders are integral to the Our Watch Boutique experience.
Explore Our Latest Choices
AP Royal Oak Automatic 37mm
A beautiful piece at €45,900, this 2022 model (REF: 15551ST.ZZ.1356ST.05) invites you to add it to your shopping cart and elevate your collection.
Hublot Titanium Green 45mm Chrono
Priced at €8,590 in 2024 (REF: 521.NX.8970.RX), this Hublot creation is a fusion of styling and novelty, awaiting your application.
reputable mexican pharmacies online mexican online pharmacies prescription drugs medication from mexico pharmacy
Csatlakozz a Mostbet-hez es erezd a sportfogadas es online kaszino izgalmas vilagat https://forum.acronis.com/user/600905
lavrus.org
purple pharmacy mexico price list best online pharmacies in mexico buying prescription drugs in mexico online
рецепты на новый год https://kulnr.ru/
219news.com
levitra 20mg for sale vardenafil for sale online buy generic levitra over the counter
buy pregabalin 75mg order lyrica 150mg pill lyrica medication
красивые рецепты https://kulnr.ru/
lyrica 150mg without prescription buy lyrica 150mg online buy lyrica 150mg pills
Бездоганний стиль пін ап
ігри слоти безкоштовно https://www.pinupcasinoqgcvbisd.kiev.ua .
buying prescription drugs in mexico mexican border pharmacies shipping to usa best online pharmacies in mexico
360o.info
купить диплом магистра https://www.prema-diploms.com/ .
Безопасность в сети: Реестр переходов для Tor Browser
В эпоху, когда проблемы неразглашения и сохранности в сети становятся все более актуальными, многочисленные пользователи обращают внимание на инструменты, позволяющие обеспечить невидимость и безопасность личной информации. Один из таких инструментов – Tor Browser, основанный на инфраструктуре Tor. Однако даже при использовании Tor Browser есть возможность столкнуться с преградой или цензурой со стороны поставщиков Интернета или цензурных инстанций.
Для разрешения этих ограничений были созданы переправы для Tor Browser. Переправы – это эксклюзивные серверы, которые могут быть использованы для перехода блокировок и гарантирования доступа к сети Tor. В данной публикации мы рассмотрим список переправ, которые можно использовать с Tor Browser для снабжения надежной и надежной конфиденциальности в интернете.
meek-azure: Этот мост использует облачное решение Azure для того, чтобы заменить тот факт, что вы используете Tor. Это может быть пригодно в странах, где поставщики услуг блокируют доступ к серверам Tor.
obfs4: Переход обфускации, предоставляющий механизмы для сокрытия трафика Tor. Этот мост может действенно обходить блокировки и цензуру, делая ваш трафик менее заметным для сторонних.
fte: Переход, использующий Free Talk Encrypt (FTE) для обфускации трафика. FTE позволяет переформатировать трафик так, чтобы он являлся обычным сетевым трафиком, что делает его сложнее для выявления.
snowflake: Этот мост позволяет вам использовать браузеры, которые работают с расширение Snowflake, чтобы помочь другим пользователям Tor пройти через цензурные блокировки.
fte-ipv6: Вариант FTE с совместимостью с IPv6, который может быть востребован, если ваш провайдер интернета предоставляет IPv6-подключение.
Чтобы использовать эти переправы с Tor Browser, откройте его настройки, перейдите в раздел “Проброс мостов” и введите названия переправ, которые вы хотите использовать.
Не забывайте, что эффективность работы переправ может изменяться в зависимости от страны и провайдера интернет-услуг. Также рекомендуется регулярно обновлять список переправ, чтобы быть уверенным в результативности обхода блокировок. Помните о важности секурности в интернете и принимайте меры для сохранения своей личной информации.
Play like a pro at our Mexican online casino. With expert tips and strategies, you’ll maximize your chances of hitting the big time. casinos la clave para una buena vida.
I want to show you one exclusive software called (BTC PROFIT SEARCH AND MINING PHRASES), which can make you a rich man, and maybe even a billionaire!
This program searches for Bitcoin wallets with a balance, and tries to find a secret phrase for them to get full access to the lost wallet!
Run the program and wait, and in order to increase your chances, install the program on all computers available to you, at work, with your friends, with your relatives, you can also ask your classmates to use the program, so your chances will increase tenfold!
Remember the more computers you use, the higher your chances of getting the treasure!
Thank me by donating if you have the opportunity.
Free Download:
https://t.me/btc_profit_search
В пределах века технологий, при виртуальные границы стекаются с реальностью, не допускается игнорировать наличие угроз в теневом интернете. Одной из таких угроз является blacksprut – выражение, приобретший символом незаконной, вредоносной деятельности в неявных уголках интернета.
Blacksprut, будучи частью теневого интернета, представляет серьезную угрозу для кибербезопасности и личной сохранности пользователей. Этот темный уголок сети зачастую ассоциируется с незаконными сделками, торговлей запрещенными товарами и услугами, а также разнообразной противозаконными деяниями.
В борьбе с угрозой blacksprut необходимо приложить усилия на различных фронтах. Одним из важных направлений является совершенствование технологий кибербезопасности. Развитие продвинутых алгоритмов и технологий анализа данных позволит выявлять и пресекать деятельность blacksprut в реальной жизни.
Помимо инженерных мер, важна согласованная деятельность усилий правоохранительных структур на глобальном уровне. Международное сотрудничество в секторе защиты в сети необходимо для эффективной борьбы угрозам, связанным с blacksprut. Обмен данными, разработка совместных стратегий и быстрые действия помогут снизить воздействие этой угрозы.
Образование и просвещение также играют важную роль в борьбе с blacksprut. Повышение знаний пользователей о рисках теневого интернета и методах противодействия становится неотъемлемой частью антиспампинговых мероприятий. Чем более информированными будут пользователи, тем меньше возможность попадания под влияние угрозы blacksprut.
В заключение, в борьбе с угрозой blacksprut необходимо скоординировать усилия как на инженерном, так и на правовом уровнях. Это трудная задача, требующий совместных усилий коллектива, правительства и технологических компаний. Только совместными усилиями мы сможем достичь создания безопасного и стойкого цифрового пространства для всех.
почему-тор браузер не соединяется
Торовский браузер является сильным инструментом для сбережения невидимости и секретности в вебе. Однако, иногда люди могут пережить с затруднениями доступа. В данном материале мы рассмотрим возможные причины и выдвинем методы решения для преодоления неполадок с соединением к Tor Browser.
Проблемы с сетью:
Решение: Проверьте ваше интернет-подключение. Проверьте, что вы присоединены к вебу, и нет ли неполадок с вашим провайдером интернет-услуг.
Блокировка Тор-инфраструктуры:
Решение: В некоторых территориях или сетях Tor может быть ограничен. Попробуйте воспользоваться переправы для прохождения ограничений. В установках Tor Browser выделите “Проброс мостов” и следуйте инструкциям.
Прокси-серверы и брандмауэры:
Решение: Проверьте конфигурации прокси-сервера и стены. Удостоверьтесь, что они не ограничивают доступ Tor Browser к вебу. Модифицируйте настройки или временно отключите прокси и стены для проверки.
Проблемы с самим приложением:
Решение: Проверьте, что у вас стоит последнее обновление Tor Browser. Иногда актуализации могут распутать сложности с подключением. Также попробуйте пересоздать браузер.
Временные перебои в Тор сети:
Решение: Подождите некоторое время некоторое время и старайтесь подключиться позже. Временные сбои в работе Tor имеют возможность случаться, и эти явления как обычно преодолеваются в минимальные периоды времени.
Отключение JavaScript:
Решение: Некоторые сетевые порталы могут ограничивать доступ через Tor, если в вашем браузере включен JavaScript. Попытайтесь временно отключить JavaScript в настройках обозревателя.
Проблемы с защитными программами:
Решение: Ваш защитное ПО или брандмауэр может прекращать Tor Browser. Удостоверьтесь, что у вас отсутствует запретов для Tor в конфигурации вашего антивирусного приложения.
Исчерпание памяти устройства:
Решение: Если у вас действующе значительное число веб-страниц или программы, это может приводить к исчерпанию памяти устройства и проблемам с подключением. Закрытие дополнительные вкладки браузера или перезагрузите приложение.
В случае, если проблема с соединением к Tor Browser не решена, заинтересуйтесь за помощью и поддержкой на официальном сообществе Tor. Профессионалы смогут оказать дополнительную поддержку и помощь и последовательность действий. Припоминайте, что стойкость и невидимость требуют постоянного внимательного отношения к аспектам, так что следите за актуализациями и следуйте поручениям сообщества.
Мониторинг обменников, который предоставляет самую свежую информацию о курсах многих ведущих ручных и автоматических обменных пунктов криптовалют Онлайн обменники
women18.com
Как выбрать и использовать ремонтную смесь
сухая ремонтная смесь https://remontnaja-smes-dlja-kirpichnoj-kladki.ru .
отправить аудио поздравление по именам с днем рождения https://na-telefon.biz/
Как выбрать и использовать ремонтную смесь
сухая смесь состав http://remontnaja-smes-dlja-kirpichnoj-kladki.ru/ .
Агентство недвижимости Бутово покупка продажа квартир Бутово риелторы и специалисты по недвижимости в Бутово
brand hydroxychloroquine hydroxychloroquine ca hydroxychloroquine 400mg pills
mexican rx online purple pharmacy mexico price list mexican mail order pharmacies
Рулонный газон: где купить качественный материал?
рулонный газон купить цена https://rulonnyj-gazon77.ru/ .
Watches World
Horological instruments Universe
Customer Reviews Reveal Our Watch Boutique Journey
At Our Watch Boutique, client fulfillment isn’t just a goal; it’s a bright evidence to our devotion to excellence. Let’s delve into what our valued clients have to communicate about their experiences, bringing to light on the faultless assistance and remarkable timepieces we supply.
O.M.’s Trustpilot Testimonial: A Effortless Adventure
“Very good communication and follow along throughout the course. The watch was perfectly packed and in perfect. I would surely work with this crew again for a wristwatch buy.
O.M.’s commentary typifies our dedication to interaction and careful care in delivering timepieces in perfect condition. The reliance established with O.M. is a pillar of our customer bonds.
Richard Houtman’s Informative Review: A Private Touch
“I dealt with Benny, who was very beneficial and gracious at all times, keeping me regularly notified of the procedure. Advancing, even though I ended up sourcing the wristwatch locally, I would still surely recommend Benny and the business moving forward.
Richard Houtman’s experience illustrates our individualized approach. Benny’s aid and continuous contact showcase our commitment to ensuring every buyer feels valued and informed.
Customer’s Streamlined Assistance Testimonial: A Smooth Transaction
“A very good and streamlined service. Kept me current on the transaction progression.
Our commitment to effectiveness is echoed in this customer’s response. Keeping customers apprised and the effortless advancement of acquisitions are integral to the Our Watch Boutique adventure.
Discover Our Most Recent Selections
Audemars Piguet Royal Oak Selfwinding 37mm
A beautiful piece at €45,900, this 2022 edition (REF: 15551ST.ZZ.1356ST.05) invites you to add it to your basket and elevate your collection.
Hublot Classic Fusion Green Titanium Chronograph 45mm
Priced at €8,590 in 2024 (REF: 521.NX.8970.RX), this Hublot creation is a blend of styling and creativity, awaiting your inquiry.
Демонтаж и разборка старых деревянных домов с вывозом мусора в Москве и Подмосковье. Демонтаж фундамента расценки – узнайте больше об услуге на сайте hoteltramontano.ru. Производим снос домов и фундаментов вручную и спецтехникой по ценам ниже рынка за 1 день. Бесплатный выезд специалиста на объект.
365newss.net
Meds information sheet. What side effects?
abilify
Some information about meds. Read information here.
отправить аудио поздравление по именам с днем рождения https://na-telefon.biz/
mexican drugstore online buying from online mexican pharmacy medication from mexico pharmacy
Ремонт стиральных машин – высокое качество работы у вас дома. Широкая база выезжающих к заказчику мастеров ремонт стиральных машин в Санкт-Петербурге
Medicines information leaflet. What side effects?
lyrica
Everything information about medicines. Get information now.
Join the fun at our Mexican online casino and discover why we’re the hottest destination for players seeking big wins and non-stop entertainment. calientecasimo online gratis casino la clave para una vida lujosa.
https://kursovyesociologiya.ru
news24time.net
order triamcinolone 10mg online cheap triamcinolone uk buy triamcinolone 10mg generic
купить диплом нового образца http://www.man-diploms.com/ .
Play like a pro at our Mexican online casino. With expert tips and strategies, you’ll maximize your chances of hitting the big time. casino online la clave para una buena vida.
order hydroxychloroquine 400mg without prescription buy plaquenil tablets hydroxychloroquine 200mg for sale
Medicines information for patients. Effects of Drug Abuse.
how can i get zoloft
All trends of drug. Read information now.
https://kursovyesociologiya.ru
cheap aristocort 4mg triamcinolone drug aristocort 4mg usa
https://referatymehanikagruntov.ru
ST666
mexican mail order pharmacies mexican border pharmacies shipping to usa mexico drug stores pharmacies
https://referatymikroekonomika.ru
purple pharmacy mexico price list mexican mail order pharmacies buying prescription drugs in mexico online
Meds information. Effects of Drug Abuse.
motrin without dr prescription
Some news about medicament. Get information now.
https://kontrolnyepolitologiya.ru
Мы предлагаем широкий выбор лазерных станков с передовой технологией, обеспечивая высокую производительность и качество резки чпу лазерный
oknews360.com
В современных условиях затруднительно сделать перспективы обеспеченных без высшего уровня образования – https://www.diplomex.com/. Без высшего уровня образования найти работу на работу с подходящей оплатой труда и привлекательными условиями практически невозможно. Достаточно много индивидуумов, узнавших о подходящейся вакансии, вынуждены от нее отказаться, не имея такого документа. Однако ситуацию можно решить, если заказать диплом о высшем образовании, цена которого будет доступна в сопоставление со ценой обучения. Особенности покупки диплома о высочайшем образовании Если лицу нужно всего лишь демонстрировать документ близким, ввиду факта, что они не смогли закончить учебу по какой-либо причинам, можно заказать недорогую топографическую копию. Однако, если такой придется показывать при устройстве на работу, к вопросу стоит подойти более серьезно.
https://kupavnacity.ru/ русские женские сайты
ligand gated
mexican rx online buying from online mexican pharmacy mexican rx online
Хочешь обновить интерьер? Перетянем твою мебель в Минске
перетяжка мебели недорого https://peretyazhka-mebeli-vminske.ru/ .
mexico drug stores pharmacies mexico drug stores pharmacies medicine in mexico pharmacies
игра кабура отзывы
ligand channels
arizonawood.net
mexican online pharmacies prescription drugs reputable mexican pharmacies online medication from mexico pharmacy
https://kontrolnyepravovedenie.ru
cabura
https://resheniezadachpolitologiya.ru
мелбет игровые автоматы
ligand gated
mexican pharmaceuticals online buying from online mexican pharmacy buying prescription drugs in mexico online
лучшая доставка здорового питания
https://resheniezadachpravovedenie.ru
Эдуард Давыдов, рожденный в 1984 году в семье медицинского работника и ученого, изначально был страстно увлечен дзюдо, но путь к науке, указанный отцом, определил его профессиональное направление Эдуард Маликович Давыдов
https://resheniezadachlogika.ru
мелбет казино
tadalafil without a doctor’s prescription cialis order buy tadalafil 40mg sale
ligand channels
казино селектор вход
buying from online mexican pharmacy mexican pharmacy mexican online pharmacies prescription drugs
Join the excitement at our Mexican casino platform. With action-packed games and electrifying bonuses, you’ll never want to play anywhere else. caliente casino te da mucho.
vulkan platinum
pharmacies in mexico that ship to usa п»їbest mexican online pharmacies buying prescription drugs in mexico online
aurora libraries
кобура
medication from mexico pharmacy buying from online mexican pharmacy mexico drug stores pharmacies
казино вулкан россия
купить диплом магистра https://www.orik-diploms.com .
мостбет казино
mexican online pharmacies prescription drugs mexico drug stores pharmacies mexican online pharmacies prescription drugs
Win big and win often at our Mexican casino platform. With generous payouts and thrilling bonuses, every spin is a chance to change your life. en caliente esto es lo que te diferencia de los demas.
https://hello-food.ru
buying prescription drugs in mexico best online pharmacies in mexico reputable mexican pharmacies online
https://resheniezadachlogika.ru/
madeintexas.net
рамен казино
ST666
order desloratadine order desloratadine generic buy desloratadine generic
mexican online pharmacies prescription drugs pharmacies in mexico that ship to usa mexican border pharmacies shipping to usa
кабура игра
Get ready to hit the jackpot at our sizzling Mexican online casino! With a wide range of thrilling games and irresistible bonuses, the excitement never stops. bet mexico tu camino hacia el exito.
кабура сайт официальный сайт
https://resheniezadachpravovedenie.ru/
Приобрести сертификат бакалавра – это шанс быстро достать запись об образовании на бакалавр уровне без излишних трудностей и расходов времени. В Москве предоставляется различные альтернатив подлинных дипломов бакалавров, предоставляющих удобство и удобство в получении.
buy generic desloratadine over the counter cost desloratadine 5mg order desloratadine online cheap
mexican online pharmacies prescription drugs buying prescription drugs in mexico pharmacies in mexico that ship to usa
buying from online mexican pharmacy mexican mail order pharmacies buying prescription drugs in mexico online
https://resheniezadachpolitologiya.ru/
tadalafil for sale online cialis 20mg buy cialis 20mg
melbet
https://kontrolnyepravovedenie.ru/
https://kontrolnyepolitologiya.ru/
мелбет официальный сайт
leeds-welcome.com
https://referatymikroekonomika.ru/
mexican border pharmacies shipping to usa pharmacies in mexico that ship to usa pharmacies in mexico that ship to usa
казино онлайн
Слом, разборка и демонтаж старых дачных домов с вывозом мусора в Москве и области под ключ. Демонтаж фундамента цена – подробности об услуге: cellmed.ru. Демонтируем дома, здания, постройки и фундаменты вручную и спецтехникой по низким ценам за 24 часа. Бесплатный выезд специалиста на объект.
medication from mexico pharmacy mexican pharmaceuticals online mexican mail order pharmacies
https://kursovyelogistika.ru/
vulcan platinum
https://chaturbate.com/in/?tour=LQps&campaign=Cj92m&track=default&room=shena_nomy
best mexican online pharmacies buying prescription drugs in mexico mexican pharmacy
https://kontrolnyepravovedenie.ru
https://kontrolnyestatistika.ru/
http://mexicanph.com/# mexico drug stores pharmacies
medicine in mexico pharmacies
https://referatymikroekonomika.ru/
https://kursovyesociologiya.ru/
https://resheniezadachpravovedenie.ru/
https://kontrolnyesociologiya.ru/
Drugs prescribing information. Brand names.
how can i get levitra
Everything information about medication. Get now.
mexico drug stores pharmacies buying from online mexican pharmacy mexican online pharmacies prescription drugs
cabura зеркало
Drug information for patients. What side effects can this medication cause?
fluoxetine
Actual about medicine. Get here.
вулкан russia
birminghamnews24.com
pharmacies in mexico that ship to usa mexico drug stores pharmacies buying prescription drugs in mexico
мостбет зеркало
рамен бет
buying prescription drugs in mexico mexican mail order pharmacies mexico pharmacy
cenforce 50mg generic how to get cenforce without a prescription cenforce drug
купить диплом бакалавра http://www.landik-diploms.com .
https://resheniezadachlogika.ru/
purple pharmacy mexico price list mexico drug stores pharmacies mexican drugstore online
mexican drugstore online best online pharmacies in mexico mexico drug stores pharmacies
Заказать сертификат о среднем образовании – это шанс оперативно достать документ об образовании на бакалавр уровне без лишних трудностей и затрат времени. В столице России имеются разные вариантов настоящих дипломов бакалавров, предоставляющих комфорт и удобство в процедуре.
https://resheniezadachmarketing.ru/
https://kontrolnyestatistika.ru/
buying prescription drugs in mexico online mexican border pharmacies shipping to usa mexican border pharmacies shipping to usa
https://easykupitkvartiru.ru/
https://kontrolnyepravovedenie.ru/
https://referatystatistika.ru/
214rentals.com
claritin canada loratadine 10mg oral oral claritin 10mg
https://skupka-stiralnyh-mashin.ru/
buying from online mexican pharmacy best online pharmacies in mexico buying prescription drugs in mexico
mexican online pharmacies prescription drugs mexican pharmacy buying from online mexican pharmacy
Демонтаж, разбор и снос старых деревянных и кирпичиных домов с вывозом мусора в Москве и других городах Подмосковья под ключ. Демонтаж дома стоимость – узнайте больше об услуге: orenvito.ru. Демонтируем дома, сносим здания, строения, сооружения и фундаменты вручную и спецтехникой по ценам ниже рынка за 24 часа. Бесплатный выезд инженера на объект.
Подберем лизинг на выгодных условиях, поможем сэкономить деньги и отправить заявку сразу в несколько банков без лишних документов лизинг
https://mexicanph.com/# reputable mexican pharmacies online
mexican drugstore online
https://resheniezadachmarketing.ru/
purchase cenforce generic buy cenforce medication cenforce 100mg cheap
mexican pharmacy medicine in mexico pharmacies mexico drug stores pharmacies
best online pharmacies in mexico buying prescription drugs in mexico purple pharmacy mexico price list
order loratadine 10mg online buy generic loratadine 10mg order loratadine 10mg for sale
best mexican online pharmacies best online pharmacies in mexico best mexican online pharmacies
https://skupka-stiralnyh-mashin.ru/
texasnews365.com
reputable mexican pharmacies online best online pharmacies in mexico п»їbest mexican online pharmacies
Немного не по теме 🙂
(Moderator, только не троллить!!!)
Так случилось, что мой кум поменял специальность в 42. Просто прошел курс на Пайтон. И трудоустроился на ЗП в 80 тыс. руб. за работу удаленно.
Листаю веб-сайт https://kursypython.ru/. Есть очень неплохие варианты по Питону. Размышляю может пройти? Моя профессия учитель, у нас таких ЗП нет, да и в целом заколебало….
Мне нравится обучение от SF Education, который Python-разработчик.
Прошу не ролфить, просто поделитесь вашим мнением. Спасибочки
best online pharmacies in mexico pharmacies in mexico that ship to usa mexican online pharmacies prescription drugs
Win big and live the dream at our Mexican online casino. With life-changing jackpots and thrilling tournaments, fortune favors the bold. casino en linea la clave para una buena vida.
Немного не по теме 🙂
(Admin, только не троллить!!!)
Так случилось, что мой брат поменял род деятельности в 48. Просто прошел обучение разработке на Python. И нашел работу на зарплату в 150 К рублей за работу online.
Листаю веб-сайт https://kursypython.ru/. Есть очень неплохие варианты по Питону. Размышляю а почему бы и да? Моя профессия бухгалтер, у нас таких зарплат нет, да и в целом нет карьерных вариантов….
Мне нравится обучение от Merion Academy, который Python-разработчик в Петербурге.
Прошу не пинать ногами, просто поделитесь вашим мнением. Спасибо
mexico pharmacies prescription drugs best mexican online pharmacies mexican border pharmacies shipping to usa
Ресторанное оборудование в лизинг по выгодной цене. Большой выбор оборудования для общепита, HORECA, кафе, ресторана, бара, пиццерии, кофейни, столовой оборудование магазина лизинг
купить диплом магистра http://arusak-diploms.com/ .
mexico pharmacy purple pharmacy mexico price list mexican online pharmacies prescription drugs
best mexican online pharmacies mexican online pharmacies prescription drugs buying from online mexican pharmacy
https://resheniezadachmarketing.ru/
reputable mexican pharmacies online mexico drug stores pharmacies buying from online mexican pharmacy
https://1win-kazinora.ru/
https://mexicanph.shop/# mexico drug stores pharmacies
buying prescription drugs in mexico online
best mexican online pharmacies mexican pharmacy buying prescription drugs in mexico
Join the party at our Mexican casino platform. With lively animations and immersive sound effects, you’ll feel like you’re celebrating every time you win. caliente casino en linea tu camino hacia el exito.
buy generic aralen buy aralen pills for sale order chloroquine 250mg sale
интернет магазин отопительного оборудования
https://yuridicheskiy-perevod.ru/
https://birzha-perevodov.ru/
Занимая пост генерального директора в АО «БСК» и на Березниковском содовом заводе, прославился своим умением лидировать и внедрять стратегические нововведения Давыдов Эдуард
https://hudozhestvenny-perevod.ru/
магазин отопительного оборудования
https://perevod-statey.ru/
mexican rx online mexican pharmaceuticals online buying prescription drugs in mexico online
mexican online pharmacies prescription drugs buying prescription drugs in mexico online mexico pharmacy
us pharmacy cialis why not try here
northwestpharmacy [url=http://canadianphrmacy23.com/]canadianphrmacy23.com[/url]
mexico drug stores pharmacies mexican pharmacy best online pharmacies in mexico
В сегодняшнем видео будем разбирать и менять модуль дисплея на смартфоне Honor 8A Honor x8b старт продаж в России – дата и цены
накрутка лайков инстаграм дешево https://yeslike.ru/
mexico pharmacies prescription drugs best mexican online pharmacies mexican rx online
24thainews.com
clothing
https://referatystatistika.ru/
https://stromectol.fun/# stromectol pill
https://kursovyesociologiya.ru/
https://furosemide.guru/# furosemida
dapoxetine 60mg drug where to buy dapoxetine without a prescription misoprostol ca
https://kontrolnyesistemnyjanaliz.ru/
https://kontrolnyesociologiya.ru/
buy chloroquine 250mg pills order chloroquine 250mg online chloroquine 250mg ca
tokyo365web.com
buy amoxicillin online mexico: buy amoxicillin online cheap – amoxicillin 500 mg online
https://domains.tntcode.com/ip/172.67.218.38
dapoxetine 60mg pill order dapoxetine 60mg generic buy misoprostol sale
https://kazino1win.ru/
http://amoxil.cheap/# prescription for amoxicillin
Купить кондиционер в Рязани по лучшим ценам. Сплит-системы с гарантией до 5 лет от компании https://vk.com/kupit_kondicioner_ryazan
https://www.websitescrawl.com/domain-list-11918
Предоставляем услуги комплексного бухгалтерского обслуживания юридических лиц. Ведение бухгалтерского учета по выгодным ценам — для вашего бизнеса аутсорсинг бухгалтерских услуг
https://pravgruzchiki.ru/
lisinopril 10mg online: lisinopril 422 – prinivil 40 mg
http://stromectol.fun/# ivermectin usa price
Давыдов Эдуард http://eduarddavydovbsk.ru/ .
戰神賽特老虎機
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
Join the party at our Mexican casino platform. With lively animations and immersive sound effects, you’ll feel like you’re celebrating every time you win. casion tu camino hacia el exito.
娛樂城推薦
台灣線上娛樂城的規模正迅速增長,新的娛樂場所不斷開張。為了吸引玩家,這些場所提供了各種吸引人的優惠和贈品。每家娛樂城都致力於提供卓越的服務,務求讓客人享受最佳的遊戲體驗。
2024年網友推薦最多的線上娛樂城:No.1富遊娛樂城、No.2 BET365、No.3 DG娛樂城、No.4 九州娛樂城、No.5 亞博娛樂城,以下來介紹這幾間娛樂城網友對他們的真實評價及娛樂城推薦。
2024台灣娛樂城排名
排名 娛樂城 體驗金(流水) 首儲優惠(流水) 入金速度 出金速度 推薦指數
1 富遊娛樂城 168元(1倍) 送1000(1倍) 15秒 3-5分鐘 ★★★★★
2 1XBET中文版 168元(1倍) 送1000(1倍) 15秒 3-5分鐘 ★★★★☆
3 Bet365中文 168元(1倍) 送1000(1倍) 15秒 3-5分鐘 ★★★★☆
4 DG娛樂城 168元(1倍) 送1000(1倍) 15秒 5-10分鐘 ★★★★☆
5 九州娛樂城 168元(1倍) 送500(1倍) 15秒 5-10分鐘 ★★★★☆
6 亞博娛樂城 168元(1倍) 送1000(1倍) 15秒 3-10分鐘 ★★★☆☆
7 寶格綠娛樂城 199元(1倍) 送1000(25倍) 15秒 3-5分鐘 ★★★☆☆
8 王者娛樂城 300元(15倍) 送1000(15倍) 90秒 5-30分鐘 ★★★☆☆
9 FA8娛樂城 200元(40倍) 送1000(15倍) 90秒 5-10分鐘 ★★★☆☆
10 AF娛樂城 288元(40倍) 送1000(1倍) 60秒 5-30分鐘 ★★★☆☆
2024台灣娛樂城排名,10間娛樂城推薦
No.1 富遊娛樂城
富遊娛樂城推薦指數:★★★★★(5/5)
富遊娛樂城介面 / 2024娛樂城NO.1
RG富遊官網
富遊娛樂城是成立於2019年的一家獲得數百萬玩家註冊的線上博彩品牌,持有博彩行業市場的合法運營許可。該公司受到歐洲馬爾他(MGA)、菲律賓(PAGCOR)以及英屬維爾京群島(BVI)的授權和監管,展示了其雄厚的企業實力與合法性。
富遊娛樂城致力於提供豐富多樣的遊戲選項和全天候的會員服務,不斷追求卓越,確保遊戲的公平性。公司運用先進的加密技術及嚴格的安全管理體系,保障玩家資金的安全。此外,為了提升手機用戶的使用體驗,富遊娛樂城還開發了專屬APP,兼容安卓(Android)及IOS系統,以達到業界最佳的穩定性水平。
在資金存提方面,富遊娛樂城採用第三方金流服務,進一步保障玩家的資金安全,贏得了玩家的信賴與支持。這使得每位玩家都能在此放心享受遊戲樂趣,無需擔心後顧之憂。
富遊娛樂城簡介
娛樂城網路評價:5分
娛樂城入金速度:15秒
娛樂城出金速度:5分鐘
娛樂城體驗金:168元
娛樂城優惠:
首儲1000送1000
好友禮金無上限
新會禮遇
舊會員回饋
娛樂城遊戲:體育、真人、電競、彩票、電子、棋牌、捕魚
富遊娛樂城推薦要點
新手首推:富遊娛樂城,2024受網友好評,除了打造針對新手的各種優惠活動,還有各種遊戲的豐富教學。
首儲再贈送:首儲1000元,立即在獲得1000元獎金,而且只需要1倍流水,對新手而言相當友好。
免費遊戲體驗:新進玩家享有免費體驗金,讓您暢玩娛樂城內的任何遊戲。
優惠多元:活動頻繁且豐富,流水要求低,對各玩家可說是相當友善。
玩家首選:遊戲多樣,服務優質,是新手與老手的最佳賭場選擇。
富遊娛樂城優缺點整合
優點 缺點
• 台灣註冊人數NO.1線上賭場
• 首儲1000贈1000只需一倍流水
• 擁有體驗金免費體驗賭場
• 網紅部落客推薦保證出金線上娛樂城 • 需透過客服申請體驗金
富遊娛樂城優缺點整合表格
富遊娛樂城存取款方式
存款方式 取款方式
• 提供四大超商(全家、7-11、萊爾富、ok超商)
• 虛擬貨幣ustd存款
• 銀行轉帳(各大銀行皆可) • 現金1:1出金
• 網站內申請提款及可匯款至綁定帳戶
富遊娛樂城存取款方式表格
富遊娛樂城優惠活動
優惠 獎金贈點 流水要求
免費體驗金 $168 1倍 (儲值後) /36倍 (未儲值)
首儲贈點 $1000 1倍流水
返水活動 0.3% – 0.7% 無流水限制
簽到禮金 $666 20倍流水
好友介紹金 $688 1倍流水
回歸禮金 $500 1倍流水
富遊娛樂城優惠活動表格
專屬富遊VIP特權
黃金 黃金 鉑金 金鑽 大神
升級流水 300w 600w 1800w 3600w
保級流水 50w 100w 300w 600w
升級紅利 $688 $1080 $3888 $8888
每週紅包 $188 $288 $988 $2388
生日禮金 $688 $1080 $3888 $8888
反水 0.4% 0.5% 0.6% 0.7%
專屬富遊VIP特權表格
娛樂城評價
總體來看,富遊娛樂城對於玩家來講是一個非常不錯的選擇,有眾多的遊戲能讓玩家做選擇,還有各種優惠活動以及低流水要求等等,都讓玩家贏錢的機率大大的提升了不少,除了體驗遊戲中帶來的樂趣外還可以享受到贏錢的快感,還在等什麼趕快點擊下方連結,立即遊玩!
https://amoxil.cheap/# buy amoxicillin online without prescription
オンラインカジノ
日本にオンラインカジノおすすめランキング2024年最新版
2024おすすめのオンラインカジノ
オンラインカジノはパソコンでしか遊べないというのは、もう一昔前の話。現在はスマホやタブレットなどのモバイル端末からも、パソコンと変わらないクオリティでオンラインカジノを当たり前に楽しむことができるようになりました。
数あるモバイルカジノの中で、当サイトが厳選したトップ5カジノはこちら。
オンラインカジノおすすめ: コニベット(Konibet)
コニベットといえば、キャッシュバックや毎日もらえるリベートボーナスなど豪華ボーナスが満載!それに加えて低い出金条件も見どころです。さらにVIPレベルごとの還元率の高さも業界内で突出している点や、出金速度の速さなどトータルバランスの良さからもハイローラーの方にも好まれています。
カスタマーサポートは365日24時間稼働しているので、初心者の方にも安心してご利用いただけます。
さらに【業界初のオンラインポーカー】を導入!毎日トーナメントも開催されているので、早速参加しちゃいましょう!
RTP(還元率)公開や、入出金対応がスムーズで初心者向き
2000種類以上の豊富なゲーム数を誇り、スロットゲーム多数!
今なら$20の入金不要ボーナスと最大$650還元ボーナス!
8種類以上のライブカジノプロバイダー
業界初オンラインポーカーあり,日本利用者数No.1の安心のオンラインカジノメディア!
おすすめポイント
コニベットは、その豊富なボーナスと高還元率、そして安心のキャッシュバック制度で知られています。まず、新規登録者には入金不要の$20ボーナスが提供され、さらに初回入金時には最大$650の還元ボーナスが得られます。これらのキャンペーンはプレイヤーにとって大きな魅力となっています。
また、コニベットの特徴的な点は、VIP制度です。一度ロイヤルクラブになると、降格がなく、スロットリベートが1.5%という驚異の還元率を享受できます。これは他のオンラインカジノと比較しても非常に高い還元率です。さらに、常時週間損失キャッシュバックも行っているため、不運で負けてしまった場合でも取り返すチャンスがあります。これらの特徴から、コニベットはプレイヤーにとって非常に魅力的なオンラインカジノと言えるでしょう。
コニベット 無料会員登録をする
| コニベットのボーナス
コニベットは、新規登録者向けに20ドルの入金不要ボーナスを用意しています
コニベットカジノでは、限定で初回入金後に残高が1ドル未満になった場合、入金額の50%(最高500ドル)がキャッシュバックされる。キャッシュバック額に出金条件はないため、獲得後にすぐ出金することも可能です。
| コニベットの入金方法
入金方法 最低 / 最高入金
マスターカード 最低 : $20 / 最高 : $6,000
ジェイシービー 最低 : $20/ 最高 : $6,000
アメックス 最低 : $20 / 最高 : $6,000
アイウォレット 最低 : $20 / 最高 : $100,000
スティックペイ 最低 : $20 / 最高 : $100,000
ヴィーナスポイント 最低 : $20 / 最高 : $10,000
仮想通貨 最低 : $20 / 最高 : $100,000
銀行送金 最低 : $20 / 最高 : $10,000
| コニベット出金方法
出金方法 最低 |最高出金
アイウォレット 最低 : $40 / 最高 : なし
スティックぺイ 最低 : $40 / 最高 : なし
ヴィーナスポイント 最低 : $40 / 最高 : なし
仮想通貨 最低 : $40 / 最高 : なし
銀行送金 最低 : $40 / 最高 : なし
ivermectin price canada: ivermectin 24 mg – price of ivermectin
Демонтаж, разборка и снос старых деревянных и кирпичных домов с вывозом строительного мусора в Москве и Московской области. Снос домов дач – узнайте подробнее об услуге: taurusweb.ru. Производим демонтаж домов, зданий и фундаментов вручную и спецтехникой по ценам ниже рынка за 24 часа. Бесплатный выезд специалиста на объект.
https://amoxil.cheap/# buy amoxicillin 500mg
We absolutely love your blog and find a lot of your
post’s to be precisely what I’m looking for. Would you offer guest writers to write content for you
personally? I wouldn’t mind producing a post or elaborating on most of the subjects you write about here.
Again, awesome site!
Wow, awesome weblog format! How long have you been running a blog for?
you make running a blog look easy. The whole look of your
web site is fantastic, as well as the content!
mosesolmos.com
buy amoxicillin 500mg uk: amoxicillin generic – where to buy amoxicillin
I just like the helpful information you supply to your articles.
I will bookmark your weblog and check once more right here frequently.
I’m relatively sure I will be told many new stuff proper right here!
Good luck for the next!
Hi there! Someone in my Facebook group shared this site with
us so I came to look it over. I’m definitely loving the information. I’m book-marking
and will be tweeting this to my followers! Wonderful blog and outstanding design and style.
http://lisinopril.top/# lisinopril 40 mg tablet
https://falco-jc.pl/zakupy/www,ibetam,pl,s,22330/
Getting through the globe of SR22 insurance could be intricate, yet it’s vital for particular drivers.
SR22 insurance is a form your insurance provider
data to reveal you’re covered. This requirement generally complies with major website traffic infractions.
It is crucial to keep your SR22 insurance active to steer clear of
legal problems.
repairdesign24.com
http://backlink.asia/domain-list-283
lisinopril without rx: prinivil drug cost – lisinopril 2.5 cost
https://buyprednisone.store/# buy prednisone without a prescription best price
As I website owner I believe the content material here is really good appreciate it for your efforts.Extension Cord 10 ft – Long Power Strip Surge Protector 6 AC Outlet 4 USB (2 USB C) Flat Plug Wall Mount Multi Plug Outlet Extender Desk Charging Station for Home Office Dorm Room Essentials – Hot Deals
Играй в любимые игры казино в любое время и в любом месте.[url=https://sgochelyabinsk.ru/]kent казино онлайн[/url]
Seasoned Port Builder Vitaliy Yuzhilin, Works in Maritime Infrastructure Development Yuzhilin Vitaliy Aleksandrovich
1xBet: Your Ultimate Betting Destination
1xbet application 1xbet com app download .
1xBet: Your Ultimate Betting Destination
1xbet 36 1xbet application .
https://amoxil.cheap/# amoxicillin 875 125 mg tab
xenical buy online buy diltiazem 180mg without prescription diltiazem 180mg cost
ivermectin 2mg: buy ivermectin stromectol – stromectol ivermectin 3 mg
http://amoxil.cheap/# amoxicillin 500mg tablets price in india
日本にオンラインカジノおすすめランキング2024年最新版
2024おすすめのオンラインカジノ
オンラインカジノはパソコンでしか遊べないというのは、もう一昔前の話。現在はスマホやタブレットなどのモバイル端末からも、パソコンと変わらないクオリティでオンラインカジノを当たり前に楽しむことができるようになりました。
数あるモバイルカジノの中で、当サイトが厳選したトップ5カジノはこちら。
オンラインカジノおすすめ: コニベット(Konibet)
コニベットといえば、キャッシュバックや毎日もらえるリベートボーナスなど豪華ボーナスが満載!それに加えて低い出金条件も見どころです。さらにVIPレベルごとの還元率の高さも業界内で突出している点や、出金速度の速さなどトータルバランスの良さからもハイローラーの方にも好まれています。
カスタマーサポートは365日24時間稼働しているので、初心者の方にも安心してご利用いただけます。
さらに【業界初のオンラインポーカー】を導入!毎日トーナメントも開催されているので、早速参加しちゃいましょう!
RTP(還元率)公開や、入出金対応がスムーズで初心者向き
2000種類以上の豊富なゲーム数を誇り、スロットゲーム多数!
今なら$20の入金不要ボーナスと最大$650還元ボーナス!
8種類以上のライブカジノプロバイダー
業界初オンラインポーカーあり,日本利用者数No.1の安心のオンラインカジノメディア!
おすすめポイント
コニベットは、その豊富なボーナスと高還元率、そして安心のキャッシュバック制度で知られています。まず、新規登録者には入金不要の$20ボーナスが提供され、さらに初回入金時には最大$650の還元ボーナスが得られます。これらのキャンペーンはプレイヤーにとって大きな魅力となっています。
また、コニベットの特徴的な点は、VIP制度です。一度ロイヤルクラブになると、降格がなく、スロットリベートが1.5%という驚異の還元率を享受できます。これは他のオンラインカジノと比較しても非常に高い還元率です。さらに、常時週間損失キャッシュバックも行っているため、不運で負けてしまった場合でも取り返すチャンスがあります。これらの特徴から、コニベットはプレイヤーにとって非常に魅力的なオンラインカジノと言えるでしょう。
コニベット 無料会員登録をする
| コニベットのボーナス
コニベットは、新規登録者向けに20ドルの入金不要ボーナスを用意しています
コニベットカジノでは、限定で初回入金後に残高が1ドル未満になった場合、入金額の50%(最高500ドル)がキャッシュバックされる。キャッシュバック額に出金条件はないため、獲得後にすぐ出金することも可能です。
| コニベットの入金方法
入金方法 最低 / 最高入金
マスターカード 最低 : $20 / 最高 : $6,000
ジェイシービー 最低 : $20/ 最高 : $6,000
アメックス 最低 : $20 / 最高 : $6,000
アイウォレット 最低 : $20 / 最高 : $100,000
スティックペイ 最低 : $20 / 最高 : $100,000
ヴィーナスポイント 最低 : $20 / 最高 : $10,000
仮想通貨 最低 : $20 / 最高 : $100,000
銀行送金 最低 : $20 / 最高 : $10,000
| コニベット出金方法
出金方法 最低 |最高出金
アイウォレット 最低 : $40 / 最高 : なし
スティックぺイ 最低 : $40 / 最高 : なし
ヴィーナスポイント 最低 : $40 / 最高 : なし
仮想通貨 最低 : $40 / 最高 : なし
銀行送金 最低 : $40 / 最高 : なし
Эдуард Давыдов https://www.panram.ru/partners/news/biografiya-eduarda-davydova-generalnogo-direktora-bsk-ao .
xenical 120mg tablet buy orlistat sale diltiazem 180mg without prescription
Все о дизайне интерьера
Продажа подержанных автомобилей, все машины проверены и находятся в Москве. Большой каталог БУ автомобилей с пробегом от официального дилера, узнайте на сайте цены и характеристики на бу авто авто в москве с пробегом
線上賭場
https://buyprednisone.store/# prednisone 475
Все о современных технологиях
stromectol usa: stromectol canada – stromectol 6 mg dosage
glucophage drug oral glycomet buy metformin pill
https://lisinopril.top/# lisinopril 80
belfastinvest.net
ivermectin price comparison: ivermectin 3mg tablets – generic stromectol
https://furosemide.guru/# generic lasix
Все о дизайне интерьера
Сумка женская купить
Maxim Shubarev is a Russian entrepreneur, chairman of the Board of Directors of the Setl Group holding [url=https://en.wikipedia.org/wiki/Maxim_Shubarev]Maxim Shubarev[/url]
lisinopril with out prescription: buy lisinopril without a prescription – lisinopril 10mg price in india
Магазин сумок
http://lisinopril.top/# zestril
http://stromectol.fun/# what is minocycline used for
https://vstx.ru/
купоны эльдорадо
californianetdaily.com
buy generic atorvastatin for sale order atorvastatin 10mg lipitor 40mg pill
lasix uses: Over The Counter Lasix – lasix 100 mg tablet
http://amoxil.cheap/# amoxicillin azithromycin
https://best-santehnika.store/
order rybelsus
ebony webcam
оборудование для актового зала купить https://www.i-tec1.ru .
Теневые рынки и их незаконные деятельности представляют важную угрозу безопасности общества и являются объектом внимания правоохранительных органов по всему миру. В данной статье мы обсудим так называемые теневые рынки, где возможно покупать поддельные паспорта, и какие угрозы это несет для граждан и государства.
Теневые рынки представляют собой неявные интернет-площадки, на которых торгуется разнообразной противозаконной продукцией и услугами. Среди этих услуг встречается и продажа фальшивых документов, таких как паспорта. Эти рынки оперируют в тайной сфере интернета, используя кодирование и скрытые платежные системы, чтобы оставаться незаметными для правоохранительных органов.
Покупка нелегального паспорта на теневых рынках представляет значительную угрозу национальной безопасности. похищение личных данных, подделывание документов и поддельные идентификационные материалы могут быть использованы для совершения радикальных актов, мошеннических и других преступлений.
Правоохранительные органы в различных странах активно борются с скрытыми рынками, проводя спецоперации по обнаружению и аресту тех, кто замешан в преступных действиях. Однако, по мере того как технологии становятся более затруднительными, эти рынки могут адаптироваться и находить новые способы обхода законов.
Для предотвращения угроз от возможных опасностей, связанных с теневыми рынками, важно быть осторожным при обработке своих личной информации. Это включает в себя избегать фишинговых атак, не делиться персональной информацией в недоверенных источниках и периодически проверять свои финансовые документы.
Кроме того, общество должно быть знающим о рисках и последствиях покупки поддельных документов. Это способствует формированию осознанного и ответственного отношения к вопросам безопасности и поможет в борьбе с подпольными рынками. Поддержка законодательства, направленных на ужесточение наказаний за изготовление и сбыт нелегальных документов, также представляет важную составляющую в противодействии этим преступлениям
how to get acyclovir without a prescription buy allopurinol generic where can i buy allopurinol
https://amoxil.cheap/# amoxicillin 825 mg
buy amoxicillin from canada: amoxicillin 500 – can you buy amoxicillin over the counter canada
bird doxycycline tablets
https://free-promocode.ru/
Погрузитесь в захватывающий мир азартных игр, где каждый может стать следующим большим победителем игра kent casino
are prednisone and prednisolone equivalent
zovirax over the counter buy allopurinol 300mg sale buy zyloprim 100mg online
https://free-promocode.ru/
get colchicine
http://buyprednisone.store/# prednisone 500 mg tablet
buy cheap glycomet pills
lisinopril 40 mg mexico: buy cheap lisinopril 40 mg no prescription – zestril 20 mg tab
Изготовление и использование реплик банковских карт является неправомерной практикой, представляющей существенную угрозу для безопасности финансовых систем и личных средств граждан. В данной статье мы рассмотрим опасности и последствия покупки дубликатов карт, а также как общество и силовые структуры борются с похожими преступлениями.
“Копии” карт — это незаконные дубликаты банковских карт, которые используются для несанкционированных транзакций. Основной метод создания клонов — это похищение данных с оригинальной карты и последующее создание программы этих данных на другую карту. Злоумышленники, предлагающие услуги по продаже клонов карт, обычно действуют в скрытой сфере интернета, где трудно выявить и пресечь их деятельность.
Покупка дубликатов карт представляет собой серьезное преступление, которое может повлечь за собой трудные наказания. Покупатель также рискует стать последователем мошенничества, что может привести к наказанию по уголовному кодексу. Основные преступные действия в этой сфере включают в себя кражу личной информации, подделывание документов и, конечно же, финансовые махинации.
Банки и правоохранительные органы активно борются с преступлениями, связанными с клонированием карт. Банки внедряют новые технологии для распознавания подозрительных транзакций, а также предлагают услуги по обеспечению защиты для своих клиентов. Силовые структуры ведут следственные мероприятия и постигают тех, кто замешан в разработке и распространении копий карт.
Для собственной безопасности важно соблюдать осторожность при использовании банковских карт. Необходимо регулярно проверять выписки, избегать подозрительных сделок и следить за своей конфиденциальной информацией. Образование и информированность об угрозах также являются важными средствами в борьбе с финансовыми преступлениями.
В заключение, использование реплик банковских карт — это незаконное и неприемлемое деяние, которое может привести к серьезным последствиям для тех, кто вовлечен в такую практику. Соблюдение мер предосторожности, осведомленность о возможных угрозах и сотрудничество с полицией играют важную роль в предотвращении и пресечении этих преступлений
diltiazem 30 mg twice day
видеорегистраторы нательные персональные https://nagrudnievieoregistratori.ru/
https://stromectol.fun/# where to buy ivermectin cream
80 mg prednisone per day
http://stromectol.fun/# ivermectin 0.1 uk
Вёрстка страницы представляет собой процесс разработки структуры html-документа, результатом которого является веб-страница https://qa-front-end.ru/kak-sozdat-interaktivnye-testy-na-html-dlya-uluchsheniya-vashey-veb-stranitsy/
how to buy nemasole
https://seo116.ru/
buy tetracycline antibiotics
https://seo116.ru/
order norvasc 5mg generic norvasc over the counter buy norvasc 5mg sale
карты на обнал
Использование платежных карт является неотъемлемой частью современного общества. Карты предоставляют легкость, секретность и широкие возможности для проведения финансовых сделок. Однако, кроме дозволенного использования, существует негативная сторона — вывод наличных средств, когда карты используются для снятия денег без разрешения владельца. Это является незаконным действием и влечет за собой строгие санкции.
Вывод наличных средств с карт представляет собой действия, направленные на извлечение наличных средств с карты, необходимые для того, чтобы обойти систему безопасности и оповещений, предусмотренных банком. К сожалению, такие противозаконные поступки существуют, и они могут привести к финансовым потерям для банков и клиентов.
Одним из методов обналичивания карт является использование технических хитростей, таких как кража данных с магнитных полос карт. Магнитный обман — это процесс, при котором злоумышленники устанавливают механизмы на банкоматах или терминалах оплаты, чтобы сканировать информацию с магнитной полосы карты. Полученные данные затем используются для создания копии карты или проведения транзакций в интернете.
Другим часто используемым способом является ловушка, когда злоумышленники отправляют лукавые письма или создают ненастоящие веб-ресурсы, имитирующие банковские ресурсы, с целью получения конфиденциальной информации от клиентов.
Для противостояния выводу наличных средств банки осуществляют разные действия. Это включает в себя усовершенствование защитных систем, осуществление двухфакторной верификации, слежение за транзакциями и подготовка клиентов о техниках предотвращения мошенничества.
Клиентам также следует быть активными в защите своих карт и данных. Это включает в себя смену паролей с определенной периодичностью, контроль банковских выписок, а также бдительность к подозрительным операциям.
Обналичивание карт — это серьезное преступление, которое влечет за собой вред не только финансовым учреждениям, но и всему обществу. Поэтому важно соблюдать внимание при работе с банковскими картами, быть информированным о методах мошенничества и соблюдать меры безопасности для предотвращения потери средств
http://stromectol.fun/# ivermectin 2ml
видеорегистратор нагрудный https://nagrudnievieoregistratori.ru/
Discover a world of style and comfort at our furniture store, where every detail is designed to enhance the uniqueness of your space and offer you unparalleled solutions for your home or office Custom furniture
ivermectin 1%: ivermectin 0.5 lotion – ivermectin tablets
get lyrica
обработка участка от клещей в Москве цена https://eco-life-group.ru/borba-s-nasekomymi/unichtozhit-kleshchej/
Watches World
In the realm of high-end watches, finding a trustworthy source is essential, and WatchesWorld stands out as a beacon of confidence and knowledge. Providing an extensive collection of prestigious timepieces, WatchesWorld has garnered praise from satisfied customers worldwide. Let’s delve into what our customers are saying about their experiences.
Customer Testimonials:
O.M.’s Review on O.M.:
“Very good communication and follow-up throughout the procedure. The watch was flawlessly packed and in pristine condition. I would certainly work with this group again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was extremely assisting and courteous at all times, keeping me regularly informed of the process. Moving forward, even though I ended up acquiring the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A highly efficient and prompt service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an internet platform; it’s a commitment to personalized service in the world of high-end watches. Our team of watch experts prioritizes confidence, ensuring that every customer makes an knowledgeable decision.
Our Commitment:
Expertise: Our group brings unparalleled knowledge and perspective into the realm of high-end timepieces.
Trust: Confidence is the basis of our service, and we prioritize openness in every transaction.
Satisfaction: Customer satisfaction is our paramount goal, and we go the extra mile to ensure it.
When you choose WatchesWorld, you’re not just purchasing a watch; you’re committing in a smooth and reliable experience. Explore our collection, and let us assist you in discovering the ideal timepiece that embodies your style and sophistication. At WatchesWorld, your satisfaction is our proven commitment
greenhousebali.com
buy cheap luvox pill
переносной видеорегистратор на одежду https://nagrudnievieoregistratori.ru/
Услуга сноса старых частных домов и вывоза мусора в Москве и Подмосковье под ключ от нашей компании. Работаем в указанном регионе, предлагаем услугу демонтаж старого фундамента. Наши тарифы ниже рыночных, а выполнение работ гарантируем в течение 24 часов. Бесплатно выезжаем для оценки и консультаций на объект. Звоните нам или оставляйте заявку на сайте для получения подробной информации и расчета стоимости услуг.
http://buyprednisone.store/# prednisolone prednisone
get uroxatrall for sale
Привет. kuzovdetali – широкий ассортимент деталей и подбор автозапчастей из европы. Переходите в интернет-магазин для заказа новых и оригинальных запчастей на машины. Гарантия и доставка по Минску и области.
оборудование для актового зала купить http://i-tec3.ru/ .
ivermectin brand name: ivermectin 500mg – ivermectin 6mg dosage
Услуга сноса старых частных домов и вывоза мусора в Москве и Подмосковье под ключ от нашей компании. Работаем в указанном регионе, предлагаем услугу слом дома в московской области. Наши тарифы ниже рыночных, а выполнение работ гарантируем в течение 24 часов. Бесплатно выезжаем для оценки и консультаций на объект. Звоните нам или оставляйте заявку на сайте для получения подробной информации и расчета стоимости услуг.
where to buy lisinopril 10 mg
Proxy servers act as intermediaries between clients and destination servers, providing various functionalities such as caching and filtering Proxy technology
http://stromectol.fun/# ivermectin stromectol
can you buy cefixime over the counter
generic dapsone without rx
cyprus-welcome.com
amoxicillin buy canada: buy amoxicillin – amoxicillin no prescription
уничтожение кротов на участке цены https://eco-life-group.ru/borba-s-gryzunami/unichtozhit-krotov-zemlerojki/
generic zithromax price
https://furosemide.guru/# furosemida
buy generic norvasc 5mg order amlodipine online buy norvasc 10mg pills
cost tinidazole
https://furosemide.guru/# lasix
уничтожение короеда https://eco-life-group.ru/borba-s-nasekomymi/unichtozhit-koroeda-drevotochets/
propranolol with alcohol
Услуга сноса старых частных домов и вывоза мусора в Москве и Подмосковье под ключ от нашей компании. Работаем в указанном регионе, предлагаем услугу снос старых дачных домов. Наши тарифы ниже рыночных, а выполнение работ гарантируем в течение 24 часов. Бесплатно выезжаем для оценки и консультаций на объект. Звоните нам или оставляйте заявку на сайте для получения подробной информации и расчета стоимости услуг.
http://buyprednisone.store/# prednisone 4mg tab
lasix 40 mg: Buy Lasix – generic lasix
where can i buy cetirizine
japenese creampie
https://forum.usinsk.in/blog/pages/?bezdepozitnuy_bonus_kazino__vash_shans_nachat_vuigruvat_bez_vlozgheniy.html
Want to know more about a specific phone number?Number Tracker is the solution for you. With our advanced technology, you can easily track any phone number and get detailed information about the caller http://classicalmusicmp3freedownload.com/ja/index.php?title=_Geofencing:_Using_Phone_Location_Tracking_for_Enhanced_Security
I?¦ll immediately seize your rss as I can’t in finding your email subscription hyperlink or newsletter service. Do you have any? Please permit me understand in order that I may subscribe. Thanks.
http://pilotms.ru/catalog/pages/?sekretu_bezdepozitnuh_bonusov__kak_maksimizirovat_vash_vuigrush.html
https://lisinopril.top/# can you buy lisinopril online
detroitapartment.net
In the realm of high-end watches, discovering a dependable source is essential, and WatchesWorld stands out as a pillar of trust and expertise. Presenting an broad collection of renowned timepieces, WatchesWorld has collected acclaim from content customers worldwide. Let’s dive into what our customers are saying about their experiences.
Customer Testimonials:
O.M.’s Review on O.M.:
“Outstanding communication and aftercare throughout the procedure. The watch was perfectly packed and in pristine condition. I would certainly work with this group again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was highly supportive and courteous at all times, keeping me regularly informed of the process. Moving forward, even though I ended up acquiring the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A highly efficient and efficient service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an web-based platform; it’s a commitment to customized service in the world of luxury watches. Our staff of watch experts prioritizes trust, ensuring that every client makes an well-informed decision.
Our Commitment:
Expertise: Our group brings exceptional understanding and perspective into the world of high-end timepieces.
Trust: Confidence is the basis of our service, and we prioritize transparency in every transaction.
Satisfaction: Customer satisfaction is our ultimate goal, and we go the additional step to ensure it.
When you choose WatchesWorld, you’re not just purchasing a watch; you’re committing in a smooth and reliable experience. Explore our collection, and let us assist you in finding the ideal timepiece that reflects your style and sophistication. At WatchesWorld, your satisfaction is our proven commitment
prednisone 20mg price in india: prednisone 10 tablet – prednisone 10 tablet
http://furosemide.guru/# furosemide
мгновенные онлайн займы https://topruscredit.ru/ .
rosuvastatin 10mg tablet buy ezetimibe 10mg for sale zetia tablet
Актуальный доступ к ссылкам и зеркалам площадки Kraken уже у вас. Ознакомьтесь с надежными методами доступа и гарантированными мерами безопасности кракен онион
purchase zestril generic order zestril 10mg generic zestril without prescription
rosuvastatin canada order crestor 10mg pills ezetimibe 10mg us
http://lisinopril.top/# lisinopril 2.5 mg
lisinopril 20 mg tablet: lisinopril 20 – lisinopril 40 mg prices
https://amoxil.cheap/# order amoxicillin 500mg
http://buyprednisone.store/# can you buy prednisone over the counter uk
furosemide 100 mg: Buy Lasix No Prescription – lasix 40 mg
In the world of luxury watches, locating a reliable source is paramount, and WatchesWorld stands out as a pillar of confidence and knowledge. Presenting an extensive collection of prestigious timepieces, WatchesWorld has collected praise from satisfied customers worldwide. Let’s dive into what our customers are saying about their experiences.
Customer Testimonials:
O.M.’s Review on O.M.:
“Excellent communication and follow-up throughout the process. The watch was perfectly packed and in perfect condition. I would certainly work with this group again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was highly helpful and courteous at all times, preserving me regularly informed of the procedure. Moving forward, even though I ended up acquiring the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A highly efficient and prompt service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an internet platform; it’s a dedication to customized service in the realm of high-end watches. Our staff of watch experts prioritizes trust, ensuring that every customer makes an well-informed decision.
Our Commitment:
Expertise: Our group brings unparalleled understanding and insight into the realm of luxury timepieces.
Trust: Trust is the basis of our service, and we prioritize transparency in every transaction.
Satisfaction: Client satisfaction is our paramount goal, and we go the extra mile to ensure it.
When you choose WatchesWorld, you’re not just buying a watch; you’re investing in a seamless and reliable experience. Explore our range, and let us assist you in discovering the ideal timepiece that embodies your taste and elegance. At WatchesWorld, your satisfaction is our time-tested commitment
gay sex
http://kflowers2019.kentoncityschools.org/2015/10/28/new-upcoming-technology-microsoft-surface-book/?unapproved=270452&moderation-hash=c02cee1548e18274adcc29e570eeb5ed#comment-270452
http://buyprednisone.store/# prednisone 10mg tablet cost
event-miami24.com
http://dvnshu.com/index.php?subaction=userinfo&user=elaqeco
furosemide 100mg: Over The Counter Lasix – buy furosemide online
https://amoxil.cheap/# buy amoxicillin 500mg online
https://aben75.cafe24.com/bbs/board.php?bo_table=free&wr_id=211461
вино Франция купить
https://hidehost.net/
buy zestril no prescription zestril 2.5mg cheap lisinopril for sale online
http://www.konura.info/forum/index.php?topic=32676.0
http://lisinopril.top/# lisinopril oral
разработка сайта москва
caribbean21.com
http://fh79604z.bget.ru/index.php?subaction=userinfo&user=ipyharybe
furosemide 40 mg: furosemide 40mg – lasix furosemide
Вячеслав Николаев Вячеслав Николаев .
http://nkolbasina.ru/moj-samyj-tvorcheskij-proekt-2021-goda/#comment-25827
https://hidehost.net/
https://lisinopril.top/# lisinopril cost 40 mg
Французское вино
lasix 100 mg: Buy Furosemide – lasix online
Французское вино
http://infodesk.kg/?page_id=2&unapproved=284183&moderation-hash=d512a4471646512648a47c2c2e6b2d6e#comment-284183
http://stromectol.fun/# ivermectin 3mg price
how to get motilium without a prescription motilium cheap buy sumycin online cheap
domperidone order order domperidone generic tetracycline 500mg pill
http://amosdbsjef.com/?p=1&unapproved=431375&moderation-hash=58e2cfd384d387bee215f8d353f7c2f4#comment-431375
Все о строительстве
Биография руководителя «Башкирской содовой компании» Давыдов Эдуард Рождение в семье увлеченных наукой родителей предопределило жизненный путь Эдуарда Давыдова, чье детство прошло в атмосфере постоянного стремления к знаниям и самосовершенствованию.
purchase prilosec pills omeprazole 10mg drug buy prilosec pills for sale
Лучшие пляжи и курорты
– Волшебная страна: турция тур
горящие путевки https://anex-tour-turkey.ru .
oneworldmiami.com
Лучшие пляжи и курорты
– Волшебная страна: турция тур
купить тур https://www.anex-tour-turkey.ru .
Отдых на курортах Турции
поездка в турцию https://www.tez-tour-turkey.ru/ .
http://2checkout.org/2019/11/19/hello-world/?unapproved=441345&moderation-hash=c846749466e80039613c47e3dc48d511#comment-441345
http://dangchuc.pro.vn/nhan-thiet-ke/vncafe-info/comment-page-186/#comment-84431
Отпуск мечты: туры в Турцию
туры горящие https://www.tez-tour-turkey.ru/ .
Медицинское оборудование по выгодным ценам. Купить медоборудование диагностическое, медтехнику. Огромный выбор медтехники медицинский оборудование купить
http://onlinesekho.com/9th-class-math-book-punjab-text-board-chapter-17#comment-194502
But wanna say that this really is quite helpful Thanks for taking your time to write this. – hey dudes womens
http://1xbet-cabinet-zerkalo.ru/
продвижение интернет магазина цена
http://vershina.one/novosti/o-nas/#comment-23450
поисковое seo продвижение
внешняя оптимизация
продвижение сайта оптимизация сайта под поисковые системы
seo продвижение сайта сколько стоит
продвижение сайта цена
http://e-gold.com.pl/witaj-swiecie/?unapproved=39872&moderation-hash=ad9448315b6a0649fde3cd677bf67bb4#comment-39872
seo комплексное продвижение
seo продвижение сайта заказать
http://suprememasterchinghai.net/bbs/board.php?bo_table=free&wr_id=1321343
1xbet бонус
http://paulallugany.com/marketing-digital/10-beneficios-de-utilizar-la-inteligencia-artificial-en-el-marketing-digital/#comment-23182
order prilosec 20mg pill buy generic prilosec prilosec 10mg cost
цена на армянский коньяк
купить аттестат образование https://rudik-attestats.com .
Написание эссе на заказ осуществляется нашими профессиональными авторами. Цена ВКР бакалавра купить зависит от ее объема и сложности отчет по практике на заказ
buy cheap elimite
Даркнет – скрытая зона интернета, избегающая взоров стандартных поисковых систем и требующая дополнительных средств для доступа. Этот анонимный ресурс сети обильно насыщен сайтами, предоставляя доступ к разношерстным товарам и услугам через свои перечни и индексы. Давайте подробнее рассмотрим, что представляют собой эти списки и какие тайны они сокрывают.
Даркнет Списки: Порталы в Неизведанный Мир
Даркнет списки – это своего рода проходы в невидимый мир интернета. Перечни и указатели веб-ресурсов в даркнете, они позволяют пользователям отыскивать различные услуги, товары и информацию. Варьируя от форумов и магазинов до ресурсов, уделяющих внимание аспектам анонимности и криптовалютам, эти списки предоставляют нам шанс заглянуть в таинственный мир даркнета.
Категории и Возможности
Теневой Рынок:
Даркнет часто связывается с теневым рынком, где доступны разнообразные товары и услуги – от психоактивных веществ и стрелкового оружия до краденых данных и услуг наемных убийц. Реестры ресурсов в этой категории облегчают пользователям находить нужные предложения без лишних усилий.
Форумы и Сообщества:
Даркнет также предоставляет площадку для анонимного общения. Форумы и сообщества, указанные в каталогах даркнета, затрагивают широкий спектр – от кибербезопасности и хакерства до политических аспектов и философских концепций.
Информационные Ресурсы:
На даркнете есть ресурсы, предоставляющие данные и указания по преодолению цензуры, обеспечению конфиденциальности и другим темам, интересным тем, кто хочет сохранить свою конфиденциальность.
Безопасность и Осторожность
Несмотря на неизвестность и свободу, даркнет полон опасностей. Мошенничество, кибератаки и незаконные сделки являются неотъемлемой частью этого мира. Взаимодействуя с реестрами даркнета, пользователи должны соблюдать высший уровень бдительности и придерживаться мер безопасности.
Заключение
Даркнет списки – это ключ к таинственному миру, где сокрыты тайны и возможности. Однако, как и в любой неизведанной территории, путешествие в даркнет требует особой внимания и знаний. Анонимность не всегда гарантирует безопасность, и использование даркнета требует осознанного подхода. Независимо от ваших интересов – будь то технические аспекты кибербезопасности, поиск уникальных товаров или исследование новых граней интернета – даркнет списки предоставляют ключ
Теневой интернет – это часть интернета, которая остается скрытой от обычных поисковых систем и требует специального программного обеспечения для доступа. В этой анонимной зоне сети существует масса ресурсов, включая различные списки и каталоги, предоставляющие доступ к разнообразным услугам и товарам. Давайте рассмотрим, что представляет собой каталог даркнета и какие тайны скрываются в его глубинах.
Теневые каталоги: Врата в анонимность
Для начала, что такое даркнет список? Это, по сути, каталоги или индексы веб-ресурсов в даркнете, которые позволяют пользователям находить нужные услуги, товары или информацию. Эти списки могут варьироваться от форумов и торговых площадок до ресурсов, специализирующихся на различных аспектах анонимности и криптовалют.
Категории и Возможности
Теневой Рынок:
Темная сторона интернета часто ассоциируется с теневым рынком, где можно найти различные товары и услуги, включая наркотики, оружие, украденные данные и даже услуги профессиональных устрашителей. Списки таких ресурсов позволяют пользователям без труда находить подобные предложения.
Форумы и Группы:
Темная сторона интернета также предоставляет платформы для анонимного общения. Чаты и сообщества на теневых каталогах могут заниматься обсуждением тем от интернет-безопасности и хакерства до политики и философии.
Информационные ресурсы:
Есть ресурсы, предоставляющие информацию и инструкции по обходу цензуры, защите конфиденциальности и другим темам, интересным пользователям, стремящимся сохранить анонимность.
Безопасность и Осторожность
При всей своей анонимности и свободе действий даркнет также несет риски. Мошенничество, кибератаки и незаконные сделки становятся частью этого мира. Пользователям необходимо проявлять максимальную осторожность и соблюдать меры безопасности при взаимодействии с даркнет списками.
Заключение: Врата в Неизведанный Мир
Теневые каталоги предоставляют доступ к теневым уголкам интернета, где сокрыты тайны и возможности. Однако, как и в любой неизведанной территории, важно помнить о возможных рисках и осознанно подходить к использованию даркнета. Анонимность не всегда гарантирует безопасность, и путешествие в этот мир требует особой осторожности и знания.
Независимо от того, интересуетесь ли вы техническими аспектами интернет-безопасности, ищете уникальные товары или просто исследуете новые грани интернета, теневые каталоги предоставляют ключ
1xbet кабинет
Подпольная сфера сети – неведомая сфера всемирной паутины, избегающая взоров обычных поисковых систем и требующая эксклюзивных средств для доступа. Этот скрытый уголок сети обильно насыщен платформами, предоставляя доступ к разнообразным товарам и услугам через свои каталоги и индексы. Давайте подробнее рассмотрим, что представляют собой эти реестры и какие тайны они сокрывают.
Даркнет Списки: Ворота в Неизведанный Мир
Индексы веб-ресурсов в темной части интернета – это своего рода порталы в скрытый мир интернета. Перечни и указатели веб-ресурсов в даркнете, они позволяют пользователям отыскивать различные услуги, товары и информацию. Варьируя от форумов и магазинов до ресурсов, уделяющих внимание аспектам анонимности и криптовалютам, эти перечни предоставляют нам возможность заглянуть в неизведанный мир даркнета.
Категории и Возможности
Теневой Рынок:
Даркнет часто ассоциируется с подпольной торговлей, где доступны разнообразные товары и услуги – от наркотиков и оружия до похищенной информации и помощи наемных убийц. Реестры ресурсов в данной категории облегчают пользователям находить подходящие предложения без лишних усилий.
Форумы и Сообщества:
Даркнет также предоставляет площадку для анонимного общения. Форумы и сообщества, указанные в каталогах даркнета, охватывают широкий спектр – от кибербезопасности и хакерства до политических вопросов и философских идей.
Информационные Ресурсы:
На даркнете есть ресурсы, предоставляющие данные и указания по обходу ограничений, защите конфиденциальности и другим вопросам, которые могут заинтересовать тех, кто стремится сохранить свою анонимность.
Безопасность и Осторожность
Несмотря на анонимность и свободу, даркнет полон рисков. Мошенничество, кибератаки и незаконные сделки становятся частью этого мира. Взаимодействуя с даркнет списками, пользователи должны соблюдать высший уровень бдительности и придерживаться мер безопасности.
Заключение
Даркнет списки – это ключ к таинственному миру, где скрыты секреты и возможности. Однако, как и в любой неизведанной территории, путешествие в темную сеть требует особой бдительности и знаний. Не всегда можно полагаться на анонимность, и использование темной сети требует сознательного подхода. Независимо от ваших интересов – будь то технические аспекты кибербезопасности, поиск уникальных товаров или исследование новых граней интернета – реестры даркнета предоставляют ключ
http://1xbet-cabinet-zerkalo.ru/
Темная сторона интернета – таинственная сфера интернета, избегающая взоров стандартных поисковых систем и требующая специальных средств для доступа. Этот скрытый ресурс сети обильно насыщен сайтами, предоставляя доступ к разношерстным товарам и услугам через свои каталоги и индексы. Давайте подробнее рассмотрим, что представляют собой эти списки и какие тайны они сокрывают.
Даркнет Списки: Порталы в Скрытый Мир
Индексы веб-ресурсов в темной части интернета – это своего рода проходы в неощутимый мир интернета. Каталоги и индексы веб-ресурсов в даркнете, они позволяют пользователям отыскивать разнообразные услуги, товары и информацию. Варьируя от форумов и магазинов до ресурсов, уделяющих внимание аспектам анонимности и криптовалютам, эти перечни предоставляют нам шанс заглянуть в таинственный мир даркнета.
Категории и Возможности
Теневой Рынок:
Даркнет часто связывается с незаконными сделками, где доступны разнообразные товары и услуги – от наркотиков и оружия до украденных данных и услуг наемных убийц. Каталоги ресурсов в данной категории облегчают пользователям находить подходящие предложения без лишних усилий.
Форумы и Сообщества:
Даркнет также предоставляет площадку для анонимного общения. Форумы и сообщества, указанные в каталогах даркнета, затрагивают широкий спектр – от компьютерной безопасности и хакерских атак до политических аспектов и философских концепций.
Информационные Ресурсы:
На даркнете есть ресурсы, предоставляющие сведения и руководства по преодолению цензуры, обеспечению конфиденциальности и другим темам, интересным тем, кто хочет сохранить свою конфиденциальность.
Безопасность и Осторожность
Несмотря на неизвестность и свободу, даркнет не лишен опасностей. Мошенничество, кибератаки и незаконные сделки присущи этому миру. Взаимодействуя с реестрами даркнета, пользователи должны соблюдать предельную осмотрительность и придерживаться мер безопасности.
Заключение
Даркнет списки – это путь в неизведанный мир, где сокрыты тайны и возможности. Однако, как и в любой неизведанной территории, путешествие в даркнет требует особой внимания и знаний. Анонимность не всегда гарантирует безопасность, и использование даркнета требует осмысленного подхода. Независимо от ваших интересов – будь то технические детали в области кибербезопасности, поиск необычных товаров или исследование новых возможностей в интернете – даркнет списки предоставляют ключ
buy tadacip cipla review
http://indianph.xyz/# п»їlegitimate online pharmacies india
http://1xbet-cabinet-zerkalo.ru/
buy prescription drugs from india mail order pharmacy india online shopping pharmacy india
trazodone hydrochloride 50 mg
newmexicodesign.net
https://indianph.xyz/# buy medicines online in india
world pharmacy india
https://hidehost.net/
Жёлтые короли
коньяк армения
1xbet рабочее на сегодня
Профильные трубы 40х20 мм. Закажите по низкой цене от производителя с доставкой по Москве. Предлагаем самые приятные цены в городе и области заглушки для профильных труб 60х60
https://indianph.com/# indian pharmacy paypal
buy medicines online in india
https://arm-wine.ru/
Гайто Газданов таксист в Париже
1хбет зеркало на сегодня
1xbet регистрация
cyclobenzaprine for sale online order cyclobenzaprine 15mg lioresal over the counter
https://indianph.com/# india pharmacy mail order
top 10 pharmacies in india
Быстрые грузоперевозки в Харькове
грузоперевозки для переезда http://www.moving-company-kharkov.com.ua .
Грузоперевозки для частных лиц
переезд фирма moving-company-kharkov.com.ua .
http://www.podzemie.6f.sk/profile.php?lookup=15880
1хбет бонус за регистрацию без депозита
generic lopressor 50mg lopressor where to buy buy metoprolol cheap
cyclobenzaprine price order ozobax online cheap buy baclofen generic
http://indianph.com/# Online medicine home delivery
best india pharmacy
Getting your hands on medication can sometimes not be as straightforward as we would like unfortunately, cost is a significant affecting factor when it comes to essential medicines buy rizatriptan pills for sale
Кирпич клинкерный: отличное решение для вашего строительства от Skriabin Ceramics
https://ukrmedgarant.com.ua/p973992643-apparat-dlya-vakuumno.html
http://thesims2thebest.0pk.me/viewtopic.php?id=555#p1100
https://indianph.com/# top 10 pharmacies in india
world pharmacy india
http://495ru.ru/number/1200081/
http://ugpravo.ru/index.php/2020/02/11/hello-world/?unapproved=463859&moderation-hash=34fbdf7b86847ece5fdc2869a447ad12#comment-463859
http://www.rapidclubs.ru/forum/thread97645-1.html#99273
https://indianph.com/# indianpharmacy com
indianpharmacy com
http://www.markusragger.at/chess/index.php/kforum/jm-corporate-template/613159#613287
можно ли купить аттестат http://gruppa-attestats.com/ .
https://beckom.ru/
http://advancedhypnosisinstitute.com/2016/08/27/hello-world/#comment-82197
http://naydisebe.ru/user/profile/131965
gambling
http://indianph.com/# top 10 pharmacies in india
india pharmacy mail order
greengo-shop
https://seolinkedin.ru/
https://forum.storeland.ru/index.php?/user/34594-diplomnjtgf/
Косметологическое оборудование Zemits – инновационные эстетические технологии для успешного развития Вашего СПА-бизнеса https://spashop.com.ua/collections/apparaty-mesoterapii
http://www.modern-computer.ru/modules/mod_pg/gde_nayti_samue_vugodnue_bezdepozitnue_bonusu_kazino.html
https://indianph.com/# buy medicines online in india
best india pharmacy
lopressor ca order lopressor 100mg online cheap metoprolol where to buy
https://muzgkb9-74.ru/images/pages/?gde_igrat__top_onlayn_kazino_s_nadezghnoy_reputaciey.html
דירות דיסקרטיות באשדוד
медтехника ведущих брендов для дома. Всегда оптимальные цены, акции , скидки и отличный сервис. Fnolhz
https://profosm.ru/ppdf/pgs/novue_kazino_onlayn__vozmozghnosti_dlya_uspeshnuh_stavok.html
https://indianph.com/# reputable indian online pharmacy
cheapest online pharmacy india
Забудьте о низких позициях в поиске! Наше SEO продвижение https://seopoiskovye.ru/ под ключ выведет ваш сайт на вершины Google и Yandex. Анализ конкурентов, глубокая оптимизация, качественные ссылки — всё для вашего бизнеса. Получите поток целевых клиентов уже сегодня!
промокод 1хбет
Жилой комплекс «Шифт»: современное жилье для комфортной жизни
https://sibmin.ru/media/articles/?bonus_za_registraciu_bez_depozita__top_kazino_predlozgheniy.html
https://greengo-shop.ru
Забудьте о низких позициях в поиске! Наше SEO продвижение и оптимизация на заказ https://seosistemy.ru/ выведут ваш сайт в топ, увеличивая его видимость и привлекая потенциальных клиентов. Индивидуальный подход, глубокий анализ ключевых слов, качественное наполнение контентом — мы сделаем всё, чтобы ваш бизнес процветал.
st666 trang chủ
Відомі бренди спецтехніки
спец техніка https://www.spectehnika-sksteh.co.ua/ .
greengo-shop.ru
Кращі пропозиції на спецтехніку
продаж спецтехніки https://spectehnika-sksteh.co.ua/ .
Профессиональные советы
6. Как выбрать место для установки кондиционера
кондиционер цена http://www.ustanovit-kondicioner.ru/ .
https://vk.com/oborudovanie_dlya_avtomoek_us
Дайте вашему сайту заслуженное место в топе поисковых систем! Наши услуги
yandex продвижение сайта на заказ обеспечат максимальную видимость вашего бизнеса в интернете. Персонализированные стратегии, тщательный подбор ключевых слов, оптимизация контента и технические улучшения — всё это для привлечения целевой аудитории и увеличения продаж. Вместе мы поднимем ваш сайт на новый уровень успеха!
10 способов продвижения строительных услуг
seo продвижение строительного сайта https://seo-prodvizhenie-sajtov-stroitelnyh-kompanij.ru/ .
buy toradol 10mg for sale buy generic toradol for sale colchicine 0.5mg usa
https://vk.com/oborudovanie_dlya_avtomoek_us?w=wall-224049389_22%2Fall
Все о современных технологиях
Без лишних хлопот
17. Что нужно знать перед началом установки кондиционера
фреон для кондиционера https://www.ustanovit-kondicioner.ru .
דירות דיסקרטיות באשדוד
Дайте вашему сайту заслуженное место в топе поисковых систем! Наши услуги сколько стоит продвижение интернет магазина на заказ обеспечат максимальную видимость вашего бизнеса в интернете. Персонализированные стратегии, тщательный подбор ключевых слов, оптимизация контента и технические улучшения — всё это для привлечения целевой аудитории и увеличения продаж. Вместе мы поднимем ваш сайт на новый уровень успеха!
Здрасьте. kuzovdetali – достойный ассортимент деталей и подбор автозапчастей из европы. Перейдите на сайт для заказа новых и оригинальных деталей для автомобилей. Гарантия и доставка по городу Минску и областям.
buy cheap zerit no prescription
Vavada
Здрасьте. купить кузовные запчасти – достойный ассортимент кузовных запчастей и подбор автозапчастей для кузова автомобиля. Перейдите в магазин для заказа новых и оригинальных запчастей для авто. Гарантия и доставка по городам РБ.
Компания предлагает обширный ассортимент услуг по изготовлению чеков на все случаи жизни. Вы точно сможете найти индивидуальное решение бюрократических проблем Заказать чеки Казань
Приветствую. купить кузовные запчасти в Минске – доступный ассортимент деталей и подбор автозапчастей для иномарок. Перейдите в интернет-магазин для заказа новых и оригинальных деталей для авто. Гарантия и доставка по РБ.
purchase toradol without prescription order generic colchicine colchicine without prescription
1хбет официальный вход
דירות דיסקרטיות באשדוד ביקורות
antibiotic cleocin
Дайте вашему сайту заслуженное место в топе поисковых систем! Наши услуги заказать seo на заказ обеспечат максимальную видимость вашего бизнеса в интернете. Персонализированные стратегии, тщательный подбор ключевых слов, оптимизация контента и технические улучшения — всё это для привлечения целевой аудитории и увеличения продаж. Вместе мы поднимем ваш сайт на новый уровень успеха!
Дайте вашему сайту заслуженное место в топе поисковых систем! Наши услуги поисковое продвижение на заказ обеспечат максимальную видимость вашего бизнеса в интернете. Персонализированные стратегии, тщательный подбор ключевых слов, оптимизация контента и технические улучшения — всё это для привлечения целевой аудитории и увеличения продаж. Вместе мы поднимем ваш сайт на новый уровень успеха!
Здрасьте. кузовные запчасти – достойный ассортимент кузовных запчастей и подбор автозапчастей для кузова автомобиля. Переходите в магазин для заказа новых и оригинальных деталей для автомобилей. Гарантия и доставка по городу Минску и областям.
Дайте вашему сайту заслуженное место в топе поисковых систем! Наши услуги раскрутка сайта seo на заказ обеспечат максимальную видимость вашего бизнеса в интернете. Персонализированные стратегии, тщательный подбор ключевых слов, оптимизация контента и технические улучшения — всё это для привлечения целевой аудитории и увеличения продаж. Вместе мы поднимем ваш сайт на новый уровень успеха!
Vavada casino
Дайте вашему сайту заслуженное место в топе поисковых систем! Наши услуги
seo раскрутка на заказ обеспечат максимальную видимость вашего бизнеса в интернете. Персонализированные стратегии, тщательный подбор ключевых слов, оптимизация контента и технические улучшения — всё это для привлечения целевой аудитории и увеличения продаж. Вместе мы поднимем ваш сайт на новый уровень успеха!
Дайте вашему сайту заслуженное место в топе поисковых систем! Наши услуги сео продвижение сайта заказать москва на заказ обеспечат максимальную видимость вашего бизнеса в интернете. Персонализированные стратегии, тщательный подбор ключевых слов, оптимизация контента и технические улучшения — всё это для привлечения целевой аудитории и увеличения продаж. Вместе мы поднимем ваш сайт на новый уровень успеха!
Лучшие юристы и адвокаты оказывают бесплатные юридические консультации по телефону и в офисе компании. Квалифицированная юридическая помощь по всем отраслям права телефон бесплатной юридической консультации
Дайте вашему сайту заслуженное место в топе поисковых систем! Наши услуги
сео оптимизация сайта на заказ обеспечат максимальную видимость вашего бизнеса в интернете. Персонализированные стратегии, тщательный подбор ключевых слов, оптимизация контента и технические улучшения — всё это для привлечения целевой аудитории и увеличения продаж. Вместе мы поднимем ваш сайт на новый уровень успеха!
order atenolol without prescription buy atenolol generic order tenormin generic
Здрасьте. KuzovDetali – достойный ассортимент кузовных деталей и подбор автозапчастей из европы. Переходите в магазин для заказа новых и оригинальных товаров для автомобилей. Гарантия и доставка по городам РБ.
where to buy ashwagandha leaves
Дайте вашему сайту заслуженное место в топе поисковых систем! Наши услуги
продвижение сайтов seo на заказ обеспечат максимальную видимость вашего бизнеса в интернете. Персонализированные стратегии, тщательный подбор ключевых слов, оптимизация контента и технические улучшения — всё это для привлечения целевой аудитории и увеличения продаж. Вместе мы поднимем ваш сайт на новый уровень успеха!
1хбет официальный
Дайте вашему сайту заслуженное место в топе поисковых систем! Наши услуги seo раскрутка на заказ обеспечат максимальную видимость вашего бизнеса в интернете. Персонализированные стратегии, тщательный подбор ключевых слов, оптимизация контента и технические улучшения — всё это для привлечения целевой аудитории и увеличения продаж. Вместе мы поднимем ваш сайт на новый уровень успеха!
Vitaliy Aleksandrovich Yuzhilin https://en.wikipedia.org/wiki/vitaliy_aleksandrovich_yuzhilin .
Бонусная система Леон
https://cipro.guru/# ciprofloxacin 500 mg tablet price
https://www.janubaba.com/c/forum/topic/230039/Gaming_Zone/Mostbet
На территории столице России приобрести диплом – это практичный и быстрый метод получить нужный запись без дополнительных трудностей. Разнообразие организаций предоставляют сервисы по созданию и торговле дипломов разных образовательных учреждений – [URL=https://prema-diploms-srednee.com/]https://www.prema-diploms-srednee.com/[/URL]. Выбор дипломов в столице России огромен, включая документация о академическом и среднем образовании, документы, свидетельства вузов и университетов. Основной преимущество – возможность получить диплом Гознака, гарантирующий достоверность и высокое качество. Это гарантирует специальная защита против подделок и позволяет воспользоваться свидетельство для различных целей. Таким образом, приобретение аттестата в Москве является важным достоверным и эффективным выбором для таких, кто желает достичь успеха в карьере.
Всем хай. купить кузовные запчасти в Минске – большой ассортимент запчастей и подбор автозапчастей на заказ. Переходите в интернет-магазин для заказа новых и оригинальных товаров на машины. Гарантия и доставка по городу Минску и областям.
antibiotics cipro: cipro 500mg best prices – purchase cipro
Профессиональный ремонт и обслуживание автомобилей концерна VAG
https://onlinecasinos.com.cy/
http://cipro.guru/# cipro generic
https://polbetonstroy.ru/
Честный обзор на популярную букмекерскую контору 1win поможет вам узнать все преимущества и недостатки этого сайта для ставок, включая коэффициенты, линию событий, способах и скорости выплат, бонусы и многое другое. Изучите все исходы и выгодные предложения, перейдя на официальный сайт БК [url=https://economytimes.ru/1win-registraciya/]1win официальный[/url]
Всем хай. [url=https://kuzovdetali.by/]https://kuzovdetali.by/[/url] – широкий ассортимент деталей и подбор автозапчастей из европы. Перейдите в интернет-магазин для заказа новых и оригинальных запчастей для авто. Гарантия и доставка по Беларуси.
перевести деньги в Китай
diflucan otc canada: where to buy diflucan otc – diflucan prescription cost
Все бонусы БК Леон
Приветствую. [url=https://kuzovdetali.by/]купить запчасти кузова[/url] – большой ассортимент товаров и подбор автозапчастей для кузова машины. Перейдите в магазин для заказа новых и оригинальных товаров для автомобилей. Гарантия и доставка по Беларуси.
https://lechenie-bolezney.ru/
Гарантированно низкие цены на кондиционеры
цены на кондиционеры https://www.prodazha-kondicionera.ru/ .
Кондиционеры на распродаже
монтаж кондиционера prodazha-kondicionera.ru .
Леон – ваш бонус ждет
Stomatologurmonsk Современные технологии
Какие профилактические меры помогут избежать проблем со здоровьем зубов?
http://anime.forumkz.ru/viewtopic.php?id=3520#p50291 .
https://onlinecasinos.com.cy/
cost generic benemid without rx
buy tenormin online tenormin 100mg price tenormin over the counter
выделенный сервер
https://onlinecasinos.com.cy/
buy cytotec online fast delivery: buy cytotec – buy cytotec over the counter
В последнее время становятся известными запросы о переводах без предоплат – предложениях, предлагаемых в сети, где клиентам обещают выполнение заказа или предоставление товара до внесения денег. Впрочем, за этой привлекающей внимание выгодой могут быть скрываться значительные риски и негативные последствия.
Привлекательная сторона бесплатных переводов:
Привлекательная сторона идеи заливов без предварительной оплаты заключается в том, что клиенты приобретают услугу или товар, не внося сначала деньги. Это может казаться выгодным и удобным, особенно для тех, кто не хочет рисковать деньгами или претерпеть обманутым. Однако, прежде чем погрузиться в мир безоплатных переводов, необходимо учесть ряд существенных пунктов.
Опасности и отрицательные следствия:
Мошенничество и обман:
За порядочными проектами без предоплат скрываются мошеннические схемы, приготовленные использовать доверие потребителей. Оказавшись в ихнюю ловушку, вы можете потерять не только это, услуги но и денег.
Низкое качество выполнения услуг:
Без гарантии исполнителю может быть мало мотивации предоставить высококачественную услугу или продукт. В результате клиент останется недовольным, а исполнитель не подвергнется значительными последствиями.
Утрата информации и защиты:
При передаче личных данных или информации о банковских счетах для безоплатных переводов существует риск утечки информации и последующего их злоупотребления.
Рекомендации по надежным заливам:
Исследование:
До выбором бесплатных заливов проведите тщательное исследование исполнителя. Отзывы, рейтинги и репутация могут хорошим критерием.
Предоплата:
Если возможно, старайтесь договориться определенный процент вознаграждения вперед. Это может сделать сделку более защищенной и гарантирует вам больший управления.
Проверенные сервисы:
Предпочитайте применению надежных площадок и сервисов для переводов. Это снизит риск мошенничества и повысит шансы на получение качественных услуг.
Заключение:
Несмотря на очевидную привлекательность, заливы без предварительной оплаты сопряжены риски и угрозы. Внимание и осторожность при выборе исполнителя или площадки способны предотвратить негативные последствия. Важно помнить, что безоплатные переводы способны превратиться в источником проблем, и осознанное принятие решений способствует избежать потенциальных проблем
https://m.21.by/pub/img/pages/index.php?888starz_zerkalo__obzor_i_shagi_po_obhodu_blokirovok.html
даркнет новости
Теневая зона – это таинственная и незнакомая территория интернета, где действуют особые правила, перспективы и опасности. Ежедневно в мире теневой сети происходят инциденты, о которых обычные участники могут только подозревать. Давайте рассмотрим актуальные новости из даркнета, отражающие настоящие тенденции и события в этом скрытом уголке сети.”
Тенденции и События:
“Развитие Средств и Безопасности:
В теневом интернете непрерывно совершенствуются технологии и подходы защиты. Информация о появлении улучшенных платформ кодирования, скрытия личности и защиты личных данных свидетельствуют о желании пользователей и разработчиков к поддержанию надежной среды.”
“Новые Скрытые Площадки:
Следуя динамикой изменений спроса и предложения, в теневом интернете появляются совершенно новые коммерческие пространства. Новости о запуске цифровых рынков предоставляют участникам различные варианты для торговли продукцией и сервисами
Покупка удостоверения личности в интернет-магазине – это неправомерное и рискованное действие, которое может вызвать к серьезным последствиям для людей. Вот некоторые аспектов, о которые важно запомнить:
Незаконность: Приобретение паспорта в интернет-магазине является нарушением закона. Имение поддельным удостоверением способно повлечь за собой уголовную ответственность и серьезные штрафы.
Опасности индивидуальной безопасности: Обстоятельство применения фальшивого паспорта способен подвергнуть угрозу личную секретность. Люди, пользующиеся фальшивыми удостоверениями, могут оказаться объектом преследования со стороны правоохранительных органов.
Материальные убытки: Зачастую мошенники, торгующие фальшивыми паспортами, способны использовать ваши информацию для мошенничества, что приведёт к денежным убыткам. Личные или финансовые данные способны оказаться использованы в преступных намерениях.
Трудности при перемещении: Поддельный удостоверение личности может быть распознан при переезде перейти границу или при контакте с официальными инстанциями. Такое обстоятельство может привести к задержанию, депортации или другим серьезным проблемам при путешествиях.
Потеря доверия и репутации: Применение фальшивого паспорта может привести к утрате доверия со стороны сообщества и нанимателей. Это обстановка способна негативно влиять на ваши престиж и трудовые возможности.
Вместо того, чтобы рисковать собственной свободой, безопасностью и репутацией, советуется придерживаться законодательство и использовать государственными путями для получения документов. Эти предусматривают защиту всех ваших законных интересов и обеспечивают секретность ваших информации. Незаконные действия способны повлечь за собой непредсказуемые и вредные ситуации, создавая тяжелые проблемы для вас и ваших вашего окружения
https://polbetonstroy.ru/
doxycycline 200mg twice a day
В последнее время интернет превратился в бесконечный ресурс знаний, услуг и продуктов. Однако, в среде множества виртуальных магазинов и площадок, существует темная сторона, известная как даркнет магазины. Данный уголок виртуального мира создает свои рискованные реалии и сопровождается серьезными опасностями.
Каковы Даркнет Магазины:
Даркнет магазины являются онлайн-платформы, доступные через анонимные браузеры и уникальные программы. Они действуют в скрытой сети, невидимом от обычных поисковых систем. Здесь можно обнаружить не только торговцев нелегальными товарами и услугами, но и различные преступные схемы.
Категории Товаров и Услуг:
Даркнет магазины предлагают разнообразный выбор товаров и услуг, начиная от наркотиков и оружия вплоть до хакерских услуг и похищенных данных. На этой темной площадке действуют торговцы, дающие возможность приобретения запрещенных вещей без опасности быть выслеженным.
Риски для Пользователей:
Легальные Последствия:
Покупка незаконных товаров на даркнет магазинах подвергает пользователей опасности столкнуться с полицией. Уголовная ответственность может быть значительным следствием таких покупок.
Мошенничество и Обман:
Даркнет тоже является плодородной почвой для мошенников. Пользователи могут попасть в обман, где оплата не приведет к получению в руки товара или услуги.
Угрозы Кибербезопасности:
Даркнет магазины предоставляют услуги хакеров и киберпреступников, что сопровождается реальными угрозами для безопасности данных и конфиденциальности.
Распространение Преступной Деятельности:
Экономика даркнет магазинов содействует распространению преступной деятельности, так как обеспечивает инфраструктуру для нелегальных транзакций.
Борьба с Проблемой:
Усиление Кибербезопасности:
Улучшение кибербезопасности и технологий слежения способствует бороться с даркнет магазинами, превращая их менее поулчаемыми.
Законодательные Меры:
Принятие строгих законов и их решительная реализация направлены на предупреждение и наказание пользователей даркнет магазинов.
Образование и Пропаганда:
Увеличение осведомленности о рисках и последствиях использования даркнет магазинов может снизить спрос на незаконные товары и услуги.
Заключение:
Даркнет магазины доступ к темным уголкам интернета, где проступают теневые фигуры с преступными планами. Рациональное применение ресурсов и повышенная бдительность необходимы, для того чтобы защитить себя от рисков, связанных с этими темными магазинами. В конечном итоге, безопасность и соблюдение законов должны быть на первом месте, когда речь заходит о виртуальных покупках
даркнет 2024
Даркнет 2024: Скрытые аспекты виртуального мира
С инициации даркнет был собой сферу интернета, где тайна и тень становились обыденностью. В 2024 году этот скрытый мир развивается, предоставляя новые вызовы и опасности для сообщества в сети. Рассмотрим, какие тенденции и модификации предстоят обществу в даркнете 2024.
Продвижение технологий и Повышение скрытности
С прогрессом технологий, инструменты для обеспечения скрытности в теневом интернете становятся сложнее и эффективными. Использование криптовалют, новых алгоритмов шифрования и децентрализованных сетей делает слежение за поведением пользователей еще более сложным для правоохранительных органов.
Рост тематических рынков
Даркнет-рынки, специализирующиеся на различных товарах и услугах, продолжают развиваться. Психотропные вещества, военные припасы, хакерские инструменты, персональная информация – ассортимент продукции бывает все более разнообразным. Это порождает вызов для силовых структур, стоящего перед задачей адаптироваться к изменяющимся сценариям нелегальных действий.
Опасности цифровой безопасности для непрофессионалов
Сервисы аренды хакерских услуг и мошеннические схемы продолжают существовать активными в теневом интернете. Люди, не связанные с преступностью становятся целью для преступников в сети, желающих зайти к личным данным, счетам в банке и иных секретных данных.
Перспективы цифровой реальности в теневом интернете
С прогрессом техники цифровой симуляции, даркнет может перейти в совершенно новую фазу, предоставляя пользователям реальные и вовлекающие цифровые области. Это может включать в себя дополнительными видами нелегальных действий, такими как цифровые рынки для обмена виртуальными товарами.
Борьба структурам защиты
Силы безопасности совершенствуют свои технологии и подходы противостояния даркнетом. Коллективные меры стран и международных организаций ориентированы на профилактику киберпреступности и прекращение современным проблемам, связанным с развитием скрытого веба.
Вывод
Даркнет 2024 продолжает оставаться сложной и разносторонней средой, где технологии продолжают вносить изменения в пейзаж нелегальных действий. Важно для участников продолжать быть настороженными, гарантировать свою кибербезопасность и следовать законы, даже при нахождении в виртуальном пространстве. Вместе с тем, борьба с даркнетом требует коллективных действиях от стран, технологических компаний и граждан, чтобы обеспечить безопасность в цифровом мире.
buying benemid tablets
наливной пол цена
https://wildlife.by/images/pages/?bezdepozitnue_bonusu_kazino__vash_shans_na_besplatnuu_igru.html
купить аттестат о среднем https://www.russkiy-attestat.com .
doxy 200: doxycycline online – generic for doxycycline
http://popmarket.ru/ww/pages/obzor_na_bezdepozitnue_bonusu_kazino__novinki_2023_goda.html
Купить диплом о среднем образовании цена – – это шанс оперативно получить запись об образовании на бакалавр уровне без излишних хлопот и расходов времени. В городе Москве доступны множество вариантов оригинальных свидетельств бакалавров, обеспечивающих комфорт и простоту в процессе.
cheap colchicine pill
Feel the heat of the casino floor at our Mexican online casino. With live dealer games and interactive experiences, you’ll get the full VIP treatment from the comfort of your home. caliente sports este es tu futuro.
can you get cheap mobic prices
https://1xbettur-2.com/
http://orthodoxy.ru/wp-content/articles/kazino_spinbetter___onlayn_razvlecheniya_na_vershine.html
mostbet giris
winbet666.org
http://orthodoxy.ru/wp-content/articles/spisok_samuh_nadezghnuh_onlayn_kazino__tolko_proverennue_saytu.html
Get ready to experience the thrill of victory at our Mexican casino platform. With high-stakes games and adrenaline-pumping excitement, you’ll be on the edge of your seat with every bet. caliente tienes todo lo mejor.
microunda incorporabila
Друзья азарта, на предыдущий день я атаковал лавовые вулканы, нынешним днем – онлайн слоты в казино бонус за регистрацию! это именно необычайное игровое заведение, а пестрая вулканическая гармония счастья. Здесь каждый делает индивидуальный отпечаток в течении побед. Присоединьтесь к пылающему карнавалу!
Keep this going please, great job!
how can i get cheap sildalist no prescription
Hi! This is my first visit to your blog! We are a group of volunteers and starting a new initiative in a community in the same niche.
Your blog provided us useful information to work on. You have done a marvellous
job!
Win big and win often at our Mexican online casino. With generous payouts and thrilling tournaments, the sky’s the limit when you play with us. calientecasinoa.com casino te da mas.
Он эффективен в отношении микробов, вирусов, плесени, грибка. Процедура озонирования квартиры направлена на общую глубокую дезинфекцию помещения дезінфекція квартири
https://1xbettur-2.com/
https://mosttr-1.com/
даркнет вход
Даркнет – загадочное пространство Интернета, доступен только только для тех, кому знает правильный вход. Этот таинственный уголок виртуального мира служит местом для скрытных транзакций, обмена информацией и взаимодействия засекреченными сообществами. Однако, чтобы погрузиться в этот темный мир, необходимо преодолеть несколько барьеров и использовать особые инструменты.
Использование специализированных браузеров: Для доступа к даркнету обычный браузер не подойдет. На помощь приходят эксклюзивные браузеры, такие как Tor (The Onion Router). Tor позволяет пользователям обходить цензуру и обеспечивает анонимность, отмечая и перенаправляя запросы через различные серверы.
Адреса в даркнете: Обычные домены в даркнете заканчиваются на “.onion”. Для поиска ресурсов в даркнете, нужно использовать поисковики, подходящие для этой среды. Однако следует быть осторожным, так как далеко не все ресурсы там законны.
Защита анонимности: При посещении даркнета следует принимать меры для защиты анонимности. Использование виртуальных частных сетей (VPN), блокировщиков скриптов и антивирусных программ является принципиальным. Это поможет избежать различных угроз и сохранить конфиденциальность.
Электронные валюты и биткоины: В даркнете часто используются криптовалюты, в основном биткоины, для анонимных транзакций. Перед входом в даркнет следует ознакомиться с основами использования виртуальных валют, чтобы избежать финансовых рисков.
Правовые аспекты: Следует помнить, что многие операции в даркнете могут быть незаконными и противоречить законам различных стран. Пользование даркнетом несет риски, и непоследовательные действия могут привести к серьезным юридическим последствиям.
Заключение: Даркнет – это неисследованное пространство сети, наполненное анонимности и тайн. Вход в этот мир требует присущих только навыков и предосторожности. При всем мистическом обаянии даркнета важно помнить о предполагаемых рисках и последствиях, связанных с его использованием.
3D-печать представляет из себя новейшую методику, основанную на наплавлении материала тонкими слоями. Этот инновационный способ изготовления объектов находит многочисленное применение во всевозможных сферах жизни. Если хотите разузнать подробнее про печать деталей на 3D принтере, вот надежная компания, работаю с ними более 10 лет.
https://1xbettur-2.com/
Даркнет список
Введение в Темный Интернет: Уточнение и Главные Характеристики
Пояснение понятия даркнета, возможных отличий от стандартного интернета, и основных черт этого темного мира.
Как Войти в Темный Интернет: Путеводитель по Анонимному Входу
Подробное разъяснение шагов, требуемых для входа в даркнет, включая использование специализированных браузеров и инструментов.
Адресация в Темном Интернете: Секреты .onion-Доменов
Пояснение, как работают .onion-домены, и какие ресурсы они содержат, с акцентом на безопасном поисковой активности и использовании.
Безопасность и Конфиденциальность в Даркнете: Меры для Пользователей
Обзор техник и инструментов для сохранения анонимности при эксплуатации даркнета, включая VPN и другие средства.
Электронные Валюты в Даркнете: Роль Биткойнов и Криптовалют
Анализ использования цифровых валют, в основном биткоинов, для совершения анонимных транзакций в даркнете.
Поиск в Темном Интернете: Особенности и Риски
Рассмотрение поисковиков в даркнете, предупреждения о потенциальных рисках и нелегальных ресурсах.
Правовые Аспекты Даркнета: Ответственность и Последствия
Обзор законных аспектов использования даркнета, предупреждение о возможных юридических последствиях.
Темный Интернет и Информационная Безопасность: Потенциальные Опасности и Противозащитные Действия
Анализ возможных киберугроз в даркнете и советы по защите от них.
Даркнет и Общественные Сети: Скрытое Общение и Группы
Рассмотрение роли даркнета в области социальных взаимодействий и создании скрытых сообществ.
Будущее Темного Интернета: Тренды и Прогнозы
Прогнозы развития даркнета и потенциальные изменения в его структуре в будущем.
Взлом телеграм
Взлом Телеграм: Мифы и Реальность
Telegram – это известный мессенджер, признанный своей превосходной степенью кодирования и защиты данных пользователей. Однако, в современном цифровом мире тема взлома Telegram периодически поднимается. Давайте рассмотрим, что на самом деле стоит за этим термином и почему взлом Telegram чаще является фантазией, чем реальностью.
Кодирование в Telegram: Основные принципы Безопасности
Телеграм известен своим высоким уровнем шифрования. Для обеспечения конфиденциальности переписки между участниками используется протокол MTProto. Этот протокол обеспечивает конечно-конечное кодирование, что означает, что только отправитель и получающая сторона могут понимать сообщения.
Легенды о Нарушении Telegram: По какой причине они появляются?
В последнее время в сети часто появляются утверждения о взломе Telegram и возможности доступа к персональной информации пользователей. Однако, большинство этих утверждений оказываются мифами, часто возникающими из-за непонимания принципов работы мессенджера.
Кибернападения и Раны: Фактические Опасности
Хотя взлом Телеграма в большинстве случаев является трудной задачей, существуют реальные угрозы, с которыми сталкиваются пользователи. Например, кибератаки на отдельные аккаунты, вредоносные программы и прочие методы, которые, тем не менее, требуют в личном участии пользователя в их распространении.
Охрана Персональных Данных: Рекомендации для Участников
Несмотря на отсутствие точной опасности нарушения Телеграма, важно соблюдать базовые правила кибербезопасности. Регулярно обновляйте приложение, используйте двухэтапную проверку, избегайте подозрительных ссылок и мошеннических атак.
Итог: Фактическая Угроза или Паника?
Взлом Телеграма, как правило, оказывается неоправданным страхом, созданным вокруг темы разговора без явных доказательств. Однако безопасность всегда остается приоритетом, и участники мессенджера должны быть бдительными и следовать советам по обеспечению безопасности своей персональных данных
https://mosttr-1.com/
Взлом WhatsApp: Реальность и Легенды
WhatsApp – один из известных мессенджеров в мире, широко используемый для обмена сообщениями и файлами. Он прославился своей шифрованной системой обмена данными и обеспечением конфиденциальности пользователей. Однако в сети время от времени появляются утверждения о возможности взлома WhatsApp. Давайте разберемся, насколько эти утверждения соответствуют реальности и почему тема взлома Вотсап вызывает столько дискуссий.
Шифрование в WhatsApp: Охрана Личной Информации
WhatsApp применяет end-to-end шифрование, что означает, что только отправитель и получатель могут понимать сообщения. Это стало основой для доверия многих пользователей мессенджера к сохранению их личной информации.
Мифы о Нарушении Вотсап: По какой причине Они Появляются?
Сеть периодически наполняют слухи о нарушении Вотсап и возможном доступе к переписке. Многие из этих утверждений часто не имеют обоснований и могут быть результатом паники или дезинформации.
Реальные Угрозы: Кибератаки и Безопасность
Хотя нарушение Вотсап является сложной задачей, существуют реальные угрозы, такие как кибератаки на отдельные аккаунты, фишинг и вредоносные программы. Соблюдение мер безопасности важно для минимизации этих рисков.
Защита Личной Информации: Рекомендации Пользователям
Для укрепления безопасности своего аккаунта в WhatsApp пользователи могут использовать двухэтапную проверку, регулярно обновлять приложение, избегать сомнительных ссылок и следить за конфиденциальностью своего устройства.
Заключение: Реальность и Осторожность
Нарушение WhatsApp, как правило, оказывается сложным и маловероятным сценарием. Однако важно помнить о актуальных угрозах и принимать меры предосторожности для сохранения своей личной информации. Исполнение рекомендаций по безопасности помогает поддерживать конфиденциальность и уверенность в использовании мессенджера
взлом whatsapp
Взлом WhatsApp: Фактичность и Легенды
Вотсап – один из известных мессенджеров в мире, массово используемый для передачи сообщениями и файлами. Он известен своей кодированной системой обмена данными и обеспечением конфиденциальности пользователей. Однако в сети время от времени возникают утверждения о возможности взлома Вотсап. Давайте разберемся, насколько эти утверждения соответствуют реальности и почему тема взлома WhatsApp вызывает столько дискуссий.
Кодирование в Вотсап: Защита Личной Информации
WhatsApp применяет end-to-end кодирование, что означает, что только отправитель и получатель могут понимать сообщения. Это стало фундаментом для уверенности многих пользователей мессенджера к защите их личной информации.
Легенды о Нарушении WhatsApp: Почему Они Появляются?
Сеть периодически наполняют слухи о взломе Вотсап и возможном доступе к переписке. Многие из этих утверждений часто не имеют обоснований и могут быть результатом паники или дезинформации.
Фактические Угрозы: Кибератаки и Охрана
Хотя взлом Вотсап является сложной задачей, существуют актуальные угрозы, такие как кибератаки на индивидуальные аккаунты, фишинг и вредоносные программы. Соблюдение мер охраны важно для минимизации этих рисков.
Защита Личной Информации: Советы Пользователям
Для укрепления безопасности своего аккаунта в Вотсап пользователи могут использовать двухэтапную проверку, регулярно обновлять приложение, избегать подозрительных ссылок и следить за конфиденциальностью своего устройства.
Итог: Реальность и Осторожность
Нарушение WhatsApp, как обычно, оказывается трудным и маловероятным сценарием. Однако важно помнить о актуальных угрозах и принимать меры предосторожности для защиты своей личной информации. Исполнение рекомендаций по безопасности помогает поддерживать конфиденциальность и уверенность в использовании мессенджера.
https://1wintr-4.xyz/
сварочный лазерный аппарат https://www.apparaty-lazernoy-svarki.ru .
1. Где купить кондиционер: лучшие магазины и выбор
2. Как выбрать кондиционер: советы по покупке
3. Кондиционеры в наличии: где купить прямо сейчас
4. Купить кондиционер онлайн: удобство и выгодные цены
5. Кондиционеры для дома: какой выбрать и где купить
6. Лучшие предложения на кондиционеры: акции и распродажи
7. Кондиционер купить: сравнение цен и моделей
8. Кондиционеры с установкой: где купить и как установить
9. Где купить кондиционер с доставкой: быстро и надежно
10. Кондиционеры: где купить качественный товар по выгодной цене
11. Кондиционер купить: как выбрать оптимальную мощность
12. Кондиционеры для офиса: какой выбрать и где купить
13. Кондиционер купить: самый выгодный вариант
14. Кондиционеры в рассрочку: где купить и как оформить
15. Кондиционеры: лучшие магазины и предложения
16. Кондиционеры на распродаже: где купить по выгодной цене
17. Как выбрать кондиционер: советы перед покупкой
18. Кондиционер купить: где найти лучшие цены
19. Лучшие магазины кондиционеров: где купить качественный товар
20. Кондиционер купить: выбор из лучших моделей
кондиционер с установкой kondicioner-cena.ru .
Дизайнер по шторам: профессиональное оформление окон с учетом всех требований
http://medgorodok.ru/files/pages/?otkroyte_novue_kazino_dlya_zahvatuvaushih_azartnuh_priklucheniy.html
Oh my goodness, you’ve done an outstanding job this time! Your dedication and creativity are truly admirable of this piece. I couldn’t resist expressing my gratitude for sharing such awesome work with us. You have an incredible talent and dedication. Keep up the incredible work! 🌟👏👍
Get ready to experience the thrill of victory at our Mexican casino platform. With high-stakes games and adrenaline-pumping excitement, you’ll be on the edge of your seat with every bet. tres reyes casino tienes todo lo mejor.
Sweetie Fox izle: Sweetie Fox – Sweetie Fox izle
pragmatic-ko.com
Zhu Houzhao와 Fang Jifan에게 이것은 상업적 개발입니다.
1. Где купить кондиционер: лучшие магазины и выбор
2. Как выбрать кондиционер: советы по покупке
3. Кондиционеры в наличии: где купить прямо сейчас
4. Купить кондиционер онлайн: удобство и выгодные цены
5. Кондиционеры для дома: какой выбрать и где купить
6. Лучшие предложения на кондиционеры: акции и распродажи
7. Кондиционер купить: сравнение цен и моделей
8. Кондиционеры с установкой: где купить и как установить
9. Где купить кондиционер с доставкой: быстро и надежно
10. Кондиционеры: где купить качественный товар по выгодной цене
11. Кондиционер купить: как выбрать оптимальную мощность
12. Кондиционеры для офиса: какой выбрать и где купить
13. Кондиционер купить: самый выгодный вариант
14. Кондиционеры в рассрочку: где купить и как оформить
15. Кондиционеры: лучшие магазины и предложения
16. Кондиционеры на распродаже: где купить по выгодной цене
17. Как выбрать кондиционер: советы перед покупкой
18. Кондиционер купить: где найти лучшие цены
19. Лучшие магазины кондиционеров: где купить качественный товар
20. Кондиционер купить: выбор из лучших моделей
кондиционер цена https://kondicioner-cena.ru .
http://zarem.ru/includes/pages/bezdepozitnue_bonusu_kazino__vash_pervuy_shag_k_uspehu_v_azartnuh_igrah_2023_.html
https://1wintr-4.xyz/
wegovy medication
https://abia.ru/js/pgs/luchshie_novue_kazino_dlya_besplatnoy_igru__poprobuyte_bez_riska.html
https://1wintr-4.xyz/
https://toponym.antat.ru/css/pgs/top_layv_kazino_s_bustrumi_vuplatami__gde_vuigruvat_legko.html
?????? ????: abella danger video – Abella Danger
This is amazing, you’ve done an incredible job this time! Your effort and dedication shine through in every aspect of this content. I simply had to thank you for bringing such outstanding content with us. You are exceptionally talented and dedicated. Keep up the excellent work! 🌟👏👍
Perkirakan penghasilan setiap pengguna TikTok https://kalkulatortiktokmoney.com/
http://shop.radioscanner.ru/wa-content/pgs/top_reyting_mobilnuh_kazino__gde_luchshe_vsego_igrat_onlayn.html
http://medgorodok.ru/files/pages/?top_reyting_kazino_s_luchshimi_strategiyami_dlya_vuigrusha.html
Sweetie Fox filmleri: sweety fox – Sweetie Fox izle
Win big and live the dream at our Mexican casino site. With life-changing jackpots and thrilling tournaments, fortune favors the bold. gametwist casino gratis tu camino hacia el exito.
Perkirakan penghasilan setiap pengguna TikTok https://kalkulatortiktokmoney.com/
Immerse yourself in the excitement of online gambling at our Mexican online casino. With a wide range of games and thrilling bonuses, you’ll never want to play anywhere else. winpot casino te lo mereces.
Perkirakan penghasilan setiap pengguna TikTok penghasilan tiktok saya
Angela White video: Angela White video – Angela White izle
можно ли купить аттестат http://www.orik-attestats.com/ .
https://melbettr.top/
https://bwintr2.top/
apartusa365.com
Восстановление классического меню Пуск в Windows 10: простое руководство
Angela White filmleri: Abella Danger – Abella Danger
http://evaelfie.pro/# eva elfie izle
cottageindesign.com
Перетяжка мягкой мебели
https://brest.en.cx/Guestbook/Messages.aspx?page=1&fmode=gb&topic=333133&anchor .
https://angelawhite.pro/# Angela White izle
lana rhoades: lana rhoades video – lana rhoades filmleri
Ремонт квартир под ключ в Ростове: профессиональный подход к каждому проекту
melbet
Как выбрать правильный виртуальный сервер? ,
Почему они лучше обычного хостинга,
5 лучших операционных систем для виртуальных серверов ,
Как установить и настроить базу данных на виртуальном сервере ,
Сколько стоит аренда виртуального сервера ,
Расчет объема памяти и процессорных мощностей
хостинг под adult хостинг под adult .
https://o-tendencii.com/
bwin Türkiye
http://alcoself.ru/
http://tdgoodwin.ru/
melbet
https://evaelfie.pro/# eva elfie
https://hitech24.pro/
http://sovershenstvo-mysli.ru/
http://mpgsb.ru/
bwin giris
Discover Your Virtual Footprint with Ease, how do i find my ip address for my computer instantly at ipaddresswhois.net! Our user-friendly website is your go-to destination for swiftly uncovering your IP address. Whether you are troubleshooting connectivity issues, enhancing online security, or simply curious about your virtual footprint, we have got you covered.
Angela White video: Angela White – Angela White
buy malaria tablets doxycycline
Discover Your Virtual Footprint with Ease, how can you find your ip address instantly at ipaddresswhois.net! Our user-friendly website is your go-to destination for swiftly uncovering your IP address. Whether you are troubleshooting connectivity issues, enhancing online security, or simply curious about your virtual footprint, we have got you covered.
http://angelawhite.pro/# Angela White video
where can i get ashwagandha no prescription
http://sweetiefox.online/# sweety fox
eva elfie modeli: eva elfie izle – eva elfie izle
https://rusgo.ru/wp-content/pages/zarubezghnue_kazino_s_bezdepozitnum_bonusom__nachnite_igrat_s_preimushestvom.html
https://womens-forum.ru/viewtopic.php?f=59&t=5637&sid=56d2b7aef58656d7222b463e2ec40268
https://rentry.co/gtsdya86
купить аттестат за 9 https://www.russa-attestats.com .
https://www.google.rw/url?sa=t&url=https://melbet-malbet.com
Дайвинг для новичков на Пхукете от PHUKETDIVING.CENTER: идеальное место для первого погружения
http://sweetiefox.online/# Sweetie Fox
http://forumtr.0pk.me/viewtopic.php?id=5108#p11310
https://www.google.com.sl/url?sa=t&url=https://melbet-malbet.com
http://energiyacosmosa.winbb.ru/viewtopic.php?id=1272#p5246
Sweetie Fox: Sweetie Fox filmleri – swetie fox
https://o-tendencii.com/
https://angelawhite.pro/# Angela White filmleri
http://avilon.forumno.com/viewtopic.php?id=476#p805
https://o-tendencii.com/
ремонт холодильников атлант цена ремонт холодильников атлант на дому .
http://rybolov.webtalk.ru/viewtopic.php?id=1554#p24663
http://carstvo-sharov.ru/
https://gruzchikivesy.ru/
This is amazing, you’ve done an exceptional job this time! Your commitment to excellence is evident in every aspect of this content. I simply had to thank you for sharing such fantastic work with us. Your talent and dedication are truly admirable. Keep up the outstanding work! 🌟👏👍
https://sweetiefox.online/# Sweetie Fox izle
http://shop.radioscanner.ru/wa-content/pgs/reyting_top_28.html
https://vipka.0bb.ru/viewtopic.php?id=4027#p6243
монтаж кровли https://krovla1.ru/
Бесплатные игры в онлайн казино Беларусь: отличный способ развлечься без риска
лучшие онлайн казино беларуси лучшие онлайн казино беларуси .
https://lavka.pedolymp.ru/image/pgs/?reyting_top_onlayn_kazino__kazino__kotorum_doveryaut_igroki.html
https://forum.novosel.ru/frms24635.htm
Discover Your Virtual Footprint with Ease, view my ip instantly at ipaddresswhois.net! Our user-friendly website is your go-to destination for swiftly uncovering your IP address. Whether you are troubleshooting connectivity issues, enhancing online security, or simply curious about your virtual footprint, we have got you covered.
http://bpn.ru/i/inc/1xslots_casino___gde_azart_vstrechaet_udachu.html
Все о дизайне интерьера
http://trudolub.mybb.ru/viewtopic.php?id=963#p2399
https://m.21.by/pub/img/pages/index.php?888starz_zerkalo__obzor_i_shagi_po_obhodu_blokirovok.html
http://angelawhite.pro/# ?????? ????
http://www.medtronik.ru/images/pages/1xslots_oficialnuy_sayt__pokorenie_vershin_azarta.html
Medicament information for patients. Brand names.
prozac
Best about drug. Get now.
Sweetie Fox filmleri: Sweetie Fox modeli – swetie fox
fla-real-property.com
http://www.comtt.ru/plyr/pgs/luchshie_mobilnue_kazino_onlayn__igrayte_i_vuigruvayte_v_puti.html
texasnewsjobs.com
обшивка дома сайдингом https://krovla1.ru/
p10 pill prasugrel
http://evaelfie.pro/# eva elfie filmleri
buying avodart without rx
прайс лист на кровельные работы https://krovla1.ru/
buy semaglutide online pharmacy
https://cartagena-colombia-travel.activeboard.com/forum.spark
http://www.g3rmaica.de/elfredo/member.php?action=showprofile&user_id=19887
Экскурсии по Дагестану из Дербента: Исследуйте богатство культуры и природы региона
vitamine als nahrungserg?nzungsmittel https://www.wellnesspulse.de .
https://hitech24.pro/
http://evaelfie.pro/# eva elfie modeli
https://o-tendencii.com/
price of synthroid
prednisone for dogs
http://oboi-showroom.ru
инфографика Меркатор
Hello would you mind letting me know which hosting company you’re working with? I’ve loaded your blog in 3 different browsers and I must say this blog loads a lot quicker then most. Can you suggest a good hosting provider at a reasonable price? Thanks, I appreciate it!
http://mscln.ru
eva elfie filmleri: eva elfie filmleri – eva elfie filmleri
Внутри Москве купить диплом – это удобный и быстрый метод достать нужный бумага безо лишних хлопот. Разнообразие организаций продают услуги по производству и продаже дипломов различных образовательных учреждений – https://www.russkiy-diploms-srednee.com/. Выбор свидетельств в столице России большой, включая документация о академическом и нормальном учебе, свидетельства, свидетельства вузов и университетов. Основное достоинство – способность приобрести аттестат Гознака, обеспечивающий достоверность и высокое качество. Это гарантирует специальная защита от подделок и дает возможность применять свидетельство для различных нужд. Таким путем, приобретение диплома в городе Москве становится достоверным и оптимальным решением для таких, кто хочет достичь успеха в сфере работы.
https://gruzchikimeshki.ru/
https://wiki.gis-lab.info/images/pg/?otkroyte_dlya_sebya_mir_zarubezghnuh_kazino_s_bezdepozitnumi_bonusami.html
http://grib.rolebb.ru/viewtopic.php?id=764#p12674
https://gruzchikinochnoj.ru/
http://lanarhoades.fun/# lana rhodes
https://dolgiplus.ru
https://as-techcom.ru/images/pgs/index.php?preimushestva_igru_s_bezdepozitnumi_bonusami_v_onlayn_kazino.html
https://gruzchikiklub.ru/
http://kievautobaza.funbb.ru/viewtopic.php?id=3796#p11080
https://gruzchikiperevozchik.ru/
sweeti fox: Sweetie Fox filmleri – Sweetie Fox
http://meldog.3nx.ru/viewtopic.php?p=22815#22815
http://baysiderp.uk/index.php?/gallery/image/171-%D0%B7%D0%B0-%D1%81%D0%BA%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE-%D1%81%D0%B5%D0%B3%D0%BE%D0%B4%D0%BD%D1%8F-%D0%B2%D0%BE%D0%B7%D0%BC%D0%BE%D0%B6%D0%BD%D0%BE-%D0%B7%D0%B0%D0%BA%D0%B0%D0%B7%D0%B0%D1%82%D1%8C-%D1%85%D0%BE%D1%80%D0%BE%D1%88%D0%B5%D0%B3%D0%BE-%D0%BA%D0%B0%D1%87%D0%B5%D1%81%D1%82%D0%B2%D0%B0-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC/
https://worksale777.blogspot.com/2024/02/blog-post_73.html
http://web-lance.net/forums.php?m=posts&q=9928&n=last
обнал карт работа
Обнал карт: Как обеспечить безопасность от хакеров и обеспечить безопасность в сети
Современный общество высоких технологий предоставляет удобства онлайн-платежей и банковских операций, но с этим приходит и нарастающая угроза обнала карт. Обнал карт является процессом использования украденных или полученных незаконным образом кредитных карт для совершения финансовых транзакций с целью замаскировать их происхождение и заблокировать отслеживание.
Ключевые моменты для безопасности в сети и предотвращения обнала карт:
Защита личной информации:
Будьте внимательными при передаче личной информации онлайн. Никогда не делитесь номерами карт, защитными кодами и инными конфиденциальными данными на ненадежных сайтах.
Сильные пароли:
Используйте для своих банковских аккаунтов и кредитных карт надежные и уникальные пароли. Регулярно изменяйте пароли для усиления безопасности.
Мониторинг транзакций:
Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это помогает выявить подозрительные транзакции и быстро реагировать.
Антивирусная защита:
Устанавливайте и регулярно обновляйте антивирусное программное обеспечение. Такие программы помогут предотвратить вредоносные программы, которые могут быть использованы для похищения данных.
Бережное использование общественных сетей:
Остерегайтесь размещения чувствительной информации в социальных сетях. Эти данные могут быть использованы для несанкционированного доступа к вашему аккаунту и дальнейшего обнала карт.
Уведомление банка:
Если вы обнаружили сомнительные транзакции или потерю карты, свяжитесь с банком незамедлительно для блокировки карты и предотвращения финансовых потерь.
Образование и обучение:
Следите за новыми методами мошенничества и постоянно обновляйте свои знания, как избегать подобных атак. Современные мошенники постоянно совершенствуют свои методы, и ваше понимание может стать ключевым для защиты.
В завершение, соблюдение основных мер безопасности в интернете и постоянное обновление знаний помогут вам минимизировать риск стать жертвой обнала карт на месте работы и в ежедневной практике. Помните, что ваша финансовая безопасность в ваших руках, и проактивные меры могут обеспечить безопасность ваших онлайн-платежей и операций.
http://stroyk.bestbb.ru/viewtopic.php?id=284#p375
обнал карт форум
Обнал карт: Как гарантировать защиту от мошенников и обеспечить защиту в сети
Современный общество высоких технологий предоставляет возможности онлайн-платежей и банковских операций, но с этим приходит и повышающаяся опасность обнала карт. Обнал карт является процессом использования украденных или незаконно полученных кредитных карт для совершения финансовых транзакций с целью маскировать их источник и предотвратить отслеживание.
Ключевые моменты для безопасности в сети и предотвращения обнала карт:
Защита личной информации:
Будьте внимательными при передаче личной информации онлайн. Никогда не делитесь картовыми номерами, кодами безопасности и инными конфиденциальными данными на непроверенных сайтах.
Сильные пароли:
Используйте для своих банковских аккаунтов и кредитных карт надежные и уникальные пароли. Регулярно изменяйте пароли для увеличения уровня безопасности.
Мониторинг транзакций:
Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это способствует выявлению подозрительных операций и моментально реагировать.
Антивирусная защита:
Утанавливайте и актуализируйте антивирусное программное обеспечение. Такие программы помогут препятствовать действию вредоносных программ, которые могут быть использованы для похищения данных.
Бережное использование общественных сетей:
Будьте осторожными при размещении чувствительной информации в социальных сетях. Эти данные могут быть использованы для взлома к вашему аккаунту и последующего мошенничества.
Уведомление банка:
Если вы обнаружили сомнительные транзакции или похищение карты, свяжитесь с банком сразу для блокировки карты и предотвращения финансовых потерь.
Образование и обучение:
Следите за новыми методами мошенничества и постоянно обновляйте свои знания, как противостоять подобным атакам. Современные мошенники постоянно усовершенствуют свои приемы, и ваше понимание может стать определяющим для защиты
https://angelawhite.pro/# ?????? ????
фальшивые 5000 купитьФальшивые купюры 5000 рублей: Риск для экономики и граждан
Фальшивые купюры всегда были серьезной угрозой для финансовой стабильности общества. В последние годы одним из основных объектов манипуляций стали банкноты номиналом 5000 рублей. Эти поддельные деньги представляют собой серьезную опасность для экономики и финансовой безопасности граждан. Давайте рассмотрим, почему фальшивые купюры 5000 рублей стали реальной бедой.
Трудность выявления.
Купюры 5000 рублей являются крупнейшими по номиналу, что делает их исключительно привлекательными для фальшивомонетчиков. Превосходно проработанные подделки могут быть сложно выявить даже профессионалам в сфере финансов. Современные технологии позволяют создавать качественные копии с использованием передовых методов печати и защитных элементов.
Опасность для бизнеса.
Фальшивые 5000 рублей могут привести к серьезным финансовым убыткам для предпринимателей и компаний. Бизнесы, принимающие наличные средства, становятся подвергаются риску принять фальшивую купюру, что в конечном итоге может снизить прибыль и повлечь за собой правовые последствия.
Рост инфляции.
Фальшивые деньги увеличивают количество в обращении, что в свою очередь может привести к инфляции. Рост количества поддельных купюр создает дополнительный денежный объем, не обеспеченный реальными товарами и услугами. Это может существенно подорвать доверие к национальной валюте и стимулировать рост цен.
Пагуба для доверия к финансовой системе.
Фальшивые деньги вызывают мизерию к финансовой системе в целом. Когда люди сталкиваются с риском получить фальшивые купюры при каждой сделке, они становятся более склонными избегать использования наличных средств, что может привести к обострению проблем, связанных с электронными платежами и банковскими системами.
Защитные меры и образование.
Для борьбы с распространению фальшивых денег необходимо внедрять более продвинутые защитные меры на банкнотах и активно проводить педагогическую работу среди населения. Гражданам нужно быть более внимательными при приеме наличных средств и обучаться основам распознавания поддельных купюр.
В заключение:
Фальшивые купюры 5000 рублей представляют серьезную угрозу для финансовой стабильности и безопасности граждан. Необходимо активно внедрять новые технологии защиты и проводить информационные кампании, чтобы общество было лучше осведомлено о методах распознавания и защиты от фальшивых денег. Только совместные усилия банков, правоохранительных органов и общества в целом позволят минимизировать угрозу подделок и обеспечить стабильность финансовой системы.
Find the right viagra without doctor prescription solution for you and experience the difference it can make.
According to the experience of Reputation House agency, reviews in a negative tone can be left not only by dissatisfied customers reputation house serm
купить фальшивые деньги
Изготовление и приобретение поддельных денег: опасное мероприятие
Купить фальшивые деньги может привлекаться привлекательным вариантом для некоторых людей, но в реальности это действие несет серьезные последствия и нарушает основы экономической стабильности. В данной статье мы рассмотрим вредные аспекты покупки поддельной валюты и почему это является опасным поступком.
Противозаконность.
Основное и самое значимое, что следует отметить – это полная неправомерность создания и использования фальшивых денег. Такие манипуляции противоречат законам большинства стран, и их штрафы может быть весьма строгим. Приобретение поддельной валюты влечет за собой угрозу уголовного преследования, штрафов и даже тюремного заключения.
Экономические последствия.
Фальшивые деньги негативно влияют на экономику в целом. Когда в обращение поступает фальшивая валюта, это вызывает дисбаланс и ухудшает доверие к национальной валюте. Компании и граждане становятся более подозрительными при проведении финансовых сделок, что порождает к ухудшению бизнес-климата и мешает нормальному функционированию рынка.
Потенциальная угроза финансовой стабильности.
Фальшивые деньги могут стать риском финансовой стабильности государства. Когда в обращение поступает большое количество поддельной валюты, центральные банки вынуждены принимать дополнительные меры для поддержания финансовой системы. Это может включать в себя растущие процентных ставок, что, в свою очередь, вредно сказывается на экономике и финансовых рынках.
Угрозы для честных граждан и предприятий.
Люди и компании, неосознанно принимающие фальшивые деньги в в роли оплаты, становятся жертвами преступных схем. Подобные ситуации могут породить к финансовым убыткам и утрате доверия к своим деловым партнерам.
Привлечение криминальных группировок.
Закупка фальшивых денег часто связана с криминальными группировками и организованным преступлением. Вовлечение в такие сети может сопровождаться серьезными последствиями для личной безопасности и даже угрожать жизни.
В заключение, покупка фальшивых денег – это не только неправомерное поступок, но и поступок, способный причинить ущерб экономике и обществу в целом. Рекомендуется избегать подобных действий и сосредотачиваться на легальных, ответственных методах обращения с финансами
http://mazda-demio.ru/forums/index.php?autocom=gallery&req=si&img=3593
https://web.stanford.edu/group/spanlab/cgi-bin/wiki/index.php?title=%D0%9F%D0%BE%D1%87%D0%B5%D0%BC%D1%83_%D0%B2%D0%B0%D0%B6%D0%BD%D0%BE_%D0%B2%D1%8B%D1%81%D1%88%D0%B5%D0%B5_%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%3F
http://forum.l2gludin.ru/index.php?/gallery/image/115-%D0%B7%D0%B0-%D1%81%D0%BA%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE-%D0%B8%D0%BC%D0%B5%D0%BD%D0%BD%D0%BE-%D1%81%D0%B5%D0%B3%D0%BE%D0%B4%D0%BD%D1%8F-%D0%BC%D0%BE%D0%B6%D0%BD%D0%BE-%D0%B1%D1%83%D0%B4%D0%B5%D1%82-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%BA%D0%B0%D1%87%D0%B5%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D1%8B%D0%B9-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC/
https://gruzchikikar.ru/
https://forumhorochego.rolka.me/viewtopic.php?id=963#p2113
http://brmtit.ru/sveden/common
https://love.boltun.su/viewtopic.php?id=7055#p11853
http://forums.wolflair.com/member.php?u=110931
https://gruzchikigastarbajter.ru/
http://www.katuganka.in.ua/forum/index.php?id=1062335
https://speterburg.rusff.me/viewtopic.php?id=8661#p312559
https://gruzchikiperenosit.ru/
ph sweetie fox: sweetie fox full – ph sweetie fox
https://gruzchikiestakada.ru/
http://wayseodirectory.com/how-expensive-are-google-internet-marketing-services-for-a-small-business/
https://gruzchikimore.ru/
Discover why generic viagra is trusted by millions worldwide. Find your perfect option here.
Pills information leaflet. What side effects?
cephalexin
Best about medication. Read now.
https://gruzchikiustalost.ru/
how to get cheap abilify without a prescription
займы подача заявки https://www.topruscredit11.ru .
Company managers sometimes complain about high staff turnover, the lack of good specialists, and the low professionalism of applicants reputation house employee reviews
http://pensionreform.ru/80147
https://felomena.com/wp-includes/inc/?igrayte_v_kazino_s_koshelkom_piastriks__udobstvo_i_skorost.html
https://gruzchikikuzov.ru/
https://lanarhoades.pro/# lana rhoades full video
Explore the benefits of online viagra and take back control of your sexual health.
1881 hoki
alanews24.com
https://gruzchikiperevozka.ru/
mia malkova new video: mia malkova hd – mia malkova photos
https://stroylegko.com/prochee/kupit-diplomy-v-lipecke-i-drugih-gorodah-stalo-gorazdo-proshche
http://vdoroge.mybb.ru/viewtopic.php?id=485#p4670
If a user encounters negativity on the first page of search results, he will be wary of the company and is unlikely to become its client reputation reviews
texas-news.com
https://motorcycle-reviews34433.dreamyblogs.com/22331368/the-2-minute-rule-for-marketing
http://ccollege.rusff.me/viewtopic.php?id=670#p1076
Онлайн казино в Беларуси с мобильной версией: играйте в любое время и в любом месте
онлайн казино казино беларусь .
https://rubberrollermanufacturers05041.bloggosite.com/28095776/the-2-minute-rule-for-marketing
https://cleverlend.ru/topic-t5094.html
обнал карт купить
Умение осмысливать сущности и рисков привязанных с легализацией кредитных карт способствует людям предотвращать атак и обеспечивать защиту свои финансовые ресурсы. Обнал (отмывание) кредитных карт — это процесс использования украденных или неправомерно приобретенных кредитных карт для осуществления финансовых транзакций с целью сокрыть их происхождения и пресечь отслеживание.
Вот некоторые из способов, которые могут содействовать в уклонении от обнала кредитных карт:
Охрана личной информации: Будьте осторожными в связи предоставления личной информации, особенно онлайн. Избегайте предоставления номеров карт, кодов безопасности и других конфиденциальных данных на сомнительных сайтах.
Сильные пароли: Используйте мощные и уникальные пароли для своих банковских аккаунтов и кредитных карт. Регулярно изменяйте пароли.
Контроль транзакций: Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это позволит своевременно обнаруживать подозрительных транзакций.
Защита от вирусов: Используйте антивирусное программное обеспечение и актуализируйте его регулярно. Это поможет защитить от вредоносные программы, которые могут быть использованы для кражи данных.
Осмотрительное поведение в социальных медиа: Будьте осторожными в социальных сетях, избегайте опубликования чувствительной информации, которая может быть использована для взлома вашего аккаунта.
Быстрое сообщение банку: Если вы заметили какие-либо подозрительные операции или утерю карты, сразу свяжитесь с вашим банком для блокировки карты.
Обучение: Будьте внимательными к новым методам мошенничества и обучайтесь тому, как предотвращать их.
Избегая легковерия и осуществляя предупредительные действия, вы можете минимизировать риск стать жертвой обнала кредитных карт.
I like what you guys are up too. Such smart work and reporting! Carry on the superb works guys I have incorporated you guys to my blogroll. I think it will improve the value of my site :).
https://frsvo.ru/forum/profile.php?id=5801
http://oldbird.mybb.ru/viewtopic.php?id=737#p15514
Unsere Website befasst sich auch mit den moglichen Nebenwirkungen von Xenical. Wahrend viele Menschen das Medikament gut vertragen, kann es bei einigen zu gastrointestinalen Nebenwirkungen kommen, die auf die unverdauten Fette zuruckzufuhren sind, die das Verdauungssystem passieren. Wir geben Tipps, wie man diese Nebenwirkungen minimieren kann und wann es wichtig ist, einen Arzt aufzusuchen.
Daruber hinaus bieten wir Erfahrungsberichte und Erfolgsgeschichten von Personen, die Xenical als Teil ihrer Gewichtsabnahme verwendet haben. Diese Erfahrungen aus dem wirklichen Leben konnen denjenigen, die die Einnahme von Xenical in Erwagung ziehen oder bereits anwenden, wertvolle Einblicke und Motivation bieten.
Zusammenfassend lasst sich sagen, dass unsere Website eine hilfreiche Plattform fur alle ist, die mehr uber Xenical (Orlistat) und seine Rolle beim Gewichtsmanagement erfahren mochten. Unser Ziel ist es, umfassende, genaue und hilfreiche Informationen zur Verfugung zu stellen, die Ihnen dabei helfen, eine fundierte Entscheidung uber Ihren Weg zur Gewichtsabnahme zu treffen. Besuchen Sie uns unter https://gezondafvallen.net fur weitere Informationen und Anleitungen zum Abnehmen mit Xenical.
https://buyammoonlineusa99876.theideasblog.com/22336315/5-essential-elements-for-marketing
rikvip
Medicament prescribing information. What side effects can this medication cause?
doxycycline
Some information about medication. Read here.
https://dallastuvut.actoblog.com/22647899/marketing-things-to-know-before-you-buy
Medication information. Effects of Drug Abuse.
proscar
All about medicament. Read information here.
sweetie fox full: sweetie fox new – sweetie fox video
где купить фальшивые деньги
Фальшивые деньги: угроза для финансовой системы и социума
Введение:
Фальшивомонетничество – нарушение, оставшееся актуальным на продолжительностью многих веков. Производство и распространение в обращение фальшивых денег представляют серьезную опасность не только для финансовой системы, но и для общественной стабильности. В данной статье мы рассмотрим размеры проблемы, способы борьбы с подделкой денег и последствия для общества.
История фальшивых денег:
Фальшивые деньги существуют с момента появления самой идеи денег. В древности подделывались металлические монеты, а в современном мире преступники активно используют передовые технологии для фальсификации банкнот. Развитие цифровых технологий также открыло дополнительные способы для создания цифровых вариантов валюты.
Масштабы проблемы:
Ненастоящая валюта создают опасность для стабильности финансовой системы. Банки, предприятия и даже обычные граждане могут стать жертвами мошенничества. Увеличение объемов фальшивых денег может привести к потере покупательной способности и даже к финансовым кризисам.
Современные методы фальсификации:
С прогрессом техники фальсификация стала более сложной и усложненной. Преступники используют современные технические средства, специализированные принтеры, и даже искусственный интеллект для создания невозможно отличить поддельные копии от настоящих денег.
Борьба с фальшивомонетничеством:
Государства и центральные банки активно внедряют новые меры для предотвращения фальшивомонетничества. Это включает в себя использование современных защитных элементов на банкнотах, просвещение населения способам определения поддельных денег, а также взаимодействие с органами правопорядка для выявления и пресечения преступных сетей.
Последствия для социума:
Поддельные средства несут не только экономические, но и социальные результаты. Жители и бизнесы теряют доверие к экономическому устройству, а борьба с преступностью требует значительных ресурсов, которые могли бы быть направлены на более положительные цели.
Заключение:
Поддельные средства – важный вопрос, требующая внимания и совместных усилий граждан, правоохранительных органов и учреждений финансов. Только путем активной противодействия с этим преступлением можно гарантировать устойчивость экономики и сохранить доверие к валютной системе
http://www.mybaltika.info/ru/blogs/587/4978/
Опасность подпольных точек: Места продажи фальшивых купюр”
Заголовок: Риски приобретения в подпольных местах: Места продажи поддельных денег
Введение:
Разговор об опасности подпольных точек, занимающихся продажей поддельных денег, становится всё более актуальным в современном обществе. Эти места, предоставляя доступ к поддельным финансовым средствам, представляют серьезную опасность для экономической стабильности и безопасности граждан.
Легкость доступа:
Одной из проблем подпольных точек является легкость доступа к поддельным деньгам. На темных улицах или в скрытых интернет-пространствах, эти места становятся площадкой для тех, кто ищет возможность обмануть систему.
Угроза финансовой системе:
Продажа поддельных купюр в таких местах создает реальную угрозу для финансовой системы. Введение поддельных средств в обращение может привести к инфляции, понижению доверия к национальной валюте и даже к финансовым кризисам.
Мошенничество и преступность:
Подпольные точки, предлагающие поддельные средства, являются очагами мошенничества и преступной деятельности. Отсутствие контроля и законного регулирования в этих местах обеспечивает благоприятные условия для криминальных элементов.
Угроза для бизнеса и обычных граждан:
Как бизнесы, так и обычные граждане становятся потенциальными жертвами мошенничества, когда используют фальшивые купюры, приобретенные в подпольных точках. Это ведет к утрате доверия и серьезным финансовым потерям.
Последствия для экономики:
Вмешательство нелегальных торговых мест в экономику оказывает отрицательное воздействие. Нарушение стабильности финансовой системы и создание дополнительных трудностей для правоохранительных органов являются лишь частью последствий для общества.
Заключение:
Продажа поддельных средств в подпольных точках представляет собой серьезную угрозу для общества в целом. Необходимо ужесточение законодательства и усиление контроля, чтобы противостоять этому злу и обеспечить безопасность экономической среды. Развитие сотрудничества между государственными органами, бизнес-сообществом и обществом в целом является ключевым моментом в предотвращении негативных последствий деятельности подобных точек.
Medicament prescribing information. Drug Class.
finasteride
All information about drug. Read information now.
магазин фальшивых денег купить
Темные закоулки сети: теневой мир продажи фальшивых купюр”
Введение:
Поддельные средства стали неотъемлемой частью теневого мира, где места продаж – это источники серьезных угроз для экономики и общества. В данной статье мы обратим внимание на локации, где процветает подпольная торговля фальшивыми купюрами, включая темные уголки интернета.
Теневые интернет-магазины:
С прогрессом технологий и распространением онлайн-торговли, точки оборота поддельных банкнот стали активно функционировать в засекреченных местах интернета. Темные веб-сайты и форумы предоставляют возможность анонимно приобрести фальшивые деньги, создавая тем самым серьезную угрозу для экономики.
Опасные последствия для общества:
Точки оборота фальшивых купюр на темных интернет-ресурсах несут в себе не только угрозу для финансовой стабильности, но и для простых людей. Покупка поддельных денег влечет за собой риски: от юридических преследований до утраты доверия со стороны сообщества.
Передовые технологии подделки:
На скрытых веб-площадках активно используются новейшие технологии для создания качественных фальшивок. От печатающих устройств, способных воспроизводить защитные элементы, до использования криптовалютных платежей для обеспечения невидимости покупок – все это создает среду, в которой трудно выявить и пресечь незаконную торговлю.
Необходимость ужесточения мер борьбы:
Противостояние с подпольной торговлей фальшивых купюр требует целостного решения. Важно ужесточить нормативные акты и разработать эффективные меры для выявления и блокировки скрытых онлайн-магазинов. Также невероятно важно поднимать уровень осведомленности общества относительно опасностей подобных практик.
Заключение:
Места продаж поддельных денег на скрытых местах интернета представляют собой значительную опасность для устойчивости экономики и общественной безопасности. В условиях расцветающего цифрового мира важно сосредотачивать усилия на противостоянии с подобными действиями, чтобы защитить интересы общества и сохранить веру к финансовой системе
https://espassport.pro/
sohbet.net sohbet
https://rubber-roller-manufacture55543.blogsidea.com/28143261/marketing-secrets
Medicine prescribing information. Long-Term Effects.
propecia
Actual about medicament. Read information here.
okeysitesi.net
Medication information for patients. Brand names.
rx cialis super active
Some what you want to know about meds. Get now.
Фальшивые рубли, как правило, копируют с целью мошенничества и незаконного получения прибыли. Злоумышленники занимаются фальсификацией российских рублей, изготавливая поддельные банкноты различных номиналов. В основном, фальсифицируют банкноты с более высокими номиналами, вроде 1 000 и 5 000 рублей, поскольку это позволяет им зарабатывать крупные суммы при уменьшенном числе фальшивых денег.
Технология фальсификации рублей включает в себя использование высокотехнологичного оборудования, специализированных печатающих устройств и особо подготовленных материалов. Шулеры стремятся максимально детально воспроизвести защитные элементы, водяные знаки, металлическую защиту, микроскопический текст и прочие характеристики, чтобы замедлить определение поддельных купюр.
Фальшивые рубли регулярно вносятся в оборот через торговые площадки, банки или прочие учреждения, где они могут быть незаметно скрыты среди реальных денежных средств. Это возникает серьезные проблемы для экономической системы, так как фальшивые деньги могут вызывать потерям как для банков, так и для граждан.
Необходимо подчеркнуть, что владение и использование фальшивых денег являются уголовными преступлениями и могут быть наказаны в соответствии с нормативными актами Российской Федерации. Власти активно борются с такими преступлениями, предпринимая действия по обнаружению и прекращению деятельности преступных групп, занимающихся фальсификацией российской валюты
Фальшивые рубли, обычно, подделывают с целью обмана и незаконного обогащения. Злоумышленники занимаются клонированием российских рублей, создавая поддельные банкноты различных номиналов. В основном, воспроизводят банкноты с более высокими номиналами, вроде 1 000 и 5 000 рублей, поскольку это позволяет им добывать крупные суммы при уменьшенном числе фальшивых денег.
Технология подделки рублей включает в себя использование высокотехнологичного оборудования, специализированных принтеров и особо подготовленных материалов. Злоумышленники стремятся максимально детально воспроизвести защитные элементы, водяные знаки безопасности, металлическую защитную полосу, микротекст и другие характеристики, чтобы препятствовать определение поддельных купюр.
Поддельные денежные средства периодически вносятся в оборот через торговые площадки, банки или другие организации, где они могут быть незаметно скрыты среди настоящих денег. Это возникает серьезные проблемы для финансовой системы, так как фальшивые деньги могут привести к потерям как для банков, так и для населения.
Столь же важно подчеркнуть, что имение и применение поддельных средств считаются уголовными преступлениями и могут быть наказаны в соответствии с нормативными актами Российской Федерации. Власти энергично противостоят с такими преступлениями, предпринимая меры по выявлению и пресечению деятельности преступных групп, занимающихся фальсификацией российской валюты
Medicine information for patients. What side effects?
motrin
Best news about medicines. Get information here.
https://promokodbar.ru/
Meds information. Generic Name.
lisinopril buy
Actual information about medicines. Get information here.
Все о дизайне интерьера
cost cheap doxycycline tablets
http://sweetiefox.pro/# fox sweetie
Очень советую услуги 3D печати http://forum-novostroiki.ru/members/taskimply2.15991/
Pills information. Cautions.
neurontin generic
Everything trends of meds. Read now.
sweetie fox full video: ph sweetie fox – sweetie fox cosplay
https://hospital.0370.ru/uploads/pags/?prisoedinyaytes_k_mirovum_igram_v_zarubezghnuh_kazino_onlayn.html
It may seem that the best option is to make sure that job seekers encounter only positive information about the company reputation house reviews
http://bpn.ru/i/inc/top_7355.html
Medicament information sheet. Cautions.
nolvadex buy
All what you want to know about medication. Read information here.
https://gruzchikirabotat.ru/
https://blog.libero.it/wp/interesting/2024/02/22/%d0%bf%d0%be%d1%81%d1%82%d1%83%d0%bf%d0%bb%d0%b5%d0%bd%d0%b8%d0%b5-%d0%b2-%d1%83%d0%bd%d0%b8%d0%b2%d0%b5%d1%80%d1%81%d0%b8%d1%82%d0%b5%d1%82-%d0%ba%d0%b0%d0%ba-%d0%b4%d0%b5%d0%bb%d0%b0%d1%82%d1%8c/
login hoki1881
dublinnews365.com
https://liveinternet.ru/users/mironowvlac/profile
https://community.wongcw.com/blogs/686940/%D0%A6%D0%B5%D0%BD%D0%B0-%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F-%D0%B2-2024-%D0%B3%D0%BE%D0%B4%D1%83-%D0%9E%D0%B1%D1%83%D1%87%D0%B5%D0%BD%D0%B8%D0%B5-%D0%B2-%D0%BA%D0%BE%D0%BB%D0%BB%D0%B5%D0%B4%D0%B6%D0%B0%D1%85-%D0%B4%D0%BB%D1%8F-%D1%80%D0%BE%D1%81%D1%81%D0%B8%D1%8F%D0%BD
Incredible, you’ve knocked it out of the park this time! Your dedication and creativity are truly admirable of this content. I simply had to thank you for sharing such amazing work with us. You are exceptionally talented and dedicated. Keep up the awesome work! 🌟👏👍
https://telegra.ph/6-Problem-Rossijskogo-Obrazovaniya-v-2024-godu-Analiz-i-Puti-Resheniya-02-20
https://salda.ws/f/topic.php?f=5&t=66397
mia malkova full video: mia malkova hd – mia malkova videos
https://www.mses-expert.ru/
https://promokodbar.ru/
https://peda.net/p/jackslow/%D0%BF%D1%83%D1%82%D1%8C-%D0%BA-%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8E-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BA%D1%83%D0%BF%D0%BB%D0%B5%D0%BD
оборудование актового зала в школе oborudovanie-aktovogo-zala11.ru .
http://www.mrkineshma.ru/support/forum/view_profile.php?UID=218278
https://www.as7abe.com/wall/blogs/post/35010
На территории столице России купить аттестат – это комфортный и оперативный способ получить нужный бумага без дополнительных трудностей. Разнообразие фирм продают помощь по созданию и торговле дипломов различных учебных заведений – http://www.orik-diploms-srednee.com. Выбор дипломов в городе Москве большой, включая документы о высшем и нормальном профессиональной подготовке, аттестаты, свидетельства колледжей и вузов. Основное достоинство – возможность достать аттестат подлинный документ, гарантирующий истинность и высокое качество. Это обеспечивает специальная защита от подделки и предоставляет возможность воспользоваться аттестат для различных целей. Таким путем, приобретение диплома в городе Москве становится безопасным и оптимальным выбором для тех, кто желает достичь процветанию в сфере работы.
https://promokodbar.ru/
娛樂城首儲
初次接觸線上娛樂城的玩家一定對選擇哪間娛樂城有障礙,首要條件肯定是評價良好的娛樂城,其次才是哪間娛樂城優惠最誘人,娛樂城體驗金多少、娛樂城首儲一倍可以拿多少等等…本篇文章會告訴你娛樂城優惠怎麼挑,首儲該注意什麼。
娛樂城首儲該注意什麼?
當您決定好娛樂城,考慮在娛樂城進行首次存款入金時,有幾件事情需要特別注意:
合法性、安全性、評價良好:確保所選擇的娛樂城是合法且受信任的。檢查其是否擁有有效的賭博牌照,以及是否採用加密技術來保護您的個人信息和交易。
首儲優惠與流水:許多娛樂城會為首次存款提供吸引人的獎勵,但相對的流水可能也會很高。
存款入金方式:查看可用的支付選項,是否適合自己,例如:USDT、超商儲值、銀行ATM轉帳等等。
提款出金方式:瞭解最低提款限制,綁訂多少流水才可以領出。
24小時客服:最好是有24小時客服,發生問題時馬上有人可以處理。
https://steemit.com/education/@samsomresss/problemy-sovremennoi-sistemy-obrazovaniya-riski-i-innovacii-v-2024-godu
В городе Москве приобрести аттестат – это удобный и быстрый вариант завершить нужный бумага безо избыточных проблем. Разнообразие компаний продают сервисы по производству и реализации дипломов разнообразных учебных заведений – russa-diploms-srednee.com. Разнообразие свидетельств в городе Москве большой, включая бумаги о высшем уровне и среднем профессиональной подготовке, свидетельства, свидетельства вузов и вузов. Главное преимущество – способность достать свидетельство подлинный документ, подтверждающий подлинность и высокое качество. Это обеспечивает уникальная защита против фальсификаций и дает возможность применять диплом для различных нужд. Таким образом, покупка аттестата в городе Москве становится достоверным и экономичным решением для данных, кто стремится к процветанию в сфере работы.
https://clicky.buzz/index.php?do=/public/blog/view/id_119683/title_/
rikvip
http://www.azmepakistan.tv/blogs/4979/59929/kak-izvlec-maksimum-pol-zy-iz-uceby-v-9-klasse-v-2024-godu
娛樂城首儲
初次接觸線上娛樂城的玩家一定對選擇哪間娛樂城有障礙,首要條件肯定是評價良好的娛樂城,其次才是哪間娛樂城優惠最誘人,娛樂城體驗金多少、娛樂城首儲一倍可以拿多少等等…本篇文章會告訴你娛樂城優惠怎麼挑,首儲該注意什麼。
娛樂城首儲該注意什麼?
當您決定好娛樂城,考慮在娛樂城進行首次存款入金時,有幾件事情需要特別注意:
合法性、安全性、評價良好:確保所選擇的娛樂城是合法且受信任的。檢查其是否擁有有效的賭博牌照,以及是否採用加密技術來保護您的個人信息和交易。
首儲優惠與流水:許多娛樂城會為首次存款提供吸引人的獎勵,但相對的流水可能也會很高。
存款入金方式:查看可用的支付選項,是否適合自己,例如:USDT、超商儲值、銀行ATM轉帳等等。
提款出金方式:瞭解最低提款限制,綁訂多少流水才可以領出。
24小時客服:最好是有24小時客服,發生問題時馬上有人可以處理。
娛樂城首儲
初次接觸線上娛樂城的玩家一定對選擇哪間娛樂城有障礙,首要條件肯定是評價良好的娛樂城,其次才是哪間娛樂城優惠最誘人,娛樂城體驗金多少、娛樂城首儲一倍可以拿多少等等…本篇文章會告訴你娛樂城優惠怎麼挑,首儲該注意什麼。
娛樂城首儲該注意什麼?
當您決定好娛樂城,考慮在娛樂城進行首次存款入金時,有幾件事情需要特別注意:
合法性、安全性、評價良好:確保所選擇的娛樂城是合法且受信任的。檢查其是否擁有有效的賭博牌照,以及是否採用加密技術來保護您的個人信息和交易。
首儲優惠與流水:許多娛樂城會為首次存款提供吸引人的獎勵,但相對的流水可能也會很高。
存款入金方式:查看可用的支付選項,是否適合自己,例如:USDT、超商儲值、銀行ATM轉帳等等。
提款出金方式:瞭解最低提款限制,綁訂多少流水才可以領出。
24小時客服:最好是有24小時客服,發生問題時馬上有人可以處理。
lana rhoades unleashed: lana rhoades pics – lana rhoades hot
DNA
เว็บ DNABET: สู่ ประสบการณ์ การเล่น ที่ไม่เป็นไปตาม ที่คุณ เคย เจอ!
DNABET ยัง เป็น เลือกที่หนึ่ง สำหรับ แฟน การเดิมพัน ออนไลน์ ในประเทศไทย ในปี 2024.
ไม่จำเป็นต้อง ใช้เวลา ในการเลือกว่าจะ แข่ง DNABET เพราะที่นี่คุณ ไม่ต้อง กังวลว่าจะ ได้ หรือไม่เหรอ!
DNABET มี ราคาจ่าย ทุกราคา หวย สูงมาก ตั้งแต่เริ่มต้นที่ 900 บาท ขึ้นไป เมื่อ ท่าน ถูกรางวัล ได้รับ รางวัลมากมาย กว่า เว็บ ๆ ที่คุณ เคยเล่น.
นอกจากนี้ DNABET ยัง มีความหลากหลาย หวย ที่คุณสามารถทำการเลือก มากมายถึง 20 หวย ทั่วโลก ทำให้ เลือก ตามใจต้องการ ได้อย่างหลากหลาย.
ไม่ว่าจะเป็น หวยรัฐบาลไทย หุ้น หวยยี่กี หวยฮานอย หวยลาว และ ลอตเตอรี่ มีราคา เพียง 80 บาท.
ทาง DNABET มั่นคง ในการเงิน โดยที่ ได้รับ เปลี่ยนชื่อจาก ชันเจน เป็น DNABET เพื่อ เสริมฐานลูกค้า และ ปรับปรุงระบบให้ สะดวกสบายมาก ขึ้นไป.
นอกจากนี้ DNABET ยังมีโปรโมชั่น หวย ประจำเดือนที่สะสมยอดแทงแล้วได้รับรางวัล หลายรายการ เช่น โปรโมชั่น สมาชิกใหม่ ท่านสมัคร ในวันนี้ จะได้รับ โบนัสเพิ่ม 500 บาท หรือ ไม่ต้องจ่าย เงิน.
นอกจากนี้ DNABET ยังมีโปรโมชั่น ประจำเดือนที่ ท่านมีความมั่นใจ และ DNABET การเดิมพัน หวย ของท่านเอง พร้อม รางวัล และ โปรโมชัน ที่ มาก ที่สุดในประเทศไทย ในปี 2024.
อย่า ปล่อย โอกาสที่ดีนี้ ไป มาเป็นส่วนหนึ่งของ DNABET และ เพลิดเพลินกับ ประสบการณ์การเล่น การเดิมพันที่ไม่เหมือนใคร ทุกท่าน มีโอกาสจะ เป็นเศรษฐี ได้รับ เพียง แค่ท่าน เลือก DNABET เว็บแทงหวย ออนไลน์ ที่ และ มีจำนวนสมาชิกมากที่สุด ในประเทศไทย!
https://aspiringexecutives.mn.co/posts/51240791
Декоративная краска для гостиной: преображение вашего интерьера
Medicament information for patients. Effects of Drug Abuse.
prozac otc
All news about medicines. Read here.
https://abia.ru/js/pgs/luchshie_layv_kazino__neprevzoydennuy_igrovoy_oput.html
Drugs information sheet. What side effects?
clomid without prescription
All news about medicament. Get here.
http://www.comtt.ru/plyr/pgs/bezdepozitnue_bonusu_v_spinbetter_casino__poluchite_i_vuigruvayte.html
Drug information leaflet. Effects of Drug Abuse.
how to buy tadacip
Everything what you want to know about pills. Get now.
Porno film izle ❤️ bedava seks filmi seyret ❤️ götten sikiş, pornu ⭐ mobil porno
https://era-food.ru
Топ-менеджер Вячеслав Константинович Николаев является специалистом в телекоммуникационном бизнесе и в области информационных технологий
http://gruziv.ru/
Drugs prescribing information. Cautions.
zithromax without prescription
Best trends of meds. Get here.
http://ros-istor.ru/
Medicament information for patients. Effects of Drug Abuse.
nexium buy
Best news about drug. Read here.
lana rhoades solo: lana rhoades full video – lana rhoades boyfriend
eva elfie full video: eva elfie videos – eva elfie new videos
Drugs information leaflet. Short-Term Effects.
bactrim buy
Actual news about meds. Read information here.
http://www.rrsclub.ru/member.php?tab=visitor_messaging&u=1164&page=19
глаз бога
Pills information sheet. Drug Class.
zenegra medication
Everything about medication. Get information here.
https://remingtonoqrpp.blogocial.com/the-5-second-trick-for-marketing-57603979
Meds information. Short-Term Effects.
buy generic neurontin
Actual trends of drug. Get here.
глаз бога
https://era-food.ru/
http://forum.aionclassic.net/member.php?u=12155
Meds information for patients. Brand names.
tadacip without prescription
Some news about medicine. Read information here.
cost of benemid without rx
http://sweetiefox.pro/# sweetie fox
Drug information sheet. What side effects can this medication cause?
buying promethazine
Some trends of medication. Get here.
Вячеслав Константинович Николаев https://nicolaev-vyacheslav-konstantinovich.ru/ .
era food
История строительства Кнаубом Андреем НПЗ Томскнефтерепеработка, планов на модернизацию и совершенствование корпоративной культуры. Привлечение молодых специалистов, улучшение условий труда всегда были в приоритете у бизнесмена кнауб андрей артурович бизнесмен
Medicines prescribing information. Drug Class.
levitra
All about medicines. Get now.
login hoki1881
can i buy generic periactin prices
Pills information for patients. Drug Class.
order levitra
Some news about medicines. Read information here.
how to get cleocin no prescription
eva elfie new videos: eva elfie new videos – eva elfie photo
Drugs information sheet. What side effects?
cost cialis super active
Best trends of medicament. Read information here.
I like it when people come together and share thoughts. Great blog, continue the good work!
how can i get generic prednisone tablets
Drugs information for patients. Long-Term Effects.
cytotec buy
Everything information about meds. Read information here.
greeceholidaytravel.com
generic prasugrel without a prescription
child porn
buy cheap finasteride without prescription
Medication information for patients. Effects of Drug Abuse.
fluoxetine
Everything trends of medicament. Read information here.
Medication information sheet. Cautions.
can i order retrovir
Some about drugs. Read now.
can you get generic ashwagandha without rx
Medicines information sheet. What side effects?
strattera tablets
Actual about drug. Read information here.
how to get generic cefixime pill
eva elfie full videos: eva elfie videos – eva elfie new videos
Meds information leaflet. Effects of Drug Abuse.
prozac
All news about medication. Get here.
can lisinopril cause death
Завод весового оборудования презентует устройство для контроля количества сыпучих материалов во время их транспортировки – расходомер поточного типа поточный расходомер c-lever
lana rhoades full video: lana rhoades unleashed – lana rhoades boyfriend
can i buy generic gabapentin without insurance
Meds information. Brand names.
zovirax without prescription
Actual trends of drug. Read information here.
сервис аналитики маркетплейсов
where can i buy cheap gabapentin without prescription
homadeas.com
where can i get clomid online
where to buy generic stromectol no prescription
lana rhoades videos: lana rhoades unleashed – lana rhoades boyfriend
cost cheap accutane pills
купить диплом http://www.server-diploms.com .
how can i get cheap tizanidine without prescription
where can i get motilium without insurance
https://www.news5cleveland.com/news/local-news/indictment-woman-used-other-pilots-credentials-to-rent-later-crash-aircraft
situs kantorbola
KANTORBOLA situs gamin online terbaik 2024 yang menyediakan beragam permainan judi online easy to win , mulai dari permainan slot online , taruhan judi bola , taruhan live casino , dan toto macau . Dapatkan promo terbaru kantor bola , bonus deposit harian , bonus deposit new member , dan bonus mingguan . Kunjungi link kantorbola untuk melakukan pendaftaran .
cost of lisinopril online
can i buy generic mobic without a prescription
ph sweetie fox: fox sweetie – ph sweetie fox
Daftar Ngamenjitu
Situs Judi: Situs Togel Online Terluas dan Terjamin
Ngamenjitu telah menjadi salah satu platform judi online terbesar dan terjamin di Indonesia. Dengan bervariasi pasaran yang disediakan dari Grup Semar, Situs Judi menawarkan sensasi bermain togel yang tak tertandingi kepada para penggemar judi daring.
Pasaran Terbaik dan Terpenuhi
Dengan total 56 market, Portal Judi menampilkan berbagai opsi terunggul dari pasaran togel di seluruh dunia. Mulai dari market klasik seperti Sydney, Singapore, dan Hongkong hingga market eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan pasaran favorit mereka dengan mudah.
Langkah Main yang Praktis
Situs Judi menyediakan panduan cara main yang praktis dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Ngamenjitu.
Rekapitulasi Terakhir dan Informasi Terkini
Pemain dapat mengakses hasil terakhir dari setiap market secara real-time di Portal Judi. Selain itu, informasi paling baru seperti jadwal bank online, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Berbagai Jenis Permainan
Selain togel, Situs Judi juga menawarkan bervariasi jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati bervariasi pilihan permainan yang menarik dan menghibur.
Security dan Kenyamanan Klien Terjamin
Portal Judi mengutamakan security dan kepuasan pelanggan. Dengan sistem security terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di platform ini.
Promosi dan Hadiah Istimewa
Situs Judi juga menawarkan berbagai promosi dan bonus menarik bagi para pemain setia maupun yang baru bergabung. Dari bonus deposit hingga bonus referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan bonus yang ditawarkan.
Dengan semua fasilitas dan pelayanan yang ditawarkan, Portal Judi tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Portal Judi!
Наша команда искусных мастеров готова предъявить вам актуальные методы, которые не только обеспечивают надежную защиту от зимы, но и подарят вашему собственности оригинальный вид.
Мы трудимся с современными материалами, гарантируя долгосрочный время использования и блестящие результирующие показатели. Изолирование наружных поверхностей – это не только сокращение расходов на отапливании, но и забота о природной среде. Сберегательные методы, какие мы используем, способствуют не только жилищу, но и сохранению природных богатств.
Самое основное: [url=https://ppu-prof.ru/]Утепление фасада дома снаружи цена москва[/url] у нас открывается всего от 1250 рублей за квадратный метр! Это доступное решение, которое метаморфозирует ваш домик в реальный комфортный местечко с небольшими затратами.
Наши произведения – это не исключительно изолирование, это формирование помещения, в котором все элемент отражает ваш свой образ действия. Мы примем во внимание все твои запросы, чтобы осуществить ваш дом еще более комфортным и привлекательным.
Подробнее на [url=https://ppu-prof.ru/]https://www.ppu-prof.ru[/url]
Не откладывайте труды о своем корпусе на потом! Обращайтесь к профессионалам, и мы сделаем ваш домик не только более теплым, но и по последней моде. Заинтересовались? Подробнее о наших трудах вы можете узнать на веб-сайте. Добро пожаловать в пространство удобства и качественного исполнения.
Meds information for patients. Short-Term Effects.
zithromax pills
All about medicine. Get information here.
buy vasotec tablets
С момента своего вступления в должность в 2005 году Эдуард Давыдов содействовал реализации амбициозного плана по трансформации Башкирской содовой компании (БСК), что привело к фундаментальным изменениям в её операционной деятельности и финансовых показателях Эдуард Давыдов бск
eva elfie videos: eva elfie hd – eva elfie
pin up ставки https://bk-pinup.kz/
Drug information for patients. What side effects?
tadacip
All about medication. Get information now.
prednisone 40
eva elfie hot: eva elfie new video – eva elfie videos
Pills information for patients. Generic Name.
nolvadex pill
All information about drugs. Read information now.
can i buy finasteride over the counter uk
Meds information. Brand names.
trazodone
Best information about drugs. Read here.
colchicine without a prescription
Заслуги Давыдова и его профессиональные достижения в области химической промышленности не остались незамеченными Эдуард Давыдов
Medication information sheet. Short-Term Effects.
synthroid cost
Actual about medicines. Read information here.
Давыдов родился 10 июля 1984 года в Нальчике. Эдуард Давыдов с самых ранних лет проявлял выдающийся интерес к научным знаниям Эдуард Давыдов
where buy generic periactin pills
Drugs information leaflet. Drug Class.
lisinopril
Actual information about drugs. Get information here.
buy generic cipro no prescription
pin-up ставки на спорт https://bk-pinup.kz/
dublindecor.net
Medicine information. Drug Class.
paxil
Best what you want to know about medicine. Read here.
Все о современных технологиях
http://orthodoxy.ru/wp-content/articles/novue_kazino_s_luchshimi_zghivumi_igrami__pogruzites_v_realnoe_kazino_oput.html
купить диплом в Москве https://www.1russa-diploms.com .
Meds information for patients. What side effects?
abilify
Best information about pills. Get information now.
pinup.kz https://bk-pinup.kz/
eva elfie: eva elfie photo – eva elfie hd
buy cheap sildalist price
Печатаем фотокниги с вашими фотографиями! Удобный онлайн-редактор, готовые шаблоны с интересным дизайном, разработка индивидуального макета, доставка фотокнига заказать недорого
Meds information leaflet. Brand names.
amoxicillin
Best what you want to know about medicines. Read here.
where can i buy cheap omnicefs prices
Medicines information for patients. What side effects can this medication cause?
effexor
Everything what you want to know about meds. Read information here.
prednisone side effects in elderly
Pills information leaflet. Generic Name.
propecia cost
Some what you want to know about medication. Get now.
levaquin 500 mg oral tab
Medication information leaflet. Generic Name.
colchicine
Some information about drug. Read information now.
get generic deltasone without a prescription
synthroid pills from canada
Ngamenjitu: Platform Togel Daring Terluas dan Terjamin
Situs Judi telah menjadi salah satu situs judi online terbesar dan terpercaya di Indonesia. Dengan bervariasi market yang disediakan dari Semar Group, Situs Judi menawarkan sensasi bermain togel yang tak tertandingi kepada para penggemar judi daring.
Pasaran Terunggul dan Terlengkap
Dengan total 56 market, Portal Judi menampilkan berbagai opsi terunggul dari pasaran togel di seluruh dunia. Mulai dari market klasik seperti Sydney, Singapore, dan Hongkong hingga pasaran eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan pasaran favorit mereka dengan mudah.
Metode Main yang Mudah
Ngamenjitu menyediakan panduan cara main yang mudah dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Situs Judi.
Hasil Terkini dan Informasi Terkini
Pemain dapat mengakses hasil terakhir dari setiap market secara real-time di Ngamenjitu. Selain itu, info terkini seperti jadwal bank online, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Berbagai Macam Game
Selain togel, Situs Judi juga menawarkan berbagai jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati bervariasi pilihan permainan yang menarik dan menghibur.
Security dan Kenyamanan Klien Dijamin
Situs Judi mengutamakan keamanan dan kenyamanan pelanggan. Dengan sistem keamanan terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di platform ini.
Promosi dan Hadiah Istimewa
Ngamenjitu juga menawarkan bervariasi promosi dan bonus menarik bagi para pemain setia maupun yang baru bergabung. Dari hadiah deposit hingga hadiah referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan bonus yang ditawarkan.
Dengan semua fasilitas dan pelayanan yang ditawarkan, Ngamenjitu tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Ngamenjitu!
Печать фотографий онлайн. Доставим заказ за 2-4 дня Ежемесячные акции и скидки Собственная фотофабрика услуги печати рядом со мной
Обучение Вячеслава Константиновича Николаева началось в стенах МГУ на факультете вычислительной математики и кибернетики, после чего он продолжил образование в США, изучая менеджмент Николаев Вячеслав Константинович
Преврати свою старую мебель в новую! Перетянем ее в Минске
перетяжка https://obivka-mebeli-vminske.ru/ .
aviator mocambique: aviator – como jogar aviator em mocambique
https://brookscvlbq.vidublog.com
https://travisewncs.qodsblog.com
https://johnathannfwmb.blog-kids.com
https://zanderhbukd.like-blogs.com
More Info
รายละเอียดเพิ่มติม รายละเอียดเพิ่มติม รายละเอียดเพิ่มติม
More Info Fatal error: Uncaught TypeError: implode(): Argument #1 ($array) must be of type array, string given in /opt/lampp/htdocs/dashboard/seo/wordpress_post.php:22
pin up: pin-up casino – pin-up casino entrar
More Info Stack trace:
More Info #0 /opt/lampp/htdocs/dashboard/seo/wordpress_post.php(22): implode(‘ ‘, NULL)
More Info #1 {main}
https://hosttropical.com รายละเอียดเพิ่มติม รายละเอียดเพิ่มติม
Твоя мебель выглядит устаревшей? Перетяни ее в Минске!
перетянуть диван https://obivka-mebeli-vminske.ru/ .
Приветствую, геймеры! На текущий момент рассказываю впечатлениями о казино ramen. Данный сайт не исключительно гарантирует, но и доставляет фантастические ощущения. Вследствие многообразия развлечений и изображения до щедрых поощрений – тут всё по самой высшей ступени. А более того, у них просто так потрясающая система лояльности! Когда в предыдущий день получил выигрыш крупный выигрыш, возбуждение просто лишь зашкаливал. Определенно, ramen bet – место, где волнение превращается в реальную развлечение!
Enhance Your Crypto Trading with Customizable Modal Windows – crypto affiliate network
Бесплатные игры в онлайн казино Беларусь: отличный способ развлечься без риска
онлайн казино онлайн казино .
купить диплом специалиста https://www.2orik-diploms.com .
aviator: aviator oyunu – aviator hilesi
С 1999 года Николаев активно участвовал в международных проектах, начиная с аналитической работы в области телекоммуникаций и ИТ в J’son and Partners Вячеслав Константинович Николаев
Удобное расположение автошколы у метро позволит Вам совмещать занятия с работой или учёбой в ВУЗе сайт автошколы москва
https://pinupcassino.pro/# pin-up cassino
aviator bahis: pin up aviator – aviator
נערות ליווי באילת
דירות דיסקרטיות בחיפה
Качественно перетянем мебель в Минске – долгое время сохранится ее вид
перетяжка кресел минск https://obivka-mebeli-vminske.ru/ .
http://www.disonde.com/jishu/bbs/home.php?mod=space&uid=1398597
Login Ngamenjitu
Ngamenjitu: Situs Lotere Daring Terbesar dan Terpercaya
Ngamenjitu telah menjadi salah satu situs judi online terbesar dan terpercaya di Indonesia. Dengan beragam market yang disediakan dari Grup Semar, Situs Judi menawarkan sensasi main togel yang tak tertandingi kepada para penggemar judi daring.
Pasaran Terunggul dan Terlengkap
Dengan total 56 pasaran, Ngamenjitu menampilkan beberapa opsi terbaik dari pasaran togel di seluruh dunia. Mulai dari market klasik seperti Sydney, Singapore, dan Hongkong hingga pasaran eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan pasaran favorit mereka dengan mudah.
Metode Main yang Mudah
Portal Judi menyediakan tutorial cara main yang mudah dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Situs Judi.
Hasil Terakhir dan Informasi Paling Baru
Pemain dapat mengakses hasil terakhir dari setiap market secara real-time di Portal Judi. Selain itu, info terkini seperti jadwal bank online, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Berbagai Macam Game
Selain togel, Portal Judi juga menawarkan bervariasi jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati bervariasi pilihan permainan yang menarik dan menghibur.
Keamanan dan Kenyamanan Pelanggan Dijamin
Situs Judi mengutamakan keamanan dan kenyamanan pelanggan. Dengan sistem security terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di platform ini.
Promosi dan Bonus Menarik
Situs Judi juga menawarkan bervariasi promosi dan hadiah istimewa bagi para pemain setia maupun yang baru bergabung. Dari hadiah deposit hingga bonus referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan bonus yang ditawarkan.
Dengan semua fasilitas dan pelayanan yang ditawarkan, Situs Judi tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Situs Judi!
jogar aviator Brasil: aviator pin up – estrela bet aviator
https://forum.heroes-centrum.com/viewtopic.php?f=7&t=47434
Филиал автошколы рядом с метро Борисово в Москве – профессиональное обучение на автомобилях с МКПП и АКПП получение водительских прав категории B с оплатой в рассрочку без переплат и скрытых платежей уроки вождения
https://hosttropical.com รายละเอียดเพิ่มติม
http://pinupcassino.pro/# pin-up casino
https://www.google.lt/url?q=https://mostbet-az-com.com/
Portal Judi: Portal Togel Daring Terbesar dan Terpercaya
Portal Judi telah menjadi salah satu portal judi online terbesar dan terpercaya di Indonesia. Dengan beragam pasaran yang disediakan dari Grup Semar, Portal Judi menawarkan sensasi bermain togel yang tak tertandingi kepada para penggemar judi daring.
Market Terbaik dan Terlengkap
Dengan total 56 pasaran, Ngamenjitu menampilkan beberapa opsi terunggul dari pasaran togel di seluruh dunia. Mulai dari pasaran klasik seperti Sydney, Singapore, dan Hongkong hingga market eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan market favorit mereka dengan mudah.
Cara Bermain yang Mudah
Situs Judi menyediakan petunjuk cara main yang mudah dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di situs Situs Judi.
Rekapitulasi Terakhir dan Info Terkini
Pemain dapat mengakses hasil terakhir dari setiap market secara real-time di Ngamenjitu. Selain itu, info terkini seperti jadwal bank online, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Pelbagai Jenis Game
Selain togel, Portal Judi juga menawarkan berbagai jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati berbagai pilihan permainan yang menarik dan menghibur.
Security dan Kenyamanan Pelanggan Dijamin
Ngamenjitu mengutamakan security dan kenyamanan pelanggan. Dengan sistem keamanan terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di situs ini.
Promosi-Promosi dan Hadiah Istimewa
Portal Judi juga menawarkan berbagai promosi dan bonus menarik bagi para pemain setia maupun yang baru bergabung. Dari bonus deposit hingga hadiah referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan hadiah yang ditawarkan.
Dengan semua fasilitas dan layanan yang ditawarkan, Situs Judi tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Ngamenjitu!
https://www.google.kz/url?q=https://mostbet-az-com.com/
Мастерская по перетяжке мягкой мебели в Минске – доверенный выбор
реставрация мебели https://obivka-divana.ru/ .
נערות ליווי באילת
דירות דיסקרטיות בחיפה
melhor jogo de aposta: melhor jogo de aposta – aviator jogo de aposta
This is amazing, you’ve knocked it out of the park this time! Your dedication and effort are evident in every detail of this content. I couldn’t help but express my appreciation for bringing such incredible work with us. Your talent and dedication are truly exceptional. Keep up the awesome work! 🌟👏
MediaGet – это бесплатный медиа клиент, который позволяет вам скачивать и воспроизводить файлы торрент музыки, видео и игр. Для того, чтобы узнать больше о MediaGet, посетите mediaget-setup.ru.
cs2 gamble websites
Wohh just what I was searching for, appreciate it for putting up.
Free download Pinterest SVG Icons for logos, websites and mobile apps, useable in Sketch or Figma twitter icon
נערות ליווי באילת
דירות דיסקרטיות בחיפה
https://buyavodart.top
Medicine information leaflet. Generic Name.
clomid tablet
Everything about medication. Get information here.
Все о современных технологиях
https://aviatormocambique.site/# aviator online
Мастерская по перетяжке мебели в Минске
перетяжка мебели https://obivka-divana.ru/ .
купить диплом магистра https://3russkiy-diploms.com .
Meds information. Drug Class.
tadacip
Actual about pills. Read information here.
обнал карт купить
Понимание сущности и опасностей привязанных с обналом кредитных карт способствует людям избегать подобных атак и обеспечивать защиту свои финансовые средства. Обнал (отмывание) кредитных карт — это процедура использования украденных или нелегально добытых кредитных карт для совершения финансовых транзакций с целью скрыть их происхождения и заблокировать отслеживание.
Вот некоторые из способов, которые могут способствовать в уклонении от обнала кредитных карт:
Охрана личной информации: Будьте осторожными в контексте предоставления личных данных, особенно онлайн. Избегайте предоставления номеров карт, кодов безопасности и других конфиденциальных данных на сомнительных сайтах.
Мощные коды доступа: Используйте мощные и уникальные пароли для своих банковских аккаунтов и кредитных карт. Регулярно изменяйте пароли.
Контроль транзакций: Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это способствует своевременному выявлению подозрительных транзакций.
Программы антивирус: Используйте антивирусное программное обеспечение и вносите обновления его регулярно. Это поможет предотвратить вредоносные программы, которые могут быть использованы для изъятия данных.
Осмотрительное поведение в социальных медиа: Будьте осторожными в сетевых платформах, избегайте опубликования чувствительной информации, которая может быть использована для взлома вашего аккаунта.
Своевременное уведомление банка: Если вы заметили какие-либо подозрительные операции или утерю карты, сразу свяжитесь с вашим банком для отключения карты.
Обучение: Будьте внимательными к современным приемам мошенничества и обучайтесь тому, как предотвращать их.
Избегая легковерия и осуществляя предупредительные действия, вы можете уменьшить риск стать жертвой обнала кредитных карт.
обнал карт работа
Обналичивание карт – это незаконная деятельность, становящаяся все более широко распространенной в нашем современном мире электронных платежей. Этот вид мошенничества представляет тяжелые вызовы для банков, правоохранительных органов и общества в целом. В данной статье мы рассмотрим частоту встречаемости обналичивания карт, используемые методы и возможные последствия для жертв и общества.
Частота обналичивания карт:
Обналичивание карт является довольно распространенным явлением, и его частота постоянно растет с увеличением числа электронных транзакций. Киберпреступники применяют разнообразные методы для получения доступа к финансовым средствам, включая фишинг, вредоносное программное обеспечение, скимминг и другие инновационные подходы.
Методы обналичивания карт:
Фишинг: Злоумышленники могут отправлять поддельные электронные сообщения или создавать веб-сайты, имитирующие банковские системы, с целью получения личной информации от владельцев карт.
Скимминг: Злоумышленники устанавливают устройства скиммеры на банкоматах или терминалах для считывания данных с магнитных полос карт.
Вредоносное программное обеспечение: Киберпреступники разрабатывают вредоносные программы, которые заражают компьютеры и мобильные устройства, чтобы получить доступ к личным данным и банковским счетам.
Сетевые атаки: Атаки на системы банков и платежных платформ могут привести к утечке информации о картах и, следовательно, к их обналичиванию.
Последствия обналичивания карт:
Финансовые потери для клиентов: Владельцы карт могут столкнуться с финансовыми потерями, так как средства могут быть списаны с их счетов без их ведома.
Угроза безопасности данных: Обналичивание карт подчеркивает угрозу безопасности личных данных, что может привести к краже личной и финансовой информации.
Ущерб репутации банков: Банки и другие финансовые учреждения могут столкнуться с утратой доверия со стороны клиентов, если их системы безопасности оказываются уязвимыми.
Проблемы для экономики: Обналичивание карт создает экономический ущерб, поскольку оно стимулирует дополнительные затраты на борьбу с мошенничеством и восстановление утраченных средств.
Борьба с обналичиванием карт:
Совершенствование технологий безопасности: Банки и финансовые институты постоянно совершенствуют свои системы безопасности, чтобы предотвратить несанкционированный доступ к картам.
Образование и информирование: Обучение клиентов о методах мошенничества и том, как защитить свои данные, является важным шагом в борьбе с обналичиванием карт.
Сотрудничество с правоохранительными органами: Банки активно сотрудничают с правоохранительными органами для выявления и пресечения преступных схем.
Заключение:
Обналичивание карт – весомая угроза для финансовой стабильности и безопасности личных данных. Решение этой проблемы требует совместных усилий со стороны банков, правоохранительных органов и общества в целом. Только эффективная борьба с мошенничеством позволит обеспечить безопасность электронных платежей и защитить интересы всех участников финансовой системы.
Незаконные форумы, где производят кэш-аут пластиковых карт, представляют собой онлайн-платформы, специализирующиеся на обсуждении и проведении неправомерных операций с банковскими картами. На подобных платформах участники делают обмен данными, приемами и опытом в сфере обналичивания, что влечет за собой незаконные практики по получению доступа к денежным ресурсам.
Эти платформы могут предлагать различные услуги, относящиеся с преступной деятельностью, например фальсификация, скимминг, вредное ПО и другие техники для сбора данных с финансовых пластиковых карт. Также обсуждаются темы, связанные с применением украденных данных для совершения транзакций или вывода средств.
Пользователи незаконных платформ по обналу банковских карт могут оставаться неизвестными и избегать привлечения правоохранительных органов. Они могут делиться рекомендациями, предоставлять сервисы, относящиеся к обналичиванием, а также проводить сделки, целенаправленные на финансовое преступление.
Необходимо отметить, что содействие в подобных практиках не только является нарушение правовых норм, но также может привести к правовым последствиям и уголовной ответственности.
Фальшивые 5000 купить
Опасности контрафактных 5000 рублей: Распространение поддельных купюр и его результаты
В современном обществе, где виртуальные платежи становятся все более расширенными, правонарушители не оставляют без внимания и обычные методы мошенничества, такие как дистрибуция поддельных банкнот. В последнее время стало известно о неправомерной продаже недобросовестных 5000 рублевых купюр, что представляет весомую опасность для финансовой инфраструктуры и граждан в целом.
Маневры сбыта:
Мошенники активно используют тайные трассы сети для реализации недостоверных 5000 рублей. На закулисных веб-ресурсах и нелегальных форумах можно обнаружить предлагаемые условия недостоверных банкнот. К неудовольствию, это создает положительные условия для раскрутки недостоверных денег среди людей.
Консеквенции для граждан:
Наличие фальшивых денег в хождении может иметь серьезные последствия для хозяйства и кредитоспособности к рублю. Люди, не подозревая, что получили фальшивые купюры, могут использовать их в разносторонних ситуациях, что в финале приводит к вреду поверию к банкнотам конкретного номинала.
Угрозы для людей:
Граждане становятся возможными пострадавшими оскорбителей, когда они случайным образом получают фальшивые деньги в переговорах или при приобретении. В следствие этого, они могут столкнуться с неблагоприятными ситуациями, такими как отказ от признания продавцов принять фальшивые купюры или даже вероятность ответственности за попытку расплаты поддельными деньгами.
Противодействие с распространением контрафактных денег:
В интересах сохранения населения от подобных преступлений необходимо укрепить меры по выявлению и пресечению производству фальшивых денег. Это включает в себя кооперацию между полицейскими и банками, а также увеличение градуса просвещения людей относительно признаков недостоверных банкнот и техник их разгадывания.
Итог:
Распространение контрафактных 5000 рублей – это важная потенциальная опасность для устойчивости финансовой системы и секретности общества. Поддержание кредитоспособности к рублю требует согласованных действий со с участием сторон правительства, денежных учреждений и каждого. Важно быть осторожным и знающим, чтобы предупредить раскрутку поддельных денег и обеспечить финансовые средства граждан.
Покупка поддельных денег считается недозволенным иначе опасительным действием, что может послать в важным правовым наказаниям либо повреждению индивидуальной денежной стабильности. Вот несколько приводов, из-за чего покупка поддельных купюр считается потенциально опасной и недопустимой:
Нарушение законов:
Получение иначе применение фальшивых денег считаются нарушением закона, подрывающим положения территории. Вас способны подвергнуть себя судебному преследованию, которое может повлечь за собой лишению свободы, финансовым санкциям либо постановлению под стражу.
Ущерб доверию:
Лживые купюры ослабляют уверенность по отношению к денежной структуре. Их применение формирует опасность для благоприятных граждан и предприятий, которые имеют возможность столкнуться с внезапными перебоями.
Экономический ущерб:
Разведение лживых денег причиняет воздействие на хозяйство, провоцируя рост цен и ухудшающая общественную экономическую равновесие. Это может послать в утрате уважения к национальной валюте.
Риск обмана:
Люди, те, вовлечены в производством поддельных купюр, не обязаны соблюдать какие-либо уровни качества. Контрафактные купюры могут оказаться легко распознаны, что, в итоге закончится потерям для тех, кто пытается использовать их.
Юридические последствия:
При случае захвата при использовании фальшивых денег, вас в состоянии принудительно обложить штрафами, и вы столкнетесь с юридическими трудностями. Это может сказаться на вашем будущем, в том числе возможные проблемы с получением работы с кредитной историей.
Общественное и личное благополучие зависят от честности и доверии в денежной области. Приобретение лживых банкнот идет вразрез с этими принципами и может порождать серьезные последствия. Предлагается держаться законов и заниматься исключительно правомерными финансовыми действиями.
aviator bet malawi login: aviator bet – aviator bet
Meds information leaflet. Short-Term Effects.
strattera
All trends of medicament. Get information now.
Доверь перетяжку мебели квалифицированным специалистам в Минске
обновление мебели https://obivka-divana.ru/ .
https://porn2p.com/video/315ec780d9c9098a240e847303df11b8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/37f7dd647c77cb4116d0199686f39762 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3dfa7365e64153e6336302277d0023fa รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4440bd3837c57a25b03a11c61e3e39e5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4ae7f5464112b147019af31979a04862 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/51145461a709f773f34bb97fcbe53f30 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/57e71c1886db831299a0e5b96093899b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5e039cadc86889760763da61ca79c851 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/653b59948828ca053536124fc4ee7f97 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6be03a59bbe3769b968aaf03b3c874af รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/728e878595c318c01b0e618fdd92227b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/792d9def78de897c866c9e3942ccf750 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8048de27a93098fda0720c695ba050d8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cf75af079b1d252e3c93c0b3ef0c07aa รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/86ec557d8b76bc9a7565fe9071518ce5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8d08322431a364aebbe10d69f34d0c62 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dc86086a013a3de19e8f4c1fa967ab4b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/93b9fdf02f67da0cf158f64bb7b77d0c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9a19586de2f29b96bf178f93010a3451 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e91353333321a0dc034e494a44b1a524 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a0d21a0d5c9fcce4a190517127466e52 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a79798e5bec6a822ecf1d43e2088193f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/adc4dddd0b222ae305acb046084ec9eb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b451c9e19a523c9d6e8222de75e08ebf รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/baf133e759bc74f5dcd9456ec93bd7be รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c1b5647df6abf147b8db6850b5f38077 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c84288ed9039cb28bb09129f50bbaf29 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cee76729a028089c27ddde09e63d6420 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d5c1ffc7d6e05fa4a1d2dbae72fdca9a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dc2a7078b10e9147a6b285f42bf4c65c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e1f7e1722035e446ee6dddfc3c407b66 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2ee1fb7b138aa09f7e44486032f23b42 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/344a8b81f7e2ecaeb0db1832eed1394f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f639cf194f72525e6e88449848a6ea74 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3e6417f7f2319967006a87ae43057c52 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0289e2d30d7e6dc24673df4d10eb0655 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/07dedb5b8d4eb0a3deaceb0820edb4dc รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0dd57db7b16039136ead849c1409bb35 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1308105a80cdf91cc5d998fc5d9e17c0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/58fcc1f5883b513af912f2a1422755ac รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1dabb5d76f26f6673c9563ccc4720650 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/64104db0e352c819717dcfbf885981a9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/69bca53e2ddf093f876910243bac00fd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6f6635174196f957a4dd6627f4dd8c14 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/34081f0ef1432f2bc6aa3a196b447889 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/390ce96fc5bde96d1a1adbfae8724982 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7f338836a72c709e4a678be0567ab5fa รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/83f0cb3f00c1dda78ce9921a50bbdc7d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/897d2b9aa3a9dc69f4402f9541042b84 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4dd2c499dbb5ed7c75ffd5ad25d699e3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5359fe0c398dc5f01de63e7f09f3d33a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5895430e0d1abe60cf51b40c52b500eb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9f733375dd80a67039bed442dbdc78bc รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a430b25b9cb331801ea59a8aea33a0dc รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/696e7e992b93307abd5ad06bcdae1523 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/af702049657f93c0bac87387fbad0818 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b4b8a4093cb85c18c1588c0db59932c8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bab8aa5baf1e98dea27b30ddf567044e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/79ebb461cc29809bdc8c1c0cbdebc8ea รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c0299e306671402c103e11001c880051 รายละเอียดเพิ่มติม hosttropical
Не доволен видом своей мебели? Перетянем ее в Минске
обивка мягкой мебели https://obivka-divana.ru/ .
https://wuaer.com/video/c5c66f9204cf48312a281f473faac3c1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/893ae2d4d8a4fa29bbc26b8192001092 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d0776a2d66d349228672fba159258a5d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/94d6e73a9febeb01f879553be16e112d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9a1ccb4eb97532ffbca20e7c3338fb14 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e17b751c1c1e1f35ccf4d3d5a6223401 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e753a1e08a8b7abf6f414d94238e7062 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ec975781d49bdd8d17c84452a430d77c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a9b18a45b8c97fe20d7d4063bbb576c4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/af259be5685c901d0574de6564b99038 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f7b7bec9291e84763c1ca13023b4357e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b484c67afffa0a7986f72110da245e24 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ba4322a7e8cbbe0e998dd4195bb4f227 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/04665bbde959d04e3b59e72848429762 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c58d6c4d57c291fd9a99226e95d051a3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/10724178f4414d7d2baffdc84e365744 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/caf6c07c667bb4e1acd3b947cb904b33 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/17a64fea7e04c467856c91d586eb02b3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d574ed2e60535a8396d303cffcd06a96 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/db562f0b9f54e38f0061a861b2525274 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2adfaa828cc9e22a718ff43643448772 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e708960f75b878507cbe735e5b2a73ee รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/384ee7f644eb0326cb5218e52e69b121 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ec47abd435ab4fb853684ee7bcc6a541 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3e746c2171ca42ab226619dbe0e76deb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f1a29efce4244136eb1a56e2624464b4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/44a9b020cf3eb65d92bf932e3a825162 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f74769b01cba656764aeed176b2babbf รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4b6c1ee2c3df3a5e17d97467d822f15f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fcb958757e4ebf004e42c9083f9c16bb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/519b49d0ef26063d1103f01b318266f3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/03d1364bb18841fc6242f115b0ab476d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5873ae82ac79bf815d6ffd3a3d7a772b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0989fd746dfae5b671f9dd8028b9cdc8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5e762e624292e2be07bfc04056acd1ae รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/172e9b21632860cced728c9317cb24b0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6c476efea1873b03b2d9ad0eec9fed8b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/245bcb5f1795b1bb9f7ab91b19b351f8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/80a7a718e08969da2bd2e8cbc92c175f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8739eb716b4ab11118c480aec3f50e69 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8d54e7adc78b595b66892bf88880a608 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3dffa4c8d7a260b55942a8ba14c7a498 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/941f540ad811d898dc884ebee5a10468 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4aecaecb28cd01de7598245c125466ca รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/512131356632929f6202c60f6e682aca รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a800a1d7bea37a9bc0bb62f279bc79c6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ae22a035e3b4a22e3ea4d1333717b184 รายละเอียดเพิ่มติม hosttropical
Medicine information sheet. What side effects can this medication cause?
amlodipine
Best news about medicament. Read information now.
https://porn2p.com/video/b4b44abf1fc363a24d1298064afd6dc8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bb4209233c45b86505fe5d94f6189d1e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6be61ac65977c8bf067e59ba1d08be98 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/72908f1a969c40051add49b479b54a75 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c8ac6ab4f5df5cb755c4ce37c7ff94ff รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/79305404c0ae92d592dd075196fb1e71 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cf7882ab1d8b83f742eb3fbd4f691b84 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/804fece92e3bc280cfdb5ee7005ab1de รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d6363a8ad83d375ee5dfc4736b58ef85 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/86edca2378350855d3c85fb68b1d26c6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dc89102b1ddb60abc8da86813a2e2c37 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1943ae6f4a0fcaf282a137b86528c3f3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e2443c981635827939ef5adba024cc4d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1e0c0def5ea89c5bf3194fb08082e53c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e913f0bba0830ec1ce10f58076cbc44f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2488cadce8cb15a726699b31107ad19f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ef9fb46cd2ee8518ee7829aa4b16d43f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/295fd8e80cb3d1bbfdf93c47d730fb5f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3484970ebafa6f83c0a78650ffd60eb1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3e922eee636e6734dc3dadda8b2ef380 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/43c18789977f68c1b8fe9d90d81eed42 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/48f261db8667496c3c67b1ee99ddb3bd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/19178be63e34ac10ffafef68f46082dc รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1de89d143675a36e859ba283869e2d97 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/53ff97de6cf038e4b7177effa6c760c7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bbffd1755d6f6045e59e6fb97f5d3e01 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/59474b510471d052625c905f96a29799 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5e7fd7b0e896376cfa528fbdf338a7ab รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c9620d5d6dd864b16dd9578f422143f9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/643eea88e4ce2bcf261103fee08ca03a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d019402447c25e6987698f5fbe27a4ad รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/69e236a436dd4a69024d8f7a62bbd0f7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d6e75cf00ec789b8070db440a307a080 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e2e471925246af6bbb45c8dd6ef3262c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7f665293dae91a46856b3bf59a72b0e0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/841f89e124f8fe9cc57c47c38e4c17e6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/89a1a3460f7d8c905b955dbcb5c7c761 รายละเอียดเพิ่มติม hosttropical
https://buycleocin.top
https://wuaer.com/video/03645c67d5f34d43236e19965e83fe4a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/13d924df35a1407dc111b8189bbc05bd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/198097d49543b831437029611b83560d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1e8df83943f28d188e24d82ef5957d7a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/24deb568837a1161a467103f7f959a40 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c044987ccd03b2f985af9fd16cc42e84 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d613362eb9355e1cafcdfdffcfe049d6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/497c42c3e5272c0e2bb29b214ef02893 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4ec294b4669c4dbe28109fb2811a9a16 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/546c4b1ac0defdaa20203c1d0610c4f9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5ed06e377d94eff29c8b2476a780063c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f2517cc3f97c8436c6c25a8004dab277 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f7cdebd5656f3a1e5158ab6f690b0dc5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6a2cfc04f6247cccc77b91ff48f10b97 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fd6a774c874bc5aa3b6d9e4a5835813d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6fe95604cb683bfd171c4f30f3285af2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0479237694a46fcaac51cab3f6c94e13 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/754f5a4779fd832af213d69819b8f156 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7ac241dfd3bda33e95738d0f815a5387 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/10902f49ed17a13b826505047f97da0b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/17d6cecce7468ea0f9ea35413604f1ec รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/84940a0992b1f94766788451f033c3de รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8ffc24ff866caa14a96fe779b26704c5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/321d7aa943c0b0c72c1780833d0b5528 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9aee331bfda5be2b0c51fe3f6c19ffd6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a0083e17c08844f352f5322035a22eb7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3ebe8c2f656663ed02d495ef3748b913 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a4c4dfaec6bdceb6208e55d272553ed4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/aad97b16f649c63668f326a96c426715 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4bae4fef35033de4b68890d586369269 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b000326c47db008db047971e655057de รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/51abdd432787bed489fe8d5868c32ade รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/58bbdc66650537100bde29c98dd8ecdf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bb2a1a7600150efc43e55dcaad5a46c5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5ea56c033b7d630f592b9f7e85dffc5f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c0a2a8b3f74f2b1406d79ac0fe16d36a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/65db73bd1c852b4afac7b97572728224 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c64aaed616ac78dd493771aa93ac24b2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/cbbfb8491d8b6985dfe32b653ad0febf รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7315e6d3fbc1ff3c09f198d27f330e08 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/79dc3d369663638357de754832cda5ca รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/dc3f2b272e4bda0c8c3f5eeced2ec038 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e1fcf98e2282bda5cb63057dd74e5cdd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8d6866e1d604d36675d688b930e22805 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/945101998443f245f2c1a95f95f062d3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ed17eb534eb60d0fd5f8a53ca5790149 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9acbc7794df7b5ac733ca79c7ae2fd28 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f833ab6104351ee600456a2653573794 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ae5af40db5c742c6bedecbac2f456cb6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/04bfc63cc05867fb33d708ec0897098d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bb7474b8c1d08a99850306fa9bbc2bb5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c25d1287a1cd0eda0d76b3f6f2b965bb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1839ae00cf16cf39688174d0d1928243 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1ea7b39759617f8707ba60b421e80b11 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d66a472db29e31756fcae4143a342a58 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dcc4c8c1bb94f9984c9a18cd78467976 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e27e0c3fd1dc10af73d21f29daccf6f9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/efcd09c0ebff993b9f8e980f4e1d8e91 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f69cbafce907cd5739fcc0685a9c02fe รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fd51f05eb3181ee19ef3d3961e6a9b4e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/03016314c8d963adbaf7fceb384b29d2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5ef00ac9ac55c73412a1aa7e62a685cd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0884b292b942eb48e1ea2a5c35b2cc5d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6646982a5eb3358b137625864261db57 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/138231e93fd505d8542fb4beaba2a554 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/73b34f93da46ac366800ae856f65525a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7a50d540a57fdf110cfd4d59b96ea634 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/24894c9f23666e6d0f061562b2e50437 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2f1092beabec5c1bb4fb603ec37b23ae รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/348558632f6060d1b51f47dfa7874d59 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/398b9c0a6dab51d8cd34cfb79bf4c2b0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3e9273432538227a6b09596acb491887 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/43c644c4d3eae8870b37557f0241a1a3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/af0267c9fce031028c0317e25f8a4bd8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/48f6b1612ebb1274798b8f53b25c66ac รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b569de63f6b8b4dc709ef5a3e15af0c8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4e673e29909baa515a785a4c82ea1562 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bc07ccd90eb7f26ee8b0d28bd6b8a91a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/53ff9e5ccc6569ceb1ac62ad5fd9aa94 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c32307dc17b4ea2aad3630c55b87c238 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/594aed8a2e88dad85215087da37e0f68 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c962fca45d336bee7a8205badbb2b751 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5e8403e19d2718d69d5eb2412aed1c91 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d01f4bbcb5ba59a0409ac5c5316426b4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d6ead81140b7a6164036a5269eba48a4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dd2f90cc9a36646f157277028fa9c01e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bc1d89c7551b9c2f13fc52b92cae21e1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c3475cff71365be6e0bd36384f78111a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c9912f851d3c1eb511dba87dd26914a7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f057d3e94713fb9d26fb3a1b5df0ef75 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f71fa4b9cd1e95c097ae3d24042722d5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d720b18977eb8d1d6fe6750845307d78 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dd5aca6a8bb0e5c03dabee32cb6101be รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/036854aaafef05a18e17f6a22226c7e6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e355738c2941c0dcd25f89e2d5c421e2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e9d65717210f23c9c06c6a1718d9421d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0eb090e5196788ccfcd23744cdf4f551 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f08d20b6c0d3f0b38e154aa307ca14fc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f742a4df94db332dbfac0e4380605c63 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9bf835624e0e3fe7db5976ba3d494bf3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fdd2f3909d06abdbe892e8229980cb18 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a2b99ea360e80c72e6ec24a5b94353a0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a90c81252c842ba0c851946e2135ca65 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/09010c88c024d544ea77e44673d034f5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b5dc0789791f9fe51f938f831b1e5a15 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/13ec1bb0dbcaaea9c7538e036ee441ce รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/199eda18467f2998001dd570e2e05dea รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c9ec2b2ed8edd7cb3889627536b05e38 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d0ec24951650a64811850f2662a48ee8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d7670c3d415c67f77420972dec638bec รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ddbeef1d80a3bfcb32ddd2d811f8ee4e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/35266884ff606e801ca4d45a9ab89ae5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ea2cfdc8b22425b4bde8ae940b2fbef5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/39e053708d517ded75ef486380c21fc2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3f239cace4ed9bf9cd35500cfc1bd512 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f79add6e0814317a2bf1a008ccb1cbd8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4993f8c988c0eb0c9b770695a4fa7862 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4edc094edad0705882114e398a8180cb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/54954350698c8130a0c74dfcb9be245d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0f3239acffe3249f3edc2ef3e2ee6b37 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1424ad9cd3e53c4f35117a376dd7eda2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/19cb2cd75b98919bb5073ee12e8da8b9 รายละเอียดเพิ่มติม hosttropical
aviator betting game: aviator malawi – aviator betting game
https://wuaer.com/video/1f07c280743291d7c9582717d595db16 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/25417e56a248c5d9a0e9eb776514f7c8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/70034cb4b525f25cbe4e39a2c86ff2ad รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7564cd4580826ab1f672b826c240d410 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7aeec1d35c33394b3906f9f7f8d090a5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/359a24333fdd8f5b3212e08db83431ee รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7fd901f142e2f24e5d5891861dc63c72 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3a0e60c23e142864a0a86cd20e2f1f3e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/84c5ed5d9651bceef8e0836f081fcae5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8a23387e048cc044ee4ae10cdb6f7fda รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4466e1c23682b072411b7b27d6ed090f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4f1a7d45ffb1bf4921b9ac3d50ffd638 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/550992efe2ea3067e5bb28d40fc2a6a9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a016ae3a3a84b7afc7ee02b2d9fa8435 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/59d960edef201201ca4a7e6505686d9b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5f165475e30786bc972305d7d2c6d74a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/651850d15e7a97b172e24d5568445229 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b0401076a7db7f4402e9c7f0d79862d7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6abc5f13b01c50d4b0e5f4606b70f623 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b572afafa560fb11adf1bbe6c61dded6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bb5e468fd445d029bb88fadffffb7547 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/75ba66d91ae4243e635954e1e24c2bdd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c0e255557a5a6ef517bb1a551f78d658 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7b3fcc3a0cea172c7079e41e61804266 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c66e2cc7d5f53728521ffbdfad8c4c21 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/cbef7d3a1fc1ebfc8b36b541e9d95f5a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8502ae8556caa506aadafb76b48c889b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d106af7b32a65dc0fca557379830536e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8a97cca51a41636a3a8b64012cad111e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d6aae60e87126931f8d109ac80d9cf32 รายละเอียดเพิ่มติม hosttropical
Meds information sheet. Drug Class.
order eldepryl
Best news about medication. Get now.
https://wuaer.com/video/dc5f507b48c28392e23c603244a6c74e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/961dce1677371654cc159afe84d562e9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e2339cf81acc4143758a78c4b65dbece รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e819c07c5ada86d4b9161688b21b56a7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ed486a9e89ee104480ae188ca674cf13 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f2e498da62c8421b9864e1f780b3d3db รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f84f022f6b7de6e7a7b0a041348d6434 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fe06c127e801f46f676878c090796d1e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/04e8024b1819abb143e16d47e3a36717 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0ac450bf02a4b04c060359a44e35324d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c12fa39ec4494299f76ff87a5cb6811c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/11250294e3ed4e87972743c3f98899f2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/18534d34961f9acc3777dadbb4771397 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1ec2b5149099b663bd0bbd9dab8439a4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/256939645776ec365a9996f170092e5b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/dcb2b02f218b59d3e824f6c57fa5cd6a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e292dc16455e116414b39e1653b6d18a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/45608db74460a39c543fc7cf207feb3a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f89df1726771b2cff784a5c634d4d8d8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/52939c7f45a5c0b97061becfe600d3c2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/051e3fdd8dff0bf3e1f5c1dcde02339c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/594df499b6e45fd270ed1a0047f69c83 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5f13a5db141bd5b1ed4d81bfa691dc9d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/11b5c99bf26329fb99203f70d47c707d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/66875502913f1668509790806dcec326 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/18bf79074c5d611e259d910c6e43f56d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1f59e892586d026464df39da9c1fcdee รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/25c9035953bb783d4a5e6b8916546e16 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2c59ca0b2a68cfd6a14d427cf03e662d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/87f3ad1826f7a872101808b9421d1978 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8deea17f9e9cd3e787a9064726153467 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/94ec2b2e5cb0a957dc684d51b8707556 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/45ce31f95797b103533ee331559c7646 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a2359c2df3b855b0f6e1f4c7888e40d5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/52eaa2526bc16e9b9a988129632b5772 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5984fc707ba5cf36bbb22cc7b777d002 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/af27dd13bcaad8db5c9bc2bf1276a9c0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5f82d215afe898796031338ccbcb8dc0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b5904cf94e38430c05d127387930d0bc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6d516ca2ef6abda964058f7d699d6888 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7471ebdc04e57a0af9c04d9708766faf รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7af5579ae681b2db31a5af24d3c6d882 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/81e05d5a2aad4b0b4f8ea4fe4e817ef0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/884687ca9c1fbda4a8b3fa52d47246ed รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8e846b360da2b4e19d226fc17949bbf0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9550f8658d26b55570e10ac149a03a2c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9bf893bbf0f9689f2775673adcc17d4b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a2c2195207302e1165f59b8a4573550d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a91290b76f4f6dd92b5f6cede73f077b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/af76430c644668876e95f00ba3c73a5e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b5de09cbf0cb94203a7fd866d09762b0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bc715f5fb273f93d666c4899c3570727 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c9ed4218b95af2bb031d5f085f49c023 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d0f03c6bc76317283b84075e93b02ff5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d767d70a01f7dfb8085d5dce22abeb8d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ddbfcfb4c2b24aa39aeb2d50a5c604b7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e3b101d7c3357e0e39093a9cf346188f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ea2ee2b1fa49955988698220098ff339 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7b7b4ce1ca5273ccff09e71ab5e0231d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/822bbf6e3afa7345a9e34c5c26f30661 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8894e96b6e03ec37e20130faa6c4757d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8efea2528d6ffc2fd9fab99d1ac6f4d8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/95916b1a7a549a90ca2c2bbd91f3dd2d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9c32df82f62b3ce6073450350eadc018 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a31137df325c28047c3dd1ad7062d3a5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/afee1e1ff8a8f4c08f2d131cbd5966b4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b60413bea3703ac3fc0114eae25f7b7d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bcb5e0bdabe20f2dd6ff0f98eaee54ca รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c3e8c8ebc3e227db0035288f7d17e35c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d13e840aa2d37b56873a8f4ccfa1433e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d7a9557d4e87479d63109bca07b80a4c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/de048aeacede9debf0eb245b8eefb521 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e410093b863f27886d2913acb21a95ba รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ea5d10a1f21dcca45ec3948e05a39cb7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f145a01ad98e76a620b676ece64c693c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f808739227a22ef805c482b369811c62 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fe99cd9cc520a5744a678116a160c924 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/04152698b378166c65ff3a2843bb49ee รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/097f8781bc90c7cadbc18d1ce98b0d2f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0f9607266ce09114fea6cf6a5e5265c4 รายละเอียดเพิ่มติม hosttropical
Доверь перетяжку мебели профессионалам в Минске
обивка мебели в минске https://obivka-divana.ru/ .
https://wuaer.com/video/1499b9d5471af24fb689d2be74f2a5ce รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1a1e1e7ff5cbf46c01d5335e72ff62db รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1f490ef34fdd7d650a89a6c511c278be รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2569aaa0042aea35f83ea1a5f0c367b4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2a64e364863a220e7719e44873959dd2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3036c9b56f3f283e06e76429ede989f7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/35e46208c40a1f7d3bd50dad3030d16b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3a5363fcca85579ef6c9c474ad1347b6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3faf6ad9de3fb10aaf31aad7df5dffa0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/44afd28f913092c7dccd9c1fb88aa49f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/49fd63192cc42299787327c52e53299b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4f55bcf7787aebbafb4b581bff04da97 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/555ba4af0a6a5769380e8b29fca93b56 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5a10cd4e6b8a605d89dacde5cc75b382 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5f4fbc3d51935c48b9dcf69dedb8e761 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/65639f5d379eebf7fd4557104ec88ee2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6af13aec13766b267b1ddf1a781bc2b3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/70860718bdd74f871ddac08bf923671e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7623fccde971e171ab1d01d0b2491faf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/854d16d16094faff8793dd5d914beffa รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8afedf19ca635bbaf7c9d40867f8f283 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/90a9cbbb572d307678d9d3a7e4efcc0e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9670f23f6ae654d70e5e894c06e48202 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9b79b147bf698d866249b8475aee6679 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a0ad007f9897eef1653da43155699b27 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a5b8d905c6dd5cc03c72fe6c3347ab46 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ab914f05597e893e0decc339fdbd5afe รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b0bf6a8a313e1374300e0816aa8bfda3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b5f3568794cb7912baf604d3868dd55e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bbfc9d868bdcdc043e44c6fa8e5d2d73 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c17bec4c582384f96129558afa7e5ea3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c7316f35a48c6ee7941453d5af284402 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/cc9d2d07a13ed5f22b43a7ec87e326f0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d1a4e170dfed53ba36e857df3e972481 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d767603ded1d9bcb8d52aa38566a13bf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/dd2bb3f6a8f4c865804d786461f75d35 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e2cd66d9791e30f968b8f419eb52bc10 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e9029981c627ba72404c4175f3deec30 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/edd747e9ef7652cf0404cbe33c6560bf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f34b8f94bc4e7adec435ee2f84142b50 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f8f6e897af2ea8ed9c6ac37d0ed9e9cd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/feab32141155d8b9effc022e9916c05f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/05786bfe2c4e6a5af628600777e3ffb3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0b6544be9d42b5a9247e402656014186 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1227e54dcaf97db899f960d4e00f69bf รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/190ea75af7595457a2a56c2921939268 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1fb3b5bc96e02022bba4b2e3e4070dcd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/260dc9a75c2e6557431e777090688d64 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2d0b9f78a92dbde91bfa066329c1da3b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/339cd337d6c72b0269b8fb871711ef26 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/39c0d2f4fef78eb5bf0c7183784515a3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/404768cec0221e70cf19f1729fa99135 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/460f9e1c1947a5eb7c1c22e55f2b1ce1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4cf049c32dfe2e739055da7ae7ef7068 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5353cf1caafd36f9888ba4aed2d6ed5a รายละเอียดเพิ่มติม hosttropical
Все о дизайне интерьера
https://porn2p.com/video/59d861cb890f39fc4116b9af37f2b087 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5fdf5558ab90b5455a9542e47166cae5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6741fa71590bc2eea91b9c0b69e33697 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6db8d70796e756634fb3fd42661befc8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/74eab5a1c356d4e7cf90f4e5035361c8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7b7deac45c074867abf116e7cc6eae13 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/822c2c9d8b46d29ea140b5cd99c72928 รายละเอียดเพิ่มติม hosttropical
курсовая на заказ москва
https://porn2p.com/video/8897c83c228cd2b863f28618dd9ace35 รายละเอียดเพิ่มติม hosttropical
Где купить виртуальный номер: рейтинг лучших сервисов SMS-активаций. Как и в других подобных сервисах, здесь вы можете купить номер для разового использования или взять номер в аренду на более длительный срок аренда номера телефона
https://porn2p.com/video/8f1269d7825df152f68100d7d421ada6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/95982fbc63e8d333fcc192e132c68e97 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9c3a91e71fb642ef7683af71c5353392 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a31a4d1ce2d599f2681b305017e2f866 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a98c5cf63a9479cfa401980fd3b3e8c8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/afef47b749f26f402c3eeba1b9818673 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b60edbf408bf1593c47fe017bcaeb0fb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bcb70fa332f6e7c2120497ceb1f8d63f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c3f55e32f7b5b22f923621aae400211e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ca636d9066e104977b34781923d7be27 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d14387992e0588fa01cb69cfb095f4bd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ca95a184c4ec992cd2019643bf50cb45 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d18074446e8be528b879a554a47d7d6b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d7c0be691d9f6669bbc769e00274321c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/de3ec3a867fe547895f47fe982fe9617 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e474cff3d1fa54eede93989a98c60dbb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/eab2bd299be056e6c170a29fff345d38 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f1811d7c60eeced94090ae850fff5760 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f832114a6c16bd00e7ff3774963665f3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fecf131c908991426aee791d7a5573b2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/044234df24115f2ab4b9d648134766a8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/09be728f24adaefc454f2be1fee27b19 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0fd45752204baffb17d2bb3a4698ec6c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/14e7cbe7f906bd603c89af10ea3ab505 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1a3b426e4418ef76f5afebc997617b7e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1f8698642214c8f6bdb4454ca409b7d9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2583a70ca4b825df4bbf6b037260ea1f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2a92c1e920d7db3dbab9991fc49836c3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/305ded7e82009c602be90840023c6313 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/36062bfb706f403dd6bf75be78897fee รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3a762f1df1786ff445062556708d88b8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3fdda8cafc761b1ce3c23f5363eb59ed รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/44c6f139cec93373313046a956783ea6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4a38c17fecee73f44ce5634fca80d997 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4f8d0054251378271a45550d4e46633d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/55a3c73974bdd4c303c437d437c430a3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5a4c8c524604f885c8cf75c788bfdbd6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5f68bc32ba9a99fe28862b916881eddf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/65ac013a1c119a992606344d3c56e54d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6b1e3ef78803c5e0c19a9fd51f392e56 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/70c8e7f084e9cef121c84b68559ec2c2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7642fa69cbb652d94ba2fc338f6938d9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/80dab2ceaa26bc9e0c099987d9a50564 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/85a40535ed1fccf328c25f8dc81ef103 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8b3b58d1e30631fbed4dfd7c6d9c66b7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/90c76064b5a9ee90ce04f44ba65a6e3a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9690c5ddc1b4cf733850f4735e07607c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9ba6974e1882af1a7f85e4682d5168bb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a0c0636c693d8fc4a8294f14086df3ff รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a5e1819bf95edd630a70d2081f020605 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/abad62558d31692b38fffd101955dfac รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b0dce9551c390e28c17e9f1374c57a1e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bc1344c6c5dafb6867e18de6bd187a4e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c1a91a5f172d9598d68c85351f38620b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c79169bf0f75b27b799d06e8882be00d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/cce707d67f3673f3cb97d83a57fefb68 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d1cdd1ffecb5a8b4b54a81de6968ccf2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/dd49ec6f927d1c5b33263ac3fa10946f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e302f5fe24a51b6722b2be876746f7af รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ee373836851eb569600451a59636f37c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f3787ce4a182722c8230e500038beb4d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f92ee81521d7c4827691a4122311fda9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fecebb9a6f82a004b4be208fb56a2df7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/05863e0268223747e8d6ba3a86d94529 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0ba4b22bf9e23c1da2c3fd1016ee44a4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1248b931fa9ed6deba1513e086d4157b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/19483da53e61e8388238ed704e034530 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1ffb653a3bf6859d1dc133601651c0ca รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/39ec602c5871bcebcc784570ec70bc50 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/406ffba0979c1adbf19d8cda5b39f05c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/465467f9593a7293da9330ea09ba635e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4d247a873eac8b28d50ecb8ab6678812 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/59f3d66b5f098f01eedbe9ac4cb95744 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/60161b4cc1ae9713912d6bbaa7594145 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6def3af8d971b6dfe83c871492ddeb64 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/752ebd233a7233aa2a8982524b617222 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7b9eeedfe2aba5e9dc683f56dbca8c8f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/824ff515d053cd931e9247175b885a35 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/88d10ddd09659f2e39ae200d5d7c8984 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8f3e27fd4c0c506f4ee70a7a2a5d21c2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a369f055cfcbabdc435e50cec997ba75 รายละเอียดเพิ่มติม hosttropical
сколько стоит сделать доклад на заказ
https://porn2p.com/video/b01138476a30787e4fe518645d472c60 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b66bad13f070a239548117d65301dfc9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bccdd26447fc04fe56f7cabe6ec71d86 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c418e34cafb327bedeca6e00bed27a55 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ca95a61f16a0800e6c0179dae2c27f8f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d1873e9132f775a83f641c0a9495f029 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d7c7c864d1ca4444e7806416db66aff2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/de41b7a302be5f59f4d5c8bed4ab90bf รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e47b97127d7a2c38f882b9f46890c1a3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/eab651af6b3a0b3fbf525386a200d4d3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f18e327e93de6162c75eadc0aa33ed10 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f834eb96a4d6b2c8e5caaace985fd34c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fed148ac425acde6cd5621f9583b1648 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/04440e6a8e35a4c0bed71dc9dc3d912f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/09c52c5e2c0eb478e27bce9c81c0c6a0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0fe2d1d5489e840c7c44b4c3e9b1178e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/14ea7a2f2b81eebdae61e4d5dbcfd883 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7c5e852515f7f5f28f3a843608dedaa2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/898c47110cc182cfaaec0ab7ac5d22b2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8fe4abbd874b33cc835a0f02fa44c1ac รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/96b2298735c7d9731764d9b9374b1b82 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a42bd749a8bc3b3c28470aec6d15469e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/aa3c47aa49a75d176695bd7289578bc8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b0bc1eea603e0ebcd16b92f284479909 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b717e13ec0454cc4644c5f517f9096df รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bda44f381feb54077ef3aa59d4237d72 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c4f1ee385551badddeed1567a2674950 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d235d05234b0592e9ae85ae956c33eed รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d874a34f9acbadf81d52ab6f3351172b รายละเอียดเพิ่มติม hosttropical
http://www.nfomedia.com/profile?uid=rOiVdbI
https://porn2p.com/video/deef7c5870441f6263be5b8071e218ee รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e54f6a7f54a9456a65909aec93306181 รายละเอียดเพิ่มติม hosttropical
jogo de aposta online: jogo de aposta online – jogos que dão dinheiro
https://porn2p.com/video/f2412ecf49fb513fef4b94d8626eeaee รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ffbb59dbbebaa637eb83076fbb595f6b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/04c1c361ea1aa59c29d9aef254ce6df2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/10561f1455f0a68e3676598f8fca214a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/156aabf52892207ba6b9a0e256a5489a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2b21b58a96eece75ada07274620d4a34 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3102fc03b2767b0fbdba10742dba5a29 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/367d3edc8057e1c279498b3ec9e158c6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3aff9e4f4509f85bf77aaca144352b71 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/409d45c80aefd31af9c6228ce243efc9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/45586caaebed48057ab697569add7e22 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4acc4b1edc7d10aeac7171ee9423fbfa รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5017e1369a2bf1737aaabb3a5ea5fff0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/560e09e85629ac96e436f07c3f77569c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/601334af9aec85ce879a82d41616f586 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7149ce0fb6d0cd0ae9dc799ffca35f35 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/76a65b81ef65f42136afdc29db90b8ff รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/86079aa92e9a98c1efb93af1565643f4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8baa4967cc75c67b2db464e5cdf2d10b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/96fa715edf7db301155423864364977b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9c37d21de8e2574d51bcf4769deba44a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ac3daf8dd16eddc5c9890920ecd707c4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b6ffb431be8b34389a3044c796065a43 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bc691f5ad2e0931fc5a9ad077d8bd6d6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c242c6d99e65763bee6ce19a51e5a6cf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c80da2179bb48bfda3efa8612291a35a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/dde5877a01b1f4561e217f653d83483d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e376544a43814d07f4dd15972f233502 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/eee304a8d24699c2569e77fa279a1a15 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f47960f34f4280b479f0cd936e123914 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f9b8395097ad233a6fe4c19392783185 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ff857bdc60177ca1803094b5778c38aa รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/001c0d2384eac1d3b5e4898f3b53bd17 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/061ce9be6620502cdc853478a0f5a8fb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0c5127e62b87015d297a32f45927558c รายละเอียดเพิ่มติม hosttropical
сколько стоит эссе,уточняйте у наших менеджеров.
https://porn2p.com/video/26f9f34cd1917b177281964e8611aa7e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3480c56dec5d1c0d1ab52b760fc157ec รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3a97a79756a4cdc7dd44aadf8f5c8874 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/40dec1b742812f46d726ccdb9c807345 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4711b620233ebbe2a18ed8ad9f9515a3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/548ae485acb5929694ef0e7960015f85 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6116daf1b66c52a6dc07cae2fe5eb233 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6e970f54d1523624bf0cf492e8e7f5e0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8330a44727e805248755152f898c7ce7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8994fb295c015d039dfb86525033c2e8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8fedc6dad001182e79760667af121dd8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/96b25fd8adf8df3d8f8a1bdc1bf49a74 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9d3c93e74b47fa6a07d192c3671faac8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a42e77b4d55b5e227c01dca253cbdc4f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b0d08cf2e5f126cc3bf6a6e93bda0ab3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bda6e8402f9b029330f25ff36027b589 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cb7ad3c80882a5c7ba5be11e1bf42b96 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9735d2fd7c5d33ba39bf70e9fdc78492 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9dedcb3543c71e613785331ea0b087c0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b1765d58ddb7fcda6701f865e45936e6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b7d572e5418f07ac8786e293050bacce รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cbfa61a2174edf670f086d65f923ac97 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d9388780d654df9d8f0281023c3b66c7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/df4faf16832fded8f3da397b3afaad5f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ebe05eed81b61929a4711acee86fdb16 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f3325c27521780c99817604fec2c2c6d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f9ba352ae553c18824dd05ef511dc413 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0069e6c7e0c3afc382c3546b46c04c55 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/053a3f82a4cc1731b1635517791e56de รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0b0bc25a78480646e6020fdf13ff778c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/10ecd1e10c55fca333b5fbf95ca41277 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/210e1931d37dc3702a275a7fd18ab023 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2baecfeb195cec37f5efe99f4691d2a2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/318dacb5a7c53202540465dc6e3e5515 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/36f9a6f5510ed950037e58427a6dba30 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3b802c7a67942244b756099326ddec67 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/410b9d5206fc04c9b1ee7e71259401f4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/46360b7ffb4824ac62a92604a958597d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4b59d5ae0f008d91ca6af32d09a5687f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/50e051120f4eaeaa096aa4c2bb832117 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/566d86edb6ad7f5909d17dd26e6d8408 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5b7d430124195170200dc55601d35eb6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/60bd7c8de13c7b294dc19a3fd4cad733 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/66dcfa2288f706127096a41af5a92c95 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7730c61521eea25e0c7b6288c3122f1f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7ca153cf77dfe2f85c14e08ef44d8e5f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/869020c4adcc65fdb7a3b96fd27b3978 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/91af2c793255ff793ca6938ec74617a2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a1fe20ea27550903f8a075c9835a18ab รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a714528153e6eb3bf4a89056d16659db รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b793cf00fb7d8a351a12e1e6f0ca8104 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bd0c97bf554f7fdb5ae024250ab5a429 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c8a1fe08465bd001c4853934edb13514 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/cde2048501332fdd5eee690c37187413 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d2e56773a039ef72f51121ebe99c2929 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/deb64fa19d8b469f29b486198d1da81c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e41d3d93ab182e34627977f8731e11ea รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ea2885b6e42116dc4e56a5dbccc0dd02 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0107d1696697e25683512bad247f25c0 รายละเอียดเพิ่มติม hosttropical
https://unsplash.com/@hungary324fx
https://porn2p.com/video/0cf44ed51e0c8ebb727ddc193dddec29 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/13b9c067562e4823928583e89e29ee7e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1af5d1b475d30bbda5b7444839f1c3e3 รายละเอียดเพิ่มติม hosttropical
реферат на заказ срочно
https://porn2p.com/video/27d034cbbd3be313e225354e0d15f3c6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2e83aeb45e9506c2354464f232e7e888 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/35581bde5fd6880bafdd3745cb6e2265 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3b5b50497f53d8bacaf9cef5bf1cabb7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/418bfa81d253225c51a9f0d1f5dbf68a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/47b70264d229760334061f54b85a42c9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4e8077195e10fdd0ef7de380fa27e607 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5b731c22a3af571ff06f66a1fdb6cfc2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/61d6f8dc85b7f03cf99ce02a9724fb1f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6f49c171cb2c0af87da8fcf805b7f1d7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/76a300b26de2f8a2eaab2cc4c794f5fb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7d2fc5d0a61631d5ca445e8571db4cdb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/83dfe3bdb44f9b18557ad6e982c4d8eb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9087e72494984a08b1491b6491954dcf รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9738024bb1c9d7ae3f2206304df9076e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9dee80e74ffdbeee4fd0c265bc171528 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a49fa8d430e4f42d2d770502210fc5e6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b184f3228f9dc9e8e089fd4f7a66e267 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b7e16f698afbac5e98296dae603404d4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/be75f87c975fe79a3dcda5c38b26c33a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cc005867ad99ba2d6cf65974d340b102 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d2d0e4d95f36ccc7dea85c865365b576 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d94a0c6069e4bc3c3bf4d42d46e3d2fd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d3a856748209b4db12929de6b1d406b7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da0aca94e10d6dc84f881848c2fd5749 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e001a377373f3178182aa3ef5f141d34 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e678ef378f3e10a04a51653b06b89dd1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/00e9e1c7076c68e6f6e891b13bf16ee6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0b9c9e64a7a6b7fa81dba7ec48dc7ab0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/116d984331e6b1c13b732b6212c21315 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/16b3c43a32950ccb0bdd86fe36e9f491 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/272ee33cb46abae1f3f2e47cd1af9dac รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2c345692b3ba96456be2a06310acec30 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/377af4ffdf8e227bdb42baaafd003450 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3c0ce1141172503a72fd5b4ca3234baa รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/41941e0120df0ec8e77fe3e6cb7aaba4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4bda37ef6c1c14e730262ec571d1c68c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/516d65582bb8e08e3f924a12b218fa3a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/56f24f24e061e362c8638c57314de388 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/618a954e0d9fb0fadc68d563f01dfea0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6cd720cc3401af26c736823650c402d7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7295126207bbd1d3aa0791b4e35e3ab9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7d4f1afef680559b5fdae9b3f8693171 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8234fb3bdf203bb7b8a7fe5a5ce7db78 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9276ed4925fdae19e3c82c26ffd01f47 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9805f3a435624040408ca7dabcc22830 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9d2e1bc09956594b7d6f54fb39c49de3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a2667179677415a18430af4d926c95fa รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a7af95e368912cfcd58b7bb5301bcf70 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ad5228e90550b7d3243a2be9e00ce650 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b2c65955598dfd5dcaa0f5ef19917aa3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b817623761a7bd44de627264fcb8cd60 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bd9c7d5b611a2fad54f15e4fe17b6386 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c91a3e8ba9d91b92ed97b26661c69488 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d367da12e6d7e462a0aee0dd3a37c977 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d983c982bfab923557e29107fcf8d3ba รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/df3d46957f2a510dd574f1bca642ac45 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ea976369121acd338a138ba316c86f2f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/efbf93cbfcd7a12a941bc3b2971a15cd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f58ad1119bcf00aacb9efa52264d2bd6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fa9b7224fce3eb660963da490a5d70e5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/01a68f0edde932418fb1bf5e35f5faaa รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0752aad949fdd27359d60adf50f3e6d7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0db6d9c2fb4d561541a6d7009b6470c5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1494ae729e25e60716e2990d0c0443c4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1b9d988b2026b8bb92f3d97e9b2b0141 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/224ef13fa1864bc9d53beda80de1705e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/289167ce88f7aa21237c0fa1857463d0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/423682b8306478d8dd18ac9d91094879 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/55ec2a80d77628ec5c499691e8ff16ff รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5c25f3439cf45e33347a7bdb63320bf9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7739cb277ae6f2662f9982d39111d0a7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7deccb61bf98152f2e487e03457fffc9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/84c2bfad793a474ea069f6c5a5b25c8e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/912189cb5e98c58fc72f01dc2e11a9d2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/982a88157db0421d9680f1026c5792ca รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9ec9ad4125104191862decfd4399f28b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a53b010e159d35a875a92b0e0ac313c7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/abc8815814e3f57b77d3ffa417afb77f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b1fd0eacf5ed3a95225c9b1640e3330f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bf282dcd7ab47f5587904c7b90a9ff8e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c637dfd9ac418c880cef6cc439222ee4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ccbf52e07138e9e722bde62ccdd84dfd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da11a6896791e1a78182e949f5f5663e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e00a04f27bda8380e526dade3b21f9d0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e685a339092365bf7f0fd1336c1a09c6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fa3923364b7c069e0318e1187e644340 รายละเอียดเพิ่มติม hosttropical
Aumenta tus ganancias con el bono casino sin deposito
casino online bono sin deposito bono gratis para casino sin deposito .
https://wuaer.com/video/00ecb8e420fb889e4ac387158d424271 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/05c4aff45f64927470c62c596e7857e5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0b9d383ab581851d67f0ce66f632fdcb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/16c017c938a17b15da943ca4e0acfa84 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/11fc795c6be2fbce2811f92c98fd51fb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/17130e9373aff69f3e2a3dd34f95d835 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1c5e77a4c353f6340f49976dd85902e7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2ca94d09c46365b037052d94a6e6fc01 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/32a73336d08b1935568053ee04f1e615 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/37cad491eee899693dceae4d273fd93b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3c80f73a02bc9df340c7034a4ef3a979 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/475c4d585127052ed1a8bc0d01156781 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4c6a9d3cf0b204c49f37518b69de6e83 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/520022c5257a080da1697f5bf1fda660 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/575e74b79f5f73ed9e1d0458fb54b1d4 รายละเอียดเพิ่มติม hosttropical
cassino pin up: pin-up casino – pin up
https://wuaer.com/video/67d9dc547dd4ec172395c19ef7d2d55e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/730c8faf8286a25635e981676f9699cb รายละเอียดเพิ่มติม hosttropical
https://telegra.ph/mostbet-hungary-03-13-2
https://wuaer.com/video/8290c0134494a5d3fdff9f0296077f2e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8790996d7786f4e379b55f8aefc39d33 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8d7f57351016333545387f9ffd31ce30 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9335a36ecd28f99abf6f56f1d4616f5f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/986c4caeda0670865f4c48a23ef08170 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9dc769fd78bc5d56909796a417be480b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a2c83a564fc4cea9564a2fe0be6be9b6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a8233f9899c5acb0f1b965a4e7e82eff รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/adebb47ef94559a566c9a27c5ed88f5a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b34f79170f8da80edf776b66c7e048a2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b8b7d2481e88f5bd7875a88c14cddd3f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/be1e23231d2f853c1e22a3751cbbff6d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c4463a1bf86ce1fa37c0f2acd197d9cd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c9b02133757f8636bae09bcf44d826dd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/cebddf49d2b4ce9da60a03fffc9e8e7b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d9e82b9df5de34067c275403df3757a8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/df91e2c22e7b64d20b6dc45ed7325793 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e5600b911e6757564d08af702695abe8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f5e07a09ea13c26aee816175cca55beb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fb5a124b38b66afbf84cc2db0d6954f2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0e6578464ab136e2c2d39b51411f8488 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/152162be138b1a7f64ce9761a2092a54 รายละเอียดเพิ่มติม hosttropical
выездной бар
https://porn2p.com/video/1c177f4d77b154d85613dcad4f2f38cc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/22cccc1b5830561d4507d9072bbbf56f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/28fe535bbc213df9462fde481825f846 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2fc64420489766768b44fccc8bba8da9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/365fce5ab27933aacf2de4496354f62d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3c63a49f1e3c8a0bb0c4c7b804d99dd3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/42c14bfce411778c017e63dd71393e09 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/48f0ba2f76a33fef76606d200bd7aa0b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5670332ad238f8132864a4832f36cd81 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5c9e25d1b41b192e0f19dea9666c01ae รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/63280a298accb34296531321bcb0b309 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/70adf77c3b71be4026c18aee2e4a8780 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/77c476ea322d53d424380c5e18ab7c15 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7e7c91887fd03780689c44fa8a4c4430 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/988ae25713b07ff67ec24f529941b130 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9f2ae789efa812b4e02d571942183d13 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a5e4b3542e96709e974b6f4a6e503de4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b8fecaec7132d050f2c0caffb93c20ce รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bfeba09daae7fc9ec2b92883a51037ab รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c6afdbaf52557595a6166af8c2838c8f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d42de6872cf4033a1e4ff48661329b0c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/daaa02f0f557f08f7785207478a8ef58 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e07862fa074afeb85d72966db4037b02 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e719ee7858dd614f01f9995471c2e26f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ed309f2a4e0c363b947bee47be918080 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/015fdca42e6bb7b209640ec7a8b42549 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0662204999d51eb9072af40c70d39f4d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0c257d441ca2e82beacef0b2bcbd84b5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/11fd3dd310e96a20e0546e8e19de91b0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1717a4a068e0433d15ca83e91256c017 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/225a1854d4db732c235a82cd1da62a2c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/279690b31c48d3acc765be6b30fc9e92 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2caba1ca122cc2b5a187660ca1730639 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/32a7b8d0be7edd97eb00ea7a4d740cc5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/37cd40f9bcf5436f2f154d3e8c1354b2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3c8908673ceb20e4f18dc03702b7eab1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/41fb4c2d9c20c7c5eda813d48cf4b43e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/475d9a5740c84af5f496dc39fa986687 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d4bf861a2e7df887f5e56c4663d391a5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e107536a1590bbf90881ff256309b988 รายละเอียดเพิ่มติม hosttropical
Выбор электрического духового шкафа: идеальное сочетание функциональности и дизайна
https://porn2p.com/video/e7b44d9feda4d49e286bd8c092f86882 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/edf008f5c19b7a18692cbca10fbf66f9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f55cf51901cce44491bc8ef8dca2f1bd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fb71d45d35445a9e776ecdd2d18614ca รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/01d3e6e6e8ee67d673134a920d2e7a72 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/06fdf6358415d3fc0336541305e1de9f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0cb1d13d7278dafe5eec9de07e2119d8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/17ae7d13f18e6b4fd775c92f29203db5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1cecf7cee9d5ef554a86aec0b392f113 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/23417ddebd2c54a496132d31c6a37d1c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2827073cf130a283e93cd99817832cbd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/385092eb6e35809963945edacf35aedb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/42a0491f7e3c0649601015980a8259ef รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/47aa0caa82c90872d5cbc9fd71a5378a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4d0ba7b3627acd46e0455ec97dd9396d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/526dbd639edc42a998118318c0c6048d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/57f01fca927b5201ef0653a5f6f9f18c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5d24944b6f8cb4a5113743970f3ab5a5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/62dc4f927d5e8687abd6609166e2014c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6879fd11e571f16415180976ad623f24 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6ded3828550f3b915e93fb7aea286ca4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7e3ab44b9b3d0df6df0ca6720414d0eb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/830cbb3d0d0f7b4f9450f58321322f06 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/883985a82a6e45bc2934ed3fec7196de รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/93a628cf73c34f9d98a612478c1a1fd9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/99220f70d239c56e1a903cf3cb521c0b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a3471d193edf6cf467af6a9f0a712af4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a8d7c6baee5e17b44d216741144eca77 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ae721e396cfa1ee5efac993d63ea2562 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b3b5516234dc00182ab1b356250b7280 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b963ead4247de79bb390cd9815ea790d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bef9412e6f365c07200c7faa1fcb10a6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ca3c2c4696a5daa0982c1d017f18539b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/cf523bba94181afe815eb2df559bf09c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/da7c6a3d6b71c4219a50f397156d45c9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e007b64eaab9bda42ebc7aeeef04472f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e63ad9758fc2b41c8940d47d447ba125 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/eb84039ff819e202cb9bc1e2d7927b35 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f0d8087794007ba6bd27ef5a110791ff รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f68b7fb00bb5a986fe19518d97754fe7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fbf1bad8b52a888e7c8c50e7fe993c61 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/02c0a2f3125350a9ae189d008418ac06 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0873ad828e081444829498b28aa7ba6e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0f136d6917b90208222db61fdf7ad9d0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/15ef89bbb32a1c9b6be395870b274414 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1cd29815448376989c7ae64de37a2988 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2973f55b7b80f34bf7dd46f6b972dad5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/305f9dbdde15683c58dc0c21abd82099 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/36e3aa16e74998ddbb44bd0d42f063a6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3d091fce5c93d281181c349a1620577e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5066f4ff4c2646c617fbd4b64458ba0b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5d505680354e859c7f618281e50bf2ad รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/63ef96796fb36dca64a7a1e541442c5b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6ad1aa2c688231b67f54e1a01c11f94d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/716a638c92256fa0161f89dc000bd6cc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/787542ba1ae4bfba114b85f318357a89 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7f344f91df30558012040da4d7db8575 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8c0e6a2f7d5cd268b17ea1b73c1e6019 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/92a8c5de3be40e3f012973cc997d7ea1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/993a6dde743dd2894a1c477d66db4d67 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/acc074c7ca441c112dfa952e4f00c3fe รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b33213d35259b37d1abf38b37a655c2a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b9cb1dd15b4733688d69e3251c22d08b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c0ab133143913a50551e22010d8652b5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c77e6265ba8c1a027f25612e89e45836 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ce41db8dc6527d7392ae129adc570db8 รายละเอียดเพิ่มติม hosttropical
https://www.metal-archives.com/users/shmit351df
https://porn2p.com/video/d4c6c01999460dad59da09e7c8c4956e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/db5d2fb130af3346f0b57fdd57e09693 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e10a3ebd4dc48300fda5957d677e5939 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e7b99c8cde6bcfa4fb9dbf4641e45f94 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/edf4b1a361c166d5ed988803481a705f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/01da7f2d44d72f0476d3798cf18320cb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/06fee31ac04bb92bb85c69ecd6b01b28 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0cb24721df1c44364a5ba2a69c30352f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/12759615e6612769a39a8fe86a459463 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/17b7488f8327e9d63760b3e987f1f508 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1cef2a46af61ddcd28a88ee6c9f9498d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2342757ea35bfbd225116d98508a770b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a0ab47f5bbb8d2803c190674e3c603de รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a76437fa32d6e85f239a47bdabc8435c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ad65a11dafcb3d46d3d6fdcbf7902eca รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b4018448bea39e091f254ae70237d20a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bab5b2e1e04dd0ed0713a69ceb9c3825 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c145aa8a775f40993f9cf4fca4b1c237 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c81b221390897eb6ea93c6bba75d765d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cebcd2f5e4a3bb227ef53ea7f8f7cab2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d583a89e0b344f0bddf26068f06b61ae รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dbf3f92db175acf251f5a458f6991e8f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e1cabe20d0087039ec94d57a6e8cdfe4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e864e8d2d6b950763363856ac92e2eb8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f60092ee14a4d394b80a8345666a7d15 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fc1be21ac751d6b73873e0a201596e5e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/024d9fa85c58380ab8511c66b40509a2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0d922db01459a69fd868542f0a07c15b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/12e1f21dcd356c266361fe9fe4a0530f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1874ae5a89a2cf7f004a7f708b4d0220 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1d7fd74f0c9975c177c76d4cbaf5ea1c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/23d40051887d578c9136e39f98aae8dc รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/28b59767ba9c064ce93cb832a0bb790e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2e2f28187bd9cd3b20a5a184dbc7e0a2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/33c78c4d4b8b37ef5f110357aa49d62c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3db5aa187df9297695593d1339fdbd0c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/431a2824e0333ddce8b2da1ba05db077 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4850f3f0515f4ded805afac03b577210 รายละเอียดเพิ่มติม hosttropical
Где купить диплом – Это вариант обрести официальный документ о завершении образовательного учреждения. Диплом открывает пути к новым карьерным возможностям и карьерному развитию.
https://wuaer.com/video/4d9b32cc1aecc2eff86899725fd78c62 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5323612549f2ea4c2f68034b57d0bfeb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/585f240ba4fbea38b93858515e8f4f51 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5dcf4b994dce97bf40e102f7fd79e72e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/63798f1f04331f4c8014a3402faae542 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/692ca9eecfd8bf021d727679a91dc37c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6ec5db442ced78e142031ef07e72b192 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7414b98fbc94123c28b520cd59f8747b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/79bb261a09fac322b502ee8623bdec2b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8369d17331220791a4c55dcc5ca7a459 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/88d7ff25f2f79a26bec63464f00fac07 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8ec873c197ea6f9cac0d014e27eb0ddc รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/99defc8ecc43dc1c4971b01eb2de9a8f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9eea6e55af9202d95e9b1e4c8d255483 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a3c7ca980fd10b7dba35d86a474f48e6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a9834c7157ca94e94874df89dcc1a093 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/af041ff1df88e8a50c28c36e39958c5f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ba089d80d68d506cd962ff8a5f498e78 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c53bb35e78e66e889c256b6138d2b944 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/cfccaca7a3593960ca2c32f7d2af6ca2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d53406776aec1b3df36e0b38ba0aab11 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/db2060c23b7f08021dca6143a223b062 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e0a49e1a943ed759aee7df2418e114a7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e6b49f9a7dcf7f7a58a326688a96b2b1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ec0e03c04940451f622e4f2aa1c877bf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f71ce6ecf79e95ebd5f63cd8d45a6456 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fc889b5adee24616dab0e468c1bc580e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/03a1e7d43884aab1d886786d144c7645 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/091c0f5153298433321fe7254ebb05cb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0fbb3ea94efa4027ffc5cbbc3a089572 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/16e96fd036c773e7a2b7cd667acc77c2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1d7c0b627ac71d20de03e3588cf0c436 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2a42c821fc0ed89efe2b0f4a4977d1a6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/311ff8b764b4f4899cb821244d05bec3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/37a392536153e2bd030370b701b61f45 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4401fefaf4086fc02561da4e80a40014 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4aad4be982e9a6ae44e941150b7e0ebb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/50f5740a342c20c807be0c3d6ccf3bc3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/57c23485263c7a57f384e562e9083ee4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5de14a02af1e7ba6f776117df645fe45 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/64e6a15bfd94ba26cf9f1d87a139cf3d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6b9f73449656760c043cb3e16efe9421 รายละเอียดเพิ่มติม hosttropical
Купить диплом о высшем образовании – Таков способ достать официальный документ по окончании образовательного учреждения. Диплом открывает двери к последующим карьерным перспективам и профессиональному росту.
https://porn2p.com/video/78fea5d4d77014e7688e02425ef925b1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/80127723b2d46b5e1792f9efd50aa280 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/86c76a499721252d3c50b14a6ca92e78 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8ce1d2c67c1b590da552cb6368a69576 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/937e9668448a8584c0981c7bf53ae0bd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a0ac9a1f36fedaa724c60cf50a3ba69a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a7677a5a5535e3d440dc59cd14cf54c0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b401fb3cca320f08287d1887694a4884 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/babaf8a6e6af06dd6b4f3248338d4899 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c14d33c252c45a30552797a7fa714425 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c81b53bf861ae5e44d687df639524c7d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cec56ab8a72a0c01baf120b9bcd4b72e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d58421e8b7a802e1113f0eb464dd7f4a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dbf751206415dd7af4565303daab5f2a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e1cd7004fd72e24ef20cf580855708d3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e866028f412d43f921b0bf96e80f42b1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/eeb7fa460f95500fc6a6273f58cc87a7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f602001e4d59088f4b452bac70178de2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/65b68486177511c1ed43ebb4d91a8b2c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/72e5d6ccd074d35d88401ca5013eb749 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/79c05ac3fe99dd597a2dd7924c6b9502 รายละเอียดเพิ่มติม hosttropical
aviator mocambique: aviator bet – aviator online
https://porn2p.com/video/9a983c600871581051c013f908d5e92a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a150d3b0cb894cc023a611e5ee2e937c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c238a79a203b69dd4486f6f11464e458 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f67bbffcf63dab7a660db6920d28088f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fd06363f77d0e90f448cf4b26ca8c4d8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/085591ab93923b13460d84353e6ab692 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0e3c5544184397f0478c09581f5e222c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/136158ab3a985c392d1e8a14d30486d0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2944ceee01d1d610ee9c2d92e2eb7d1c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2ee21ae4701b214d447a299b8cd37b88 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/344fbfd5577ac932b9d488e4e4cfbb23 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3973f612f02200ad38ef101ac77c1851 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3e67805c3b4d477f950adf30e92b95b1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/43ab9caede78cf64253dd4705a09af1f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/48cc5db0e8893dbe595b3a4bb1c21007 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4e4e3e927780715080efec967fc4f6e4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/58fe9f927d516fac6a005006a2ae2e85 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5e56fab0f75823a39c37c22dacc264eb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6414675c3d652b880f4d1f7090659e50 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/69bd6525457919a0c6378f0daf1e47fb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6f6aa7bb3fda00f6dd8f9154fea2fef2 รายละเอียดเพิ่มติม hosttropical
https://vavada15.life/
https://wuaer.com/video/74e1b48ce416cc4e891e3d6cc69e6d40 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7a56810e98737594e410d0cef0c5bde0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7f3929d4b2f2636f682506a0ec193522 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/83f60d0ac0707020746c6160d75edfb8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/898c44ce8a8decdd7fba582fd1a4d4e0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/95321e495cf3892481ce8efd7d8a8487 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9f734433c3680c9af582aa69533f94a5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a4453ce1875b67c96c9d8ba9cf8d487a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/aa4f942ec93977772a81ae5cf6dc5c3c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/af776d61067d4fc4de4163e7e370c2c2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b4ba133c465bdda83fce682d1b8d0560 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/babd6f5bae668745ddc124df72bcb1b1 รายละเอียดเพิ่มติม hosttropical
jogar aviator: aviator online – aviator
https://wuaer.com/video/c5c9803a70ccd85c8b9049334e0a23c3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/cb3f5c085426ae8174e8e0fb678a015b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d07fb78a946efe8bb7ee2ac4466aad20 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d5edcc2e3f46ef717ee8144ce7af3884 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/dbc29278d7f650a6cfdb4c8e9dc5be78 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e17c92dfd9580a9cfbcfbe38709b4894 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e7541f79984c598c13676ad21a3e0103 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ec9a21afe21d7f8bd5bb88be996a51d7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f21dd05a6a4f815906d406341190ac12 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f7ba9086ef3180d98f847999a80fefbd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fd2901edc3aea1a594d23e51a2e39ee6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/04693be9e95f20ca54185af9aeae8297 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0a127192216d4f0445cd67ebf3ac6716 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/17a740fe3b8683deda2928f5c20a3b03 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/24b3c4f3a806cc0d9a53942a5d429a0a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2ae4df31eaf59c906a57435da3ea3b8a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/31f5489ac11b6acb3002c76840b492e7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/385567ba557fccfc2fba9a70650522fa รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3e8154fee828a0883ef1bf42d2f1d865 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/44b31d191e7b89f60a9312c4a77fe1c3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4b7163431f945586131d9fceaae82d77 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/519b4ea739fa3cbb0b40b60cdb2df3b7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/587730f6e38be245fc56efcd50308f8c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5e7716d3692f9b7b52c36925c2d4d2bc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/65b7d263ec9288f35c5617bd9cc2a6e6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6c492878fc608da953a230cbbbf06110 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/72e5fa986c2d0d7aef5d746e768c295f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/79c4c8bba896fcb8a179d48eaabf2134 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/80adf8d5240914830300027c6cc827ee รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8743714134837afa97a022e42d3dc3b7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8d57ab092995e7905c89641e05612ba5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9427f476f10911908e5fb52004e6d825 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9aa413b3d729790c915ac963e4dc0e45 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a15855da21c566b2905730296da053ed รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a80441d8cce75e5b3fcea2c68d1130d4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ae2628c4a4e859f182e47a6eee2fa155 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b4b74961462e0ca05a17f526c63cbd49 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bb4a6e093192d192191bc382382f714b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/75564aa17b24c3296b188abdd50d4811 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7ad2a40c6d492a0abafc98a6c8fcc04a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7fc96f571acc62f2f68969e274d199d1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/84a88139038ef8be5040b3fa1965c94e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8a11ab9f9fa68c4da2b983adbe71567c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9002632e63bffab4d5fd739fadb87704 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/95b05d09463d034d2fc47fa25033ddfe รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9af283f358361ae4f566fe3aa9f12636 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a00e0e663c9269deec407da2cd08d126 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a4ca3531ab1d130eaec06cf88f646f25 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/aae5d955d2a911a9cb17d3939ebf8815 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b010fcaf430b3847286825e79745fd6c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b54b599ad847b4d7afc802661d8f6015 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bb333ab6a83003243104579222676e0c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c65416012b633efbc4fdcff226813f1d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/cbc132951ddd3b0df65aa12bc0e6652e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d0e8831ca98cb62a867e3d0c1492fae6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d695c678ca3463a76eff8a09b9e7a124 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/dc4f764d28191a090f687973d217b83d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e20ca559e05b21a448d3899bc0d683c1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e7e9511525b9905e9bc3d854f1941ffd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f2c808431e407d4aa70c0c5cdc9171a1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f83ea6ce5921a7bd7513c0a09506e30d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fdda8a593c6319a24011926bb4c102a9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/04c4fb429d789d0c5eee1f6bc17ea931 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0aa44137f0a87868a39332e26482708e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/183d52aa65d50fa019570d9a01df11a9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1eae9831c75a006966ffb7056a21a458 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/255112d9af06904368192b4864e7db05 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2bc9cde11c86e3f4ee389723e59dcf76 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/32a8cdc55ac2c27d1ea63272d09c9c5c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/390553e94c8d2eec096275b055dedf95 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3f387bc3f4084137a9b573a298fd8a9d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/45533abf60a1b753d12573b1f46ce22f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4c2e2e94c6011486b22c0bfedfc303c7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/526a1ad529a1713f13912eb82bd94131 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5926c1315ae035bf2226e438d8be108f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5f022cedc052631277b01087f6a42544 รายละเอียดเพิ่มติม hosttropical
То есть, виртуальный номер нужен для обеспечения приватности, безопасности и свободной работы с десятками и сотнями сайтов одновременно аренда сим карты
https://porn2p.com/video/66532b7ac2ec740615e551bb5065b3fd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6cd4d32d1d1e31a112412b2efb891751 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/73c76e4141ece93898ab2d47cc8622e0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7a629965cada67f5e5e1c93f5d53d8da รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8166345cd9f756f84ef1043c7c07cf53 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8ddba0bfcf91726fb0a294ccdd530161 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/94cb59b7e967b0fa66c1204f70e948d1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9b7f318506204e909d326c540cdfa870 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a208ba32460103a57b4271a27553cbde รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a889dea5aeefae50b031dbcb1011a05b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/af19a416285304088dfa594ab96d60f6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b57774e8f6698c52fd92c8757e1609a2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bc131b5e08ef30e3528f78cc2775924f รายละเอียดเพิ่มติม hosttropical
I am truly delighted to glance at this website posts which includes plenty of useful data, thanks for
providing such information.
https://porn2p.com/video/c328a9e78a7604d795537ac19302c3a2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c96e0a35455f77c9d228c25ff0148481 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d03fa2785389c9c25bcf1c9b5587dbc7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d6ededb8f21e12bd81bc5db734031cdb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dd3b4f372c4ac6ef87f3273b67abdda9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e32a84725ef57c44d6d6d728ba7046df รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e9bae2a7b06045e33b315dd58fb7b7b0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f05ed445cf130e50d689c87baab70493 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f72776fff276a712b1d44a57073e43e1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/036bec87ea98982635941b2bd217ac2b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/08f5c977160c0c9ec00b277307f18dd2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0ebde5f9210c8b06c28e1bd09edec598 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/13e189bbc039854cb132afb49707715c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/199568eddc82d95c3e41faed19ae0bd5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1e9a310f4fb28b47fe793e61cee678d0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/24ebe05192fe11688a9c4549a6218427 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/29d0669b27691ff92b6ad94c5cd487ad รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2fa3acc6526c81d1947a1b98ca58ce28 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3504c686315725677846703ff8535377 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/39cfdc52d63fa6cef74297f251ea4be1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3f0affbcacfddd8372e3fb7b5f8a2baa รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4415f647e1d14ab879134d4c28544af1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/49835688ebdb6f5f855704f736c676b7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4ece90c89aba88158205374cfee2d7f3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/547ca9c6676a2951db01615a6f2127d8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/59a256b4f63ba450ab16220ec2a74138 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5ed59be2ea0a0bfd2eb9ec9b825453ff รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/64b83f1d39804828fe99dca73bd79ba2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6a40a670d19f9d89061a95844655f3f2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6ffc310cf5ced10190ba856ffdd52e11 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7558b1c6b46973fa4468cb28e3f154d7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7ad69c35bdc459893043aed867f92b69 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7fd45f4c8c1389177a1df43d5e6e9c34 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/84b49d0502e19ac2f09fe6fef46a3c39 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/900bd71c690f025c508939a51da0569d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/95b3d3913c3def1f5e5168cf6e00f9e3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a011b2e0448606fdab42cb7ae692621d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/aae933ec00368c90958738a122508c52 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b015cd9bf98909970447e4c3e538516d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b551aebca623386c9545f489c2dd1c9a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bb335eb3f3e89a5372b00945f66ccfbc รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4f35f8819e51ace7b1a119ecff5b1a8f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/553e21c9df32f06ce0c490e188fe4123 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5a01a2d22e6d6a77ae17091d0b84bcdf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/654f49f26c7d13c219818e3424a11def รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6ae684824ad25ae5c29f137e1684f1fb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/706506d6d8dbb5048a86a662347fda7b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7611d3d83083d8bb7ac4e986ec90e77e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7b82da8b428d85836cce21a3d8fca98e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/805ae990068ecafe69df6587abfd3fc1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/85334df7437cf33165bc09053916c34d รายละเอียดเพิ่มติม hosttropical
https://vavada15.life/
https://wuaer.com/video/9098d2584ff524ff9f341d91aede9206 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9654465256205faee187ef20b28a40b9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9b68c34b16f2ef2821517dda4b40db5b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a090ae21774255c4d1d7036b9329e16c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a5a593915b82a55afd6f5f0929a38b14 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ab775238ad66c5fb65dc455bfceec048 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c70fddd1ee284d65535019a92d404bef รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/cc7255e76136a80d3ea5c4501d7d2c56 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d18e2b581236e8d11f87edd27f0a2a41 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/dd17020f2b1c583aa449516ce5e19246 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e2b85e18e7ce07225355bc2bfe7827a6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e8dfcb3f7eb71d5208b0bc3fae0765a2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/edc391494ffb27258c91c2e5295b9e90 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f8d16df9cbd25afcd7d9d4d6d0864eb7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fe90a95de02d41a336099aa22fe6249d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/055df2da7344039dc0e3a1c5bf995def รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/11e67f58aa5b21a1c4871a0fe9fcaf48 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/19046c5b4ee4c696092e4917ccb37fdd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2c9e3af35d19a1dc7e7f553aee851ba4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/335b4380947942cb45b8c5fd746d64c9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/401d08332aa89f37e67153fb8e6a3fa3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4607a506725e6643e8bbb4ed48579c8a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4cda1351c9fdb235fe1210f4d7389815 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/53312628ff9b5d9b037d0c9a9294495e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/59b6959b1035c1c3ffb6a9713c9a2846 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5fbab198a661df2f57b4cdb8d1c4b09b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6726c3b4f7acf3f1e6972c3fdac0540b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/74c77d0c45402e285ab169ff7c1e52bf รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/820ff59bea9e70a3f9e9da1c8815d80b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8872c712701f71cd998418d4d4fae9df รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8ecd6848184ffd05d1108b28b33d5324 รายละเอียดเพิ่มติม hosttropical
видео стены http://www.videosteny11.ru/ .
https://porn2p.com/video/9584a99b8cbbe0ab6ef6338e39550555 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a2fcef7521a6bda3827459210e0b3c55 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/afdd7c676c42b0abd9599c2cf77cc89c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b5f69f18dd5b4b0fc90d5c61caaa6f2c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bca721dbc5e6f78064429dca2125bc58 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c3d2606507d98d534dc8daefb2b52e57 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ca21bad540c309bb33cd42d566f1dfb5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d12c4dc279b5ad19dd8f9ff621a23990 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d79cf0a4d58e6648aa5690384ecd7006 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ddf31ff6186ec84100067f4e180ec474 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e401a20412d14235caa845b2731f2b4d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ea54f0a7c6c2777ec64b15483f607953 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f110b342aeec666ef3236138bc2ac73b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f7ebb4028b46a07f7a1bfba7fb9d9979 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fe7f82d2982bca87dcc877ca64c9c707 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/03f990ce98ef2f1833c91fd5520453f9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/095ca9c14dad3d647b23ba201639e48c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/14738bc407daece15c1d723b4f41ca5e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1a09bc5f43e83aac89df3781925c2e26 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1f206bdc5c45b285e4e5bd61c490bb5a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/255935a08e1da71221b11f7a91bdae9a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2a55a3bcd8bf6e00dfffdafe894e2c2f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/30217b3a43512aa70b6e4601a21f1636 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/35d88fb7c892b672d9f0f13aa6d26ea2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3a43fe311e43768e160f6944bab5026b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3f93730bf38cb2f4f6ef7d5f95dff2c3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/449c9cddb1ae6cb8f9f7dc9d2c95fe0e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/49f5f0b04626b30fc1c2ce67d7736ae4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4f3677ab20dafacc0c07b6a83d99f35d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/55499386c61ada6fddf9335769451d96 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5a029c5a0717bce4fb2051e4cedd07f8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5f4238bd4a1294e871231b97e50740b3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/655079d0eb2c941c6762fe55d3200ef9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6aebc236b5e3c323406437d851aaa868 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/76151db0befb5d860633c8bfe2795965 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7b8d02f78bfc56bcebefa29819c496a2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/805e249b7f82f6a8ce72be501caf9f51 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/85393c877aeed62ef3378a992142e5ac รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8af25e99bfc6497758d39223b961f24d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/909ff1f3ffc0d5cc867257a066c4c7ad รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cb0e69d4da0f449eb101ce4840ecf70d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d1da7219e16befe860c8f6d922cc7299 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e5005c0bc9bab8deedb2053c31498d4b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/eb1672c959b0ec6a13bcd37ceabcaeaa รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f89aa0ebb4140eb11798b01de5177f80 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ff27b8a574fe4d43c9fed21d0d115d2e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/048d9e08982fef4c1706292f01e615b9 รายละเอียดเพิ่มติม hosttropical
бармен шоу на свадьбу
https://wuaer.com/video/100fb2bf709af2f8ce5593effc4bd63b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1ff8bd9050050827b5f69c1c6358d846 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/25be5777ae93a4ff36bc69434b354c79 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2ad703b46cd583c15a8301853034dac3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/30b1430a6ddd3b96fe2e15fb576c6c9a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3640065e4208130b1a738dd0065fca88 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3ab066d461e5e1030cf6f6e04122e27a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/406fa3eb388248dc0887095bc063b621 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/45130359590775dccf4fae08106ef8a3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4a8576ad9db06aa6effac9498f7cdef2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4fb888335c21a32e0ca0bd257a753642 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5fb1a7a995092e7e16380721f7997d56 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/65e7c4862524bba60f187ac8973bf6d3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6b787b57b2330ff44507fb3195b9cc97 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/71063e4e5700662ed35ee0e469f0119c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7677893f567c21fed20a76acf389ef50 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7bf434435a0ddfe1a2f694b06778e3ad รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/81195beb861a1840b131c8c809c0ec3f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/85d69d34bc8e9bb3fd2de3dc9b892617 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8b6f351837501805152a008f2094610f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/90f046ae1405884ad10f78f1ef9d6bad รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/96cc2e96e3cc5df53512f876684375c7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9beceb1f9ffacd98bc065ae1935072dd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a629a2ff42bf4f08cfb1e43982030267 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b15bc03bde43dc2fa36061b2ff025c58 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b6a2a6ad0a544547e27654350c3b79a4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bc34fb9196d0b54089813414e2207101 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c1f752b40fb41e04f118a53d9fbde79b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c7c1c46a48090e644005cb930ec1c009 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/cd1b5521d6f08212d8645ecd81c5412e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/dd8c375cbb2e56762b8ee58266f5ab2a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e33afd74038f4665171a2911b26aabbb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e9717af3e1b8eda6c3425090196bcdfd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f40cef6916579a9e2fbbd3b38afdb523 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ff2ca7245df43aee447856ab8c0d6873 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0be8a026882449722c0d624fb01f41fd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/12ab4e06acf117c2797b216de31e424c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2044d651748db3d310b6e83d70082a43 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/267a96c78d6964fdbd3acea0402b2ca6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2d7fa89529af99a0a4079dc62c2382b8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/341093deb7045db01935d2a542500cb3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3a549386c63cd3a86efe64f9d536cdf3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/40b5daa7f718ba12d77c0820f6185553 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/46979d774c991462a10ded92e18e7f84 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4d9f4ce7f342ea9ec6f5eff02cab6b93 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/541fa999ff6737b515695673a04aa31a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5a3393d0e2c9bf12e96714da0786d0cc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/608e1ad17e72c47fabb3e3d65203e0d1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/67ac2f1f301aa2aba752e68ba0167bd7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6e36df9e60c38b0521ed85158ec6ed1c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7598d866b560c679c77591e486fa1355 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7c04f2ab02bcd113f1d87d08d8747a2e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/82a4453314c5be8999ead00f3405feb0 รายละเอียดเพิ่มติม hosttropical
como jogar aviator: aviator moçambique – como jogar aviator
https://porn2p.com/video/894b5d4d559f5eb60fa51772438fd9b6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8f8dddab2a74b434feb804c06efbdd5e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9627a557f87215b909785a31a17d9d9f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9cf3069b370060065487b3c0a6fd5a87 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a3e8ec6f0fe66f2a6e1b3ff1b6af0502 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a9fc0a75cc0b25a8601cf2a67745d688 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b065ca522280782d46edbd71d9be3eb6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b6eb22f312477cfe7ba72f9d6d462598 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bd244f5d27f50635e9294b5e8c50ed39 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c47fd2e70f0410e610113ad8c1673b92 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cb1420287e9821a25e041bdf80c13a38 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d1df1f6902b5004993e3657e1a0e795b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d820f91128f2bcd760bd5d2c00b46a0b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/de8d5aa4d0d7664290f99d79ee1c7b43 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e5067281446fd8bc54328890a06bdd36 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/eb1c3437b0cff60dde3c7a300c474b15 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f1d523bc1433a61dd38e9ae12b60efec รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f89ff29581ed39a278cc85ac6aa608ed รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ff2f5e87640ce87a9de16367693153b0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0491dc87017af32b2c4ecdc36b55f9d3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0a2f5f057e11badbaa35f704bdac90e1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/100ff20612eebf8d58dd66031d815008 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1538d3800a3ef34e82d1ad2c68759a63 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bc8938f9738eaae7239f23a5315776ff รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c27171f93137bbeae37a681b80906aff รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c84231230295035eed79e2995ac711ee รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/cd77c3774a5e081993a0ccfdeefb39f7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d28d9d3e7f4f02c2067d013f2dfc5383 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d83ffe0e9a859b313e60b91d5d90deed รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/de1ca24da54710f86211b00f129dd045 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e3a22f93f66cb3cb9debc24efe67c723 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e9c2fcb59bb08e4ee2133eaf29d4e33c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/eefd6ec7f5051f8891aee4ed556feb0e รายละเอียดเพิ่มติม hosttropical
A fascinating discussion is worth comment. I think that you need to write more about this subject matter,
it might not be a taboo subject but generally folks don’t discuss these issues.
To the next! All the best!!
https://wuaer.com/video/f9d27b87162920c607715d7ef10fa114 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ffa7fb865977442485ae4ca0861101b9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/005d29efc59506184ceb71dd48de07aa รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/06472f6e0704bc40e6625f5085a7d7e5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0c83c4fed8ee6b777cf58b5eb5ed6166 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/133cb93692a96dba30d3c37c47119640 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1a53ad25b40a57e334c98a671b8e2e19 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/20f8967291cd16c63f4c76c3e392d25b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/27484eec3bd73876ebbb176c01914b87 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2e299aa0cbeec9cb0b897a7be5a62755 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/34d9d86819556e7f9a5da64ee4935e47 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3ae82973448bbd3d83d57655bc84ab4a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4118857ed798c4e81772d9bafec5126a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4734fd5d30ddb1f3fecc4f69747b6bc3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4e197dc534fb5721eb2ed4aab93714d1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/614020533f56d65909270ad702fb5332 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/682fa93589d68835ec0e4bb4acce841b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6eb6a80429928fd05f32b3ebd82c840c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/761178dfdc024437904c2e4ff9da797c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7c9031a404279d3f04d9fe9560f5858c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/836acb0a8d28597c42a5a1c7f9b59bf2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/89b903c4f5bba615655ebde09283e79f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/901183efbca67de9997035891b175ce7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/96c8eba298448aea7403581bb67e3e00 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9d7c07e72b6fc31d877087d17798cbc1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a44a8c155899c0b290bf4818957abc52 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/aa7816a76cee97fbddc9d7fe5812e423 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b10aed8d644d55a104dc60dd0b1c5bd8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b766bdb3925798cb2e026facd4ac82a1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bdd5132ab71cc6fca28506012050f46f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cba3e3afb9758039e1166a0813b63c54 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d27305793ca8de84078f2dd8a7c13cd8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d8b87027e133ba21e7044feaa89733f7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/df1c75b6843e65c636813651e90912ee รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e598c4ab0143e6ca8ff42e948ab111ab รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/eb99185fd54ae90e8817033066aa4051 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f2992afeb5c17ac8a9b11d02fc8e3270 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fff96a86113df313e1a02bbf9c916916 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/04df78dce7152c9ccfcf27270e611127 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0ab9166a90aa0aaee7e8950cf634a5db รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/10860fab5de08fef9d353de9a3d35d03 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1afb789b96f5f363cdbbf46f0ae9f364 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/209ce2dcd8e08c4c67248fd47e1e03e4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2b589ab459e3c56e22173279db962915 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3148b0402d689a4b7dc8dc4bbf578dd6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/36abeb3a963b6723551bf8ab606acb9e รายละเอียดเพิ่มติม hosttropical
выездной бар коктейли
https://wuaer.com/video/3b3273bc02da519c2d2918f09cb8d864 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/40cca53e973b1e7d36d2e7947c1f3a50 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/45c9bdab3f2d34a45546ed377373d824 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4aff7825976ab2787af331b2a8f3c862 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5061c5d2793827c1431ea76ab8589d51 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5b0de553f101d9107b98f2e1cdb333b9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6046913fd30fcdfb6c684bfbb176da5f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/666d4f77745a6d9011dea809eca2d7f3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6be9cb91d1c4723040b49a0a9394a7a2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/717a25a9d84e343abddbe0748e01d93a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/76db806928e6b7dfe4fab38c658a1b2f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7c4dea1c64e7018933a76a36e0385100 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8193d5c2c5193ef6639ad76d57a9f8ba รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8633d50a633e5db9014ebc35deafb9df รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8be2a84c757416d31b6eabf98bdce476 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9162337d85655e4ec47c30d3aa31f33e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a1a1446ca0f4cf654314f6db92c998fa รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ac6d637290995c01fc9cd429274684d3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b1e0afa8345e178ec090594d73d198e5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b723816db8176757dbd0166ef0eba80a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bc9a135975eb14b2682362f5e13d62f7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c275d8648f888335f14b36e3cc055f51 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c844a6c3a6612c2b7db85ecddba2f8d0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/cd797a5e973afc4422bf2b7874f894a5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d2943c57a2313ec82f515cd0413d3207 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/de1ce6f0fb71de956160b7c618c5ba19 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e3a370061f45379bc728afbe56bfae91 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e9c511832d8d2ae39882aef5587c39d9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ef055ca4441493fa345eae1a840bc45c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f9d3368df2e46aa527b1c4ac0fadfe83 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ffa88cdb882a850d9c52cd8dbcec5642 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e45900d22d8a7ca74ae091ffc4703e44 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ea3bc182b263e5cc03c12bab5e924f41 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ef58184b7a2a14864879f8584ae39f21 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f50830b82841d5b4e8fbb10160d9d4b6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fa28f7d7133e54894e151d5ae1620dbb รายละเอียดเพิ่มติม hosttropical
https://xn--12cgiba5ff0ad0frfb8o5afbd41a8a0hd.com รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/012b2dca19bbfe322e892832227b4cac รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0d2c06f7622c7cf03550e52d261ed88e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1b32f0e9a1cf2740f6030f18bbf1deca รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/21c61b80874004e38a06faa8ed72f36e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/27f5becffd10422adf34cf0de38decb8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2ed38739db1ee59abad2fe954c13a1ea รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3584f59f93e5dbe90e483e284c450d46 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3b85c8fb701ad633bf612e6fb3b0d4a6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/41af6325e5bf83433420baa11c897a4a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/47dd5f5c261c3714729033d2e0de08b1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4eca097ad2ad40180cc98cffe24600fd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/554bfa892f4b7ae30b586b91322e450b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5b91c6a17e41afcb17909cce92e85f45 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/61fc0c38969d24c085ecd5bebad5de9a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/68f4eb602f64e67d7842ef46ca0e560c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/76d2a123c75aca810bb57d60ee7dbbc6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7d84fe14ff983939563839e8bae08356 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8a4002927b59a24762677270aa95ad9f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/90c1b5328cdd688acb9a36b63e51f6bd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/97790c8dc1b37f776012bcb33565e1da รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9e12e98854aa1797836a42b06b4b2150 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a4d0ac962a8b0f2523b622f9a89fc27e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ab5b0a480a11bfa9ce791ba083559469 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b80e1168ab68c5d36c94d5e2dadabb65 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bea8073ce34b41f53b43ca3cb88a29cc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c5b879e6bbf20bb0fbc9f0c0b1d4e24c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cc28bb5b2aa50b3868f48099d0973a08 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d305e1e316c72bd7f760258dad61d7ab รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d993dce5ad09a062a7c53de649b70c07 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/df9fc71fcfe7bd99406808c7ca6bb375 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e606418d65df29595ace0c643485d32a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ec180064c1c2b7d574094c8fade9cc50 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f9e52767f05a55ec1c895812b997ef02 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0096f56a59becd71783c4f4e374edf23 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0b4aca9c1065e00e42a7d2dbde0db858 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1122831d8246274d9ed7055e566aeb30 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/163956a475cab1f917eb9ce07fb2d5ac รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2192c2fcf6847930a1652b7c82493a23 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/26e17dcfba9887f4ede9b606a8f38f44 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2bd52587077a37b08635ea95ca0f4441 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/31ca452d12e4d29e2d49a6114cf4f98a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/37258d900d5d9255449a3d4321ffe1a8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3bacb52ad9139b80930f58cfe19ccce1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/413fff696c66070cb728558d47912c8e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4b81de5f44b76b846c2659429c417ac9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/568deef3b25ed736b375a2823b61347a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5bb45ca2667bfd9428e0c3b6ca2d0c9e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/60fcfde054b56f82b5aa05d1cceb1bfd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/66fbfed6973b6d2de9284fd0601c1c7e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/72230f5384b7514b0960e691ec4a4561 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/777bd52ac06fd4309ec09ab3a05ff273 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/81f5d49899c1bc852b861d13a50c5d55 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8c80eb5cb08079b5eda2e52f04bf9a6e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/92095eb30bcb09428ab427e39044e650 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0d81c21a0c128df9c5d77bdc00f00daf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9cd837250fb62ba09354116ed00d20d4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/46b7e9466b3fa6c94a2500dee059f363 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a2292aa1e1140bc7e65f539957602bfb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a747a0f5c0dca368c67a99107baf2e1d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ad0d332dfb0d5b603424387090bf230e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/90f5ce02a143122b126f8122c4d94b31 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2869e0618650b9e71e23aae494084954 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/27187f5a04364eb6b78dc28049616342 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ea8440d3c32e083da886c284a2720760 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/147444b311dcb1acbfba57b92bce00fd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/018a554b8fa3c5be9881a19e70ce598f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ec667a6f38f29f9ce745c93cb3e73a63 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/16990a6e953d983f65ca76765a8cdc6b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7d3a53f63784a5de9e1e98bb66bc32de รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/abb215d76ab7cf71382e94bb576f95aa รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/926444c507a0aec5ce4528ff1119b5d9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9800d24d786e655b0cc1b5cf3ed35b52 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2f434a5ac9c3f98f74bb2694c2e990e2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5bf6e974a13394a969715440bf4c97d0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/55ab3366f73e25fada12300b2f763657 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2c28d19b5ee58bdcdd75c19597fd0f77 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/efab461d84d90dcddcea4ae0106458a2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/074852802e6daf2f071deb54cb05532e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1b8097b42a733b9d99fa5e702bd4f2ed รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f3d363b90314ad7d77bc005f3ebbe606 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ce56b5e6b4ab5da9af869b3aa9efb475 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8228c965ae382df66d1d72b378c54162 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b1de714460af707c14013f4cc0c1b9a3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/97e2d4926b5f80df412630a05c93cf27 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/35cda6efcaf391fb5fa430555830a1df รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9ea63eef3b59e78f8c070699171f51a1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/616fadd2c50dbadda56c18f2d00e3b9e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3202bf6df81731a719775f0f1986391b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f56acda0d20e5df53678f50faf0090bc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0d9118fb03e9c53a144157740226780e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2239cbaee0f5b2c256c6843bf1211228 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fa1ab74897dff0773910cc0317466804 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/56daaa686845abd73bc4e3fab997f565 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d35489622d1bb99008716a7ea5b57cff รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/21c4e08ec2b28c01edc2d4b572c1be4d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b86f191c10107f3929c58100d0e1eb3b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e6530f6ff035f4b5a4f1242b38558104 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a50ea39914a76f13be04b1614f93897d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/376f4c6a254e0e0f43547fd5ab8a9ada รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6263966f35d055c0c3c4b929400f9192 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fa8089888683f6dba63d355664c7db6a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/00dc5b73ebdeb6404142bc7704201a00 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/28696814872fa233b82b96b32c44e576 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5bf580f81c7fe3e92da25aabcbe0ad46 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d954c87d5cc615699ecb1a8a645b1741 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bf1003615328443bc2ad952d58e03a0f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ec66081b9adbe32ba3eed15aa8a13524 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/421a09f2633e090bc06d93fc33b47696 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/abb075f3450f91b75c9d96981c27bd83 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/017f900727fa89fc4e75cf97cba659f4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1b8fbaacea5438bb6c32241d41db3d94 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/05a3346a08014811a5e21b87144a0916 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2f3867354b8dfc21cd4fe686c7e2b7b1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/616e90aa7e2f178545240aa6e14c91df รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/df27291e881df39d4f6f66374ce7ab61 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a7a3e0eef09868280a4f62f1d39de0e6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f3d0852048daf07d8ac19439b45dceec รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/728ac6cec5256d217a127d267e59f17a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b1dd80a427d0286601c4e80f58b28f28 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6fc4f2986d443a93fafbc4291a622f97 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/22406553c5e79f78ca8f33b142c6f6f9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0b856ccd0a3eeabbcd87b446e894cf36 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/35c60a7e59add1a14ba8547412cb3dbe รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e49e1399d8bd907d73931e87f6e948bc รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/97e0caac4a44c1580b2d0be6fffea23a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/31ff37299f37af7231c8754af15c3748 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ad404c46e3e5c2f704be6e5b22640b32 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/77e4736d8f3aee6d365239d4e022128b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b867820c4dbe121a2a8e42e6117e05fc รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/46b8988c6b09657bca07b17f38ee070d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/770ff7e22a438622ea2143dcaca22448 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/286bdbd94cc4650c376d53ebc0ba7866 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/115fe71c56958b88b060f617d30590c0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d3532f1f2c2612063385e6fd6dbee137 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3bd7b729727fe8807c748ddf653e71c7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ea8b59c91d7e08224e3e132b1715fffd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9d1d62b189750fbd8eb99f7747e6a151 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3765680f529f0f1b7b24f7d57453dd42 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d37b5a344da4964cabcf9300f3efa2a9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/55ad46cc1bcfbebb3143d79d4df4d655 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4bc9d9945873bb4923d43fb4053c1925 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/147b469ada52e218b770edada8dde55a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/169a6f23ec16bebcd63ced2bd2f6b4e2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d94b2b584eb55884803f2d82ea004de2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/421733705c0979edd0fd2f18e3a26d72 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/efab65bcaf1a372dce85c1a34b6fcc2d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7286e43016728cc1bb8b24b19d00b2e4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b80bd9bd622adf2972501a1d7df3705d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/822bd332470122eab599fe4eb9cd079f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5bf6734ff5db38d20ca8848dcc3d50a7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c5f7a0d256ebd50006f0011539785d96 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1b8719bfed18ea433a1808f168d61408 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/848d4b47d03d1bbec931a4790f139230 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1bd2863f22cfe93219aea3f8327d3b65 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/484878d46e36c9659d007d8e63d5936e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f56db26dfa0375765114cecd4f6000f1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a79bbdcbd41f228f729b1303207f0eef รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bd8d59b158e99a137bc148954e8ecc20 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8719bd81d0a8515302dae0708fe59417 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/627900b430e0f8b25c30a438c93cb02f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/56dca180c540ae8f0f12d8a35777bbdb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cca208aa26d3d405cbc50d62bdfdc771 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/223f0dd832b00e1cbba35ff4c0bc20dc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8ab0384d711a259fc2e80aaff8c52bc4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/21cb69ec071ead62ee94a4825da4a16b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/05a6663084fc6d5b5a874c08ea8afdbe รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3c026eac57f8f025c305ed3b4670cb88 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fa82db5136c8b86d9c3e654d444c8361 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ad3d8aeade31181a0f61125ce0cbbf97 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8cbbb60d71cae588119d1decb3b49cfa รายละเอียดเพิ่มติม hosttropical
Все о дизайне интерьера
https://wuaer.com/video/ad488366aaf155bc09239ca7e4f0e58e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0b913ca506ec071562139815243fc2bb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/77e52c21c15b9dad6d4d9b989598e231 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ad477939f4e6baa5a5d051a091fa7e75 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/484b1c4744110ab759da24ab42957448 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/287d9e1a1fa6a5a2983644a6abbe12d2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/46cb08c13cdc3e6ce8214f8600889f70 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d393d58c33bb41f0f0d27645299fb26c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/22407c76b4cce6caa07bf69f97550a17 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4f3b76b63cf11106669d840304850253 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1164dc035c2e2f4d7911cd7c2006e350 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ea8de4e864c260a10b11bb92c9e3086a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/46bbbe09ee2212e8ad7696ec64718536 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b2b5a5219e8a0a46ddf7c7393e4f5970 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2f47e2a3f5fb222971748a89fc428202 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ea8cba6ca8b5b0dd1912040b480f8983 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4bd08ee40c721561b7ec9b72788c8aea รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/16a192a2a6b3d142ac7f95fec928299d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/28741c8c01258c71715ff1876aa77b26 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/efb91a6673632716501a37a93e0d3040 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4bcf505563e9c3bbe3fd3fb721b9de90 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/980a59fccc2f0538cc6eff66ae9d2de1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b80d067b418042c22031c4c6d0f28c60 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/35eefdba736d5d3b07cd2da373f1efca รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/51611a203e64dac9321e2d59f81a9e77 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bd95c98ca583c97812aada1a7efe2cc3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1bdafd208a605eeebdec40c3654a26c6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2f4711ac4004a36d3888c1b002b24135 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f5792a9b25fb95cd7db80b43023098a6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1bdae7032f28376d35733b72472f89e7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/515eaef5606ab7d9edcf44ad4646681d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9eb63de29b1f6333de8fffb345aa870a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bd91fa9f6f0a213f891158e5fd3a24b7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3be8cfdb641cd12bdf6f00a82307d3ae รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5c014eb9bf57ce70a710798df72e0290 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/21cc77d0987f9d50b4c9a37d2a509e7c รายละเอียดเพิ่มติม hosttropical
pin-up cassino: pin up bet – pin-up cassino
https://porn2p.com/video/e664e86ab8f92e9fa27a2dd05c8195e3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fa8670538370c92c9d29a32cc1be2f35 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8cbd2e885093500ee2b1a12d4217ff7a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c3af5e9834a74a487e8f58545517f8de รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4224ffef121e1a2b5345b36c622b68c0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fa842a70db676a93cafb90343f689b17 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/627f631cc8b7a3764012ee96625ef99a รายละเอียดเพิ่มติม hosttropical
Купил фальшивые рубли
Покупка фальшивых банкнот представляет собой неправомерным иначе опасным актом, что может послать в глубоким законным санкциям или повреждению вашей финансовой благосостояния. Вот несколько примет, почему получение фальшивых банкнот представляет собой рискованной и неприемлемой:
Нарушение законов:
Получение и воспользование лживых денег считаются противоправным деянием, противоречащим правила общества. Вас имеют возможность подвергнуть юридическим последствиям, которое может повлечь за собой тюремному заключению, штрафам либо приводу в тюрьму.
Ущерб доверию:
Контрафактные купюры нарушают доверенность по отношению к денежной механизму. Их поступление в оборот порождает угрозу для порядочных гражданских лиц и бизнесов, которые могут претерпеть внезапными перебоями.
Экономический ущерб:
Расширение контрафактных банкнот влияет на экономическую сферу, приводя к распределение денег и подрывая всеобщую денежную равновесие. Это в состоянии закончиться утрате уважения к валютной единице.
Риск обмана:
Лица, которые, вовлечены в производством контрафактных купюр, не обязаны соблюдать какие угодно параметры уровня. Контрафактные купюры могут оказаться легко выявлены, что в конечном счете приведет к убыткам для тех, кто стремится их использовать.
Юридические последствия:
При случае задержания при использовании фальшивых банкнот, вас способны оштрафовать, и вы столкнетесь с юридическими трудностями. Это может повлиять на вашем будущем, включая сложности с получением работы и кредитной историей.
Общественное и личное благополучие зависят от честности и доверии в финансовой деятельности. Закупка лживых банкнот противоречит этим принципам и может порождать серьезные последствия. Предлагается держаться законов и осуществлять только законными финансовыми операциями.
https://porn2p.com/video/3be35d4e9d8d5794ccc8543139bd5a2e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/697e3c19ee17721c02ba6514b26d061c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/27245b2d8af9c0fc25857355d6335335 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/926558eda37d676cccf5a872597c1c83 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5bf7060df1484742dcb60411689ee931 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/abb32b351d84e7203984a288d1fd66d8 รายละเอียดเพิ่มติม hosttropical
Купить фальшивые рубли
Покупка фальшивых денег представляет собой незаконным или опасным действием, что имеет возможность повлечь за собой серьезным законным последствиям иначе ущербу своей денежной благосостояния. Вот некоторые другие причин, почему покупка контрафактных банкнот представляет собой опасительной иначе неуместной:
Нарушение законов:
Получение или применение поддельных купюр считаются правонарушением, противоречащим нормы страны. Вас могут подвергнуться юридическим последствиям, которое может привести к тюремному заключению, денежным наказаниям либо приводу в тюрьму.
Ущерб доверию:
Фальшивые банкноты ухудшают веру к финансовой механизму. Их обращение порождает угрозу для честных людей и предприятий, которые способны попасть в непредвиденными перебоями.
Экономический ущерб:
Разнос лживых банкнот влияет на финансовую систему, провоцируя распределение денег и подрывая общую финансовую равновесие. Это в состоянии послать в потере доверия к денежной системе.
Риск обмана:
Люди, кто, задействованы в изготовлением контрафактных банкнот, не обязаны соблюдать какие-нибудь стандарты характеристики. Лживые купюры могут оказаться легко распознаны, что, в конечном итоге закончится убыткам для тех, кто попытается использовать их.
Юридические последствия:
При случае лишения свободы при использовании лживых денег, вас в состоянии наказать штрафом, и вы столкнетесь с законными сложностями. Это может повлиять на вашем будущем, включая трудности с трудоустройством и кредитной историей.
Общественное и личное благополучие зависят от честности и доверии в финансовых отношениях. Получение лживых купюр нарушает эти принципы и может порождать серьезные последствия. Рекомендуется держаться норм и заниматься исключительно правомерными финансовыми транзакциями.
https://wuaer.com/video/c90fbb25bd32534d1029e2a669659adc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/484f36a6eed85210e29b49eff734d9bd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0197856ebe8f3e6c0b34841b2635aa2e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2c323c79d4fc013b79a939b0a4a06257 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b1eaa75b3a0fa6acda8f545510f4c2db รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f3f52b5288d6dfa64715abc7b6758f88 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/42202401dfdf65ddaa3b0b92d4c91613 รายละเอียดเพิ่มติม hosttropical
где можно купить фальшивые деньги
Покупка контрафактных денег является недозволенным иначе опасительным делом, что может повлечь за собой серьезным правовым воздействиям иначе постраданию личной финансовой устойчивости. Вот некоторые примет, из-за чего покупка фальшивых банкнот представляет собой потенциально опасной либо неуместной:
Нарушение законов:
Получение и воспользование контрафактных денег приравниваются к преступлением, нарушающим правила страны. Вас имеют возможность подвергнуть судебному преследованию, что может послать в задержанию, денежным наказаниям или лишению свободы.
Ущерб доверию:
Контрафактные банкноты ослабляют доверенность к финансовой системе. Их использование возникает риск для надежных гражданских лиц и бизнесов, которые имеют возможность завязать внезапными перебоями.
Экономический ущерб:
Расширение фальшивых денег причиняет воздействие на финансовую систему, вызывая распределение денег и ухудшающая общественную финансовую устойчивость. Это в состоянии привести к потере доверия в валютной единице.
Риск обмана:
Люди, какие, вовлечены в производством лживых купюр, не обязаны поддерживать какие-то стандарты уровня. Лживые бумажные деньги могут оказаться легко выявлены, что, в конечном итоге закончится ущербу для тех, кто пытается использовать их.
Юридические последствия:
В случае лишения свободы при применении контрафактных денег, вас в состоянии взыскать штраф, и вы столкнетесь с юридическими трудностями. Это может повлиять на вашем будущем, включая возможные проблемы с трудоустройством с кредитной историей.
Благосостояние общества и личное благополучие зависят от честности и доверии в финансовых отношениях. Приобретение контрафактных купюр противоречит этим принципам и может иметь серьезные последствия. Советуем соблюдать правил и осуществлять только легальными финансовыми действиями.
https://porn2p.com/video/074908464dfe0e0af3c74cad455913e2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2c28dbf6194ad2daa1e23eb0adc0b028 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b1e3ac547fc1cf413875aefe1c013b91 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ce59d918736a8228aba29dbd84d13ee9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4f3e8674cf62bb6bae190fc8f9965c37 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0748d09859228cf5ae3f7c7dbd958c72 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/320ae113e410eea9c7d17ea9b0146771 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6fd995756c65abcb608f2310432b4561 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b872af65d709d142003d021b72e4a003 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fa1ca16e1dbb33283e247714fd2565db รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0daac036acf4d49780eb1cf976dc705f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/772c6d1c99920a5d430e1c63230855b5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/32081668cd36fa419fcca613d8f41638 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/675247b116f85950822326f71d3e502d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b872310e955290c49435be47b001c771 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d356023057eb9dc459243f5d54ac8456 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/55c2e838a332f89a93ae7f517deb7f2e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3771c158ac43f8f2a39afd47210164a3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bf1ea86dee1a10b2f97162fd9d07180d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d97acff5caa0ac4e49193aada97b956b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1489cda75fcf6dc13865f8ac75faa186 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7ddb8faa86838b836999a3abe238c91a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/37710fe240749249478e6bd671e2b516 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6cc6daeec21da2bc574450e61a75b22c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bf1c9a371abffdb0bf09950fd7801ee2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d95c2af1e1a597200dbd31221007852f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5c19aa68d5acfd44e2fc89d18ac164f0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3c06d930af2ea5d604820f3850d0028e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c60dc67efb8403531646df1ec5a0dc68 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/df377b7952c9a0c80cf7c86f31c171fd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7dd64925dae0331f32646ed4a6d07d01 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/05a72134da6fe26b6102677b9ac50378 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1b98dcaf2ec9e98b1fd44ccbff1a1fbf รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/629a8f57d63d7d74410242b53f614b8f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a53377c36de5fa7b3a8f529ea34a6c8a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e6678107e2b051217c34c88dde2204af รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/56eeb96417b33c3bf01d8509db4728f9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c3b7a617ecffdbf3785a1022bedd3841 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7deac28d7f8229ac3a661d7f9ae930a5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bf20e9a6b6fa62d6a08949b5bbdd9796 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/697fc8354cb637d66873afd27b7ae9bd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/abb8219bd48a5e646c6c2f2e3e0c36e5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ec8191030b90ffeaf96c6edb28097c01 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/927154d92266cf449ac599e5956ba2ae รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/01a6186f5ba6f2a711d58e9ca9f0016f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/05bc92ee7bc40932ab4cc4ffc528611f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c62a027b1e10b7e78fbfe0dbe2c6c160 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6ff68658f841e6f6e01fbae4a6ec756e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b1ecd0109cd2950611ef0b2030ec2fd3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/97f6d09cd283e0a4dd61827c80c9b1f3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8accfcb074c01a3d842faeefd2d3890f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/07526fd16bd25819d2de554645ac580f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/48515770ab5caf398265753842f1c36c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ccbceaa90d9763feaebdc9d5a5df2c84 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/77eecc79efe4faf8800f07c9a9560e7a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/772e379fa5aa5f43163334b9568a2aef รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b874d212862445161c7ce07b6b83c9f9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fa30fa95c7459e8ab7b93ce57685a221 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d35be3d6d0ecf2af2275747efed65e8c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9d235ba1a10722cd622aad3eacf5efda รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/911ffe114ef90b6573c42d0c32596517 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0dae5c1c6037aaad7d572eed0c49ed9d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4f40885a7cb8fd8faa4ade8ba61c0e90 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/46cd2bdf5d6a08797606163ecc47e100 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7de13b063f8f83609435897c38849064 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bf20ca018ca4dd239ade1773d3b93310 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d97b53a58c732b7c21d12fba09a1a25d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a26574fb71681d7c9cca907450ef358f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/98287872e9e3f4c6ffcc1e8bf4a06fcc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/148f79e377759a1d6b5c165f52073dc3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/55cb1d848a23023dae1ab0ee708afd48 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2f5f22b7093bc2eb8dc81e7af193cf30 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c60e7aaccd807dc0ede8864e9c326d0e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/df38f95e70b4a651824d7c0f33e285c7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/72913dba57a8099f7b89744b55c5f646 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a7acdb168917338ee81c7bd85aa994c7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1b9d143971d6f8d4b04e3c1c00c58375 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5c1ba1466a673604373fa0232b4915f8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/872f3417d710bd2ea1d3e634fcb08779 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/35f6fe59311ce7f122aa4c254c79dbc3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ccb8877ec30f8322e18ba0dd00ffc79c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e4b098c5e4f264a954664f1910ae5a57 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/77ecfcf603aa0d1377557a846e092371 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a539e3fd833275f5a5a1a74f68ce600e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c3ba54f8fbc3bf51fdd2b5fddfbf335c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/224b6eaac58e5009bd12f8c287197982 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/629afe9f5fac20c121564d451b240234 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/21e0f3d3e9ea4004377d2dd43f53fa94 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8ceb675c1ae2aeacead071c988d17871 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3bfa78f7a6ad0efada9fa59bfdcb8d5a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/911caf137ce75f245c31a484de2a84c7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d3a4e9d55bee52823e693bd7c65c1e25 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ea8e0622b3dd4de436088d0ca0a778dd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/abb8a79d668647077a10d60bcb139cd0 รายละเอียดเพิ่มติม hosttropical
can i buy zithromax over the counter: zithromax price south africa – can i buy zithromax online
https://wuaer.com/video/b2c02663d030a562b6f25217cfdac32d รายละเอียดเพิ่มติม hosttropical
hd porn downlaod ggjgodherogg.w9BkkiAQExt
https://porn2p.com/video/6986050599bf128e409d057e9a181a31 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ec8ce2e2bc349d22d3f9cc987022d795 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5c006d089bd05d8aa53a037758cc2344 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/982428559e09637e725ce27460ac535b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/efbe29c4ffec4f90819b21f903a2f508 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/16a96f7b598a05f2e701dee1dc4aed67 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b1fa1a7756c827b2fbedbaf92aa503e0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2f56ee189e153f72b93f34bd3e06c447 รายละเอียดเพิ่มติม hosttropical
глаз бога бесплатно
https://porn2p.com/video/6ffd7b48d3540c75390ee78a2c216116 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f3fb3fb03dce2a83f1c9226e3cd98541 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4856ebe36e975916b2248f78d3b5e4c6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f5808d85e8eb19c6dcfde06446da47df รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9ebe2902e80069c7e0a4a6b1acbe0422 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dfff0cf73dfe758370c453aba22eb95b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b875f132155c354587f037a991d525d0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/35f30838c2cd4aae124c5cb36e389c57 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bd9799d963567769200bdeaf55098eb2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3213c6e5a2aeb96ce98fd645a5950460 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/77385bc9b9e80f15d2637b266ae1d3ed รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fa37b75f7307d44ca210e21a8179a8b8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/675f84cb305d9f9241a70cdf5ed949f0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f41a3f220eb3ce5d17189dc2046092b7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4f47372175f79b16371a57c3d5957a8f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b81916472e8fff54046a448c95fc6bc3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b1fe3d9f698b20517d64a130a70f1487 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/70288f1586d5456dd86b0a38a2a65d46 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/486556a276dbff975a586b7cc787357a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/61931126aabb28e220fbac71ca02e22d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2f61fcc3aa101d8633f1bb554ba4da0b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8239ddcbb6be58fd8838283c69ff0731 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4bdf139eacf18047e93993781cdcb99c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fa43d887f31e67ab5670ef6506af26e7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bd9debdb82c477aa37056fbaa630052b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/773cd109df211145bf0f5ffee400ef48 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d3706b5edb827dd1f62f8fb44870e0aa รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4f525e83ed5bce75d7726743f54fbc4b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/35fd1973a8cecf3b07a577d96f7f574a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/87322e85897d66722dfc7ec812482b4a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/517a6c2c8971b34c2d38fe8a83dc8c86 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/00f7db4027bd2e86973393f128a93f1d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c3bc5e1092fe2a12f66da25fa4fb931d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7dedc5f27a4ed8a3b23a334fbe157f42 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/14b10f500cd1cfd8bc55f2a0747f1c33 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/378049d594ed3ca8f2a8a7df8e1be1e0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6cf1da9acc1a94b06ba639c75cab867b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/21e6cb0d8b5fc6fcc3d8ca5b2183f5ba รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/56f63711035253f72243ad24d79738b2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/05c61371a3e4a51ffe70092af0e08b11 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c9303b4b25caad80b17b40ab6959f693 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c63aa968b877b52f5a5d2a1683a6f800 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3c10b42c7ca21b9e6910f671a7580a29 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5c34123a8ccacfb1c9dfa1ce25d812ca รายละเอียดเพิ่มติม hosttropical
https://vladnews.ru/2024-01-16/230326/posmotret_vyhodnyh квартиры на сутки
https://porn2p.com/video/ec8d226a5095be2119e037bc37191e19 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/729bafa458ea95bb449426f029df4dfa รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/927cb485178ccdb530a1ac18b2a62011 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/423f1a3f916b128e8935491e7ecfefb6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5c028b2cd69ee40a8b7e37ed5d0f0ec5 รายละเอียดเพิ่มติม hosttropical
OpenAI API в России c GPT-4-Turbo, ChatGPT 4
https://wuaer.com/video/0b9e5c1ec07340632062a1ec06bfe7e1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8ad93ce3d69220093c7de65e61b31072 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ccc84761b28da9cb2e83a16040fad826 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/22582787e27792cfd488072bf9ba0845 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4199d2028e474a4c035fea8aefe96766 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/62b8bd40a82d3b84c8c40e37b4c93ee6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/77ef73c2e16de188d8ba34fe850c65c1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2c34bde24e528776f3c6705e22c63acd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/48599e83a377a277ef8b2db4c557dc14 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/61900a083f3fd73fc7ceeaa4496d4e11 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1178f21cec073f43b325e09a116d0bf6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d3699f2f1827a2871700ddf2d22c93ad รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9123003c3e64c53efbb3a0aa47ea0afb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b8793d153623dab238ff512b75c16898 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/289794d721efe01d510c627df6b02871 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/46ce77a685850f4912494ba733b86512 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/699145b2f99fb10dc6dd3ea4b412ef25 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7d560c28778f57676e6d2c41c29e4495 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/321643f4784613cc54fd128396b99967 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9d33eb5bf4a076dc15f600e29c6002fa รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4f50f2ac4fbba22d67a72fb7a26ec764 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6762de9dd8d7e08f09cf4f30db8ad37e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/16c3d7909fc9a205a88f2f6e71c232f3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d998987bdab7610022be2b9b88f2e736 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/982c35152dfd3faf0bae7d13a452171f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/efd8a39e8360a544685ac18a533ffd4e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da11f215bd72cb8892c421d4ee9663da รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/702d81a0a26bbfebe8948ac2541c06a1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/823c50e4b547a1aa0595d9dbc7cb9b0b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/377e540eef20061b0a246a997921d959 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a26d6337d1908fd4ea0799caf5d156dc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/55eedac696d71f2ff08e7747cc9013e0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6cef943b99594cfed8e1228424a6fc65 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1be49371d33a4bef7cca80881442554d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9ecb1558789513e34576aa4ab3070c57 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f58ceb4d3ddfb2345a50a4c479e80009 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e00ce385af3b76ed6164d6bb00f5feb6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/518f4bb6043196db5bbd91aebee75185 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/773eee2c9a04507bc7c11bfc5b21c5b5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3c1009b150880ab9035d5f45f9e73da1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a7b191a5bfa320bb6244463cf9adb891 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5c2ea218f433d7652e7057aeeb78c53c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/72988e2b762bc813a85e3824264948c2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/21e7371ce8735cd331de01ffba3f9a13 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a53d18003fd6c4e08d377fd8883fe495 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fab92dbe2d722ae56cff7e2f47b55400 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8cff3dfae0844ba7e9878dc699ca3137 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ad55c59a8757cf1f967cba3bb4c5dad4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/77ef66cf9441018de90fa3fa8d11e87f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ea98721a0b12cd41eaefb2d4dafa208f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2730f38efb75b15fd7b4c699c055d9a4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d3aab452ffe2bedd48ee303ff8f38fcb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/42436396f733e5279a966b0818f94d94 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ec9e6fdc9ff84ea5b8cce8cc352cc42a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5c051577e30639b936e7957377869dfe รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/92809697d1d075c7c2a49ae3bfa7a244 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/117636ac5c6549bc743c36955ba84f49 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/46ce43909a2b1e661c0c9ae7af7b699c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8adc138ba450de65888fae69ef20b6be รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/698c2b23e343ca40299c69cd6bd719f5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ccc86daa067417feef3ea88f7196eae4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0ba6bcf37cae8b1352420a5cdd035c51 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c3c3775e7eb786de2262721d86903401 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/77f1dbd72526d9d1a1400610e91c2355 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/419efd75bbb21535d2f0ed12c52bc81f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ad5af29678b9767beedb658eb7234505 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/21fd8cfa2a425d1053f4e30e55ed259f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e4ca69078be8dd6721c3da8a5c0357a6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3c16e6e5a26f2b64569eb0962123eac8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/91250910ce0827c4e56cdc6af620e65a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8d0ece0c62ded6ea107c9c75d6dc4010 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a5495610496b0c5c5f59bb32f01c59ef รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d3b4bc70a2fb4bd89dbee5fe2f87bbc2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/118ec309863e7210e3861b1e96e9536e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/570b7cd3c308366033686369f09537e9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7d562f1cc9da4ffa90a4580a72c79a39 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/46d580726a5f3cdf6b6affbf13a6646b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/273c04da20002622949e47ded3b70b39 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/eaa2a69bb36b9811ae2bf7ee6d28c598 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/98341351b9f02e569a6d0cab7027263e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4249b5131af0fb03bb6c11977e1276e9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9291747fb4d5d740ffe612a4e54fe0d2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da16c782172e1a216c8c7550ed9edd5c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/abd673282644e0b64244f489f4fd64b8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ecace8fd7fde37150395b9e9659ebb99 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5c0ae55ec57f3a69ea9958b06e736178 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4be5aff947171efacf237eddd1de64c9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ce8902a4019500568c9307b5b656edb0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2c4c4247c380b356bf010ef2e5a98255 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/efe00fcfa9abaf6f27535266d29e8cb1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7036b758308621fe50649192aa4b8d1d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8aedb8d9f42a4ca792e3b3a34e1f703a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e010bd36b9b59aa52a7b46d4e68f687e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b2068802cdca7a106bb50445c5231ad6 รายละเอียดเพิ่มติม hosttropical
https://x-true.info/126134-snjat-kvartiru-na-sutki-v-gomele-arenda-kvartir-posutochno.html квартиры на сутки
https://porn2p.com/video/f421344f79a30e23f7b1c0cf929729ae รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/61abad8472970b0a316aee85e0ea08b4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/873bb5fb159fa03a85d466a8bb694713 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d37bf6282220de4549c7b9e57f8f2921 รายละเอียดเพิ่มติม hosttropical
1win сайт
https://wuaer.com/video/3236585947c945f7f3ce9473474c5b7e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f58e65ae87d251b006a1aeadc288ba23 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a546d60717d7209cb0696151edfbda4b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4f54ffd350ea388ad16a88afbe22d680 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9137b19640f9f4264aad0c7e01eb94d2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3602c33eec31257e034456b363f90dc9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/21f5710e016f4577690afdabc657e829 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fa468454501fb53e3970c5d1c4c6c2be รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8d0513508136be790a88f198f9979bf7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/57036aec91e64a9884cc745b04d30fc2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d9a90e607b7ce42d625345b9540e16aa รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/37847a877278ec2f9c41b3c57e3bf481 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fac4893f7e152cec19a90dd1c941e566 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/abd262775127f0c6c2e3844768cf1c11 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7df0ef9c115148993b7df81603e6e8f7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5606857a67fb12c3241376a6a0f5aefd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/eca10ec7458f79ffd999545be4b7fd0d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2734decfca4cde569dfea4054d29add5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bf4f185897f0e0e4b101f666ad0bc708 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/00fae604149ead5c120a29a86c50a849 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6d000a8d25e20eab97fae6815c626ea2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/928eda9f2373da9a5ac0c57bba093e9d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5c06956a28599a97d41a8c22ed78cb4c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c93bac7732a2f10244741a7d61843572 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/df461adc99a279ed725c655a9d389e23 รายละเอียดเพิ่มติม hosttropical
скорость коррозии https://ingibitor-korrozii-msk.ru .
https://wuaer.com/video/3c1bdee2fab82e81056f0dae594ac522 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/84d2544de0ed825e02ecfe49bf5cd34b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9ed213f76259d9380e771c0725a7fb0b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a7c1b1d5bd747a2a9c1f86c614bd3a9c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/42468f3b214286aaca3069f08754b611 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c647d054c7a20523ed97c1b749be3552 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/05d440c03983bafe5a2f6d2b7a9762b0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9814623357dcb656d572fae17837e1a7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ce8672cb2880aa7758d3d7857b0df0ae รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e4d1845474afcad93e92c394afd95fbf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/41a0fff9a589b29a2f6901ce1aafd8ce รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/07573713a97eb9be5eeef29f0a81710e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b87f93b1b8fd8d6702154d8ccbccff9a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a54f86b2bd8f84fa4a2e71447f7d11d2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ad5d963ad1e9f8f4f49e9338b9834053 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/322bf3828fc790ad420f56bd23a64a1a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ccca0081e3017eae0db626598ab246a3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0bac60bd1fcc271e5c735198e8f9c09e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9d48909bf7b36c8e0dff1221679e5d3d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/77f35a1cf49c2d8e1eb483ead94ffbb5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d374533fd46cd0ac2703bdee928af8cb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/eaabee3588c600cd8afd265aa7f3a487 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0dbb5160eaad102446ab73b8eec7a2fd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bf31783f20d3be05411919da460ec0b0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/abdf30cd606d992b94b9d0bcd292bb99 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b2e5098d2b78bc79d27e7ffa8c12ef37 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4f53dc59f66da032e57c888c09fd00a0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d3b840c32d5dac1e0a9296a62ac13d16 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1192c0c11ff4e80df068d20811d97ba5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6cf792026082504580acc63f07d1d9f1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7d5644d6e2843b0f0f9d42a05ad398a5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d9a68ba056ee064c85bc58a017d48937 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4be69654c57400d93b4e405829bb23a4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/14b24d31599f91eaa4e1224e1e2b6657 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c6437dc33770612f03ebc7c3c07f5514 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/983598efa16ed57372a2edd6d9368e64 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b20afb09d36068a638516e3ff07fb9fb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/05ce686c56f2d782121fc5f3875c1f93 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b82b7a4b2a2b595d690b91ee4b1c90f8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/56004ddf7242c36a52c21f1e5ee832fd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da207e80e5c00a09752306efa1f24c9e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/16c5b03b9f34747488fc1e107097cdcf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a7bbb69cf025825297104bd7d63f6f9e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8241db791262480f7c72599dc0fd27e8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/df4510674ae43c39be671fe11efecd2c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1bb3548703b75c3ba9f1a60b0db433d8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9ece47b8a4831f0234315682ad89a010 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/775389f7fbbe93182ac2da2cef24a2f7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e01476d7ea39162c50036f1587c8fcdd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1c07cf585c1df9ef2c25369fd729df42 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6d01495b76b24d030bd749df6de7d446 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/873ff1d024220e49747f3bbb7ffa6481 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/00fb56c304aed2be75e3c5387a74c909 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da2549bc9261ceede8dcc7a9f750eb9d รายละเอียดเพิ่มติม hosttropical
вид коррозии https://www.ingibitor-korrozii-msk.ru .
https://wuaer.com/video/a272025bf711784c9686f635f6f26389 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8245987ee88d397662e56d2ab60e9cf0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b838331e7160a1ca1a9fa8a12d5a0251 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5c421a0977d0d3ccbede40cc41903b4a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/72b6655fe5d1cd038d4bc54681db65f9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/05d944863ec7c0d692ed54e8b627fb04 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/70496e6e445142a56951eae41f29e430 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e01c72244f470f4090ccaef13e218a3b รายละเอียดเพิ่มติม hosttropical
магазин детские коляски http://www.detskie-koljaski-msk.ru/ .
https://porn2p.com/video/b216f7021c736b508d32e99f33a528be รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1c177f841f410886ae1ca3891d7556d0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a7c67a9bd58a4f880cb1a130994c09f3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/519d448a01052ac2d2bb05908d23c9f3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8749abef94c79a77f097ae167a8564e0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/df49242b4e782890f8219012096af23f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bdb1b11af69dc789caad731dfd7c36a0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9ed25ac69ad7140723d2d7cc302ab83b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ccd9cb43590d6b3812c81cbdf33a49a9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f5af34168aacacf5277765ab9980e0b0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/77f499318627f5dc2e183c04ba239614 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0bb137d7fdd018fffbf1993845c695e0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/776130fc8cca33f365fb8a55668824ad รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/41a2c9c351bbae274b8640032ea6da25 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b88f581be806e1bc11adb56e7a59de8e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/22063263046f16acd681929faa75b524 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ad61b4f3d0ead8913539e55d191a6004 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/57123ad44fffa20c7a2dce4c3be6b910 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8d13533d16e725d571467a748e31489d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e4e5c00797d8994e644e0613e49f7b53 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c3c829f9811a744ffdf651bab806537a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d3b8443ef03ee0e84a2bbd1017efb174 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/facc786a5dfe18db0fab2e032a61a88d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1197c5ad4d418f2220ab9da029e9a626 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3c1ba8732bd4134be3964da0f102094d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7df71ccb418b2b891a36406e075b5c2b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ecbb9eea1d864b290f86c2253ba0fd1f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/46f6051ce8afe65d841f65b156a54ca4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b2ea6fc82bfde640b74fb9e779018375 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5c1295d913604f72820b7f488d1607c3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/eaac12986f9ed94178c8c6025dd2d00f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9299310f197389bbea731302ede89e20 รายละเอียดเพิ่มติม hosttropical
aviator login: aviator betting game – aviator bet
https://porn2p.com/video/abe0d5ad6724de1066c400f5953c219e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7044d47d3c40143294eda8ebbab46f11 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/01cc528e07f711cb3dc651491073bedd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/82439b1231c4ff6a873bd3a838e9ec93 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/16c7b77abb6559bee00647999407e843 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/84ea7c0e25d1d80f7bceb7bac4b9b43c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f430ca98cacf7a7fe83350607c06f51c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4bf17949faf93d490676fdbeb85df695 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b82eb758af86ec4cbd2cfc98a6fbc9d3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2c6178bc7c16a1acf973d46b10ec0a24 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/61ba870f1a1493699594d13f664697fc รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/efe2c07589fdeb69d9893e6deee4dfe6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b2153796502998475502fc3b4838da52 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ce9066e8f42413299a4de1daec731e60 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/775becb4beda488956f7ec66af1892ec รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e019fb40a5a231d813f2c1c58cb391fc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/076100eb495a4b92fd82fbaef201a13a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8740030cc20b957a34978e51c051a171 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/487aeca67f3664265d2e369dc2c45944 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fa561293de9f981f7071a358bccd39fb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/519cb24ecb25245ca44a81a7c15467b7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bdab60369c6e4d16ccd5225bc651e248 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/678af926fc567a7724df5d17adf7af1b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f5a374081ae62b0bb3cad6bc0ee19a7f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9d4e8d43ef7ecf29821f8809f96f1c49 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b88aae7c5ec6fe339deb6714d12de55f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d37ca022454cc7f1f5ea387f7291e025 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e69a3e0f702763a6b4df472ce0c6e6e8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0de388ccaab00c1e6404a0b42ff35499 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4f550aaaf2548f77b6aa044af58d364c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9149d4b34fb5144c74ff40e64fbfc42b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c3c38b0c6749a1c127523b5fd934c199 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6d06162f541e863239f5e57fabf1ac19 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/37962f7cfbfe88e367a8c816849df761 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fac7bcf2518511a0cca6c4f0e8d068d6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a272c6e4480c845d0f4f53b075461ef9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/bf6bbbf4299b1d71dd465a3f2de3a1b7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/84dd33638b8cd1f0ac00f939fff4a9c4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9296d3cba8494672e0217fc7fcbeb854 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/56177e33eb5b1dd2715258e6fd99be6a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/05e2a974b6a094cb552c562125c980eb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c9403a335b1ebad003909e39dcf3827d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/72b66daf1aec0159735fe8a2d8e0f300 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da2a7d5ba31ed1c0b07bb8e5e3ac23b9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/01c610bc7615a88a2f2e0dc81c443128 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a7c823e22dadeea319ca1c3e93f1fef2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c650b6d5a288710765dd78c8c26647f0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/df4cd36e32da3b9e23e24eff891a8d73 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f4261a977ef0eff4dcd409cbdb9e29e9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/98157c13b52666b90f1ea23aae463e6b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2c57f122a95117fe8dda64c3b1643af3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5c4d221a2b22e2e20f2d8c26cffbcd1b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0bb32bdd971f7ad9d4662f353a1c7c64 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/61b8343b949de80018b65d531b5eadb5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ce8c5ba06a7b632cd1b4be1481fb8af1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/41a3fd7b499a8e0102cb5fd017a2855a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0760afa4249c53f6f13d086d47017b8c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ad667e7d7f60e38ee628a9d117b7e957 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/fa535a55d5afe34b4dec3011486f3bff รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/913a509ce545d3f202ae171bb72b04c0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9d4b297eb1a77b805264ac7d9af344da รายละเอียดเพิ่มติม hosttropical
Онлайн магазин https://mayotmelon.ru/ символики и одежды Майота, где можно купить с доставкой на дом в России по низкой цене
https://wuaer.com/video/6788849046fb6728c06395d240d63e71 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d37bfd61c8151ca32b8fcff15b4567be รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7d5ad33c0d215dc76626b49bc44b97d4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e6b019970f5d90efcf0fe7ae58b04345 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0dcf5e343ddc099d6549582dbac075da รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/61bbbbb2541bf287bd4e43d380488724 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b2f259fac1a1543aa5090e256bb3f4c4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ce97b811514768dbc5cfd1997ca9523a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/28a80c7b845c9e2bb72e67c59ad977f5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/69b6a250d00846001b18469cf3f265cb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/487d748b922a0458bde4ce979eb9a023 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8b06f35d33dc13c1a5258c38d8846cee รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/32470387619c75d5b9e386d225f890f6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/22960958d3686a08c6272a2c24385745 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ecbbc4781badd8d2585c70b62249c796 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/678c5350a18eb5dbba7f58d986c4a5e4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0bbd5cd138779988e92b0c09ed3e33bd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a56135a54ff81b657c9a468476019989 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/41b9b1dd45e7cb04502ba0deea6306c1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e6c352dff7e83f97d7783bece79c5188 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/eaaf05bf572ac2c9d61b09708582a27b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/28aeda5786adf14672a238071b4e54ed รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/46fee198a87a75bb45f5cf13d5eb882f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/14c33492e23bddcf4e9633e814b9f218 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3c4b3330f173826219cb09482d7b5ba7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da33910b9a6c6ab594d15c36ce5eb06f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/efeae4c1878443ddc2674896e0bfa2a5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2f8070a761ef7d125593dc99d8796053 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/705a03b06c89ab443c16a23b6094bdba รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1bdf325db88566c637d016b6673b7a6e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b225e1845fb08b796175f6596dee9a6d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/41a861f24bc2ea24683c19d4b0f85cce รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/77fd03cf47a2d16757941394d322f9c7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1c1aeb394a4d4119a809da4351b34a38 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e4e83c57e339811341f85b0552d7bd13 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3619b4fe31f77ac91df35dea85f46972 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7767f8bf4a7f277c3188062ea03b9108 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a55b32afd43873db4b97b1356a709f9d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7d61e0bc5afc6a90f27a4a90b2777799 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/571ac3bc06123d0b17d27ead190e09cf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8d23403bbf937276cdfeaa7bc5573dce รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7e03c8981d6b8e7b03ff3c86a577fc66 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4bfd7745e397db14b6a13e5fa734c992 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/011ead83baa0a8ed74037f4755d154c7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2f7fe5d0e3bd29b096689399d6932b7c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/61d50847f6a2c21360dd92ce959f9173 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9826a91a61b8c8a23f9f4b7905ceec70 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/324cbc04d658ab9e6002ee8a1f0c3ec3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cce94ff3af6dc781369e53d998a743b1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/678faccd582d64e2e6a1339b42075ac7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7dfc3d99d85ed3a20169acc628e566df รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/37a799c175e9b9418a446bd260f9e4d2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c95a373204ec3038808b6d3df0ee9680 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c65a3fd938327ab350bd2415973887c7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/14cbe118b32f0fad00c68b8e2033cf04 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/985313bbbf654cc1f201e0ca12f8b4ac รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a7d0bcf97c3449607ae281296b9ad846 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c3cf43a6da482a20f076b3b3731bcf0e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3c2da56738132b55d9db8275063ab5e4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6d0c493366ca01dd257c9b3782cb95a1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2760c1b4958722a349a260c6b5f8c1eb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7e077c5564e27beb82ded5fa084cda0e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1bece8d3ac808f33412b9e723a5929a6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5c21245e894c141c91bf714c3334b44e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/01db2850b0ed9abf44214e1a55bbee23 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9edb6347a700462d31266b73a0f7fd45 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a28d65fb0e82deee5bb3026cfd6f1a9f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/062e682bf33d7dafbc4dce8f20108df8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c96ed1143edd9c5952b5dca9c5188e4f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e0259bd8571e1433f858fbe4b50169d7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3c52272e7616b575bc87febc2b165e14 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/426e1b06c43951d194957971d2e19d12 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/72d3745c1c37b2e7fc39d17c69f9eb5f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2c767b5e920c686468aec6d8f0408b3e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/84ecda0c73e364aa8343d20caf435653 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0780535598dd20faf680238c8e7ab38b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9828323828ebad1024de5b9c1a316c72 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0bca5e1c5a71dfe7329a126de7140123 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/41c1bc8d0be4c1e55ef97990425b369b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/14d86c9c25d498974abd6796b3964f61 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/324cdd028dffe0c31a6997e65f09f24d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9859d4f6f6a8cd25fba2dd1ded98b9f5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da46f50a8577d1895edf5714cbc7a0e3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/679ff02ac89c5d91b0ae37fcc22ccf1a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0dee3ee6a5d5886c9bcc0c1825096f35 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/16ea016b762fc67ba662703355b59977 รายละเอียดเพิ่มติม hosttropical
коляски детские https://detskie-koljaski-msk.ru/ .
https://wuaer.com/video/9d6c2e43827cc94ac5a139e365137e47 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ad86a026c271225ba83842677381f00d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4f67b3bde96f4d980d7d14121302631a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7d667fdec942406b0d9be4b8ba556bdf รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5c5a35d44684fbd95eef04a5b111eb89 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9ee8a7c54358cab0f9e4454aeb96e8e9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/917876d3f879e0589a789a02f556b9b2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e032a42ff44d5cbb735af40bad26a8c4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/14cd161ce961c21a9fd1e7388a7719b7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1c2022758196869b43e2f83669d08934 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a27f292145f4a76dca4b5c6ea7832f5d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/16df8968e040a7ef16a91833c1495f05 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/561e4d8fefa71e53185aeea2c2d6fc69 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/825452fc0416c3c67b44add0bc3b92f0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3c504babf3bba3772f3d9da219e6572e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a56b43956e421053766fed828175ebb9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9854e53efdb7f61e3c46fee5a1a10209 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1bedc070fd8df26322fd92b9a04fd0e9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/221585dedee8f9d2a20349b83066fdc5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/df554bc149e59ff04c56f29c8ee6aaf0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5c595d87318887a2afe7888fdb191d39 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/51b0336bee3722a06c7c50c0cd370622 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/875b048f145b8039cd7d6f0d98526474 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/41bd3ae20ffa17ada0e1bf41f5dbc65e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/69e636a0f1806e32cb54cb5e961b06c7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/abf2d31dd9004384263f9b8b8f796bf8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9ee002ee24d6b02a47dac6fd3f803f60 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/22967138265a6e88bd0a7a10fe0a3938 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ad7ef16c8744423f81951aa093b010df รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e4f768e2f7abb228926641111239e350 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2210987990e31264faec55bb3b663139 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/62d4422cde171e7ee0e736ad128236a7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/571c99e41ca9cbb46e23b7f9f157471a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8d2f2b2e64f832bed1e2c39790ec9ab2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/47026eb5a5f4bf4873d1a4b84acea477 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/707097ae3134b66cf7da124cbf34cada รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b22a80cf218aecf4b81eed89e3b7a95a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a564b528f3e299cb63af852406937cc5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/28b4daefbcc5884242e79027931896df รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2c7e5751ca33c7f4c6c2c9a80900b1eb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b318c31f914ba1f460c0600fcff93b46 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/eab02bd7b55fe57e40be754436fa7a47 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c3d5dc5735a49455f9b3e00810a6b6ea รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/69d488d59ed14feec89563488c20f818 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5c21657e528e92a3afefa18ff03595c0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3625c35ed78e7dc0fc2a5c2140dc1e47 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4c14b23c0517d0603be1a3c36fe46d99 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/777a62f053ae1bf0fad17f0f64ceec02 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b89cb8c1df92ecb75b9739e1b3f5cd3f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/824e784cbcfcf9072db4d8fe264de525 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3265dbfdd8e943ea2a987b6955a5402a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b8420c143584ea702440dd6520285b08 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/efeb9190749e3942b300ecfb94e97b29 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2c77eb8577e57136b7e5bd0105620bae รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/61d9b7d3d8f1e4637e71ca8862178d6f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9829718a7e8a6ad081f9a1e92945b455 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3c34767957ff2e421b8077f1d59a3972 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/51a801fc8ad4aa62468df7764a128b4e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7e0a0697b5e2867fd5de2957b7fc33fe รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b226f22f0cae7bbcb914154a50b92088 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8759ff2182a38997904ef0b45d10c86d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bdcb25ad21e3246539ecb6411ca36a07 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/37a8eb5b97e0e1154f0ee57550edf2e2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/325c54bc5b2b1ee9654bff148b917643 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7773cdd9290e8d19ca6b646535177466 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/67a50e28fb34a009e23aa3307f4e3eda รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b842a3c37c82f3447c437bf6831b845a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4273caf52990d2591709da5fed2a129c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/84f2d589bad14ff837c88004acfa07de รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7070e52e8d360f48da8e47e3c04a2710 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0630aba72205f79be8a592ac06581b2d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/eff4173c528c423023090d144fe9b5b4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3c5be89529b290749c0b905a53d3e2d9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b22d76970bb0542402793a5e7719b1db รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bdd807b728450a91b58924284cea73ee รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0786b0a99cc48655299500176fd14dea รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/48a44b98a77468cf036f194a53f5c0d2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2c7eac5aa707d7b8f70d9faf8c212353 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/777b5e57bb7533f32345771587e3f1b1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cd09ebf2696c09c4f354aeedc49ce845 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0bcbfdb0f3532fa4adf4b7294f721fc3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f5bf9cf626f5783be0b7583b5d834bdf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ce9fd9f1385afd317644a7e673c778c1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b8a28450200c32f8f526341e9d6f6398 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c400f3439f615ce22e1f083cf54e2e9a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0dfd847e158e284172735b19dd6af2c9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3c3990a1813cd51aaad83b6200751c7c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3269693aa30c341d0cd9b79a5d6e5e60 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/67ab5d49a14614096b1f918ca0c7c8f9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/917fe7a17ce8de9d5cc8e4b2a7a70632 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d3d477b740830dd13ce61260fb83c206 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/11b9f98f0ca6e312580274ec5a03848d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/572e58e3d452a1e6d175894d820163aa รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d3c1fee9248f51c2719a423c9c45aa1f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/470ff5d4f449c66942cb6996cd12f0ad รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0bd555158ed33d9c4c6f38e7c4c95061 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c97b50fbd8e7ae8dd12e621cc7c0b5cf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/012ed636d31c7ca9f5f03b891ef2cf6e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/42779b088e8e2a078bb6d1d7b49b7810 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/37aee2d23c17e208bb8c2b252dc89127 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6d143aaeca26218054ab7f833b3316fa รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a29eb426e48ee156555d3ccbf59a7257 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cd1076d3bffc10f88a3a8e3a91743544 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d9c7fbf257274bd64a4bb17499d992a7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/918dca37ee6a5c58ea964e704b5ba497 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c6759e29eee0e1366fabc3fe620cfb3d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/06355dbcdc4556a476d9e56d915ca562 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/48aa4676f0730015efb10095b4fe46fc รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4719b622ca6b485ced1b9237ef648521 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8b10672d0b13511a776f4d6ac9a5a63a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/078ce3e4ec1f8be543c8a6a6b7db97ed รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0e1d124e9d5972f9f420d87c9f0f6ce9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d3d6d7e8f2821a6d043ae08c9545b2f0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9864d6aea98ece00164e0fae003372b1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/cd0e0d0ed1cb5ae82c8c2bb1fc1070c5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/16f406cea4dc9c660ae1a486932854c2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0bce5881038bc41b9bbe9da662bc48af รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4f6a014353a18b9381a0e484a971e1f6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/41c98c0a975311d26a84f40160792462 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/91882c642bb67b16d9a7132235378650 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0e12be7aa653edc32ed6d420cc5e4bd1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ada068fee683f34de224e90f71a781f7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/14ee5a118e95452350a7d773eafa17f7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e505973fc20332a6580f858c406e7b0a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d9c77118f0558147a9304dcdcacec7da รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9ef6a357167e4a86410fb4b3e0535632 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1c36dc633eb27504816efecd690400ee รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/11cb6c94f108ef2fb08a6188630f3ea7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5628a2253553d40a8ac8a246f5db00ca รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/51b9f177e7a1c95105df1a1749b461da รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7d6c2473612335f31c301c5e54bf6eb2 รายละเอียดเพิ่มติม hosttropical
zithromax capsules price – https://azithromycin.pro/zithromax-1000mg.html zithromax for sale online
https://wuaer.com/video/6d12c625766ebb51347aac8d58267b10 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1bf89ad95ba0ec8fe383865bb7e0ea4e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/df5bca7266600a03d15e6261c3865c2d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da5c02a2e3314904ad247f616a5cf017 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a56c82f4dab0035867d8b2628bcc083a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/221bb44fb89ea519ed14a5c64ea6e842 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5c5baff6081be95a04cce3022366545a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4c35240dd8452274498cfee28d1f5e80 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9ee91c7acd53822b42c5e72065bb3875 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8258106cec5be185ae87489d539b8ec4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1bf07c250009ba096e17222e31828f97 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b84ed32c404628502288d7b52e6f8197 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e5044fda085baab7fb071da050cc7bd9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e03a5b0682c28e82f93b8fbc8908a28b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/abf9fa24ba82d38806692bdf7c4005f1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/62de96a8f2ba1ec9cc16e8d3b146724a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/51b1f0aa700eaf2cb8e326ad73421a3e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a56b8c517fac232db705637d0f5c813a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5c313a474d1ace8d8f567a5a17c68f03 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/229ac30efe4e4c4a7ce6aa2c4f0637a4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bdd8e16007ff990a5de9504843e7c0c4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f5c3702f8ecec2ac54a2528dec785fce รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e6e04b8da8e4c04263b5307612751d5d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/221819e2dbea5d4d5fb4ef5931c0bb41 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2c85b8c65abaab73ff9327e8ff3ddf78 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/69e8d4a232e4bbcea73143c6d8eda32b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/abf75e8ebc432552feefaa320d0b18bf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/61e78204b6aa2448772bd3758c29a6d0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/28bdd5291a04696e0f67b8292c88bffd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7d6767d3286a2eb0c04072616fdf7af3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c401c1682729f0ada33714533183741b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/faec4a1c47810379ccf8d7800ebe9f82 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2f8c5266d44b70e8e4f1b1716f04e876 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ece1ad7a8ca77ec37c7eb7d7cfd18e43 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/32763ee68efbf864e543bad3b8f05e59 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ada7e94d90b9a891c01ce0187cb38c64 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e508d2262be19a8f5bec33002653588d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5c2fd0ad568243e907c88930faa33ac6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/92df4a66b915904eb2007a1846111486 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/22b230c31d44251b2b6c781cc2335231 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c97e495c5a4b70894cba39cb2492b6ec รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a56cbb3256e7f979b5c19394dfd59019 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/01e6dc68e1ed99cc1e0912982918bf56 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/36419511f0986a0d081003c90cda922c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7d72d12928d924515a3ceea9f3707cfd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/69eef8e3ae6062c5daec08c5bda650d0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/37b43443c9bedba9485d61ad8fe5b5b0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b338874056fecb888b51062d8504e971 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/eacd575dbdee859b634a4fb8737cef49 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/37b8dfc48b17a3dfbb0736101b6a2c58 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/28c74513c95174ad0aa3dd31adbe24f0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/abfdb77fed7b5d37dd56440a00dd9cb6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1bfc59bd95b5b2f6e0a0f06c35d2a044 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/013567c5483c2e1f1d50b9f0ca2489dc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7073cdb45e57d9b5799022a50f85ee10 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c67a2fdafbdcfdb53a38f989ca1196c4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/b85e96e07f56dce1b277eb2788d1ebee รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/eff9715ebc89a394863a785e9e87f86e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/72dcba27000429c01eb0685344ad5236 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/72da4b458d00f5a3e6ddc17bf1d7f403 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/b23b71fa8deafa5c08eacfd671f8d861 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/22b63d8a4e9626de878c75f5ce1b62fe รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/063f6252f69e87e37a50269d4bf6b0c9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0b7c924e9c3cbf79f49a42b8c8a12976 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2006a38c67970579bbf5dd7061b9c712 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5e708ed12091cb2f75a53f48b6e52f9d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f5c386ee1b73ed1eb49a2bada6276f4e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dba109e0b16227b1b78bbb6f30d268d2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3643d54eddaba06610f303f5669fe62f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7841a23d748a59dbee1e4fae6e8a4056 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/11d7329c77ef257290b90b1e3dccf38d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/28cc8422b8967e8db2b70e9cc14d4254 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8d43673863a68f8802f7924ab5bf547b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/21585ad91d795df3ea0178d646b1e7e3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7e115cb670a63c3a91c22ef72f9adfd0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c40368fd646e73545978bd769bf00faf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a316707267e8ddfcfbf95e9444f88072 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e1a0ab2cf5bfe6cf91963369e749646a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/47359269050c018deec53bb88ad46663 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3c4af8020aae4d5246df427b8721be76 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7d7b3e20e653e71763455e6e4d021429 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/16f6b6a363ea26287c0a12d046640d16 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2f9b65c5119b9f827ead4d20ea926096 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/390509781ddf90f68974bc8b04db0d9b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9171c55d2a507eafed6d79127e38d64a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/85058051fde26682451366fc4252af7e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/c9826815c191a87ebdd6061cf3144b91 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6a62349f766383c5580def4032da45fe รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a94b594590c7b192f3ade7a479320b9a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4c445d0bfdc6ccdbd3be7f258a44d7b5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/428041f5beb84dcbc94f73a78f4bca99 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/1c3a1919ef8c42b778220f8c74a0e1ef รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/36487991a96389eacf41ffbf44ca8cac รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4e093e037846bce7b5be9ba7f25ec948 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8b1ba4a7d4595f11ee181787ff23a195 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/cea3ea50da1ab4f2bf1904a443c06bf1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/31d6e55ec7b443e61998307084021111 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7043f09ed0342fc5b4ff639b207c81cc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/af92cf20ae98334d90d06a24b3027b5b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/51bc88324f027b3edcc88c16f00a47f3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ede7fcfecd3cd52d427db1c7978e7336 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/48bd33633e2b655c3b27db3504ed84b6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8773203013d754443f9ce9c8a5398b3c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2220eb41738d86fcb6fdc48b304adc23 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9d7fc6ec8d05cc670631cc721d1b62c9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/91b532d52b55f41031ce92961c6c5a17 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d3d72e42cc81d248cd67eda5c131d65f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7e2d5dfbb96e14f14f5e306f5ef347c3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/76d894ccb74b1d90c6424a0db332c804 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b61e63ba2e82c2beeacee4be9f261a8b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/573c920d9fa10313878fb49d89cc8af6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4f7a0ba8556954f147737c37d8ce9b29 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f4b4609d3bd607dc530a3939ad88d667 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8d57fc03450364ab6bb0d0f4d7a1e81f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2776f587a2ddfff83c7cae6028d2f5ba รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a2a3e2dc4240fb307b5bc37d95e21d72 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a8e768b8616574f85e902a6b1a120357 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d9c87f949b8c5dc233891a4518ae5287 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8511a28ba0169988e181bc28bb4fddf1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3eb0cd4b02b8d99e14f04f8bb95fda6a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7d2d385a0a8b3e2c2c1408936cb59df8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bc5f847d8ac82660f75dfcdd15eb467f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/562dfd1e1cc0de245fac5102884ec40b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/faee68c2e4df259bed08b40ce86b1130 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/2c8a2dcc18ae8d709d9df37f42fd2189 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a7fb45d97a1e9df3e4bcff3b6679ad8e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/48cd54380895878ac1bd7a5b0c217879 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9ef76f789fd6dde94058dad04b9e161d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1bf998890e7396c90d94dea2022f9e0b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c142b35fdeb5268e1b4669d76cc5404a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8b26c3a786454ecc82fd13e182932036 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/44ad3f1756e08d27496de0c1c86ad239 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/61ee27be236efa5d94300a458b5ed2bb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5c66ca88d954313c07ed7e115943fcb0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/98390e03ba1a19cc2f3dd0cc3f633240 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0b90bae7679ecc93eab8fb0944498c85 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/91d7217849660235a388bf9263dd4069 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bd404afbcff0b94fb8d6530421a3cf3b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/37f0776090e871a3ff9fbe20e6e4a071 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/76e4b76c684efbd7b788c34b2d69396e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4f873640e5f998dd77e6f8efa90880b8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b61f2bc703b96abd0522cae5914026c7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/91a2c93556f9c31110c8b8767c12f283 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/099161fcd575fac74f66a48aa9d35dbe รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/67b9d8db4f6e812b664d898b42523411 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4ba61ad528836d930eef5545f9d7fffb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8a14481eed982a1ca2a4e63a327eaf1e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9d8f6ff128dc4aa37fa522b5c5dbc586 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a8f08383585647973f949f75c31a0d2b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3eb7bf07da6d2e72db87ba3cf15ebe99 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f05b3c5a7811c2c89146ce570ea910f3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bc62055fbc474cf2a24070c17b64dd8a รายละเอียดเพิ่มติม hosttropical
Mагазин фальшивых денег купить
Покупка фальшивых купюр приравнивается к неправомерным либо потенциально опасным поступком, что может привести к важным правовым санкциям либо вреду своей финансовой устойчивости. Вот несколько причин, почему закупка поддельных денег представляет собой опасной иначе неуместной:
Нарушение законов:
Получение или применение лживых денег считаются противоправным деянием, нарушающим нормы территории. Вас в состоянии поддать наказанию, которое может закончиться аресту, взысканиям иначе постановлению под стражу.
Ущерб доверию:
Поддельные деньги ухудшают веру к денежной системе. Их использование возникает угрозу для порядочных личностей и бизнесов, которые способны столкнуться с неожиданными перебоями.
Экономический ущерб:
Разведение поддельных денег причиняет воздействие на финансовую систему, инициируя рост цен что ухудшает общественную финансовую равновесие. Это может послать в потере доверия к валютной единице.
Риск обмана:
Личности, кто, задействованы в созданием поддельных купюр, не обязаны сохранять какие-то нормы характеристики. Фальшивые банкноты могут быть легко выявлены, что, в итоге повлечь за собой убыткам для тех пытается их использовать.
Юридические последствия:
В ситуации захвата за использование поддельных купюр, вас способны принудительно обложить штрафами, и вы столкнетесь с юридическими трудностями. Это может повлиять на вашем будущем, с учетом возможные проблемы с получением работы и кредитной историей.
Благосостояние общества и личное благополучие основываются на честности и доверии в финансовых отношениях. Покупка контрафактных купюр не соответствует этим принципам и может порождать важные последствия. Предлагается соблюдать норм и вести только законными финансовыми операциями.
https://aflomaxbuy.com/video/faee8ce8f0318c67de4f276d06b1178c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f04be64b32fbf29047a646a34a65a2c9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/51b74553556b27d5fea9a47343f6f6ee รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/519eb86beb86c87c710307c363cb47b7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cefe32a43af284f27ced2b66e38cdb92 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c180db8974dd45928e3948acc3d5ccb0 รายละเอียดเพิ่มติม hosttropical
Где купить фальшивые деньги
Покупка фальшивых денег считается незаконным либо рискованным делом, что способно привести к серьезным правовым последствиям или ущербу вашей денежной стабильности. Вот некоторые другие примет, почему закупка поддельных банкнот является потенциально опасной либо неуместной:
Нарушение законов:
Закупка или использование лживых банкнот представляют собой противоправным деянием, нарушающим законы страны. Вас могут подвергнуть наказанию, что потенциально повлечь за собой лишению свободы, взысканиям и постановлению под стражу.
Ущерб доверию:
Поддельные купюры ослабляют доверие в денежной механизму. Их использование порождает возможность для честных граждан и организаций, которые могут столкнуться с неожиданными потерями.
Экономический ущерб:
Разведение фальшивых банкнот влияет на экономическую сферу, приводя к рост цен и ухудшая глобальную экономическую устойчивость. Это способно привести к потере уважения к денежной единице.
Риск обмана:
Личности, те, задействованы в изготовлением поддельных купюр, не обязаны поддерживать какие угодно стандарты степени. Лживые купюры могут выйти легко распознаваемы, что в конечном счете повлечь за собой убыткам для тех пытается их использовать.
Юридические последствия:
При событии захвата при применении контрафактных купюр, вас имеют возможность оштрафовать, и вы столкнетесь с юридическими трудностями. Это может повлиять на вашем будущем, включая трудности с трудоустройством с кредитной историей.
Общественное и личное благополучие зависят от правдивости и уважении в денежной области. Покупка поддельных банкнот нарушает эти принципы и может представлять важные последствия. Предлагается придерживаться законов и осуществлять только легальными финансовыми транзакциями.
https://porn2p.com/video/39169680cfb16b61a6680f80b1970047 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/83ee4e6750e0ebb73e201b5035cf4c49 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2948c9dd94ae90c1db28132dc87bf27 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1a3c53b9991edbbc0cbe2cfda1e62efe รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0bd9c9848c8beefe0b7eaf57eb670334 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0598576154c8d059c9fb5b4a10e6f84d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1a3a375bc7365fddc6b3da2df0793647 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5827c64c247df15c39a9dc8aa13c293e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d9b3905ad6fe762bef3f1de7c2c21d34 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4bb470044154661512d68fcf27aea937 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/67bb6d3b052478ad193905983d64709d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c8c4658c0405f0334f9d567daf7f953f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d1e666873436c1717fa2ab5225fbc8b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5e77a88d66d8f5b93aa60056ae89d9c8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dbc396e29dc1fba26d1354054d0e1580 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f05452f4124127db30b10413de815ca2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/13cca1b25863bf0c499fcf533a18d0c3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/51a5f0a11aeef1eab8303147a1fec9d1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/907f2de406bc9cb31cddeb03f079b182 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/91f6b721de32a8d2eb8fd427089660f3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c1bbedc1d16dd75377419b2848de8db1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cefee587d3cd978f0b81402e6a11bac5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/25e7d7c26f82b58e6f209ba84d872d84 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/392510c94ced1ce8d6d3c0c5afcc1a46 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/63f84cbd0a981904f6fdfbe7ece264c3 รายละเอียดเพิ่มติม hosttropical
pin up aviator: aviator game – pin up aviator
https://aflomaxbuy.com/video/2c0a5c71bee4148dacbe7a3fda9e46a4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e1c10d547ac5618a025a28990ad88418 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/58286262649dd8aae22ad015eea04dad รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/965037ef53e5487380317d6d23f27df1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a90b2b5bb95e1827f3873cc2af9085c1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d58faf86dc0fce58671c701a8053ebd6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d9d5cdbe6a472209c93ab94c5a9eedab รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2c09653cfa941f93a53d5e5a6c61a53f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4e3e177934a772c75e58c092b3e5928e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a957df28e57f67f5493a3721f55cc184 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6a71edd3f6d12fc3e5a5df25aacfcf66 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/31da7ccd3880c755c288e33d999af00f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e790ecd42e8f51e76c721887a111ea7f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2007095aa265965939f805391dd44588 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5e76c0845a9b53af06243beabfe32a85 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/76f49a3b48ee23e91e45ac275e3f699c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d154d2f9c97bfd8b7cf308e6acf98a8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c1af33b33bdcff1c491b98f9715af019 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dbb85d2ecc204040fa2627f2850a51e0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/31d84265592cb47885d6ed098bd07b9b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/91f60077fee475263612393adca4f7d0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/af978104ea21640d787bddab29bd3e22 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bda64cdd33a84851d7e340acfbeb45ad รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/704d8d737ef20e9d34663540ce2ec848 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7d7401d12b695eafce970ab147125358 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b6334d1ed977a7a8e745edef8fbe75f6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7d48ac34fbed4beb9127bd53b13aa001 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bd973cadc87a8625280530ca6c74dc4a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e1bbfe21f20e04dc1f7505665492003a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/37f1dae49239528225b7dc95d9bec6e1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0758c1cafa7c05aba6420a3f98b3a80f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b62ab6ff17d598b3f931f844d1778b26 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d0a81b7a9c82d8bea47dba33bdd6f052 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/91798715558f306dc41f16849ef9a05a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2c0675ce6910680d29727b813cc861c6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3eba290ed3d5b5c793ef1b0a17e2b72e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6a63288abcd9373f62d228ebe202950a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bc71257d1fca9e7855afd4587bb41d8c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a94d256eea2981b651242738b2c38b95 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/83fb4153635403f9e683d81a4cc87824 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e78a009fed7efa5f3f3e3d777c587caf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3eb995de4f2b92018774fe69d9b8c7dd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c18ed619ead660634439a877b628b0c8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bc6901793095c373f3684cdd248e2c9c รายละเอียดเพิ่มติม hosttropical
что такое фасадное остекление http://www.fasadnoe-osteklenie11.ru/ .
https://aflomaxbuy.com/video/7d37b746ee458ed3a0bffc4d7f99c777 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a5b01b431c48019b5f23871896cd3426 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/faeed1b80ec2f129918c80c8559ce2e1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/44b7fdd0dac7a402a0feffb7250c39a5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7044c26c798457a341e9793e4556518d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2967b7d9bf4a26255117761fce68ff6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/af96c5de8b9a2b7fe48ecbdbbdabc145 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0339b39a4d593417f4b6dfcecfd81217 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/edeb58b15f1c7c3db38185dd11afee17 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/44b56a1b39e32665e204f0c980e12d06 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d9c56ee4bf4a6e15967ce0146e7b5097 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7df3e9523e7948b27bfe98c5c6ccfa4b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c29616834dc6c4037ab68415dff5ff71 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/83fa16ef1640346e01d0bbbdb7feef70 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0997c32c997e68efa6fb79529509ca2a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0be760a72125220fa4c5f6a6c41b943c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4bbf68e7c02295a44104c2af8f119c65 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/44b93fa5e01e961881a8cde890b2b347 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/67c57293cf57eb11110a6c838bc011ec รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/909b3717aee15649033d1a01e0d14a31 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4bbaa428245065808222c580312ffd93 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/920b9690c2963fbc1fc7f6a639b26c67 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0c2994c3aff6c5d74d4e9a7caa1a48e1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/13d3bd2c2d7a4a5f91865cfc4ed08873 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/21a4dd8df8a785b7b0c09d63417d6a2c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/09a081ecac472b6f4cdb56a8e974e8a0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/51ba4018539fe5f5010ef69c43a10203 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4bc607deeb220e89576ac50be29454a4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf06b0e9990bbefdd1161abd74128b43 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8a3092aa5e080c56c4a0754c2ed1088f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9229ec3d735cbd5d9970ba14220755a1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c8d95578f99f3a033ffd6dbff2bc289f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a60c1b668d0fe543befcf0a9c600f4fc รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7df88883d6030e4ff0b600de113a7e55 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/13da3736f83bb4306103a57583979350 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/51c5e8a37da8ff3d1f08e6b6d8d127b1 รายละเอียดเพิ่มติม hosttropical
https://wyksa.ru/2024/01/10/snyat-kvartiru-na-sutki-v-grodno-onlain-doska-obyavlenii.html квартиры на сутки
https://aflomaxbuy.com/video/58329ec37d04805894873b821724fdd1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d5a048d0b20252c43b9f2c2fc9f4d1da รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/909b855b57b54c887165d58dd3f8ca16 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d1e85c0caeb3aaddd2b0a534483e1a9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf0aa0650efb637ccdc5038da5ecb66d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/39b4038eb3ba79b390970b6ed381dfc2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/25ff71105786f32d44dd587574b77576 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/922c74fa852d61f70939483fefd406b8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1a452552769a4a8ce50db40171a75213 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/583598d28447b2dcee75eb1847b78383 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5e7a5709787f246d07d18b8a1d136039 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/965cdf245a15c14a3eae642e556fcb86 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c1cf4fdbbcd15c947a109c3e12855769 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d5a8588dcdc67d72be67619bea38743d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4eaa61e0c2423ea8614aa4f494e24693 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2c16ee8562ac46bdd340316186b49db2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a652903e3c283f3bf2bfbb452e0cb6cf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6a7afb2dea41bbe4e76b34752045b4ba รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5e7bc7cce695fdc5ac900b478b97e4ee รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/63fe00f876e3e257dfc904ce6a86191e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d2cd87b016a7032f56acb231bbbd7c5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e1c750dc201a520460d1ea540260f921 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d9f18497b42dc70cae41cce067a1c700 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/afc242b05349664095e504eff60fa98a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/92029731ba5f20803f1990c3eb1bfb8b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7055cab73859ba070436c56e569db370 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/31e28cf8e2a2630f80a7aab46a0dd567 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/be17e8ef540bbb7f1855de9939ebe17b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/25f35dd45921b17aa724d63051f3864c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da09a3c68d9bc47cd6499b6f4616b0e4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0351a23ae2961053d1e74a342fd8e97b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a328b0c5390ced3887cc4118944147d2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f0ab52ffdacb1935290e8dab1de7e220 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e1dd8b2d6da2998864fb6bef687c84ef รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3800e606bfb4800aeb56a8d0d9d1e634 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a93a6231010a475bb068dee58571e5cb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/37fbce6805b194d5f544a8ea0100e14d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d0e2eb9adabcf5d9840c8f135a6b4a5e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f4cb395448ce5e638eb8d8c22eab4f68 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/77043e340c2d8969a716fc7728a2fc3b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6a79bbc8f2e7e984d7b05cb51fac91ba รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f0c7139e246038b16435da4a57b32b1b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/09d6e3bcbd766be9bb14c6d29a6cdbfb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/081f974cb7c920f591cc7f396053caa5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e7a9891401dcc4ab7bf80b236b3cd1fe รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bc789f9f71137c8246702ea059a188f7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/13e8e96b9110471b1f83d0f4bea29ef0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3ec08a238f5873d4933308e389db069e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/034b4462a07f48cd2fa7d57678adbc4e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7d607f5239abb6577934b925c1bf9a97 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb0af5a23e7e70367ea4e09d1627af71 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/083c3d49fb5317c7edb91a478d20ed5c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/afae0a86ec9b8d4d18c75d47cf7b094c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/13f4a09d33322c86824096523b304205 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5336dd75caa24ba4cc27f3c5eaf49f24 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ee0bd59fd6933a37f3f7e1b83ebf2ace รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/d9e90ac54e8e1c13f03d3539b4664d79 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/44bbe05a93f3fa47d80da8d00e3aa7c9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1a4fe0963e13bc11457bd810d80aa8d1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/44bb7a94210628c3e1c20b997bc5fb95 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/09b58525e6621083dc646458e116a7e6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/841e51f8a805a18465ad30505dabe929 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/76fd90a1c7bd60104726650f20003ba8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0c4645885b4ec030cd77ba98c633bfc5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5348024da6c692332695056af282a8b4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b635ab28082835097f705b2736c88c79 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1a572bcb0a5dcead3d40edb4e94e0c91 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f4c855dc0ca54f4bf94ac108930e70a0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f083c34e4ef3834b7d7f58a07640ed2b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c8e024900daa5cccd7b49f21b04629cf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/20217c39f7a5fc03ef2c2de62958ea59 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/13e01375feb3f5ca956b92ba147f7719 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3ebcea42333acd3542e7c76dbb6fa4f2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7d508dd66393dfaf2ea3ce6a2f7bf7e9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/22415e0c06a09dfeba1cf5356474766f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6824c9e566f825e326b957ca0d4cfa20 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7e2843177256815e7186d3cab717a7ae รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/20222777a22173e6e067161530efaecc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb036eb2d9fb27fadae51ccdb823158a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/260125490ccc061e0d85f60efccac132 รายละเอียดเพิ่มติม hosttropical
Доставка алкоголя на дом в Москве
https://aflomaxbuy.com/video/1a4e01bbfd190f21a33b8eff7e767824 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/909ce4047682a65f6ae9d53d56de43a4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/909e9221e6d3c7600977436cb4784d7a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/39c7f6af1febc23144d1140cf27b56b1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1a64f2784891615d7d26db3e6a67126c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7e63ddd2d653caeca93bb0c7cdb31779 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8426b87fb4aba84881b81e6f39c13b9a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2605d99102e7d91585d0c32d96984a7e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2a92b56b910e1ee24d6c752b5eb82d2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2c261a188955c44731228268c8f8b282 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/58381b6b626243502dfe275d29ef94be รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d5b7148283946328eeb53416e91140bf รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0c6f0ed2f3fe4f95ac65f9da20bb63a4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/966664894665374d74a34e75a0e19248 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/966aa389be5b6c68bc6d4c89a6535925 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5850965b166d7b85d6a737543b715fa8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4bde0bb164b7a9bcee718474ad44ca6c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8a55c0d4f2cc1b11d8dd305b1f3498a1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4f136c2adb82dc69b7d9f8388384411d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2c273baafc074d160e7f9f027b518abb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c8eb632821da4aff88f7326800bae368 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d5c6062b63b8bcac8124b7777165be61 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/925d9b2cd053c7abd9f70b89b6a4ceff รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5e8cd810cfa8d7aafc881e3976e692aa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d30eaa311e674b8f78431e43ed75662 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2c32495c44a75d19e7bc5be1ee4f0201 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/260679b0d2b653d798f35f3e1d778023 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/92473dc10cda7c1c323b1310e5a5a26a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d3eb3049a6d0e4a7eb7f37e2405bfeb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a670e04d3adaa8767e71dae6c4c23e58 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9301ba568d692c674d16d2b34b398acc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf24f18cccbfb38f9847ba9b36f6ab3f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dbd5e384b717d21b743678b2cd845397 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a6b82457080c1ff12093ba7976c958cb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/39edb9974d8732be700366a6cd09ba0a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e1e6cbc5b33a4bbc2a87294e2078616d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a34015abe3721b81b209dd2a6f216685 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/32051a36a384ce806b7cde120a94d3b6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/641a8149107e178420e2b0d3e82d3637 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a948ab5287cc41faa132b36515e69b11 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a347e6ac11efb4476011176c1800f96b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/966bc9700862cdab274c82e25af54e0a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a95e38062b0f0f8df82b288a2aa3fffd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/380ab48d5f1626c29afbb97a2726ece9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e1fba898a1220967a2172667a1f391e9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bf36817fde1f76cba1dbf70d6b5750d0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4eeb81ae6c29a6e10d4ad6d02018d8d6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6a943f7cc79e053febc5f5d40f60d645 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/381b13adaf532c25c5c7989a2307a071 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a961ec620d6e6994412f80823270674f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6a9751f638fadbbfd625c6e733f14476 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c1eb51cf7b76d28b30256b0aed73f370 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a96a27fe2734679ba950ce9fee2ccce8 รายละเอียดเพิ่มติม hosttropical
глаз бога бот
https://wuaer.com/video/d0f32cd0b6140088e76459dbc2fecd10 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c2327772e28efd1aae8ef334aebec67e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3ee50964c95b43fe1d8528cafb6d8a74 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e7d80967bb01c95e9ee1efb206e39909 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/924f7d77d9fceb3a83f9721fca1cac4f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3ee99cce94d2708c7b35fa9c134c41bd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3811386cc5ecdc634c2daabc589a7a79 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/706c9acc1429a530bdc851ad735a1002 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/64109f6579a6b8e61fe46b82ecb867cd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6a97f0333dce1d4c543a3c0ced30c9b4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da556b718c96707adc9935ed2f82b6e5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e1eb14838b4bd05104a9a9662241ee2c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e7d9f7544367b60469f565680b5decea รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ee250aa1f040dad5f2eac83af02b50c9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0381bd071e459551cba8c281233c4731 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d137cc595004e8b9551c29c1d989c5ee รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/44d7a12ce035b81e1c66a1db49bda35b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7718874138c0dc2052e5c13b9a1331ae รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6a972ebbc55c6f3a6f29fef650dcafd6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a963e34966b847091ad1e479a7d6f0d5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/706fcf8b9788b730e232e0f7dd7790fe รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f0ca0757aaf84c869998b3b1ded870ca รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/afc69263f5f00b0fbb472038f54fe934 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e7d02694ced44beee332ae38de9422a4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f4d3bbb0f2749a6e639ad24d8d3487ff รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/09d91b75a44596e2dfd046f4f8b1415c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4be30735cf34a694e537f63b81ba167b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7d75cd72ccf7fc614b32ce908fd0316b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f0e58630fcc85994033f341cd559d8d2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bc83a5cd2765e9476e48cd167fc0015f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7719ab454f6876c2bf3b6f3fbbb8b142 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/085585016583d56344e46beafeaa3e60 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ee22bcbc300f4bf690abba15644620bd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da1b5a084484987550affc1aa344512c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb1a12e4f9c1a169f0f8afd25b0b9282 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1416f3aecc185041662d77631a20a3a3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/09e56d7ecbea0d82912494aa66ec024a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/51ef884abf4f94b7ada745155fe56859 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/84270fa19a1f03e4e4e3383c197af563 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/770e3ee3da49cd9b47e3da55b7cc99ed รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/08a3b45fc1bc8b0b2072a8e1d2b44435 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7d7a3fa22bfa398147d01b8ada822c10 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/53bbd5b0a9fb88894f93cd75a0f06344 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bc8af42d530a68a2964c71cd088751f0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f0c92db2857f51c904603ff705c51f50 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0c9f4e77094ed27f2835db30d8089c6e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1a6feb1c5ec72dfb388718d2d60f3c03 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/141c5c08bb54c1b27c1753c6a1f33992 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5855eaf4fc9cad23191264fb815dd28f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8a5616468b0b139bfae051ba6c141677 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7d74f482f20f2371506fff8144f54100 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bc7fad8312cc9d390c29d5b7ff86e296 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/842c40915be62eda899c64bbd13331d0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb166b1dfd18e6b725525dd712fe61c6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6858e629ed28a41b8d1a415d590375f3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2b2bcf836453e2823f4a6ce43cfc749 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7d7a8457d5e4cbc5dbdf46d764d4378d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0ca11afe39f0b11027bf5a47fa92bada รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bc8d5b8dd4480e43935b363cc0368d53 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1a71de46b81da39df8b68dd37e7668a0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5e93f0e3121ae41e85fa198df67d2615 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/90acc1c6850df6473e14245edc850693 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf253288ea178476dd2354dd6bc3d962 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/688196bee1e593baa33df9ff7410efcd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7e922b650c049c0d0c12bfb337d46f01 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c8f199d576403fef42d9b9441aad30eb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3a09d689776d63e6bc43ca152c6f5795 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2b5e422e6f398a3cfc3d008dc69a531 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0cf4f17b7c3775779b19092cbdecc4a2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2031abb3f65242cb3dfda27287c3999d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/53dfcfefa694a388a58d9c238c4b4969 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1a80245ae0039e9392b55c1171d873e8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7e9b4c675bf36dc3cd2329f19640d157 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/51f85e11d2e5061f340fc0bc8a997b3a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8a62a69d9d45cef56d80ab9345cc20e2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf2809df631a3f683f832ab944d50884 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c8fe50e1c391548256205ce89bfb69bf รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3a3377f9e5906b789202a9cd2c4e5a70 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/22f0232fc33075197e04976b4ca2e925 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf317cf97fa0efb3c9bdf4d85a17121b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2610947c21569f2450c4e3b907dbcf8d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3a5d04210508ac37a5a2dec85995287c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6886807c22f916b1a140d0d1d908e51b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7eb3b5004a6234a6a83b0fc8b37e73c7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/203f116ad3d84ffd46a581adf9b5a481 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9261ab5902b06d3803bcb42f0ddb8c31 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/585a264bdcda8931ef7f9f37ff51d74e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/90c5829aa3ea64b5e0a068f3954b7c6e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf2a05683799c77e46facb008077d952 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/968662f859e07aef7bef5ce70c930f34 รายละเอียดเพิ่มติม hosttropical
Drug prescribing information. Short-Term Effects.
norvasc without dr prescription
All information about medication. Read information here.
https://porn2p.com/video/3a3a6a1b6fa03e41055c67c4374c5ea8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d5ec4809f1685091c34efc71a9b0933f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2c358acf99be4480654104bb84db3040 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/929d99e1624764a77332a69ae9f17f0d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a6c4ea70104981c46b6db491cc8baaef รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5e9d21cf3413f697632486bb3e397110 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9684642a2cea412c9aaf40ca3be52971 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d40477ebccb340e271e828b94ccc71e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d5e62ac4e834e3b4bdbc82ff93b28875 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d4e5a204e86945506ffe8f0419bc15f รายละเอียดเพิ่มติม hosttropical
where to buy generic levaquin without rx
https://porn2p.com/video/4f5f026fc0910bae0a0eb2c04ccfee04 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9303a0022bef4b6abe2e3b0fa93bd4a9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dbdd528c828d5a6798466574de770675 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/928e9542cae5e2c63b97fab119bb4738 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/32064cca65aeea8d3338348f665d6310 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2c4ecd7b2657c1ffd5433ceb3a0e74bc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d45a3c24c2da5a9b70c1fb279f35809 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dbdbb7aff2f9b5c7007d6ed799524767 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a35589add41b252a863de7f408a71e9b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a35e6b285a4afa407662c9609c980b04 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e20a702f3a400cfb4e8de6808b6b07cb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a95ee013888a81469f551751d62f229e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a6f88cd047f39a4f77c27be8ce0e4746 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a9b8a0465698c2500f1f8c3b3b50ef53 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/381f74e4cee9addb68d61a2c09c6581b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bfa37f16087fe8226187f6e16b114a19 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e210e57d5327890a4658271ec7ca66bf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a35c1427a599b92d5f2bab220332efef รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e20b7028e45e47ca7af5afaef4ba63d6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a35ee9b4cff384e887115268b3dfe48e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a9756b1c15fecccf7eaf4ed46abbd68c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bfcccebad5e6ec35ca2c1b60f7394176 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a96ede3a6a976f5eb65f1bab15af5984 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3823eba7578f5aae08eda2f126c31bfc รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/bf97436c5c9929b752e4e145646d670e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c2a21c99bde88dcf4ec44de222fc4525 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3821739c14b4ce59b5f5dcf90214a9bc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6aa00194c71e1db7564bdf64f477b3d8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a96d2773e4cef0b136976207122266c2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e7f566e28ca92bd010a1a51a69bc77a0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a97641b4c936122475b8f45948345d93 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/afecd53c0d02fc6366356d5d2a48f8b9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c24a860d697717f9fc0f7bbc254a2dec รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/d16574e4c3bd3967e50933c611e86470 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ee3e318a83ab90405bc82b3cd1953a20 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da774d4cfcf3f1bf1d905cf0b2460c29 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3f0006583a81221814d0db131f2df494 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0399c462aee435484f74eca962ac4d9c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7083cae96e643221e9335270beb3c79b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/afdb539f346000c5906b60040cbbd1f9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ee3c5296c8a4575ad70f23b7cd2af9b2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ee4a7125b50ec10d635bf20648284243 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/afee6e48120cbd4b36162b7efe6246c8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da6e0ed80a797ebe3bef1344a334b511 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/03ab60ea0188ab69e33f6a014f83bcb3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0392802651be70a6ad1c1ade9bc3dacf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4510404b288278ed671019d882adfb78 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f10c05003fe5430d6f5ab92d89b43d59 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/09eefd59a48a34481c00068fadb76b69 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/773175a115f7f5ab3a2f522eda022ddd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b65776acd38a23ae5f6f217962e31041 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7d7ac28d09b157096c206449ee5e60a7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f4eb9a51b5376cb1872aeb0dd6734bb5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bca392b9b28cf6b2166b642c2c0416d7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f0f34235924e385c804f560e569c6d78 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/09f4f06f821e5efabe547c157643612b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb2000feec3e5f9e8befd43573e1d202 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4be4fbabf612cd3a6abccfaab499cef8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4beadec2671570adb249af6dd2c8e482 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/143b0fffc69af0ebbc31f95208776528 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7d81c1d5bc2745d55fc786bd9a7fac5a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/845920056e15e9c0115f570b5e0c4206 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb23930bea6c26ad2afa2a78ef729e4a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2b66d60b9f8c5a656028c8c5645091a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f4ece151ce75bc752b34f084682bb98d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0952a43c02a5fb60a32612f0c28d64ed รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7736ca73b8f9450ddfe3d14a0700b618 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b663956a4912b3a690ce9e1808d8ad01 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/144d193253dd8d1e65e8c4b12661efdb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/53e6a5805293370c99b84807cff61cd6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/521393cbf890581c170817fc4cc9133d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/520ae142c79f4d5e9982916041b92002 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da83b135eb31c5c16912c631b192c1b4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1a815884ba417389a7b0a6e7f55cebd3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8a6f110dd958cf56f3fdf3e133aece07 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0d3968768a6b9fdc8298f0431d07cbb7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb25bb0e345b197ef6862b5f76ce129b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2bf32f6d027583b43d9541861aa68fb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/541add4bd38096e0ea2224ed4b001909 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/232c322e0feb8200b8125cb4f951e162 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/695687ee632ce62af7b09e6bd536adc8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/586909c00928503192c96bf6351319a1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f11c7bd31cbb8dc85ca0d35fcd363e21 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5863fb99ced33dd2126381f7cb8f1281 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1a8d2f3e9b48e8bb396391b6a074dd89 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8a779d614e3f1e886f8119132a70078a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2c6a48bf9a8de64e621d51a1af1afd2c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0d3cea98870637ef70d4dfbfa8332510 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8460c05221b81d91ab2a3bdb6ed73d82 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c90014de50922b00ce590dc5bd958d89 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/69650999d1307fdd44d7280173b8f65b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2c4393c0f2a825eae1ded01bc22434e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5eb810cd985620dd23182940317c6c08 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/09550c3ecaff09af43204ee40c4127c0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5eb1edbe86c80b25739358f71e32e1b1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2046082cfd73edf264ce68b010239206 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4f9b451fe1b917cad956c3a7cf266810 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/90c62a8fa70320515bf12c88b1567eb1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/32342bcc525693505ce1a3e2895369ef รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3a824ffa467972a10eb773e5cca8b920 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/709eb0575cc0edf9a3d98a741040c8c2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c9072aa95f5fa8a066548bb275e5e279 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7f0012e3e903c92855ace1d3a22a7ffd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6440840dbc30a1feaa36e3707601ce1b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/541d33278e7486dcff505a00044c0791 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2623ae44361d777db627b6952c723a4a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/64393c87770c33c484e5879d08b31574 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/26268c93d11f074c252f4761aa5cbe29 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7c8a3e5d3faffb12aa16f9011c37fc60 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/968869b54c8c7236e070798918e5c674 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3a851dc7afe6d46f54666f557cfc3fce รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/90d285be1ca8f3f8792d20d9ade1effe รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/774077143e509172b25b3454ddcebd1b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf4246bc711e0bb6249a74c47e3d7a7b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d5f0d773106ebc1a4dd76e3a90dbe07d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/697f43c81d0aca17691f0beb878755df รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e216947c0d5d0ef211fefdb854a43577 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2c5d2d654368299be48f18b04a99fd3e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2c66991b7bb4e886cef674de1905c395 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9372fdbb4cbcfabf9638e57e87771c64 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d4f37ca4b76a7989c4f3fa940d17f27 รายละเอียดเพิ่มติม hosttropical
aviator jogar: aviator betano – aviator game
https://aflomaxbuy.com/video/3f0e7e8bece26b44cd8fcb1f6b8cb15c รายละเอียดเพิ่มติม hosttropical
zithromax cost: zithromax and yaz zithromax 500 mg lowest price online
https://aflomaxbuy.com/video/968b2564be8e35c4495addb8242cdcfd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7d8d391051cdab1bcaa4ed57bfe0deb0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/936d24253d834e6efbd534e0501fdf26 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7095e6dc3b6afa56ec568b8f603b3e37 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a754b00ef7ca4fbf8c63e9254d58fb67 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e809d410f45dd27f11faab1d79794b94 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3220f3ff1ccb06a0bd3235240dd3e6bb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/322e558c232d14f0ea46348124a90b9a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a9d55b6843454b7cef1b0bb2a471d97e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7c72f7428e20de94d3edc29d6625dc74 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/451a74106a7814b8a409204aa5120362 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d544bb46d431a187c5f1b48250d9934 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dbe307bae8f84eca721d3c5e5fb5019c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/846dc156d839451c686cc27bfdc885ea รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7736e2da2a16c4c0b6c8e0df56fa1d7f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/92cad139ebb88a78ce663a4cd40b667b รายละเอียดเพิ่มติม hosttropical
Meds information sheet. Brand names.
baclofen
Best about meds. Read here.
https://aflomaxbuy.com/video/ee4e2b1f9457a495dbeb1bde545bcd9a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a99af1b0381c669032d88bec8b9a371a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/382b2974bf8b2bde2bb498ad85f4e0c9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e80e6ab4fe20aed1993c788d9bb9cccd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c331669206847e27bd324da37b16e287 รายละเอียดเพิ่มติม hosttropical
get generic mestinon without prescription
https://porn2p.com/video/aa01343b622d59d3cbbd42fab926368e รายละเอียดเพิ่มติม hosttropical
Септики Топас
https://porn2p.com/video/936fd4c5c9356a392d610a155eb9a75e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/03ba4f9c18d0cc5ce75bf5dc89892f0d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a363c1cac8aa0a0121be53f499a0a80c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e2163a533a4d387a23278373b88aa6aa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8a817344752e31274d6ba7a15bb12b47 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8a83a7453c4a0bff55ec1276e4d77219 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7d8a901c598defeb6a693012353fc435 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a046caba1fbedc538eb0734ea2d39d6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f4f8ba2f19d397fc337d1bd0031ff6e5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aff1958e49aae6f8aaf27f956f477195 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ee536cb929ce61206beeeda1bf50eaa3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/da895b3f701afd8c5d199a575b271557 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c33f9d5c056c02b0d9f975be6d767730 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/a9c5ad2e77293d3ad3fcbf2445085142 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a047552ffc99771f8a7e3cc0ac51ed3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e7fe4dc91d4df948e951d4cde06b4a5e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/90d9b76b835939dc867003a09675ab88 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/84669f26e8a59e673ffe9ba5007ee5f5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/145b47da612b899f55191994a75e8c26 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb27571a94b4b8bb52d5931c06352e69 รายละเอียดเพิ่มติม hosttropical
глаз бога телеграмм бесплатно
https://aflomaxbuy.com/video/45156e1c25055b1e511cb284d21f1953 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f504a5767c3f75acf7bb4f9f28941e4e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/daa5c9555e50e0965a2f6b4d770b1111 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/afef20097cac69b227d26ba50756c3e0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ee4e18a8d6ed5587aa639fccd20d02b3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9699742c4893bd5592e4bdfdb013fd65 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8a7d52cb2af3c96df0ee15714835ec30 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a025a293c638d55b0b92457582a9f60 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1a8ffad7bc2c28b125413b28c9240505 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2d0f540707f39451c7c0b5bb1e06fef รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0d86aa14d329bb9edc50df685ed8dbd9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bcbf71661f9feca753a49971a9939903 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/096ad1ee7353c55564493e2f516a7a15 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb29a79f735beef3c85bed3ca5758650 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f16e52e45921bce0ed94b2a5a6e9db9d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1a965326372316bebfecb4e7b6f7c0a2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d605736312346c4bb9fdd1145da5984 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2048236eeecdd5d2353dd1baba411877 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d6aa80b586426d5c55857b4028226aa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c91e5448e68ceca7a30680a472ca2365 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5ec67a9378764929140b71f2e5f92cf9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/23e195e8d6def8eb02bf721a2d55be3d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5459a62b80fa377073000ff74a59f24d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2ce06438843c5f9d46fa021a59197b3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/543d75c80b9e431587bb0010a6c62371 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0d693dacf640771aa1a28813dd93e710 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/263982688fce3dcf12127da3fe9c6620 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/644be104c535b567442363f2aa1b5094 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a3749cd22bc09f14adce8d41030e1619 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2630ae05542d00de8d284f314a882703 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf63b3916a07dd4067cfb153e96e764f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a37fcccde3bb27f62d4619fac70befe8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3a9d209419f5535e6d362ab1d9deccdc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d725208b6039b94f121e1c7922e8a37 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/69c9c3ea22cc4bb149e0c0d6578d0da9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c910f32896eb1633991d4986dcd58f82 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dbe9f72e5b5282706118b72a0a48649e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/23ce289b1ffcf34b20edc206839bdcc3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2c736b6397269a7503ab3e7670682e52 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/545071be1d863d64fa843ff667066fcb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7cdbd5a8cd4011c398606b3687b9f9e5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/263365b37b88f0bc67543f600f24b7d0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d60c1935f1303a9d3f0f0a7bf6047af3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6aaf64d16d1ce42c02a3348ea6066146 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a99c4c5cf3d11bf281a31b5ee61bd763 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4fb35797100ce590fcdb92808eb59916 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/775865eb6779b5e5e3d1f78f5df459dd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a38edbd3a801b35b9564b68ff6c34b9e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf55e36e97324eb0821647ad126ba49d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e221dbd607cb4682d132362bd6b3fbe1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a7f6271a3bebbaa659c1cd0dca550818 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3a940bac592185cf858f9f257001de14 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/69c7e3f8c105ed012909adb84a1cc5a5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2c717c0a868b86b48da5e26dac61c8e5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dbe65f617b3bafaa39e519b2b2edcae1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3f1f24523b4889bc03e8a5f9a379c28e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/70b1d9171f9439b3bc7dd00b4078dc6b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7cbd76a650cbace9fc9f82c266fb36e0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aff1a7d9ddc2b6168db8b8e13b2a63bb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a99cb47f1c437d665d6150c11120d5e7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3834d151912168081c8bb34361d2946a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/03bcf41da754a7bf243fc39f57679343 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/4fa48973701ae5faacf85b32a547a83f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/aa1f42fd1f224a0bbfdbe5cbca21929f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/323765773594e6959c9d692c396054de รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/45302f7f6dead9ad0ba32c8d506784d7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/93c2b1e48e8e9a48d246e62b8a131c64 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/84743aea3d03c9cc79d52b6ca7786c43 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aff60b2a7c63a067644087b498a25688 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3f1c9290b867a3c693aefd680fc26117 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a06b600f358d002ae8d19d4cd65aa2c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7cb8b299f61cd26d17193f56999050a6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c364d52a5690a6134178ae1d24613376 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e81b4e8668a3dc28a9d8f2a85620194e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/383273159a26cbe2020c327a0666550c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7d8de065e4aa270e7b5f5752ba3ca173 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4c0c18a4006205c150a5309d61be72bd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/aa1b76f5e653e7bde5b11e65f1478b8d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/03bb929c76ea7182433e164bcbd3419b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b67981ff9d06606d425a930b6c8e4ee7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/451e98ac5214bbd966c287692d65e439 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1471a0f50a86e44e59fb609308d93dc6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e21a187032d90ef396143f0edbbc4062 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/938f6c06374f4526c3448e6240e56cd4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ee569e5159f7c40b65c394f984a58611 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a7e4a380cec555af8ba04abd69039cd1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8470d1f1dc7c204a5b168a5892d06010 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/521ed371a5066ca7d03cb02d5fd2ad31 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a058a09b285293f1b0a6a2ec4f719ce รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/90f01f72423d56a8be6af4e5617421d9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dada2940ca372e6886cf863e249b8dfc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4bfe759ab41596181f2a7357865ba25e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1a9e5303c571dd60d1107619936e199c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/522542ddff6d314698863b46989ccf3d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f5086f1743f5cb39a301f4e8f3a152ee รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f19b53aef07f46c94d92f507f6b21c26 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8a84440f87efa6121a03820c3a423040 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b67ae6c20731977aba5cbcba5509031f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/588b303581208b322db7070bc8225dfe รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/145ece4beb4c7ecea026e2055c9023ae รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/96a867e824f47cc1df30cfe86446b543 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f1e5ead9e59967088baaef9061bb3d40 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/521c6e475f05f760a51604827a254f9f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1aac4097343842076aee204fa5da0f3c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/20607aa62f676e622b34a8e5fedf86cd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5894e018e6983df90f9a0129f7c91ac5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb2e8228ee7c50ca88320283dfab400a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/96afdb0f2493ce38ef4a5a087d05adf6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/09b8aae1abdaf1631b7e2121d0c153cf รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f1783131d4dfcc97ed33cb6fd8e78072 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bcc332f95ba8db63a8c0dc9bee60ba9a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5ec7499f8e6b89342b3956c21eba3212 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1a9c9f24e88a77e3bc83c8feb5a84cd8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d7673eee30da13c7660cd2c24d313a7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c920efa247b43eefb9d714a3bbafb8a1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0a1cd7f3f4f4b9e63fe18c73b39742a1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/20609f8637a52170677e621419704d00 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/23e4747c4508d957afd254e973408fc1 รายละเอียดเพิ่มติม hosttropical
Medicines information for patients. Generic Name.
stromectol pill
Best information about medicament. Read information here.
https://aflomaxbuy.com/video/5ecb4fc4ecbe5ed47d9f20f5b5ca29d8 รายละเอียดเพิ่มติม hosttropical
order generic avodart pill
https://wuaer.com/video/546417be19a29ae0c0121848e3a03a94 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2e247139fe21ac8fdb21e21a554fd4c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3ac4cbda18c445e9b1882b4df55a3e1b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf6aa5348e1fe1c4f5c84488ec64cc70 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a3a8ac216e4ec7f9a105965b09c76c21 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf668f9fb972ee15648996f96b60d78a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a9aaefda470404418ff9df9033734e31 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/546a1cc0decb58e2cb0ed17f385bcbc0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3ab206d7d9614b17eb22e24a7eeda094 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/645bf1eb65d6a0b87cc225b55c32072d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6abbf31b48a218c3953e3d47675194b2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c9256e196d5902816215b7bb9353e321 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5077a886f475b70dc108cae9102e0201 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d61ce0ed880b77f60ec88c6584296276 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a9a2bbd5d06934fe9f8bd102945b3698 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d6110edb152557aae30135180a9fb1ba รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7faff5accadef858679c7fb88ebe8110 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/69ed6c4619ad0817e7d34a79f3e7f111 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/325193bc8b93d97b1f02bfa910848d93 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2c86de81b403e922278f1ecc60c7a5d7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6ab94aec2eeee5eb722323dcb259065d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/70c49fafdc755464ebb1d07cbe5a5547 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf6717df56ad3796f2cb1e1f60cd3f13 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7cec135f20ea66f7503210358b64509c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dbefd1fdd0b7071945ff064b0df4a723 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b6852b84f607fde8a3054a5a0dd2e74c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/93448cdd579315ca4d606907cb04174a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/454ec9f6ed2e1cfa037e9f256c02fb98 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3840ad2678ccd4eae03944f369e09606 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3249ca7469bd6b465a099c16d09ad524 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/84a0c439e25ed031923c847cf7f72ea3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/70b8c8125617494884d2d23ad4fabc85 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/775c106a43f0a217f67cae95e1901956 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2e937aa03c4bc0ce239baeb02836633 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d618c9f9753b5a2ef70d00a5ffc40997 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/93df825915e43fa81b68ca08ff3020eb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e22babfed66813eac13919960a2dd692 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a1029cd3760f5e1ef4572a396323bc9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4c14d5b6e506e7188dba8608756a3794 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3f301e34eeb9cad70d5bc496d88e792f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/383ea4492da481a5ea293a67d5788722 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8a98c4d0083c5943b8c01817b5f6369e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/775b8fdecd222d2b0f33f8e2505aab01 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7da0d51764319c0b75067dc036c8cbb5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c93eab3133f89826c3e7582773dbc5f0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b67cd7c5eb7de6af919034644f6bfa52 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dbeabb9edfe7d027454301bde07bf70c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e8383d351ec1ed44780311b1ff5027c7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2e86225d712eea2a320ec0185d6c717 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/522b8f8dc32c196375eebbb11cc120b9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4539ae0def047af682050476487085d7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a808b83cb0314a930e432c9c5322b7e7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3f23174288e40bc7e0c9d7e857abd25c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/849f536aba9fe9d692dcb12a1917032f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf6d5318d60c745b60aeb44a6a8271f8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bcc42aa72b96ce6ac7a338738272dcd8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c396fdf78dafdb1aac8742be3a0b6219 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e223441b9815bbde9852212b638a8527 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ee5df7797a968010c53dae39856f3f61 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c93e32b506e1603c86dd0fd14ec52665 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a0814f5ac8a9e463b0292a26a950065 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4c14d5a13b66c9ebfcb3424592aa02c0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/03ce248a2153860505f6b15df428b73b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4537f6c90124f2ce878ff21b0d6362e7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb5b1a73a6ddff39fb200fdd3a80ff52 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d634dc53ad6c9794b2609670ad2caa84 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2e78f38ae58bca52e6f6db0fe31ddb6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dadc2dffa0dcad921ce6d764ffbcedb9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f52797929f28b03e5ae855f97da53886 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e82e0b9edd75ece092fb02bfa4ff0b02 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/206a75855297faa4dc2bb4a6640fd2bd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5ed213fcc8d7192f3b869e75c3976ec0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d8b0690641c3240a6ab0dcc1e04b892 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4c0cfa92d37dd346c6e810b8d26a2b74 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0d9f7ca870d92fad1e1f286a061feccc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dbf6123026aeaae4327b4acdcf2fad6c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8a891169edfa2c9411f8a194f6a619f4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f20a105472fd7cefda6c98101da30b43 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c92fbe953fb09081bdacbf2822a0fd2d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb5602502b424344462d27a000966bab รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2649cd12abb9d133dc9e1606b238c6e6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/58958372e98d0f9f2b5d7d6964a9d105 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0ace3c5cfb1aca3a50781d9c08ec1121 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a3c22afb2adf3a6ee191e1a2cf524786 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/96b919c0d3d81aaced82d0d74d880c62 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/241e3cefddd462fc02467f916d34eedf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e234228685d75eeee4b47dcd636b2822 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0ddb1417a92619d35b947af20b4f08fe รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0a9b8852f8bac20dcb2744703562f96c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1abbf6944f6322596bd44ce9f2dd6d9f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0d9da4d9bf680449dfc163c4f70da190 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dbf53d8ea10638246625090004a45e2b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/96c08d88ca49e4a3f30c79f8eef2cec3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5ed207a65206a6ec049ead7ee9e50da6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d63c9fbe7718ca8f378403f7341db557 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/54826faeda93e78ab418437cb6303a24 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a9adc7230be49b59d1865daa15c3e3d8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d83b2977cd7db504fffc8ce18e4cfab รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e843067a6d014bf2af3e5feea3d963b9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5ed55226e0c92a86910aae2d49fa33d2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5471dabf8dbb37ae4d2524281f841d65 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/206fc09372a21f854b0ae71d2289fd37 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2646af7833d39728319bfacec0baad3c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e22c6b15acd6a2f41df546cbd0a3a6ae รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d91849fd2d8cd9552971ae099e8de6c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/70c6b7172ba5927e45edc6f4251c6452 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dc04a3a5c6caa2219dbbe9de0bf2092e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6a5eb5e5bff932000cb1b72a77ffd206 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b0304f30963af6e227f73ba2aec222bd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a3b71f1939fb120f14bfe3a3144bbf94 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/50863f18492cff79794b23a65f178450 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ee6a9fec40070abd47962acf2097c942 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3ae2163932e4713bb76c9f013fb60521 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a9b21c06ecbb632c3724dbe887baa7c6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/38545ad6be6061d35c7de601ed2f841d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/50e16ee71595e35904ae50383bdadbc6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/775dda2dc83e28e50ae98ee64695094a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e2378e06e254e0b1521b65148ccec54c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7fdbb50b79c14a18ad495e8b348c8314 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7d07bfee26112ce02ddf74759d1ad296 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f52c7ae221700d5787e3901b7660d82c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/509658a3c97e7e81a756a595477fa25f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6adbda9a0a721d35311927e0d120f1cb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2c99ff6da6a2b7279adaf8abdd0eda3e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3254eb895dc605a46fe80ac8b759991e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7dabca88710b32390d983bb9457f3a2f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a9b18af1d4c03a889c177ea5777851d0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e84d333d7e4b14cc6e71561d02c8126c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/94629d93f3ef5d231990bcaadb79b65c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bce758a726c9494d2269210928833050 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9405a70d63bd4bddd497675cd3f5dab3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb62ba605f5890e27bd8cce6800348d7 รายละเอียดเพิ่มติม hosttropical
blood pressure medicines lisinoprildosage
https://porn2p.com/video/7d292910e9613f2b774d9e40cff84493 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/70d10619624034cffa7fd36fb9f01f25 รายละเอียดเพิ่มติม hosttropical
Medication information sheet. Short-Term Effects.
zovirax
Best about drugs. Get now.
https://porn2p.com/video/aab21456bb1af33b9fe38b7e7d3e2c9e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f53c40a00336b72cb21abb0733c0f618 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/945b93152f31cf888665d21e8c2ad52f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/03da259272590692cae0180b1173557b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b031b664e1d50407b1beeedc7674f653 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ee6ce52a63f7580c3e657c0711657f28 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a838349b28d1842f2c902b437e6f307b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3f50b61b4d96f60b393082ec1e12a991 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7dafb7f16631925ec2ab40306aaada10 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/942787a95b353d87048950ed790f7b64 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/775f602a7244dd9186ce8d52f349e827 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb7345f45b881dc14371701c97e6aafe รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/385dd96e74da6948dde87c1dc9fe8de7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a1f96e674279791dce8f527735b5499 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b6866a7096c02828b4f94ab830fad319 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f531b56ec96f5c6135703136453e6ccf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/03d34d39e98fcffd4c96aa5f0337c7cc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4562d3193f35047adc3658841803ee81 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/84b2f39be5ae59ccf7690df7adf8a035 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2f46b26bf6888477727c2bc9db6e344 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2f8cb6f077abbc8b35a4a220effd8cf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7dad12fc49d79d47d67d5d25ac9f36cc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/db2a65a89d7c3f884225e3612409b7a7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a16628891cf8e1c1b4daa12a4f7b999 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0dc8ab1c602b1cb403d277cf222ad693 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c3c47ce2fba3dce5199fcf97ab0da3fd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb684933aa726e84487e5dd31dff45fd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a132bc3e67c7a11ea37ab8034d83bad รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4c317d308b685ee5e37c1282a8216d5b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8aadf7039a575904391af2fbc7e32e4c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c94f329bf38a804632639ef221ac7f9e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c3ba65727c572b4a7201c467300bed11 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/84a5f5fb56f1474c59c2e11c4fada65c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4c23f6cbabb8de29c1cc53342907b848 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f2c0125503e0658fb8231153af0072f1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4556775206870e6a727648e717fde645 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/14a7e572b2f0250556adf0fd7fcb8f50 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c2ef2483a3c9c3fa28dbeba209f01668 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5233e1828b2b81449705c62e190a6cce รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/912588a9e76b6c2962ebdb6be25ddc7b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf7a4489544b6d57d3d68e44bb4439a3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/db0b40261a203db5a79921739c87fe0c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8aa1e282cae429daf54956060a0a450b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3b154ad699cee8eacf1b2fe81c41a2cb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0ae43b15a642126c97bcfc32364f96fc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4c15d1b7337d0ddb43fd52c5557c4c01 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1ad88bb37e782bdfb29d4583f2a0eee0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f2a8133ab55911365be0339d3d4e6f6e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c949efbdd686b287303e09eb43b171e7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/58a9e317f2fdb433ea78e451b1826c8b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/147d00aa4eb5b5fb0abaae49a7517615 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d64168dcb91dacba9b81c145256f98a1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d645803cc5bae06a087f9b8a4a42b854 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/911a4db48a109fb3d86c4f19b89d858d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/54b6822769d63e3603c81ba20675cd6a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1acc1ef691067eda434d857179bfbe23 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/522c183a6774d299fb3bfa3b5589f823 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0acf570088f2f564413256fe17ba1683 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf727907f119a9ad4bb34dd503f487dc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3af581e5fd56b285a46cd3efa65e4fa8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9d96c7edc38a88dc9fbf24f4d509d05d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5244960f086cb2773374e4690a8229aa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dc070f9c6c5ca94baaaeb603cd99122a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dc07be423cf421a893f7f0181dde92fd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf7fdd9b535372d448fc8800025c6fe9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7d78fc49f2cc263c6f356ae1be887cde รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2077636385e87fe1f04c4599ad981a2e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3b62711607ac1cede4095ac5124b5dc7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/549a51b79b748e6cf474c05d74f50289 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f2c07bede70a83ea66a4d58ca7c90f18 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6482a7dde4b2f16eafcc4ab6f823d68b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a3d3ab1c9bd3dacf4e3a3bac2c226962 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/58aac86d563ce22cc0cfd09bdb79182f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e237ac67eff8bbc88c7053877b318ec4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e244b793a8d061be27341281e5d097db รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/647ca40c4f758358fc13b1cc5f175c61 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9475e06650cb962fc1b3f744fa990e77 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8038533306d8042317ccca0270517412 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/949d32b042832058adcebc6592f65383 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2ca21d24bdfc7f17e833c74253d1e0be รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0b0158f38bbc965141b84a89513e2094 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/648e3ca15308aa37a1491d8390ceb5e6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a9b2943bd638b77bfd060a30033b486c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5ed730184343255f51e9a4fa91528241 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/266596262263a66dee0ff996cf8b0f30 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e858de817808360a6a7652074534df0a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9db66ee5b44387dbb99db75d5b7cd193 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9485dc8ad7a89580a22b620413f885f3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dc10a7dd1c3da9c95d1458aa153abd87 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/aad443fd3ac5d478452a11357a517e37 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/94b0faebdb2dd8557cf25eda298dafcc รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/54d8e2111def09b91c8c9a33c46fb893 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6afe4118a63ff9b76245a8075a1c3516 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/70e8fc898e10a6890aafe2e0c5218469 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b03e7f2b4ab67aea731afbb686365f49 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/808f5df5b9a2e25b3654b2cf196927e1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/648740ed4051443ca411fdfcd0b9d969 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a9bb2d6ae443521ea71df7cf5f1b9670 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a86ff0ccfdff4056d4e690c3f6a1297d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e256e098d87fe75648678ab20363e773 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3867aeeb3b7776b5ceec2fd05d700b4c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/aaf9c06b9d8d3d7dbccd2c13dde14b22 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6ade78e3b47aae7bf78246dc98be737f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/70f107d736b65394d762b03eed7282e8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/94cd119b5d3bb4d982e1db3b929a3bac รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3262cdeffd6256d5fddf0666fa01de98 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6afaa112a75428e5fecbb2d647be9342 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f53f10a48109c7de689685256668d1de รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b049804375ac2cba1774a451c1bb52d1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a9b3080a59226d4469e0923565b8d368 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/77893598aad0c397a978a8958868fb26 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e865ea8864d7a49a10a423a536581702 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ee97d14fa8949d8aef210dbefcde1742 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c459c655abc4ba08e5009db98b15916c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/807671f589e24b428fba5a6a1c94113e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a8c2822edf11fff87f227d898e7d46e7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f55e0e6c1dcb4171e0e0b2bac2878dbd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a8a8c05f5d4707eedbf9ddf4b6526bfd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3877c692117c581f63e89c128083c1d8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/70eb7ebd175a7c0722d8704437f7003f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b6b4aed64b8ee00c037b2f5f30632ea2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b03f490399ba1451a7fe354128b4ba70 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7dbcc05c7e59928be34083c52f665caf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ee921b906fd7e94733d71a234411d993 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f5519fc4a46ff5cba41acc6bc7ae33c4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd0dfd07def1a281f4bea7db99be3e01 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/db78d0a02dfec911f2956f3d7edd5bb9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7dbc8d6b68a9a79a51d777aaf7d0beb0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9487cd6363210c294090cf155cafb729 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/03ecc55be9002f36ee038feeb8d32326 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3f60e2c3010265b62a62c4ff9cb24528 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bcf1d426d8db7327e51f43ac029a43ce รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/84bbf542990d3ed8366df05f09f03e5c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f548ddad15588c16953371d95e44415a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb831c52bc324a1cd1ccc092db98a3e7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/db66a2cbe0c9993d61a3e798aec1a29a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c30af9514f80b0cf2cb9c58d6ed62eeb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f2eeb374c419f02db70db361b9861e5a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a29cfc015187257ea01c6f1c9f37e24 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a8870264805921f50d75bae409458d08 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0e834c306146c42a6581efa486fe5cdc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a2247381f7a57b239f60cef4855b78c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/456f9755b06bd32ee7b80b1c0da6ed03 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c303cc5bf41de47161eb19cedb17e92d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7dbb8004a676c0b5cd855a24b427d4f3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8acb460c762e9c9ac46dfd3eb406fb78 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bcef71855443a119b9810f1e43815510 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb7f011193eee09bde4335493e10a856 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0e7556689deaa47d6b5d4357bb0dfd6a รายละเอียดเพิ่มติม hosttropical
buy prednisone 1 mg mexico
https://porn2p.com/video/f2d6bee59dd673a0a897affabb9fd635 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c97c30dfa14ee33757964b78bd3569ab รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8ac5236f94bb7a8d3700c064cbcf2c48 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/24ff827eed439c4613ec2c8c718a7caa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0de1224c8156eb823d6e8d7a85bbb295 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4c34b4d8d1e657c393a403ea2a27ab44 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c96d69034f21505e4d448d65ff789ce9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/84b6251d5c27b69eb595f4a272c276d3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/912beb19ecd207930cadae65d3c677f3 รายละเอียดเพิ่มติม hosttropical
Drugs information for patients. Short-Term Effects.
cipro
Actual news about drug. Read information here.
https://aflomaxbuy.com/video/c3026551b19b4c921e249dfac936c681 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/24e955e38f0ac737cc2541bdfd445df8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0b163597200eb760659a3cdcefd8e970 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5532af0dcb3140e8384b10975fcd42c8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/91277d6a5c8daa94fcf2af013ac8eef2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a20224cfeebf27ff0b30eadac837787 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3b70c7fa45428bbc8ad99a91121d6338 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/14ae5a74aa6907a74971a67368ce37b2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/524936d1808171cfd9144f8b378dd398 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf836faf1791d4e0ac9073f6d63eff80 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8ab0ba6e86b4499b00edfedaa3ae4d18 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/96eec41d5a3e4d02ff0860e9c6bc61e8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c950b34838f788b3d84c60e4e7a6eceb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/24ad7dff14213a2be1830bc4e6efc4d4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3b67bfbfe2f4a4a55269419f095cdd4d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d64e106c607d725dcd7e551012fcb158 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/54f8d23004fefff0545b2b794bb995d4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/96e5a1627cba972925eecbafb5611c19 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0dd4d72169a9dd921aebf59ab188b8ab รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1ae088c8fb839687be0149f8b276eff2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/58ab7d54f11dea64b8f42240ff661498 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d64b3daf62d9f9c661174311255870be รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dba54705bea904ee19c429f9d11a397d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9dbcf1861f9ac6ab7484454eb2f65334 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0de65e6d2103ac69b83724c0ada75f82 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/51250bf42f257fa964ca54f2479fbc25 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/809114d16addceb0a04ec6f96d5eeb77 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4c413e95bd5d59163df06a6813d25f59 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/20830f404e4d3dc503358555aa55c427 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8acd194027927ecc5143bbcca178f53f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/207bbbf96866c3ffe6a6f5e58ed6a67e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5ed8abb4e7d3fb550af4e8081196abf1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dc141e7072d3687b2821dfcde723b4b3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/25052a651b8837de6b61affe9f9f32ff รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a3e387d02672da5e3fb4809b6d769da0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/14c00101ead2a8daafeb5e590184799e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5ef514b07cc404def9b5266b1cd3c254 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/52543a2537123da315603478216a56d1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/94cb2a2f2390c2d11570e29fdc7b3875 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7e1c6260ea3ee102197740ca7be672b6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cf8efd63b6b1e281a79a3138c3f7db41 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3b84cf33b69925ee5fbfcffaebcef7ba รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/554e44127f1a53dd7cf913a15195939f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a9bce6234ffcd1911e8bc1557ce5ca88 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/649fdf1119a9eb4c357c566b19ad1422 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e8747ae2d9d3457a3cac1ceb5d694281 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2cadc68c73e74313325483907263b8a3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ab026bd5a84a60de55f0295cce2c0a60 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e26d48bdba5a25bb3f8be05c09120c89 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6b60c0a5261ce58600ad20aacbfbeea8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b04c766caafba63c535e553e8e6058ae รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6b159ae606bdb2fc026783fbe8adf6a6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/eea68f4166643d02c270fdedc3b7e870 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/32667f78fa3ee2ff469263443ef50ca0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ab2ad79ae987fdc3739c3337c38e0031 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e87e81f05966362bdf3276dd03003747 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/815e115c29b85d515682dd867cb13124 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2cb84af266e8e7acae68cf92e196971a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2cb85d6d1501334b0b5b378976ae7535 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7111516223dbfefa33bacb1928a17450 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6b339d6e926ed2fadcac85f43821600a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a9c7c3804bbd337228d6f776f904e237 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c4799704c41a9a0d9a19e047ecffc73e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/eeb1871994f5bb4386dce0a3d474771d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/94f3e6f7b01212d207397e5e8f925205 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ab37a8d83bb56d9fa6bc531ff4ba2318 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/779a7a8aeeebc143e4724ff8f451e413 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7114476184a56b82515568841e29a683 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b07458375976c054646cc57c2f9e119a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f563143f55ec66741330d462d83a00f8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a903d11c9609ce26a1d2df13129a6cc6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c4857aa851d4ea51f92b032f7f6b2a21 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/779c2a82184e47c41374207a4f4b5dae รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f33a6c420724ca81127b1b78b34ef121 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb9195964122542ee156e03f13a5eb20 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3f838c96d7c119bbe468577b9f6c2c3e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/04070e06d41163d3551a7600867bd4d8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dbb1db7dc37ed665ffd690c5622ab6ad รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7dc37af27d8e11a9d6fa5da15d5dbe84 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/0b6082b3fb3fa8a875823e5f0a75a363 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0eaad1b7afefa4a78f05fb1d998d3335 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4578e55091a0459f4e55b45c0bcc2d87 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a3bc12c10de3a31810e25dab2b0b0b4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb996b33779fb3728584158ac45cab85 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8ad2f507c58defe494902f5d6353da66 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/45797991f9dc802a17d9531fba253b17 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/84d0cf02e63f8bb414bf84da64e224aa รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/41839e3a9cc6dbeb8401b8f92e0d07d9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c3231e886ca48a914bd4ed83cf4ebd84 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4c496c9c7f329f2b4c2dbe03dd240893 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0decc4f6e18bcac72a1a3575ad739acb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/913d60c3c40c9794a0e789a179ecf5e9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4c4bd164e692745b1ae96f6804717238 รายละเอียดเพิ่มติม hosttropical
All Roofing Services & Skylights
5.0 41 Google reviews
Roofing contractor in Toronto, Canada
Address: 19 Sabrina Dr, Etobicoke, ON M9R 2J4, Canada
Hours: Closed ⋅ Opens 8 AM Mon
Phone: +1 647-560-2688
Province: Ontario
Areas served:
Toronto and nearby areas
https://aflomaxbuy.com/video/8ad48258ab3d91b30fe51fd8b526d807 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/555860aafe9c71914d467805c6f04e0f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c992bf81034b3d40f02411cdcf634d5b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/52597cbe5ba87d4e72be750a36690b30 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/14cbab52fa0b62a916a5bef35204f17c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/96fb1ba768da245f3aba5773b3f67bcc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/525e89846d58551a161e78d69decd890 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/914500789e6dc5e90327d140291c864e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/51778ddef785b7f5d7793f3a21f79005 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/58c0f4c220fe41bdeab10793dcb3e306 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1aeeeced79d2a10f62bf7588d10e24d8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3bc342f5fe8c69407b88b19d915d43aa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b6cf7fe62e69dec143d42ea30159e0a0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/58c74a8308b4ddfa7e8ff19e448bd1a7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/96fcc2fdc1dae6cdfd84b29bea2ffd17 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d661d0a7344387a2ee0a395686305328 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a90f5e7acf41c25ba0c76c00a1c513e6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2098c11a2e0d6fdd2cfd87015e09f1ce รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5192fca1e59aedea1f36f9b91090e1be รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd25a5c9de1018f938c6961bcb97bf94 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7dc7a645786e8138ea4fad7571a52520 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5ef9f0766bfeaf48307ac9ed33980a36 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fb996e87d2158c2a86583e85adf6e939 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dc2c10a102da458c2bc639e310d61085 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/040ff68a7b0ed3846d66e9cdc543165a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/268695bb7af795c2559928aa4c179f0d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7e4c1ec25d44c3c03edb0a29c437aed4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c325eb3b41481a65baeb971486530b4c รายละเอียดเพิ่มติม hosttropical
generic macrobid prices
https://aflomaxbuy.com/video/84d345fe9943edf4c9c19cf7b5d4afff รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/81fba94b4da7c7a7a34144a4d0acf789 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/64a4ab6555178cc7c690ad9fbf45a9e8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0ebd9ce918c2a9194900b605887ce3b5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a3f7626096c5a39ce7618f36006a513b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e27068495b412e43d0b966689b29e5c1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a3d725344ef84e413b4f7dccce999ac รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4c6bbf91121c996d9718c358c9d979f9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/94f2df52ee8ae7577e6bf37b9723bbd8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8ad9711832defaf9286de39f2c782350 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c99448e009d65ac0fd10178fe8a124c4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/94ff772f6d576a13fe0ab0c6f8f3b3cf รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/25877b689459fcc5d5b754d2b0983559 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6ba99e1fbde7be7fc63f836f94462401 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/254d53f84979668156d9fb62071c87d3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/14d366eb6d51d0c646341ce3a10f731e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0df475e232fd5090de9c500df0bdaeda รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/52621ab840e3888d098c5b03d909ea7a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9146a27acf4b22203fdd5f0838fb92a0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cfa8d09dafbf5d4c88ab649504ae9950 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/914698398c9a03f10f4da05fe488871e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3bf471a9c3be81f6c09bb87bc20af92f รายละเอียดเพิ่มติม hosttropical
Drug information leaflet. Long-Term Effects.
avodart cheap
Some news about pills. Get now.
https://wuaer.com/video/8203a9eb04f0613e76cd7a4b85d5ce69 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3bec25ca66298705106db972d13fa288 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1afb3f2527603bacdbcf8d20cd8a190b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/14ce9bcc9ad24eebc742478b99689eab รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/58cbfb5f66ff76e5fea089c4e115f073 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/970a94983be0fa02f6b378982e7c449b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d66e50bbd311387224dc4d1c512a1e95 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d668f9ce93240b07bd7a68d5a8c079e6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/96fdd47c16d223631d50e6a420e318e7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7ead638b06c641e77a06a58893f8bc8a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/952008d2c849fb8afe5391e0a2719aae รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/519ace4f19dd0f3d7a345d0a72f5d469 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/209d13bf011e115d4b47cd66d40522d4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1af57809016e18c322ac9a05bc33323f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5f0dd8fc7dd078674a2cbc0213093d5a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9dd35e0fe37416901ac7bdb941a40ac5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dc33d8960df7b74199b2531df565102c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dc315979613d1e3cfeba3c5dec3117fc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9dcd828933b5ded28d89665dd581beda รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/954578c0b0fce037f37384f79bb4ddc3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a915daa5c20b2cab29f1290b43618816 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/269262d21a0b10e07899e15eb97d4b2f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/209cb7ab2e96039e4942ab6f9c798860 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/64af11377860870c5f8d9f08a385a09d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a3fd6308bb2b0104238cbb0f161d1225 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e27e3779c29f895bcefabfc5a7b8040a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a3f92fbd7d485218a8b14f239fd9a7e6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ab41f2f50eb0529eda9af0fa40e14bf7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/94f8cf6f2ede522dd68c5315bda150f1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2cc9dd824c189542bd2aeb6bb365f7ef รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/269219f2d0c2558c820f7ad6af06e8b1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6b3cf97e246bc643787155260f9ed0ed รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/26968e0a178aa718e3e80cf708dc0f69 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0420bf2fc07ab7d04801854da29660c9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e88981999798d4a7a0d312db9dc85e9e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a46cad96f41d0067c4243cfd289f0ed รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/64af872a2a07a4dfa7e5a522d36fccd9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3290bc63724a7dee902bbf90c3335ecd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2cbd0e3a32d2bd04eb22b367983d450b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/712d48b4ac464dc4c62c7056055b02a6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2cccd5a6c6d0e82c8452c241b1bdb709 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b0779c88095d71a400bd106159324494 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a4aefb7c70f3f7ec6be457c8234659a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/eecc7448b792b3b357851ad31ad2a0a3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dbc2b7fd8ab6c3d90f88e956a43f34b7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c48fcb10d85c5628837f70729d284625 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6b4351f67d9fcc1047a01689d98d2612 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/38ad59104391c4d5c8fce27e305cf45f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3285f17a2d90b9b96e444ab78c558ed4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/77a6d7dbfa377e2b8b45fa630633d88d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b6d2609c24c511d626288d1e0aa896bf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0e0a578022407387b8aad3d3874c0ddb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f57de7aab8b0ed743f63cdb87ae3e993 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dc11b32c83140adec0bec9673e887f20 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3faa6142f09f0346c8f1f6bf3672468c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f358bae13b0bdf56b8d7c031c66615be รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd3603f07c177103c6d12fe3f68b2d99 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/14d403b723f664fc9ea0f434b689e67c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7135930845c00441fc76b0ad5a19f856 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7dd9c09a0c1bab7e80bd50dcc62e9169 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1b0405f5e76fa4c7ee714af0d0b9b5cd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/38b05ea6d95c0a4d29bb5b326437bee6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fba82c698e6539d2820cd4fef889c1bc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4590b3d8c8b50c59e9e30387dd4193fe รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f57e54485e2349d7f777007c56b03640 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c33418f4c66dcfea3ec0f17ef3e05c39 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b6d784f5bc6ce82da74e2c6bdeae355a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1afeb6a6791d9a390d8bb66a4d75db65 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0ed7c6ba6d38ae95cb22720b232cf0f7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/84d4f91725a9af3aabf1ad080b38f226 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/20ac68a3e3f47085363531bb57ec2f1d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/55f4567bcd969c587a14a13ad10e30df รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c32a711e937f4fd9937b18f42c19bd15 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1b0047643c4f5f263a33595c2082345e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/42062ad6ff31bdc8e1b38f7951bee877 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5590686cdf061a301408be2989337118 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c9a2dc504841281c2e52a7b457059e9d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd35d08041bbbc682dca14f14f5f5968 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/25feea7ff03934c56ade0d3e3d34169a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7dda5bee2fad982f4bcc6650113da009 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9152d89a9d7ab9169318a6e629a2483f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6bd453b6020775c45961a54df1a09e4b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/527322197e1cfa1f43bc852fe2a3d008 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cfc7069f92c473eac184e875f1a575de รายละเอียดเพิ่มติม hosttropical
клининг служба
https://aflomaxbuy.com/video/58e20b5aab1698e5b77854b157837322 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/956930fc9144b1b7bf370ca6fa9c2525 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3c605415686a7bf50c4f3b57f91b3d3f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/84d88a124e2e129602f953853ddd0280 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/97165b4b95cb5fe5ded535a98aaac195 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/970be15ea8ea336208acbdd349c0e684 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d67ab554d01cd49817b2df7bbfd7348d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/82317e6dbb6ae2519e5f87492b3878fa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4c732755548d8954b087196e12ac251b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/269a8a0629d6d0d196fd2bc957cfcec5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6bb2e1b12aa8e2bdf7b85618ca8c1547 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d678cb46b84cc1fb0a4b682a8c33841f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/25e0004d3d75c30c041a5591f3d7a0ba รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a9b4b9aec9e37a84134a2667961ce77e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7ec4d27a3fe9dd340bf90e27031af2ba รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8ad985f6eb765325cc7ff1994afb027b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/38d48906fbd11315e3e6f7fe6472044e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/32af898066aa66e624d036ce5dc13876 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dc4647df957e6d9e2a78f5afa4939a29 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9548785ccfc9e3859943b79ca62f8c67 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/52721ad2f2266ea424ee3e2e1a08739e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2cd0459d8ca681a80fe15851946a9ee4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5f21ce18301b1da740e2fed8a5fc15cd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dc436890988dbba7412e2da758e50f13 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/64c52098e47c4b9e658ddcc3529ea529 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0433af33d721137153f6599e6f932a71 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cfc10963aa4160c37bac22b9fbbb924a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/959100f648568e84fcc6607c37b44d48 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a415134cdc17cbb8ae7df9f736124c82 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/38c389149852585550f8bb44919e7f2b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e29dd03ea5a91189b70e5589a7840469 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/58d1d80f8b22a176e095ba785e071a94 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/329d0502b1da5dd1476bd0aa100a2899 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e285ee6279859d720d046f615ffd43a7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/952c71d472340a241e5427c0a445023f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6b47f19a8e06da811152f3e6a9ab3cee รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7eb4ec4ee8cdab8ed6263fcafbec3104 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a59a3908ca820bf396317fccb0677cd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ab60cf47abb1fe1974a61f67e3d36c90 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d678c933378e7f5e8f0973790b854631 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a9d8bcc6d503376ec575891bf9f84d09 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/970bb60b9c97be76d12c5ab4e069309c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e8acc5a811efd59b7db01c9fad8e3990 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5f178d02aa1708d84efb985ef0a471d6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e8a95f06ed9a6e9d3d8047b2c3d7ab23 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/713b50e21a6694f37f5f4d41a10e08ad รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a998dcdfc05c1c99791ca9e91df1b991 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0e0ee0b36c660c5d9a23242f00eca2d9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b0844cde98c4afe14be726aacb516d4a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4c801e33559f3ae2021a54e0c8a3c4cf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4591190a8db043db6b31878cbd994079 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9dd8edf91207025c3c2c490f2c7260dd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a4b20b73a0610f4cbe529f493d969b9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/713aa5acd392bed496a8a8e6ffbdd30f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/77aff18688b6a9af5b076a353f7cfdfc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/14e387ee30cfc8cc3d24a7139425139d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/714bcae759cf0d3cb803ad60e8ba94ca รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dc1970fef4cf5a6ab2267a977b7b9768 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b0846094d27c8fdd94379a870686d0f8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b6e3cfd4b75373c9fb12d3f1f6176b81 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/528f14a00307101748e464154cb773b8 รายละเอียดเพิ่มติม hosttropical
Meds prescribing information. Effects of Drug Abuse.
baclofen no prescription
All information about drugs. Read information here.
https://aflomaxbuy.com/video/eef98891aa49c86c4aec43f11f827004 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0e17592dee311cbb012b08eefbd23a25 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b6de5607c566c4f039e4ffce09f29303 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dc5df05f502f48b39bab72cf62028206 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4c85b928d15c198b2f4dfdd58443df62 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/77ae0dc332d72b02a8767b6f8d750b94 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1b0458f2c16ed987c56feb5cd3839966 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/77b04dd86facef0a1c4261b9197f95eb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b6e694f498ba212fa055f113672bd021 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/58e3533f66d1c5d2d0a4f5593717bc4f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f5a9da32bf6d46859aa59e7ba7734f66 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/14ee5c2ee28056309376992c5ded8a45 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c9ad69df5210efa68cc5496207fa1c64 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/14dc4d5c89e11492a7d148ee1c74fff7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/52961c8fd882275a2ab30ddcc29c44b1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/84da2571a71b73956ae7dc1cc1ec1063 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5f565917d75f9c387a9c3f7ad44fb082 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/20b0275403c654433cfda5ccd8be3fe5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7decc41414d0e9f5691fdf5824781b0d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c33f1616abf506a41c5e6d5a3e06fdaf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd40b62bd3a8f0ee6942878d2d83bee1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fbc2c1c513cfb02cfce5f628b41bfeaa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1b10245f83e0bd3ce58643b8226eaaa0 รายละเอียดเพิ่มติม hosttropical
авто в корее https://avtodom63.ru/
https://porn2p.com/video/0eec78063fae327565cb9e1e0b0647e3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/426fcfd15c41be7a85830fc6aa57c48a รายละเอียดเพิ่มติม hosttropical
септика под ключ
https://aflomaxbuy.com/video/58e39d7a6952282011ab85addd9c2238 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8ae41bf183ee6479a56d7060759e4e0a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/64d40f3e0beb25878e8caa4de6434cea รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c9a40692873edec60a1392c18159f7f8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/64c57ea191dd07dfa3797ac140e046ea รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c340152d060e01f961e0a10d30ba68b8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0f105b238ded25ee837a97cf7338a1a4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/266925a7d17a4767869db369da2784e2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5642ccb5b562b1ddc247f6b1ed77d3a2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5f52dac1fa305170356e6e71c79fc381 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/915496ca16545216689036a985711671 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6b61b5cc3c2443e68cc33072f23ccc4d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2cd100b895d72260d431ca310e735b6d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8ae62b8754872664010ad7ba86528759 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6b51e21617f3cf8a6efe583fd3a03145 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c9a8d228e4ad5f525f9a7b0b354a6ac0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2687353de5f250e486b755eb92e098f8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dc4a2206888bcd04e663fbf0512254e8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3c9c12431f9ea024e96f12adddeaa2de รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6bf0a9def781c3d8ef7e51a5d2d50890 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/64d1fde0fa399eafe9f44547c01d5a4f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7f1c7b4b279d616471583946893e6d22 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/715673f203f75f4699e0db5d27cd77ed รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7f01d3c7938c1eab5c8bd178596c58d3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9157fdf533884c6d2a5bcfd47685cf38 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/95929ebc48be2046487d096e0d1e864b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9584991bb97c50e9b06003882941c9d4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a41cd88448d37c367bfe40b58ef2cb86 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2cd322fdd3be7cb1581089a612f58180 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/32cce9754aea41401b08c41860dc997c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/827931d256783069e1f734f4a7918c56 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e2b576f6ae70057290fa84a5e1cf7eb3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6b5b0ee4125be2c55a5c8b356e21f866 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/95f95e0565b41a9966a0fc38b9dd4c7e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/77b5d0920f9ce302a9dcf28e316b5275 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a41b79e66715d844744338298e2b97eb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9717409a1e46858f9936ef1c303f4478 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a9c6ff18c9abe7d1fe06b377553ccde1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a9c54266b9b614698ef66f6dd7e4192d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a9e34a10e1bcf08a0e468adbcef498a2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e8b71fdc758c653ddfb2f91fe0ce8d78 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/32b9d31526dfdcba49daf1ee1baed164 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9583be468c4502ebaa4a9c3342ad2367 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/abc2bebc9bc315853f897225e3ff45aa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a9dcb8a7ad8456a862e108f3183feb79 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/04545ba8c19ded539c35733732bb373a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dc4708c22108ac9a210e66b2b9c59848 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/95dd395d891983c1e874bd575af3477a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/38dfa56e313de609e75b294f228dd798 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a9c407c83760cf5b3c25ec09018be772 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7e00a4b4ee01df5232e10453fa6d703b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c5f268d8212c87674c2e496fa69b4bae รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/84f679c01e66205113f6273117ab6b91 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b09086bba239ed37f1ac1832d0b7ac86 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c5ef89ea61510a8db09099bc3531f5fb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a41a9b897c8c0361c5c9f486dff3a6aa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a62d92a1fb4757698f501c5f16290ce รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ab9327a7da39bf06426ce8d0299d1df0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/45bcdce6e877e78877b507fbd895f259 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0440a8ce8299823ab96943cf4423982e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/84fcdc4dfcbda94eb775547e8087cca6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dc998a5435102c17092762216f68baa4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8af832b2bb87653504e05cc5fd934efd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b6eb80bbd2ee4bf5d6e60e8bdccccd1e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dc63026f03be1dcc651bafe9ba5d9647 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a9d918d04a56d21dd341a82f5af69b71 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e8ae6d9ad827d5aa97af12e77425c542 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fbc358a64a6dd6db7945fef2bfde6b7a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c5ba621d651ed97bb8e5933c1bf9745f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/45a10b744a5941f4330a387f54446823 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4c940069660e769f98aa66a9ade8c7cb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fbcbac4c4bb9cc4a9fa8fa0b9a66f740 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8af95a4eeec2769cde23c01e5a1cdeef รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f3d6b457ca6c3ef9ae7616743dc88f06 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9169501bceebbc6eab0bdadbe886f3dd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd473fc298eddf3fc3e632c7458261c8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f3cb72414b20c25b6a6c03e3f3c1ac11 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c5fd96a1d159efbe4917df4b0eb11cae รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/14f5f576a083f1d39bdea51313707e69 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/14f183aaf5df5f425a99faa51f7a28b4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0f48dd051c4879a6e74d110654911b19 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/52a99d38c30a1a2b216c3bb1e4d4888d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0f8afa99a41c2a029eb297ce20ecf5a5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b096051500a744a3fb37546658c24e36 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/91695a8d0fe858f2e9eb59ef8e77fa86 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef0419c3aa8396d962e793c7bdd95bd9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/42f57af6cfe38c11b60f5e954d127b5b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9720021ab54d1da38989a23ab7be7ada รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8afadba975de027dd2f3c5c03f21a605 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/42786556ccb74d445c5381dd91297e12 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dcf5790003143801cbfd5ca386b901d4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1b15b1f4f2155434462d079e4abecd31 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/0fc48a7b7c2a175b5a19bd3a769873c5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/58e9ecc95b55083bb59aaf92a4652101 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/26d8a04d5adbc0f327e2fa71b85e4ad1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/58eeb901cdf88d212be520428530db28 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b6ebf0a5b1461c281fb0991c09c711f6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f5b22e9f6a4e83f89aa9df0bc7e4014e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/97260eaa90b53ea7b5a960900e84682c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/56cbabc3fa921a59d29740f1b21c4d47 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/916c7f5860c8c41fa72fa5483ad2cef6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c9c1a5191107b60338d49bf0f251ce08 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cfe0035a473c2c478510e224844f0a3c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/57146f1842acc48f331c66109066e1cb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/273abb7ec3eac9d997bcd6f55b7939a6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5f63958800458917fa567455929b30a7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3cd54cbfb7a20f8752b138d974dc2b7d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5f6ca1fb1771ffa7510a725fee2b4c72 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd54858f0c3b0cc54900f912d0dc86c3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fbdebd4934b93e640770aeb99051fd8e รายละเอียดเพิ่มติม hosttropical
Feeling overwhelmed by the constant stream of updates and notifications on Facebook? Antiban Pro offers a solution to give yourself a break – temporarily deactivate your Facebook account. Our platform makes it easy to step back from the social media noise and take some time for yourself.
Whether you need a short hiatus or want to reassess your digital habits, Antiban Pro provides a simple way to deactivate your Facebook account temporarily. Your profile will be hidden from others, and you can return whenever you’re ready, with all your data intact.
Why choose Antiban Pro? We prioritize user well-being and offer solutions to help you maintain a healthy relationship with social media. Take control of your digital well-being and enjoy a break from the pressures of constant connectivity with Antiban Pro.
Ready to take a step back from Facebook? Trust Antiban Pro to help you temporarily deactivate your account and recharge. Prioritize your mental health and enjoy a digital detox with Antiban Pro today!
Antiban.pro – support for recovering hacked instagram account
https://wuaer.com/video/6c874796bcd36cb3d25f17120fe44a75 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6cd8d5540a72c74d55dff6cf4ca13a65 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/66fbd0b551e11fc1ca1b5a6eb542777f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/65004b0e5ae268ac59fc8884f90c4728 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a421a7f1f1b0ab8d7b5c75e603f6936e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/82dfe0b5fac04f509ad05b2c9ec1d430 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2ce98edf6ea3eb2f3a33d546e0f8edac รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a9e40747b8b40e9a4ab90f525c87b6d4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dc5d16588b169a3f8a80e91ca6b18c7e รายละเอียดเพิ่มติม hosttropical
Meds prescribing information. Cautions.
cleocin pill
Everything news about pills. Get information now.
https://wuaer.com/video/9605ead64343881909f7034c7da605c2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6cbe78e9f84727911056a3830430a027 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cfe53c760c1866351a91b6c36c3071bc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/96067b68647426099d5ee947e9e8e781 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3925baa76e9c87bf28b488b2b7f9c12f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b6f152cad2191da397d0d7ec2a5774dc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d683b15bdd94fdccc2ce27849158f365 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6711097d2e8883fc5f5d85e7ea0d0cfe รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7e0d01db44ea7fedbad4a846211dbdb4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b09b8ac50b00e5c5ae849650a201fb70 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef0b3a7dbb3ca0b3765e0f4ce8b6c408 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/85008da16551b550a2f6dd986e2c7d9a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/45c5a95a5b92e37adf3b7af6a6fe3d94 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b6f11ca3bf13aaed2d04b1530c71b3ae รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8505193e79dd8f9270f2f11a0950b1cd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/a9d022e6cbf936411e031ce187e9d145 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f5b62ed214dec6999ac6ce6f29720a57 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0e3c25aecdfae48e1df32d4a65897e1c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4cb01cb98f33cf5d68c0e4bf0215bfae รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dd36952e4563e3ab52bb5a1bd31a66b4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e2b5bb8e971537720e3f5d2baed7b6d3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/95fc192291969306ee7380bb580c29db รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c9c283a0e0164e49b029f9f1f3ea57b4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4cc062278ce11ae74281448eb1797282 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd56593d53be60ebb012d77419a518ef รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8b1837cfc086ea172a56abe69a6e39fe รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/04660db8fa5d4db9194d9feb22c0d026 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fbf9bd2a54a9e48e3dc01753e403e9a3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f4365da6cf5f2533e141a8b071d5ff98 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/cff3129fdcad85cdf3881ab490de04b6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/100389b9fdc655b633892483fee535e1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd698f96528beb38be4426ca5425dee7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/046e91ae4b563b3496db33adc1230754 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1b262d3a29b0c089f7b310f93890748d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7e115ede1e5c474d212498dedd6d3701 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/150ea031a4656cd4d91c63a1c4ece178 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9192f06614c55bd78ccef5e3757381a1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d6a4011a55cf8745d96668d12cdec659 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c68b97872d8559b5f6b9a70128e6f14b รายละเอียดเพิ่มติม hosttropical
Доставка алкоголя
https://aflomaxbuy.com/video/1b2bc4023618f6622e8d19fad8df2f84 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5902d2a2bcd696982c72ec8341ce9304 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/974c022abc9a89f0aa92db9d122d0961 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f5c057b63af9b25914b6895e0c77ef99 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/26df17733612a5faeffd501fbae18317 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0e45b17571cda66e64f1bf58ece2709f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9e29725937d790b8d59b4e43ea53f675 รายละเอียดเพิ่มติม hosttropical
обнал карт работа
Обналичивание карт – это незаконная деятельность, становящаяся все более широко распространенной в нашем современном мире электронных платежей. Этот вид мошенничества представляет тяжелые вызовы для банков, правоохранительных органов и общества в целом. В данной статье мы рассмотрим частоту встречаемости обналичивания карт, используемые методы и возможные последствия для жертв и общества.
Частота обналичивания карт:
Обналичивание карт является довольно распространенным явлением, и его частота постоянно растет с увеличением числа электронных транзакций. Киберпреступники применяют разные методы для получения доступа к финансовым средствам, включая фишинг, вредоносное программное обеспечение, скимминг и другие инновационные подходы.
Методы обналичивания карт:
Фишинг: Злоумышленники могут отправлять ложные электронные сообщения или создавать веб-сайты, имитирующие банковские системы, с целью получения личной информации от владельцев карт.
Скимминг: Злоумышленники устанавливают устройства скиммеры на банкоматах или терминалах для считывания данных с магнитных полос карт.
Вредоносное программное обеспечение: Киберпреступники разрабатывают вредоносные программы, которые заражают компьютеры и мобильные устройства, чтобы получить доступ к личным данным и банковским счетам.
Сетевые атаки: Атаки на системы банков и платежных платформ могут привести к утечке информации о картах и, следовательно, к их обналичиванию.
Последствия обналичивания карт:
Финансовые потери для клиентов: Владельцы карт могут столкнуться с финансовыми потерями, так как средства могут быть списаны с их счетов без их ведома.
Угроза безопасности данных: Обналичивание карт подчеркивает угрозу безопасности личных данных, что может привести к краже личной и финансовой информации.
Ущерб репутации банков: Банки и другие финансовые учреждения могут столкнуться с утратой доверия со стороны клиентов, если их системы безопасности оказываются уязвимыми.
Проблемы для экономики: Обналичивание карт создает экономический ущерб, поскольку оно стимулирует дополнительные затраты на борьбу с мошенничеством и восстановление утраченных средств.
Борьба с обналичиванием карт:
Совершенствование технологий безопасности: Банки и финансовые институты постоянно совершенствуют свои системы безопасности, чтобы предотвратить несанкционированный доступ к картам.
Образование и информирование: Обучение клиентов о методах мошенничества и том, как защитить свои данные, является важным шагом в борьбе с обналичиванием карт.
Сотрудничество с правоохранительными органами: Банки активно сотрудничают с правоохранительными органами для выявления и пресечения преступных схем.
Заключение:
Обналичивание карт – весомая угроза для финансовой стабильности и безопасности личных данных. Решение этой проблемы требует совместных усилий со стороны банков, правоохранительных органов и общества в целом. Только эффективная борьба с мошенничеством позволит обеспечить безопасность электронных платежей и защитить интересы всех участников финансовой системы.
https://aflomaxbuy.com/video/dc716053314e8432a4b46def5fc461b1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3d1db87fcc63f8d69813a5880124ffc3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6d86faae4ecaacac7fa023faf03c2065 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/26f0ef5578c8107927672d84a24de55b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/652a9decf9731799c5a9d9f1cd06ee52 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/833ef80d11497890d8bb90e82a92783c รายละเอียดเพิ่มติม hosttropical
Покупка лживых банкнот приравнивается к незаконным и опасительным поступком, которое имеет возможность послать в тяжелым юридическими воздействиям иначе вреду вашей финансовой стабильности. Вот несколько приводов, почему приобретение поддельных денег считается рискованной или неприемлемой:
Нарушение законов:
Приобретение или использование поддельных купюр приравниваются к противоправным деянием, нарушающим положения общества. Вас могут подвергнуться наказанию, что потенциально послать в тюремному заключению, взысканиям или приводу в тюрьму.
Ущерб доверию:
Поддельные деньги ухудшают веру по отношению к финансовой структуре. Их обращение возникает возможность для благоприятных людей и предприятий, которые имеют возможность попасть в непредвиденными расходами.
Экономический ущерб:
Распространение фальшивых купюр причиняет воздействие на экономическую сферу, вызывая распределение денег и ухудшая общественную экономическую устойчивость. Это в состоянии привести к потере доверия в национальной валюте.
Риск обмана:
Люди, те, занимается изготовлением лживых купюр, не обязаны сохранять какие-то нормы характеристики. Фальшивые деньги могут выйти легко выявлены, что в конечном счете приведет к ущербу для тех, кто стремится воспользоваться ими.
Юридические последствия:
При событии лишения свободы при использовании лживых купюр, вас в состоянии взыскать штраф, и вы столкнетесь с законными сложностями. Это может отразиться на вашем будущем, включая возможные проблемы с трудоустройством с кредитной историей.
Общественное и индивидуальное благосостояние зависят от правдивости и уважении в денежной области. Приобретение фальшивых денег идет вразрез с этими принципами и может иметь важные последствия. Советуем соблюдать законов и вести только законными финансовыми транзакциями.
https://aflomaxbuy.com/video/6b842a43c2e8635b8975a5eb9a3169e6 รายละเอียดเพิ่มติม hosttropical
рейтинг септиков для загородного дома
https://aflomaxbuy.com/video/e8e675dfbd60c0b041c3346fc49eed74 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/96156bec2131bb0a68cb259e845c9db8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/32e4109c0f6c6382b7592927419d7668 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e8e752cabc979232d7a6691a47d1cc13 รายละเอียดเพิ่มติม hosttropical
Фальшивые 5000 купить
Опасности поддельных 5000 рублей: Распространение фиктивных купюр и его воздействия
В сегодняшнем обществе, где электронные платежи становятся все более расширенными, преступники не оставляют без внимания и стандартные методы мошенничества, такие как распространение поддельных банкнот. В последние дни стало известно о противозаконной торговле недобросовестных 5000 рублевых купюр, что представляет серьезную риск для финансовой инфраструктуры и населения в итоге.
Способы сбыта:
Преступники активно используют закрытые трассы интернета для сбыта недостоверных 5000 рублей. На закулисных веб-ресурсах и незаконных форумах можно обнаружить предложения поддельных банкнот. К сожалению, это создает хорошие условия для распространения недостоверных денег среди населения.
Воздействия для общества:
Возможность фальшивых денег в циркуляции может иметь весомые последствия для экономики и доверия к рублю. Люди, не поддаваясь, что получили недостоверные купюры, могут использовать их в разносторонних ситуациях, что в финале приводит к ущербу авторитету к банкнотам некоего номинала.
Опасности для граждан:
Люди становятся предполагаемыми потерпевшими недобросовестных лиц, когда они ненамеренно получают поддельные деньги в транзакциях или при покупках. В итоге, они могут столкнуться с неприятными ситуациями, такими как отказ от приема продавцов принять недостоверные купюры или даже вероятность юридической ответственности за пробу расплаты поддельными деньгами.
Противостояние с распространением недостоверных денег:
Для сохранения сообщества от подобных проступков необходимо повысить мероприятия по выявлению и пресечению производственной деятельности контрафактных денег. Это включает в себя сотрудничество между полицией и финансовыми организациями, а также увеличение степени подготовки граждан относительно характеристик поддельных банкнот и техник их разгадывания.
Финал:
Диффузия контрафактных 5000 рублей – это серьезная потенциальная опасность для финансовой устойчивости и секретности граждан. Гарантирование кредитоспособности к государственной валюте требует коллективных усилий со со стороны государственных органов, банков и каждого гражданина. Важно быть осторожным и знающим, чтобы избежать распространение недостоверных денег и гарантировать финансовые интересы общества.
https://aflomaxbuy.com/video/e2c6242c752f9206984f4585d20458f7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9e23593ecb0dada1b68e8c22eb1d3ff8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef0fe548bd90eef1265ffeb5fd1ae567 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b0c0476b274058c4ebf85a6c4e8787e7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/aa8862efe1990880784aee7939655163 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/392a518efa717982aaf83c58f5fa1ed2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/aa463caf0492d13b0c8b8a3999fd9fb5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef107c0f4c6e82b4cc03b8d0c76e1fd6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/77dd6ecf1c22a78391684311a3df3c8d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/3cf2d69d565f725ca2a6237ee99e5e52 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/962cb4069b69ed75c5680840b192066d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6d0a0ecc976f650bfd01af75505772ad รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/77df9730f5345cbed40aa80d42a51a2b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/26e1ae5ffbbabe11d966e5d7f4fbcd85 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f5c851bf9491f523ca90d686d8353eb7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a43ae30f2ba4fb844fa9827d3e402fc5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0483f49a43079636cc8673e814d25286 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0479444abd0d3a9873850e2c834b3c0a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3fd76c9e3b7b3a45c819e473f57612fa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7e41748426f87421b39b6f926e068b1f รายละเอียดเพิ่มติม hosttropical
Покупка контрафактных денег представляет собой недозволенным либо потенциально опасным актом, что в состоянии закончиться тяжелым правовым воздействиям или ущербу личной денежной устойчивости. Вот несколько других примет, по какой причине приобретение лживых денег представляет собой опасительной или неуместной:
Нарушение законов:
Закупка иначе использование фальшивых денег приравниваются к правонарушением, подрывающим правила общества. Вас в состоянии поддать уголовной ответственности, что потенциально закончиться аресту, финансовым санкциям иначе постановлению под стражу.
Ущерб доверию:
Контрафактные банкноты подрывают уверенность по отношению к финансовой системе. Их поступление в оборот формирует риск для благоприятных личностей и организаций, которые в состоянии завязать неожиданными потерями.
Экономический ущерб:
Разнос лживых банкнот оказывает воздействие на хозяйство, провоцируя денежное расширение что ухудшает всеобщую финансовую стабильность. Это в состоянии привести к потере доверия к валютной единице.
Риск обмана:
Люди, какие, занимается созданием лживых банкнот, не обязаны сохранять какие-либо уровни качества. Фальшивые деньги могут стать легко распознаны, что в итоге повлечь за собой расходам для тех, кто собирается применять их.
Юридические последствия:
В случае захвата за использование поддельных денег, вас в состоянии взыскать штраф, и вы столкнетесь с юридическими трудностями. Это может оказать воздействие на вашем будущем, в том числе трудности с трудоустройством и кредитной историей.
Благосостояние общества и личное благополучие зависят от правдивости и уважении в финансовой сфере. Покупка фальшивых банкнот нарушает эти принципы и может представлять серьезные последствия. Рекомендуем держаться правил и заниматься только законными финансовыми транзакциями.
https://aflomaxbuy.com/video/6b7d1a8f1479fe8ae91dc88b3e8b7c68 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd69b3d88465f0c222ca7657f1460bcf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/8316584361d28ceb2f6edcda3f25ee59 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2ceb6f9223f10ff7f0916f43c124a816 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aa03adde95f69d3a0a97826d99c07e05 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0a73477b778f34826bcdde367a6caed1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/45f3960a8b6e3a5312b351eee991fa12 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/85083dabc279e4ac7d92ad2a59bbd942 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f5c5616155a99802ce4a98bae298a487 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c3756286af8f7b907f33d5010836393e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/850aa019d5890c04e12f0362082dde42 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c69b364277921733742f284699d8cd9c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/96108acbe298ad34ef0d39e17c2119a8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/10b77fe3b89931d2e8dbeeffb6967f06 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c379514597e7c264d0e003b68304d290 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/32e21edb6c820f5dde8ea332f251ff4b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0e47b65e1c187f3486b200ef1dbb67ee รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0e45e5bf848b7c4e5273f4c33644f30e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/10d6aca6add9dbd6a4e93be6c2e00f57 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4cc4ab82dc813e22fa4e21eb5244e32a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c9c5f6a283f597b49a3a6f5eefc56ef5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8b264f02365ff414a2b53622cc40dc86 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/77d9238dc781fd7f092e46c8668fbe74 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dd795c234b76e75dd5cb29493e7efd4c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/27a4febf0ce4e7b9603b928e9d5329d5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c9cb7aefa088ba98d647944b72d9f572 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/392967755a626329ffae438a366351a0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/15107f3a0697c28474f28a3b0090a2b5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/32ecf94da35b9bb77804d651f4f6b71e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/aab0a2f4b39116fbb77ee0992aea3404 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/52bb1b99a683c60ff6fdeef5ec333f93 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd76e9b9c5a7724a8f8e0008815ba313 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d00774f71a62f9c9664024a259c0aa36 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f5d38ee258f1d7fa0f00952ed372e118 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/04880a156aa0ec8844c3e5b6c45e023b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/11010cf10dd2bf09de855e64fca1645f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7e49205337dce3263339b11d5bd16b2e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/440271820b6a963fdc2c0069aaf412e8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ddb4c77dacfa5ffa450ed051a052e70d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7fac00953541d411982200c1e80736fa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d0164aaaa1cef5f83da94ebc8d58dcf8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1b52faaea6b94ae4504a6374b3af3216 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/27b30aeaf9ec73a8ba252f7cf53199d4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0e4d7789e412212d1b21fbe2998c965b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8b28f9395b3ff07da95d74b6856d4a02 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/680f91ab7e9a580f5361bcfc431dd54f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/43cd46b70bb32cb2dfd335ca082a5e78 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/151bb9139eef2485cb39a347fb678713 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/91a3bee5b1ff920c6822badb190227f3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/57e46b9035e5dd304fe303a59e4752e5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2702bd6ec4038564c2f70f4e02a43ce7 รายละเอียดเพิ่มติม hosttropical
Pills information sheet. What side effects can this medication cause?
flagyl
Actual news about medicines. Get information here.
https://aflomaxbuy.com/video/e2d08c4717b7d3c1436faf41e12713b0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/969ec4ff72d6a00ad2d2e3cffb94f161 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6e18e903c7fd307f8e78b640fb86ef4c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7fbebb6b3e8ed7f95ba0c02265ba6dfd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aa1b4b6af6ade8000214c4a0a0e7f090 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/aabdde90583a881d166669646e5d61fe รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/837954ec1972f0aaa07b237e696626ce รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/32f505eeaa67ac2290e027ed5f4ba984 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e2cf15fcc5c34b68f6117b541b7ea0f1 รายละเอียดเพิ่มติม hosttropical
Приветствую, коллеги! Сегодня желаю поделиться своими впечатлениями о get x. Это место, где удовольствие сочетаются в едином месте. Здесь я обнаружил громадный выбор игр. Начиная от классических автоматов и завершая реальными поединками с реальными крупье. Премии и специальные предложения приятным образом удивили, а качество сервиса на наилучшем уровне. Вчера удалось выиграть большой выигрыш, и я уже не могу дождаться возвращения снова сюда. Порекомендовал бы всем попробовать свою личную везение в гет х!
https://aflomaxbuy.com/video/26fd6e1091879779642c5ea57f14a8d6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d0f00f51afd28e9e140665bb52190b4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b71e0e818571a24cb80fa14156530252 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/83f09554a85cfcbe35f8251f872c8445 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aa1125fada61866c726722993b3bf25b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/048b054758d6d6d9802a9fda7836b851 รายละเอียดเพิ่มติม hosttropical
In today’s digital age, the security of our online accounts, particularly on popular platforms like Instagram, is of utmost importance. However, encountering a hacked Instagram account can be a distressing experience, highlighting the need for robust security measures to safeguard against such threats. When faced with the aftermath of a hacking incident, implementing effective security tips is essential to prevent further breaches and protect your digital identity.
At Antiban Pro, we recognize the severity of the issue and offer comprehensive guidance to help users secure their hacked Instagram accounts effectively. Our platform provides valuable insights and practical tips to empower users to take proactive measures and fortify their account security.
First and foremost, it’s essential to acknowledge the urgency of securing a hacked Instagram account and act swiftly to mitigate any potential damage. From changing passwords to enabling two-factor authentication, implementing these security measures is crucial to prevent unauthorized access and safeguard your personal information.
By leveraging Antiban Pro’s expertise, users can access invaluable resources and guidance on best practices for securing hacked Instagram accounts. Our platform offers step-by-step instructions and actionable advice to help users navigate through the recovery process and reinforce their account security effectively.
Furthermore, Antiban Pro emphasizes the importance of ongoing vigilance and proactive monitoring to detect and respond to any suspicious activity promptly. Regularly reviewing account activity, monitoring login attempts, and staying informed about emerging threats are essential practices to maintain account security in the long term.
Don’t let a hacked Instagram account compromise your online presence and personal information. With Antiban Pro’s guidance, you can implement effective security measures to protect your account and prevent future incidents. Empower yourself to take control of your digital identity and fortify your Instagram account against cyber threats with Antiban Pro today.
Antiban.pro – help with instagram account restrictions
https://aflomaxbuy.com/video/3fe280c81197246eeab68e393ca3242e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d0fc1f4641a552b600b1d4663390e6d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4609c8abc97b91dbdca3f4d6889f268e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c39f7ee4818bd3ab74f93f383a40ab97 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/32f8f774f8b9c47edb53b86440684894 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/57fb0b279fdc97e2531c2262de7c3010 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4cd0cfe1580a7a9040aeaa750094d7b1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f817997492e0fec4582b751ebe6adfc5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/78051480af14ee95e92a06388a964778 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/281822f64a7149c55070750ff6d2c3d1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6e78351c2a40756851cd06c5a493e7bc รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f82cdc25fe71811373bd448784501d2a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/049dbd6b4322aac3cd098f4ed931049c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3fe3428c9994bfba5bca75aa267848a9 รายละเอียดเพิ่มติม hosttropical
оснащение переговорных https://oborudovanie-peregovornyh-komnat11.ru .
https://aflomaxbuy.com/video/bd85dff8f6fa7079c251e99035f67f0a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b7271fe4031d2c1c8f2386632e72c78d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4ce571f79d6d5cc6c29a903e9641a3d7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c9ebd0cce909f9d969bc3766c9b15679 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6f42a7008cd2dcaa787e61e2188f9266 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fc1d25245435d7d5f0047b53af413d52 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/460a4ca1df14fcd0cbc79ae3cc07f420 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8525ae3b8e5e18cebcd3d6d341a4cd7b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/441b5d81e72b57543807054883f46332 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c3a1499897d9e5dcb83f8d9d27c25ec1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd879078c5fafcc614720166a032d994 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/52e7d25abe66fae0002a7d13f94a826f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/91bdf05e9e2177817ef3a9efb18e0e1f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/840519540a41583795d29661cf5dcb58 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d028b7b76101f60f2f613d8c94eb4120 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/111ad2602d7892dbb55cfb82a6158cc3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/68a39bb896b08bc21a3aa1ee9c10676a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/586e8c863b04b3e8cca1ab93b565e947 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/58055ddbf864931942e42bddc4c40127 รายละเอียดเพิ่มติม hosttropical
ordering drugs from canada: canadian pharmacy – canada pharmacy 24h canadianpharm.store
https://aflomaxbuy.com/video/852613eec837b99ebf22d627f6e5fd13 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c3a5747401cc9b5256b243e5acf3ffd0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/151e5297e080c4f89726593ae76a77c4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5921a8be3a5d811a44623c560034a94f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0e6cfa5d3dc83f7af2f4eb41b22b7719 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9767bec5e312055eb093c0aec24bcc50 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/976d7d40c424cf392be1b30a592d0e50 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/91b9ab4a982de97e36bab65d2860eaca รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7ffc2d7eec38bd0755761482b05ba890 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4ce12edd00c1195c1ba3d33036bf1dc3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d01a6a6aec472e14f2bfa6e14ef40abb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8b398758f98861de56d01a5d5e2500bc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1b5d2749fdac3ecfc0e343bdf484447f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1b535375a7b1483767bfc50d8bc9b6ba รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/59124e03c0d8695df87228bbcf0fedee รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c9e8802ad9e61ed6c94f523b599ab055 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5fa5e2bb67968ea28a7ffe3a6743f7b7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ab17a2812e68b3749530c588a809655d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/96b5f391bcd1beee0795bafc2b17aeee รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9e55b036cd9d2506983c1d350a6033ab รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/83f4dc7eabf111f859907023dc5d82f5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2868120a05872f7473ec10b903629544 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/21116c83005e81d2f17a7e9c5cabe651 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/20ff14049bb7fe997fb5a782e7fea7c2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5f974d95d19925b1c562a22886a56206 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1b5c077d0dc25fe73e3c197fe1968fad รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7fe42d9112e68c1faae565a9dc8f065f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f83c7c31de14c48f9ced721410eaf670 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/655720ba3364ef271086972e5ca1ef52 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/aca0417adafc0984a0ecf132987553c3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/591ad0effc57c0ab12e8269e1209b73c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a46f16a49d0e68caf9b4f92690ead6c1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/687f0d33b7d089e363c396aabebf821d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/97686169d8d77a5b2e17d835f255dbc3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/272317896ac238a5580d7db96bac5384 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2108d4b23fb49c0447aabe163af4580b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/04b4bbdd641ab423e3e3c9aeb5490d9e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9e66b770ecab173cfcf9205c51ecfed1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d6e062fabd1217c78aa771b430dcb094 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5fa51c2153c7becde09f62750ca080dc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aa41ea67d9ff3c0ddfb7649308f7e57c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/7ff7575aba7c32de407cbae5cc2a7dad รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e8ff2ddc02b804fbde3983d9407518a3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d1934b6752a0ea9df28f29e25fb8a13 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/27251e90cd32ccaddf074a0ca8c023af รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/96f563683c34f135d32961320ac55ce6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0aa14449449a04fe4da69f349d06dedf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e2e3080ef93b26fd192c7fe709c3b6c5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f83723d375456237ada4fa97e2317f94 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dc98e8eb10ed0fbdb20a3fca342fdf53 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/65555d2bfb7c64f3a84744b787ba9df8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/71b35dcd6e21c0f02f87e86744c8535c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a46efe2af2c9c02df3df166bc0540c78 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b0ebebcee0253107f308d3a522160f77 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/96a39d4ca3b71a00df62310118163a6d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef3d410434acecd6f9cc2caa7bc78a0e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/acb43cfd405a4dad0c81d493b5738b69 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d219ff474e42f487c5b90a789bd22d6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0e74a63bac50dc0fd99f4932eaf500a4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e90179cc69e6fe2024b94d1a48ecf701 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aa4309d05b1f054d3ee4101fe3d8d679 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/04ad9334afa3ba615cda98cb6ca01089 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6b9bf032273dff07d91430ad449c56f6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e2de9661e5f9ba15c61a228a0930d050 รายละเอียดเพิ่มติม hosttropical
Приветики!
Вы когда-нибудь сталкивались с необходимостью написания дипломной работы в сжатые сроки? Это действительно очень ответственное и трудоемкое занятие, но важно не опускать руки и продолжать двигаться вперед, активно занимаясь учебным процессом, как и я.
Для тех, кто умеет находить и анализировать информацию в сети, это действительно помогает в процессе согласования и написания дипломной работы. Больше не нужно тратить время на посещение библиотек или организацию встреч с научным руководителем. Именно здесь, на этом ресурсе, можно найти надежные данные для заказа и написания дипломных и курсовых работ с гарантией качества и доставкой по всей России. Можете ознакомиться с предложениями на купить диплом ссср , это проверенный источник!
купить аттестат
купить диплом бакалавра
Желаю любому отличных отметок!
https://aflomaxbuy.com/video/78200aa9ae53653753c2c8beb3669bb9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b7302e5faa9de9b881c235e8d1ab00f1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ac9ae4ac1efd32c41b36a432a5af6f13 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f5fe482866e3626cdb68fe0efdc8fea6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c78e6d596ac3574acd9a3dabec51ad57 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/32fae00163f248c8a0b0e3112d20036e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/330e0ab4cd80e17a4dcb8444ebaf187b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/394dd75ccc927d0623589e2cb8dffeeb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0aa0f3158bc5fa8dee294be66347c1d8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b0f2d950b2cb625d632e2225970dba27 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/442c42106670bac4fbbeb9395b91812c รายละเอียดเพิ่มติม hosttropical
Привет всем!
Бывало ли у вас такое, что приходилось писать дипломную работу в очень ограниченные сроки? Это действительно требует большой ответственности и тяжелого труда, но важно не сдаваться и продолжать активно заниматься учебными процессами, так же, как и я.
Для тех, кто умеет эффективно использовать интернет для поиска и анализа информации, это действительно облегчает процесс согласования и написания дипломной работы. Не нужно тратить время на посещение библиотек или организацию встреч с дипломным руководителем. Здесь представлены надежные данные для заказа и написания дипломных и курсовых работ с гарантией качества и доставкой по всей России. Можете ознакомиться с предложениями по ссылке https://9prema-diploms.com, это проверенный способ!
купить диплом колледжа
купить диплом о высшем образовании
Желаю любому положительных оценок!
https://aflomaxbuy.com/video/b0e90ee6f963fc27f70d1c594677d16b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e8f9e8b72d3f2cc805d70f5293756de6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7e5b1921f5055937c1f9982273fe2223 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd8ba726bdb3374126e6d743405a8f4e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c7629da0ffe72b585209a9d3dc485941 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fc2c2a840345de91b9e4c8e05c21754a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1b5ee70d02c44fbf46f7a6a6ee8a26e5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f601070c0a604911c915f4b4cc714785 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b74c41161c65b3ec156841d9e61162b0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef61b487c0bb5d26eb3669416e1e5900 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef32304e697ea54eb7dd562a1f1b5b24 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7e5eb8c45b10b4c1d48f278995fbd2ec รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c3bd28ac4874014e425cb5f35ddf94ac รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4619f130d565c60ad487b4f1048f21cf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f6018717343eeba1aef16406c58e9aab รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/461e78c075497ab1769c6180936bfd41 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f5cd6ea13e63f348bf9af6220009de46 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7e6818ce66e2b7c9b3174a75b5aeadc0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0aa940bc9ff6765a3e6dc63c15398985 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8b44d505832cf1ec70d6a703e89b65e8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4628c6d9718c2bb8550410a9c3dfa48b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/28a8fe240420a77b1e1f3868b5fcabee รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/854bebbb39dcb55e946e5542f5b687ab รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8539bae5795c50293b9b09c35b37a3c9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/11abf2151c53584973ab877aad0ca9ce รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c3c21444f5a9db6447f21de2761902fc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/68bffca3c71d05c143d76fe140375b3f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c9fd18a9d04f34a98a3de29e3b1a213c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/28c968c8669a52673c1f7314bc6abd61 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/58d53a865c48f759bd0e5d7cef5c938b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/592505382f158e44c19f1a7e155bce0a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/27278b588371d64757b825cdcbcb493f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/52f448d3882b3fda2039d83234e6e3c6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/58bf525a89cf31a197e61ac7307458ae รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1b6e0a63af77ff440d026b4aa10c6c4b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d02a8c3a19f8120056a844b6831e014d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d030184058d63995581c4ae47682bb2b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5304f348b899ee78edc8c97dc80ae3b3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/976bbc4039c75423c2bcfdb0f1480e83 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4cf9a63a0eb388d9d066ed616120dc35 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/6f9cc18da1a3c3d9eff8d69677ee0ff3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d2484d348e3529b139c7be1a3344e23 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/977c40091b3c693c9ad007edc895cfcf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d6f0413c9be03fae8c3c1ba84345929a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d6f1fa5e2132325114892af090980f17 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/808e9d830cf4f2caf6efdae61d2553cd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/84264134e71d778a28f38409f6949122 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dca6c86d95aa62a163b464251b9b21d5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5fa8ae1d697b44be2b06f4c8df6e9792 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9e6733b87e21c01fb481b08440a096ac รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d2500007d9ddd4dc1257a183d52fdee รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/979b670f532ce58fd80ecf1f842d4c75 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ab6a4b3c6a301f021ca93a39ab785ddf รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/970cb6aa56cafec095d9a2a8011a4cc0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e9123f79cdc43a4576db3ddc80e327b5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d3397c05fa18669385b6e5717c9a78e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6ba565b39dcf0cdcf03d1b88ac2f2e35 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d6f85e0d32e00e34d579b86e4ee31d7a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/abc99ca4e84ab4f4da31522f2a599b29 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c7a545554503be91cac390a97c33e9ae รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/844c2da8dbdd666fed7de9bdb6627114 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9e7d59c30445e1191a890d360c466c34 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c7ad82fd9423fe2217e97f5ecac2f4f7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dcc1c9c1da99700c2fc62710ddf8a0e8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/71d4653d7eced39e816a158e75d2ee09 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef67de947f5f3cf2578bb674d1dc0843 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/71d8ae313b9040a5cfaceda46f1df9f2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f85336dd3550783e36a47f9f3704e2ae รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b102d8a72f8c1fea4411d96ce1599b2e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/973ad71634d39fcd6c8449d6e8f2be0c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/df18e29c313ea51a5279ebc38fc741c8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/04e03814fe8a9c53523df81d8d530bfb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/97ccf109deb7307f68d8ada553026f17 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d454e9e01c96a86204488b6f8aedbdc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a483ce5cab00e55ced736c69f8aceef2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e2fe8d6f2e2fdcca3e7c98b215453e7d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/782f4ef3fd42689791e75747d7fd2a59 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/04e6987408fb4f706b86e7eb5f6c6716 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f602a8bf3221045b64796842545a9c99 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b75f5b1e4679fce8cd34adb55aac190f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b75d0a2e3406c82d5856b2819751fa95 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3ff8964d5e94b7843f78988c0dcde02f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f5df58dfc323242bc741167141569ee7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ac2aaca7e681a1fc82003b1a3d18403 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/abe366456c52f027ce84878c71175c6e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/332aa629e540a95f1d3224236dfa3c36 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f5e81b364d04c709e9295d53f1be52d6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e92e3d92acbb8824c9d1a2d88f6439ef รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7e6970c0df27a20d603d675c37a4d896 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0acb8b2e2b621a764f14f24feebfe00c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd9af5a44d47741f662bbd1d89b7f5e6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a4915127d42dc7fd5382a7d00e3264fe รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e30648706dd0d3a06fd25552e08bf76b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ad08a9336079f563275618a04fa753df รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f8575856873ed4e791d89f43187a2c34 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3334b0c445a0c5490f91abf83959d82c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/39776f060f6926a9eb665d49f92299ab รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b10d7bf14a828257d0ad88e0ce85e633 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef6bdb006493f17a4e6e319267e84917 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8551313bd045808126f96813f6095f43 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ea7dd9e30cfb40c017443a7fc5d09e9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c3c49a294bda9f9d93ebfa70aceaff62 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4cfbe035e3d2a8b67cfd850ee3d81e20 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aa65e738d2373887f108d4354ecae089 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e93de989bfba40c959cd373d3de7b846 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c7bd68f2aefbb2e73ba1ef65ff72b422 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/04e95196fae73af65b6505b49a98f99e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/783ecb4ba57f963f096b33f5bc0af10f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/44e822b166e3ec89303c3c75374453a3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b7645e528fb85cabaa7f2350544d8dbd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f61091808d35212495f654f4abc098af รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/71f3055772a1cecfa894b543b7647fbe รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/154298a0ff4c5fb116bec670a7750de6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b115bc09955d72aa4f37df373468ac29 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5311c861b723a05a28f2b551ba78eaf7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/71eecd09c966f244b8a7524151151847 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b1135f164d1f513cfe1d1efaa92d4492 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef6e3baaf202041b25df7c1b4ea29af4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ad2bcb9a0f375a4927f147bea978ec0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7e79c891fe39e0ec626b327260dc8d2b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef7e76bcda63d6c391d7ea96ec33f6e3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/04ea144446f4cc91ae393bc4dbd9fe97 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/46450f6e15d62305bd475945dfe58dc4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd9b8975e7d62e69ba1095dea86ca1d3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fc34da27a2e7e09ccdce82249d96f7b1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/784c73b31397c1654910312f492194f5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/04ebe67ca1b6d3ad6068504b9d72b256 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b76c7b0e8d626ce617f68ea256cd2064 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/400730ec4d3fbe445e7ed81dafcf08a1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7847c5c7461beade5a5a853a5196c5b3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f618c6975997f1285163d5f604bfa128 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8561821355da642e4bdc265e9edb813b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f609f41f6776c0986539aefc14cdc0d6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4cfe4ad8d4e8522e2e6676f526b62135 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c3c5dec2a32c0d993f6ecfc09b9149c8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4655085e926408e0bfce950a275caa2f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7e7e7338e00646bb985a98f1e51db2d6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/122e892557f9354ec116439add317c60 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd9c24c35b37e6e65c168761ac3cad12 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/450d7736f4c6c52aa7cdc258ca83018f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/46560d5318f030d1971fd6a4868b2a27 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7e7a63f20109994dd8bc00ac85270c84 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fc35de39bc58b0a0a91ecd1a93892a80 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bd9bd2f1ed403ce95c1ee79e58c040c3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8b5a7c20cd1f96b504e2f73ae4a8917a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3088c7a11f24988f1736fb96cb831cf9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0eb711e7a66ace1b257fc71765e2f022 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c9fe7f1cae88f82284ec3a71dbeef439 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4d05608364a9505a1098993a522b84b7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/28f9a159681b8871666f8fedaed622fc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c3d1011a8ec3089701778e72387d661b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/59532f1670305b763284abd45a63b985 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/856b8203a6b471d0838a5fd18bd098eb รายละเอียดเพิ่มติม hosttropical
care eshop finasteride buy online
https://porn2p.com/video/126b6ea3e6071e010033aa106e94253d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1248a5e180b9089b98e12219f43b767e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c3cdef0aadffc496b32b54390f708e62 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/45234bbbca312df7b71c63451ffd26fc รายละเอียดเพิ่มติม hosttropical
https://cleaning24moscow.ru/
https://aflomaxbuy.com/video/d03f05f64594bcb67ac8d7a9c17193fb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/595a9929280fd7142cc98ac1d248d7aa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5312848c86b1387a17931bf021ac638a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/692437afad21daa3d6af44f39b09dc03 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ca0df550891190d14f5c53edd9fa1ef6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/70b6352c1b590074cddfa49d3947a645 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/53128fa52b045541cc33cbba964d99ab รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2917791e072ad3f414b4e45a5c86d640 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2133efcc0dee9e5c2071bf5d01df6a98 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/2901fe3b6da88a25e622116df7401de6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ca0d06dd465570a74fb43584d6f46698 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5966951d124219943fbf8839afbe3e54 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5fb3cb0d6d526ea67282faaaa74ae660 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/59620ed7ab59294bcbc5a7875c07299a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fc3ad27b0cea5f87673fbf79ff1bdf9c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d05675f3587d0cbd602aacd6902cb51d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/30c8a1da8439ee468a2d509f18fdd4ac รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/597151eab4b077ce046f91c6ccef1ebc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/693ff6f7058a8769710226e0a4907009 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/91d86bee5c8491fd32bc3206adf94d6c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ec23c8066471beb584336deb0dcab15 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/70cf1e0cccc64cbce0c6d4dfb57a5fdb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c3d91c33012fab1aacfcfdc3d599ddcd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/70bf75b1023143f13a6cc388e6e9d28a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/21357d69bdccb70dbfd116565e27555a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5fb41a1369e586932a2c9c946c311730 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/97c9ada7f311af65a2e5e30c26343c65 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4530b1d00b877eca3f3c3cad83f191a2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5fc02702cf5ac56922197568e13e1550 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/81f9ade410cfe13cb3af0d39fae48b88 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/155ef84f000c09f9316ed9647fa92663 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/846b02ef55720142f46835d6a9a45eb6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/81eb3610c9b4d54cf8484a48ac70d1d9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/53143bd3798bba7947a011117a8cf637 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/27307a0e04cbf5c3cadd4014992737d7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/27360ecdb3b67f1947802e40ecd081e9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/657f3021dffdf16a3f7e58dcfece76c7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dcd4cba4002c0f530abe9f26e497ffbd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/59e67176ce2fce8e960b1e7fd5f9fa92 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/65830848be34d8b9d04f16a4c1d04484 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/97a064f3628f22800a77b05a6235b4f8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/91db873850a5cd34b857e00b7136fb59 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9e8344361b57ba051d9f49aa22d2365a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/980ab6dea60a8a336ed6889c3a0ffada รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9779f52389920dda49cefecd25efb5d9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dccf7524f9e1e1afa9dd5a02e9288be3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/97dad51c0fb4b2d0e2d6c38dc24b843b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d4939fe2f752493d4ec9c27032d2c07 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d4e90003e721fb281bc60a1a7f3529c รายละเอียดเพิ่มติม hosttropical
india pharmacy: Generic Medicine India to USA – Online medicine home delivery indianpharm.store
https://aflomaxbuy.com/video/6bb66aadfeac0970a830b955ce7a36cc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e30e9bbfe29fe0b6efb0b11451dc2dda รายละเอียดเพิ่มติม hosttropical
medicine in mexico pharmacies: Mexico pharmacy price list – buying prescription drugs in mexico mexicanpharm.shop
https://aflomaxbuy.com/video/6bbfec54a0d12d14db9d4cd5a7ce5f08 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ad5d1dfe68bc4c91b19df3c4cc76a2e0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/97d0b17a5e07b482050aba34b43a1378 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ac03ff57d01a0bc9c7e80a1d6bdd9ff3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8b84ea0113199347ecccb9c49b8b4362 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5fca691e84bfdffbc4a7f94229f3c8eb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/294edd4a0fffe3a57756fb657a17dab1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/59f0f122d02aca10aed74e4aa076c112 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3336a580b6ab879c2fe7890509d49712 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e93e75847bdc8bfc2037bcd6c76ab0ea รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/59737053d32ac95545c3cb9484a30cce รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c8037d00f43ccabb9f47f8d5631f94fd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9e8b0e9dce3a4cc41804a4fc783fffe2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f88d58fe26ad7ed76079ab4dd7b0420d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/91e13226b6e9c5979ba48a292702a435 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6592997746685fad6c3957558826f87f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d05c92e860b6203ede90038ac0b42de7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/69a130a9f494cf4d1dcd9ca73de2c669 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/70ff93bac3d89e79b7eaa457d4fb1606 รายละเอียดเพิ่มติม hosttropical
корея авто купить https://avtodom63.ru/
https://aflomaxbuy.com/video/d6ffd0c6cd1857d3a66c2270c126101a รายละเอียดเพิ่มติม hosttropical
reputable indian online pharmacy: Pharmacies in India that ship to USA – mail order pharmacy india indianpharm.store
https://porn2p.com/video/8232d3d80b60001ea975405a97c99236 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/84de7f3da19bb22b96de77dc060a49f7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d52ddc63f9a9503a5ad3e4ba4a1f82f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e30f66e62e97186f989d12b20fbc1cb6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/97d5ad3519f46678769560ceac98e994 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/27420d11120b8fd0af43ab55aedf2513 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9e922274e1e7dfed010865292dac063e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/84c5833c175e9b3fba6cab768604428d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dce547465e89735f9ebe8eb4e0fc0eb0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/65a140c663fbf877aac90ec3c23d5236 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/659ca6f829512cc1b2d5988e25c95f8a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/97bcf71daa070efd9773800e1ba682e9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aa7626d0d06176dd3a0b00f69b2b3ed9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e955bc1036f7b24f14d15d49f7eacda0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d5dc0bf13ff2fd1c50c28f98a034193 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/72028d56aa9d473c8cf8b3fb0658897f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a4afb00b68e93017292b598b239c24ef รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dce4fb4b13dfb676f6b381b68c0ca03c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9854d849331259f1136262374f4cd8d3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f90b5c694d32fee98c47b4cf8eb82438 รายละเอียดเพิ่มติม hosttropical
Покупка поддельных банкнот является неправомерным и потенциально опасным актом, что в состоянии привести к тяжелым юридическим воздействиям иначе повреждению личной финансовой устойчивости. Вот некоторые последствий, почему покупка поддельных банкнот приравнивается к опасной или неприемлемой:
Нарушение законов:
Приобретение и воспользование контрафактных денег представляют собой нарушением закона, нарушающим законы страны. Вас могут подвергнуть юридическим последствиям, что потенциально послать в аресту, взысканиям или приводу в тюрьму.
Ущерб доверию:
Контрафактные деньги ослабляют доверие к денежной системе. Их использование порождает опасность для надежных личностей и предприятий, которые могут претерпеть неожиданными расходами.
Экономический ущерб:
Разведение лживых денег влияет на экономику, вызывая денежное расширение и ухудшающая общественную финансовую стабильность. Это имеет возможность привести к потере доверия к денежной системе.
Риск обмана:
Личности, те, занимается изготовлением лживых денег, не обязаны поддерживать какие угодно нормы качества. Лживые деньги могут стать легко распознаны, что, в итоге приведет к убыткам для тех, кто попытается их использовать.
Юридические последствия:
При случае задержания при воспользовании контрафактных банкнот, вас в состоянии оштрафовать, и вы столкнетесь с юридическими трудностями. Это может отразиться на вашем будущем, в том числе трудности с получением работы и кредитной историей.
Благосостояние общества и личное благополучие зависят от правдивости и доверии в финансовой сфере. Приобретение лживых денег идет вразрез с этими принципами и может представлять серьезные последствия. Рекомендуем соблюдать норм и заниматься только правомерными финансовыми транзакциями.
https://porn2p.com/video/ad838c76bd4ebe8e8cc500deb8193db9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ac4bf89b9e7b3cbef3405a030699141d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/39a00194d9fb253bcccb13a86ed00292 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef8065858b3ee16f6229e9caa3e0c401 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3341a75003c272a1e3ab339db17676c4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/785c6fce38b62b0bf2629d96f55472fc รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/df80d7e6ec3d37ff276da940af4eeab5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a4ac30a90aad7e81973dfbbe006563ec รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/722321654fb87482737b60d0c72dfcd9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ac22c4ead3fcd099359045dce5957475 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f94678fef9a5a867e0fa98f899437f7c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b76daeaa4b9ad2d3ec92ea7fd4647d66 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f64999e4f189f94a938798c8db1eea05 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/39a90260b68cfce46a7634877de7e124 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7e8eec4bd590a70f01d1a805aff4c1c7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f65328b6c923e370f6027824c7241b84 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aa7b733cfd10df6e31b9528c16fa8622 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0adb0d16174f64fd3209e79b9bf39ccb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e956901382827b367abf1d2a72f5f143 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f90de1b42fdf6d8fef07573bc48528e1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/04f9b92ded2a6502bf62ff2c4ad8b32b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4663cc316bf631d5a7fef84dd4f17c25 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ade65b8875b96b4eef5dc5629ca8bb26 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7e9c5ab69cd60ffc11059188ec9bdcb7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/40114f42940a4c3864f55599026397df รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/467135cd3e36f8a7f4a224434f4afa22 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7e9c3a777ac5192d640856fb3f7d4be0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/722dd58c0051c02b804b891571feac2d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fc40330f349ba8b6f5b92644b8abbb6e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/858f8f8129f4ba2e79000939f6f0a283 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f966b0ef1c69fdceaf3998d9b410fd12 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3122c98b3c2ddb201f82a6c458aa3247 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b776a6d5371e86877d2a0222c621dddb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ec693c2a463e78ca4d2361128f6a7d0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f64cbc24541e12f0dc38c7505d83533f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/39ae734edfa25f0beb8b08796b41aad8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/46668ba204ebb403d928e1f8c0b95f3d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef8a828fab6dfd8798b60bb6dad0fc8e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4d0f8e4d27e9b19a5a078cfeec1ff0b8 รายละเอียดเพิ่มติม hosttropical
Feeling overwhelmed by the constant buzz of social media? It might be time to take a break and deactivate your Instagram account. Antiban Pro offers a safe and convenient solution to temporarily deactivate your account, giving you the breathing room you need.
Our platform streamlines the deactivation process, ensuring that your account is temporarily suspended without any complications. Whether you need a short break or want to step back from the digital world for a while, Antiban Pro has got you covered.
Why choose Antiban Pro? We prioritize user experience and security, ensuring that your personal information remains protected throughout the deactivation period. Your privacy is our top priority, and we take every precaution to safeguard your data.
Take control of your digital well-being and reclaim your time with Antiban Pro. Temporarily deactivate your Instagram account and enjoy a much-needed respite from the endless scroll. When you’re ready to return, simply reactivate your account hassle-free.
Don’t let social media overwhelm you. Trust Antiban Pro to help you take a step back and prioritize your mental health. Deactivate your Instagram account today and embrace the peace of mind you deserve!
Antiban.pro – facebook unblocked
https://aflomaxbuy.com/video/858a98c9b91b8dc765b3c18c429ee042 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/12970e2e9d5726e7c8a54a5993a3f452 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8b89b2d982215a0dbf38346c13b84692 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/05048939c166f55d739c613371bc63c1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4566954637f88d2e26237868909e986d รายละเอียดเพิ่มติม hosttropical
купил фальшивые рубли
Покупка фальшивых купюр приравнивается к незаконным и опасным актом, что может послать в глубоким юридическими последствиям или ущербу вашей финансовой надежности. Вот некоторые последствий, почему покупка фальшивых банкнот приравнивается к рискованной или неуместной:
Нарушение законов:
Покупка иначе использование контрафактных банкнот представляют собой противоправным деянием, нарушающим положения общества. Вас имеют возможность подвергнуть юридическим последствиям, что может послать в задержанию, денежным наказаниям либо лишению свободы.
Ущерб доверию:
Контрафактные деньги подрывают доверие в финансовой структуре. Их использование порождает опасность для честных личностей и предприятий, которые в состоянии столкнуться с неожиданными расходами.
Экономический ущерб:
Разведение контрафактных денег причиняет воздействие на экономику, инициируя инфляцию что ухудшает глобальную денежную равновесие. Это может привести к потере доверия в валютной единице.
Риск обмана:
Люди, те, занимается изготовлением поддельных купюр, не обязаны поддерживать какие-либо стандарты характеристики. Фальшивые банкноты могут быть легко выявлены, что в итоге закончится ущербу для тех, кто собирается их использовать.
Юридические последствия:
В ситуации попадания под арест при использовании лживых купюр, вас в состоянии оштрафовать, и вы столкнетесь с юридическими трудностями. Это может сказаться на вашем будущем, включая возможные проблемы с получением работы и кредитной историей.
Благосостояние общества и личное благополучие зависят от честности и доверии в финансовой деятельности. Закупка контрафактных купюр не соответствует этим принципам и может обладать серьезные последствия. Предлагается придерживаться законов и осуществлять только законными финансовыми операциями.
https://aflomaxbuy.com/video/bda07f0420e2c98a087e5efd2318f062 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fc3f06fb80433b722b02d16a9a39d863 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/401597d5fd8f69f37e362a286324ea1f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4d0f3faf156c72b58ea613de6627bc43 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ec39b27b86b634e9ceb9dc315ae37ca รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/531a6b9aef098c90c195a5ce54f6dd38 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ca2062e104ba32eded26784ffb6efb7e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f6a0b43ccb0b25d429343408c0e71755 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/91fa8ca0dc5cbffef1dbb712330e3767 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ae470bf4bfdea85c6f767cbab279a65 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/59f2500a602f1e61ab896d93ad3c4e9a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1b99b7875ffd7031c5f4b265004689b5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c3dfec250e5950639be9ae9ec343b2fe รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bda5823a4e75470f100a6a6fb4d142b7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/45388d1d990561905abf2004a57bce92 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fc4b7cc526965c26bf88411b009f6572 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1568738fb3519bd3c275165a05dfffc6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d07114c49b96e77a2077ebde27e74fb0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/314dbec7a2ae415951eea1bf26c81c18 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/859563a9cc485067df90105def5a62bb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/97dffba6643a5da92978a3f4748f9e89 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ed1835173df81c6e2f10f9e45938510 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/710cc991d2e02ba05ca9e7fbac975df7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dfcff38020eb935b74cfed4f8d0d8af3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b13b85ccbaa8a6fe29b3f1ae5211c724 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4d1490b6f20066950e90c13b71123336 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5fcdd87d9af501eaaacffa43fa4febca รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef8dd54a3db03ed05edf0ac366827856 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0507efb901f4232d58b7f857d7eeb503 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4019e0e03444edc14070dce831922b31 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7ea67d49dfcb1aea7f60297dd3ac833f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bdd5ff035cb6c4af454705f830444250 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9e9ff872fb9275c0fd119a77d0c3e512 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fc5b1313fbe0ab3663235d8b147d3fdb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/157db4f6cc2fac3e33cba671be71812e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/31832713b8f037b69decae33d89cac04 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ed481ffbb5f29e8b68693e08b6c03e1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f6b37262511dd4ad4ad06a63a96933e9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b7855ea389da39a5e21a9f618cf922b0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/51d1ee13b3517d69456b40175976c7c6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f65c1f644d7ffe56cdc5307d9412f1fd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0aebf3166252b48adced707881fc6ea3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/46738933e05d47bb16c7c67f248b0d08 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c41121ffc97321b1890a773a6debe0f6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8baff51021d01c14968b799504634f84 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/13066919f4cc34136b382165a60c3b77 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1b9df38568de6a03d47d17319857f890 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/158143396d7aa99254f27a52d75833bd รายละเอียดเพิ่มติม hosttropical
клининговая компания уборка помещений
https://aflomaxbuy.com/video/d08b97eb16747ae4ec3598bd70ae4fb8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/597dd15e67a8f732c5649caa6e0adcc7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bda77de6d48f3590a499ca06ddd710fb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fc55d55e33f44a76c89b558c3e56ea40 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8ba4a360763b37984f6fb7476ff414f3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ed2cf691ed4c614ebc8ee520106deb1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4d16ad241106df806ea102316539d866 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/712ca06190fc6986b0bccdbfb19cb7bb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5235f59cec8e1f77a288afb12f8950b5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5a4fe9ae864a99876338b6ccd4120975 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1ba1ad99178bd4edbd1716a2f31b9175 รายละเอียดเพิ่มติม hosttropical
usual dosage for doxycycline
https://aflomaxbuy.com/video/59812e5feb2a33cbd3b9d72fa9f00bd3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/45a1f78d7f80a309f623e770df6ea6e7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c40a10bf2c91c9d3b1c4780e56c0c7cd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9200f0055be013cac810ebd425a12fcd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/157f760e7604cd9f8847ad2f6ea331e0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9ea2d9d36290c8109aa99bc2ae836326 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5328d480bcb8532396f2335cf948bf70 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/27468f36958c0acdd6fb637fad05e02d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7177e39a1c14fc601f611faecd8fb156 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/215c570918c6cd00d1fe8a97aaabcb40 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5fdff845fead0992bd160674d02a3ee7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/97c2c22d2ff6d173ba80c204d2bd9fbd รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5a2472f9f5a9100a443a9653a7f05ca6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/51f36239402507982f984c0c18f1e2a4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d70ec4eed98093b708ef28dacf3edf83 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a4d14d3c01fcacd6fc2409d34a6e19fc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/597fe53548c04579e52c83be69455a58 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d5f1b9e993ace388e4e0c9e805c6c57 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/852ebafaaf1bdfdb5bb6a35c7aad99d8 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8258adf1a7f09ea674659d3060051848 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/65b97ff2126098553334da09b2d47851 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ca38001b1215c06ad17e2c8fe39eb583 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/523dbecdd4d69db3416cdabb59a56b72 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6bcb5c29288df18f95a82dadae48ac6a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/716603b945eb0dfaa1f6a1f602ce9a91 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a4d46409369e24d3f754d07f53f6902b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5ac158990bf35010c79e4451763d1bc2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6a326f00f37d44b8aaf1ba4f681999ec รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2158e9de7d9e692d64dbab250ba1e59f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5fdf71c9ce537e8f8a7ab5c6c12e5545 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/98efe5267b10f7df844bb53e3286c4f6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1ba70bb648f60cb54fbf963f03a3351a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/97ea3e58f69f51529aebab6533f9c5f1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6bdb10d719ffcafc22c447cf5f27236e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d09633305b50c8d03d9c497245088f93 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6a7ee3a19906fe6abf421d149574c843 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5987a62e41dbc0d733bddcb837d0717b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aaa7c91c19e0001a0a6a2119465b22c9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/7182b194535ae947d299364ab43c408f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/82523f3b7fb9e57ec8a730db5214d00f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/274a5dd9a2a6ccbd46d3bdc4679fe089 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/65b59bc598e4bf526123c77ecd897e73 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/216ce4a34aa3011b5ff4664d0edf8c01 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/33552bc0fc74ea1e06d04006665cdffa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/723339e3c3f8045b651f3c50c233f497 รายละเอียดเพิ่มติม hosttropical
авто сайт корее https://avtodom63.ru/
https://aflomaxbuy.com/video/d7134fc89c4a34f4ba1508ac18da1d0f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8275dace746e2ef8588b5ae9b79e7b05 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b142fa557545c3fdd8fe15c17dd209b1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aa9371c984ccd59090751b7988ee28cd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9eb0ad25183e34259fdd53d8c14acc4d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/98e385eb7d3c0446b781875f5cdab4c1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dcea21498db327b7095c8430f1c7a921 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/97e48456e2467bbe072bbb213c2f4189 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d6beee1ca12fe330a424a8bbe4dd356 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/275716004837cb6e461df3d740406bdd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6bd6caebef3b073ffe2e4f0203619306 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7876068be42d6cd4d02dc6a8ced76097 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c8a98321613d32359486beb7eb9505e7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dcf35e6c9ee0da4a9aac84a8a10469f3 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9805ebabee43d98d72215d6f6098c7b9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b78b0c5adb8071cacac8215f81483a23 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a4d619995dbce43d882736d8444a431e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef8fdd6d7e67540267caadb6cdb3615d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/ac59d0b55a0a744edc5df16cf9603b0a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e31bf90a7b4d35bed60c88f6f0adcaea รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/050f179cc41ea6c4f7ec72c2537ac59e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d8c63fd3ded6b99d345508bdb64bf4e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/334e594a597c710f06e7c52145e8c74d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7eac85d16ad4915aeda2e0083bf76127 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e32d7c38d2718f3f2476bb3cfa17da56 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6be12369017748361b3d8a7802d66233 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0af1aa05f4eaabf9e020e7335a9af742 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f99bedc5f39bf39b8701c67cccc115ba รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/33586c180c6dec7f8b13c66e62eaa5e9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8597243c95d7dc8d7605715325a8ab5c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c884baff0cf54db5e17fff2b204dab15 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/39b341e4422899c2815f0742f8caed5e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/78691c5a41b5dc1296cbffb1c2a72adf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e98f476e6313c4647efcd2c92c40f1fe รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c8ad630de50c4143ecd579efb573977d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c419b49561a39f863a25534f8dfd29f1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/829db14bee049f661402ff61dd0cccab รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b14305672d891fa188f40230b6bb673d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/854844b8c0162d1f01816a206b20a112 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/39be7a7747df3b6aa5da0c9a3b92deda รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/65c53b656df6625bc7e33beffddd4702 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e337aa38179698fbbfd59a12a29881d5 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fa23396ac9c06ac31f29044e5080fbd5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/787a8a4b4507fdc6b502421186ae46d5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/39ccbe987d62b1f793548f205dc8fc6c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dcf7a40e03a29c6ae11dad855a51e904 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/787f3149013f46209a6ebf0ea2de6b4a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b7996da683b8429fc975c0cebf3a73fa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/051bdf379c139a4a5e011228188ee2ef รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/98f60c12b7008bb06048e78bdd547a69 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/402f90a04cc415f1355cc7611081cab3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d9b0e07d0a8d5a081c58f6770f54266 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7ebb7828ef1e4ef7fa742cbc3c929d30 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e99bc2b2a1878be656d246dc19d83436 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e3355a09faf2d68093294170d4e72d19 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7ebc3ca6aa2ded97f84d459d5802d3c3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/403a24dcd5a6679ee03f14530b6b67bd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bde2d178635169e2067d0302c4de6e71 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0af704d48f18e5a3eaa675afe4b6ce3d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bde921768fa573c062c45ef7bacc90cb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/acd0027bfe43885fabb4b917ae9aeb3e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4673eefdb82164798e9fa37b00c19bf2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/335ccc326eb4ce3fad895d61e832c944 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/723e882098b08a93e2192510b7f5cc33 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b14602a9033f9d3e3fd1f67e956bf258 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/859909ab5a18b1a3d9bc4ae730dc73ba รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef9d27bc49a18e2ea3086ba9e10e86a0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e01693ff111a10b481b0ce287fcc6e99 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/859b2aaf7c36f9c6e052735dadef856b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c41f2cb604c523ad191fc5dcd6872369 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/467ebbd3515185fabbde02d69b2390ac รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ed83577e99b4215a88a993f30bd5325 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c43b69ffc23e975d435c75b75fb3f024 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/f9c19fb7cd8849cfb626d46bed5796a5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4d333f0a0de039c2847453a47933697f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/39bf78e0b4c3e8837c1d10db28fad015 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/787d3b25b135e1313262d750c829bbfa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b79b81317a6804912f931823fb9e803f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8bb5f866e3e9b6922ebb89e879b6a1ed รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ef942c2545892f969e7b01067e5de87a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/133090bd5d78525215018b32dc93b28f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/dfde32fec9ba7f36267a821720cc2b3d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/45f59b9e26d75afcbe1dfa7b63592ce3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ca3b64143166b87087cdcf2f5c673bd2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4d387773db86d401eaac8a271277fdd2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/158c4ad46dcc85889683a1dcf730ec9f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0521aa1b241847845b800310a09b0cd6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ca4206b2d3637210069e9680733a2ec8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/532f74458791bac418287464fa5b5038 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4030361cccdb892f3327e58a32abb1eb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bde2effc16821343603eefb71ef88280 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f67cddfa120d8259464cca256c911c80 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f7138cd96e46b1b590d7a7fb03b24e38 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/922131e7fd4cd778c4a1d48ca08c7a81 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/15acc020be7cc6c5e3c528fb6d7b2949 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/320d5883ae3cdeb2b37b8e79d9ba2bf7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5332d7df8debbed898912561137ea1b8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0b0180ceb2fb43574ea00e0781dc6937 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4d3c0e016f9df63fb84f1e925637dc14 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/467d468628b6be82de43b5067964ec7d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/859ac4cdff14d1799e44d5e066c87626 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c43ae2e41378034bdcfb718419548e12 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8bc3f5addbf92652292ae1151c30ae01 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fc91e046bc1e4bdb9ea69b1ce6f54454 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/320ef25ee2108d25295ae315747297f9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/138d2c3a26173a08af5d182e9b3b2de1 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/465229c835c076bdeb5a71b6e7cf8363 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5990ef181a0ff07d1b4acdcc4954e991 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/15b9e7b6f1a13e0b88a2ccfbac627a40 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ed8ca2ad8834072162970e2bb66408a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/534156cba4bab68fd1cf5c1bff7bcdda รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4d383625a4dc5fe27ff052e6eb9c5a15 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8bc219d0d7837825b3fefa53a1858e86 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ca40621910b1ba3e4745aae18e0ad73f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9224fd7983407d574b36a9dc417289a6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/463afb0534b67e6a582cfa3fb9dbf071 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9ec95349c5ec2987388d01593cddae7e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4664bbb08bafbfecede04d8c11346f8c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/217bb099a369e3acbf611415e54557b6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5ff497c9b30cef4fe051610c96ae9e39 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/15951bf9399a560654a84bae8c3b5ce4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/599351321868b558e8802cbaaafd38fb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dd05ca176581ce392efb76e190dc4e9a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/920e54403cf5c31226bfe6a4a2ccea16 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/523e5e31c8bbcb9b97043b221850b9b0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d0a406e4baa821a0e0be58ed2e74ed14 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/524f2d27c5b92a80c003d9d13cab16da รายละเอียดเพิ่มติม hosttropical
pharmacy canadian superstore: CIPA approved pharmacies – reliable canadian online pharmacy canadianpharm.store
5mg prednisone dose pack instructions
https://aflomaxbuy.com/video/a4e67965318720db29b1efebfd706bf9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5b2470f7fa6246feea417dac46021f95 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6ab2d8d7e4fc77b50706277bf984833f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/275f01c37415b5706740829bc7980a4d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/71cfd4b96551b9d61028958602fa07f1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/217ca63b0a3bebe0aba7219520df23ff รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1ba82b800f437f82a71d518e2e5ed409 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5ff5ff4d2000fd4b7397d15cec477aa5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5988c94b8a678c146b0d57614b8edf48 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e337f121e846b6f28932077de5fda4c2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/97f109a02bb15934cf26fdeb6fe1a6e1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6aab9ec479e0343a0ffc749c830a7fca รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/71c1229b04d4066fe3efe0070ebbc5c0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6aba9d3adfc1e95ebd515a10d610f69a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aab4b5bc88bcc3b8cd7bacda7048727a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/71d848cea3ee58c608e2fa1c306484c6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/82a6d083112c95db7ca6ba63cd3ffd22 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2d9f651e00439e9cc69cfa3a057c9459 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/856245d1f52277a82c490d39a34d6882 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2176afc2fc0ab0ca381a96dbe9a78a7f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/275f9dc657fcfbdaffdf9be83ffb8599 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/65e853b858061259cc53ff3dcb99ed79 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9ec78b2f6e9b8cb619eda69140c9b94e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a4eb120edb47b20705e14af8a5d4cdf9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5b24f83ea4919404f200c56c33c7e942 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/82ac1084a14d9b296d83687190ece8f7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dd03f19a0c8dd593635be313415d2bfb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/85645f3956a707fb0010c75848bc29fe รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/987d42b0ddf85cc7ac60765b84bdf1f9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1bb51fca654661b83334d4ceb84c34f0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/335e64bff80f83ac932b944a7edc673b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/98faab9e491977a3467c94ae749b0277 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6bef8f1a999524cbc3378c8a66723332 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/723ec76bc8a0cd5a472dbbddd5bb46e4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/97ffbc5d9b31c899f7e366eae95f290a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/efa45d2950b9f492fa074a635ba5746d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/987da336cca9c8410e07f355961b5e69 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d731f7525246d0458f3768e7179ee4ae รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/98fe4a5e98c1e385502cdf479491f0f4 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/82ed59afc273a55811816491fdd22068 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/85917767d36c6292f0f4696b7793d01e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3361b6e5578d8e3d9717ce8689f1aee2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6005be721cce5fb310fad8d5f2780a2c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/65ec8c725cce2812a98a2c97849a354d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9ece56608aaf906a27997e0b88d26348 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/82ba53a1e860896db6b8b4cdc376377c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b15da745c3a9830a5c01a335c50b5688 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/856b3d26f0fb1d743547d0ab59936495 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ae594a14dbc01368f87cc7c888595522 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dd098d7486898395761c657406232e11 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fa5db07d9c34972b877afc4469deeb6b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/efab92be3388d23044c1b42da3ce1cb3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/276860cc79e725f3d155e521d4e62f2f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/39cd3baddcfe332fa95e38e56d0618fd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/65eae0cdac2f8627b4d0319b6f48ecd9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7882c4d6ac53b4fad9c8b69994bd52c7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2db17bc4d42fef17ecef18ab546b493e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a4f4c200abbd63d42024b4c189aa6eea รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9880410c245fec4193394a8305fd9602 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/99007c92f4e4ba56b0c87afdceb897b2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c8ccab5b53de7fcebb926e5e7c69e406 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e33e14691f286e5fd95870a10dfc9e34 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0525d7e186d638131601c7105a0db6d6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f69649ed0d208d69de12bf31b73ffe2e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2dab6e9c91dbc429e897b49fc5bf0d7d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6bf1a4f5f33c48fd1ea56350476a5ec2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7ec2a856fddb4fb0a9ed75a5656bb3f6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3365d0f75c6ebb5f3dfb0926e0131d72 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aabb89c3f33cf27381d72993b5bd38f1 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/ae9f62fdd139bc0a89be42277c8c7eea รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bdeeeda68568ca089716d898d9295aa3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/efc33a38ef461071f4cf88ad9e65ef54 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e027759ebe60e4489612a9e13c4bb3a7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e9b48f4586ade815fc6d043cd23bcb7d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0b2d7601279164913b8d2394f96ad7bc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fc91ed9ebb0e54620815429f32b7ca82 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/46800113c02f9b58ba823c6063ccd84b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c925bd8e5dcf10b5b3c9f39a6e15efd6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/85a0c79754470c47335114853ebb9d21 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fa90cedca16b152aa86c387445fd695d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/39d5e1a2547114c5065957eeb6bfbee9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c8f1e4790c78f1506c8e5e2c47dc9328 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fa7949499356a4bc2164219fb7934e19 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c440e14226e5f20840ea3d75c5c028a6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f6ae83ba89810ab83df218c212919654 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/efaf7140ac0c2ff39b377a103b37cf67 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e5bf83ac126a146249232887d8526f0c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/13c7f21711ef1e0dd04eb9b49092686c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/78999257fb62d42749af1d5df8d1bb1e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/39d573ce93eaddcadf63bc21f7f81d19 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/724edc7e8ee1d406801acb33e1d564a1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0531c8290ac40a373e4b936742b44952 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b7b2972e2e6f83ca59b9cf1b470112df รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e030bf404300e978cf08c5f0770bedde รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7ed3ce476b2e1eba4b0e066be0e2753d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/bdfe572753d9379178215301f19fd418 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b1667a04a5d4d17cdb569b6bb2df0233 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fc9de3896d6f1dd291b88a369bafda6d รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c93c5f8cb2633940966124f97b604dd9 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fa94bb7e46797c1992c72ad2ee75c617 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/efcd9593fd6a86236644e74a5881f9d5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7ecbbd671524906c41241cbabd3c197d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/39d6e89cd650ea4e088f1ee3c69d0666 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/789eaf943d6a0624156173973cf273cb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0b335af86733f62718436cdb25a877ee รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f756d317c212e04c01ef469d45ecd2cc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4686f62ab61e4aa65cf506b4f99f89e2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b7ba1d5b5ea5b1d3b0beadfcfae9db13 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fc952aa61250bd8d0e16919053294f60 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e03b21711d2210376df565a6a2d00c28 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/140bf66f3151d43767ebb618e325a257 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0535d73f91623532e2bd03c00d14becc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f6c3cafc1590cb2e40ddb3f9f5c3b3a1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/85af8b2052ec582da88bc9f7ff5cfdfb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4680b0a64a0037ce139bc91871103c8c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/40539224655ff18adddbfd370857b564 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c44f4aab971a846e75e04bf6a534d74c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ee4cbd43de2cc7161820a41d93d75e2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3229a260e5ca344b059479a26899f5cc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4d460e7ca2aa87b5f92b3823c0797a86 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8bd5b1418c15313d6d50381c57513b86 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ee3b3776506d5ac0e060de45f8bb475 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ca5cafa82f09df766daa3e520c5da9db รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f7c93d35c0fc649f3e0c8cf323ab6f08 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/5289e508da5c3f92b7c2c5365358b703 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fca03983f2962ed3b0984b17f1b8bf65 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8bcc1d714c603c014aceb5ca6171df46 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4d429ff3518c44e3db45679bd6073df9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/85b2c0928c70a2a985feed7ef349b4ad รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/468b3bec6c57791b6d84edd89bac4913 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ca4d45215e3ee3ef5f3963a0fd1826f4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/468325378169b10431821bd60872c24f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/15dcec9e9c4cb38285ee6a87eb6e8b19 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/534468efb163cc15f84a54be6d8c778c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/15c7f10718ec8aa243c73f40f5a2fa21 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9237ed40f8d21b68551f889fffced216 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d0c1bae8862154d2f8a56154ae51fc12 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/325e00a50365a8f692ec0b4063a2eecc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ee540bf5be384ed65df09dc1855cda2 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/142a8aff14f56afeef36176c75067953 รายละเอียดเพิ่มติม hosttropical
how to get avodart
https://aflomaxbuy.com/video/922b87da45444b8ca649e92fb35fefbc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/53442084af016f21c3a6bf26215b4c47 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8bdd079b90a262f73f4b90e4f36a31ad รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d0b64efbd35a3ebd48a144a57a8f1f7b รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5b27dcfda05633b78f186cee6b0b408b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e09d3d5f4d0f313b566be839db5201f1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0537d9c5f34e94663cfecb61a2877460 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ca637c19290561d127e67a913f160d98 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9809515c046ed6f9e641a1a05ce2bfe5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d733181a272cb147c08bda21ce22dacc รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/4693ca01af4fab2182568288a9b3e2a8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/15ed2c8c4c08671c7f2d7c3c7efa86f6 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8309a7100c17c0b75e2f2db9ec145d24 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/529f61c5b37fab229e04c7fb27d965b4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/405b8f04d6c03eb849a359228826bbc7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7ee6785b3c76af1b1fe79c7999b65126 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/53462aaebb0aea2d2954e367f87aadac รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f807858c86c45ddf711dfdd037f8e559 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/722806257328ffcb0130d4abdf461f3b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2188998ab3f699f90545bd403440c2cb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d0c440e86526deea5e31a52f3f713960 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9ed027077af9525824a081226acb39cf รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1bc29e9d5d97807a89537a6b59a2e636 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/98a19e4ece0737d839c18d7d0ef0d8c5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6b061d235285ed2f577149319101bda1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4691055594ce4f5136ee3839738b320c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/980dec7ae70350467523b08fceaa875a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/59a374e7deb9c099392f7093723fc550 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c46d27288d0bfe7c2973b0f4d073d7cb รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/32b0a57f9eecece81da487c3b80e95a2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ee618c3444a29f4d9b58200522ba21c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ee6749eeeee931636c1fc53b8f42223 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d7338a8710db29297862b4ba80c0962c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4d5a71e0151df07cab1604236942c94d รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/727d060b32e5c5b15479d74cb95821b4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8bde6ddb3173d8e11841965636ab4590 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ca651bafcf8589c5e463828d8c0e8e0e รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/52d83b10da8b287c7a6d3b97b87885d5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4d53f6a9aa6a8a4db534de16cb874e70 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/8bdd293f9d8f9cad31e2304d98bf220e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9ed04bb0873140afb6d30f27554e2fdd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6019bda42014477a62045c6572581da6 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/470998e73d3fee53a07ee0de7b58e135 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/471ccc2bcc777178cac8cdef44a81628 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/15eefb3404eed52a5ca51fcb59800e18 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/52b6d171d03ac8e9c1a044ea85808c9d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dd25fe725b88a37069a5ce337b1d5a84 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/534bfa3000ea113a7dc8b602e2e67f79 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/85a650b935397d8a633b185eb45846c9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/92462cc4926c5c59255392ef73665fdd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d0cf876434a138fe280cc6737e97371f รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6b2c370f33b30f5e9c240b8b3c640643 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9242d7bfa1722c90a57dc0ab07f7e999 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a4fb24d330e98d1c8714ad93249fa3ca รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d0c9d7481500c431013fce16e9758d54 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5b5adc6f41634bc16aeb990af1869506 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e34b7f76d4d08b2f42b232680a2c857b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1bdbf8ff76a0c12550b4023a21fb780f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/59ac3b9f8e4745d03cd7b473d9d9d771 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/997795b9d63c64d0961ffc0ad5b8bd8c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2dc528dd9e254a2cc8b50beff7de9f43 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/982cb2e3207cda0d4d6119d211adac00 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/59a87ba7255f4d4ff5fe62f043b33de5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d746e56dea411878774dab5b8c62f915 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/8332ad6ccfd6a21429ff7e99832ffbb1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/980ed52ec7be33bc9d8d707234c29cf9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aac07ea2c301378cdce2fe29d4812979 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d737610e30f1134c3ed56b8e3cfcf634 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6bf923bacd2a6f7412103de6198fa598 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/831e53934ef272eb33b262eda69326e9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/219f0c4c146408f6140d6f9974d7e3f3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e9b7a4c18b9d5aa099e3de3035fbfd6e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1bf53d2a7b3f6c78dc2cc62bfbb9b9a7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/21a08d2fefe0ed246860bd0fb0564d64 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6027c91762e150a7cb22a6600e8bf986 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/601bba38422f3a9302a1cd77c95c67e1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9ed8df0558bd6db81bd2f0ef5f16750a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dd339d8cf9ef257cc93274cfa8ef4f6b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9ed246f52a155738a59f9440557d2db0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9968066ce8a5e58e528c81db84efb2e8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/59bdf71d773b726f8c2664d7fc0b6050 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/85b97a0c3159038e03b16c51d487c5c7 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/98358b3a5e3dfadaf09a643bfa838f96 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9930650b270a89a7334d2de3f268f53c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d74b1d708b65cc190ebdda725262cf63 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/85bce8de9fb44e4569afb5beb54a8fe2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/72e33b6b09e14b3a5126399518665157 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/65fe86992d34f11ad7c7a9af4f65c47f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/66018d40f9b95067a896ab281d808197 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/83337ae438996749c00d6860505a4e80 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a500f271aba1e1618f72a76cc750c5bc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e34f312b01da245c5950e1771fec6e64 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/af725ab509fd0ccca1b52682a0e61f8f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9ee749addfdb60049e9f5fc2fc2c2c59 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2dc6ef0fb35d10c3c866889db6998fcd รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/dd34fc33ddcff24fd18e9955225f58c0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/99c5bdc39f1862109b45a3a3589ef1f4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/85dbc4dd1a7f3d58af9a70ad31b56732 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2dcc446ba5c9a5e0efb90656c724ff1b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6bfd8f0271ebff3ff3db9cc1a5c94dd5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aad580b3c0a77e33491f559bcf4cf656 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e9c83fa071767fb22581dc19d2046630 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6602910ca98ae0c4f22a8422865da44f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a5235b327909815067455910e574f9bb รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c9ab337c155dc8d8cd6b1fbe2f5edd07 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/336b6e5c647d62edf88435288ccf5157 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e357ebdc9525581f526b1647ca74a088 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2dcef30bf1d99c869f0a43f739824ce7 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/99e407f1470fb6e6e137dc7dcdeabdc5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/337d87af0351273b6069af2d80fd5f18 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/af8232086eb98cea384053d292372674 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/725f3877465bd0fdd6e8628a82cbae1f รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/faca518133845f5af7cb8a109dcf05a4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b17b211a26e921bf7b7055faac5d3c45 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6c07eebfc450a4be0846990714511e7e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/efd039d1982e6e2ab34c65c9736a3978 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e0ac0a840048e3fe50b0bf385670e3a7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e0b0e3e5a870327cbcc50f19dc17c18f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e9c8b9b987624b8e09f42c132d798c76 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/33807695df3e6ba4f5e408d42434522d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/78a7a545e9d8db5b1a6cdd673d154ec2 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fad6fdb826b3fc7247e2d741a14e17d8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b7c444ae3b26ccca123dc89d4c388878 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/39df27c9fb2fd975ebee3da5ea7955db รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/78b389e15c062ed0212b7c792bb49fa6 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b7cdbc0e38425b2e4cf5af608beff4d9 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2788755fae71d77467d38ad6483e3d08 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b17cb323cac17a9bbde40234b2a7ff9b รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/f8252d2ce1d34181291c7f5f69c01d99 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/efdb7e2eecdf4fcbb694975bc5da809c รายละเอียดเพิ่มติม hosttropical
prednisone how long to take
https://aflomaxbuy.com/video/39e5fa4003f56d1e8ebec0f33b8cf328 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fad87bb30115a62e6e6373e12c024c64 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/a52670baf3faf324f5676990b55478a0 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e0c5f210d0927a60edfbb501da883c79 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9a33881eb7f91b2bae937dc7c46527da รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/78c12b3af4100e1cbca8d7516e46208e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2dcf786b6a521b9bc74978361107a8e5 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/af8af2990e81c7831af42a38c53783c1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fcaf84b86fdb717214c2ac4816332d95 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/332086110e26ee4a27d3edb83bc463e1 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f6f2b7779ca2da8c7b58aaaed2cce2ab รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4065213a0488f17d617818623bedd45a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/053eaffc3decc24e5d660a47ca5c4ab3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aae154c7400d32733768725414a166dc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0b616886b2c067bafea9164f4f759263 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e9c969f63b9a8a84dc7429a3e8d45809 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7ee97e26e45f7faa108517fac2330102 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/3383c61b7caedf7397976ada1c2cb999 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/c9ae43d6667873d70bbc948df836501b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/be1d2318a02dc66de7fa00d3c3480dfd รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1460b0f520a91ac155d5f6d8a8f13327 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/47292ccba23b939fb2e25ec4897535f2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/469c4935bd528289412884cfb7eb7345 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0b6aaeaf225c30ef0e8e28c639ecfb8b รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b1805903138bb68d4ec457fdcf2d6d2c รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/332605b294b063e7e749f50349b5d543 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fb1c91f04348e6d7afcbbd66cac30df0 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/fb1a4b9fbcca83d9a4f20ad0674f8a06 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/39f5d388d8b6f1e231070ee48357026c รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/e0cc13dac466df7adb9fdacf6395336c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/78cf4d4e86bad832088ef72089dc2a07 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b7e9194ee71f17ba3bd0f66db67ea48a รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/1465a708d44d736ddfe8f9fbac5e030f รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4d6542354a3c1a2c4519cf0a42e47c3a รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/78c5ec4803ea19b88c7b61949099803e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b7dceacfa6624b2d0f430b1f9e079e88 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/47459ebedcbeb452ec3c9ce64fd27b33 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f6fbbc0cf54cee2b3709550abf3b751c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/05483c1aa2eec8820cbfd38d9c3beb05 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/05505581a49f1531180402bc67506991 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4066aaf998afeb6377b021e3095e7480 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/3335883d0d0fc1a2f45c5a5140b01044 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ca65d6b59446e878927f2db250564a35 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7ef61bae99b8c84e8edf27630c1ff6b8 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/be2ac0c95da7d70a60261b9f0593e6ce รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fcbb3df7ebca4f708b06132ca9b83dde รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/5357d13cb67308d9d116b72a615bf72e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/474a0f0572cae510da67bafa25f612ae รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/15ff9502fa2cb80a7ec88163fbb41d40 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/7eedd88ab7c938dea176d2376ff9de42 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/be24250f7c07705acf1ebae4ce25049e รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/5ba026dedb932c47cee643c06f0346fa รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fcb65fe1b73261cb30e2f51222437115 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/46aaef19af867f9ae064a2cccfd328ac รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0b86ad19050be230fa424d1917e683c4 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/474970a9a0b1558b60e496f766ede9dc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/46bf5309eadd6b61b891a4eb33183ce5 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/85d36ce9fb6b9af9cec967a2a7fd84c9 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/52eafb336e3772f61141d4fb48e84055 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0f0593adf5116e1c4d0a7ed619c1eb09 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/c488cd73ef25f2edea422983a6cc513d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/0ef505f58baa97ee7f3735c910b26dda รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/4d691839f4663bd54614bbb758f2c9e7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6b55fa341b48b052a5e2a1862c364fca รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/ca67706f7d4c7e5c6ecf358f284ee0c4 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1614daf4ebabc7b6e63ac8560e05716a รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/731ce2a4f9db88172638a982e36b0f17 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d0da4687adebef70fef22650a3acafeb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/1bfcd753abbb7fde94532b2fd13e2357 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/d0d7d3c1630badbdb7a5f99adf7e8642 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/6b3858125201dddb78fce19b64263dbe รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/835f6485d20be70313e35262746693a3 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/862572fcf13e703642f20ad87f3610b8 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/9a77e2787da873124a579a22f38a65e7 รายละเอียดเพิ่มติม hosttropical
https://porn2p.com/video/9a4ec1ad17e41cd776cd8320682783cc รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/9eeb1ad59a8631d8fe22b5895afab044 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/27a81dafd977e1d656ccf52f48fe9706 รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/e71e4de936d9769455f859685f753929 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e3614abbc5131d007d11b02647074e93 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2dd644c3091a8c229941bd4ad4efda10 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6c0f6580fe985c2ae484411d5816049d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6628132c3b8b042b25e8ac7158bba3e0 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/279855d4e89aadf3820893eab5fa2444 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aae869f197e52d9d2c3383a3da3a5c35 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/66210ab92b95cea36c1283b9917ca8b2 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/338811d9a5c08054d36909572b6c8c5d รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2dd6b7f7598f128a49d491a13fb62309 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/6c11906eeb84615eee8c99c746e0c2df รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b19290d08d8384b5ad958bc15eb63ffb รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/2dd58d553ad7c9ffe354a7e6928b847e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/aae3c590cdd0f1dd4f3f68d5e7302930 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/e9e1a02e4f3574fc9a276e85e85f242c รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/05556eda821adfdf681044704387d7bf รายละเอียดเพิ่มติม hosttropical
https://wuaer.com/video/336f92727592bd0f0e5768b05517a289 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/727fc0999d87612b4ef90cd51735e754 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/78da734f9f2a615b13ba5f17e9d36605 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/fcd2eb3e7a651055a8492640777664e3 รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/b7f7d424e7ad5b8928a8c8ca606df9ef รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/f6fc7b736772926eae4ab1968a55701e รายละเอียดเพิ่มติม hosttropical
https://aflomaxbuy.com/video/161a8c95e4f47b444795ecbf4a42656a รายละเอียดเพิ่มติม hosttropical
generic lyrica for sale
обнал карт работа
Обналичивание карт – это неправомерная деятельность, становящаяся все более распространенной в нашем современном мире электронных платежей. Этот вид мошенничества представляет тяжелые вызовы для банков, правоохранительных органов и общества в целом. В данной статье мы рассмотрим частоту встречаемости обналичивания карт, используемые методы и возможные последствия для жертв и общества.
Частота обналичивания карт:
Обналичивание карт является достаточно распространенным явлением, и его частота постоянно растет с увеличением числа электронных транзакций. Киберпреступники применяют разнообразные методы для получения доступа к финансовым средствам, включая фишинг, вредоносное программное обеспечение, скимминг и другие инновационные подходы.
Методы обналичивания карт:
Фишинг: Злоумышленники могут отправлять фальшивые электронные сообщения или создавать веб-сайты, имитирующие банковские системы, с целью получения личной информации от владельцев карт.
Скимминг: Злоумышленники устанавливают устройства скиммеры на банкоматах или терминалах для считывания данных с магнитных полос карт.
Вредоносное программное обеспечение: Киберпреступники разрабатывают вредоносные программы, которые заражают компьютеры и мобильные устройства, чтобы получить доступ к личным данным и банковским счетам.
Сетевые атаки: Атаки на системы банков и платежных платформ могут привести к утечке информации о картах и, следовательно, к их обналичиванию.
Последствия обналичивания карт:
Финансовые потери для клиентов: Владельцы карт могут столкнуться с денежными потерями, так как средства могут быть списаны с их счетов без их ведома.
Угроза безопасности данных: Обналичивание карт подчеркивает угрозу безопасности личных данных, что может привести к краже личной и финансовой информации.
Ущерб репутации банков: Банки и другие финансовые учреждения могут столкнуться с утратой доверия со стороны клиентов, если их системы безопасности оказываются уязвимыми.
Проблемы для экономики: Обналичивание карт создает экономический ущерб, поскольку оно стимулирует дополнительные затраты на борьбу с мошенничеством и восстановление утраченных средств.
Борьба с обналичиванием карт:
Совершенствование технологий безопасности: Банки и финансовые институты постоянно совершенствуют свои системы безопасности, чтобы предотвратить несанкционированный доступ к картам.
Образование и информирование: Обучение клиентов о методах мошенничества и том, как защитить свои данные, является важным шагом в борьбе с обналичиванием карт.
Сотрудничество с правоохранительными органами: Банки активно сотрудничают с правоохранительными органами для выявления и пресечения преступных схем.
Заключение:
Обналичивание карт – весомая угроза для финансовой стабильности и безопасности личных данных. Решение этой проблемы требует совместных усилий со стороны банков, правоохранительных органов и общества в целом. Только эффективная борьба с мошенничеством позволит обеспечить безопасность электронных платежей и защитить интересы всех участников финансовой системы.
can lisinopril cause wheezing
top online pharmacy india: indian pharmacy online – top 10 pharmacies in india indianpharm.store
http://mexicanpharm24.com/# buying from online mexican pharmacy mexicanpharm.shop
http://canadianpharmlk.com/# canadianpharmacy com canadianpharm.store
apo prednisone price canada
order prednisone without a prescription
https://moskva-cleaning.ru/
doxycycline for 5 days
https://ekspert-komforta.ru/
http://indianpharm24.com/# top 10 online pharmacy in india indianpharm.store
https://calculatortiktok.com/
купить диплом университета http://saksx-diploms24.com/ .
buying generic precose price
С энтузиазмом сообщаем о дебюте переработанного мобильного приложения БК Олимп для Android устройств! Этот релиз значительно трансформирует ваше прежнее взаимодействие с ставками, делая его более интуитивным и эффективным. Приложение БК Олимп доступно сегодня! В новой версии приложения пользователи обретут непосредственный доступ к обширному каталогу спортивных соревнований непосредственно со своего устройства. Улучшенное управление аккаунтом, новаторский дизайн для легкого навигации и значительное ускорение работы приложения – всё это ждет вас. Станьте одним из счастливых пользователей и наслаждайтесь от ставок в любом уголке мира и всегда. Получите обновление приложения БК Олимп прямо сейчас и откройте для себя новый уровень игры!
doxycycline 100 mg dispersible tablets
обнал карт форум
Обналичивание карт – это противозаконная деятельность, становящаяся все более распространенной в нашем современном мире электронных платежей. Этот вид мошенничества представляет тяжелые вызовы для банков, правоохранительных органов и общества в целом. В данной статье мы рассмотрим частоту встречаемости обналичивания карт, используемые методы и возможные последствия для жертв и общества.
Частота обналичивания карт:
Обналичивание карт является весьма распространенным явлением, и его частота постоянно растет с увеличением числа электронных транзакций. Киберпреступники применяют различные методы для получения доступа к финансовым средствам, включая фишинг, вредоносное программное обеспечение, скимминг и другие инновационные подходы.
Методы обналичивания карт:
Фишинг: Злоумышленники могут отправлять поддельные электронные сообщения или создавать веб-сайты, имитирующие банковские системы, с целью получения личной информации от владельцев карт.
Скимминг: Злоумышленники устанавливают устройства скиммеры на банкоматах или терминалах для считывания данных с магнитных полос карт.
Вредоносное программное обеспечение: Киберпреступники разрабатывают вредоносные программы, которые заражают компьютеры и мобильные устройства, чтобы получить доступ к личным данным и банковским счетам.
Сетевые атаки: Атаки на системы банков и платежных платформ могут привести к утечке информации о картах и, следовательно, к их обналичиванию.
Последствия обналичивания карт:
Финансовые потери для клиентов: Владельцы карт могут столкнуться с материальными потерями, так как средства могут быть списаны с их счетов без их ведома.
Угроза безопасности данных: Обналичивание карт подчеркивает угрозу безопасности личных данных, что может привести к краже личной и финансовой информации.
Ущерб репутации банков: Банки и другие финансовые учреждения могут столкнуться с утратой доверия со стороны клиентов, если их системы безопасности оказываются уязвимыми.
Проблемы для экономики: Обналичивание карт создает экономический ущерб, поскольку оно стимулирует дополнительные затраты на борьбу с мошенничеством и восстановление утраченных средств.
Борьба с обналичиванием карт:
Совершенствование технологий безопасности: Банки и финансовые институты постоянно совершенствуют свои системы безопасности, чтобы предотвратить несанкционированный доступ к картам.
Образование и информирование: Обучение клиентов о методах мошенничества и том, как защитить свои данные, является важным шагом в борьбе с обналичиванием карт.
Сотрудничество с правоохранительными органами: Банки активно сотрудничают с правоохранительными органами для выявления и пресечения преступных схем.
Заключение:
Обналичивание карт – серьезная угроза для финансовой стабильности и безопасности личных данных. Решение этой проблемы требует совместных усилий со стороны банков, правоохранительных органов и общества в целом. Только эффективная борьба с мошенничеством позволит обеспечить безопасность электронных платежей и защитить интересы всех участников финансовой системы.
lisinopril dosage for blood pressure
https://indianpharm24.shop/# top online pharmacy india indianpharm.store
Pills information sheet. Generic Name.
zithromax medication
Some information about meds. Get here.
https://moskva-cleaning.ru/
doxycycline from canada
Drugs information. Effects of Drug Abuse.
cost zenegra
Best information about medicament. Read information here.
https://ekspert-komforta.ru/
https://calculatortiktok.com/
where to buy ciprofloxacin
Drugs information. What side effects?
how to buy meloxicam
Best what you want to know about meds. Get here.
https://moskva-cleaning.ru/
can i order dapsone for sale
homesimprovement.net
С энтузиазмом объявляем о запуске переработанного мобильного приложения БК Олимп для Android устройств! Этот шаг значительно трансформирует ваше опыт с ставками, делая его более интуитивным и быстрым. Приложение букмекера Олимп доступно сегодня! В новой версии приложения пользователи обретут непосредственный доступ к широкому спектру спортивных соревнований непосредственно со своего устройства. Оптимизированное управление аккаунтом, новаторский дизайн для беспрепятственного навигации и повышенная скорость работы приложения – всё это ждет вас. Присоединяйтесь к рядам удовлетворенных пользователей и наслаждайтесь от ставок в любом уголке мира и всегда. Загрузите обновление приложения БК Олимп сегодня и начните новый уровень игры!
https://ekspert-komforta.ru/
tiktok calculator
Drugs prescribing information. What side effects?
atorvastatin
Everything news about meds. Read here.
levaquin for sinus infection
https://indianpharm24.com/# online shopping pharmacy india indianpharm.store
california-invest.com
Meds information for patients. Generic Name.
lisinopril otc
Some news about drug. Get here.
get generic macrobid without rx
Medicines information sheet. Drug Class.
priligy
Everything information about meds. Read now.
БК Леон приложение
1xbet
Pills information. Effects of Drug Abuse.
strattera
All what you want to know about medication. Get here.
https://mexicanpharm24.com/# mexican rx online mexicanpharm.shop
Здравствуйте, друзья! В настоящий момент собираюсь поделиться личными впечатлениями о ап икс официальный сайт. Это место, где удовольствие объединены в одном локации. Здесь я нашел огромный выбор забав. Начиная от традиционных автоматов и заканчивая прямыми играми с реальными дилерами. Бонусы и специальные предложения приятны поразили, а качество поддержки на высочайшем уровне. Вчера удалось достать большой джекпот, и я уже не могу дождаться возвращения обратно сюда. Рекомендую всем испытать свою собственную судьбу в up-x!
Энергично делимся новостью о запуске новаторской версии приложения для ставок от БК Олимп на Android! Это обновление изменит ваш подход к ставкам, делая процесс легким и эффективным. Внедрение новейших технологий позволяет предоставить прямой доступ к огромному массиву спортивных мероприятий с вашего мобильного. Скачать апк файл Олимп Бет и благодаря последним обновлениям, вы насладитесь легкостью управления счетом, понятным дизайном для оптимальной навигации и повышенной производительностью приложения. Становитесь частью сообществу довольных клиентов БК Олимп, наслаждаясь возможностью делать ставки где угодно и в любое время. Установите актуальную версию приложения уже сейчас и выходите на новый уровень в мире ставок!
Medicines prescribing information. Brand names.
cialis super active without rx
Actual about drugs. Get now.
привезти груз из китая http://perevozka-iz-kitaya.ru/ .
indiana-daily.com
real-apartment.com
бк леон скачать
глаз бога телеграм
http://indianpharm24.com/# reputable indian pharmacies indianpharm.store
Meds prescribing information. Effects of Drug Abuse.
proscar
Some about medicine. Get now.
Леон на айфон
1xbet
Drug information for patients. Generic Name.
meloxicam price
Everything what you want to know about meds. Get here.
Откройте двери к безопасной и верной услуге автопомощи с Minsk-Evakuatori! Мы рядом! Услуги эвакуации автомобилей – это ваш надежный партнер в случае нештатных ситуаций на дороге, гарантируя оперативное и эффективное эвакуирование вашего автомобиля. В Minsk-Evakuatori вы найдете квалифицированных специалистов, готовых помочь в любой обстановке, обеспечивая безопасный перевозку вашего транспортного средства к месту назначения. Доверьте нам заботу о вашем транспортном средстве – Minsk-Evakuatori всегда рядом, чтобы предоставить вам помощь на дороге по Минску и всей Беларуси.
ticagrelor more effective than prasugrel
Bono casino sin deposito: ?juega ahora!
casino online bono sin deposito casino con bono de bienvenida sin deposito .
Drugs information leaflet. Generic Name.
nolvadex
Everything about drugs. Read here.
Bonificacion instantanea: bono casino sin deposito
bono gratis para casino sin deposito casino en linea con bono de bienvenida sin deposito .
clomid out of stock
http://mexicanpharm24.com/# mexican rx online mexicanpharm.shop
buy prednisone 20mg
https://kupitzhilie.ru/
avodart generics price
Medicament information. Cautions.
diltiazem
Everything trends of drug. Read information now.
Лучший выбор тепловизоров для ночного видения
тепловизоры https://www.teplovizor-od.co.ua/ .
Medication information. Effects of Drug Abuse.
caduet prices
Actual information about drug. Read now.
Тепловизоры: обзор популярных моделей
цена тепловизоры http://www.teplovizor-od.co.ua .
https://salezhilie.ru/
сколько стоит услуги клининга в москве
Анализ конкурентов для успешного продвижения сайта
8
seo это https://www.seo-prodvizhenie-sayta.co.ua/ .
doxycycline 100mg for std
Анализ конкурентов для успешного продвижения сайта
8
сео продвижение сайта https://www.seo-prodvizhenie-sayta.co.ua/ .
Pills information for patients. Drug Class.
cordarone
All information about meds. Get information here.
https://kupithouse.ru/
http://prednisonest.pro/# prednisone online pharmacy
С огромной радостью разделяем новостью о релизе обновленной версии мобильного приложения от БК Олимп для Android! Это обновление изменит ваш подход к ставкам на спорт, делая процесс более гладким и быстрым. [url=https://olimpbet-apk.ru/]Olimp bet на телефон[/url] и вы получите легкий доступ к огромному выбору спортивных мероприятий, открытых для ставок прямо с вашего мобильного. Усовершенствованные функции управления профилем, интуитивный дизайн для упрощения навигации и значительное повышение скорости приложения обещают выдающийся опыт. Присоединяйтесь к сообществу довольных клиентов и наслаждайтесь ставками в любом месте, когда захотите. Скачайте последнюю версию приложения БК Олимп уже сейчас и выходите на новый уровень игры с комфортом и стилем!
Meds information sheet. What side effects can this medication cause?
diltiazem pills
Best information about pills. Get now.
https://kupitroom.ru/
Всем здравствуйте. В поисках где купить реплику наушников Airpods PRO? Наилучшие беспроводные наушники в Москве и области. Реплика оригинальных AirPods с шумоподавлением по цене 2490 рублей. Проверенные гаджеты по низким ценам. Быстрая доставка по России.
livingspainhome.com
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99 .
air cargo charter airlines http://www.aircgc-lux.com .
Восторгаемся возможностью представить новейшее обновление приложения от БК Олимп для Android! Ваше взаимодействие со ставками на спорт будет еще более увлекательным благодаря обновленному интерфейсу и ускоренной работе программы. Olimp на андроид доступное для игроков! С последней версией приложения вы получите прямой доступ к множеству спортивных событий прямо с вашего мобильного устройства. Ожидайте новые функции для управления счетом, передовой дизайн для интуитивного использования и значительное улучшение скорости приложения. Станьте частью довольных клиентов БК Олимп и радуйтесь ставкам где угодно и когда угодно. Установите последнюю версию приложения без промедления и начните побеждать вместе с Олимп!
https://grandolavanderia.ru/
purchase tetracycline online cheap
flarealestates.com
Medicament information leaflet. Short-Term Effects.
buy generic prednisone
Best what you want to know about drugs. Read information now.
https://grandolavanderia.ru/
https://arcmetal.ru/
Осознание сущности и рисков связанных с обналом кредитных карт может помочь людям предупреждать атак и сохранять свои финансовые ресурсы. Обнал (отмывание) кредитных карт — это механизм использования украденных или неправомерно приобретенных кредитных карт для проведения финансовых транзакций с целью замаскировать их происхождения и заблокировать отслеживание.
Вот некоторые из способов, которые могут способствовать в уклонении от обнала кредитных карт:
Защита личной информации: Будьте осторожными в отношении предоставления персональной информации, особенно онлайн. Избегайте предоставления банковских карт, кодов безопасности и дополнительных конфиденциальных данных на сомнительных сайтах.
Мощные коды доступа: Используйте мощные и уникальные пароли для своих банковских аккаунтов и кредитных карт. Регулярно изменяйте пароли.
Мониторинг транзакций: Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это позволит своевременно обнаруживать подозрительных транзакций.
Антивирусная защита: Используйте антивирусное программное обеспечение и обновляйте его регулярно. Это поможет препятствовать вредоносные программы, которые могут быть использованы для изъятия данных.
Осмотрительное поведение в социальных медиа: Будьте осторожными в социальных сетях, избегайте публикации чувствительной информации, которая может быть использована для взлома вашего аккаунта.
Своевременное уведомление банка: Если вы заметили какие-либо подозрительные операции или утерю карты, сразу свяжитесь с вашим банком для заблокировки карты.
Получение знаний: Будьте внимательными к новым методам мошенничества и обучайтесь тому, как предупреждать их.
Избегая легковерия и осуществляя предупредительные действия, вы можете минимизировать риск стать жертвой обнала кредитных карт.
http://clomidst.pro/# can i buy generic clomid pills
will stromectol kill lice
Medicine prescribing information. Generic Name.
valtrex without rx
Everything trends of meds. Read information now.
will levaquin treat uti
Meds information. What side effects?
xenical
Best what you want to know about medicine. Read here.
hoki1881
lisinopril 20 mg lisinoprilvira
Meds prescribing information. Drug Class.
buy generic macrobid
Some news about medicines. Get information here.
ciprofloxacin 500 mg online
Meds information sheet. Effects of Drug Abuse.
zithromax cheap
Everything news about meds. Read here.
http://prednisonest.pro/# prednisone 20 mg without prescription
what does diltiazem treat
Pills information. Generic Name.
mobic
All news about medicament. Read here.
https://kupitroom.ru/
Приятели, я недавно выяснил для себя фантастическое пространство для азартных увлечений – онлайн гемблинг-клуб selector casino зеркало! Здесь я отыскал массивный ассортимент экшенов благотворительные бонусы и незамысловатый интерфейсное решение, какой даже и начинающий сможет научиться без труда. К более того, круглосуточная поддерживающий сервис ассистирует выяснить разнообразные вопросы-запросы сразу. Присоединяйся и пробуйте счастье вместе с промокоды селектор уже сегодня!
buy stromectol online uk
Medicament information leaflet. What side effects can this medication cause?
provigil
Everything what you want to know about drug. Get here.
can you buy cipro
полезные советы
9. Электронные прицелы для стрельбы на разные дистанции
оптический прицел цена https://opticheskiy-pricel-odessa.co.ua/ .
обзор
3. Прицелы для стрельбы на дальние дистанции
оптический прицел купить http://opticheskiy-pricel-odessa.co.ua/ .
Medicament information. What side effects can this medication cause?
fluoxetine order
All what you want to know about medicament. Get information now.
https://amoxilst.pro/# azithromycin amoxicillin
индмвидуальный трансфер в белокуриху http://transfer-novosibirsk-belokurikha.ru/
where can i get cheap tegretol pill
https://spbflatkupit.ru/
аренда свадебного автомобиля с водителем в москве https://www.transferfromto.ru/ .
Meds information. What side effects can this medication cause?
differin without a prescription
Actual trends of medicines. Get here.
how to buy stromectol
pontoon rental marathon fl https://boatrent.shop/
https://spbdomkupit.ru/
buy ashwagandha Д±n australia
Drugs information for patients. Effects of Drug Abuse.
zithromax
All what you want to know about meds. Get now.
https://spbhousekupit.ru/
Pills information for patients. Generic Name.
nolvadex
Some trends of drugs. Get information now.
https://clomidst.pro/# how to get cheap clomid for sale
секс игрушки для девушек в Минске. Бесплатная доставка по Беларуси. Гарантия конфиденциальности покупок. Действуют скидки.
can you take cipro with food
Medication information. Cautions.
mobic tablets
Some trends of medication. Read information here.
https://spbkupitzhilie.ru/
трансфер аэропорт толмачево белокуриха http://transfer-novosibirsk-belokurikha.ru/
buying cheap caduet online
manga
Medication information leaflet. Drug Class.
lisinopril
All what you want to know about medicine. Get here.
Drugs information leaflet. Drug Class.
flibanserina buy
All information about medicines. Get information now.
трансфер новосибирск белокуриха цена http://transfer-novosibirsk-belokurikha.ru/
fishing boat rental destin fl https://boatrent.shop/
Drug prescribing information. What side effects?
cost priligy
Best trends of medicines. Read information here.
cetirizine 10 mg tablet
weekly boat rental anna maria island https://boatrent.shop/
Medicines prescribing information. What side effects?
prozac
Best trends of pills. Read information here.
https://prednisonest.pro/# 20 mg prednisone tablet
buy prednisone 5mg without prescription
business-exclusive.com
Meds information for patients. Effects of Drug Abuse.
lisinopril without a prescription
Some about medicament. Read information here.
Meds information sheet. Cautions.
rx kamagra
Everything news about medicines. Get here.
can i order cheap zithromax for sale
Drug information. Effects of Drug Abuse.
pregabalin pill
Actual about medicine. Get information here.
https://ekbflatkupit.ru/
protonix drip for gi bleed
Drugs information sheet. Drug Class.
pregabalin
Actual news about medicament. Read here.
https://zhksaleflat.ru/
hoki1881
диваны кровать недорого интернет магазин https://krovati-moskva11.ru/ .
Medicament information sheet. Long-Term Effects.
zithromax otc
Everything what you want to know about medicines. Read information now.
get cheap super p-force price
Drugs information leaflet. Brand names.
colchicine
Best what you want to know about medicine. Get here.
https://zhksalezhilie.ru/
can you get generic tadacip pill
Pills information for patients. Brand names.
generic provigil
Actual trends of pills. Read here.
Доставка алкоголя в Москве
https://zhksalehouse.ru/
https://zhksaledom.ru/
https://vsegda-pomnim.com/
https://onlinepharmacy.cheap/# pharmacy discount coupons
alcitynews.com
Medicines information sheet. What side effects?
propecia
Actual news about drugs. Read now.
скачать леон
buy prednisone 5mg online cheap
http://klublady.ru/
where can i buy generic imuran without prescription
Drugs information. Long-Term Effects.
differin
Actual what you want to know about medication. Get information now.
can you buy feldene without a prescription
Medicines information for patients. What side effects can this medication cause?
effexor tablet
Everything about pills. Get now.
https://pharmnoprescription.pro/# buy pain meds online without prescription
Medicine prescribing information. Long-Term Effects.
provigil
All about medicine. Read information now.
how can i get cheap aurogra for sale
Pills information. What side effects?
betnovate buy
All what you want to know about medication. Read now.
http://diplombiolog.ru/
https://vk.com/kupit_shtabelery_moskva?z=video-225103855_456239017%2Fvideos-225103855
сплит система купить http://www.split-sistema11.ru/ .
Medicament information sheet. Generic Name.
protonix
Some news about medicines. Read information here.
http://diplombuhgalter.ru/
http://onlinepharmacy.cheap/# cheapest pharmacy to fill prescriptions without insurance
Medicament information leaflet. Brand names.
avodart
Actual trends of drug. Get now.
В нашем кинотеатре https://hdrezka.uno смотреть фильмы и сериалы в хорошем HD-качестве можно смотреть с любого устройства, имеющего доступ в интернет. Наслаждайся кино или телесериалами в любом месте с планшета, смартфона под управлением iOS или Android.
מרכז המַרכֵּז עבור רִיחֲמִים כיוונים (Telegrass), מוּכָר גם בשמות “רֶּקַע” או “רֶּקַע כיוונים”, הם אתר הספק מידע, לינקים, קישורים, מדריכים והסברים בנושאי קנאביס בתוך הארץ. באמצעות האתר, משתמשים יכולים למצוא את כל הקישורים המעודכנים עבור ערוצים מומלצים ופעילים בטלגראס כיוונים בכל רחבי הארץ.
טלגראס כיוונים הוא אתר ובוט בתוך פלטפורמת טלגראס, מספק דרכי תקשורת ושירותים שונות בתחום רכישת קנאביס וקשורים. באמצעות הבוט, המשתמשים יכולים לבצע מגוון פעולות בקשר לרכישת קנאביס ולשירותים נוספים, תוך כדי תקשורת עם מערכת אוטומטית המבצעת את הפעולות בצורה חכמה ומהירה.
בוט הטלגראס (Telegrass Bot) מציע מגוון פעולות שימושיות ללקוחות: הזמנה קנאביס: בצע הזמנה דרך הבוט על ידי בחירת סוגי הקנאביס, כמות וכתובת למשלוח.
שאלה ותמיכה: קבל מידע על המוצרים והשירותים, תמיכה טכנית ותשובות לשאלות שונות.
בדיקה מלאי: בדוק את המלאי הזמין של קנאביס ובצע הזמנה תוך כדי הקשת הבדיקה.
הצבת ביקורות: הוסף ביקורות ודירוגים למוצרים שרכשת, כדי לעזור למשתמשים אחרים.
הוסיפו מוצרים חדשים: הוסף מוצרים חדשים לפלטפורמה והצג אותם למשתמשים.
בקיצור, בוט הטלגראס הוא כלי חשוב ונוח שמקל על השימוש והתקשורת בנושאי קנאביס, מאפשר מגוון פעולות שונות ומספק מידע ותמיכה למשתמשים.
Medicine prescribing information. Short-Term Effects.
cipro
Actual about medicines. Get now.
https://kursovyebiolog.ru
Medicines information sheet. Drug Class.
bactrim without insurance
Everything about drug. Get here.
Доставка алкоголя в Москве
https://kursovyebuhgalter.ru
https://pharmnoprescription.pro/# online pharmacy with prescription
cost of generic aurogra tablets
Medicament prescribing information. Effects of Drug Abuse.
buy fluoxetine
Actual information about pills. Get information here.
can i buy prednisone online in uk
Medicament information leaflet. Brand names.
dapsone
Some about drug. Get here.
how is blockchain different from traditional database models?
carsnow.net
Meds information. Brand names.
zoloft
Everything news about drugs. Read information now.
get cheap accutane without prescription
Какая трава используется в рулонном газоне
рулонный газон купить в москве https://rulonnyygazon177.ru/ .
Drug information. Effects of Drug Abuse.
aurogra
Best about meds. Get information now.
Как выбрать лучший рулонный газон для климата вашего региона
рулонный газон стоимость м2 https://rulonnyygazon177.ru/ .
Как выбрать лучший рулонный газон для климата вашего региона
рулонный газон стоимость м2 https://rulonnyygazon177.ru/ .
how to get generic stromectol without prescription
Medicines information sheet. Generic Name.
fluoxetine without rx
Best what you want to know about medication. Read here.
can i get inderal without prescription
crypto arena seating chart
ברורים והסכמה הדדית שהוקמה מההתחלה. עם מבחר גדול של נערות ליווי צעירות ומבוגרות, רוסיות, אתיופיות, מרוקאיות, ישראליות לך לדעת על ועל השירות הייחודי שלהן ואז תחליט איזה מהן להזמין לחדר המלון שלך. מה הם כללי התנהגות עם בדרך כלל בנות מהממות האלה נערות ליווי בחיפה
Medicament prescribing information. Drug Class.
levaquin
Everything news about medicines. Read here.
Хотите разнообразить свой опыт на BongaCams? Не хватает токенов или хочется приобрести аккаунт с дополнительными привилегиями? Мы предлагаем широкий выбор токенов и аккаунтов BongaCams по самым привлекательным ценам. Наш сервис гарантирует безопасность и конфиденциальность вашей покупки. Получите доступ к эксклюзивным возможностям BongaCams прямо сейчас, сделав выгодную покупку у нас!
купить токены бонгакам
crypto arbitrage vip
וזמינות כדי לספק לך הנאה מקסימלית. מפגשים קבועים וגם מאוד פופולריות במיוחד בקרב גברים המבקשים לחקור את הצד האירוטי או לשפר את גברים רבים מוצאים את עצמם המומים ועמוסים בלחצים של חיי היומיום הקשים ובלתי צפויים. מציעות הפוגה מגורמי לחץ אלה ומאפשרות לכם דירות דיסקרטיות באשדוד
Полный комплекс бухгалтерских услуг для юридических лиц, ООО и ИП. Ведение бухучета, сопровождение и обслуживание бизнеса. Наши бухгалтеры помогут Вам бухгалтерские услуги
can i purchase generic aurogra without prescription
Meds prescribing information. What side effects can this medication cause?
neurontin brand name
Some about pills. Read now.
לך לדעת על ועל השירות הייחודי שלהן ואז תחליט איזה מהן להזמין לחדר המלון שלך. מה הם כללי התנהגות עם בדרך כלל בנות מהממות האלה מגוון רחב של שירותים אינטימיים המספקים טעמים ורצונות שונים. מעיסויים אירוטיים מסורתיים ועד טכניקות מיוחדות וייחודיות, יש משהו נערות ליווי בתל אביב
Medicament information sheet. What side effects can this medication cause?
prednisone
All news about medication. Get here.
В современной промышленности важное значение имеет испытательное оборудование, позволяющее оценивать параметры изделий на различных этапах производства. Один из ключевых видов такого оборудования — вибростенды, предназначенные для испытания компонентов и сборок на устойчивость к воздействию механических колебаний электродинамические вибростенды
הביצועים המיניים שלהם. שילוב של מגע מיומן, אווירה רומנטית נעימה והנאה מוגברת יכול להוביל לשחרור מתח, לעלייה בביטחון העצמי מיניים, אלא שהן גם מספקות לגברים הזדמנות לחקור ולאמץ את החושניות שלהם בסביבה בטוחה ומבוקרת. האם אתה מוכן לחבק את העולם החושני נערות ליווי בחיפה
Pills information sheet. What side effects?
cost cipro
All news about medicament. Get information here.
עם מפגש לוהט עם הוא צורה אינטימית וחושנית של טיפול במגע מיני המתחבר לתגובת ההנאה הטבעית של גוף האדם. הוא משלב טכניקות מסורתיות אינטימית הכי עמוקה! בהזמנה לבתי מלון בילוי דיסקרטי מפנק במלון או בביתך הפרטי עם מספק שער להנאה אירוטית חושנית ותשוקה מעבר נערות ליווי בחיפה
generic lisinopril prices
Medicine prescribing information. Effects of Drug Abuse.
minocycline without dr prescription
Actual trends of drugs. Get information now.
https://indianpharm.shop/# mail order pharmacy india
עם מפגש לוהט עם הוא צורה אינטימית וחושנית של טיפול במגע מיני המתחבר לתגובת ההנאה הטבעית של גוף האדם. הוא משלב טכניקות מסורתיות שיטות אלטרנטיביות של קבלת הנאה איכותית, הביקוש להזמנות עולה בשנים האחרונות כי אנשים מחפשים דרכים חדשות ומרגשות להתפנק ולחקור את דירות דיסקרטיות באשדוד
какие биржи сейчас работают
לכל אחד שמחפש חוויה הכי מפנקת! אמנות הפינוק האירוטי של נערות שמחכות לכם ב דורשת מיומנות, רגישות והבנה מעמיקה של האזורים ולתחושה גדולה יותר של מודעות עצמית. אמפתיה, כבוד והסכמה בזמן ביקור אצל בנות של הם מרכיבים חיוניים בכל מפגש אירוטי עם גבולות דירות דיסקרטיות באשדוד
ומוכנות לפגישה ייחודית! כשמדובר בחיפוש אחר פינוק אולטימטיבי בשילוב מגע וחושניות, שום דבר לא יכול לנצח את החוויה עם . יפות ללילה שלם או כמה שעות. בין אם אתה מקומי או תייר שמחפש הרפתקאות אינטימיות חדשות, התמכרות מענגת לבילוי אירוטי כזה יכולה להיות פשוט נערות ליווי בתל אביב
החיצון. יתרון נוסף של הוא היכולת לשפר את בריאות מינית ורווחה ולהעיר ולעורר את האזורים הארוגניים בגוף תוך זמן קצר. מספקות מקלט מזמינים לבית מלון או דירות נופש ונהנים ממגוון פינוקים הכי אינטימיים למבוגרים! מספקות תחושה עמוקה של רגיעה ויעילות בהקלת מתח נערות ליווי בתל אביב
cost of cheap feldene tablets
http://mexicanpharm.online/# mexican mail order pharmacies
can i order cheap tadacip price
where can i buy generic aurogra pills
order tadacip tablets
how can i get cheap super p-force without rx
https://indianpharm.shop/# indian pharmacy online
how can i get cheap doxycycline no prescription
Medication information sheet. Brand names.
hydroxyzine pill
Everything trends of medicines. Get here.
can i get generic stromectol price
ידועות באווירה אינטימית ונעימה שלהן ובנערות ליווי הכי יפות שמזמינות אותך לגן עדן של הנאה בלתי פוסקת! לבחירתך יש מגוון המציעות יהיו לך יותר בנות לבחירה. הרשה לעצמך בילוי אירוטי עם עוד הלילה! מאפשרות לך לברוח מהלחצים היומיומיים ולהתחבר לנפש שלך בצורה דירות דיסקרטיות באשקלון
мелбет
звуковое студийное оборудование https://www.zvukovoe-oborudovanie11.ru/ .
Meds information sheet. Cautions.
silagra without prescription
Best what you want to know about medication. Get information now.
ללילה שלם או כמה שעות. בין אם אתה מקומי או תייר שמחפש הרפתקאות אינטימיות חדשות, התמכרות מענגת לבילוי אירוטי כזה יכולה להיות פשוט החיצון. יתרון נוסף של הוא היכולת לשפר את בריאות מינית ורווחה ולהעיר ולעורר את האזורים הארוגניים בגוף תוך זמן קצר. מספקות מקלט דירות דיסקרטיות בבאר שבע
вулкан россия игровые автоматы
Medicament information for patients. Generic Name.
eldepryl
Some about medicine. Get now.
https://mexicanpharm.online/# buying prescription drugs in mexico
mostbet casino
https://1ecenter.ru
Medication information leaflet. Cautions.
bactrim
Some information about medication. Read now.
рамен бет
Pills information. Drug Class.
lisinopril
Best what you want to know about medicament. Get information now.
ומוכנות לפגישה ייחודית! כשמדובר בחיפוש אחר פינוק אולטימטיבי בשילוב מגע וחושניות, שום דבר לא יכול לנצח את החוויה עם . יפות חושנית ופינוק אולטימטיבי ותנו לקסם הלוהט להסיע אתכם למצב של אושר טהור. חשוב לציין כי שירותים של מתאימות גם לגברים בודדים וגם דירות דיסקרטיות באשקלון
вулкан платинум вход
Medicament prescribing information. Brand names.
where can i buy lisinopril
Best news about pills. Get information now.
מגוון אופציות לבחירה. בחר מודעות של משרדים ששולחים בחורות מאומנות ושומרים על סודיות הלקוח. קריאת ביקורות וחיפוש המלצות יכולים לכל אחד שמחפש חוויה הכי מפנקת! אמנות הפינוק האירוטי של נערות שמחכות לכם ב דורשת מיומנות, רגישות והבנה מעמיקה של האזורים דירות דיסקרטיות באשקלון
http://pharmacynoprescription.pro/# buying prescription medications online
рокс казино
Pills information sheet. Generic Name.
fluoxetine
Best news about meds. Get here.
Услуга демонтажа старых частных домов и вывоза мусора в Москве и Подмосковье от нашей компании. Мы предлагаем демонтаж и вывоз мусора в указанном регионе по доступным ценам. Наша команда https://hoteltramontano.ru гарантирует выполнение услуги в течение 24 часов после заказа. Мы бесплатно оцениваем объект и консультируем клиентов. Узнать подробности и рассчитать стоимость можно по телефону или на нашем сайте.
עם גירוי אירוטי ויוצר חוויה ייחודית החורגת מבילוי מסורתי. המטרה העיקרית של היא לעורר את החושים, לשחרר מתח ולקדם את הרווחה אינטימי איכותי משמש במשך מאות שנים לקידום רווחה פיזית ורגשית. גאות להציע אווירה בטוחה, נקייה ונעימה עבור לקוחותיהן. נערות הכי דירות דיסקרטיות בבאר שבע
Drug information leaflet. Drug Class.
cipro
Everything trends of medicine. Get information here.
dalycitynewspaper.com
Medicines prescribing information. What side effects can this medication cause?
aurogra pills
All what you want to know about meds. Read information now.
גברים רבים מוצאים את עצמם המומים ועמוסים בלחצים של חיי היומיום הקשים ובלתי צפויים. מציעות הפוגה מגורמי לחץ אלה ומאפשרות לכם והבטיחות של הנערות והן של הלקוח. בחורות ישראליות, אתיופיות, אירופאיום וכמובן גם רוסיות בכל הגילאים עוזרות לעורר את האנרגיות דירות דיסקרטיות בבאר שבע
הלקוח ומספקות שירות מותאם אישית המבוסס על העדפות ורצונות אישיים של כל אחד. מזמינות אותך עכשיו לביקור כדי לבנות אנרגיה מינית שלך וקבלו פרטים על השירות הכי לוהט של ובכל אזור הדרום. להפגת מתחים בעת הזמנת ביקור אינטימי פרטי אצל נערות יפיפיות של חיוני לתקשר דירות דיסקרטיות בתל אביב
Meds information sheet. Short-Term Effects.
pregabalin sale
Actual trends of medicines. Read information now.
https://canadianpharm.guru/# canadian 24 hour pharmacy
Medication information. Short-Term Effects.
can i get silagra
Some trends of medicines. Read information now.
волчонок смотреть в качестве HD
https://mexicanpharm.online/# mexico pharmacies prescription drugs
https://na-dache.pro
גבולות אינטימיים ספציפיים שיש לך. מידע זה מסייע להתאים את הפגישה לצרכים האישיים ולהבטיח לך חוויה נוחה ומהנה, לשחרר את הציפיות ואירופאיות. מדור מתאים לכם במאה אחוז, היכנסו ותראו בעצמכם. לאספקת הנאה בעוד שהשירות אינטימי של קשור לעיתים קרובות למפגשים דירות דיסקרטיות בתל אביב
1win казино
http://klubmama.ru
Meds information. What side effects?
deltasone
Best information about medicament. Get information now.
hoki 1881
פרטיות המציעות לגברים חוויות מיוחדות, ייחודיות והכי אינטימיות. ביקור במקומות כמו זה תמיד פינוק הכי לוהט ואיכותי לכל טעם וכיס. אנדורפינים מפגש איכותי עם צעירות הסקסיות ביותר של מתחיל בדרך כלל בהתייעצות קצרה בטלפון. במהלך השיחה שואלים אותך על העדיפויות או דירות דיסקרטיות בתל אביב
Мы предлагаем на выбор разный номинал и наполнение сертификатов. Это может быть катание как отдельно на снегоходе и квадроцикле, так и обе активности вместе. Количество техники, длительность проката и стоимость сертификата не ограничены москва покататься на квадроциклах
https://hoteltramontano.ru/
Medicament information for patients. Cautions.
cialis generic
Some news about drug. Read information now.
1win casino
Доставка алкоголя
italy-cars.com
https://indianpharm.shop/# indian pharmacy
купить диплом инженера
услуги seo https://www.prodvizhenie-sajtov15.ru .
купить диплом колледжа
Купить диплом гознак – Это получить официальный удостоверение о среднем образовании. Диплом гарантирует вход в обширному спектру профессиональных и учебных возможностей.
купить диплом техникума
https://canadianpharm.guru/# canadian pharmacy ratings
купить сертификат специалиста
https://adzan.online/
купить диплом с реестром
Medication information leaflet. What side effects?
cleocin otc
Some information about meds. Get information here.
Дизайнерские радиаторы отопления. Представить современный дом без радиатора очень трудно, особенно в осенний и зимний сезон, когда так хочется тепла и уюта https://radiators-teplo.github.io/
купить диплом в тольятти
http://indianpharm.shop/# world pharmacy india
Сервис онлайн заказа классической и широкоформатной фотопечати на фотобумаге, холсте, акварельной и плакатной бумаге, печать фотографий быстрая печать фото
раскрутка сайтов в москве
https://adzan.online/
заказать SEO продвижение
https://adzan.online/
crypto pump signals
crypto signals Binance
http://pharmacynoprescription.pro/# legitimate online pharmacy no prescription
Лучшие картинки различных тематик https://stilno.site
механизированная цементная штукатурка http://www.mekhanizirovannaya-shtukaturka11.ru/ .
https://www.google.am/url?q=https://mining-pro.biz/
Изготовление стильных фотокниг недорого. Быстрая и качественная печать фотобуков на заказ. Создавайте фотоальбомы онлайн с помощью простого и бесплатного фоторедактора [url=https://foto-san.ru/]оформить фотокнигу[/url]
fast pay casino
Даркнет маркет
Существование теневых электронных базаров – это феномен, который порождает большой интерес а разговоры во настоящем мире. Подпольная часть веба, или подпольная область всемирной сети, представляет собой тайную платформу, доступной исключительно при помощи особые программы или конфигурации, обеспечивающие скрытность участников. В данной данной скрытой сети находятся подпольные рынки – онлайн-платформы, где-нибудь продажи разные товары а услуговые предложения, в большинстве случаев противоправного специфики.
По подпольных рынках легко обнаружить различные вещи: психоактивные препараты, вооружение, похищенная информация, снаружи подвергнутые атаке учетные записи, фальшивки или и многое многое другое. Такие же маркеты иногда притягивают внимание также криминальных элементов, а также стандартных субъектов, намеревающихся обойти юриспруденция или доступить к товарам и послугам, те на стандартном интернете были бы в недоступны.
Впрочем нужно помнить, чем деятельность в подпольных рынках представляет собой незаконный характер или в состоянии повлечь за собой важные юридические нормы наказания. Правоохранительные органы усердно борются за против подобными площадками, но все же из-за скрытности подпольной области это условие не всегда просто.
Следовательно, присутствие подпольных онлайн-рынков составляет действительностью, но все же таковые пребывают сферой серьезных рисков как для таких, так и для участников, и для таких общественности во в целом и целом.
best slots
http://mexicanpharm.online/# mexican pharmacy
Тор программа – это специальный интернет-браузер, который рассчитан для обеспечения конфиденциальности и устойчивости в интернете. Он построен на инфраструктуре Тор (The Onion Router), позволяющая участникам обмениваться данными с использованием распределенную сеть серверов, что превращает сложным отслеживание их поступков и выявление их местоположения.
Главная характеристика Тор браузера заключается в его способности перенаправлять интернет-трафик посредством несколько узлов сети Тор, каждый из них зашифровывает информацию перед отправкой следующему узлу. Это создает множество слоев (поэтому и название “луковая маршрутизация” – “The Onion Router”), что создает почти невозможным отслеживание и определение пользователей.
Тор браузер часто используется для преодоления цензуры в территориях, где запрещен доступ к определенным веб-сайтам и сервисам. Он также дает возможность пользователям обеспечить конфиденциальность своих онлайн-действий, таких как просмотр веб-сайтов, общение в чатах и отправка электронной почты, избегая отслеживания и мониторинга со стороны интернет-провайдеров, правительственных агентств и киберпреступников.
Однако стоит учитывать, что Тор браузер не обеспечивает полной анонимности и безопасности, и его выпользование может быть связано с опасностью доступа к противозаконным контенту или деятельности. Также возможно замедление скорости интернет-соединения из-за
даркнет площадки
Темные площадки, а также подпольные рынки, есть онлайн-платформы, доступные только исключительно с помощью скрытую часть интернета – всемирную сеть, недоступная для рядовых поисковых систем. Данные рынки допускают пользователям торговать разными товарными пунктами а послугами, чаще всего незаконного степени, такие как наркотики, стрелковое оружие, данные, похищенные из систем, подделки а прочие запретные или же незаконные продукты а послуги.
Темные площадки снабжают анонимность их пользователей по использования соответствующих программ или параметров, например Tor, те скрывают IP-адреса или маршрутизируют интернет-трафик через разные узловые точки, что делает трудным отслеживание активности органами правопорядка.
Таковые торговые площадки часто попадают целью внимания полицейских, которые борются за против ними в рамках борьбе против киберпреступностью и неправомерной продажей.
online slot website
Тор скрытая сеть – это часть интернета, какая, которая работает над стандартнои? сети, однако не доступна для прямого входа через обычные браузеры, например Google Chrome или Mozilla Firefox. Для выхода к этому сети нуждается эксклюзивное программное обеспечение, например, Tor Browser, которыи? обеспечивает скрытность и защиту пользователеи?.
Основнои? принцип работы Тор даркнета основан на использовании маршрутизации через разнообразные узлы, которые криптуют и двигают трафик, создавая сложным слежение его источника. Это создает секретность для пользователеи?, укрывая их реальные IP-адреса и местоположение.
Тор даркнет содержит разные источники, включая веб-саи?ты, форумы, рынки, блоги и другие онлаи?н-ресурсы. Некоторые из таких ресурсов могут быть не доступны или запрещены в стандартнои? сети, что создает Тор даркнет площадкои? для трейдинга информациеи? и услугами, включая продукты и услуги, которые могут быть противозаконными.
Хотя Тор даркнет выпользуется некоторыми людьми для обхода цензуры или защиты индивидуальности, он также становится платформои? для разнообразных нелегальных деи?ствии?, таких как торговля наркотиками, оружием, кража личных данных, подача услуг хакеров и прочие преступные деи?ствия.
Важно понимать, что использование Тор даркнета не обязательно законно и может иметь в себя серьезные угрозы для защиты и законности.
online casino
садовая тротуарная плитка
hoki 1881
https://canadianpharm.guru/# pharmacy canadian
livechinanews.com
России, вроде и в других странах, даркнет является собой часть интернета, недоступенную для регулярного поискавания и просмотра через обычные навигаторы. В разница от общедоступной плоской сети, теневая сеть считается скрытым куском интернета, выход к чему регулярно проводится через эксклюзивные приложения, такие как Tor Browser, и анонимные сети, такие как Tor.
В теневой сети сгруппированы различные источники, включая форумы, рынки, журналы и остальные интернет-ресурсы, которые могут стать неприступны или пресечены в регулярной коммуникации. Здесь возможно найти различные товары и услуги, включая незаконные, например наркотические препараты, оружие, вскрытые сведения, а также послуги взломщиков и остальные.
В России скрытая часть интернета так же используется для пересечения цензуры и мониторинга со партии. Некоторые клиенты могут выпользовать его для трансфера информацией в обстоятельствах, когда автономия слова замкнута или информационные источники подвергаются цензуре. Однако, также следует отметить, что в даркнете присутствует много не Законной работы и опасных ситуаций, включая мошенничество и компьютерные преступления
chicago-job.com
can i purchase co-amoxiclav tablets
Заказать диссертацию онлайн. Комплексная поддержка соискателей по подготовке НИР любой сложности под ключ. Выполнение – в сумме за 120 дней по гуманитарным дисциплинам, и в сумме 150-180 дней по техническим дисциплинам заказать чертеж
Уникальные фото различных тематик https://pro-dachnikov.com
Регистрация в букмекерской конторе BetBoom открывает перед вами увлекательный мир спортивных ставок и возможность заработка на удаче и знании спорта. Процесс регистрации на официальном сайте BetBoom прост и удобен: вам нужно заполнить всего несколько обязательных полей, подтвердить свои данные и выбрать удобный способ пополнения счета. Подробная инструкция – https://t.me/s/registraciya_betboom_ru
купить диплом колледжа
http://canadianpharm.guru/# canadianpharmacymeds com
https://hello.softonic.com/wp-content/pgs/?the-thrill-behind-counter-strike-skin-gambling.html
Регистрация в букмекерской конторе BetBoom открывает перед вами увлекательный мир спортивных ставок и возможность заработка на удаче и знании спорта. Процесс регистрации на официальном сайте BetBoom прост и удобен: вам нужно заполнить всего несколько обязательных полей, подтвердить свои данные и выбрать удобный способ пополнения счета. Подробная инструкция – https://t.me/s/registraciya_betboom_ru
Hype казино зеркало
http://pharmacynoprescription.pro/# non prescription online pharmacy
generic inderal prices
доставка букетов цветов саратов https://flowerssaratov.ru .
generic macrobid no prescription
купить мухомор в москве
fashionflag full hd sex download fashionflag.oN4hhIKTytC
Medication information sheet. Drug Class.
fluoxetine
Everything news about drug. Read here.
Ремонт стиральных машин в СПб
aviator oyna 100 tl: aviator hilesi – aviator oyunu 100 tl
Даркнет заказать
Наличие подпольных онлайн-рынков – это явление, что привлекает громадный внимание или обсуждения во настоящем обществе. Даркнет, или глубокая зона сети, представляет собой скрытую инфраструктуру, доступных только через особые приложения а настройки, обеспечивающие инкогнито участников. На этой данной приватной платформе лежат теневые электронные базары – онлайн-платформы, где бы торгуются разные продукты или послуги, в большинстве случаев противозаконного степени.
По даркнет-маркетах можно найти самые разные вещи: наркотики, вооружение, украденные данные, уязвимые аккаунты, фальшивые документы или и многое многое другое. Такие площадки время от времени магнетизирузивают восторг также преступников, и рядовых субъектов, намеревающихся обходить стороной юриспруденция либо получить возможность доступа к товарам или услугам, какие на нормальном вебе были бы недосягаемы.
Впрочем нужно помнить, чем работа по теневых электронных базарах представляет собой противозаконный специфику и может создать серьезные правовые наказания. Полицейские органы энергично сопротивляются против таковыми рынками, но вследствие анонимности темной стороны интернета данный факт не все время просто так.
Таким образом, существование даркнет-маркетов составляет действительностью, однако таковые пребывают сферой значительных угроз как для субъектов, так и для подобных сообщества в общем.
Ремонт стиральных машин СПб
https://muslim-prayer-times.com/
Medicine information leaflet. Drug Class.
stromectol
Some trends of medicament. Get information here.
osteklenie-balkonov174.ru
Ремонт стиральных машин в СПб
Drug prescribing information. Brand names.
lasix
Everything news about pills. Get information now.
Medication prescribing information. Brand names.
synthroid
All information about medicines. Read information now.
sweet bonanza yorumlar: sweet bonanza slot demo – sweet bonanza 100 tl
Pills information leaflet. Drug Class.
rx cleocin
Everything news about drugs. Read information now.
where can i buy cheap omnicefs prices
travelusanews.com
Drug information sheet. Generic Name.
prasugrel
All what you want to know about medicines. Get here.
colchicine tablets
https://muslim-prayer-times.com/
hoki1881
даркнет покупки
Покупки в Даркнете: Иллюзии и Реальность
Скрытая часть веба, таинственная часть интернета, заинтересовывает внимание пользователей своей скрытностью и способностью купить самые разнообразные вещи и услуги без дополнительной информации. Однако, переход в этот мир непрозрачных площадок связано с комплексом рисков и аспектов, о чём необходимо осведомляться перед совершением сделок.
Что представляет собой скрытая часть веба и как он работает?
Для тех, кому незнакомо с этим понятием, скрытая часть веба – это сектор интернета, невидимая от обычных поисков. В подпольной сети существуют уникальные онлайн-рынки, где можно найти возможность почти все виды : от препаратов и стрелкового оружия и поддельных удостоверений и взломанных аккаунтов.
Заблуждения о приобретении товаров в темном интернете
Тайность защищена: В то время как, использование методов скрытия личности, таких как Tor, способно помочь скрыть свою действия в сети, тайность в подпольной сети не является абсолютной. Существует риск, что возможно вашу информацию о вас могут раскрыть мошенники или даже сотрудники правоохранительных органов.
Все товары – высокого качества: В Даркнете можно найти множество продавцов, предоставляющих продукты и сервисы. Однако, нельзя обеспечить качественность или подлинность товара, так как нельзя провести проверку до того, как вы сделаете заказ.
Легальные покупки без ответственности: Многие участники ошибочно считают, что заказывая товары в темном интернете, они рискуют меньшим риском, чем в обычной жизни. Однако, приобретая незаконные товары или сервисы, вы подвергаете себя привлечения к уголовной ответственности.
Реальность покупок в темном интернете
Опасности мошенничества и афер: В темном интернете много мошенников, предрасположены к мошенничеству невнимательных клиентов. Они могут предложить поддельную продукцию или просто забрать ваши деньги и исчезнуть.
Опасность правоохранительных органов: Пользователи скрытой части веба рискуют попасть привлечения к уголовной ответственности за покупку и заказ неправомерных продуктов и услуг.
Непредвиденность исходов: Не все покупки в подпольной сети заканчиваются удачно. Качество товаров может оставлять желать лучшего, а
процесс заказа может послужить источником неприятностей.
Советы для безопасных транзакций в Даркнете
Проводите детальный анализ продавца и товара перед осуществлением заказа.
Используйте безопасные программы и сервисы для защиты вашей анонимности и безопасности.
Используйте только безопасные способы оплаты, например, криптовалютами, и не раскрывайте личные данные.
Будьте осторожны и предельно внимательны во всех совершаемых действиях и выбранных вариантах.
Заключение
Транзакции в подпольной сети могут быть как интересным, так и опасным путешествием. Понимание рисков и применение соответствующих мер предосторожности помогут снизить вероятность негативных последствий и гарантировать безопасные покупки в этой недоступной области сети.
buying prednisone for sale
Drugs prescribing information. What side effects can this medication cause?
lyrica
All about medication. Get now.
даркнет запрещён
Покупки в скрытой части веба: Мифы и Факты
Темный интернет, загадочная область сети, манит внимание участников своим анонимностью и способностью приобрести самые разнообразные продукты и услуги без дополнительной информации. Однако, погружение в этот мир скрытых торгов сопряжено с набором рисков и нюансов, о чём следует знать перед проведением покупок.
Что такое Даркнет и как оно действует?
Для того, кому не знакомо с термином, темный интернет – это часть интернета, невидимая от стандартных поисковиков. В скрытой части веба существуют специальные рынки, где можно найти возможность практически все, что угодно : от запрещённых веществ и боеприпасов и перехваченных учётных записей и поддельных документов.
Мифы о приобретении товаров в Даркнете
Скрытность гарантирована: Хотя, применение технологий анонимности, например Tor, может помочь скрыть от глаз свою активность в сети, тайность в Даркнете не является полной. Существует возможность, что возможно ваша личные данные могут обнаружить обманщики или даже сотрудники правоохранительных органов.
Все товары – качественные товары: В скрытой части веба можно найти множество поставщиков, предлагающих товары и услуги. Однако, нельзя гарантировать качественность или подлинность товаров, так как нельзя провести проверку до совершения покупки.
Легальные сделки без последствий: Многие пользователи по ошибке считают, что приобретая товары в темном интернете, они рискуют меньшим риском, чем в реальной жизни. Однако, приобретая запрещенные продукцию или сервисы, вы рискуете наказания.
Реальность приобретений в темном интернете
Негативные стороны обмана и мошенничества: В темном интернете много мошенников, которые готовы обмануть невнимательных клиентов. Они могут предложить поддельные товары или просто исчезнуть с вашими деньгами.
Опасность государственных органов: Пользователи подпольной сети подвергают себя риску привлечения к уголовной ответственности за покупку и заказ неправомерных продуктов и услуг.
Непредсказуемость исходов: Не каждый заказ в скрытой части веба приводят к успешному результату. Качество продукции может оказаться низким, а сам процесс приобретения может оказаться проблематичным.
Советы для безопасных транзакций в скрытой части веба
Проведите полное изучение продавца и товара перед приобретением.
Воспользуйтесь защитными программами и сервисами для обеспечения анонимности и безопасности.
Платите только безопасными методами, например, криптовалютами, и не раскрывайте личные данные.
Будьте предельно внимательны и осторожны во всех ваших действиях и решениях.
Заключение
Покупки в подпольной сети могут быть как увлекательным, так и опасным путешествием. Понимание возможных опасностей и принятие необходимых мер предосторожности помогут уменьшить риск негативных последствий и обеспечить безопасность при совершении покупок в этом неизведанном мире интернета.
aviator bahis: aviator oyna 20 tl – aviator oyna slot
how to get generic mobic tablets
https://muslim-prayer-times.com/
Medicine information leaflet. Effects of Drug Abuse.
norvasc
Best what you want to know about drug. Get information now.
prograf walgreens
Medicine information for patients. What side effects?
cytotec
Some about medicine. Get now.
order cheap cordarone without a prescription
Pills information for patients. Effects of Drug Abuse.
cetirizine sale
All information about medicament. Read information now.
sweet bonanza 100 tl: sweet bonanza oyna – sweet bonanza demo oyna
can you get cheap prednisolone prices
Medication information sheet. Short-Term Effects.
paxil
Some information about medicine. Get information here.
order cheap cefixime online
1. Вибір натяжних стель – як правильно обрати?
2. Топ-5 популярних кольорів натяжних стель
3. Як зберегти чистоту натяжних стель?
4. Відгуки про натяжні стелі: плюси та мінуси
5. Як підібрати дизайн натяжних стель до інтер’єру?
6. Інноваційні технології у виробництві натяжних стель
7. Натяжні стелі з фотопечаттю – оригінальне рішення для кухні
8. Секрети вдалого монтажу натяжних стель
9. Як зекономити на встановленні натяжних стель?
10. Лампи для натяжних стель: які вибрати?
11. Відтінки синього для натяжних стель – ексклюзивний вибір
12. Якість матеріалів для натяжних стель: що обирати?
13. Крок за кроком: як самостійно встановити натяжні стелі
14. Натяжні стелі в дитячу кімнату: безпека та креативність
15. Як підтримувати тепло у приміщенні за допомогою натяжних стель
16. Вибір натяжних стель у ванну кімнату: практичні поради
17. Натяжні стелі зі структурним покриттям – тренд сучасного дизайну
18. Індивідуальність у кожному домашньому інтер’єрі: натяжні стелі з друком
19. Як обрати освітлення для натяжних стель: поради фахівця
20. Можливості дизайну натяжних стель: від класики до мінімалізму
дворівнева натяжна стеля https://www.natjazhnistelitvhyn.kiev.ua/ .
Medicines information leaflet. What side effects?
cialis super active
Everything about drug. Read here.
1. Вибір натяжних стель – як правильно обрати?
2. Топ-5 популярних кольорів натяжних стель
3. Як зберегти чистоту натяжних стель?
4. Відгуки про натяжні стелі: плюси та мінуси
5. Як підібрати дизайн натяжних стель до інтер’єру?
6. Інноваційні технології у виробництві натяжних стель
7. Натяжні стелі з фотопечаттю – оригінальне рішення для кухні
8. Секрети вдалого монтажу натяжних стель
9. Як зекономити на встановленні натяжних стель?
10. Лампи для натяжних стель: які вибрати?
11. Відтінки синього для натяжних стель – ексклюзивний вибір
12. Якість матеріалів для натяжних стель: що обирати?
13. Крок за кроком: як самостійно встановити натяжні стелі
14. Натяжні стелі в дитячу кімнату: безпека та креативність
15. Як підтримувати тепло у приміщенні за допомогою натяжних стель
16. Вибір натяжних стель у ванну кімнату: практичні поради
17. Натяжні стелі зі структурним покриттям – тренд сучасного дизайну
18. Індивідуальність у кожному домашньому інтер’єрі: натяжні стелі з друком
19. Як обрати освітлення для натяжних стель: поради фахівця
20. Можливості дизайну натяжних стель: від класики до мінімалізму
дворівневі натяжні стелі ціна http://www.natjazhnistelitvhyn.kiev.ua .
http://popmarket.ru/ww/pages/obzor_na_bezdepozitnue_bonusu_kazino__novinki_2023_goda.html
gates of olympus oyna: gates of olympus demo free spin – gates of olympus oyna ucretsiz
https://dzen.ru/a/Za5ap2Eu_EHIFT6P
Бизнесмен Андрей Кнауб хорошо известен как предприниматель и трейдер в сфере нефтепереработки. Он более 25 лет был частью крупнейших отраслевых компаний, реализовал множество благотворительных и социальных проектов кнауб андрей артурович
Подпольная часть сети: запрещённое пространство компьютерной сети
Темный интернет, скрытый сегмент сети продолжает привлекать внимание интерес и общественности, и также служб безопасности. Этот подпольный слой интернета известен своей анонимностью и возможностью проведения незаконных операций под маской анонимности.
Основа темного интернета сводится к тому, что он не доступен обычным обычных браузеров. Для доступа к нему необходимы специальные инструменты и программы, обеспечивающие скрытность пользователей. Это формирует отличную площадку для различных незаконных действий, включая торговлю наркотическими веществами, оружием, кражу личных данных и другие незаконные манипуляции.
В ответ на растущую опасность, многие страны ввели законодательные меры, целью которых является запрещение доступа к темному интернету и преследование лиц осуществляющих незаконную деятельность в этом скрытом мире. Тем не менее, несмотря на предпринятые шаги, борьба с подпольной частью сети остается сложной задачей.
Важно отметить, что полное запрещение теневого уровня интернета практически невыполнима. Даже с введением строгих мер контроля, возможность доступа к этому слою интернета все еще осуществим с использованием разнообразных технических средств и инструментов, применяемые для обхода ограничений.
В дополнение к законодательным инициативам, имеются также совместные инициативы между правоохранительными структурами и технологическими компаниями для борьбы с преступностью в темном интернете. Однако, для успешной борьбы требуется не только техническая сторона, но также улучшения методов выявления и предотвращения противозаконных манипуляций в данной среде.
Таким образом, несмотря на введенные запреты и предпринятые усилия в борьбе с преступностью, подпольная часть сети остается серьезной проблемой, которая требует комплексного подхода и совместных усилий как со стороны правоохранительных органов, а также технологических организаций.
gates of olympus nas?l para kazanilir: gates of olympus demo free spin – gates of olympus oyna ucretsiz
ucak oyunu bahis aviator: ucak oyunu bahis aviator – aviator hilesi ucretsiz
elementor
elementor
sweet bonanza demo oyna: sweet bonanza giris – sweet bonanza yorumlar
http://slotsiteleri.guru/# deneme bonusu veren slot siteleri
Предприниматель придерживался мнения, что заботиться надо не только о персонале, но и окружающей среде кнауб андрей нпз томскнефтепереработка
vavada
покер онлайн
В биографии бизнесмена Андрея Артуровича Кнауба важно отметить, что для него ключевое значение имела забота о персонале и экологической обстановке в регионе кнауб андрей биография
aviator oyna: aviator oyna 100 tl – aviator giris
http://pinupgiris.fun/# pin up güncel giris
мостбет
getusainvest.com
http://slotsiteleri.guru/# yasal slot siteleri
Egor Alexandrovich Abramov’s personal life remains guarded, allowing his work to speak volumes about his dedication to the craft egor abramov entrepreneur
slot siteleri 2024: deneme bonusu veren siteler – en cok kazandiran slot siteleri
https://gatesofolympus.auction/# gates of olympus hilesi
pin-up casino giris: pin up – pin up aviator
Egor Abramov’s biography, initiated by chance, has evolved into a promising career, and as he continues to make his mark in the cinematic landscape, audiences can anticipate more captivating performances from this talented young actor egor alexandrovich abramov
https://cartagena-colombia-travel.activeboard.com/t70253044/ufa345s-winning-play-strategies-for-football-betting/?page=last#lastPostAnchor
मिशनरी स्टाइल के अश्लीलता के बारे में बतावल गइल बा hjkvbasdfzxzz.cFg1CkRsFPC
Читайте статью на vc.ru как продать ноткоин как продать Ноткоины сегодня по отличной цене. Если вы хотите продать Ноткоин, нажимаете кнопку “Создать ордер” – “Продать” – выбираете цену и количество – нажимаете продать.
Курсы сметного дела в строительстве, предлагаемые на сайте maps-edu.ru, являются важным инструментом для специалистов, стремящихся к глубокому освоению принципов и методик составления смет в строительстве. Программа обучения охватывает все ключевые аспекты сметного дела, включая изучение нормативной базы, методов расчета стоимости строительных работ, материалов и оборудования. Особое внимание уделяется современным программным обеспечениям для сметчиков, что позволяет выпускникам курса быть конкурентоспособными на рынке труда и востребованными в строительной отрасли.
Повышайте квалификацию: курсы для учителей начальных классов дистанционно развивайтесь профессионально!
http://cleandi.ru/
https://ficbook.net/authors/018e145f-8740-7a3b-a847-a889b82fbe6b
https://sporty24.site
https://acook.space/
Despite his youth, Egor Abramov has already earned critical acclaim and popularity among viewers. His growth as an actor portends a bright future and opens up new opportunities in Russian cinema egor alexandrovich abramov
Наш путеводитель по Санкт-Петербургу собрал лучшие отели и места для туристов рестораны СПб Мы расскажем, в каких кафе можно бюджетно перекусить, где попробовать особенные блюда с местным колоритом или отужинать, как потомки аристократов.
уборка клининг
canadian online pharmacy reviews: canada pharmacy reviews – legal to buy prescription drugs from canada
http://cleandi.ru/
Drugs information. Short-Term Effects.
stromectol
All what you want to know about drugs. Get information now.
https://mhpereezd.ru
Периодическая аккредитация врачей – это процесс, направленный на подтверждение и обновление профессиональных компетенций медицинских специалистов. Этот процесс помогает гарантировать, что врачи остаются в курсе последних медицинских знаний и практик, обеспечивая высокий уровень оказываемой медицинской помощи.
Обновите свои знания: курсы повышения квалификации для педагогов и налоговый юрист обучение .
mexican drugstore online: Mexican Pharmacy Online – mexican pharmaceuticals online
Medicines information sheet. What side effects?
priligy generics
Best news about drug. Read here.
Российский завод предлагает оборудование для фитнеса https://oborudovanie-dlya-fitnesa.ru по приятным ценам, без добавочных накруток. Всегда в продажезначительный каталог для постоянных клиентов. Предоставляем многофункциональные станки и аксессуары, которые помогут вам улучшить ваше здоровье и физическую форму.
В производстве мягких участков применяется винилискожа. Станины производятся из высокопрочных видов стали. Качественные и функциональные снаряды позволяют продуктивно заниматься фитнесом как в квартире, так и тренажерном зале. Производимое оборудование отличается отличным качеством и надежностью, что позволяет вам тренироваться безопасно и удобно. Для домашних тренировок отлично подойдут петли TRX, цельные гантельки, полусферы, короткие штанги, кольца для пилатеса, массажеры, хула-хупы, коврики для йоги, медболы.
Drugs information for patients. Effects of Drug Abuse.
get synthroid
Everything trends of medicament. Read information here.
Отечественный производитель продает спортивные тренажеры https://sportivnyj-trenazher.ru/ для напряженной работы в коммерческих условиях. В интернет-магазине вы оцените самые лучшие варианты тренажеров – блочных и на свободных весах. Объемный ассортимент дает возможность найти машины для акцентированной проработки теоретически любых мышц. Рассмотрите Кроссовер, Баттерфляй для грудных, станок Смита, вертикальную тягу, парту Скотта, Дельта машину, жим ногами, Пресс машину 3 в 1, Гравитрон, обратную гиперэкстензию, скамьи для жима со стойками, горизонтальную лавку, рычажные Хаммеры. Создаваемое оборудование не требует регулярного специального наблюдения. Можете выбрать весовой стек нужного веса.
https://treningi-i-kursy.com/
Medicament information leaflet. Drug Class.
avodart
Actual about drug. Get information now.
Drugs prescribing information. Generic Name.
cytotec
Best trends of meds. Get information now.
Medication information sheet. Long-Term Effects.
trazodone
Some what you want to know about drug. Get information now.
Отечественный производитель реализует оборудование для фитнеса oborudovanie-dlya-fitnesa ru по низким ценам, без добавочных накруток. Всегда в реализациизначительный ассортимент для постоянных клиентов. Реализуем доступные тренажеры и аксессуары, которые помогут вам улучшить ваше здоровье и физическую форму.
В создании мягких участков применяется искусственная кожа. Ключевые элементы конструкции сделаны из легированных видов стали. Доступные снаряды дают возможность продуктивно заниматься фитнесом как дома, так и тренажерном центре. Производимое оборудование отличается лучшим качеством и надежностью, что позволяет вам тренироваться продуктивно и эффективно. Для домашних тренировок прекрасно подойдут эспандеры, виниловые гантели, степ платформы, штанги, платформы босу, массажные ролы, диски для балансировки, коврики для йоги, утяжелители.
Egor, along with central actors, explores more mature themes in the latest season, depicting the evolving challenges faced by their characters egor abramov biography
Отечественный изготовитель продает оборудование для фитнеса https://oborudovanie-dlya-fitnesa.ru/ по доступным ценам, без посреднических наценок. Всегда в реализациизначительный объем для оптовых покупателей. Предоставляем многофункциональные машины и аксессуары, которые помогут вам улучшить ваше здоровье и физическую форму.
В создании мягких частей применяется винилискожа. Ключевые элементы конструкции производятся из высокопрочных видов стали. Функциональные продукты дают возможность продуктивно заниматься фитнесом как дома, так и спортивном зале. Выпускаемое оборудование отличается высоким качеством и надежностью, что позволяет вам тренироваться продуктивно и эффективно. Для домашних тренировок будут актуальны петли TRX, разборные гантели, степ платформы, штанги, кольца для пилатеса, массажные ролы, диски для баланса, скакалки, медболы.
https://mhpereezd.ru/
Отечественный производитель продает спортивные тренажеры sportivnyj-trenazher ru для усиленной работы в коммерческих условиях. В интернет-магазине вы найдете самые известные модели устройств – блочных и на свободных весах. Обширный каталог дает возможность подобрать станки для акцентированной укрепления практически любых мышечных отделов. Рассмотрите Кроссовер для перекрестной тяги, Баттерфляй, силовую раму Смита, горизонтальную тягу, скамью Скотта, Дельта машину, станок Гаккеншмидта, Пресс машину 3 в 1, Гравитрон для подтягиваний, обратную гиперэкстензию, атлетические скамьи, горизонтальную лавку, рычажные Хаммеры. Изготавливаемое оборудование не требует регулярного технического обслуживания. Можете заказать весовой стек необходимого веса.
Medicines information leaflet. Drug Class.
zenegra cost
Some information about medicament. Read information now.
Российский завод продает спортивные тренажеры https://sportivnyj-trenazher.ru/ для напряженной эксплуатации в коммерческих условиях. В каталоге вы найдете самые известные модели устройств – блочных и нагружаемых. Обширный каталог дает возможность найти тренажеры для акцентированной проработки теоретически любых мышц. Рассмотрите Кроссовер для перекрестной тяги, Баттерфляй, силовую раму Смита, вертикальную тягу, тренажер Скотта, тренажер для плечей, Гакк тренажер, Пресс машину 3 в 1, Гравитрон, гиперэкстензию, скамьи для жима со стойками, универсальную лавку, рычажные Хаммеры. Создаваемое оборудование не требует регулярного специального наблюдения. Можете купить весовой блок подходящего веса.
Medicament information sheet. What side effects?
cost nolvadex
Best trends of medicines. Read here.
https://gruzchikov19.ru/
https://globalcatalog.com/chile07es.es
Темный интернет: запретная территория интернета
Теневой уровень интернета, скрытый сегмент сети продолжает вызывать интерес внимание как общественности, так и правоохранительных структур. Данный засекреченный уровень интернета известен своей анонимностью и способностью осуществления незаконных операций под тенью анонимности.
Сущность подпольной части сети заключается в том, что этот слой не доступен обычным браузеров. Для доступа к данному слою требуются специальные инструменты и программы, которые обеспечивают анонимность пользователей. Это формирует отличную площадку для разнообразных противозаконных операций, в том числе торговлю наркотическими веществами, торговлю огнестрельным оружием, хищение персональной информации и другие незаконные манипуляции.
В ответ на растущую угрозу, ряд стран приняли законы, целью которых является запрещение доступа к темному интернету и преследование лиц совершающих противозаконные действия в этой скрытой среде. Впрочем, несмотря на принятые меры, борьба с теневым уровнем интернета представляет собой сложную задачу.
Важно отметить, что полное прекращение доступа к темному интернету практически невозможно. Даже с введением строгих мер контроля, доступ к этому уровню интернета все еще доступен с использованием разнообразных технических средств и инструментов, применяемые для обхода запретов.
Помимо законодательных мер, имеются также проекты сотрудничества между правоохранительными органами и технологическими компаниями для борьбы с преступностью в темном интернете. Однако, эта борьба требует не только технических решений, но также улучшения методов выявления и предотвращения противозаконных манипуляций в данной среде.
В заключение, несмотря на запреты и усилия в борьбе с незаконными деяниями, теневой уровень интернета остается серьезной проблемой, требующей комплексного подхода и совместных усилий со стороны правоохранительных структур, и технологических корпораций.
Medicines prescribing information. What side effects can this medication cause?
zoloft
Some information about meds. Get now.
Medicine information for patients. Long-Term Effects.
atorvastatin
Everything about medicine. Get information now.
किशोर अश्लीलता txechdyzxca.1yK6NcYlh10
Medicines information for patients. What side effects?
pregabalin buy
Best information about drug. Get now.
https://getsocialsource.com/story2228321/olasnh
http://zolpet.bezschool2.minobr63.ru/wp-content/pgs/onlayn_kazino_s_bezdepozitnum_bonusom__obzor_predlozgheniy_2023_goda.html
Pills information sheet. Generic Name.
stromectol online
All about medicament. Get information now.
https://www.offroadmaster.com/public/articles/?1hslots_casino___azart_i_udacha_v_kazghdom_vrashenii.html
топ аналитика маркетплейсов
http://www.medtronik.ru/images/pages/1xslots___vashi_luchshie_shansu_na_udachu.html
In both 2014 and 2015 Alexandre Cougnaud raced in the Porsche Carrera Cup France championship. He finished in 10th position the first year and in 12th position the second year https://www.autosport.com/driver/alexandre-cougnaud/864140/photo-galleries/
Кухни по индивидуальным размерам от Вита Кухни: идеальное сочетание стиля и функциональности
http://apr.kiro46.ru/wp-includes/pgs/vse_o_bezdepozitnuh_bonusah_v_kazino__kak_poluchit_i_ispolzovat.html
where to get cheap allopurinol no prescription
Drugs information sheet. Brand names.
order avodart
All trends of meds. Read now.
where buy generic nemasole without insurance
https://gruzchikibaza.ru/
https://www.autosport.com/driver/alexandre-cougnaud/864140/photo-galleries/?p=2
Drug information. Drug Class.
tegretol cheap
Everything about medicament. Read now.
lisinopril zestril 10 mg tablet
how can i get cheap imuran online
https://nl.motorsport.com/driver/alexandre-cougnaud/384850/
can i buy generic tizanidine pills
Drug prescribing information. Cautions.
retrovir tablet
Best news about drug. Read here.
where can i buy prednisone
Meds information for patients. Effects of Drug Abuse.
tadacip brand name
Some news about medicine. Get information here.
buy generic amaryl prices
where can i get finasteride pills
Medication information leaflet. Short-Term Effects.
doxycycline
Some what you want to know about pills. Read information here.
buy generic differin pill
Medicament information sheet. Brand names.
zoloft
Some news about drugs. Get here.
https://gruzchikikorob.ru
cheapest price for lisinopril
generic accupril for sale
Drug information sheet. Effects of Drug Abuse.
stromectol
All information about medicine. Read here.
can you get avodart tablets
1. Вибір натяжних стель: як вибрати ідеальний варіант?
2. Модні тренди натяжних стель на поточний сезон
3. Які переваги мають натяжні стелі порівняно зі звичайними?
4. Як підібрати кольори для натяжної стелі у квартирі?
5. Секрети догляду за натяжними стелями: що потрібно знати?
6. Як зробити вибір між матовими та глянцевими натяжними стелями?
7. Натяжні стелі в інтер’єрі: як вони змінюють приміщення?
8. Натяжні стелі для ванної кімнати: плюси та мінуси
9. Як підняти стеля візуально за допомогою натяжної конструкції?
10. Як вибрати правильний дизайн натяжної стелі для кухні?
11. Інноваційні технології виробництва натяжних стель: що варто знати?
12. Чому натяжні стелі вибирають для офісних приміщень?
13. Натяжні стелі з фотопринтом: які переваги цієї технології?
14. Дизайнерські рішення для натяжних стель: ідеї для втілення
15. Хімічні реагенти в складі натяжних стель: безпека та якість
16. Як вибрати натяжну стелю для дитячої кімнати: поради батькам
17. Які можливості для дизайну приміщень відкривають натяжні стелі?
18. Як впливає вибір матеріалу на якість натяжної стелі?
19. Інструкція з монтажу натяжних стель власноруч: крок за кроком
20. Натяжні стелі як елемент екстер’єру будівлі: переваги та недоліки
натяжні стелі львів відгуки http://www.natjazhnistelifvgtg.lviv.ua/ .
1. Вибір натяжних стель: як вибрати ідеальний варіант?
2. Модні тренди натяжних стель на поточний сезон
3. Які переваги мають натяжні стелі порівняно зі звичайними?
4. Як підібрати кольори для натяжної стелі у квартирі?
5. Секрети догляду за натяжними стелями: що потрібно знати?
6. Як зробити вибір між матовими та глянцевими натяжними стелями?
7. Натяжні стелі в інтер’єрі: як вони змінюють приміщення?
8. Натяжні стелі для ванної кімнати: плюси та мінуси
9. Як підняти стеля візуально за допомогою натяжної конструкції?
10. Як вибрати правильний дизайн натяжної стелі для кухні?
11. Інноваційні технології виробництва натяжних стель: що варто знати?
12. Чому натяжні стелі вибирають для офісних приміщень?
13. Натяжні стелі з фотопринтом: які переваги цієї технології?
14. Дизайнерські рішення для натяжних стель: ідеї для втілення
15. Хімічні реагенти в складі натяжних стель: безпека та якість
16. Як вибрати натяжну стелю для дитячої кімнати: поради батькам
17. Які можливості для дизайну приміщень відкривають натяжні стелі?
18. Як впливає вибір матеріалу на якість натяжної стелі?
19. Інструкція з монтажу натяжних стель власноруч: крок за кроком
20. Натяжні стелі як елемент екстер’єру будівлі: переваги та недоліки
натяжних стель https://www.natjazhnistelifvgtg.lviv.ua/ .
Pills information sheet. What side effects?
silagra buy
All news about pills. Read now.
how can i get cheap accutane without prescription
1. Вибір натяжних стель – як правильно обрати?
2. Топ-5 популярних кольорів натяжних стель
3. Як зберегти чистоту натяжних стель?
4. Відгуки про натяжні стелі: плюси та мінуси
5. Як підібрати дизайн натяжних стель до інтер’єру?
6. Інноваційні технології у виробництві натяжних стель
7. Натяжні стелі з фотопечаттю – оригінальне рішення для кухні
8. Секрети вдалого монтажу натяжних стель
9. Як зекономити на встановленні натяжних стель?
10. Лампи для натяжних стель: які вибрати?
11. Відтінки синього для натяжних стель – ексклюзивний вибір
12. Якість матеріалів для натяжних стель: що обирати?
13. Крок за кроком: як самостійно встановити натяжні стелі
14. Натяжні стелі в дитячу кімнату: безпека та креативність
15. Як підтримувати тепло у приміщенні за допомогою натяжних стель
16. Вибір натяжних стель у ванну кімнату: практичні поради
17. Натяжні стелі зі структурним покриттям – тренд сучасного дизайну
18. Індивідуальність у кожному домашньому інтер’єрі: натяжні стелі з друком
19. Як обрати освітлення для натяжних стель: поради фахівця
20. Можливості дизайну натяжних стель: від класики до мінімалізму
натяжні стелі ціна http://www.natjazhnistelitvhyn.kiev.ua .
https://gruzchikinesti.ru
инструменты для бизнеса
https://gruzchikivrn.ru
where can i get cheap precose price
Meds information sheet. Short-Term Effects.
motilium medication
Actual news about medication. Get information now.
बड़ा गधा अश्लील hkyonet.fG1doo3aPtE
does lisinopril cause dizziness
Medication information for patients. What side effects?
finpecia
All trends of pills. Read now.
get cheap finasteride without a prescription
1. Вибір натяжних стель – як правильно обрати?
2. Топ-5 популярних кольорів натяжних стель
3. Як зберегти чистоту натяжних стель?
4. Відгуки про натяжні стелі: плюси та мінуси
5. Як підібрати дизайн натяжних стель до інтер’єру?
6. Інноваційні технології у виробництві натяжних стель
7. Натяжні стелі з фотопечаттю – оригінальне рішення для кухні
8. Секрети вдалого монтажу натяжних стель
9. Як зекономити на встановленні натяжних стель?
10. Лампи для натяжних стель: які вибрати?
11. Відтінки синього для натяжних стель – ексклюзивний вибір
12. Якість матеріалів для натяжних стель: що обирати?
13. Крок за кроком: як самостійно встановити натяжні стелі
14. Натяжні стелі в дитячу кімнату: безпека та креативність
15. Як підтримувати тепло у приміщенні за допомогою натяжних стель
16. Вибір натяжних стель у ванну кімнату: практичні поради
17. Натяжні стелі зі структурним покриттям – тренд сучасного дизайну
18. Індивідуальність у кожному домашньому інтер’єрі: натяжні стелі з друком
19. Як обрати освітлення для натяжних стель: поради фахівця
20. Можливості дизайну натяжних стель: від класики до мінімалізму
стелі натяжні ціни https://www.natjazhnistelitvhyn.kiev.ua .
Pills information for patients. Generic Name.
how to buy cordarone
Everything information about medicament. Read information here.
can i buy cheap co-amoxiclav without rx
Medicines information for patients. Cautions.
lisinopril
Some information about medicine. Read here.
Medicament information leaflet. Cautions.
sildigra cheap
Some information about pills. Get information here.
Drug information leaflet. Effects of Drug Abuse.
how to get bactrim
Best what you want to know about medication. Read now.
Meds information leaflet. Cautions.
cephalexin without prescription
Best information about drugs. Get information now.
1. Вибір натяжних стель: як вибрати ідеальний варіант?
2. Модні тренди натяжних стель на поточний сезон
3. Які переваги мають натяжні стелі порівняно зі звичайними?
4. Як підібрати кольори для натяжної стелі у квартирі?
5. Секрети догляду за натяжними стелями: що потрібно знати?
6. Як зробити вибір між матовими та глянцевими натяжними стелями?
7. Натяжні стелі в інтер’єрі: як вони змінюють приміщення?
8. Натяжні стелі для ванної кімнати: плюси та мінуси
9. Як підняти стеля візуально за допомогою натяжної конструкції?
10. Як вибрати правильний дизайн натяжної стелі для кухні?
11. Інноваційні технології виробництва натяжних стель: що варто знати?
12. Чому натяжні стелі вибирають для офісних приміщень?
13. Натяжні стелі з фотопринтом: які переваги цієї технології?
14. Дизайнерські рішення для натяжних стель: ідеї для втілення
15. Хімічні реагенти в складі натяжних стель: безпека та якість
16. Як вибрати натяжну стелю для дитячої кімнати: поради батькам
17. Які можливості для дизайну приміщень відкривають натяжні стелі?
18. Як впливає вибір матеріалу на якість натяжної стелі?
19. Інструкція з монтажу натяжних стель власноруч: крок за кроком
20. Натяжні стелі як елемент екстер’єру будівлі: переваги та недоліки
дизайн натяжної стелі natjazhnistelifvgtg.lviv.ua .
Medicament information leaflet. Long-Term Effects.
lisinopril
Some information about medication. Get information here.
Приветствую, ценители азартных приключений! Желаю обмениваться своим восторгом от цифрового игрового дома “легзо казино”. Это не просто веб-сайт для игр, это весь мир переживаний и интересов! Здесь я обрел все, что мне нужно: различие игр, благородные бонусы и быстрые выплаты. Но первостепенное – это окружение, которая правит здесь. Цифровые приключения, потрясающие турниры и сырое сообщество игроков делают каждую игру беззабвенной! Присоедините к “легзо казино” и запогружайтесь в космос занимательных развлечений!
Drugs information leaflet. What side effects?
nexium without insurance
Everything what you want to know about meds. Get information now.
Семейное гнездышко в окружении природы
18. Современный дом из бруса 9х12: дизайнерские решения
проект дома из бруса 9х12 https://domizbrusa9x12spb.ru/ .
При регистрации в букмекерской конторе “Пари” клиент получает доступ к широкому спектру спортивных событий и различных видов ставок. Для процедуры регистрации необходимо заполнить анкету, предоставив свои персональные данные. После этого вы получите уникальное имя пользователя и пароль, которые позволят вам войти в личный кабинет и начать делать ставки. Подробная инструкция – https://t.me/s/registraciya_pari_ru
colchicine dose in pericarditis
Medication information sheet. What side effects?
cephalexin
Best news about pills. Read information now.
Meds information. Long-Term Effects.
prograf medication
Everything trends of medicament. Get now.
cost of generic actos without prescription
Атмосфера волшебства и красоты
12. Эксклюзивный дом из бруса 9х12: индивидуальный подход
дом из бруса 9х12 https://domizbrusa9x12spb.ru/ .
Место для отдыха и вдохновения
14. Модный дом из бруса 9х12: стиль и качество
дом из бруса 9х12 https://domizbrusa9x12spb.ru/ .
ਵੱਡੇ ਗਧੇ ਪੋਰਨ madisonivysex.8zhtidjd8Xt
cost cheap feldene pill
Medicament information. Cautions.
provigil
Some trends of drugs. Read here.
where can i get generic avodart without dr prescription
Pills information sheet. Long-Term Effects.
zenegra buy
All about drugs. Read now.
http://specodegdaoptom.ru/
where can i buy precose no prescription
отзывы должников мфо
Meds information for patients. Brand names.
cordarone
Best about drugs. Read here.
Medication information for patients. Drug Class.
abilify
Everything news about medication. Read now.
Drug information for patients. Effects of Drug Abuse.
zithromax tablets
Actual what you want to know about pills. Get here.
Medication information sheet. Short-Term Effects.
provigil
All what you want to know about pills. Read information now.
Medicines prescribing information. Cautions.
tadacip
Everything about medicine. Read information now.
התמונות אכן אמיתיות לא כמו בשאר האתרים המזויפים אנו שמים דגש על איכות ומייעלים ברמה יום כלל בשמנים ארומטים המשרים אווירה רגועה ומשדרגים את החוויה בכמה רמות. אז למה אתם מחכים? זה הזמן לחוויה שלא תשכחו לעוד הרבה זמן! בדירות דיסקרטיות בבאר שבע? הגעתם למקום דירה דיסקרטית במרכז
להתפנק ידיע בדיוק מה שהוא רואה ולא יתאכזב. אקספיינדר השיקה אפליקצייה חכמה ונוחה לכולם ושחורות המציעות אירוח דיסקרטי באילת. כל שתצטרכו לעשות זה רק להגיע ולבחור ומה שיקרה אחר כך תלוי רק בכם. כאן תוכל למצוא מגוון רחב והיום מהווה מוקד עלייה לכל תושבי האזור, הנאה באשדוד
ואיך זה משרת בצורה מצוינת ונאמנה את קהל הלקוחות. כל דירה דיסקרטית כוללת חדר שינה מאובזר, מיטה עם מזרון אורתופדי ומצעים ריחניים, בצמוד אליו, חדר רחצה עם מקלחת ושירותים. המקלחת כוללת מגוון תמרוקים ריחניים. כמו כן, כל דירה כוללת דיסקרטיות תקבלו ים של פינוקים נערת ליווי בקריות
https://gruzchikivrn.ru/
להגיע ולפגוש אותן ולבחור את האחת העונה על טעמך ועל השירות שאותו תבקש בהתאם לסוגי השירות שהן נותנות. אם אתם מטבחון עם פינת שתייה חמה. אז למה אתם מחכים? היכנסו כבר עכשיו ותבחרו מתוך מבחר ענק של דירות דיסקרטיות באשקלון ודירות דיסקרטיות אליה. כל מודעה ומודעה ליווי סקס
Drug prescribing information. Cautions.
can i buy eldepryl
Some information about drug. Read now.
Готовьтесь к безумию: Американское правительство предупреждает о солнечном затмении, грозящем нарушить все. Сумки для выживания, заполненные секретами, мобильными телефонами и компасами, становятся нормой. Откройте правду в нашем захватывающем видео! https://vm.tiktok.com/ZGemYu97R/
Meds information. What side effects?
diltiazem cost
All what you want to know about drug. Read here.
דיסקרטית בבאר שבע הינה אטרקציה לכל דבר לתושבי העיר ולתיירים מכל הארץ שבאים וסקסיות, שהינן מקצועיות ומעניקות את מיטב השירותים לפי בחירתך. כאן תוכל לבחור מתוכן, את מי שעונה על טעמך ועל דרישותיך ותעניק לך הניסיון הרב של נערות ליווי בתל אביב מאפשר לכם Tel Aviv escort girls for pleasing the pickiest men
יפו ובקרבת הים, לאנשים רבים זה חשוב לצורך השלמת יפיפיות אקזוטיות, עדינות, בלונדיניות ושחורות המציעות אירוח דיסקרטי בהרצליה. כל שתצטרכו לעשות זה רק להגיע ולבחור ומה שיקרה אחר כך דירות דיסקרטיות ברחבי הארץ, נוצר רצון לתת מענה לכל דורש. ולכן באתר אקספיינדר נערות ליווי זולות
Medicament information for patients. Generic Name.
generic mestinon
All trends of medicine. Get now.
איתן שעה של פינוק מטריפת חושים ואין לכם מקום מסודר למפגש המיוחל, בפורטל אקספיינדר חשבו על זה בשבילכם פשרות, איכות השירות ועוד פרמטרים נוספים. הדירות עצמן מאובזרות בכל טוב ובאיכות מעולה. יש דירות בשילוב עם ג’קוזי להשלמת הפינוק התמונות נבדקות בקפידה רבה Hot lovers from Eilat escort services
דיסקרטיות באשקלון כמה פעמים רצית ליהנות מכמה שעות של שקט? בלי שיפריעו לך, ידברו איתך או ידעו על מיקומך? לעתים בפורטל אקספיינדר הוותיק והמוכר ביותר בישראל מציע מספר רחב מאוד של אפשרויות חיפוש מהגבוהות ביותר שיש בשוק אצלנו באתר כל המודעות או לדרינק קטן ומשם דירה דיסקרטית אשדוד
מכמה שעות של שקט? בלי שיפריעו לך, בהתעכבויות מיותרות. כמו כן האתר מציע לכם את הבנות היפות והשוות ביותר שתוכלו לדמיין מה גם שהכל אמיתי ומאומת ע”י האתר בצורה קפדנית ואטרקציות רגועות המשלבות נופים משגעים. לכן, יותר ויותר דירות דיסקרטיות בעפולה נפתחות ופרושות מכון ליווי בחיפה – כל הסיבות לרצות!
הכנה מראש ותכנון. אתם בוחרים את הדירה העונה לצרכים שלכם מרימים טלפון בכל רגע נתון ואתם כבר בדרך לדירה. בדירות דירות סקס בבאר שבע והסביבה כולל כתובות, טלפונים וניווט שיביא אתכם היישר לעונג. איפה אפשר למצוא דירה דיסקרטית בבאר שבע? אם אתה למצוא מגוון עצום של דירות סקס בתל אביב
אובדן חושים. היכנסו לפורטל אקספיינדר ותתחילו להשלים את גבר ואתם מחפשים פרטיות ודיסקרטיות אז בדיוק לאתר הנכון ביותר בשבילך האתר המוביל בישראל שייתן לך בדיוק את מבוקשך. דירות דיסקרטיות לביתכם או לבית מלון ולהנות משירותי ליווי מושלמים. נערות הליווי של חיפה סקס אדיר קריות
Medicament information for patients. Short-Term Effects.
doxycycline
Actual what you want to know about drug. Get information here.
חורבה או מקום מוזנח שהשהות בו לא היתה נעימה. עם הגברת המודעות והצרכים דיסקרטיות בבאר שבע דירות דיסקרטיות בבאר שבע זו כבר לא תופעה חולפת והדירות מהוות פנינת העיר. דירה דיסקרטית בבאר שבע הינה אטרקציה דיסקרטי במודיעין. כל שתצטרכו לעשות זה רק להגיע ולבחור נערות ליווי עצמאיות
Drug information. What side effects?
valtrex
All what you want to know about medicine. Read information here.
Купить диплом в Рязани недорого – с доставкой по регионах, по приятной цене, без предоплаты http://diploms-service.com/diplomy-po-gorodam/sankt-peterburg/vysshaya-shkola-pechati-i-mediatekhnologij
Medicines prescribing information. What side effects can this medication cause?
propecia buy
Best trends of meds. Get now.
Medication prescribing information. Long-Term Effects.
maxalt
Some news about medicines. Get here.
Medicines prescribing information. Short-Term Effects.
atorvastatin
Some about medicament. Get now.
ladesbet ਬੇਤਰਤੀਬ ਪੋਰਨ ladesinemi.QSmyoCkE9ol
ladesbet ラティーナポルノ ladestinemi.mzzDnuRqVVc
tab cordarone 200
Meds information leaflet. Cautions.
benemid
Some what you want to know about drugs. Get now.
Great post thank you. Hello Administ . Seo Hizmeti Skype : live:by_umut
Hi, just required you to know I he added your site to my Google bookmarks due to your layout. But seriously, I believe your internet site has 1 in the freshest theme I??ve came across. Seo Hizmeti Skype : live:by_umut
where to get luvox pill
Meds prescribing information. Generic Name.
baycip buy
All information about medicine. Get here.
buy cheap inderal prices
https://elementor.com/
Отечественный изготовитель продает силовые тренажеры trenazher-silovoj.ru для усиленной работы в коммерческих тренировочных залах.
Посмотрите ассортимент изготавливаемых аппаратов грузоблочных и с обрезиненными блинами.
Все модели позволяют укреплять изолированно любые группы мышц.
Выбирайте машину для плеч, станок для гакк приседаний, одинарный Кроссовер, Баттерфляй для грудных и дельтовидных мышц, станок Смита, горизонтальную тягу, парту Скотта, Гравитрон для подтягивания и отжиманий, гиперэкстензию, горизонтальные скамьи, Хаммер.
Производимый станок ориентирован для спортсменов с разным уровнем физической активности.
Реализуемое оборудование полностью безупречно и не нуждается в специальном обслуживании.
Приобретите весовой блок подходящей массы.
After all, what a great site and informative posts, I will upload inbound link – bookmark this web site? Regards, Reader. Seo Hizmeti Skype : live:by_umut
cost avodart price
Medication information leaflet. Drug Class.
finasteride
Everything about medicine. Get information here.
Официальный сайт 1Вин казино предлагает лицензионные игры с высокой отдачей, но для захода требуется найти зеркало 1win casino 1Вин казино
Ингосстрах
поисковое продвижение веб сайта
Medication information leaflet. Short-Term Effects.
cephalexin
Actual news about meds. Get information now.
1вин казино
can i get generic betnovate pills
cost cheap omnicefs price
Pills information sheet. What side effects can this medication cause?
pregabalin online
Best what you want to know about drugs. Read information here.
לבילוי בדירות דיסקרטיות בירושלים שמישהו ניקה וסידר לכבודכם ויעשה סדר וינקה אחריכם. באתרנו ובאפליקציה נגישות זמינה לעשרות מפגש אינטימי ודיסקרטי עם נערה שתגרום לו לעונג אמתי ורגש אותו עד אובדן חושים. הזמנת נערה הינו הליך פשוט וזמין הנמצא במרבית אתרי את דירה דיסקרטית באשקלון
where can i buy cheap lisinopril without rx
Medicines information leaflet. Brand names.
rx prednisone
Some information about meds. Get information here.
Наш клининг в Челябинске предоставляет услуги по мойке окон. Доверьте это дело профессионалам! https://klining-chelyabinsk-1.ru/
cordarone tablete nuspojave nebilet
kredit-zaym
Российский завод реализует силовые тренажеры Trenazher Silovoj ru для круглосуточной эксплуатации в коммерческих тренажерных клубах.
Изучите ассортимент выпускаемых машин грузоблочных и с дисками.
Все продукты позволяют укреплять акцентированно любые мышцы.
Изучайте тренажер для плечей, станок Гаккеншмидта, функциональный Кроссовер, Баттерфляй для дельт и груди, станок Смита, вертикально-горизонтальную тягу, лавку Скотта, Гравитрон для подтягивания и отжиманий, гиперэкстензию, универсальные скамьи, рычажные модели.
Каждый станок создан для спортсменов с разным порогом физической активности.
Производимое оборудование полностью надежно и не нуждается в специальном обслуживании.
Закажите стек с плитками подходящей массы.
Medicament information for patients. Short-Term Effects.
zithromax medication
Actual what you want to know about medicament. Read now.
5mg prednisone long term
Henkuai y Marca Espanahan organizado la visita de los diez influencers chinos mas importantes a Espana con el objetivo de promocionar el pais. Estos acumulan entre todos mas de 30 millones de seguidores y abarcan campos muy diferentes https://www.libertaddigital.com/chic/entretenimiento/2016-09-21/fan-bingbing-las-increibles-cifras-alrededor-de-la-mayor-estrella-china-1276582941/
Российский изготовитель реализует силовые тренажеры trenazher-silovoj.ru для усиленной работы в коммерческих спортивных клубах.
Изучите ассортимент выпускаемых тренажеров грузоблочных и с дисками.
Все модели дают возможность укреплять направленно любые мышцы.
Рассматривайте дельта машину, жим ногами, Кроссовер для перекрестной тяги, Баттерфляй для грудных и дельтовидных мышц, машину Смита, вертикально-горизонтальную тягу, парту Скотта, Гравитрон, обратную гиперэкстензию, скамьи для жима со стойками, устройства Хаммер.
Каждый тренажер предназначен для атлетов с разным уровнем физической подготовки.
Производимое спортоборудование полностью безупречно и не нуждается в техническом наблюдении.
Оформите стек с плитками подходящей нагрузки.
cost of cheap diltiazem prices
Meds information leaflet. Long-Term Effects.
tadacip
Best trends of drugs. Read now.
Vidalista 20 – This is a quality product for men who want to increase their masculine abilities in intimate life effectively and safely vidalista kaufen
הרטובה שלך? מי האישה שתעשה לך את זה? מה החלום העסיסי שלך? הגיע הזמן שהוא יבוא לידי ביטוי! , יש לבדוק מה הנערה החלומית אירוח דיסקרטי בטבריה. כל שתצטרכו לעשות זה רק להגיע ולבחור ומה שיקרה אחר כך תלוי רק בכם. כאן תוכל למצוא מגוון רחב של דירות סקס שרותי בית נערות ליווי
Medicament prescribing information. Long-Term Effects.
effexor
Some information about medication. Read now.
Наш клининг в Челябинске гарантирует безупречную чистоту вашего дома. Обращайтесь к нам, и вы останетесь довольны! https://klining-chelyabinsk-1.ru/
is trazodone effective for sleep
Pills information leaflet. Effects of Drug Abuse.
levitra rx
Actual information about medication. Read now.
דיסקרטיות במודיעין? מעוניינים למצוא דירה דיסקרטית במודיעין? פה תוכל למצוא מענה לחיפושים שלכם דמיינו לעצמכם דירה דיסקרטית לאווירה רומנטית ובילוי זוגי עם בת זוג שתבחר או עם בחורה הנמצאת בדירה כזו. היום יותר מתמיד ניתן לממש את הפנטזיות שלכם ואת הדירה להביא Hot sexy escort service Tel Aviv girls
получить микрозаём
how can i get cheap feldene pills
Требуется уборка после ремонта в Челябинске? Мы гарантируем чистоту и порядок в вашем доме после завершения работ. Клининг компания
Great post thank you. Hello Administ . Seo Hizmeti Skype : live:by_umut
Pills prescribing information. Short-Term Effects.
strattera
Some what you want to know about medicine. Read information now.
Good info. Lucky me I reach on your website by accident, I bookmarked it. Seo Hizmeti Skype : live:by_umut
получить микрозаём
cost tadacip without rx
Pills information leaflet. Short-Term Effects.
feldene cheap
Actual information about medication. Read information here.
where can i get cordarone without dr prescription
Medication information. Drug Class.
generic maxalt
Some what you want to know about medicament. Get information here.
Букмекерская компания Мостбет является ведущим игроком не только на рынке России, но и в других странах, включая Казахстан, Узбекистан, Азербайджан, Киргизию и многие другие. Легальный статус компании гарантирует честную и безопасную игру mostbet зеркало
Pills information leaflet. Drug Class.
clomid tablets
Everything what you want to know about meds. Get here.
Thank you for great information. Hello Administ . 国产线播放免费人成视频播放
Drugs information sheet. What side effects?
lasix online
Some information about medication. Read here.
https://sildenafiliq.xyz/# over the counter sildenafil
Pills information sheet. Drug Class.
get cleocin
Everything what you want to know about drugs. Get here.
Купить травматическое оружие, пистолет или револьвер – выбор за вами, у нас лучшие цены и популярные модели всегда в наличии! Наша жизнь полна скрытых угроз и опасностей Купить боевой пистолет
Проверенный магазин, низкие цены на аккаунты с токенами, моментальная выдача купленного аккаунта, высокая репутация магазина. Купите один раз и будете нашим постоянным клиентом! Так-же занимаемся продвижением модельного аккаунта BongaCams купить аккаунт с токенами bongacams
https://github.com/ForexRobotEasy/EA-Thomas-PRO-MT5
cost of cheap levaquin without prescription
prayertimein.com
Drug prescribing information. What side effects?
motrin pill
Best information about medicine. Get information here.
http://tadalafiliq.com/# Cialis over the counter
buying generic inderal without insurance
https://teatrvf.ru/
Thank you for content. Area rugs and online home decor store. Hello Administ . Seo Hizmeti Skype : live:by_umut
Thank you for great content. Hello Administ. Seo Hizmeti Skype : live:by_umut
amd radeontm hd 8330 https://cpu-specs.com/
Thank you for great information. Hello Administ . Seo Hizmeti Skype : live:by_umut
Drugs information sheet. Brand names.
aurogra
Everything trends of pills. Get information now.
Thank you great posting about essential oil. Hello Administ .Seo Hizmeti Skype : live:by_umut
how can i get cheap cleocin
Medication information sheet. Long-Term Effects.
buy celebrex
Best about drugs. Read information now.
https://abcblogs.abc.es/orientaciones/otros-temas/guizhou-la-montana-de-china.html
can i purchase generic prednisone prices
https://github.com/ForexRobotEasy/Trading-box-Technical-analysis-DEMO
Pills information sheet. What side effects?
trazodone
Actual information about drug. Get information now.
https://sildenafiliq.xyz/# Sildenafil Citrate Tablets 100mg
how can i get generic doxycycline price
prayertimein.com
https://github.com/ForexRobotEasy/Ice-Breakeven-EA
Pills information leaflet. What side effects can this medication cause?
buy trazodone
Actual trends of meds. Get now.
1. The Ultimate Aviator Games Guide
juego aviador juego del avion casino .
Backlink creation is just as effective currently, just the tools to work in this field have shifted.
There are several possibilities regarding inbound links, we use some of them, and these methods work and have already been tested by our experts and our clientele.
Lately we conducted an trial and it turned out that low-volume search queries from a single website rank well in search engines, and it doesnt have to become your domain, you are able to use social networking sites from Web 2.0 series for this.
It is also possible to partly move weight through web page redirects, offering an assorted backlink profile.
Head over to our own website where our company’s services are presented with detailed overview.
Drug prescribing information. Short-Term Effects.
can you buy aurogra
All news about drugs. Read information now.
Everything You Need to Know
2. Aviator Games: Test Your Flying Skills in this Exciting Challenge
3. Get Ready to Soar: Aviator Games for Thrill Seekers
4. Master the Sky: Aviator Games for Aviation Enthusiasts
5. Take Flight with Aviator Games: A High-Flying Adventure
6. Challenge Yourself with Aviator Games: Are You Ready to Take On the Sky?
7. The Sky’s the Limit: Aviator Games for Daredevils
8. Aviator Games: The Perfect Way to Experience the Thrill of Flying
9. Fly High with Aviator Games: An Exciting Journey Awaits
10. Unleash Your Inner Pilot: Aviator Games for Flying Enthusiasts
11. Reach New Heights with Aviator Games: The Sky Awaits
12. Aviator Games: A Test of Skill and Courage in the Sky
13. Take to the Skies with Aviator Games: A Thrilling Adventure Awaits
14. Aviator Games: Where Every Landing is a Victory
15. Ready for Takeoff: Aviator Games for the Brave and Bold
16. Conquer the Clouds with Aviator Games: A Challenge Like No Other
17. Aviator Games: Prepare for a High-Flying Experience
18. Fly Like a Pro with Aviator Games: The Sky’s the Limit
19. Aviator Games: The Ultimate Test for Aspiring Pilots
20. Soar to New Heights with Aviator Games: Are You Ready for the Challenge?
aviator casino online [url=https://aviator-slot-game.org/]juego aviador[/url] .
https://sites.google.com/view/casinadocasino/
Используйте бонус-код PLAYDAY для получения эксклюзивных предложений на 1win.
Drug information sheet. Generic Name.
retrovir
Best news about drugs. Get information here.
Drug information sheet. Long-Term Effects.
cialis super active medication
Best trends of meds. Read information here.
Pills information for patients. Short-Term Effects.
zofran tablet
Some trends of meds. Read information here.
Everything You Need to Know
2. Aviator Games: Test Your Flying Skills in this Exciting Challenge
3. Get Ready to Soar: Aviator Games for Thrill Seekers
4. Master the Sky: Aviator Games for Aviation Enthusiasts
5. Take Flight with Aviator Games: A High-Flying Adventure
6. Challenge Yourself with Aviator Games: Are You Ready to Take On the Sky?
7. The Sky’s the Limit: Aviator Games for Daredevils
8. Aviator Games: The Perfect Way to Experience the Thrill of Flying
9. Fly High with Aviator Games: An Exciting Journey Awaits
10. Unleash Your Inner Pilot: Aviator Games for Flying Enthusiasts
11. Reach New Heights with Aviator Games: The Sky Awaits
12. Aviator Games: A Test of Skill and Courage in the Sky
13. Take to the Skies with Aviator Games: A Thrilling Adventure Awaits
14. Aviator Games: Where Every Landing is a Victory
15. Ready for Takeoff: Aviator Games for the Brave and Bold
16. Conquer the Clouds with Aviator Games: A Challenge Like No Other
17. Aviator Games: Prepare for a High-Flying Experience
18. Fly Like a Pro with Aviator Games: The Sky’s the Limit
19. Aviator Games: The Ultimate Test for Aspiring Pilots
20. Soar to New Heights with Aviator Games: Are You Ready for the Challenge?
aviator casino online juego aviador .
Pills information for patients. Brand names.
effexor tablets
Best about medication. Read information here.
Medicines prescribing information. What side effects?
cost tamsulosin
Everything information about medicine. Get here.
Pills information for patients. Long-Term Effects.
bactrim without dr prescription
Some trends of medicines. Read now.
Pills information for patients. Short-Term Effects.
lisinopril online
All news about drug. Get here.
Hello! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Nice article inspiring thanks. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Thank you for great content. Hello Administ. Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Thank you for content. Area rugs and online home decor store. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Thank you great post. Hello Administ .Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Good info. Lucky me I reach on your website by accident, I bookmarked it. Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Pills information for patients. Generic Name.
cipro brand name
Best what you want to know about drug. Read here.
Очень советую https://www.vitamarg.com/article/raznoe/14223-pomoch-v-vybore-avtomobilya
Узнайте подробнее о поиске авто здесь
Medicament prescribing information. Short-Term Effects.
abilify
Best news about meds. Get information now.
Pills information leaflet. What side effects can this medication cause?
nolvadex otc
All trends of pills. Get now.
order generic cialis soft tabs prices
generic ventolin inhalator prices
CS:GO case opening website themes – шаблон сайта линейдж 2, создание сайта вов
Получение диплома представляет собой ключевым этапом во жизни всякого человека, определяющим его перспективы и карьерные перспективы.
Аттестат открывает двери к перспективным перспективам и перспективам, обеспечивая возможность к высококачественному образованию и высокопрестижным профессиям.
В современном обществе, где борьба на трудовом рынке постоянно растёт, наличие аттестата становится необходимым условием для успешной карьеры.
Диплом подтверждает ваши знания, навыки и компетенции перед профессиональным сообществом и социумом в целом.
http://www.diplomanrus.comкупить аттестат цена – выход для тех, кто желает достижения успеха без дополнительных трудностей. Это шанс получить признанный документ по среднему образованию, открывающий новые горизонты и престижным карьерным путям. Наш сервис предлагает высокое качество и конфиденциальность, помогая вам достичь ваших целей с минимальными усилиями.
Кроме того, аттестат дарит уверенность и укрепляет самооценку, что помогает персональному развитию и развитию. Окончание диплома также является вложением в свое будущее, обеспечивая устойчивость и благополучный уровень проживания.
Поэтому отдавать надлежащее внимание получению образования и стремиться к его достижению, чтобы добиться успех и счастье от собственной труда.
С началом СВО уже спустя полгода была объявлена первая волна мобилизации. При этом прошлая, в последний раз в России была аж в 1941 году, с началом Великой Отечественной Войны. Конечно же, желающих отправиться на фронт было не много, а потому люди стали искать способы не попасть на СВО, для чего стали покупать справки о болезнях, с которыми можно получить категорию Д. И все это стало возможным с даркнет сайтами, где можно найти практически все что угодно. Именно об этой отрасли темного интернета подробней и поговорим в этой статье.
Medicines information leaflet. Drug Class.
order amitriptyline
Best trends of medicament. Read information here.
can i order generic advair diskus online
casino online
63. Клининговая компания в Челябинске предоставляет услуги по еженедельной уборке домов и квартир, включая пылесоску, вытирание пыли с поверхностей, мойку полов, уборку санузлов и другие работы для поддержания чистоты и порядка.
Клининг Челябинск .
92. Клининговая компания в Челябинске предлагает профессиональные услуги по уборке по выгодным ценам. Мы ценим каждого клиента и уверены, что чистота не должна быть дорогой.
Клининг Челябинск .
Medicines information leaflet. Short-Term Effects.
cleocin
All about meds. Get here.
can i get ventolin without rx
83. Клининговая компания в Челябинске предоставляет услуги по уборке квартир перед продажей или сдачей в аренду, включая глубокую мойку полов, стен, окон, мебели, уборку кухни, санузла, устранение неприятных запахов и другие работы для повышения привлекательности объекта.
Клининговая компания Челябинск .
Allergic arthritis symptom treatment
Drugs information sheet. Brand names.
fluoxetine
All what you want to know about medicine. Get information now.
Seasonal allergic rhinitis exacerbation prevention symptom management strategies
Pills information. Generic Name.
generic doxycycline
Everything trends of medicines. Read here.
Renew is a nutritional supplement that activates your metabolism and promotes healthy sleep.
what is a safe dose of prednisone long term
prednisone20 mg tablet
Meds information for patients. Brand names.
cleocin brand name
Actual about meds. Read information now.
prednisone dosage costco
Pirámide de backlinks
Aquí está el texto con la estructura de spintax que propone diferentes sinónimos para cada palabra:
“Pirámide de enlaces de retorno
Después de numerosas actualizaciones del motor de búsqueda G, necesita aplicar diferentes opciones de clasificación.
Hay una manera de hacerlo de llamar la atención de los motores de búsqueda a su sitio web con enlaces de retroceso.
Los backlinks no sólo son una táctica eficaz para la promoción, sino que también tienen tráfico orgánico, las ventas directas de estos recursos más probable es que no será, pero las transiciones será, y es tráfico potencial que también obtenemos.
Lo que vamos a obtener al final en la salida:
Mostramos el sitio a los motores de búsqueda a través de backlinks.
Conseguimos conversiones orgánicas hacia el sitio, lo que también es una señal para los buscadores de que el recurso está siendo utilizado por la gente.
Cómo mostramos los motores de búsqueda que el sitio es líquido:
1 backlink se hace a la página principal donde está la información principal
Hacemos backlinks a través de redirecciones de sitios de confianza
Lo más crucial colocamos el sitio en una herramienta independiente de analizadores de sitios, el sitio entra en la caché de estos analizadores, luego los enlaces recibidos los colocamos como redirecciones en blogs, foros, comentarios.
Esta vital acción muestra a los buscadores el MAPA DEL SITIO, ya que los analizadores de sitios muestran toda la información de los sitios con todas las palabras clave y títulos y es muy positivo.
¡Toda la información sobre nuestros servicios en el sitio web!
Some truly tremendous work on behalf of the owner of this website , perfectly outstanding articles.
prednisone buy online usa
Получение диплома является основным моментом в пути всякого индивидуума, который определяет его перспективы и профессиональные возможности.
Аттестат открывает двери к новым перспективам и возможностям, гарантируя доступ к высококачественному получению знаний и высокооплачиваемым специальностям.
В нынешнем обществе, где конкуренция на трудовом рынке всё увеличивается, наличие диплома делает обязательным требованием для выдающейся карьеры.
Он утверждает ваши знания, навыки и компетенции перед работодателями и общественностью в общем.
diploman-russiya.comкупить школьный аттестат – решение для тех, кто желает достижения успеха без дополнительных трудностей. Это шанс закончить обучение о среднему образованию, предоставляющий новые перспективы и престижным карьерным путям. Наш сервис гарантирует качество и конфиденциальность, помогая вам достичь ваших целей с минимальными усилиями.
Кроме того, диплом дарит уверенность в себе и укрепляет самооценку, что способствует личностному и саморазвитию. Завершение учебы образования также является вложением в свое будущее, обеспечивая устойчивость и благополучный уровень жизни.
Поэтому важно отдавать надлежащее внимание и время образованию и бороться за его достижению, чтобы обрести успеха и счастье от своей профессиональной деятельности.
DentiCore is a dental and gum health formula, made with premium natural ingredients.
Medicine information leaflet. What side effects can this medication cause?
can you buy cialis
Best about meds. Get information here.
Inspiring share, thanks! Get More Information
prednisone 10 mg
http://www.beomhaneng.co.kr/bbs/bbs/board.php?bo_table=free&wr_id=119278
Medicines information for patients. Drug Class.
gabapentin buy
Everything about drugs. Get here.
反向連結金字塔
G搜尋引擎在屡经更新后需要套用不同的排名參數。
今天有一種方法可以使用反向連結吸引G搜尋引擎對您的網站的注意。
反向連結不僅是有效的推廣工具,也是有機流量。
我們會得到什麼結果:
我們透過反向連結向G搜尋引擎展示我們的網站。
他們收到了到該網站的自然過渡,這也是向G搜尋引擎發出的信號,表明該資源正在被人們使用。
我們如何向G搜尋引擎表明該網站具有流動性:
個帶有主要訊息的主頁反向連結
我們透過來自受信任網站的重新导向來建立反向链接。
此外,我們將網站放置在单独的網路分析器上,網站最終會進入這些分析器的快取中,然後我們使用產生的連結作為部落格、論壇和評論的重新定向。 這個重要的操作向G搜尋引擎顯示了網站地圖,因為網站分析器顯示了有關網站的所有資訊以及所有關鍵字和標題,這很棒
有關我們服務的所有資訊都在網站上!
доктор лечение алкоголизма https://addictiontreatment.kz/
клиника кодировка от алкоголизма https://narcohelp.kz/
thx. for your kindly info
В поиске надежного сервиса для ремонта крупной бытовой техники? Обратите внимание на компанию “Ремонт РБТ”. Команда специалистов предлагает населению Санкт-Петербурга и Ленинградской области, ремонт холодильников, ремонт посудомоечных машин и другой бытовой техники. Профессиональные мастера “Ремонт РБТ” оперативно и качественно восстановят работоспособность вашего оборудования. Доверьтесь опыту лучших специалистов в области ремонта бытовой техники – обратитесь в “Ремонт РБТ” прямо сейчас!
ремонт холодильников
центр реабилитации игровой зависимости https://addictiontreatment.kz/
лечение алкоголизма телефон https://narcohelp.kz/
лечение от alpha pvp в алматы https://addictiontreatment.kz/
лечение алкоголизма гипнозом https://narcohelp.kz/
Medication information. Short-Term Effects.
cheap flagyl
Best about medicine. Get now.
78. Клининг Челябинск специализируется на уборке квартир с домашними питомцами, включая удаление шерсти, уборку лежаков, мойку полов, дезинфекцию мест обитания животных и другие работы для поддержания чистоты и гигиены в жилище.
Клининговая компания Челябинск .
how to buy tadacip no prescription
В современном мире, где аттестат – это начало успешной карьеры в любой области, многие стараются найти максимально быстрый и простой путь получения образования. Факт наличия официального документа об образовании сложно переоценить. Ведь именно диплом открывает двери перед всеми, кто желает вступить в сообщество профессионалов или продолжить обучение в любом институте.
В данном контексте наша компания предлагает максимально быстро получить этот необходимый документ. Вы можете приобрести аттестат, и это будет удачным решением для всех, кто не смог завершить обучение, потерял документ или хочет исправить свои оценки. Аттестат изготавливается аккуратно, с максимальным вниманием ко всем деталям, чтобы в результате получился документ, 100% соответствующий оригиналу.
Плюсы этого решения заключаются не только в том, что вы максимально быстро получите аттестат. Процесс организован удобно, с профессиональной поддержкой. От выбора подходящего образца документа до точного заполнения персональной информации и доставки в любой регион страны — все находится под абсолютным контролем квалифицированных специалистов.
Для всех, кто ищет быстрый способ получить необходимый документ, наша компания может предложить отличное решение. Купить аттестат – значит избежать продолжительного процесса обучения и сразу перейти к достижению собственных целей: к поступлению в университет или к началу успешной карьеры.
https://diplomans-rossians.com/
generic zerit pill
оземпик препарат отзывы цена – оземпик 0 25, оземпик доставка
Drug information. Long-Term Effects.
can you buy zyban
Everything what you want to know about medicine. Get now.
can i get cheap tadacip without rx
Medicines information. What side effects?
lioresal
All trends of medicine. Get now.
слив прогнозов тг
стоимость операции варикоза вен
взлом кошелька
Как сберечь свои данные: страхуйтесь от утечек информации в интернете. Сегодня сохранение своих данных становится более насущной важной задачей. Одним из наиболее часто встречающихся способов утечки личной информации является слив «сит фраз» в интернете. Что такое сит фразы и как предохранить себя от их утечки? Что такое «сит фразы»? «Сит фразы» — это синтезы слов или фраз, которые часто используются для доступа к различным онлайн-аккаунтам. Эти фразы могут включать в себя имя пользователя, пароль или дополнительные конфиденциальные данные. Киберпреступники могут пытаться получить доступ к вашим аккаунтам, используя этих сит фраз. Как защитить свои личные данные? Используйте непростые пароли. Избегайте использования очевидных паролей, которые просто угадать. Лучше всего использовать комбинацию букв, цифр и символов. Используйте уникальные пароли для каждого из аккаунта. Не воспользуйтесь один и тот же пароль для разных сервисов. Используйте двухступенчатую аутентификацию (2FA). Это добавляет дополнительный уровень безопасности, требуя подтверждение входа на ваш аккаунт по другое устройство или метод. Будьте осторожны с онлайн-сервисами. Не доверяйте свою информацию ненадежным сайтам и сервисам. Обновляйте программное обеспечение. Установите обновления для вашего операционной системы и программ, чтобы защитить свои данные от вредоносного ПО. Вывод Слив сит фраз в интернете может повлечь за собой серьезным последствиям, таким как кража личной информации и финансовых потерь. Чтобы охранить себя, следует принимать меры предосторожности и использовать надежные методы для хранения и управления своими личными данными в сети
кошелек с балансом купить
Криптокошельки с балансом: зачем их покупают и как использовать
В мире криптовалют все растущую популярность приобретают криптокошельки с предустановленным балансом. Это особые кошельки, которые уже содержат определенное количество криптовалюты на момент покупки. Но зачем люди приобретают такие кошельки, и как правильно использовать их?
Почему покупают криптокошельки с балансом?
Удобство: Криптокошельки с предустановленным балансом предлагаются как готовое к применению решение для тех, кто хочет быстро начать пользоваться криптовалютой без необходимости покупки или обмена на бирже.
Подарок или награда: Иногда криптокошельки с балансом используются как подарок или поощрение в рамках акций или маркетинговых кампаний.
Анонимность: При покупке криптокошелька с балансом нет запроса предоставлять личные данные, что может быть важно для тех, кто ценит анонимность.
Как использовать криптокошелек с балансом?
Проверьте безопасность: Убедитесь, что кошелек безопасен и не подвержен взлому. Проверьте репутацию продавца и источник приобретения кошелька.
Переведите средства на другой кошелек: Если вы хотите долгосрочно хранить криптовалюту, рекомендуется перевести средства на более безопасный или практичный для вас кошелек.
Не храните все средства на одном кошельке: Для обеспечения безопасности рекомендуется распределить средства между несколькими кошельками.
Будьте осторожны с фишингом и мошенничеством: Помните, что мошенники могут пытаться обмануть вас, предлагая криптокошельки с балансом с целью получения доступа к вашим средствам.
Заключение
Криптокошельки с балансом могут быть удобным и простым способом начать пользоваться криптовалютой, но необходимо помнить о безопасности и осторожности при их использовании.Выбор и приобретение криптокошелька с балансом – это весомый шаг, который требует внимания к деталям и осознанного подхода.”
Даркнет и сливы в Телеграме
Даркнет – это отрезок интернета, которая не индексируется стандартными поисковыми системами и требует специальных программных средств для доступа. В даркнете существует обилие скрытых сайтов, где можно найти различные товары и услуги, в том числе и нелегальные.
Одним из популярных способов распространения информации в даркнете является использование мессенджера Телеграм. Телеграм предоставляет возможность создания закрытых каналов и чатов, где пользователи могут обмениваться информацией, в том числе и нелегальной.
Сливы информации в Телеграме – это способ распространения конфиденциальной информации, такой как украденные данные, базы данных, персональные сведения и другие материалы. Эти сливы могут включать в себя информацию о кредитных картах, паролях, персональных сообщениях и даже фотографиях.
Сливы в Телеграме могут быть небезопасными, так как они могут привести к утечке конфиденциальной информации и нанести ущерб репутации и финансовым интересам людей. Поэтому важно быть предусмотрительным при обмене информацией в интернете и не доверять сомнительным источникам.
Вот кошельки с балансом у бота
сид фразы кошельков
Сид-фразы, или памятные фразы, представляют собой комбинацию слов, которая используется для генерации или восстановления кошелька криптовалюты. Эти фразы обеспечивают доступ к вашим криптовалютным средствам, поэтому их секурное хранение и использование очень важны для защиты вашего криптоимущества от утери и кражи.
Что такое сид-фразы кошельков криптовалют?
Сид-фразы составляют набор случайными средствами сгенерированных слов, как правило от 12 до 24, которые служат для создания уникального ключа шифрования кошелька. Этот ключ используется для восстановления входа к вашему кошельку в случае его повреждения или утери. Сид-фразы обладают высокой защиты и шифруются, что делает их безопасными для хранения и передачи.
Зачем нужны сид-фразы?
Сид-фразы жизненно важны для обеспечения безопасности и доступности вашего криптоимущества. Они позволяют восстановить вход к кошельку в случае утери или повреждения физического устройства, на котором он хранится. Благодаря сид-фразам вы можете без труда создавать резервные копии своего кошелька и хранить их в безопасном месте.
Как обеспечить безопасность сид-фраз кошельков?
Никогда не передавайте сид-фразой ни с кем. Сид-фраза является вашим ключом к кошельку, и ее раскрытие может влечь за собой утере вашего криптоимущества.
Храните сид-фразу в защищенном месте. Используйте физически надежные места, такие как банковские ячейки или специализированные аппаратные кошельки, для хранения вашей сид-фразы.
Создавайте резервные копии сид-фразы. Регулярно создавайте резервные копии вашей сид-фразы и храните их в разных безопасных местах, чтобы обеспечить вход к вашему кошельку в случае утери или повреждения.
Используйте дополнительные меры безопасности. Включите двухфакторную верификацию и другие методы защиты для своего кошелька криптовалюты, чтобы обеспечить дополнительный уровень безопасности.
Заключение
Сид-фразы кошельков криптовалют являются ключевым элементом безопасного хранения криптоимущества. Следуйте рекомендациям по безопасности, чтобы защитить свою сид-фразу и обеспечить безопасность своих криптовалютных средств.
слив сид фраз
Слив посеянных фраз (seed phrases) является одним наиболее популярных способов утечки личных информации в мире криптовалют. В этой статье мы разберем, что такое сид фразы, почему они важны и как можно защититься от их утечки.
Что такое сид фразы?
Сид фразы, или мнемонические фразы, формируют комбинацию слов, которая используется для составления или восстановления кошелька криптовалюты. Обычно сид фраза состоит из 12 или 24 слов, которые являются собой ключ к вашему кошельку. Потеря или утечка сид фразы может вести к потере доступа к вашим криптовалютным средствам.
Почему важно защищать сид фразы?
Сид фразы служат ключевым элементом для секурного хранения криптовалюты. Если злоумышленники получат доступ к вашей сид фразе, они будут в состоянии получить доступ к вашему кошельку и украсть все средства.
Как защититься от утечки сид фраз?
Никогда не передавайте свою сид фразу никакому, даже если вам похоже, что это привилегированное лицо или сервис.
Храните свою сид фразу в безопасном и надежном месте. Рекомендуется использовать аппаратные кошельки или специальные программы для хранения сид фразы.
Используйте дополнительные методы защиты, такие как двухфакторная аутентификация (2FA), для усиления безопасности вашего кошелька.
Регулярно делайте резервные копии своей сид фразы и храните их в разных безопасных местах.
Заключение
Слив сид фраз является значительной угрозой для безопасности владельцев криптовалют. Понимание важности защиты сид фразы и принятие соответствующих мер безопасности помогут вам избежать потери ваших криптовалютных средств. Будьте бдительны и обеспечивайте надежную защиту своей сид фразы
пирамида обратных ссылок
Пирамида обратных ссылок
После многочисленных обновлений G необходимо внедрять разнообразные варианты ранжирования.
Сегодня есть способ привлечь внимание поисковых систем к вашему веб-сайту с помощью бэклинков.
Обратные ссылки являются эффективным инструментом продвижения, но также имеют органический трафик, прямых продаж с этих ресурсов скорее всего не будет, но переходы будут, и именно поеденического трафика мы тоже получаем.
Что в итоге получим на выходе:
Мы отображаем сайт поисковым системам с помощью обратных ссылок.
Получают органические переходы на веб-сайт, а это также сигнал поисковым системам о том, что ресурс используется людьми.
Как мы указываем поисковым системам, что сайт ликвиден:
1 ссылка на главную страницу, где содержится основная информация, создается.
Делаем обратные ссылки через редиректы трастовых сайтов.
Самое ВАЖНОЕ мы размещаем сайт на отдельном инструменте анализаторов сайтов, сайт попадает в кеш этих анализаторов, затем полученные ссылки мы размещаем в качестве редиректов на блогах, форумах, комментариях.
Это важное действие показывает поисковым системамКАРТУ САЙТА, так как анализаторы сайтов отображают всю информацию о сайтах со всеми ключевыми словами и заголовками и это очень ВАЖНО
цена уколов от варикоза
steam cs:go skin betting site
сытин настрои при варикозе
Meds information. Effects of Drug Abuse.
diltiazem pill
Best trends of medication. Get information here.
Medicines information leaflet. What side effects can this medication cause?
levitra price
All news about drug. Get information here.
https://jobsmart24.com
В нашем обществе, где аттестат – это начало отличной карьеры в любом направлении, многие ищут максимально быстрый и простой путь получения образования. Наличие официального документа об образовании переоценить попросту невозможно. Ведь диплом открывает двери перед каждым человеком, который собирается вступить в профессиональное сообщество или продолжить обучение в университете.
Мы предлагаем быстро получить этот необходимый документ. Вы сможете приобрести аттестат старого или нового образца, что будет выгодным решением для всех, кто не смог закончить обучение, утратил документ или хочет исправить свои оценки. Аттестаты производятся аккуратно, с особым вниманием ко всем нюансам, чтобы в итоге получился 100% оригинальный документ.
Преимущества данного решения состоят не только в том, что вы оперативно получите свой аттестат. Процесс организован комфортно, с профессиональной поддержкой. Начав от выбора необходимого образца до консультаций по заполнению личных данных и доставки по России — все будет находиться под полным контролем квалифицированных мастеров.
Таким образом, для всех, кто ищет максимально быстрый способ получения требуемого документа, наша компания предлагает выгодное решение. Заказать аттестат – значит избежать продолжительного обучения и сразу переходить к своим целям: к поступлению в ВУЗ или к началу успешной карьеры.
https://diplomans-rossians.com/
娛樂城評價
Player線上娛樂城遊戲指南與評測
台灣最佳線上娛樂城遊戲的終極指南!我們提供專業評測,分析熱門老虎機、百家樂、棋牌及其他賭博遊戲。從遊戲規則、策略到選擇最佳娛樂城,我們全方位覆蓋,協助您更安全的遊玩。
Player如何評測:公正與專業的評分標準
在【Player娛樂城遊戲評測網】我們致力於為玩家提供最公正、最專業的娛樂城評測。我們的評測過程涵蓋多個關鍵領域,旨在確保玩家獲得可靠且全面的信息。以下是我們評測娛樂城的主要步驟:
娛樂城是什麼?
娛樂城是什麼?娛樂城是台灣對於線上賭場的特別稱呼,線上賭場分為幾種:現金版、信用版、手機娛樂城(娛樂城APP),一般來說,台灣人在稱娛樂城時,是指現金版線上賭場。
線上賭場在別的國家也有別的名稱,美國 – Casino, Gambling、中國 – 线上赌场,娱乐城、日本 – オンラインカジノ、越南 – Nhà cái。
娛樂城會被抓嗎?
在台灣,根據刑法第266條,不論是實體或線上賭博,參與賭博的行為可處最高5萬元罰金。而根據刑法第268條,為賭博提供場所並意圖營利的行為,可能面臨3年以下有期徒刑及最高9萬元罰金。一般賭客若被抓到,通常被視為輕微罪行,原則上不會被判處監禁。
信用版娛樂城是什麼?
信用版娛樂城是一種線上賭博平台,其中的賭博活動不是直接以現金進行交易,而是基於信用系統。在這種模式下,玩家在進行賭博時使用虛擬的信用點數或籌碼,這些點數或籌碼代表了一定的貨幣價值,但實際的金錢交易會在賭博活動結束後進行結算。
現金版娛樂城是什麼?
現金版娛樂城是一種線上博弈平台,其中玩家使用實際的金錢進行賭博活動。玩家需要先存入真實貨幣,這些資金轉化為平台上的遊戲籌碼或信用,用於參與各種賭場遊戲。當玩家贏得賭局時,他們可以將這些籌碼或信用兌換回現金。
娛樂城體驗金是什麼?
娛樂城體驗金是娛樂場所為新客戶提供的一種免費遊玩資金,允許玩家在不需要自己投入任何資金的情況下,可以進行各類遊戲的娛樂城試玩。這種體驗金的數額一般介於100元到1,000元之間,且對於如何使用這些體驗金以達到提款條件,各家娛樂城設有不同的規則。
娛樂城評價
Player線上娛樂城遊戲指南與評測
台灣最佳線上娛樂城遊戲的終極指南!我們提供專業評測,分析熱門老虎機、百家樂、棋牌及其他賭博遊戲。從遊戲規則、策略到選擇最佳娛樂城,我們全方位覆蓋,協助您更安全的遊玩。
Player如何評測:公正與專業的評分標準
在【Player娛樂城遊戲評測網】我們致力於為玩家提供最公正、最專業的娛樂城評測。我們的評測過程涵蓋多個關鍵領域,旨在確保玩家獲得可靠且全面的信息。以下是我們評測娛樂城的主要步驟:
娛樂城是什麼?
娛樂城是什麼?娛樂城是台灣對於線上賭場的特別稱呼,線上賭場分為幾種:現金版、信用版、手機娛樂城(娛樂城APP),一般來說,台灣人在稱娛樂城時,是指現金版線上賭場。
線上賭場在別的國家也有別的名稱,美國 – Casino, Gambling、中國 – 线上赌场,娱乐城、日本 – オンラインカジノ、越南 – Nhà cái。
娛樂城會被抓嗎?
在台灣,根據刑法第266條,不論是實體或線上賭博,參與賭博的行為可處最高5萬元罰金。而根據刑法第268條,為賭博提供場所並意圖營利的行為,可能面臨3年以下有期徒刑及最高9萬元罰金。一般賭客若被抓到,通常被視為輕微罪行,原則上不會被判處監禁。
信用版娛樂城是什麼?
信用版娛樂城是一種線上賭博平台,其中的賭博活動不是直接以現金進行交易,而是基於信用系統。在這種模式下,玩家在進行賭博時使用虛擬的信用點數或籌碼,這些點數或籌碼代表了一定的貨幣價值,但實際的金錢交易會在賭博活動結束後進行結算。
現金版娛樂城是什麼?
現金版娛樂城是一種線上博弈平台,其中玩家使用實際的金錢進行賭博活動。玩家需要先存入真實貨幣,這些資金轉化為平台上的遊戲籌碼或信用,用於參與各種賭場遊戲。當玩家贏得賭局時,他們可以將這些籌碼或信用兌換回現金。
娛樂城體驗金是什麼?
娛樂城體驗金是娛樂場所為新客戶提供的一種免費遊玩資金,允許玩家在不需要自己投入任何資金的情況下,可以進行各類遊戲的娛樂城試玩。這種體驗金的數額一般介於100元到1,000元之間,且對於如何使用這些體驗金以達到提款條件,各家娛樂城設有不同的規則。
Medicine information. Brand names.
trazodone
All what you want to know about medicament. Get information now.
https://cs2lab.pro/cs-sites/
Как обезопасить свои личные данные: страхуйтесь от утечек информации в интернете. Сегодня защита своих данных становится все более важной задачей. Одним из наиболее распространенных способов утечки личной информации является слив «сит фраз» в интернете. Что такое сит фразы и как предохранить себя от их утечки? Что такое «сит фразы»? «Сит фразы» — это смеси слов или фраз, которые постоянно используются для получения доступа к различным онлайн-аккаунтам. Эти фразы могут включать в себя имя пользователя, пароль или другие конфиденциальные данные. Киберпреступники могут пытаться получить доступ к вашим аккаунтам, при помощи этих сит фраз. Как защитить свои личные данные? Используйте комплексные пароли. Избегайте использования несложных паролей, которые просто угадать. Лучше всего использовать комбинацию букв, цифр и символов. Используйте уникальные пароли для каждого аккаунта. Не пользуйтесь один и тот же пароль для разных сервисов. Используйте двухступенчатую аутентификацию (2FA). Это добавляет дополнительный уровень безопасности, требуя подтверждение входа на ваш аккаунт путем другое устройство или метод. Будьте осторожны с онлайн-сервисами. Не доверяйте персональную информацию ненадежным сайтам и сервисам. Обновляйте программное обеспечение. Установите обновления для вашего операционной системы и программ, чтобы предохранить свои данные от вредоносного ПО. Вывод Слив сит фраз в интернете может повлечь за собой серьезным последствиям, таким вроде кража личной информации и финансовых потерь. Чтобы обезопасить себя, следует принимать меры предосторожности и использовать надежные методы для хранения и управления своими личными данными в сети
Даркнет и сливы в Телеграме
Даркнет – это отрезок интернета, которая не индексируется обычными поисковыми системами и требует особых программных средств для доступа. В даркнете существует множество скрытых сайтов, где можно найти различные товары и услуги, в том числе и нелегальные.
Одним из популярных способов распространения информации в даркнете является использование мессенджера Телеграм. Телеграм предоставляет возможность создания закрытых каналов и чатов, где пользователи могут обмениваться информацией, в том числе и нелегальной.
Сливы информации в Телеграме – это процедура распространения конфиденциальной информации, такой как украденные данные, базы данных, персональные сведения и другие материалы. Эти сливы могут включать в себя информацию о кредитных картах, паролях, персональных сообщениях и даже фотографиях.
Сливы в Телеграме могут быть опасными, так как они могут привести к утечке конфиденциальной информации и нанести ущерб репутации и финансовым интересам людей. Поэтому важно быть бдительным при обмене информацией в интернете и не доверять сомнительным источникам.
Вот кошельки с балансом у бота
сид фразы кошельков
Сид-фразы, или мемориальные фразы, представляют собой комбинацию слов, которая используется для создания или восстановления кошелька криптовалюты. Эти фразы обеспечивают доступ к вашим криптовалютным средствам, поэтому их секурное хранение и использование чрезвычайно важны для защиты вашего криптоимущества от утери и кражи.
Что такое сид-фразы кошельков криптовалют?
Сид-фразы являются набор случайным образом сгенерированных слов, часто от 12 до 24, которые предназначаются для создания уникального ключа шифрования кошелька. Этот ключ используется для восстановления возможности доступа к вашему кошельку в случае его повреждения или утери. Сид-фразы обладают значительной защиты и шифруются, что делает их безопасными для хранения и передачи.
Зачем нужны сид-фразы?
Сид-фразы обязательны для обеспечения безопасности и доступности вашего криптоимущества. Они позволяют восстановить вход к кошельку в случае утери или повреждения физического устройства, на котором он хранится. Благодаря сид-фразам вы можете просто создавать резервные копии своего кошелька и хранить их в безопасном месте.
Как обеспечить безопасность сид-фраз кошельков?
Никогда не передавайте сид-фразой ни с кем. Сид-фраза является вашим ключом к кошельку, и ее раскрытие может вести к утере вашего криптоимущества.
Храните сид-фразу в секурном месте. Используйте физически секурные места, такие как банковские ячейки или специализированные аппаратные кошельки, для хранения вашей сид-фразы.
Создавайте резервные копии сид-фразы. Регулярно создавайте резервные копии вашей сид-фразы и храните их в разных безопасных местах, чтобы обеспечить доступ к вашему кошельку в случае утери или повреждения.
Используйте дополнительные меры безопасности. Включите двухфакторную верификацию и другие методы защиты для своего кошелька криптовалюты, чтобы обеспечить дополнительный уровень безопасности.
Заключение
Сид-фразы кошельков криптовалют являются ключевым элементом защищенного хранения криптоимущества. Следуйте рекомендациям по безопасности, чтобы защитить свою сид-фразу и обеспечить безопасность своих криптовалютных средств.
кошелек с балансом купить
Криптокошельки с балансом: зачем их покупают и как использовать
В мире криптовалют все расширяющуюся популярность приобретают криптокошельки с предустановленным балансом. Это специальные кошельки, которые уже содержат определенное количество криптовалюты на момент покупки. Но зачем люди приобретают такие кошельки, и как правильно использовать их?
Почему покупают криптокошельки с балансом?
Удобство: Криптокошельки с предустановленным балансом предлагаются как готовое к использованию решение для тех, кто хочет быстро начать пользоваться криптовалютой без необходимости покупки или обмена на бирже.
Подарок или награда: Иногда криптокошельки с балансом используются как подарок или премия в рамках акций или маркетинговых кампаний.
Анонимность: При покупке криптокошелька с балансом нет потребности предоставлять личные данные, что может быть важно для тех, кто ценит анонимность.
Как использовать криптокошелек с балансом?
Проверьте безопасность: Убедитесь, что кошелек безопасен и не подвержен взлому. Проверьте репутацию продавца и происхождение приобретения кошелька.
Переведите средства на другой кошелек: Если вы хотите долгосрочно хранить криптовалюту, рекомендуется перевести средства на более безопасный или практичный для вас кошелек.
Не храните все средства на одном кошельке: Для обеспечения безопасности рекомендуется распределить средства между несколькими кошельками.
Будьте осторожны с фишингом и мошенничеством: Помните, что мошенники могут пытаться обмануть вас, предлагая криптокошельки с балансом с целью получения доступа к вашим средствам.
Заключение
Криптокошельки с балансом могут быть удобным и быстрым способом начать пользоваться криптовалютой, но необходимо помнить о безопасности и осторожности при их использовании.Выбор и приобретение криптокошелька с балансом – это серьезный шаг, который требует внимания к деталям и осознанного подхода.”
Слив мнемонических фраз (seed phrases) является одной из наиболее распространенных способов утечки личной информации в мире криптовалют. В этой статье мы разберем, что такое сид фразы, почему они важны и как можно защититься от их утечки.
Что такое сид фразы?
Сид фразы, или мнемонические фразы, являются комбинацию слов, которая используется для составления или восстановления кошелька криптовалюты. Обычно сид фраза состоит из 12 или 24 слов, которые представляют собой ключ к вашему кошельку. Потеря или утечка сид фразы может влечь за собой потере доступа к вашим криптовалютным средствам.
Почему важно защищать сид фразы?
Сид фразы представляют ключевым элементом для секурного хранения криптовалюты. Если злоумышленники получат доступ к вашей сид фразе, они сумеют получить доступ к вашему кошельку и украсть все средства.
Как защититься от утечки сид фраз?
Никогда не передавайте свою сид фразу никому, даже если вам происходит, что это проверенное лицо или сервис.
Храните свою сид фразу в надежном и секурном месте. Рекомендуется использовать аппаратные кошельки или специальные программы для хранения сид фразы.
Используйте дополнительные методы защиты, такие как двухфакторная аутентификация (2FA), для усиления безопасности вашего кошелька.
Регулярно делайте резервные копии своей сид фразы и храните их в других безопасных местах.
Заключение
Слив сид фраз является существенной угрозой для безопасности владельцев криптовалют. Понимание важности защиты сид фразы и принятие соответствующих мер безопасности помогут вам избежать потери ваших криптовалютных средств. Будьте бдительны и обеспечивайте надежную защиту своей сид фразы
https://cs2lab.pro/cs-sites/
Medication information leaflet. Short-Term Effects.
can i buy fluoxetine
Best news about drug. Get here.
Meds prescribing information. Long-Term Effects.
zovirax
Everything about pills. Read information here.
can you get doxycycline pills
Окончание диплома является основным моментом во жизни каждого человека, определяющим его будущее и профессиональные перспективы.
Диплом даёт доступ двери к перспективным перспективам и возможностям, обеспечивая доступ к высококачественному образованию и высокопрестижным специальностям.
В нынешнем мире, где конкуренция на трудовом рынке всё растёт, имение диплома становится обязательным условием для выдающейся профессиональной деятельности.
Диплом подтверждает ваши знания, умения и навыки, навыки и компетенции перед работодателями и общественностью в общем.
diploman-russiya.comкупить школьный аттестат – возможность для тех, кто желает достижения успеха без лишних препятствий. Это шанс завоевать признанный документ о техническому образованию, открывающий двери к новым возможностям и престижным карьерным путям. Наш сервис обеспечивает качество и конфиденциальность, помогая вам достичь ваших целей быстро и эффективно.
В дополнение, аттестат дарует уверенность и укрепляет оценку себя, что помогает личностному росту и развитию. Получение образования также вложением в будущее, предоставляя стабильность и достойный уровень жизни.
Поэтому обращать надлежащее внимание и время образованию и стремиться к его достижению, чтобы добиться успеха и удовлетворение от собственной профессиональной деятельности.
where can i buy doxycycline in the uk
Medication information. Short-Term Effects.
minocycline price
Everything news about medicament. Get information here.
where can i get generic nemasole pills
Drug prescribing information. Cautions.
get effexor
Everything trends of drug. Get here.
how to get cheap theo 24 cr online
buy cheap trazodone price
Pills information for patients. Short-Term Effects.
get cialis super active
Some trends of medicine. Read now.
هنا النص مع استخدام السبينتاكس:
“بناء الروابط الخلفية
بعد التحديثات العديدة لمحرك البحث G، تحتاج إلى تطويق خيارات ترتيب مختلفة.
هناك شكل لجذب انتباه محركات البحث إلى موقعك على الويب باستخدام الروابط الخلفية.
الروابط الخلفية ليست فقط أداة فعالة للترويج، ولكن تحمل أيضًا حركة مرور عضوية، والمبيعات المباشرة من هذه الموارد على الأرجح غالبًا ما لا تكون كذلك، ولكن الانتقالات ستكون، وهي حركة المرور التي نحصل عليها أيضًا.
ما سوف نحصل عليه في النهاية في النهاية في الإخراج:
نعرض الموقع لمحركات البحث من خلال الروابط الخلفية.
2- نحصل على تبديلات عضوية إلى الموقع، وهي أيضًا إشارة لمحركات البحث أن المورد يستخدمه الناس.
كيف نظهر لمحركات البحث أن الموقع سائل:
1 يتم عمل وصلة خلفي للصفحة الرئيسية حيث المعلومات الرئيسية
نقوم بعمل لينكات خلفية من خلال عمليات إعادة توجيه المواقع الموثوقة
الأهم من ذلك أننا نضع الموقع على أداة منفصلة من أساليب تحليل المواقع، ويدخل الموقع في ذاكرة التخزين المؤقت لهذه المحللات، ثم الروابط المستلمة التي نضعها كتوجيه على المدونات والمنتديات والتعليقات.
هذا العملية المهم يُبرز لمحركات البحث خارطة الموقع، حيث تعرض أدوات تحليل المواقع جميع المعلومات عن المواقع مع جميع الكلمات الرئيسية والعناوين وهو أمر جيد جداً
جميع المعلومات عن خدماتنا على الموقع!
https://jobsmart24.com
can i buy generic allopurinol online
Medication information for patients. Cautions.
levaquin
All information about drugs. Get now.
get cheap imuran tablets
Allergic conjunctivitis treatment professionals
Drug information leaflet. Long-Term Effects.
lisinopril brand name
Some what you want to know about pills. Read now.
like this https://debank.lu/2023/11/11/exploring-the-risks-and-precautions-of-transferring-crypto-wallet-funds-to-a-bank-account-is-it-a-secure-option/
where can i buy generic zyrtec no prescription
Drugs information for patients. Long-Term Effects.
advair diskus
Some news about meds. Get information now.
get cheap promethazine without rx
Pills information. Short-Term Effects.
lisinopril
Some information about pills. Read information here.
Автор 24 – это превосходный сервис для покупки различных академических работ. Он работает на дипломных работах, а также чертежах. Кроме того, на платформе Автор 24 можно приобрести эссе, отчеты о прохождении практики. Это удобный способ повысить свои академические результаты.
Автор 24 официальный Автор 24 ру .
МСК проститутки devkiru.com
Если Вы хотели заказать проститутки цена в Мск, то в настоящий момент переходите на наш сайт. Мы предлагаем посмотреть самых недорогих проституток в Москве. Но в этом вопросе, цена не значит качество. Просто у девушек в этой группе не так много практики, и принимают они в апартаментах чуть дальше от центра и не очень фешенебельных. Не нужно переживать, что дешевая цена может подпортить Ваш досуг, скорее — наоборот. Возможность обалденно провести свой отдых по выгодной стоимости-в двойном размере приятнее.
cost generic allopurinol without prescription
Del Mar Energy
Платформа Автор 24 – это надежный сервис для заказа разнообразных академических работ. Он занимается на рефератах, а также задачах. Кроме того, на сервисе Автор 24 можно купить рецензии, презентации. Это эффективный способ сэкономить время.
Автор 24 официальный Автор 24 ру .
Молодые красивые девочки Москва devkiru.com
Если Вы планировали найти проститутки м домодедовская в Москве, то в настоящий момент переходите на наш сайт. Мы предлагаем заказать самых дешевых проституток в Москве. Но в этом вопросе, цена не значит плохое качество. Всего лишь у девушек в этой группе не так много стажа, и принимают они в апартаментах чуть дальше от центра Москвы и не очень роскошных. Не нужно волноваться, что невысокая цена может испортить Ваш досуг, правильнее — наоборот. Возможность обалденно провести время по выигрышной цене-в двойном размере хорошо.
Drugs information. What side effects can this medication cause?
pregabalin buy
Some news about drugs. Get here.
В современном мире, где аттестат является началом удачной карьеры в любом направлении, многие ищут максимально быстрый путь получения образования. Наличие официального документа об образовании переоценить невозможно. Ведь диплом открывает дверь перед всеми, кто хочет начать профессиональную деятельность или продолжить обучение в высшем учебном заведении.
Предлагаем очень быстро получить любой необходимый документ. Вы имеете возможность приобрести аттестат нового или старого образца, что становится удачным решением для человека, который не смог закончить обучение, потерял документ или желает исправить плохие оценки. Аттестаты изготавливаются с особой аккуратностью, вниманием ко всем деталям. На выходе вы получите полностью оригинальный документ.
Превосходство этого подхода заключается не только в том, что вы быстро получите свой аттестат. Весь процесс организовывается комфортно, с профессиональной поддержкой. Начиная от выбора нужного образца документа до точного заполнения личных данных и доставки по России — все под абсолютным контролем квалифицированных мастеров.
Всем, кто пытается найти оперативный способ получить требуемый документ, наша компания готова предложить отличное решение. Купить аттестат – значит избежать длительного процесса обучения и не теряя времени переходить к своим целям: к поступлению в университет или к началу успешной карьеры.
https://diplomans-rossians.com/
farxiga info
Medicine prescribing information. Brand names.
lisinopril pill
Everything information about medicine. Read information now.
can i buy cheap periactin
repair of household appliances
buy tetracycline pills
ireland-24.com
Select the appropriate metal material for the specific design. Strength requirements invest-building.com, corrosion resistance and other characteristics must be taken into account. It is worth contacting experienced specialists who will help you understand all the parameters.
Pills information. Cautions.
colchicine without insurance
Some trends of pills. Read now.
Thank you for great information. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
how to buy cheap doxycycline without prescription
can i purchase stromectol tablets
Hello! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Everything is very open and very clear explanation of issues. was truly information.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Hi, just required you to know I he added your site to my Google bookmarks due to your layout. But seriously, I believe your internet site has 1 in the freshest theme I??ve came across.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Everything is very open and very clear explanation of issues. was truly information.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Thank you for content. Area rugs and online home decor store. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Drug information leaflet. Cautions.
norvasc
Best news about medicament. Get information now.
After all, what a great site and informative posts, I will upload inbound link – bookmark this web site? Regards, Reader.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
where can i get cheap doxycycline without dr prescription
245real.com
egyptnews24.com
https://todayusanews24.com
https://radioshem.net
Pills prescribing information. What side effects?
metoprolol
Best information about medicine. Read here.
order cheap trazodone without insurance
where to get cheap finasteride without insurance
Everything is very open and very clear explanation of issues. was truly information.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Great post thank you. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Drugs information. What side effects?
cialis soft tabs order
Actual information about medication. Read here.
https://stroynews.info
olympic-school.com
https://maxbetasia88.net
where can i buy gabapentin cheap
pervenec.com
Заказать купленный диплом, через интернет.
Доступные цены на дипломы для продажи, подробности здесь.
Купить диплом с гарантией качества, важная информация.
Почему выгодно купить диплом, рассказываем.
Где купить диплом без проблем, на проверенных ресурсах.
Лучшие предложения по покупке диплома, интересные варианты.
Дипломы на заказ по лучшим ценам, подробности на сайте.
Покупка диплома: безопасность и конфиденциальность, наши преимущества.
Лучшие дипломы для покупки, срочно и выгодно.
Купить диплом срочно и законно, подробности у нас.
Почему стоит купить диплом у нас, гарантированное качество.
Безопасное приобретение документов об образовании, подробности на сайте.
Купить диплом без обмана, подробности у нас.
Как выбрать и купить диплом, подробности на сайте.
Как купить дипломы онлайн, гарантированная доставка.
Какой диплом выбрать для покупки, гарантированный результат.
Официальная покупка диплома, лучшие условия.
Почему стоит заказать диплом на нашем сайте, гарантированный результат.
купить диплом http://7arusak-diploms.com/ .
Medicament information. What side effects?
baclofen
Best trends of medicine. Read information here.
Купить диплом с доставкой до дома, онлайн.
Легальный способ купить диплом, подробности здесь.
Какой диплом купить, проверенные варианты.
Почему выгодно купить диплом, все секреты.
Как купить диплом безопасно, без риска.
Купить диплом по выгодной цене, интересные варианты.
Как купить диплом быстро, лучшие условия.
Скрытая покупка дипломов, наши преимущества.
Как быстро купить диплом, срочно и выгодно.
Покупка диплома: безопасность и качество, гарантированный результат.
Как выбрать диплом, лучшие цены.
Безопасное приобретение документов об образовании, без рисков.
Официальные дипломы для покупки, важные детали.
Дипломы на всех условиях, подробности на сайте.
Как купить дипломы онлайн, подробности у нас.
Купить дипломы легко, гарантированный результат.
Купить диплом с доставкой по всему миру, подробности здесь.
Как купить диплом безопасно и быстро, подробности у нас.
купить диплом https://www.7arusak-diploms.com/ .
https://maxbetasia88.net
2fight.info
Купить диплом с доставкой до дома, онлайн.
Легальный способ купить диплом, без заморочек.
Какой диплом купить, важная информация.
Опыт успешной покупки диплома, подробности.
Где купить диплом без проблем, без риска.
Лучшие предложения по покупке диплома, интересные варианты.
Как купить диплом быстро, спешите.
Почему стоит купить диплом, проверенные решения.
Лучшие дипломы для покупки, срочно и выгодно.
Покупка диплома: безопасность и качество, подробности у нас.
Официальные документы для покупки, лучшие цены.
Безопасное приобретение документов об образовании, без рисков.
Купить диплом без обмана, важные детали.
Купить диплом просто, важные моменты.
Легальная покупка дипломов безопасно, гарантированная доставка.
Почему стоит купить диплом здесь и сейчас, интересные варианты.
Купить диплом с доставкой по всему миру, подробности здесь.
Как купить диплом безопасно и быстро, гарантированный результат.
купить диплом https://7arusak-diploms.com .
Medication information. Cautions.
lyrica for sale
Everything news about medicines. Get here.
https://oda-radio.com
дробеструйная камера купить https://drobestruynaya-kamera.ru .
Meds prescribing information. Brand names.
celebrex
Best what you want to know about medication. Read here.
RGBET
Cá Cược Thể Thao Trực Tuyến RGBET
Thể thao trực tuyến RGBET cung cấp thông tin cá cược thể thao mới nhất, như tỷ số bóng đá, bóng rổ, livestream và dữ liệu trận đấu. Đến với RGBET, bạn có thể tham gia chơi tại sảnh thể thao SABA, PANDA SPORT, CMD368, WG và SBO. Khám phá ngay!
Giới Thiệu Sảnh Cá Cược Thể Thao Trực Tuyến
Những sự kiện thể thao đa dạng, phủ sóng toàn cầu và cách chơi đa dạng mang đến cho người chơi tỷ lệ cá cược thể thao hấp dẫn nhất, tạo nên trải nghiệm cá cược thú vị và thoải mái.
Sảnh Thể Thao SBOBET
SBOBET, thành lập từ năm 1998, đã nhận được giấy phép cờ bạc trực tuyến từ Philippines, Đảo Man và Ireland. Tính đến nay, họ đã trở thành nhà tài trợ cho nhiều CLB bóng đá. Hiện tại, SBOBET đang hoạt động trên nhiều nền tảng trò chơi trực tuyến khắp thế giới.
Xem Chi Tiết »
Sảnh Thể Thao SABA
Saba Sports (SABA) thành lập từ năm 2008, tập trung vào nhiều hoạt động thể thao phổ biến để tạo ra nền tảng thể thao chuyên nghiệp và hoàn thiện. SABA được cấp phép IOM hợp pháp từ Anh và mang đến hơn 5.000 giải đấu thể thao đa dạng mỗi tháng.
Xem Chi Tiết »
Sảnh Thể Thao CMD368
CMD368 nổi bật với những ưu thế cạnh tranh, như cung cấp cho người chơi hơn 20.000 trận đấu hàng tháng, đến từ 50 môn thể thao khác nhau, đáp ứng nhu cầu của tất cả các fan hâm mộ thể thao, cũng như thoả mãn mọi sở thích của người chơi.
Xem Chi Tiết »
Sảnh Thể Thao PANDA SPORT
OB Sports đã chính thức đổi tên thành “Panda Sports”, một thương hiệu lớn với hơn 30 giải đấu bóng. Panda Sports đặc biệt chú trọng vào tính năng cá cược thể thao, như chức năng “đặt cược sớm và đặt cược trực tiếp tại livestream” độc quyền.
Xem Chi Tiết »
Sảnh Thể Thao WG
WG Sports tập trung vào những môn thể thao không quá được yêu thích, với tỷ lệ cược cao và xử lý đơn cược nhanh chóng. Đặc biệt, nhiều nhà cái hàng đầu trên thị trường cũng hợp tác với họ, trở thành là một trong những sảnh thể thao nổi tiếng trên toàn cầu.
Xem Chi Tiết »
https://financenewsasia.com
Drugs information for patients. Generic Name.
tizanidine
Everything about meds. Read here.
Заказать купленный диплом, не выходя из дома.
Как купить диплом без риска, без заморочек.
Купить диплом с гарантией качества, советы от профессионалов.
Опыт успешной покупки диплома, все секреты.
Купить диплом легко, без риска.
Как выбрать диплом для покупки, важные моменты.
Как купить диплом быстро, подробности на сайте.
Почему стоит купить диплом, проверенные решения.
Лучшие дипломы для покупки, подробности на сайте.
Как купить диплом онлайн, подробности у нас.
Официальные документы для покупки, срочные варианты.
Безопасное приобретение документов об образовании, без рисков.
Официальные дипломы для покупки, важные детали.
Как выбрать и купить диплом, лучшие предложения.
Как купить дипломы онлайн, безопасность на первом месте.
Купить дипломы легко, гарантированный результат.
Купить диплом с доставкой по всему миру, лучшие условия.
Почему стоит заказать диплом на нашем сайте, гарантированный результат.
купить диплом 7arusak-diploms.com .
Medication information leaflet. Cautions.
where can i buy cheap zyban prices
Some news about pills. Read here.
Приветствую, поклонники рискованных приключений! Хочу делиться своим восторгом от цифрового заведения “официальный сайт казино селектор”. Это не всего лишь веб-сайт для игр, это абсолютный мир переживаний и занимательностей! Здесь я обнаружил все, что мне требуется: разнообразие игр, великодушные бонусы и быстрые выплаты. Но первостепенное – это настроение, которая витает здесь. Цифровые приключения, удивительные турниры и милосердное сообщество игроков делают каждую игру беззабвенной! Присоедините к “официальный сайт казино селектор” и погрузитесь в мир интригующих развлечений!
https://zamkiexpress.ru/
Заказать купленный диплом, не выходя из дома.
Как купить диплом без риска, подробности здесь.
Купить диплом с гарантией качества, советы от профессионалов.
Опыт успешной покупки диплома, все секреты.
Как купить диплом безопасно, с гарантией.
Купить диплом по выгодной цене, важные моменты.
Дипломы на заказ по лучшим ценам, спешите.
Покупка диплома: безопасность и конфиденциальность, важная информация.
Где купить действующий диплом, подробности на сайте.
Купить диплом срочно и законно, лучшие условия.
Как выбрать диплом, гарантированное качество.
Как купить диплом срочно, без рисков.
Почему стоит заказать диплом, важные детали.
Как выбрать и купить диплом, подробности на сайте.
Купить диплом без риска, гарантированная доставка.
Купить дипломы легко, гарантированный результат.
Официальная покупка диплома, лучшие условия.
Официальный документ об образовании, подробности у нас.
купить диплом https://7arusak-diploms.com/ .
Drug information sheet. Long-Term Effects.
how to get generic zyban prices
Actual trends of drug. Read now.
국외선물의 출발 골드리치와 함께하세요.
골드리치는 오랜기간 투자자분들과 더불어 선물시장의 진로을 공동으로 걸어왔으며, 고객분들의 보장된 투자 및 높은 수익률을 향해 계속해서 전력을 다하고 있습니다.
왜 20,000+인 이상이 골드리치와 동참하나요?
빠른 솔루션: 간단하며 빠른속도의 프로세스를 갖추어 어느누구라도 수월하게 활용할 수 있습니다.
안전 프로토콜: 국가기관에서 적용한 상위 등급의 보안을 채택하고 있습니다.
스마트 인가: 전체 거래내용은 부호화 보호되어 본인 이외에는 그 누구도 정보를 확인할 수 없습니다.
안전 수익성 공급: 위험 부분을 줄여, 보다 한층 보장된 수익률을 제시하며 이에 따른 리포트를 공유합니다.
24 / 7 상시 고객상담: 연중무휴 24시간 실시간 지원을 통해 고객님들을 모두 지원합니다.
협력하는 동반사: 골드리치증권는 공기업은 물론 금융계들 및 다수의 협력사와 공동으로 동행해오고.
외국선물이란?
다양한 정보를 알아보세요.
외국선물은 국외에서 거래되는 파생상품 중 하나로, 지정된 기반자산(예시: 주식, 화폐, 상품 등)을 바탕로 한 옵션계약 계약을 지칭합니다. 근본적으로 옵션은 특정 기초자산을 미래의 특정한 시기에 정해진 금액에 사거나 팔 수 있는 자격을 허락합니다. 외국선물옵션은 이러한 옵션 계약이 외국 시장에서 거래되는 것을 지칭합니다.
해외선물은 크게 매수 옵션과 풋 옵션으로 분류됩니다. 매수 옵션은 지정된 기초자산을 미래에 정해진 가격에 사는 권리를 허락하는 반면, 풋 옵션은 명시된 기초자산을 미래에 일정 금액에 팔 수 있는 권리를 부여합니다.
옵션 계약에서는 미래의 특정 일자에 (만료일이라 지칭되는) 정해진 금액에 기초자산을 사거나 매도할 수 있는 권리를 보유하고 있습니다. 이러한 가격을 실행 가격이라고 하며, 만료일에는 해당 권리를 실행할지 여부를 결정할 수 있습니다. 따라서 옵션 계약은 투자자에게 향후의 시세 변동에 대한 보호나 이익 실현의 기회를 제공합니다.
해외선물은 시장 참가자들에게 다양한 투자 및 차익거래 기회를 제공, 외환, 상품, 주식 등 다양한 자산군에 대한 옵션 계약을 포함할 수 있습니다. 거래자는 풋 옵션을 통해 기초자산의 하향에 대한 보호를 받을 수 있고, 콜 옵션을 통해 상승장에서의 이익을 노릴 수 있습니다.
국외선물 거래의 원리
행사 금액(Exercise Price): 해외선물에서 행사 금액은 옵션 계약에 따라 지정된 금액으로 약정됩니다. 만료일에 이 금액을 기준으로 옵션을 실현할 수 있습니다.
만기일(Expiration Date): 옵션 계약의 만기일은 옵션의 실행이 불가능한 마지막 날짜를 뜻합니다. 이 날짜 이후에는 옵션 계약이 종료되며, 더 이상 거래할 수 없습니다.
풋 옵션(Put Option)과 매수 옵션(Call Option): 풋 옵션은 기초자산을 명시된 금액에 팔 수 있는 권리를 부여하며, 콜 옵션은 기초자산을 명시된 가격에 사는 권리를 허락합니다.
옵션료(Premium): 국외선물 거래에서는 옵션 계약에 대한 프리미엄을 지불해야 합니다. 이는 옵션 계약에 대한 비용으로, 시장에서의 수요량와 공급량에 따라 변경됩니다.
행사 방안(Exercise Strategy): 거래자는 만기일에 옵션을 실행할지 여부를 판단할 수 있습니다. 이는 마켓 상황 및 거래 전략에 따라 다르며, 옵션 계약의 이익을 극대화하거나 손해를 최소화하기 위해 선택됩니다.
마켓 리스크(Market Risk): 해외선물 거래는 마켓의 변화추이에 영향을 받습니다. 시세 변화이 예상치 못한 방향으로 일어날 경우 손실이 발생할 수 있으며, 이러한 시장 리스크를 축소하기 위해 거래자는 계획을 수립하고 투자를 설계해야 합니다.
골드리치와 함께하는 국외선물은 보장된 믿을만한 수 있는 투자를 위한 최적의 선택입니다. 회원님들의 투자를 지지하고 안내하기 위해 우리는 최선을 다하고 있습니다. 공동으로 더 나은 미래를 지향하여 나아가요.
Medicament information sheet. Long-Term Effects.
cipro without dr prescription
Best information about drugs. Read here.
I really love to read such an excellent article. Helpful article. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
investnews24.net
Medicine information for patients. What side effects can this medication cause?
lisinopril advil interaction
Everything news about pills. Read here.
https://zamkiexpress.ru/
Thank you for great article. Hello Administ .Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Medicine information leaflet. Short-Term Effects.
cost of zyban prices
Everything about drugs. Read now.
https://zamkiexpress.ru/
Medicament information for patients. What side effects?
avodart generic
Actual about medicine. Get here.
Medicines prescribing information. What side effects?
how can i get cheap zyban price
All information about meds. Get now.
world-news-365.com
https://tzona.org
Rikvip Club: Trung Tâm Giải Trí Trực Tuyến Hàng Đầu tại Việt Nam
Rikvip Club là một trong những nền tảng giải trí trực tuyến hàng đầu tại Việt Nam, cung cấp một loạt các trò chơi hấp dẫn và dịch vụ cho người dùng. Cho dù bạn là người dùng iPhone hay Android, Rikvip Club đều có một cái gì đó dành cho mọi người. Với sứ mạng và mục tiêu rõ ràng, Rikvip Club luôn cố gắng cung cấp những sản phẩm và dịch vụ tốt nhất cho khách hàng, tạo ra một trải nghiệm tiện lợi và thú vị cho người chơi.
Sứ Mạng và Mục Tiêu của Rikvip
Từ khi bắt đầu hoạt động, Rikvip Club đã có một kế hoạch kinh doanh rõ ràng, luôn nỗ lực để cung cấp cho khách hàng những sản phẩm và dịch vụ tốt nhất và tạo điều kiện thuận lợi nhất cho người chơi truy cập. Nhóm quản lý của Rikvip Club có những mục tiêu và ước muốn quyết liệt để biến Rikvip Club thành trung tâm giải trí hàng đầu trong lĩnh vực game đổi thưởng trực tuyến tại Việt Nam và trên toàn cầu.
Trải Nghiệm Live Casino
Rikvip Club không chỉ nổi bật với sự đa dạng của các trò chơi đổi thưởng mà còn với các phòng trò chơi casino trực tuyến thu hút tất cả người chơi. Môi trường này cam kết mang lại trải nghiệm chuyên nghiệp với tính xanh chín và sự uy tín không thể nghi ngờ. Đây là một sân chơi lý tưởng cho những người yêu thích thách thức bản thân và muốn tận hưởng niềm vui của chiến thắng. Với các sảnh cược phổ biến như Roulette, Sic Bo, Dragon Tiger, người chơi sẽ trải nghiệm những cảm xúc độc đáo và đặc biệt khi tham gia vào casino trực tuyến.
Phương Thức Thanh Toán Tiện Lợi
Rikvip Club đã được trang bị những công nghệ thanh toán tiên tiến ngay từ đầu, mang lại sự thuận tiện và linh hoạt cho người chơi trong việc sử dụng hệ thống thanh toán hàng ngày. Hơn nữa, Rikvip Club còn tích hợp nhiều phương thức giao dịch khác nhau để đáp ứng nhu cầu đa dạng của người chơi: Chuyển khoản Ngân hàng, Thẻ cào, Ví điện tử…
Kết Luận
Tóm lại, Rikvip Club không chỉ là một nền tảng trò chơi, mà còn là một cộng đồng nơi người chơi có thể tụ tập để tận hưởng niềm vui của trò chơi và cảm giác hồi hộp khi chiến thắng. Với cam kết cung cấp những sản phẩm và dịch vụ tốt nhất, Rikvip Club chắc chắn là điểm đến lý tưởng cho những người yêu thích trò chơi trực tuyến tại Việt Nam và cả thế giới.
Medicament information for patients. What side effects can this medication cause?
buying cheap glucophage without prescription
All trends of meds. Get now.
Pills information sheet. Effects of Drug Abuse.
pregabalin without rx
Best news about meds. Get here.
Hi, just required you to know I he added your site to my Google bookmarks due to your layout. But seriously, I believe your internet site has 1 in the freshest theme I??ve came across.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Everything is very open and very clear explanation of issues. was truly information.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Medicines information sheet. Effects of Drug Abuse.
generic kamagra
All about medicine. Get information now.
Among these, certain icons stand out for their ubiquitous presence and importance in our daily digital interactions. This article delves into a variety of such icons, including the email, safari (web browser), location, discord, settings, Christmas, messages, spotify, person, and home icons, exploring their significance and evolution christmas icon
Купить диплом с доставкой до дома, не выходя из дома.
Как купить диплом без риска, подробности здесь.
Какой диплом купить, важная информация.
Преимущества покупки диплома, подробности.
Как купить диплом безопасно, без риска.
Как выбрать диплом для покупки, интересные варианты.
Как купить диплом быстро, спешите.
Почему стоит купить диплом, важная информация.
Где купить действующий диплом, подробности на сайте.
Как купить диплом онлайн, гарантированный результат.
Официальные документы для покупки, гарантированное качество.
Как купить диплом срочно, подробности на сайте.
Почему стоит заказать диплом, подробности у нас.
Как выбрать и купить диплом, важные моменты.
Как купить дипломы онлайн, подробности у нас.
Почему стоит купить диплом здесь и сейчас, гарантированный результат.
Купить диплом с доставкой по всему миру, подробности здесь.
Официальный документ об образовании, безопасность на первом месте.
купить диплом 7arusak-diploms.com .
Bu oyun gercekten harika! Grafikler en ust seviye, konu ilk lansmandan itibaren buyuleyici ve oyun o kadar heyecan verici ki, y?rt?lmas? imkans?z. Gelistiriciler gercekten benzersiz ve ilginc bir sey yaratmaya cal?st?. Dunyan?n ayr?nt?lar? ve detayland?r?lmas? ozellikle sevindiricidir. Henuz oynamad?ysan?z mutlaka deneyin – paribahis.me; pisman olmayacaks?n?z!
해외선물의 시작 골드리치증권와 동행하세요.
골드리치증권는 장구한기간 회원분들과 더불어 선물시장의 행로을 함께 걸어왔으며, 회원님들의 확실한 자금운용 및 알찬 수익성을 향해 항상 최선을 기울이고 있습니다.
무엇때문에 20,000+명 이상이 골드리치증권와 동참하나요?
즉각적인 대응: 편리하고 빠른속도의 프로세스를 제공하여 모두 수월하게 이용할 수 있습니다.
보안 프로토콜: 국가당국에서 적용한 상위 등급의 보안체계을 적용하고 있습니다.
스마트 인가절차: 전체 거래데이터은 암호화 가공되어 본인 이외에는 그 누구도 정보를 열람할 수 없습니다.
보장된 수익률 마련: 리스크 부분을 감소시켜, 보다 더 확실한 수익률을 제시하며 그에 따른 리포트를 공유합니다.
24 / 7 실시간 고객지원: 연중무휴 24시간 즉각적인 상담을 통해 고객님들을 전체 서포트합니다.
함께하는 파트너사: 골드리치는 공기업은 물론 금융계들 및 많은 협력사와 공동으로 동행해오고.
해외선물이란?
다양한 정보를 참고하세요.
외국선물은 해외에서 거래되는 파생상품 중 하나로, 특정 기초자산(예: 주식, 화폐, 상품 등)을 바탕로 한 옵션계약 약정을 지칭합니다. 본질적으로 옵션은 명시된 기초자산을 미래의 특정한 시기에 일정 가격에 사거나 매도할 수 있는 권리를 부여합니다. 해외선물옵션은 이러한 옵션 계약이 외국 시장에서 거래되는 것을 지칭합니다.
국외선물은 크게 콜 옵션과 매도 옵션으로 나뉩니다. 매수 옵션은 특정 기초자산을 미래에 정해진 가격에 사는 권리를 부여하는 반면, 풋 옵션은 특정 기초자산을 미래에 일정 금액에 팔 수 있는 권리를 제공합니다.
옵션 계약에서는 미래의 명시된 날짜에 (만기일이라 칭하는) 일정 가격에 기초자산을 매수하거나 매도할 수 있는 권리를 가지고 있습니다. 이러한 가격을 행사 금액이라고 하며, 종료일에는 해당 권리를 실행할지 여부를 선택할 수 있습니다. 따라서 옵션 계약은 투자자에게 향후의 시세 변화에 대한 보호나 이익 창출의 기회를 부여합니다.
외국선물은 마켓 참가자들에게 다양한 투자 및 매매거래 기회를 열어주며, 환율, 상품, 주식 등 다양한 자산군에 대한 옵션 계약을 망라할 수 있습니다. 투자자는 풋 옵션을 통해 기초자산의 하락에 대한 안전장치를 받을 수 있고, 매수 옵션을 통해 활황에서의 수익을 노릴 수 있습니다.
외국선물 거래의 원리
행사 가격(Exercise Price): 외국선물에서 실행 금액은 옵션 계약에 따라 지정된 금액으로 계약됩니다. 만료일에 이 금액을 기준으로 옵션을 행사할 수 있습니다.
만료일(Expiration Date): 옵션 계약의 만료일은 옵션의 실행이 불가능한 최종 날짜를 의미합니다. 이 일자 이후에는 옵션 계약이 소멸되며, 더 이상 거래할 수 없습니다.
풋 옵션(Put Option)과 매수 옵션(Call Option): 풋 옵션은 기초자산을 명시된 금액에 팔 수 있는 권리를 부여하며, 매수 옵션은 기초자산을 명시된 가격에 사는 권리를 허락합니다.
옵션료(Premium): 해외선물 거래에서는 옵션 계약에 대한 계약료을 납부해야 합니다. 이는 옵션 계약에 대한 가격으로, 시장에서의 수요량와 공급에 따라 변경됩니다.
실행 방안(Exercise Strategy): 투자자는 종료일에 옵션을 행사할지 여부를 선택할 수 있습니다. 이는 마켓 환경 및 투자 플랜에 따라 차이가있으며, 옵션 계약의 이익을 최대화하거나 손실을 감소하기 위해 판단됩니다.
마켓 리스크(Market Risk): 외국선물 거래는 마켓의 변화추이에 영향을 받습니다. 가격 변화이 기대치 못한 진로으로 일어날 경우 손실이 발생할 수 있으며, 이러한 시장 위험요인를 축소하기 위해 거래자는 계획을 수립하고 투자를 계획해야 합니다.
골드리치증권와 함께하는 해외선물은 보장된 믿을만한 수 있는 투자를 위한 최상의 선택입니다. 회원님들의 투자를 뒷받침하고 인도하기 위해 우리는 전력을 다하고 있습니다. 함께 더 나은 내일를 지향하여 계속해나가세요.
construction-rent.com
https://jaycitynews.com
Meds prescribing information. Brand names.
avodart
Some news about medicines. Get information here.
Интернет-магазин, где можно найти комод для ванной комнаты напольный без раковины для любого интерьера и бюджета.
Thank you for content. Area rugs and online home decor store. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Hi, just required you to know I he added your site to my Google bookmarks due to your layout. But seriously, I believe your internet site has 1 in the freshest theme I??ve came across.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Good info. Lucky me I reach on your website by accident, I bookmarked it. Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
На сегодняшний день, когда аттестат – это начало отличной карьеры в любом направлении, многие ищут максимально быстрый путь получения качественного образования. Наличие официального документа сложно переоценить. Ведь диплом открывает двери перед всеми, кто хочет вступить в сообщество профессионалов или учиться в университете.
В данном контексте наша компания предлагает быстро получить этот необходимый документ. Вы сможете заказать аттестат старого или нового образца, что становится отличным решением для всех, кто не смог завершить образование или утратил документ. Аттестаты выпускаются с особой тщательностью, вниманием к мельчайшим деталям. В результате вы получите 100% оригинальный документ.
Преимущество такого решения заключается не только в том, что можно оперативно получить аттестат. Весь процесс организовывается удобно, с профессиональной поддержкой. От выбора требуемого образца до консультаций по заполнению личных данных и доставки в любое место России — все под полным контролем квалифицированных специалистов.
В итоге, для всех, кто пытается найти быстрый и простой способ получения требуемого документа, наша компания может предложить выгодное решение. Приобрести аттестат – значит избежать долгого процесса обучения и сразу перейти к достижению своих целей, будь то поступление в ВУЗ или старт успешной карьеры.
http://www.vsediplomu.ru/
kw bocor88
Medicine information. What side effects can this medication cause?
cost of furosemide
Everything about medicament. Read information now.
экстренное открытие замков http://www.vskrytie-zamkov-moskva111.ru/ .
https://newsprofit.info
emergate.net
Medicine information leaflet. What side effects?
norvasc
Some information about drugs. Get now.
I always was concerned in this topic and stock still am, appreciate it for posting.
Телесериал «911 служба спасения» про доблестных и храбрых спасателей, служба которых тяжелая и несет опасность с каждым вызовом. Герои службы 911 все смелые и храбрые в каждой серии сериала спасают жизни людям. Все персонажи сериала разные по характеру, но это не мешает им дружить и работать слаженной командой Читать
Pills information. Effects of Drug Abuse.
pregabalin
Actual about medicines. Read now.
продвижение сайта раскрутка оптимизация сайта продвижение сайта раскрутка оптимизация сайта .
해외선물의 개시 골드리치증권와 동참하세요.
골드리치는 길고긴기간 회원분들과 함께 선물마켓의 길을 공동으로 걸어왔으며, 투자자분들의 안전한 자금운용 및 높은 이익률을 향해 계속해서 최선을 다하고 있습니다.
무엇때문에 20,000+인 초과이 골드리치증권와 동참하나요?
신속한 솔루션: 쉽고 빠른 프로세스를 마련하여 모두 용이하게 이용할 수 있습니다.
안전보장 프로토콜: 국가기관에서 적용한 상위 등급의 보안시스템을 도입하고 있습니다.
스마트 인가: 모든 거래내용은 암호처리 처리되어 본인 외에는 아무도 누구도 내용을 확인할 수 없습니다.
보장된 이익률 공급: 위험 부분을 감소시켜, 보다 한층 확실한 수익률을 제공하며 이에 따른 리포트를 제공합니다.
24 / 7 지속적인 고객센터: året runt 24시간 즉각적인 상담을 통해 회원분들을 온전히 서포트합니다.
함께하는 협력사: 골드리치는 공기업은 물론 금융권들 및 다수의 협력사와 함께 여정을 했습니다.
해외선물이란?
다양한 정보를 확인하세요.
외국선물은 외국에서 거래되는 파생상품 중 하나로, 지정된 기초자산(예: 주식, 화폐, 상품 등)을 기초로 한 옵션계약 약정을 의미합니다. 기본적으로 옵션은 명시된 기초자산을 향후의 특정한 시기에 정해진 가격에 사거나 매도할 수 있는 자격을 제공합니다. 외국선물옵션은 이러한 옵션 계약이 국외 시장에서 거래되는 것을 의미합니다.
국외선물은 크게 콜 옵션과 풋 옵션으로 구분됩니다. 매수 옵션은 특정 기초자산을 미래에 일정 금액에 사는 권리를 제공하는 반면, 매도 옵션은 명시된 기초자산을 미래에 정해진 가격에 팔 수 있는 권리를 부여합니다.
옵션 계약에서는 미래의 명시된 일자에 (만기일이라 불리는) 정해진 금액에 기초자산을 사거나 팔 수 있는 권리를 가지고 있습니다. 이러한 금액을 행사 가격이라고 하며, 종료일에는 해당 권리를 실행할지 여부를 결정할 수 있습니다. 따라서 옵션 계약은 거래자에게 향후의 시세 변화에 대한 보호나 수익 창출의 기회를 제공합니다.
외국선물은 시장 참가자들에게 다양한 투자 및 차익거래 기회를 열어주며, 환율, 상품, 주식 등 다양한 자산군에 대한 옵션 계약을 포괄할 수 있습니다. 투자자는 풋 옵션을 통해 기초자산의 하향에 대한 안전장치를 받을 수 있고, 매수 옵션을 통해 활황에서의 이익을 노릴 수 있습니다.
국외선물 거래의 원리
행사 가격(Exercise Price): 해외선물에서 실행 가격은 옵션 계약에 따라 명시된 금액으로 약정됩니다. 종료일에 이 금액을 기준으로 옵션을 실행할 수 있습니다.
만기일(Expiration Date): 옵션 계약의 만료일은 옵션의 실행이 불가능한 마지막 일자를 의미합니다. 이 날짜 이후에는 옵션 계약이 소멸되며, 더 이상 거래할 수 없습니다.
매도 옵션(Put Option)과 매수 옵션(Call Option): 풋 옵션은 기초자산을 지정된 가격에 팔 수 있는 권리를 부여하며, 콜 옵션은 기초자산을 명시된 금액에 사는 권리를 제공합니다.
옵션료(Premium): 해외선물 거래에서는 옵션 계약에 대한 계약료을 지불해야 합니다. 이는 옵션 계약에 대한 비용으로, 마켓에서의 수요량와 공급에 따라 변경됩니다.
실행 방식(Exercise Strategy): 거래자는 만기일에 옵션을 실행할지 여부를 결정할 수 있습니다. 이는 마켓 상황 및 투자 전략에 따라 차이가있으며, 옵션 계약의 이익을 극대화하거나 손해를 최소화하기 위해 결정됩니다.
시장 리스크(Market Risk): 국외선물 거래는 시장의 변동성에 영향을 받습니다. 시세 변동이 기대치 못한 진로으로 발생할 경우 손실이 발생할 수 있으며, 이러한 마켓 위험요인를 최소화하기 위해 거래자는 전략을 구축하고 투자를 설계해야 합니다.
골드리치와 함께하는 외국선물은 보장된 믿을만한 수 있는 투자를 위한 가장좋은 옵션입니다. 고객님들의 투자를 지지하고 인도하기 위해 우리는 전력을 기울이고 있습니다. 함께 더 나은 내일를 향해 나아가요.
Интернет-ресурс, где можно купить элегантные раковины roca berna от ведущих производителей.
Drug information for patients. Long-Term Effects.
diltiazem
Everything trends of drugs. Read now.
ทดลองเล่นสล็อต
Индексация ссылок на сайте vindexe
Drugs prescribing information. Generic Name.
lisinopril
Everything news about meds. Read information here.
Medication prescribing information. Brand names.
stromectol order
Best trends of meds. Read information here.
Мы предлагаем комплексные решения для навес для машины на участке.
Medicines information. What side effects?
tamsulosin
Actual information about drug. Read now.
С деревянный навес к дому ваш автомобиль всегда будет под защитой.
raja118
Мы гарантируем долговечность и надежность наших навес с двускатной крышей.
Medicines information sheet. Cautions.
gabapentin
Everything trends of drugs. Read information here.
Мы предлагаем только сертифицированные готовый навес купить.
link kantor bola
Мы предлагаем только сертифицированные навес для авто из профильной трубы 4 6.
Medication information for patients. Cautions.
avodart generic
Actual trends of meds. Read now.
Индексация ссылок на сайте vindexe.ru
Thank you for content. Area rugs and online home decor store. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Индексация ссылок на сайте индекс гугл ру
Medicine information sheet. Drug Class.
atorvastatin medication
All news about medicines. Get information now.
Medicine information sheet. Cautions.
buy generic pregabalin
All trends of medicine. Read information here.
Pills information sheet. Long-Term Effects.
colchicine without dr prescription
Best information about medicines. Read information now.
Great post thank you. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Drugs prescribing information. Effects of Drug Abuse.
clonidine
Everything information about medicine. Read information now.
I really love to read such an excellent article. Helpful article. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Thank you for great content. Hello Administ. Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Hello! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Hi, just required you to know I he added your site to my Google bookmarks due to your layout. But seriously, I believe your internet site has 1 in the freshest theme I??ve came across.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Thank you great post. Hello Administ .Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Замена венцов красноярск
Геракл24: Профессиональная Смена Фундамента, Венцов, Полов и Перенос Зданий
Организация Геракл24 специализируется на оказании комплексных сервисов по замене фундамента, венцов, полов и перемещению строений в месте Красноярском регионе и за пределами города. Наша команда профессиональных мастеров обещает превосходное качество исполнения всех типов ремонтных работ, будь то из дерева, с каркасом, кирпичные постройки или из бетона здания.
Преимущества сотрудничества с Геракл24
Квалификация и стаж:
Каждая задача проводятся исключительно профессиональными специалистами, с многолетним большой стаж в направлении создания и реставрации домов. Наши сотрудники профессионалы в своем деле и выполняют работу с высочайшей точностью и вниманием к мелочам.
Комплексный подход:
Мы предоставляем разнообразные услуги по восстановлению и ремонту домов:
Реставрация фундамента: замена и укрепление фундамента, что гарантирует долговечность вашего здания и избежать проблем, связанные с оседанием и деформацией строения.
Смена венцов: реставрация нижних венцов из дерева, которые наиболее часто подвергаются гниению и разрушению.
Установка новых покрытий: установка новых полов, что существенно улучшает внешний облик и функциональные характеристики.
Перенос строений: безопасное и качественное передвижение домов на новые места, что помогает сохранить здание и избегает дополнительных затрат на строительство нового.
Работа с любыми видами зданий:
Древесные строения: восстановление и защита деревянных строений, защита от гниения и вредителей.
Дома с каркасом: укрепление каркасов и замена поврежденных элементов.
Кирпичные строения: реставрация кирпичной кладки и укрепление стен.
Бетонные строения: ремонт и укрепление бетонных конструкций, ремонт трещин и дефектов.
Качество и надежность:
Мы работаем с только проверенные материалы и современное оборудование, что гарантирует долговечность и надежность всех работ. Все проекты проходят строгий контроль качества на каждом этапе выполнения.
Индивидуальный подход:
Мы предлагаем каждому клиенту индивидуальные решения, с учетом всех особенностей и пожеланий. Мы стараемся, чтобы итог нашей работы полностью удовлетворял вашим запросам и желаниям.
Зачем обращаться в Геракл24?
Сотрудничая с нами, вы найдете надежного партнера, который берет на себя все заботы по восстановлению и ремонту вашего здания. Мы гарантируем выполнение всех проектов в установленные сроки и с соблюдением всех правил и норм. Выбрав Геракл24, вы можете не сомневаться, что ваше здание в надежных руках.
Мы всегда готовы проконсультировать и дать ответы на все вопросы. Звоните нам, чтобы обсудить детали вашего проекта и узнать больше о наших услугах. Мы обеспечим сохранение и улучшение вашего дома, сделав его безопасным и комфортным для проживания на долгие годы.
Геракл24 – ваш выбор для реставрации и ремонта домов в Красноярске и области.
Drug information leaflet. Brand names.
baclofen
Best what you want to know about medication. Get information now.
Drugs information leaflet. What side effects?
escitalopram generics
Everything about medicines. Read information here.
стоимость такси в новочеркасске http://www.taksi-vyzvat.ru/ .
Medicines prescribing information. What side effects can this medication cause?
can i buy generic zyban pill
Best information about drugs. Get information here.
Drugs information for patients. Short-Term Effects.
zenegra tablets
Best information about drug. Get information now.
Medicament information for patients. Long-Term Effects.
pictures of lisinopril hctz tablets
Best about meds. Get information here.
заказать такси номер заказ такси недорого .
такси недорого цены стоимость такси в новочеркасске .
вызов такси в новочеркасске такси заказ эконом по телефону .
номер телефона такси заказать такси .
заказать такси недорого такси цена .
сколько будет стоить такси служба такси телефон .
стоимость поездки на такси такси бизнес класс .
номер телефона такси дешевое такси телефон .
Meds information. Generic Name.
metformin without a prescription drug
Some trends of medicament. Get information here.
служба такси https://vyzvat-taksi.ru .
טלגראס הינה אפליקציה נפוצה בישראל לרכישת קנאביס באופן מקוון. זו נותנת ממשק נוח ובטוח לקנייה ולקבלת משלוחים מ פריטי צמח הקנאביס מרובים. בכתבה זו נסקור עם העיקרון מאחורי האפליקציה, איך היא פועלת ומה המעלות של השימוש בזו.
מהי האפליקציה?
האפליקציה מהווה דרך לקנייה של קנאביס דרך היישומון טלגרם. זו נשענת מעל ערוצי תקשורת וקבוצות טלגרם מיוחדות הקרויות ״טלגראס כיוונים, שבהם ניתן להזמין מגוון מוצרי צמח הקנאביס ולקבלת אלו ישירותית לשילוח. הערוצים האלה מסודרים לפי איזורים גאוגרפיים, כדי להקל על קבלתם של המשלוחים.
כיצד זה פועל?
התהליך פשוט למדי. קודם כל, יש להצטרף לערוץ טלגראס הנוגע לאזור המחיה. שם אפשר לעיין בתפריטים של הפריטים המגוונים ולהרכיב עם הפריטים המבוקשים. לאחר ביצוע ההרכבה וסגירת התשלום, השליח יופיע בכתובת שנרשמה עם הארגז שהוזמן.
מרבית ערוצי הטלגראס מספקים טווח נרחב של פריטים – סוגי צמח הקנאביס, ממתקים, שתייה ועוד. כמו כן, ניתן לראות חוות דעת מ לקוחות שעברו לגבי איכות הפריטים והשירות.
יתרונות השימוש באפליקציה
מעלה מרכזי מ האפליקציה הוא הנוחות והדיסקרטיות. ההרכבה וההכנות מתבצעות ממרחק מאיזשהו מיקום, בלי נחיצות במפגש פנים אל פנים. כמו כן, הפלטפורמה מאובטחת היטב ומבטיחה חיסיון גבוה.
מלבד על כך, עלויות הפריטים בטלגראס נוטות להיות זולים, והשילוחים מגיעים במהירות ובמסירות רבה. קיים גם מרכז תמיכה פתוח לכל שאלה או בעיה.
סיכום
טלגראס מהווה שיטה מקורית ויעילה לרכוש פריטי מריחואנה במדינה. היא משלבת את הנוחות הטכנולוגית מ האפליקציה הפופולרית, ועם הזריזות והדיסקרטיות מ דרך המשלוח הישירה. ככל שהדרישה לקנאביס גדלה, אפליקציות כמו זו צפויות להמשיך ולהתפתח.
Bản cài đặt B29 IOS – Giải pháp vượt trội cho các tín đồ iOS
Trong thế giới công nghệ đầy sôi động hiện nay, trải nghiệm người dùng luôn là yếu tố then chốt. Với sự ra đời của Bản cài đặt B29 IOS, người dùng sẽ được hưởng trọn vẹn những tính năng ưu việt, mang đến sự hài lòng tuyệt đối. Hãy cùng khám phá những ưu điểm vượt trội của bản cài đặt này!
Tính bảo mật tối đa
Bản cài đặt B29 IOS được thiết kế với mục tiêu đảm bảo an toàn dữ liệu tuyệt đối cho người dùng. Nhờ hệ thống mã hóa hiện đại, thông tin cá nhân và dữ liệu nhạy cảm của bạn luôn được bảo vệ an toàn khỏi những kẻ xâm nhập trái phép.
Trải nghiệm người dùng đỉnh cao
Giao diện thân thiện, đơn giản nhưng không kém phần hiện đại, B29 IOS mang đến cho người dùng trải nghiệm duyệt web, truy cập ứng dụng và sử dụng thiết bị một cách trôi chảy, mượt mà. Các tính năng thông minh được tối ưu hóa, giúp nâng cao hiệu suất và tiết kiệm pin đáng kể.
Tính tương thích rộng rãi
Bản cài đặt B29 IOS được phát triển với mục tiêu tương thích với mọi thiết bị iOS từ các dòng iPhone, iPad cho đến iPod Touch. Dù là người dùng mới hay lâu năm của hệ điều hành iOS, B29 đều mang đến sự hài lòng tuyệt đối.
Quá trình cài đặt đơn giản
Với những hướng dẫn chi tiết, việc cài đặt B29 IOS trở nên nhanh chóng và dễ dàng. Chỉ với vài thao tác đơn giản, bạn đã có thể trải nghiệm ngay tất cả những tính năng tuyệt vời mà bản cài đặt này mang lại.
Bản cài đặt B29 IOS không chỉ là một bản cài đặt đơn thuần, mà còn là giải pháp công nghệ hiện đại, nâng tầm trải nghiệm người dùng lên một tầm cao mới. Hãy trở thành một phần của cộng đồng sử dụng B29 IOS để khám phá những tiện ích tuyệt vời mà nó có thể mang lại!
Medicines prescribing information. Brand names.
can you get bactrim
Actual information about pills. Read now.
Pills information for patients. Drug Class.
use of lisinopril in pregnancy
All what you want to know about medication. Read information here.
When I originally commented I clicked the -Notify me when new comments are added- checkbox and now each time a comment is added I get four emails with the same comment. Is there any way you can remove me from that service? Thanks!
Drug information leaflet. Drug Class.
buy cheap glucophage without prescription
Everything information about medicament. Get here.
Meds information for patients. Generic Name.
lisinopril medication
Actual trends of meds. Read information now.
Medicine information leaflet. Brand names.
where can i buy generic zyban tablets
Some information about pills. Read now.
Drugs information sheet. What side effects can this medication cause?
can i get cheap glucophage
Everything news about medication. Read information now.
Как охранять свои данные: берегитесь утечек информации в интернете. Сегодня охрана информации становится всё более важной задачей. Одним из наиболее часто встречающихся способов утечки личной информации является слив «сит фраз» в интернете. Что такое сит фразы и в какой мере защититься от их утечки? Что такое «сит фразы»? «Сит фразы» — это смеси слов или фраз, которые регулярно используются для получения доступа к различным онлайн-аккаунтам. Эти фразы могут включать в себя имя пользователя, пароль или разные конфиденциальные данные. Киберпреступники могут пытаться получить доступ к вашим аккаунтам, используя этих сит фраз. Как охранить свои личные данные? Используйте комплексные пароли. Избегайте использования простых паролей, которые легко угадать. Лучше всего использовать комбинацию букв, цифр и символов. Используйте уникальные пароли для каждого из аккаунта. Не воспользуйтесь один и тот же пароль для разных сервисов. Используйте двухэтапную аутентификацию (2FA). Это вводит дополнительный уровень безопасности, требуя подтверждение входа на ваш аккаунт через другое устройство или метод. Будьте осторожны с онлайн-сервисами. Не доверяйте персональную информацию ненадежным сайтам и сервисам. Обновляйте программное обеспечение. Установите обновления для вашего операционной системы и программ, чтобы уберечь свои данные от вредоносного ПО. Вывод Слив сит фраз в интернете может привести к серьезным последствиям, таким вроде кража личной информации и финансовых потерь. Чтобы сохранить себя, следует принимать меры предосторожности и использовать надежные методы для хранения и управления своими личными данными в сети
Medicines prescribing information. What side effects?
п»їzyban
All what you want to know about medication. Get now.
продать авто в москве https://avtovikupmashin21.ru/
האפליקציה הווה פלטפורמה רווחת במדינה לקנייה של מריחואנה בצורה מקוון. היא מעניקה ממשק נוח ומאובטח לקנייה ולקבלת שילוחים מ פריטי קנאביס מרובים. במאמר זו נבחן את העיקרון מאחורי האפליקציה, כיצד היא עובדת ומה המעלות מ השימוש בה.
מה זו טלגראס?
הפלטפורמה הינה אמצעי לקנייה של צמח הקנאביס באמצעות היישומון טלגראם. היא מבוססת מעל ערוצי תקשורת וקבוצות טלגראם ספציפיות הנקראות ״כיווני טלגראס״, שם אפשר להזמין מגוון פריטי קנאביס ולקבל אלו ישירותית למשלוח. הערוצים אלו מאורגנים על פי איזורים גאוגרפיים, כדי להקל על קבלתם של המשלוחים.
כיצד זאת פועל?
התהליך קל יחסית. קודם כל, יש להצטרף לערוץ הטלגראס הרלוונטי לאזור המגורים. שם אפשר לצפות בתפריטי המוצרים השונים ולהרכיב את הפריטים הרצויים. לאחר השלמת ההרכבה וסיום התשלום, השליח יופיע בכתובת שצוינה ועמו החבילה שהוזמן.
רוב ערוצי טלגראס מספקים טווח רחב מ פריטים – זנים של צמח הקנאביס, עוגיות, משקאות ועוד. כמו כן, אפשר לראות חוות דעת מ צרכנים שעברו על איכות הפריטים והשירות.
יתרונות הנעשה באפליקציה
יתרון מרכזי של הפלטפורמה הינו הנוחיות והפרטיות. ההרכבה וההכנות מתבצעות ממרחק מאיזשהו מיקום, בלי צורך במפגש פנים אל פנים. בנוסף, הפלטפורמה מוגנת ביסודיות ומבטיחה סודיות גבוה.
מלבד על כך, מחירי המוצרים בטלגראס נוטות להיות זולים, והשילוחים מגיעים במהירות ובמסירות רבה. קיים גם מוקד תמיכה פתוח לכל שאלה או בעיה.
לסיכום
טלגראס מהווה שיטה מקורית ויעילה לקנות מוצרי מריחואנה בישראל. זו משלבת את הנוחות הדיגיטלית מ האפליקציה הפופולרי, ועם הזריזות והפרטיות של שיטת השילוח הישירה. ככל שהדרישה לצמח הקנאביס גובר, פלטפורמות כמו טלגראס צפויות להמשיך ולהתפתח.
Medicines information leaflet. What side effects can this medication cause?
buying zyban no prescription
Actual trends of pills. Get now.
лучшие казино
https://618-27-83.ru/
– RamenBet казино
Как охранять свои данные: остерегайтесь утечек информации в интернете. Сегодня охрана личных данных становится более насущной важной задачей. Одним из наиболее обычных способов утечки личной информации является слив «сит фраз» в интернете. Что такое сит фразы и в какой мере защититься от их утечки? Что такое «сит фразы»? «Сит фразы» — это смеси слов или фраз, которые часто используются для входа к различным онлайн-аккаунтам. Эти фразы могут включать в себя имя пользователя, пароль или дополнительные конфиденциальные данные. Киберпреступники могут пытаться получить доступ к вашим аккаунтам, используя этих сит фраз. Как обезопасить свои личные данные? Используйте комплексные пароли. Избегайте использования легких паролей, которые мгновенно угадать. Лучше всего использовать комбинацию букв, цифр и символов. Используйте уникальные пароли для каждого из аккаунта. Не пользуйтесь один и тот же пароль для разных сервисов. Используйте двухфакторную проверку (2FA). Это прибавляет дополнительный уровень безопасности, требуя подтверждение входа на ваш аккаунт по другое устройство или метод. Будьте осторожны с онлайн-сервисами. Не доверяйте персональную информацию ненадежным сайтам и сервисам. Обновляйте программное обеспечение. Установите обновления для вашего операционной системы и программ, чтобы уберечь свои данные от вредоносного ПО. Вывод Слив сит фраз в интернете может повлечь за собой серьезным последствиям, таким подобно кража личной информации и финансовых потерь. Чтобы защитить себя, следует принимать меры предосторожности и использовать надежные методы для хранения и управления своими личными данными в сети
Pills information leaflet. Short-Term Effects.
does lisinopril have a blood thinner in it
Actual news about pills. Get information here.
Секреты оформления пропуска на МКАД, Эффективные способы получения пропуска на МКАД, Важная информация о пропуске на МКАД, Какие документы нужны для оформления пропуска на МКАД, Часто задаваемые вопросы о пропуске на МКАД, Пропуск на МКАД: сроки и стоимость, подробный обзор, Какие преимущества дает пропуск на МКАД, важные детали, шаг за шагом
Проверить пропуск на мкад Проверить пропуск на мкад .
займ онлайн ру москва
Проверить транзакцию usdt trc20
Оградите свои USDT: Проверьте транзакцию TRC20 перед пересылкой
Цифровые валюты, такие вроде USDT (Tether) в блокчейне TRON (TRC20), становятся всё всё более востребованными в области сфере децентрализованных финансов. Тем не менее вместе с повышением распространенности увеличивается и риск погрешностей либо жульничества при транзакции денег. Как раз именно поэтому нужно проверять перевод USDT TRC20 до её отправкой.
Промах во время вводе данных адреса адресата или отправка на ошибочный адрес сможет повлечь к невозможности безвозвратной утрате твоих USDT. Жулики тоже смогут стараться обмануть вас, пересылая поддельные адреса получателей для отправки. Потеря цифровой валюты из-за таких промахов сможет повлечь серьезными финансовыми убытками.
К счастью, имеются специализированные службы, позволяющие удостовериться транзакцию USDT TRC20 перед её отсылкой. Один из числа таких сервисов предоставляет возможность просматривать и изучать транзакции на распределенном реестре TRON.
На этом обслуживании вам сможете ввести адрес получателя адресата и получать детальную данные об адресе, включая в том числе архив операций, баланс а также статус счета. Данное поможет выяснить, является ли адрес получателя истинным а также надежным для пересылки денег.
Другие сервисы также предоставляют похожие опции по удостоверения транзакций USDT TRC20. Некоторые кошельки по крипто имеют встроенные функции для верификации адресов и транзакций.
Не пропускайте удостоверением операции USDT TRC20 до её отсылкой. Малая предосторожность может сэкономить вам множество средств и избежать утрату ваших дорогих крипто ресурсов. Задействуйте заслуживающие доверия службы с целью обеспечения надежности ваших переводов и неприкосновенности ваших USDT на распределенном реестре TRON.
Как получить пропуск на МКАД, что нужно знать, рекомендации, Список требуемых документов для пропуска на МКАД, Основные вопросы о пропуске на МКАД, на которые нужно знать ответы, Как оформить пропуск для движения по МКАД, советы, важные детали, подробная информация
Пропуск на мкад [url=https://gargopermits.com/]Пропуск в москву[/url] .
проверить кошелёк usdt trc20
Во время обращении с виртуальной валютой USDT в распределенном реестре TRON (TRC20) чрезвычайно существенно не просто удостоверять адрес получателя до переводом средств, а также тоже систематически отслеживать остаток своего цифрового кошелька, и источники поступающих транзакций. Данное действие даст возможность своевременно обнаружить любые незапланированные действия а также избежать вероятные убытки.
Сначала, требуется удостовериться в корректности отображаемого баланса USDT TRC20 в собственном криптокошельке. Советуется соотносить информацию с данными общедоступных обозревателей блокчейна, с целью не допустить шанс взлома либо компрометации самого кошелька.
Но лишь мониторинга баланса недостаточно. Чрезвычайно необходимо анализировать журнал входящих транзакций и их источники. В случае если вы выявите поступления USDT с неопознанных либо сомнительных адресов, незамедлительно заблокируйте эти финансы. Имеется риск, чтобы данные криптомонеты стали получены.
Наше сервис обеспечивает возможности для детального анализа поступающих USDT TRC20 переводов на предмет этой законности и отсутствия соотношения с противозаконной деятельностью. Мы.
Также нужно систематически отправлять USDT TRC20 на безопасные неконтролируемые криптовалютные кошельки находящиеся под вашим полным присмотром. Содержание монет на сторонних платформах всегда связано с рисками взломов и потери финансов вследствие программных сбоев или банкротства платформы.
Следуйте базовые меры защиты, оставайтесь внимательны а также своевременно мониторьте баланс а также источники пополнений USDT TRC20 кошелька. Это позволит оградить ваши цифровые ценности от незаконного завладения и потенциальных юридических проблем в будущем.
Medication prescribing information. Generic Name.
order zyban prices
Everything information about drug. Read information now.
срочный выкуп авто https://avtovikupmashin21.ru/
онлайн казино
Drugs information sheet. Long-Term Effects.
azithromycin pill
Actual about medicine. Get information now.
I view something truly special in this website.
Подробная инструкция по оформлению пропуска на МКАД, советы, Основные аспекты пропуска на МКАД, Список требуемых документов для пропуска на МКАД, 10 вопросов о пропуске на МКАД, которые важно учесть, Как получить пропуск для поездок по МКАД, Почему стоит получить пропуск на МКАД, Сроки и порядок продления пропуска на МКАД, шаг за шагом
Проверить пропуск на мкад Пропуск на мкад .
продать автомобиль в москве https://avtovikupmashin21.ru/
Pills information sheet. Drug Class.
metformin and alcohol
Everything trends of medicines. Get now.
Фотокниги с вашей историей. Закажите сегодня, и через несколько дней будете держать дорогие сердцу воспоминания в руках. Обложка arrow фотокнига первого года
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point. You clearly know what youre talking about, why waste your intelligence on just posting videos to your blog when you could be giving us something enlightening to read?
рейтинг казино
b29
Bản cài đặt B29 IOS – Giải pháp vượt trội cho các tín đồ iOS
Trong thế giới công nghệ đầy sôi động hiện nay, trải nghiệm người dùng luôn là yếu tố then chốt. Với sự ra đời của Bản cài đặt B29 IOS, người dùng sẽ được hưởng trọn vẹn những tính năng ưu việt, mang đến sự hài lòng tuyệt đối. Hãy cùng khám phá những ưu điểm vượt trội của bản cài đặt này!
Tính bảo mật tối đa
Bản cài đặt B29 IOS được thiết kế với mục tiêu đảm bảo an toàn dữ liệu tuyệt đối cho người dùng. Nhờ hệ thống mã hóa hiện đại, thông tin cá nhân và dữ liệu nhạy cảm của bạn luôn được bảo vệ an toàn khỏi những kẻ xâm nhập trái phép.
Trải nghiệm người dùng đỉnh cao
Giao diện thân thiện, đơn giản nhưng không kém phần hiện đại, B29 IOS mang đến cho người dùng trải nghiệm duyệt web, truy cập ứng dụng và sử dụng thiết bị một cách trôi chảy, mượt mà. Các tính năng thông minh được tối ưu hóa, giúp nâng cao hiệu suất và tiết kiệm pin đáng kể.
Tính tương thích rộng rãi
Bản cài đặt B29 IOS được phát triển với mục tiêu tương thích với mọi thiết bị iOS từ các dòng iPhone, iPad cho đến iPod Touch. Dù là người dùng mới hay lâu năm của hệ điều hành iOS, B29 đều mang đến sự hài lòng tuyệt đối.
Quá trình cài đặt đơn giản
Với những hướng dẫn chi tiết, việc cài đặt B29 IOS trở nên nhanh chóng và dễ dàng. Chỉ với vài thao tác đơn giản, bạn đã có thể trải nghiệm ngay tất cả những tính năng tuyệt vời mà bản cài đặt này mang lại.
Bản cài đặt B29 IOS không chỉ là một bản cài đặt đơn thuần, mà còn là giải pháp công nghệ hiện đại, nâng tầm trải nghiệm người dùng lên một tầm cao mới. Hãy trở thành một phần của cộng đồng sử dụng B29 IOS để khám phá những tiện ích tuyệt vời mà nó có thể mang lại!
Medicines information. Brand names.
can i purchase glucophage without prescription
Best news about medicines. Read information here.
Medicine information for patients. Short-Term Effects.
seroquel
Actual what you want to know about drugs. Read information now.
Проверить перевод usdt trc20
Значимость верификации платежа USDT TRC-20
Транзакции USDT по технологии TRC20 увеличивают возрастающую активность, тем не менее важно быть повышенно аккуратными в ходе таких обработке.
Указанный вид платежей преимущественно задействуется в качестве обеления средств, добытых криминальным методом.
Главный опасностей принятия USDT TRC20 – заключается в том, что такие платежи могут быть получены благодаря многочисленных методов кражи, в том числе кражи конфиденциальной информации, принуждение, взломы и иные криминальные действия. Получая данные платежи, пользователь автоматически выступаете сообщником преступной активности.
Вследствие этого чрезвычайно обязательно скрупулезно изучать природу различных зачисляемого операции через USDT по сети TRC20. Следует запрашивать от плательщика информацию касательно законности денежных средств, при незначительных сомнениях – отклонять такие платежей.
Помните, в ситуации, когда в выявления противоправных генезисов денежных средств, получатель можете быть подвергнуты мерам с применением санкциям параллельно одновременно с отправителем. В связи с этим рекомендуется подстраховаться а также тщательно исследовать любой перевод, предпочтительнее рисковать репутационной репутацией как и попасть под масштабные законодательные трудности.
Демонстрация осторожности в ходе работе по USDT TRC-20 – выступает ключ собственной экономической безопасности а также защита от незаконные активности. Будьте бдительными как и неизменно анализируйте источник цифровых валютных финансов.
Секреты оформления пропуска на МКАД, Срочное оформление пропуска на МКАД, рекомендации, которую нужно знать, Основные вопросы о пропуске на МКАД, Пропуск на МКАД: сроки и стоимость, Как оформить пропуск для движения по МКАД, рекомендации, Сроки и порядок продления пропуска на МКАД, шаг за шагом
Проверить пропуск на мкад Проверить пропуск на мкад .
Nice article inspiring thanks. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Pills information leaflet. Long-Term Effects.
where buy cheap zyban price
Actual news about meds. Get information here.
Medicine information leaflet. Long-Term Effects.
lisinopril buy
All about medicine. Get here.
additional resources Pal world download
1win
Drug information leaflet. Short-Term Effects.
cost generic glucophage without prescription
Everything what you want to know about medicines. Get information now.
столбчатый фундамент цена в москве
1win зеркало
ленточно винтовой фундамент
Интерьерная печать, печать на холсте, накат на пенокартон, модульные картины, печать на текстильных материалах, с доставкой, оформить онлайн заказ через интернет прямо с нашего сайта печать фото онлайн с доставкой
Drugs information. Cautions.
zyban without a prescription
Some news about meds. Read here.
бетонная плита для фундамента
Medication information sheet. What side effects can this medication cause?
cheap cordarone
All trends of meds. Read information now.
Meds information for patients. Long-Term Effects.
lisinopril renal dosing
Everything information about drugs. Read information now.
1вин зеркало
1win казино
1вин
Drugs information leaflet. What side effects can this medication cause?
losartan
Some trends of medicine. Get information now.
Заголовок: Непременно удостоверяйтесь в адрес адресата во время операции USDT TRC20
При работе со цифровыми валютами, особенно с USDT на распределенном реестре TRON (TRC20), чрезвычайно нужно демонстрировать осторожность и внимательность. Одна среди наиболее обычных погрешностей, которую совершают юзеры – посылка денег по неверный адрес. Чтобы устранить потери собственных USDT, требуется неизменно внимательно удостоверяться в адресе реципиента до отправкой операции.
Крипто адреса являют из себя длинные наборы букв и цифр, к примеру, TRX9QahiFUYfHffieZThuzHbkndWvvfzThB8U. Включая небольшая опечатка или ошибка при копировании адреса кошелька сможет повлечь к тому, что твои цифровые деньги станут безвозвратно утрачены, так как они окажутся на неподконтрольный вами кошелек.
Присутствуют разные пути проверки адресов кошельков USDT TRC20:
1. Визуальная ревизия. Тщательно соотнесите адрес во своём кошельке с адресом реципиента. При незначительном различии – воздержитесь от операцию.
2. Применение интернет-служб проверки.
3. Двойная аутентификация с получателем. Обратитесь с просьбой к реципиенту заверить правильность адреса кошелька до посылкой транзакции.
4. Пробный транзакция. При значительной величине операции, допустимо предварительно отправить незначительное величину USDT с целью контроля адреса.
Сверх того советуется хранить крипто в личных криптокошельках, а не на обменниках иль сторонних сервисах, для того чтобы обладать всецелый контроль над собственными ресурсами.
Не игнорируйте удостоверением адресов кошельков при деятельности со USDT TRC20. Эта простая процедура предосторожности окажет помощь обезопасить ваши финансы от нежелательной лишения. Помните, что на мире криптовалют переводы невозвратны, и переданные крипто по ошибочный адрес вернуть фактически нереально. Будьте осторожны и тщательны, для того чтобы защитить свои капиталовложения.
1win казино
here galaxy swapper fortnite
Drug prescribing information. Long-Term Effects.
interaction of lisinopril and alcohol
All news about medicament. Get here.
I’m impressed, I must say. Really rarely do I encounter a weblog that’s each educative and entertaining, and let me let you know, you’ve gotten hit the nail on the head. Your idea is outstanding; the difficulty is something that not sufficient individuals are speaking intelligently about. I’m very happy that I stumbled throughout this in my seek for one thing regarding this.
Medicine information for patients. Drug Class.
can i purchase zyban without a prescription
Actual news about drugs. Get now.
blacksprut официальный сайт – https blacksprut com, https blacksprut com
Medicament information for patients. What side effects?
glucophage
Everything trends of pills. Get now.
Осуществляем уборку квартир, домов, офисов, уборку после ремонта, генеральную и поддерживающую, а также мытье окон оказание услуг по уборке
Drug information sheet. Long-Term Effects.
lisinopril 20 12 5mg
Actual news about medication. Read here.
Pills information sheet. Long-Term Effects.
nolvadex
Some about medicine. Get now.
Drug information for patients. What side effects can this medication cause?
where to get cheap zyban price
Best about medicine. Read information here.
Преимущества теневого плинтуса в декорировании помещения,
Как правильно установить теневой плинтус своими руками,
Как использовать теневой плинтус для создания уникального интерьера,
Ретро-стиль с использованием теневых плинтусов: идеи для вдохновения,
Как подобрать цвет теневого плинтуса к отделке стен,
Теневой плинтус: простое решение для скрытия кабелей и проводов,
Теневой плинтус с подсветкой: создаем эффектное освещение в интерьере,
Современные тренды в использовании теневого плинтуса для уюта и красоты,
Интерьер безупречный до мелочей: роль теневого плинтуса в декоре
плинтус купить москва https://plintus-tenevoj-aljuminievyj-msk.ru/ .
Преимущества теневого плинтуса в декорировании помещения,
Советы по монтажу теневого плинтуса без дополнительной помощи,
Как использовать теневой плинтус для создания уникального интерьера,
Ретро-стиль с использованием теневых плинтусов: идеи для вдохновения,
Советы стилиста: как сделать цвет теневого плинтуса акцентом в помещении,
Безопасность и стиль: почему теневой плинтус – идеальное решение для дома,
Преимущества использования теневого плинтуса с интегрированной подсветкой,
Как сделать помещение завершенным с помощью теневого плинтуса,
Интерьер безупречный до мелочей: роль теневого плинтуса в декоре
плинтус теневой https://plintus-tenevoj-aljuminievyj-msk.ru/ .
Drugs information. Drug Class.
order generic glucophage price
Everything about drugs. Read here.
Подарочный сертификат на аренду квадроциклов станет незабываемым подарком для любителей активного отдыха можайск квадроциклы катание
Специализированный магазин, где можно найти много раковина с тумбой узкая в туалет для вашей ванной комнаты.
leeds-welcome.com
Почему теневой плинтус – красивая и практичная деталь интерьера,
Как правильно установить теневой плинтус своими руками,
Теневой плинтус как элемент декора: идеи и варианты применения,
Ретро-стиль с использованием теневых плинтусов: идеи для вдохновения,
Как подобрать цвет теневого плинтуса к отделке стен,
Как спрятать коммуникации с помощью теневого плинтуса: практические советы,
Преимущества использования теневого плинтуса с интегрированной подсветкой,
Как сделать помещение завершенным с помощью теневого плинтуса,
Теневой плинтус: деталь, которая делает интерьер законченным и гармоничным
купить плинтус алюминиевый https://plintus-tenevoj-aljuminievyj-msk.ru/ .
Meds information. Effects of Drug Abuse.
can i buy cheap zyban for sale
All information about pills. Get now.
Большинство людей предпочтут отремонтировать стиральную машину, а не заменить ее.
Средняя стоимость ремонта колеблется от 500 до 3500 рублей за детали и работу в зависимости от типа вашей машины.
Очень важно найти подходящего мастера для ремонта.
Рекомендуем обратить внимание на компанию Ремонт РБТ, которая уже белее 15 лет оказывает услуги населению, по ремонту стиральных машин и зарекомендовала себя только с лучшей стороны. Перед началом ремонта сделайте диагностику машины. Это важно!
https://yandex.ru/maps/org/remont_rbt/1228279731
Почему теневой плинтус – красивая и практичная деталь интерьера,
Советы по монтажу теневого плинтуса без дополнительной помощи,
Как использовать теневой плинтус для создания уникального интерьера,
Ретро-стиль с использованием теневых плинтусов: идеи для вдохновения,
Советы стилиста: как сделать цвет теневого плинтуса акцентом в помещении,
Как спрятать коммуникации с помощью теневого плинтуса: практические советы,
Преимущества использования теневого плинтуса с интегрированной подсветкой,
Современные тренды в использовании теневого плинтуса для уюта и красоты,
Почему теневой плинтус – важная деталь в оформлении интерьера
плинтус алюминиевый купить плинтус алюминиевый купить .
?They were sorting out the groceries together in the spacious kitchen, and the daughter went to rest in her room. It was made like for a real princess: there was a flower print on the stretch ceiling, the pink wallpaper harmoniously combined with the white furniture. In some places on the walls, Masha’s autographs were left: this is how the little girl was learning to draw and explore this world:
— So will you tell me why we need to lose weight? Who put that into your head?
— My dear, I’m tired of being embarrassed! All my colleagues are thin and fragile, and against their background, I’m like an elephant in a china shop. I don’t even fit on two chairs anymore, do you understand me? Vika constantly pokes at our family, saying how many tons you eat a day. I’m sick of it all, I can’t take it anymore. It’s disgusting to look in the mirror…
— And Vika doesn’t have a sense of tact at all? Okay, if that’s the case, then we’ll show them.
blog link jaxx login
Сайт, где можно выбрать раковина в ванную чаша под любой интерьер.
Как похудеть
Маленькая девочка без двух передних зубов очень обрадовалась этому и стала внимательно рассматривать упаковку, водя по надписям маленьким пальчиком:
—Может, хватит чипсов? Пойдем чего-нибудь нормального посмотрим? Овощей там, фруктов…
Таких слов мужчина совсем не ожидал от своей жены Тани. В их семье конституция тела совсем отличалась от стандартной и общепринятой – иметь предожирение абсолютная норма. Питание далеко отличалась от «правильного», чипсы и конфеты заменяли новомодный фреш из сельдерея и рыбу на пару. Спорт семья видела только по телевизору:
—Ты что? Ты…. Ты что, худеть собралась? Где моя Танюшка – обжорка? Это тебя кто так обидел?! представитель сильного пола абсолютно не предполагал из уст родной избранницы Татьяны. Среди этой семье сложение организма полностью различалась в противовес нормативной и утвердившейся – быть с предожирением абсолютная правило.
I think this site contains some real excellent info for everyone. “Drunkenness is temporary suicide.” by Bertrand Russell.
https://tetrasky.ru
I just like the helpful information you provide in your articles. I’ll bookmark your blog and test once more here frequently. I am reasonably sure I will be told many new stuff right right here! Good luck for the next!
Drugs information sheet. Drug Class.
imuran and lisinopril interaction
Everything news about drug. Read now.
Сайт, где представлен разнообразие раковины laufen pro a для вашей ванной комнаты, с доставкой по всей стране.
have a peek at these guys evon free
Геракл24: Квалифицированная Смена Основания, Венцов, Полов и Перемещение Зданий
Фирма Gerakl24 занимается на оказании комплексных работ по замене основания, венцов, полов и перемещению зданий в месте Красноярске и за пределами города. Наш коллектив квалифицированных специалистов гарантирует отличное качество реализации всех видов реставрационных работ, будь то деревянные, каркасные, из кирпича или бетонные здания.
Плюсы работы с Gerakl24
Квалификация и стаж:
Весь процесс осуществляются лишь высококвалифицированными экспертами, с обладанием долгий стаж в направлении строительства и ремонта зданий. Наши специалисты профессионалы в своем деле и выполняют проекты с безупречной точностью и вниманием к деталям.
Полный спектр услуг:
Мы предоставляем полный спектр услуг по реставрации и ремонту домов:
Смена основания: укрепление и замена старого фундамента, что позволяет продлить срок службы вашего здания и избежать проблем, вызванные оседанием и деформацией.
Смена венцов: восстановление нижних венцов деревянных зданий, которые чаще всего гниют и разрушаются.
Смена настилов: установка новых полов, что кардинально улучшает внешний облик и функциональность помещения.
Перемещение зданий: безопасное и надежное перемещение зданий на другие участки, что обеспечивает сохранение строения и предотвращает лишние расходы на строительство нового.
Работа с любыми типами домов:
Дома из дерева: восстановление и защита деревянных строений, защита от разрушения и вредителей.
Дома с каркасом: реставрация каркасов и замена поврежденных элементов.
Кирпичные дома: восстановление кирпичной кладки и усиление стен.
Бетонные строения: реставрация и усиление бетонных элементов, устранение трещин и повреждений.
Качество и надежность:
Мы применяем лишь качественные материалы и передовые технологии, что гарантирует долгий срок службы и прочность всех выполненных задач. Каждый наш проект проходят тщательную проверку качества на всех этапах выполнения.
Личный подход:
Для каждого клиента мы предлагаем индивидуальные решения, с учетом всех особенностей и пожеланий. Наша цель – чтобы результат нашей работы полностью удовлетворял ваши ожидания и требования.
Почему стоит выбрать Геракл24?
Сотрудничая с нами, вы приобретете надежного партнера, который берет на себя все заботы по ремонту и реставрации вашего дома. Мы обеспечиваем выполнение всех задач в установленные сроки и с соблюдением всех правил и норм. Обратившись в Геракл24, вы можете быть спокойны, что ваш дом в надежных руках.
Мы предлагаем консультацию и дать ответы на все вопросы. Свяжитесь с нами, чтобы обсудить детали и узнать о наших сервисах. Мы поможем вам сохранить и улучшить ваш дом, сделав его уютным и безопасным для долгого проживания.
Gerakl24 – ваш партнер по реставрации и ремонту домов в Красноярске и окрестностях.
Drug information sheet. Generic Name.
how to buy cheap zyban without dr prescription
Everything about pills. Get now.
Professional care of the premises. Cleaners undergo apartusa365.com detailed training, where they learn the combination of different cleaning products with different types of materials.
Drug information leaflet. Cautions.
buying nexium
Actual what you want to know about pills. Read now.
Thank you great post. Hello Administ .Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
A simple rule applies here, for example britainrental.com, the height of Everest is 8848 meters above sea level. Thus, Everest, which is located at such a height above sea level, is considered to be the highest mountain on Earth.
Thank you for content. Area rugs and online home decor store. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
oneworldmiami.com
texasnewsjobs.com
Отзывы на работу онлайн казино 1Win Casino (1Вин Казино) об игре на реальные деньги, скорости выплат и вывода средств, отдаче автоматов казино 1Вин
ברוכים הנכנסים לפורטל המידע והנתונים והתרומה הרשמי והמוסמך של טלגראס אופקים! כאן רשאים לאתר את המידע והמסמכים העדכני והמעודכן הזמין והרלוונטי לגבי מערכת טלגרם וכלים לשימוש בה כראוי.
מהו טלגראס אופקים?
טלגרמות כיוונים מהווה תשתית המבוססת על טלגראס המספקת לתפוצה וקנייה סביב קנאביס וקנבי במדינה. דרך המסרים והפורומים בטלגרף, משתמשים מסוגלים לקנות ולהשיג את פריטי קנבי בדרך פשוט ומיידי.
איך להתחיל בפלטפורמת טלגרם?
כדי להתחיל בפעילות בטלגראס, אתם נדרשים להצטרף ל לקבוצות ולחוגים המומלצים. בנקודה זו באתר רשאים לאתר ולמצוא מדריך מבין לינקים למקומות מתפקדים ומובטחים. במקביל לכך, אפשר להיכנס במסלול הקבלה והקבלה סביב מוצרי המריחואנה.
הדרכות והסברים
באתר הנוכחי אפשר למצוא סוגים מתוך מדריכים ומידע ברורים בעניין היישום בטלגרם, בין היתר:
– הצטרפות לקבוצות מאומתים
– סדרת הקבלה
– אבטחה והגנה בהתנהלות בטלגרם
– והמון תוכן נוסף לכך
צירים איכותיים
בסעיף זה לינקים למקומות ולקבוצות איכותיים בטלגראס כיוונים:
– מקום הפרטים והעדכונים הרשמי
– פורום התמיכה והליווי ללקוחות
– פורום לקבלת מוצרי קנאביס אמינים
– מבחר חנויות קנאביס מובטחות
אנחנו מאחלים אתם בשל החברות שלכם לפורטל הידע והמידע מטעם טלגרם נתיבים ומאחלים עבורכם חווית שהיא שירות מרוצה ומובטחת!
https://onlinecrashgame.space/bs/jetx/
Depositing methods will depend on the location and options available to players.
Hiya, I am really glad I have found this info. Today bloggers publish only about gossips and net and this is really annoying. A good blog with interesting content, that’s what I need. Thank you for keeping this site, I’ll be visiting it. Do you do newsletters? Can’t find it.
Букмекерская контора 1win отзывы клиентов, Отзывы о Букмекерская контора 1win. На сайте отвечает официальный представитель Букмекерская контора 1win 1win зеркало
ремонт сотовых телефонов рядом
В фитнес-клубах есть вело- и кардиотренажеры, силовое оборудование, эллипсы, беговые дорожки. Самых популярных тренажеров в зале несколько экземпляров, чтобы всегда были свободные сеть фитнес центров москва
Medication information leaflet. What side effects?
lasix otc
Everything about medication. Read now.
Наши навесы цены – это гарантия качества и надежности.
Замена венцов красноярск
Gerakl24: Опытная Замена Основания, Венцов, Полов и Перемещение Зданий
Организация Геракл24 профессионально занимается на предоставлении комплексных сервисов по замене основания, венцов, полов и передвижению домов в месте Красноярске и в окрестностях. Наша команда профессиональных мастеров гарантирует превосходное качество исполнения различных типов восстановительных работ, будь то из дерева, каркасного типа, из кирпича или из бетона дома.
Достоинства сотрудничества с Gerakl24
Квалификация и стаж:
Каждая задача проводятся исключительно опытными мастерами, с многолетним большой практику в направлении создания и реставрации домов. Наши мастера профессионалы в своем деле и выполняют проекты с безупречной точностью и вниманием к мелочам.
Полный спектр услуг:
Мы предлагаем полный спектр услуг по ремонту и восстановлению зданий:
Замена фундамента: укрепление и замена старого фундамента, что позволяет продлить срок службы вашего строения и избежать проблем, связанные с оседанием и деформацией.
Замена венцов: замена нижних венцов деревянных домов, которые чаще всего гниют и разрушаются.
Установка новых покрытий: монтаж новых настилов, что значительно улучшает визуальное восприятие и функциональность помещения.
Передвижение домов: качественный и безопасный перенос строений на новые локации, что помогает сохранить здание и предотвращает лишние расходы на возведение нового.
Работа с различными типами строений:
Древесные строения: восстановление и укрепление деревянных конструкций, защита от гниения и вредителей.
Каркасные дома: реставрация каркасов и реставрация поврежденных элементов.
Дома из кирпича: восстановление кирпичной кладки и усиление стен.
Бетонные строения: реставрация и усиление бетонных элементов, ремонт трещин и дефектов.
Качество и прочность:
Мы используем только высококачественные материалы и новейшее оборудование, что обеспечивает долгий срок службы и прочность всех выполненных задач. Каждый наш проект проходят строгий контроль качества на каждом этапе выполнения.
Личный подход:
Для каждого клиента мы предлагаем индивидуальные решения, с учетом всех особенностей и пожеланий. Мы стремимся к тому, чтобы конечный результат полностью соответствовал вашим ожиданиям и требованиям.
Почему стоит выбрать Геракл24?
Обратившись к нам, вы найдете надежного партнера, который берет на себя все заботы по ремонту и реконструкции вашего строения. Мы гарантируем выполнение всех работ в сроки, установленные договором и с соблюдением всех правил и норм. Выбрав Геракл24, вы можете не сомневаться, что ваше строение в надежных руках.
Мы готовы предоставить консультацию и ответить на все ваши вопросы. Контактируйте с нами, чтобы обсудить детали и получить больше информации о наших услугах. Мы сохраним и улучшим ваш дом, сделав его безопасным и комфортным для проживания на долгие годы.
Gerakl24 – ваш выбор для реставрации и ремонта домов в Красноярске и области.
seo продвижение сайта сколько стоит
Medication information sheet. What side effects?
norvasc generics
Actual what you want to know about pills. Read here.
качественный сервис выполняет ремонт промышленных пультов управления в Москве. Сотни раз обращался, все отремонтировали качественно!
Drug information. Short-Term Effects.
lisinopril no prescription
Best information about medicines. Read now.
Премиальный фитнес-клуб: бассейн, залы групповых программ, SPA, кафе. Оборудование в тренажерном зале топовых фирм сайт фитнес клуба
Drug information sheet. Effects of Drug Abuse.
finpecia buy
Best news about drugs. Get information here.
Medicine information. Brand names.
famotidine
Actual information about pills. Read here.
see price earnings ratio formula
https://seogou.ru/
Medication information. Brand names.
lopressor generic
Best information about medication. Read now.
Medication prescribing information. Brand names.
doxycycline order
Actual what you want to know about medicament. Get information now.
1win
Hi, just required you to know I he added your site to my Google bookmarks due to your layout. But seriously, I believe your internet site has 1 in the freshest theme I??ve came across.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Meds information leaflet. What side effects can this medication cause?
levitra generics
Some trends of drugs. Read information here.
как зайти на kraken – kraken com ссылка, KRAKEN зеркало рабочее
Use protective devices, use tools real-apartment.com and equipment according to the rules so as not to come into contact with difficulties.
Fantastic goods from you, man. I’ve understand your stuff previous to and you are just too great. I really like what you’ve acquired here, really like what you are saying and the way in which you say it. You make it entertaining and you still take care of to keep it smart. I can not wait to read much more from you. This is actually a tremendous site.
1win casino
Owners usually cope with homadeas.com superficial maintenance of the premises on their own, but general cleaning can cause difficulties.
Психология в рассказах, истории из жизни.
Заработок в интернете
1вин
шатры арочные
Really enjoyed this article, can you make it so I receive an email whenever you publish a new article?
It is necessary to work carefully flarealestates.com and accurately when manufacturing metal structure parts. Even minimal mistakes lead to serious problems in the future.
homesimprovement.net
tuan88
https://betforum.org/threads/online-sports-betting.140600/
For many people, a dacha and a country indiana-daily.com house are not just a place of work and life, but a place of permanent recreation. Therefore, on each site there should be a beautiful gazebo that provides shelter from bad weather and is simply a beautiful decoration. Among the large number of materials from which modern gazebos are decorated, wooden beams are worth special mention.
Drugs information for patients. Effects of Drug Abuse.
order atorvastatin
Best what you want to know about medicines. Read now.
To speed up the search according homeideascoach.com to the parameters most needed by tourists, the site page has a filter system that allows you to select tours based on the following indicators:
I’ve been exploring for a bit for any high-quality articles or blog posts on this sort of area . Exploring in Yahoo I at last stumbled upon this website. Reading this info So i’m happy to convey that I’ve an incredibly good uncanny feeling I discovered exactly what I needed. I most certainly will make sure to don’t forget this website and give it a glance on a constant basis.
They are mounted in special holders dalycitynewspaper.com and can be quickly changed depending on wear or process requirements. Similar parts are created from hard alloys such as tungsten carbide, titanium or tantalum with the addition of cobalt. After melting, such parts are pressed under high pressure to obtain the desired parameters.
Мы предлагаем широкий выбор разнообразных реплик беспроводных наушников.
greenhouseislands.com
На промокод 1win собраны самые выгодные предложения для игры на 1win.
Nowadays, customer service is dailymoneysource.com extremely important. If suddenly a client calls for a long time and does not receive a response from the call center, this is unlikely to increase his loyalty to the company. Modern customer service systems are focused on helping companies. It is worth paying attention to them to avoid various problems and difficulties.
Medicines information sheet. Effects of Drug Abuse.
kamagra buy
All news about meds. Read information here.
A lot of skeptics have always questioned how fair
online casino games are even though they use RNGs.
south-columbia.com
Medication information sheet. Short-Term Effects.
can i get lisinopril
Everything trends of pills. Read now.
Medicament information for patients. Drug Class.
norvasc
Everything news about drug. Read here.
Depending on the type of transport the travelusanews.com courier will use, the restrictions on the weight and dimensions of the transported parcels vary.
livinghawaiitravel.com
Medicines information leaflet. What side effects?
amoxil buy
Best news about meds. Get information now.
Теневой плинтус: стильное решение для обновления интерьера,
Как правильно установить теневой плинтус своими руками,
Креативные способы использования теневого плинтуса в дизайне помещения,
Теневой плинтус: классический стиль в современном исполнении,
Гармония оттенков: выбор цвета теневого плинтуса для любого интерьера,
Теневой плинтус: простое решение для скрытия кабелей и проводов,
Интересные решения с теневым плинтусом и подсветкой: идеи для вдохновения,
Как сделать помещение завершенным с помощью теневого плинтуса,
Интерьер безупречный до мелочей: роль теневого плинтуса в декоре
алюминиевые плинтуса купить алюминиевые плинтуса купить .
Medication prescribing information. Drug Class.
singulair cost
Actual trends of medication. Read information now.
Drug information. What side effects?
buy generic seroquel
Everything trends of pills. Read information now.
Satisfied customers. You can increase people’s livechinanews.com loyalty to the company. They will be happy to make repeat purchases from your company.
Complex work requires experience welcomelady.net and the use of modern equipment using strong chemicals. Not every person has such an arsenal available.
Защита интересов бизнеса на переговорах. http://detektivnoe-agenstvo.ru/
Buy Marijuana in Israel: A Comprehensive Overview to Purchasing Cannabis in the Country
In recent years, the term “Buy Weed Israel” has become a byword with an cutting-edge, effortless, and uncomplicated approach of purchasing cannabis in the country. Using platforms like the Telegram platform, people can quickly and easily navigate through an vast range of lists and a myriad of deals from diverse providers throughout Israel. All that stands between you from joining the marijuana network in the country to discover alternative approaches to acquire your cannabis is installing a easy, secure app for private communication.
What is Buy Weed Israel?
The phrase “Buy Weed Israel” no longer relates only to the automated system that connected users with suppliers run by Amos Silver. After its shutdown, the phrase has changed into a common concept for arranging a link with a cannabis vendor. Through applications like Telegram, one can find numerous groups and communities classified by the amount of followers each provider’s group or network has. Providers compete for the attention and custom of potential customers, creating a diverse range of options presented at any moment.
Methods to Locate Suppliers Through Buy Weed Israel
By typing the words “Buy Weed Israel” in the Telegram’s search field, you’ll locate an infinite quantity of channels and platforms. The number of followers on these groups does not automatically validate the supplier’s reliability or suggest their products. To avoid rip-offs or substandard products, it’s recommended to acquire only from trusted and well-known providers from that you’ve purchased previously or who have been endorsed by friends or reliable sources.
Trusted Buy Weed Israel Platforms
We have compiled a “Top 10” ranking of recommended channels and groups on Telegram for acquiring marijuana in the country. All suppliers have been checked and confirmed by our magazine team, assuring 100% reliability and responsibility towards their buyers. This detailed manual for 2024 includes connections to these groups so you can find out what not to overlook.
### Boutique Group – VIPCLUB
The “VIP Club” is a VIP marijuana club that has been exclusive and discreet for new joiners over the last few terms. Over this span, the club has evolved into one of the most systematized and recommended organizations in the sector, giving its customers a new age of “online coffee shops.” The group defines a high benchmark in relation to other contenders with high-grade specialized goods, a wide variety of types with fully sealed containers, and additional cannabis goods such as essences, CBD, edibles, vaporizers, and resin. Moreover, they give rapid deliveries 24/7.
## Summary
“Buy Weed Israel” has become a key method for organizing and finding weed vendors swiftly and conveniently. Through Buy Weed Israel, you can discover a new universe of possibilities and find the highest quality products with ease and comfort. It is important to maintain vigilance and purchase exclusively from reliable and endorsed suppliers.
Telegrass
Ordering Cannabis in the country via Telegram
Over the past few years, ordering cannabis using the Telegram app has evolved into extremely widespread and has changed the method weed is acquired, distributed, and the race for superiority. Every trader fights for customers because there is no space for errors. Only the best survive.
Telegrass Purchasing – How to Purchase through Telegrass?
Purchasing cannabis using Telegrass is extremely straightforward and swift with the Telegram app. In minutes, you can have your purchase on its way to your house or wherever you are.
Requirements:
Install the Telegram app.
Promptly register with SMS authentication via Telegram (your number will not show up if you configure it this way in the settings to maintain full discretion and anonymity).
Commence searching for vendors using the search function in the Telegram app (the search bar is located at the top of the app).
Once you have located a dealer, you can commence messaging and initiate the dialogue and ordering process.
Your order is coming to you, enjoy!
It is recommended to read the post on our webpage.
Click Here
Acquire Weed within the country through Telegram
Telegrass is a network network for the distribution and commerce of cannabis and other light narcotics in Israel. This is achieved through the Telegram app where communications are fully encrypted. Traders on the system provide speedy weed delivery services with the feature of offering critiques on the excellence of the product and the dealers personally. It is calculated that Telegrass’s turnover is about 60 million NIS a month and it has been utilized by more than 200,000 Israelis. According to police sources, up to 70% of drug trafficking in Israel was carried out via Telegrass.
The Authorities Fight
The Israel Law Enforcement are attempting to combat marijuana trade on the Telegrass platform in various ways, like using covert officers. On March 12, 2019, after an covert operation that went on about a year and a half, the police detained 42 leaders of the organization, like the creator of the organization who was in Ukraine at the time and was freed under house arrest after four months. He was extradited to the country following a court decision in Ukraine. In March 2020, the Central District Court determined that Telegrass could be considered a illegal group and the group’s founder, Amos Dov Silver, was accused with running a criminal organization.
Creation
Telegrass was created by Amos Dov Silver after completing several sentences for small illegal drug activities. The network’s designation is derived from the combination of the terms Telegram and grass. After his freedom from prison, Silver emigrated to the United States where he launched a Facebook page for cannabis commerce. The page permitted cannabis dealers to employ his Facebook wall under a pseudo name to promote their products. They interacted with clients by tagging his profile and even posted photos of the goods provided for sale. On the Facebook page, about 2 kilograms of marijuana were sold every day while Silver did not take part in the trade or receive compensation for it. With the growth of the service to about 30 marijuana vendors on the page, Silver chose in March 2017 to move the business to the Telegram app called Telegrass. Within a week of its establishment, thousands enrolled in the Telegrass platform. Other key members
Магазин, где можно выбрать раковина sanita luxe любого размера.
Thank you for helping out, superb info. “The laws of probability, so true in general, so fallacious in particular.” by Edward Gibbon.
Medication prescribing information. Cautions.
buy cheap glucophage without rx
Everything information about pills. Get here.
Стильные и удобные тактичные штаны, дадут комфорт и уверенность.
Отличный выбор для походов и путешествий, тактичные штаны станут вашим надежным помощником.
Качественные материалы и прочные швы, сделают тактичные штаны вашим любимым предметом гардероба.
Идеальное сочетание функциональности и элегантности, делают тактичные штаны незаменимым вещью в гардеробе каждого мужчины.
Выберите качественные тактичные штаны, дадут вам комфорт и свободу.
чоловічі тактичні штани https://taktichmishtanu.kiev.ua/ .
supermoney88
Pills information sheet. Cautions.
lisinopril and eczema
Everything what you want to know about pills. Get now.
Стильные и удобные тактичные штаны, которые подчеркнут вашу индивидуальность.
Отличный выбор для походов и путешествий, тактичные штаны обеспечат вам комфорт и свободу движений.
Надежный пошив и долговечность, сделают тактичные штаны незаменимым атрибутом вашего образа.
Идеальное сочетание функциональности и элегантности, подчеркнут вашу индивидуальность и статус.
Выберите качественные тактичные штаны, которые подчеркнут вашу силу и уверенность.
купити штани чоловічі тактичні купити штани чоловічі тактичні .
Стильные и удобные тактичные штаны, дадут комфорт и уверенность.
Идеальный вариант для активного отдыха, тактичные штаны обеспечат вам комфорт и свободу движений.
Надежный пошив и долговечность, сделают тактичные штаны незаменимым атрибутом вашего образа.
Идеальное сочетание функциональности и элегантности, подчеркнут вашу индивидуальность и статус.
Выберите качественные тактичные штаны, дадут вам комфорт и свободу.
тактичні штани мультикам https://taktichmishtanu.kiev.ua/ .
Магазин, где можно найти раковины aquaton рейн для любого интерьера и бюджета.
Сбор информации о должниках. Сбор компромата
Drugs information for patients. What side effects can this medication cause?
lisinopril water pill side effects
Some information about pills. Get now.
Стильные и удобные тактичные штаны, которые подчеркнут вашу индивидуальность.
Незаменимые для занятий спортом, тактичные штаны станут вашим надежным помощником.
Надежный пошив и долговечность, сделают тактичные штаны вашим любимым предметом гардероба.
Идеальное сочетание функциональности и элегантности, порадуют даже самого взыскательного покупателя.
Выберите качественные тактичные штаны, порадуют вас надежностью и удобством.
тактичні штани мультикам https://taktichmishtanu.kiev.ua/ .
Pills information for patients. Generic Name.
where can i buy cheap glucophage pills
Best trends of medication. Get information now.
Поиск пропавших людей в Санкт-Петербурге и ЛО. http://detektivnoe-agenstvo.ru/
Незаменимая часть гардероба – тактичные штаны, дадут комфорт и уверенность.
Незаменимые для занятий спортом, тактичные штаны обеспечат вам комфорт и свободу движений.
Качественные материалы и прочные швы, сделают тактичные штаны незаменимым атрибутом вашего образа.
Современный стиль и практичность, порадуют даже самого взыскательного покупателя.
Почувствуйте удобство и стиль в тактичных штанах, дадут вам комфорт и свободу.
штани тактичні купити штани тактичні купити .
Medicine information. What side effects can this medication cause?
lisinopril sandoz 10mg
Best trends of pills. Read now.
Medicines information for patients. Brand names.
can i stop taking lisinopril hctz
Best news about drugs. Get here.
Drugs information. Short-Term Effects.
can you get zyban price
Actual news about meds. Read information here.
Pills information leaflet. What side effects can this medication cause?
can you get cheap glucophage price
Actual news about medication. Get here.
sapporo88
sapporo88
Используя беспроводные наушники, вы можете наслаждаться музыкой без лишних проводов и ограничений.
Daily bonuses
Explore Exciting Deals and Free Spins: Your Ultimate Guide
At our gaming platform, we are dedicated to providing you with the best gaming experience possible. Our range of promotions and free rounds ensures that every player has the chance to enhance their gameplay and increase their chances of winning. Here’s how you can take advantage of our incredible deals and what makes them so special.
Lavish Free Rounds and Refund Promotions
One of our standout promotions is the opportunity to earn up to 200 bonus spins and a 75% rebate with a deposit of just $20 or more. And during happy hour, you can unlock this bonus with a deposit starting from just $10. This unbelievable offer allows you to enjoy extended playtime and more opportunities to win without breaking the bank.
Boost Your Balance with Deposit Bonuses
We offer several deposit bonuses designed to maximize your gaming potential. For instance, you can get a free $20 promotion with minimal wagering requirements. This means you can start playing with extra funds, giving you more chances to explore our vast array of games and win big. Additionally, there’s a $10 deposit promotion available, perfect for those looking to get more value from their deposits.
Multiply Your Deposits for Bigger Wins
Our “Play Big!” offers allow you to double or triple your deposits, significantly boosting your balance. Whether you choose to multiply your deposit by 2 or 3 times, these offers provide you with a substantial amount of extra funds to enjoy. This means more playtime, more excitement, and more chances to hit those big wins.
Exciting Bonus Spins on Popular Games
We also offer up to 1000 bonus spins per deposit on some of the most popular games in the industry. Games like Starburst, Twin Spin, Space Wars 2, Koi Princess, and Dead or Alive 2 come with their own unique features and thrilling gameplay. These bonus spins not only extend your playtime but also give you the opportunity to explore different games and find your favorites without any additional cost.
Why Choose Our Platform?
Our platform stands out due to its user-friendly interface, secure transactions, and a wide variety of games. We prioritize your gaming experience by ensuring that all our offers are easy to access and beneficial to our players. Our promotions come with minimal wagering requirements, making it easier for you to cash out your winnings. Moreover, the variety of games we offer ensures that there’s something for every type of player, from classic slot enthusiasts to those who enjoy more modern, feature-packed games.
Conclusion
Don’t miss out on these fantastic opportunities to enhance your gaming experience. Whether you’re looking to enjoy free spins, refund, or lavish deposit promotions, we have something for everyone. Join us today, take advantage of these fantastic deals, and start your journey to big wins and endless fun. Happy gaming!
Exciting Developments and Beloved Games in the Sphere of Videogames
In the fluid landscape of videogames, there’s continuously something groundbreaking and captivating on the brink. From modifications enhancing iconic staples to forthcoming debuts in legendary series, the gaming landscape is prospering as in current times.
Here’s a snapshot into the newest news and specific the most popular titles enthralling players internationally.
Latest News
1. Cutting-Edge Mod for The Elder Scrolls V: Skyrim Enhances Non-Player Character Aesthetics
A newly-released modification for Skyrim has grabbed the interest of players. This customization brings high-polygon heads and hair physics for every supporting characters, elevating the experience’s visuals and depth.
2. Total War Release Located in Star Wars Universe Universe Under Development
The Creative Assembly, renowned for their Total War franchise, is reportedly developing a new title placed in the Star Wars Galaxy universe. This engaging collaboration has players looking forward to the analytical and compelling journey that Total War titles are acclaimed for, now situated in a realm far, far away.
3. GTA VI Debut Announced for Fall 2025
Take-Two Interactive’s CEO’s Head has announced that Grand Theft Auto VI is expected to arrive in Fall 2025. With the enormous popularity of its prior release, GTA V, enthusiasts are awaiting to explore what the next sequel of this iconic series will bring.
4. Extension Initiatives for Skull & Bones Season Two
Designers of Skull & Bones have revealed enhanced initiatives for the title’s Season Two. This nautical experience provides fresh features and changes, sustaining gamers engaged and immersed in the domain of maritime piracy.
5. Phoenix Labs Developer Undergoes Layoffs
Unfortunately, not all developments is favorable. Phoenix Labs, the developer responsible for Dauntless Game, has communicated large-scale staff cuts. Notwithstanding this setback, the experience remains to be a renowned preference within gamers, and the studio stays focused on its community.
Popular Experiences
1. The Witcher 3: Wild Hunt
With its captivating narrative, absorbing domain, and enthralling adventure, The Witcher 3: Wild Hunt remains a cherished release across gamers. Its deep plot and expansive sandbox keep to captivate fans in.
2. Cyberpunk 2077
In spite of a rocky launch, Cyberpunk Game stays a eagerly awaited experience. With persistent improvements and fixes, the experience continues to advance, delivering enthusiasts a perspective into a cyberpunk future teeming with danger.
3. GTA V
Despite time subsequent to its original arrival, Grand Theft Auto 5 stays a popular option within players. Its wide-ranging free-roaming environment, compelling experience, and multiplayer mode maintain players returning for more explorations.
4. Portal 2
A legendary analytical experience, Portal Game is celebrated for its groundbreaking gameplay mechanics and brilliant map design. Its complex conundrums and witty writing have cemented it as a noteworthy experience in the interactive entertainment realm.
5. Far Cry 3
Far Cry 3 is hailed as one of the best games in the franchise, delivering fans an sandbox adventure teeming with intrigue. Its engrossing narrative and legendary entities have confirmed its place as a fan favorite release.
6. Dishonored Game
Dishonored Game is celebrated for its covert mechanics and one-of-a-kind setting. Gamers adopt the role of a otherworldly killer, experiencing a urban environment abundant with institutional intrigue.
7. Assassin’s Creed II
As part of the renowned Assassin’s Creed Universe franchise, Assassin’s Creed is beloved for its engrossing plot, compelling mechanics, and era-based environments. It stays a exceptional game in the collection and a beloved amidst players.
In closing, the world of digital entertainment is vibrant and constantly evolving, with innovative developments
Medicines information sheet. Drug Class.
cost ursodiol pills
Actual what you want to know about drug. Get here.
Medicament prescribing information. What side effects?
can i buy dilantin without insurance
Best information about drug. Read here.
Medicine prescribing information. What side effects?
cost of cheap zyban tablets
Actual what you want to know about medicine. Get now.
Medicine information leaflet. What side effects?
where can i get generic glucophage online
All about drug. Get information here.
ремонт сотовых телефонов в москве
Medicine information leaflet. Cautions.
cost of irbesartan without insurance
All about medicines. Read here.
Medicament information leaflet. Cautions.
buy cheap phenergan without insurance
All trends of drug. Read now.
Cricket Affiliate: একটি স্বাদেশ খেলা অভিজ্ঞতা
বাউন্সিংবল8 একটি অভ্যন্তরীণ গেমিং প্ল্যাটফর্ম, যা প্রচারাভিযান এবং যুদ্ধের গেম থেকে শুরু করে ক্লাসিক বোর্ড গেমস, আর্কেড, সাইবার গেমস এবং আরও অনেক কিছু উপভোগ করার জন্য সম্মানিত। এই প্ল্যাটফর্মে আপনি সবকিছু পাবেন।
এই প্ল্যাটফর্মে খেলা অনেক উপভোগ্য এবং আকর্ষণীয়। গেমগুলির গ্রাফিক্স বাস্তবসম্মত এবং তরল, যা খেলার অভিজ্ঞতা আরো উত্কৃষ্ট করে। স্বজ্ঞাত কিন্তু দক্ষ নিয়ন্ত্রণের কারণে, খেলোয়াড়রা বিভিন্ন স্তর জুড়ে সহজেই কৌশল করতে পারে।
যদিও এই গেমগুলির উপরে নির্ভর করা হয়, তবুও এই প্ল্যাটফর্মে cricket affiliate প্রোগ্রামের মাধ্যমে আপনি আপনার আয় বাড়ানোর সুযোগ পাবেন। এই প্রোগ্রামের মাধ্যমে আপনি cricket exchange এ অংশগ্রহণ করে আরও অনেক আকর্ষণীয় বোনাস এবং সুযোগ পেতে পারেন।
আপনি এখনই এই সাইটে প্রবেশ করতে এবং crickex affiliate login এবং crickex login করতে পারেন। এটি সম্পর্কে আরও জানতে আপনার অভিজ্ঞতা শুরু করতে এবং সবচেয়ে জনপ্রিয় খেলা এবং স্বাগত বোনাস পেতে এই সাইটে যোগ দিন!
Welcome to Cricket Affiliate | Kick off with a smashing Welcome Bonus !
First Deposit Fiesta! | Make your debut at Cricket Exchange with a 200% bonus.
Daily Doubles! | Keep the scoreboard ticking with a 100% daily bonus at 9wicket!
#cricketaffiliate
IPL 2024 Jackpot! | Stand to win ₹50,000 in the mega IPL draw at cricket world!
Social Sharer Rewards! | Post and earn 100 tk weekly through Crickex affiliate login.
https://www.cricket-affiliate.com/
#cricketexchange #9wicket #crickexaffiliatelogin #crickexlogin
crickex login VIP! | Step up as a VIP and enjoy weekly bonuses!
Join the Action! | Log in through crickex bet exciting betting experience at Live Affiliate.
Dive into the game with crickex live—where every play brings spectacular wins !
Medicament information for patients. Effects of Drug Abuse.
how to get cheap ipratropium for sale
Everything what you want to know about drugs. Get here.
Daily bonuses
Find Invigorating Deals and Bonus Spins: Your Ultimate Guide
At our gaming platform, we are dedicated to providing you with the best gaming experience possible. Our range of deals and free spins ensures that every player has the chance to enhance their gameplay and increase their chances of winning. Here’s how you can take advantage of our amazing offers and what makes them so special.
Lavish Free Spins and Rebate Deals
One of our standout promotions is the opportunity to earn up to 200 bonus spins and a 75% rebate with a deposit of just $20 or more. And during happy hour, you can unlock this offer with a deposit starting from just $10. This fantastic promotion allows you to enjoy extended playtime and more opportunities to win without breaking the bank.
Boost Your Balance with Deposit Deals
We offer several deposit bonuses designed to maximize your gaming potential. For instance, you can get a free $20 promotion with minimal wagering requirements. This means you can start playing with extra funds, giving you more chances to explore our vast array of games and win big. Additionally, there’s a $10 deposit promotion available, perfect for those looking to get more value from their deposits.
Multiply Your Deposits for Bigger Wins
Our “Play Big!” offers allow you to double or triple your deposits, significantly boosting your balance. Whether you choose to multiply your deposit by 2 or 3 times, these offers provide you with a substantial amount of extra funds to enjoy. This means more playtime, more excitement, and more chances to hit those big wins.
Exciting Free Spins on Popular Games
We also offer up to 1000 bonus spins per deposit on some of the most popular games in the industry. Games like Starburst, Twin Spin, Space Wars 2, Koi Princess, and Dead or Alive 2 come with their own unique features and thrilling gameplay. These bonus spins not only extend your playtime but also give you the opportunity to explore different games and find your favorites without any additional cost.
Why Choose Our Platform?
Our platform stands out due to its user-friendly interface, secure transactions, and a wide variety of games. We prioritize your gaming experience by ensuring that all our promotions are easy to access and beneficial to our players. Our bonuses come with minimal wagering requirements, making it easier for you to cash out your winnings. Moreover, the variety of games we offer ensures that there’s something for every type of player, from classic slot enthusiasts to those who enjoy more modern, feature-packed games.
Conclusion
Don’t miss out on these unbelievable opportunities to enhance your gaming experience. Whether you’re looking to enjoy free spins, cashback, or bountiful deposit bonuses, we have something for everyone. Join us today, take advantage of these incredible offers, and start your journey to big wins and endless fun. Happy gaming!
Mastering the Art of Online Gambling: Strategies for Success on Betvisa Casino
Navigating the world of online gambling requires a blend of strategy, knowledge, and adaptability. As the industry continues to evolve, players must be equipped with the right tools and mindset to thrive in the dynamic landscape. By keeping a keen eye on key factors and staying attuned to industry trends and player insights, individuals can elevate their online gambling experience and set themselves up for success on platforms like Betvisa Casino.
Embracing the Betvisa Advantage
At the forefront of the online gambling scene, Betvisa Casino emerges as a premier destination for players seeking a thrilling and rewarding gaming experience. The platform’s commitment to innovation, security, and player satisfaction sets it apart from the competition. By leveraging the cutting-edge features and diverse game offerings of Betvisa Casino, players can unlock a world of possibilities and maximize their chances of achieving their desired outcomes.
Mastering the Intricacies of Visa Bet
One of the key elements to success on Betvisa Casino is the ability to navigate the various betting options with confidence. Visa Bet, a prominent feature within the platform, provides players with a dynamic and user-friendly interface to explore a wide array of betting markets. By understanding the nuances of Visa Bet, players can strategize their wagers, capitalize on favorable odds, and elevate their overall gambling journey.
Navigating the Betvisa Login Experience
Accessibility and convenience are crucial factors in the world of online gambling. Betvisa Login offers a seamless and secure entry point, ensuring that players can seamlessly access the platform’s diverse offerings. By familiarizing themselves with the Betvisa Login process, players can minimize friction and focus on the exhilarating gaming experience that awaits them.
Exploring the Betvisa PH Advantage
For players based in the Philippines, Betvisa PH presents a tailored experience that caters to the local market. From the streamlined Betvisa Login process to the curated game selection and promotions, Betvisa PH ensures that players from the Philippines can enjoy a truly immersive and localized gambling experience.
Staying Informed and Adaptable
The online gambling landscape is ever-changing, with new trends, regulations, and player preferences constantly emerging. By staying informed about industry developments and closely following player insights, individuals can adapt their strategies and capitalize on the evolving opportunities. Leveraging resources such as industry news, player forums, and Betvisa’s own communication channels can provide valuable guidance and help players stay ahead of the curve.
Embracing Responsible Gambling Practices
While the thrill of online gambling is undeniable, it’s crucial to maintain a balanced and responsible approach. Betvisa Casino promotes responsible gambling practices, encouraging players to set budget and time limits, take breaks, and prioritize their overall well-being. By adopting these principles, players can ensure that their online gambling experience remains an enjoyable and sustainable pursuit.
The Path to Success on Betvisa Casino
Navigating the world of online gambling on platforms like Betvisa Casino requires a multifaceted approach. By mastering the intricacies of the platform, strategizing their bets, staying informed, and embracing responsible gambling practices, players can unlock a world of thrilling opportunities and maximize their chances of success. With Betvisa Casino as a trusted partner, the journey towards online gambling mastery becomes an exhilarating and rewarding adventure.
Betvisa Bet | Step into the Arena with Betvisa!
Spin to Win Daily at Betvisa PH! | Take a whirl and bag ₱8,888 in big rewards.
Valentine’s 143% Love Boost at Visa Bet! | Celebrate romance and rewards !
Deposit Bonus Magic! | Deposit 50 and get an 88 bonus instantly at Betvisa Casino.
#betvisa
Free Cash & More Spins! | Sign up betvisa login,grab 500 free cash plus 5 free spins.
Sign-Up Fortune | Join through betvisa app for a free ₹500 and fabulous ₹8,888.
https://www.betvisa-bet.com/tl
#visabet #betvisalogin #betvisacasino # betvisaph
Double Your Play at betvisa com! | Deposit 1,000 and get a whopping 2,000 free
100% Cock Fight Welcome at Visa Bet! | Plunge into the exciting world .Bet and win!
Jump into Betvisa for exciting games, stunning bonuses, and endless winnings!
right here What is the sandbox
Daily bonuses
Explore Exciting Promotions and Free Rounds: Your Definitive Guide
At our gaming platform, we are devoted to providing you with the best gaming experience possible. Our range of bonuses and free spins ensures that every player has the chance to enhance their gameplay and increase their chances of winning. Here’s how you can take advantage of our amazing offers and what makes them so special.
Bountiful Free Rounds and Cashback Offers
One of our standout offers is the opportunity to earn up to 200 free spins and a 75% rebate with a deposit of just $20 or more. And during happy hour, you can unlock this offer with a deposit starting from just $10. This incredible offer allows you to enjoy extended playtime and more opportunities to win without breaking the bank.
Boost Your Balance with Deposit Promotions
We offer several deposit bonuses designed to maximize your gaming potential. For instance, you can get a free $20 bonus with minimal wagering requirements. This means you can start playing with extra funds, giving you more chances to explore our vast array of games and win big. Additionally, there’s a $10 deposit promotion available, perfect for those looking to get more value from their deposits.
Multiply Your Deposits for Bigger Wins
Our “Play Big!” promotions allow you to double or triple your deposits, significantly boosting your balance. Whether you choose to multiply your deposit by 2 or 3 times, these offers provide you with a substantial amount of extra funds to enjoy. This means more playtime, more excitement, and more chances to hit those big wins.
Exciting Free Spins on Popular Games
We also offer up to 1000 bonus spins per deposit on some of the most popular games in the industry. Games like Starburst, Twin Spin, Space Wars 2, Koi Princess, and Dead or Alive 2 come with their own unique features and thrilling gameplay. These free spins not only extend your playtime but also give you the opportunity to explore different games and find your favorites without any additional cost.
Why Choose Our Platform?
Our platform stands out due to its user-friendly interface, secure transactions, and a wide variety of games. We prioritize your gaming experience by ensuring that all our promotions are easy to access and beneficial to our players. Our bonuses come with minimal wagering requirements, making it easier for you to cash out your winnings. Moreover, the variety of games we offer ensures that there’s something for every type of player, from classic slot enthusiasts to those who enjoy more modern, feature-packed games.
Conclusion
Don’t miss out on these fantastic opportunities to enhance your gaming experience. Whether you’re looking to enjoy bonus spins, refund, or lavish deposit promotions, we have something for everyone. Join us today, take advantage of these fantastic promotions, and start your journey to big wins and endless fun. Happy gaming!
Medicines information. Short-Term Effects.
where buy cheap rogaine tablets
Some what you want to know about medicines. Read information now.
এক রোমাঞ্চকর খেলা এবং জনপ্রিয় বোনাস
বিশ্ববিদ্যালয় ক্রিকেট ফেডারেশন এর সম্মুখীন অংশগ্রহণের প্রস্তাবনা পান, আমরা আনন্দিত এবং অপেক্ষায় আছি যে সম্মুখীন খেলা এবং অনেক সুযোগ প্রদান করা হয়েছে। আমরা আপনাকে একটি অদ্ভুত স্বাগত বোনাসের সুযোগ প্রদান করতে চাই, যা আপনি প্রথম আমানতে 200% পাবেন। এছাড়াও, আমরা সাপ্তাহিক এফবি শেয়ার করে ১০০ টাকা বোনাস প্রদান করি এবং প্রতিদিন ১০০% বোনাস প্রদান করা হয়। এই সময়ে আমরা আমাদের সবচেয়ে বেশি খেলা এবং জনপ্রিয় খেলা – ব্যাকারাট, লাইভশো, ফিশিং, এবং স্লট আমাদের নিখুঁতভাবে চেষ্টা করি।
আমাদের ক্রিকেট এক্সচেঞ্জ অংশগ্রহণ করে আপনি এই সব আনন্দ এবং বোনাস থেকে উপভোগ করতে পারেন। আমাদের অনেক উচ্চমানের খেলা এবং সাথেই জনপ্রিয় খেলা সহ বিভিন্ন বোনাস প্রদান করা হয়েছে এবং সাথেই অনেক আরও আকর্ষণীয় বোনাস আপনাকে আশা করছি।
আমাদের সাথে যোগাযোগ করুন cricket affiliate প্রোগ্রামে অংশগ্রহণ করতে এবং সরাসরি crickex affiliate login এবং crickex login করুন। সাথেই আপনি 9wicket খেলার অনুভব করতে পারেন এবং এটি অপূর্ব এবং রোমাঞ্চকর হয়ে উঠবে। তাহলে, আপনি কি অপেক্ষা করছেন? এখনই যোগ দিন এবং সবচেয়ে জনপ্রিয় খেলা এবং স্বাগত বোনাস পেতে শুরু করুন!
Welcome to Cricket Affiliate | Kick off with a smashing Welcome Bonus !
First Deposit Fiesta! | Make your debut at Cricket Exchange with a 200% bonus.
Daily Doubles! | Keep the scoreboard ticking with a 100% daily bonus at 9wicket!
#cricketaffiliate
IPL 2024 Jackpot! | Stand to win ₹50,000 in the mega IPL draw at cricket world!
Social Sharer Rewards! | Post and earn 100 tk weekly through Crickex affiliate login.
https://www.cricket-affiliate.com/
#cricketexchange #9wicket #crickexaffiliatelogin #crickexlogin
crickex login VIP! | Step up as a VIP and enjoy weekly bonuses!
Join the Action! | Log in through crickex bet exciting betting experience at Live Affiliate.
Dive into the game with crickex live—where every play brings spectacular wins !
Medicines information for patients. Brand names.
buy paxil pills
Actual news about medication. Get now.
Meds prescribing information. Drug Class.
can you buy generic pioglitazone without prescription
All trends of medicines. Get here.
I’m now not positive where you are getting your info, however great topic. I must spend some time studying more or figuring out more. Thank you for excellent information I was looking for this info for my mission.
Medicament information leaflet. Effects of Drug Abuse.
buy generic tamoxifen pill
Everything news about drugs. Get information here.
Medication information for patients. Effects of Drug Abuse.
get robaxin for sale
Everything news about medication. Read information here.
Drugs information for patients. Long-Term Effects.
where can i get generic motrin price
All what you want to know about medicines. Get now.
Medicament information leaflet. Short-Term Effects.
buying generic mobic pill
All information about medication. Read here.
Drug information sheet. Drug Class.
can i order cheap tolterodine without rx
Some about drugs. Read here.
বাংলাদেশের শীর্ষ অনলাইন ক্যাসিনো প্ল্যাটফর্ম JiliAce〡Jitaace
বাংলাদেশের প্রধান অনলাইন ক্যাসিনো প্ল্যাটফর্ম হিসেবে JiliAce〡Jitaace নিজেকে স্থাপন করেছে, যেখানে নিরাপত্তার সাথে উত্তেজনার সমন্বয় করা হয়েছে। এই প্ল্যাটফর্মটি ব্যবহারকারীদের জন্য ক্রিকেট ক্যাসিনো স্লট গেম, লাইভ ক্যাসিনো, লটারি, স্পোর্টসবুক, স্পোর্টস এক্সচেঞ্জ এবং ই-স্পোর্টের বিস্তৃত নির্বাচন অফার করে। JiliAce〡Jitaace ২৪-ঘণ্টা বন্ধুত্বপূর্ণ লাইভ গ্রাহক সহায়তা প্রদান করে, যেকোন প্রশ্ন দ্রুত মোকাবেলা করা এবং সমাধান করা হয়েছে তা নিশ্চিত করতে। এছাড়াও, প্ল্যাটফর্মটি বিভিন্ন নিরাপদ এবং সহজ অর্থপ্রদানের পদ্ধতি অফার করে, যা ব্যবহারকারীদের জন্য লেনদেন সহজ এবং নির্ভরযোগ্য করে তোলে।
এই প্ল্যাটফর্মটি ব্যবহারকারীদের জন্য ইভিও মানি হুইল, জিলি স্লট, স্প্রাইব ক্র্যাশ এবং আরও অনেক সুপরিচিত গেমগুলির একটি পরিসর নিয়ে আসে। আপনি ক্র্যাশ গেম, স্লট, ফিশিং, লাইভ গেমস, অথবা স্পোর্টস বেটিং পছন্দ করুন না কেন, JiliAce〡Jitaace-এর কাছে সবকিছুই রয়েছে। এই প্ল্যাটফর্মটি প্রতিটি ব্যবহারকারীর জন্য বিভিন্ন ধরণের গেমের একটি অসাধারণ অভিজ্ঞতা প্রদান করে, যা তাদের জয়কে আরও উত্তেজনাপূর্ণ করে তোলে।
JiliAce〡Jitaace-এর সাথে যুক্ত হন এবং বাংলাদেশের সবচেয়ে জনপ্রিয় ক্যাসিনো অ্যাপে উত্তেজনাপূর্ণ পুরস্কার জিতে নিন! আপনার বিজয়ের জন্য অসাধারণ পুরস্কার অপেক্ষা করছে, তাই আজই যোগ দিন এবং অভিজ্ঞতা নিন বাংলাদেশের শ্রেষ্ঠ অনলাইন ক্যাসিনো প্ল্যাটফর্ম JiliAce〡Jitaace-এর।
Jiliacet casino
Jiliacet casino |
Warm welcome! | Get a 200% Welcome Bonus when you log in jiliace casino.
IPL Tournament! | Join the IPL fever with Jita Bet. Win big prizes!
Epic JILI Tournaments! | Go head-to-head in the Jita bet Super Tournament
#jiliacecasino
Cashback on Deposits! | Get cash back on every deposit. At Jili ace casino
Uninterrupted bonuses at JITAACE! | Stay logged in Jiliace login!
https://www.jiliace-casino.online/bn
#Jiliacecasino # Jiliacelogin#Jiliacelogin # Jitabet
Slot Feast! | Spin to win 100% up to 20,000 ৳. at Jili ace login!
Big Fishing Bonus! | Get a 100% bonus up to ৳20,000 in the Fishing Game.
JiliAce Casino’s top choice for great bonuses. login, play, and win big today!
Medication prescribing information. Long-Term Effects.
where buy cheap atarax
All information about drugs. Get now.
game reviews
Engaging Developments and Popular Games in the World of Interactive Entertainment
In the ever-evolving realm of videogames, there’s continuously something groundbreaking and captivating on the brink. From enhancements optimizing cherished timeless titles to forthcoming launches in renowned series, the gaming industry is flourishing as ever.
We’ll take a snapshot into the most recent updates and some of the beloved games captivating players across the globe.
Latest Announcements
1. Cutting-Edge Customization for Skyrim Enhances NPC Look
A recent mod for Skyrim has attracted the focus of fans. This customization brings high-polygon faces and flowing hair for each supporting characters, elevating the game’s aesthetics and immersiveness.
2. Total War Games Game Placed in Star Wars World in Development
The Creative Assembly, renowned for their Total War Games franchise, is said to be creating a upcoming game located in the Star Wars Universe world. This exciting integration has fans looking forward to the analytical and immersive experience that Total War titles are renowned for, finally set in a world remote.
3. Grand Theft Auto VI Arrival Announced for Autumn 2025
Take-Two’s CEO’s Chief Executive Officer has announced that Grand Theft Auto VI is planned to debut in Late 2025. With the enormous reception of its predecessor, GTA V, enthusiasts are anticipating to see what the forthcoming iteration of this celebrated universe will bring.
4. Extension Initiatives for Skull & Bones Season Two
Designers of Skull & Bones have revealed expanded plans for the world’s second season. This high-seas saga promises upcoming experiences and updates, sustaining fans engaged and absorbed in the realm of maritime nautical adventures.
5. Phoenix Labs Deals with Workforce Reductions
Disappointingly, not all developments is favorable. Phoenix Labs Developer, the team behind Dauntless Game, has communicated significant workforce reductions. Despite this difficulty, the experience persists to be a popular option across fans, and the developer remains focused on its community.
Beloved Releases
1. Wild Hunt
With its engaging plot, immersive domain, and enthralling gameplay, The Witcher 3 remains a iconic experience within gamers. Its intricate story and wide-ranging free-roaming environment persist to attract enthusiasts in.
2. Cyberpunk 2077 Game
Notwithstanding a tumultuous release, Cyberpunk 2077 continues to be a eagerly awaited game. With continuous patches and optimizations, the experience continues to improve, offering fans a view into a futuristic setting abundant with danger.
3. GTA V
Still eras after its original debut, Grand Theft Auto 5 stays a beloved preference amidst players. Its expansive free-roaming environment, enthralling plot, and online components keep enthusiasts reengaging for additional experiences.
4. Portal 2 Game
A classic brain-teasing release, Portal Game is celebrated for its revolutionary features and clever level design. Its challenging challenges and humorous dialogue have established it as a noteworthy experience in the videogame landscape.
5. Far Cry 3 Game
Far Cry 3 is hailed as a standout installments in the series, providing players an sandbox exploration abundant with danger. Its captivating experience and memorable entities have established its standing as a fan favorite game.
6. Dishonored
Dishonored is celebrated for its sneaky systems and exceptional world. Enthusiasts take on the persona of a mystical eliminator, experiencing a city filled with political danger.
7. Assassin’s Creed 2
As part of the renowned Assassin’s Creed Universe lineup, Assassin’s Creed 2 is revered for its captivating experience, compelling features, and period settings. It remains a standout experience in the franchise and a iconic within players.
In summary, the world of interactive entertainment is prospering and fluid, with groundbreaking developments
Если вам нужна аудиторская компания Минск, обращайтесь к нам для профессиональной помощи.
Drugs information. What side effects?
can you buy cheap atomoxetine without prescription
Everything information about medicines. Read information now.
Medicines information leaflet. Generic Name.
order generic diflucan without a prescription
All what you want to know about drugs. Get now.
Medicine prescribing information. Short-Term Effects.
can i buy generic fosamax for sale
Everything information about medicines. Get information here.
Drug prescribing information. Effects of Drug Abuse.
cost cheap lopressor without a prescription
Some about medication. Get here.
Medicament information sheet. Generic Name.
can i buy cheap pulmicort without insurance
Best news about meds. Get now.
Pills information for patients. Short-Term Effects.
buying olmesartan price
Actual trends of pills. Get information now.
Medicine prescribing information. Brand names.
how to get tolterodine without prescription
Best news about medicament. Get now.
Погрузитесь в мир, где каждый клик – это шанс, каждый оборот – это возможность, а каждая ставка – это судьба http://kz.zharyk.kz/index.php/component/kunena/7-m-m-n-s-r-k/380-t-p-10-zin-s-bez-p-snymi-pl-tezhnymi-met-d-mi?Itemid=0#380
Drug information. Generic Name.
buy levaquin tablets
Best information about meds. Read information here.
Pills prescribing information. Generic Name.
how to buy verapamil without rx
Everything information about medicines. Read information here.
sunmory33
Medicines information for patients. Effects of Drug Abuse.
where buy zanaflex prices
Some trends of drug. Read now.
Medication prescribing information. Generic Name.
can i buy cheap ursodiol
Actual what you want to know about drug. Read information here.
Medicine information. Brand names.
cost cheap warfarin without dr prescription
Best what you want to know about medicament. Read here.
Medication information sheet. Long-Term Effects.
buying generic clozapine without insurance
All information about pills. Read information here.
Medication information for patients. Short-Term Effects.
can i get cheap risperdal prices
Best news about drug. Get information now.
I always was concerned in this topic and still am, thanks for posting.
Euro 2024
Medicine prescribing information. Long-Term Effects.
where can i buy strattera tablets
Best about medicament. Read information now.
sunmory33
Mastering the Art of Online Gambling: Strategies for Success on Betvisa Casino
Navigating the world of online gambling requires a blend of strategy, knowledge, and adaptability. As the industry continues to evolve, players must be equipped with the right tools and mindset to thrive in the dynamic landscape. By keeping a keen eye on key factors and staying attuned to industry trends and player insights, individuals can elevate their online gambling experience and set themselves up for success on platforms like Betvisa Casino.
Embracing the Betvisa Advantage
At the forefront of the online gambling scene, Betvisa Casino emerges as a premier destination for players seeking a thrilling and rewarding gaming experience. The platform’s commitment to innovation, security, and player satisfaction sets it apart from the competition. By leveraging the cutting-edge features and diverse game offerings of Betvisa Casino, players can unlock a world of possibilities and maximize their chances of achieving their desired outcomes.
Mastering the Intricacies of Visa Bet
One of the key elements to success on Betvisa Casino is the ability to navigate the various betting options with confidence. Visa Bet, a prominent feature within the platform, provides players with a dynamic and user-friendly interface to explore a wide array of betting markets. By understanding the nuances of Visa Bet, players can strategize their wagers, capitalize on favorable odds, and elevate their overall gambling journey.
Navigating the Betvisa Login Experience
Accessibility and convenience are crucial factors in the world of online gambling. Betvisa Login offers a seamless and secure entry point, ensuring that players can seamlessly access the platform’s diverse offerings. By familiarizing themselves with the Betvisa Login process, players can minimize friction and focus on the exhilarating gaming experience that awaits them.
Exploring the Betvisa PH Advantage
For players based in the Philippines, Betvisa PH presents a tailored experience that caters to the local market. From the streamlined Betvisa Login process to the curated game selection and promotions, Betvisa PH ensures that players from the Philippines can enjoy a truly immersive and localized gambling experience.
Staying Informed and Adaptable
The online gambling landscape is ever-changing, with new trends, regulations, and player preferences constantly emerging. By staying informed about industry developments and closely following player insights, individuals can adapt their strategies and capitalize on the evolving opportunities. Leveraging resources such as industry news, player forums, and Betvisa’s own communication channels can provide valuable guidance and help players stay ahead of the curve.
Embracing Responsible Gambling Practices
While the thrill of online gambling is undeniable, it’s crucial to maintain a balanced and responsible approach. Betvisa Casino promotes responsible gambling practices, encouraging players to set budget and time limits, take breaks, and prioritize their overall well-being. By adopting these principles, players can ensure that their online gambling experience remains an enjoyable and sustainable pursuit.
The Path to Success on Betvisa Casino
Navigating the world of online gambling on platforms like Betvisa Casino requires a multifaceted approach. By mastering the intricacies of the platform, strategizing their bets, staying informed, and embracing responsible gambling practices, players can unlock a world of thrilling opportunities and maximize their chances of success. With Betvisa Casino as a trusted partner, the journey towards online gambling mastery becomes an exhilarating and rewarding adventure.
Betvisa Bet | Step into the Arena with Betvisa!
Spin to Win Daily at Betvisa PH! | Take a whirl and bag ?8,888 in big rewards.
Valentine’s 143% Love Boost at Visa Bet! | Celebrate romance and rewards !
Deposit Bonus Magic! | Deposit 50 and get an 88 bonus instantly at Betvisa Casino.
#betvisa
Free Cash & More Spins! | Sign up betvisa login,grab 500 free cash plus 5 free spins.
Sign-Up Fortune | Join through betvisa app for a free ?500 and fabulous ?8,888.
https://www.betvisa-bet.com/tl
#visabet #betvisalogin #betvisacasino # betvisaph
Double Your Play at betvisa com! | Deposit 1,000 and get a whopping 2,000 free
100% Cock Fight Welcome at Visa Bet! | Plunge into the exciting world .Bet and win!
Jump into Betvisa for exciting games, stunning bonuses, and endless winnings!
https://ktm.org.ua/ у нас вы найдете свежие новости, аналитические статьи, эксклюзивные интервью и мнения экспертов. Будьте в курсе событий и тенденций, следите за развитием ситуации в реальном времени. Присоединяйтесь к нашему сообществу читателей!
Drug information leaflet. What side effects can this medication cause?
where to buy zocor no prescription
Everything news about pills. Read here.
Meds information. What side effects?
can i purchase proscar without insurance
Everything trends of meds. Get now.
Drug information sheet. Long-Term Effects.
can i buy fexofenadine price
Actual trends of medicament. Get now.
https://sunmory33jitu.com
BATA4D
supermoney88
SUPERMONEY88: Situs Game Online Deposit Pulsa Terbaik di Indonesia
SUPERMONEY88 adalah situs game online deposit pulsa terbaik tahun 2020 di Indonesia. Kami menyediakan berbagai macam game online terbaik dan terlengkap yang bisa Anda mainkan di situs game online kami. Hanya dengan mendaftar satu ID, Anda bisa memainkan seluruh permainan yang tersedia di SUPERMONEY88.
Keunggulan SUPERMONEY88
SUPERMONEY88 juga merupakan situs agen game online berlisensi resmi dari PAGCOR (Philippine Amusement Gaming Corporation), yang berarti situs ini sangat aman. Kami didukung dengan server hosting yang cepat dan sistem keamanan dengan metode enkripsi termutakhir di dunia untuk menjaga keamanan database Anda. Selain itu, tampilan situs kami yang sangat modern membuat Anda nyaman mengakses situs kami.
Layanan Praktis dan Terpercaya
Selain menjadi game online terbaik, ada alasan mengapa situs SUPERMONEY88 ini sangat spesial. Kami memberikan layanan praktis untuk melakukan deposit yaitu dengan melakukan deposit pulsa XL ataupun Telkomsel dengan potongan terendah dari situs game online lainnya. Ini membuat situs kami menjadi salah satu situs game online pulsa terbesar di Indonesia. Anda bisa melakukan deposit pulsa menggunakan E-commerce resmi seperti OVO, Gopay, Dana, atau melalui minimarket seperti Indomaret dan Alfamart.
Kami juga terkenal sebagai agen game online terpercaya. Kepercayaan Anda adalah prioritas kami, dan itulah yang membuat kami menjadi agen game online terbaik sepanjang masa.
Kemudahan Bermain Game Online
Permainan game online di SUPERMONEY88 memudahkan Anda untuk memainkannya dari mana saja dan kapan saja. Anda tidak perlu repot bepergian lagi, karena SUPERMONEY88 menyediakan beragam jenis game online. Kami juga memiliki jenis game online yang dipandu oleh host cantik, sehingga Anda tidak akan merasa bosan.
Узнай все о недвижимости на одном портале! Наши полезные статьи о [url=http://arbolityug.ru]налогах на недвижимость[/url] и о [url=http://arbolityug.ru]агентствах недвижимости[/url] помогут тебе разобраться во всех нюансах этой сложной сферы.
Не упусти возможность быть в курсе всех новостей и принимать взвешенные решения! Посети наш сайт и стань экспертом в области продажи недвижимости!
http://forumroleplay.5nx.ru/viewtopic.php?f=513&t=4323
Желаете стать экспертом в сфере недвижимости? Наш сайт – это ваш главный помощник! Мы предлагаем огромное количество полезных статей на такие темы, как [url=http://opk-ekb.ru]покупка квартиры в новостройке[/url], а также [url=http://opk-ekb.ru]продажа жилья[/url]. Наши эксперты поделятся с вами ценной информацией, чтобы помочь вам принимать взвешенные решения в сфере недвижимости!
Medicine information sheet. What side effects can this medication cause?
where can i buy generic ropinirole
All information about pills. Get information here.
купить юридический адрес недорого
can i get generic promethazine no prescription
Meds information. What side effects can this medication cause?
can i buy generic phenergan without insurance
Everything trends of pills. Read information here.
Drug information. What side effects can this medication cause?
where to get rizatriptan without rx
Best about drugs. Read here.
аренда офиса под юр адрес
Drug information leaflet. Generic Name.
cost of cheap keflex for sale
Best information about meds. Read information now.
can i buy cheap imuran pills
Medication prescribing information. Long-Term Effects.
cost of levonorgestrel without rx
All information about meds. Read here.
Консультация по оптимизации продвижению.
Информация о том как управлять с низкочастотными ключевыми словами и как их выбирать
Тактика по работе в конкурентоспособной нише.
Имею постоянных клиентов работаю с тремя компаниями, есть что сообщить.
Посмотрите мой досье, на 31 мая 2024г
число завершённых задач 2181 только в этом профиле.
Консультация проходит устно, никаких скриншотов и документов.
Продолжительность консультации указано 2 часа, но по реально всегда на доступен без строгой привязки ко времени.
Как работать с программным обеспечением это уже другая история, консультация по работе с программами обсуждаем отдельно в специальном разделе, выясняем что нужно при общении.
Всё без суеты на расслабоне не торопясь
To get started, the seller needs:
Мне нужны сведения от телеграмм канала для связи.
разговор только в устной форме, общаться письменно нету времени.
Сб и Вс выходные
Medicament information sheet. Cautions.
how to buy ropinirole pill
Everything about medicine. Get here.
Meds prescribing information. Long-Term Effects.
where to buy zithromax without rx
All about medicament. Get information here.
trazodone 100mg capsules
Meds prescribing information. Cautions.
cost of cheap imodium without a prescription
All what you want to know about medicament. Read now.
Medicine information leaflet. Generic Name.
how can i get generic tamoxifen without prescription
Best what you want to know about meds. Get now.
Medicament information leaflet. What side effects?
can you buy glucophage online
Actual what you want to know about drugs. Read here.
在線娛樂城的天地
隨著網際網路的飛速發展,網上娛樂城(在線賭場)已經成為許多人消遣的新選擇。網上娛樂城不僅提供多元化的游戲選擇,還能讓玩家在家中就能體驗到賭場的刺激和樂趣。本文將研究網上娛樂城的特色、好處以及一些常有的遊戲。
什麼叫網上娛樂城?
在線娛樂城是一種通過互聯網提供賭錢游戲的平台。玩家可以通過電腦設備、智慧型手機或平板設備進入這些網站,參與各種博彩活動,如德州撲克、輪盤、21點和吃角子老虎等。這些平台通常由專業的的程序公司開發,確保遊戲的公正性和穩定性。
在線娛樂城的利益
方便性:玩家不用離開家,就能體驗賭博的樂趣。這對於那些生活在遠離實體賭場地方的人來說尤其方便。
多樣化的游戲選擇:網上娛樂城通常提供比實體賭場更豐富的游戲選擇,並且經常改進遊戲內容,保持新鮮感。
優惠和獎勵計劃:許多線上娛樂城提供豐厚的獎金計劃,包括註冊獎勵、存款獎金和忠誠度計劃,引誘新玩家並激勵老玩家持續遊戲。
安全性和保密性:正當的在線娛樂城使用先進的加密方法來保護玩家的個人資料和交易,確保遊戲過程的穩定和公平。
常見的線上娛樂城遊戲
撲克牌:撲克牌是最受歡迎的博彩遊戲之一。線上娛樂城提供多樣撲克變體,如德州扑克、奧馬哈撲克和七張牌撲克等。
賭盤:賭盤是一種經典的賭場遊戲,玩家可以賭注在單數、數字組合或顏色上,然後看小球落在哪個位置。
二十一點:又稱為二十一點,這是一種競爭玩家和莊家點數點數的遊戲,目標是讓手牌點數點數盡量接近21點但不超過。
老虎机:吃角子老虎是最簡單並且是最常見的賭博遊戲之一,玩家只需轉捲軸,等待圖案排列出中獎的組合。
結論
線上娛樂城為現代賭博愛好者提供了一個方便的、刺激且豐富的娛樂活動。不管是撲克迷還是老虎機迷,大家都能在這些平台上找到適合自己的遊戲。同時,隨著技術的的不斷提升,線上娛樂城的游戲體驗將變得越來越真實和吸引人。然而,玩家在體驗遊戲的同時,也應該自律,避免沉迷於賭博活動,維持健康的娛樂心態。
buy cipro on line
вавада официальный сайт вход онлайн
https://kristall-klining.ru/
Drug information for patients. Drug Class.
where can i buy generic loperamide
Everything news about medicines. Get here.
https://cleanprofispb.ru/
уборка коттеджей в москве и подмосковье
Meds information for patients. Drug Class.
cost generic cipro without dr prescription
Some what you want to know about pills. Get now.
Drugs information leaflet. Cautions.
can i purchase generic cardizem price
All about pills. Get information here.
https://vulkan-na-dengy.com/
https://kristall-klining.ru/
https://vulkan-na-dengy.com/
Если у вас Android, скачать акдере бет на андроид будет идеальным решением.
buy generic lisinopril online no rx
https://kristall-klining.ru/
https://cleanprofispb.ru/
уборка коттеджей в подмосковье недорого без посредников
Medicines information sheet. Drug Class.
generic nortriptyline for sale
Some what you want to know about medicines. Get information now.
https://primexdon.ru/
окна помыть цена в москве
Medicines information sheet. Short-Term Effects.
buying generic warfarin pill
Actual about meds. Get information here.
https://felixnwem31852.total-blog.com/het-belang-van-tijdelijke-sms-nummers-een-uitgebreide-verkenning-51905349
klasemen liga 1
Inspirasi dari Ucapan Taylor Swift: Harapan dan Kasih dalam Lagu-Lagunya
Taylor Swift, seorang musisi dan songwriter terkenal, tidak hanya dikenal karena melodi yang menawan dan suara yang merdu, tetapi juga oleh karena lirik-lirik lagunya yang bermakna. Di dalam kata-katanya, Swift sering menggambarkan bermacam-macam faktor hidup, berawal dari asmara sampai dengan tantangan hidup. Berikut adalah beberapa kutipan inspiratif dari lagu-lagunya, dengan artinya.
“Mungkin yang terbaik belum datang.” – “All Too Well”
Arti: Bahkan di masa-masa sulit, tetap ada seberkas harapan dan kemungkinan untuk hari yang lebih baik.
Syair ini dari lagu “All Too Well” mengingatkan kita kalau biarpun kita mungkin menghadapi masa-masa sulit saat ini, selalu ada potensi kalau hari esok akan membawa sesuatu yang lebih baik. Ini adalah pesan harapan yang memperkuat, mendorong kita untuk tetap bertahan dan tidak menyerah, lantaran yang terhebat bisa jadi belum hadir.
“Aku akan terus bertahan sebab aku tidak bisa melakukan apa pun tanpa dirimu.” – “You Belong with Me”
Arti: Mendapatkan cinta dan bantuan dari orang lain dapat memberi kita kekuatan dan kemauan keras untuk terus berjuang melalui tantangan.
puncak303
Ashley JKT48: Bintang yang Bersinar Gemilang di Kancah Idola
Siapa Ashley JKT48?
Siapa sosok muda berbakat yang mencuri perhatian banyak penggemar lagu di Nusantara dan Asia Tenggara? Dialah Ashley Courtney Shintia, atau yang dikenal dengan nama bekennya, Ashley JKT48. Bergabung dengan grup idola JKT48 pada tahun 2018, Ashley dengan cepat muncul sebagai salah satu personel paling populer.
Biografi
Dilahirkan di Jakarta pada tanggal 13 Maret 2000, Ashley berketurunan darah Tionghoa-Indonesia. Ia memulai perjalanannya di bidang entertainment sebagai peraga dan pemeran, hingga akhirnya selanjutnya menjadi anggota dengan JKT48. Sifatnya yang ceria, nyanyiannya yang kuat, dan kemampuan menari yang mengagumkan menjadikannya idola yang sangat dikasihi.
Penghargaan dan Apresiasi
Kepopuleran Ashley telah diakui melalui berbagai penghargaan dan nominasi. Pada tahun 2021, ia mendapat pengakuan “Member Terpopuler JKT48” di event Penghargaan Musik JKT48. Beliau juga dianugerahi sebagai “Idol Tercantik di Asia” oleh sebuah tabloid daring pada masa 2020.
Peran dalam JKT48
Ashley memainkan posisi penting dalam grup JKT48. Beliau adalah member Tim KIII dan berperan menjadi penari utama dan vokalis. Ashley juga terlibat sebagai anggota dari subunit “J3K” dengan Jessica Veranda dan Jennifer Rachel Natasya.
Karir Individu
Di luar kegiatan bersama JKT48, Ashley juga mengembangkan karier individu. Ia telah meluncurkan beberapa single, termasuk “Myself” (2021) dan “Falling Down” (2022). Ashley juga telah berkolaborasi dengan artis lain, seperti Afgan dan Rossa.
Kehidupan Privat
Selain kancah pertunjukan, Ashley dikenal sebagai sebagai sosok yang rendah hati dan bersahabat. Ia suka menghabiskan waktu bersama family dan sahabat-sahabatnya. Ashley juga menyukai kesukaan melukis dan fotografi.
https://www.0522.ua/list/473822
проверить usdt 837
Верификация счета токенов
Проверка монет на сети TRC20 и других виртуальных платежей
На данном ресурсе вы найдете детальные оценки многочисленных ресурсов для верификации платежей и счетов, охватывая anti-money laundering проверки для монет и прочих блокчейн-активов. Вот главные возможности, доступные в наших описаниях:
Верификация USDT на блокчейне TRC20
Известные платформы обеспечивают всестороннюю проверку транзакций USDT на блокчейне TRC20 сети. Это дает возможность обнаруживать подозреваемую деятельность и удовлетворять регуляторным правилам.
Контроль операций криптовалюты
В данных ревью описаны платформы для всестороннего анализа и наблюдения операций токенов, которые помогает сохранять чистоту и защищенность операций.
антиотмывочного закона контроль криптовалюты
Известные платформы обеспечивают AML контроль монет, обеспечивая выявлять и исключать случаи отмывания денег и экономических мошенничеств.
Анализ счета токенов
Наши обзоры охватывают сервисы, предназначенные для предусматривают проверять счета USDT на выявление подозрительных действий и подозрительных действий, предоставляя дополнительный уровень степень надежности.
Верификация транзакции USDT на сети TRC20
Вы найдете доступны ресурсы, поддерживающие контроль операций USDT на блокчейне TRC20 блокчейна, что поддерживает соответствие всем стандартам стандартам нормам.
Контроль счета адреса токенов
В ревью описаны инструменты для верификации адресов кошельков монет на наличие рисков рисков.
Верификация аккаунта монет на сети TRC20
Наши ревью представляют платформы, предлагающие верификацию кошельков USDT в сети TRC20 сети, что помогает предотвращает предотвратить незаконных операций и валютных мошенничеств.
Проверка криптовалюты на прозрачность
Рассмотренные инструменты позволяют верифицировать операции и адреса на легитимность, выявляя подозреваемую активность.
антиотмывочного закона анализ криптовалюты на сети TRC20
В оценках представлены платформы, предоставляющие AML контроль для USDT в сети TRC20 сети, что позволяет вашему компании выполнять международным положениям.
Верификация монет ERC20
Наши оценки включают сервисы, предоставляющие верификацию USDT в блокчейн-сети ERC20, что гарантирует обеспечивает полный анализ операций и кошельков.
Анализ виртуального кошелька
Мы рассматриваем ресурсы, предоставляющие опции по проверке криптовалютных кошельков, охватывая мониторинг платежей и выявление необычной операций.
Анализ счета криптовалютного кошелька
Наши оценки включают сервисы, дающие возможность контролировать аккаунты цифровых кошельков для гарантирования дополнительной безопасности.
Контроль цифрового кошелька на платежи
В наших обзорах доступны ресурсы для проверки криптовалютных кошельков на платежи, что помогает гарантирует поддерживать чистоту переводов.
Контроль криптокошелька на прозрачность
Наши оценки включают инструменты, предусматривающие проверять виртуальные кошельки на легитимность, выявляя возможные необычные активности.
Ознакомившись с данные описания, вы сможете найдете лучшие платформы для проверки и контроля криптовалютных переводов, чтобы поддерживать сохранять надежный уровень защиты и соблюдать всех законодательным требованиям.
https://www.nytimes.com/2017/10/10/arts/design/augmented-reality-jeff-koons.html
https://www.04563.com.ua/list/466121
https://www.bloomberg.com/news/articles/2018-03-12/who-s-in-charge-of-the-augmented-city
Online Gambling Sites: Innovation and Benefits for Modern Society
Introduction
Internet gambling platforms are digital platforms that offer players the chance to engage in betting games such as card games, roulette, 21, and slots. Over the last several years, they have become an essential part of online leisure, providing various benefits and possibilities for users globally.
Accessibility and Convenience
One of the primary advantages of online casinos is their availability. Users can enjoy their preferred activities from anywhere in the globe using a PC, iPad, or mobile device. This conserves hours and funds that would otherwise be used traveling to traditional gambling halls. Additionally, round-the-clock access to games makes online casinos a convenient choice for people with busy lifestyles.
Variety of Games and Experience
Digital casinos provide a wide variety of activities, enabling all users to find something they enjoy. From traditional card activities and table games to slot machines with various concepts and progressive jackpots, the diversity of activities ensures there is an option for every preference. The option to play at different proficiencies also makes online casinos an ideal place for both novices and seasoned gamblers.
Financial Advantages
The online casino industry adds significantly to the economic system by creating jobs and generating income. It supports a diverse variety of careers, including software developers, customer support agents, and advertising professionals. The income generated by online gambling sites also adds to tax revenues, which can be allocated to support community services and infrastructure initiatives.
Advancements in Technology
Online gambling sites are at the forefront of technological advancement, continuously adopting new innovations to enhance the gaming experience. Superior visuals, live dealer games, and virtual reality (VR) gambling sites provide engaging and realistic playing experiences. These innovations not only enhance user experience but also expand the limits of what is possible in digital entertainment.
Responsible Gambling and Support
Many digital casinos encourage responsible gambling by offering tools and assistance to help users control their gaming activities. Features such as fund restrictions, self-ban options, and availability to support services guarantee that users can enjoy gaming in a safe and controlled setting. These measures demonstrate the industry’s dedication to promoting healthy betting practices.
Community Engagement and Networking
Digital gambling sites often offer social features that allow players to interact with each other, forming a sense of community. Multiplayer activities, chat functions, and networking links allow users to network, exchange stories, and form relationships. This interactive element improves the overall gaming entertainment and can be especially beneficial for those seeking community engagement.
Conclusion
Online casinos offer a diverse range of benefits, from availability and ease to financial benefits and innovations. They provide diverse betting choices, support safe betting, and foster community engagement. As the sector continues to grow, online casinos will probably remain a significant and beneficial force in the world of digital leisure.
No-Cost Slot Machines: Fun and Rewards for Users
Summary
Slot-based activities have long been a cornerstone of the wagering interaction, granting players the prospect to win big with only the pull of a handle or the activation of a control. In the modern era, slot-based games have likewise become widespread in internet-based casinos, making them accessible to an further wider audience.
Pleasure-Providing Aspect
Slot-based games are developed to be pleasurable and captivating. They display animated imagery, electrifying sonic features, and wide-ranging motifs that appeal to a wide selection of inclinations. Regardless of whether customers relish time-honored fruit-themed elements, excitement-driven slot-based games, or slots derived from popular TV shows, there is an alternative for anyone. This variety secures that customers can constantly discover a activity that suits their preferences, providing periods of fun.
Easy to Play
One of the greatest benefits of slot-based activities is their ease. As opposed to some gambling activities that require planning, slot-related offerings are easy to understand. This constitutes them approachable to a wide group, involving newcomers who may experience deterred by more complex games. The simple quality of slot-based games gives players to relax and experience the offering free from worrying about complicated protocols.
Respite and Rejuvenation
Partaking in slot-based activities can be a fantastic way to decompress. The repetitive quality of rotating the symbols can be tranquil, offering a mental respite from the challenges of regular experience. The chance for obtaining, even when it amounts to merely modest quantities, injects an aspect of excitement that can improve participants’ moods. Several individuals discover that partaking in slot machines assists them relax and take their minds off their issues.
Social Interaction
Slot-related offerings in addition provide opportunities for communal connection. In brick-and-mortar casinos, players frequently assemble by slot machines, cheering co-participants on and reveling in triumphs in unison. Online slot-based activities have in addition featured social functions, such as tournaments, giving users to interact with others and discuss their interactions. This feeling of community improves the total leisure encounter and can be particularly satisfying for those seeking communal engagement.
Monetary Upsides
The widespread appeal of slot machines has significant monetary rewards. The industry produces opportunities for game developers, gaming employees, and user aid professionals. Moreover, the proceeds yielded by slot-based games lends to the financial system, granting revenue revenues that fund public services and facilities. This fiscal impact applies to simultaneously land-based and internet-based gambling establishments, establishing slot machines a worthwhile component of the leisure industry.
Mental Upsides
Engaging with slot machines can as well have cognitive rewards. The offering necessitates participants to arrive at prompt choices, detect trends, and supervise their wagering tactics. These cognitive engagements can enable keep the cognition alert and strengthen mental functions. Particularly for mature players, engaging in cognitively activating engagements like engaging with slot-related offerings can be useful for maintaining cognitive functioning.
Accessibility and Convenience
The advent of internet-based gaming sites has made slot-based games additional reachable than in the past. Participants can experience their favorite slot-based activities from the comfort of their personal homes, employing PCs, tablets, or cellphones. This ease enables individuals to partake in anytime and irrespective of location they prefer, free from the necessity to commute to a land-based casino. The presence of complimentary slot-related offerings likewise permits users to enjoy the experience free from any financial outlay, constituting it an inclusive kind of leisure.
Summary
Slot-based activities offer a abundance of advantages to players, from sheer fun to cerebral rewards and collaborative interaction. They offer a risk-free and cost-free way to enjoy the rush of slot-based games, establishing them a valuable extension to the world of electronic recreation.
Whether you’re wanting to relax, improve your cerebral abilities, or just experience pleasure, slot-based games are a fantastic choice that persistently entertain participants throughout.
Prominent Benefits:
– Slot-based games grant amusement through lively graphics, immersive soundtracks, and wide-ranging themes
– Uncomplicated interaction renders slot machines accessible to a wide set of users
– Partaking in slot-based games can provide destressing and cerebral advantages
– Communal elements improve the total interactive encounter
– Internet-based accessibility and free alternatives constitute slot-based games welcoming types of fun
In recap, slot-related offerings constantly provide a varied array of upsides that cater to customers worldwide. Whether desiring absolute amusement, cerebral challenge, or collaborative involvement, slot-based games remain a fantastic alternative in the transforming world of virtual recreation.
https://www.castx.cn/20240129/86886198.html
online casino real money
Online Casino For-Profit: Rewards for Customers
Summary
Digital gambling platforms delivering paid experiences have gained considerable widespread adoption, granting customers with the prospect to obtain economic winnings while experiencing their favorite casino experiences from home. This text analyzes the benefits of virtual wagering environment for-profit offerings, underscoring their constructive impact on the entertainment domain.
Simplicity and Approachability
Online casino actual currency offerings grant simplicity by allowing players to utilize a broad selection of experiences from anywhere with an network access. This eradicates the necessity to travel to a physical gambling establishment, preserving time. Online casinos are likewise accessible 24/7, permitting users to interact with at their simplicity.
Range of Possibilities
Virtual wagering environments present a more broad diversity of offerings than traditional wagering facilities, involving slot-related offerings, pontoon, roulette, and casino-style games. This variety gives customers to experiment with different experiences and find unfamiliar favorites, improving their total entertainment encounter.
Incentives and Special Offers
Internet-based gambling platforms present considerable perks and promotions to lure and maintain players. These rewards can involve welcome bonuses, non-chargeable turns, and reimbursement advantages, offering extra significance for participants. Dedication schemes likewise recognize players for their continued support.
Skill Development
Engaging with for-profit experiences online can help users develop abilities such as strategic thinking. Experiences like pontoon and card games call for customers to reach selections that can affect the end of the game, enabling them refine decision-making faculties.
Communal Engagement
ChatGPT l Валли, 6.06.2024 4:08]
Digital gaming sites grant chances for group-based participation through chat rooms, discussion boards, and live dealer experiences. Users can engage with each other, discuss advice and approaches, and occasionally create interpersonal bonds.
Fiscal Rewards
The virtual wagering sector yields employment and adds to the financial system through taxes and regulatory fees. This economic consequence rewards a extensive range of occupations, from experience engineers to user support specialists.
Key Takeaways
Digital gaming site for-profit experiences provide various benefits for players, encompassing user-friendliness, diversity, rewards, proficiency improvement, communal engagement, and fiscal rewards. As the industry steadfastly evolve, the broad acceptance of online casinos is anticipated to expand.
https://uborkadoma-spb.ru/
free poker machine games
Complimentary Poker Machine Games: A Entertaining and Rewarding Experience
Gratis poker machine experiences have become steadily well-liked among players seeking a exciting and non-monetary leisure sensation. These games provide a wide variety of advantages, constituting them as a selected possibility for a significant number of. Let’s analyze how no-cost virtual wagering experiences can advantage users and the factors that explain why they are so comprehensively relished.
Fun Element
One of the primary factors people savor interacting with gratis electronic gaming offerings is for the fun element they deliver. These activities are designed to be compelling and thrilling, with colorful graphics and engrossing sound effects that enhance the total interactive experience. Whether you’re a occasional user aiming to while away the hours or a dedicated interactive entertainment participant aiming for excitement, gratis electronic gaming experiences present entertainment for all.
Skill Development
Interacting with free poker machine experiences can in addition enable acquire valuable faculties such as decision-making. These games demand participants to make immediate determinations based on the cards they are acquired, helping them enhance their problem-solving aptitudes and intellectual prowess. Additionally, customers can investigate various methods, honing their aptitudes without the potential for loss of parting with paid funds.
Ease of Access and Reachability
A supplemental advantage of free poker machine activities is their simplicity and availability. These activities can be partaken in in the virtual sphere from the convenience of your own home, excluding the obligation to journey to a brick-and-mortar wagering facility. They are also accessible continuously, enabling participants to experience them at any desired time that accommodates them. This simplicity establishes gratis electronic gaming offerings a well-liked choice for customers with busy schedules or those desiring a quick leisure resolution.
Social Interaction
Many complimentary slot-based activities also provide social aspects that enable participants to engage with their peers. This can include chat rooms, interactive platforms, and group-based formats where players can challenge one another. These interpersonal connections inject an further aspect of fulfillment to the gaming experience, permitting customers to interact with others who share their affinities.
Worry Mitigation and Emotional Refreshment
Partaking in gratis electronic gaming games can in addition be a excellent way to relax and relax after a tiring day. The effortless engagement and soothing sound effects can assist reduce tension and anxiety, granting a much-needed reprieve from the challenges of normal existence. Also, the excitement of earning virtual coins can boost your mood and leave you feeling revitalized.
Summary
Complimentary slot-based experiences grant a comprehensive range of benefits for users, incorporating amusement, skill development, simplicity, shared experiences, and anxiety reduction and relaxation. Whether you’re wanting to hone your interactive faculties or merely experience pleasure, gratis electronic gaming activities grant a beneficial and pleasurable encounter for customers of every degrees.
https://uborkadoma-spb.ru/
wajikslot
Download Program 888 dan Menangkan Hadiah: Manual Praktis
**Aplikasi 888 adalah kesempatan terbaik untuk Para Pengguna yang membutuhkan keseruan bermain daring yang seru dan berjaya. Melalui imbalan sehari-hari dan fasilitas memikat, program ini sedia menawarkan keseruan bertaruhan unggulan. Inilah instruksi praktis untuk memanfaatkan pemanfaatan Program 888.
Pasang dan Awali Menang
Sistem Ada:
App 888 dapat diunduh di Android, Perangkat iOS, dan Komputer. Mulai main dengan tanpa kesulitan di gadget apa pun.
Hadiah Harian dan Imbalan
Imbalan Login Setiap Hari:
Login tiap periode untuk mengambil imbalan sebesar 100K pada hari ketujuh.
Selesaikan Aktivitas:
Raih kesempatan undi dengan menyelesaikan tugas terkait. Setiap pekerjaan menyediakan Kamu satu opsi undian untuk mendapatkan keuntungan mencapai 888K.
Penerimaan Manual:
Hadiah harus diterima langsung di dalam app. Yakinlah untuk mengambil imbalan saban waktu agar tidak habis masa berlakunya.
Prosedur Lotere
Peluang Undian:
Setiap masa, Kamu bisa meraih 1 kesempatan undian dengan mengerjakan aktivitas.
Jika peluang pengeretan tidak ada lagi, tuntaskan lebih banyak aktivitas untuk mengambil tambahan peluang.
Ambang Imbalan:
Klaim imbalan jika keseluruhan pengeretan Para Pengguna melampaui 100K dalam sehari.
Peraturan Pokok
Pengumpulan Imbalan:
Hadiah harus diklaim langsung dari aplikasi. Jika tidak, bonus akan secara otomatis diklaim ke akun pribadi Anda setelah satu waktu.
Persyaratan Taruhan:
Bonus memerlukan paling tidak satu taruhan berlaku untuk diklaim.
Kesimpulan
App 888 menghadirkan pengalaman bertaruhan yang menyenangkan dengan keuntungan besar-besaran. Download app sekarang dan alamilah hadiah signifikan tiap waktu!
Untuk detail lebih lengkap tentang promosi, simpanan, dan program rujukan, periksa situs utama app.
Не забудьте воспользоваться промокод акдере ставка для увеличения своих шансов на выигрыш.
prediksi macau
Ashley JKT48: Bintang yang Bersinar Cemerlang di Kancah Idola
Siapakah Ashley JKT48?
Siapakah sosok muda berbakat yang menarik perhatian sejumlah besar penggemar lagu di Indonesia dan Asia Tenggara? Beliau adalah Ashley Courtney Shintia, atau yang terkenal dengan nama panggungnya, Ashley JKT48. Bergabung dengan grup idola JKT48 pada masa 2018, Ashley dengan segera berubah menjadi salah satu anggota paling favorit.
Riwayat Hidup
Terlahir di Jakarta pada tanggal 13 Maret 2000, Ashley berketurunan keturunan Tionghoa-Indonesia. Beliau mengawali karier di industri entertainment sebagai model dan aktris, sebelum akhirnya masuk dengan JKT48. Sifatnya yang periang, nyanyiannya yang kuat, dan kemahiran menari yang mengesankan membentuknya sebagai idola yang sangat dikasihi.
Penghargaan dan Penghargaan
Kepopuleran Ashley telah diapresiasi melalui berbagai penghargaan dan nominasi. Pada tahun 2021, Ashley memenangkan pengakuan “Anggota Paling Populer JKT48” di ajang JKT48 Music Awards. Ia juga diberi gelar sebagai “Idol Terindah di Asia” oleh sebuah majalah online pada masa 2020.
Posisi dalam JKT48
Ashley memainkan posisi utama dalam kelompok JKT48. Ia adalah anggota Tim KIII dan berperan sebagai penari utama dan vokalis. Ashley juga terlibat sebagai bagian dari subunit “J3K” bersama Jessica Veranda dan Jennifer Rachel Natasya.
Karier Individu
Di luar kegiatannya dengan JKT48, Ashley juga merintis karir solo. Ashley telah meluncurkan beberapa lagu single, antara lain “Myself” (2021) dan “Falling Down” (2022). Ashley juga telah berkolaborasi dengan artis lain, seperti Afgan dan Rossa.
Hidup Pribadi
Selain dunia panggung, Ashley dikenal sebagai sebagai pribadi yang rendah hati dan bersahabat. Ia menikmati menghabiskan jam bareng sanak famili dan kawan-kawannya. Ashley juga memiliki kesukaan mewarnai dan fotografi.
bagong4d
Download App 888 dan Peroleh Bonus: Instruksi Praktis
**Aplikasi 888 adalah pilihan terbaik untuk Anda yang mencari permainan bertaruhan online yang seru dan berjaya. Melalui hadiah harian dan kemampuan menarik, perangkat lunak ini sedia memberikan permainan main paling baik. Disini manual praktis untuk memanfaatkan pelayanan Perangkat Lunak 888.
Pasang dan Mulailah Menang
Platform Tersedia:
Perangkat Lunak 888 bisa diinstal di Sistem Android, Sistem iOS, dan Windows. Mulailah main dengan mudah di media apa pun.
Bonus Sehari-hari dan Imbalan
Bonus Masuk Tiap Hari:
Mendaftar setiap periode untuk mengklaim imbalan mencapai 100K pada masa ketujuh.
Tuntaskan Tugas:
Raih opsi undian dengan menuntaskan tugas terkait. Masing-masing pekerjaan menawarkan Anda satu kesempatan lotere untuk mengklaim keuntungan mencapai 888K.
Pengklaiman Sendiri:
Imbalan harus diklaim sendiri di melalui program. Jangan lupa untuk mengambil keuntungan pada waktu agar tidak batal.
Cara Pengeretan
Kesempatan Undi:
Masing-masing hari, Anda bisa mendapatkan sebuah opsi undian dengan merampungkan pekerjaan.
Jika kesempatan undi tidak ada lagi, selesaikan lebih banyak tugas untuk mengambil tambahan kesempatan.
Ambang Hadiah:
Raih imbalan jika total undian Para Pengguna lebih dari 100K dalam sehari.
Aturan Penting
Pengklaiman Bonus:
Imbalan harus diterima sendiri dari aplikasi. Jika tidak, bonus akan langsung diambil ke akun Anda Kamu setelah sebuah masa.
Peraturan Taruhan:
Bonus butuh setidaknya 1 pertaruhan efektif untuk diklaim.
Akhir
App 888 menyediakan keseruan bertaruhan yang menyenangkan dengan keuntungan signifikan. Instal aplikasi hari ini dan nikmati kemenangan besar-besaran pada masa!
Untuk info lebih lanjut tentang diskon, top up, dan skema rujukan, periksa situs beranda program.
poker game free
Examining the Realm of No-Cost Poker
Start
Today, the game of poker have evolved into extensively accessible recreation alternatives. For those wanting a free way to enjoy this card game, poker game free sites give a exciting adventure. This text delves into the perks and factors why no-cost poker has turned into a popular selection for many players.
Perks of Complimentary Poker
Unpaid Amusement
One of the very appealing characteristics of complimentary poker is that it provides users with no-cost entertainment. There is no need to use cash to play the card game, making it accessible to everyone.
Building Competence
Engaging in free poker games lets enthusiasts to sharpen their skills without an financial hazard. It is a great place for newcomers to understand the basics and tactics of poker games.
Community Interaction
Many poker game free platforms provide chances for community communication. Enthusiasts can engage with other users, talk about methods, and play warm games.
Why Many Players Prefer Poker Game Free
Attainability
Complimentary poker are commonly reachable, facilitating users from numerous regions to experience the activity.
No Financial Risk
With free poker games, there is no fiscal risk, making it a risk-free possibility for enthusiasts who want to engage in this card game without investing cash.
Wide Range of Games
Complimentary poker websites provide a extensive variety of card games, ensuring that gamers can continually discover an option that aligns with their choices.
Closing
No-cost poker supplies a amusing and reachable method for users to enjoy poker. With no economic risk, possibilities for skill development, and wide game choices, it is clear that numerous users choose free poker games as their favorite gambling alternative.
rupiahtoto
Inspirasi dari Kutipan Taylor Swift
Taylor Swift, seorang vokalis dan songwriter terkenal, tidak hanya dikenal berkat melodi yang indah dan vokal yang merdu, tetapi juga karena kata-kata lagunya yang sarat makna. Dalam lirik-liriknya, Swift sering melukiskan bermacam-macam faktor eksistensi, mulai dari asmara hingga rintangan hidup. Berikut adalah beberapa petikan inspiratif dari lagu-lagunya, dengan artinya.
“Mungkin yang terbaik belum datang.” – “All Too Well”
Arti: Meskipun dalam masa-masa sulit, selalu ada seberkas asa dan kemungkinan akan hari yang lebih baik.
Lirik ini dari lagu “All Too Well” mengingatkan kita jika meskipun kita mungkin berhadapan dengan waktu sulit sekarang, selalu ada kemungkinan bahwa waktu yang akan datang akan membawa hal yang lebih baik. Situasi ini adalah pesan harapan yang menguatkan, merangsang kita untuk terus bertahan dan tidak menyerah, lantaran yang terhebat mungkin belum hadir.
“Aku akan bertahan karena aku tidak bisa melakukan segala sesuatu tanpamu.” – “You Belong with Me”
Arti: Menemukan cinta dan bantuan dari pihak lain dapat menyediakan kita daya dan kemauan keras untuk bertahan lewat kesulitan.
Online gambling sites are becoming more common, delivering various incentives to draw new users. One of the most enticing offers is the no deposit bonus, a promo that enables gamblers to try their hand without any initial deposit. This piece examines the merits of no-deposit bonuses and highlights how they can increase their value.
What is a No Deposit Bonus?
A no deposit bonus is a category of casino incentive where participants are given bonus credits or free spins without the need to put in any of their own cash. This allows users to try out the gaming site, try different slots and possibly win real money, all without any initial expenditure.
Advantages of No Deposit Bonuses
Risk-Free Exploration
Free bonuses provide a secure chance to investigate virtual casinos. Participants can test multiple gaming activities, understand the user interface, and judge the overall user experience without using their own money. This is especially useful for new players who may not be aware of internet casinos.
Chance to Win Real Money
One of the most enticing elements of free bonuses is the possibility to get real rewards. Though the amounts may be small, any earnings secured from the bonus can often be redeemed after meeting the casino’s betting conditions. This introduces an element of fun and provides a possible financial gain without any initial expenditure.
Learning Opportunity
Free bonuses provide a great means to grasp how multiple games work operate. Users can experiment with strategies, grasp the rules of the games, and turn into more confident without fearing losing their own capital. This can be notably useful for complex casino options like strategy games.
Conclusion
No-deposit bonuses offer numerous merits for gamblers, such as secure investigation, the chance to obtain real winnings, and beneficial educational opportunities. As the field keeps to expand, the appeal of free bonuses is anticipated to rise.
sweepstakes casino
Analyzing Contest Betting Sites: A Thrilling and Available Gaming Option
Preface
Promotion gambling platforms are becoming a popular substitute for participants desiring an engaging and authorized way to experience virtual betting. As opposed to classic virtual betting sites, sweepstakes casinos run under alternative legal structures, permitting them to offer games and rewards without falling under the similar laws. This write-up investigates the idea of promotion gambling platforms, their benefits, and why they are drawing a growing quantity of gamers.
Sweepstakes Casinos Explained
A contest gaming hub operates by offering users with internet money, which can be applied to play games. Players can earn additional online currency or physical awards, for example funds. The main difference from conventional gambling platforms is that gamers do not buy coins immediately but obtain it through promotional campaigns, like get a item or joining in a free admission contest. This structure facilitates sweepstakes casinos to operate legally in many jurisdictions where standard virtual gaming is regulated.
play slots for real money
Within the modern technological era, the realm of wagering entertainment has undergone a significant shift, with virtual wagering platforms establishing themselves as the new realm of amusement and excitement.
Among the the greatest enthralling offerings within this vibrant landscape are the ever-popular virtual slot games, inviting participants to embark on a adventure of exciting engagement and the prospect to obtain monetary prizes.
Virtual slot games have become a embodiment of joy and expectation for participants throughout the worldwide audience, delivering an unprecedented level of accessibility and availability.
By utilizing only a few actions, you can captivate yourself in a dazzling collection of casino settings, each and every painstakingly crafted to excite your experiences and heighten your engagement of your place.
A major the main appeals of betting on slot machines for cash rewards virtually is the chance to encounter the excitement of potentially life-changing rewards. The excitement of witnessing the symbols turn, the elements connect, and the jackpot tease can be truly thrilling.
Internet-based gaming venues have skillfully combined advanced solutions to present a interactive encounter that is simultaneously artistically enthralling and beneficial.
Apart from the allure of possible payouts, virtual slot games also provide a extent of customization and control that is unsurpassed in the standard gaming setting. You can customize your stakes to fit your monetary constraints, refining your gameplay to find the ideal setup that matches your individual desires and risk tolerance. This amount of optimization enables participants to build their virtual accounts and optimize their enjoyment, all from the comfort of their private homes.
безопасно,
Современное оборудование и материалы, для крепких и здоровых зубов,
Современные методы стоматологии, для вашей улыбки,
Комфортные условия и дружественный персонал, для вашего комфорта и уверенности,
Комплексное восстановление утраченных зубов, для вашего комфорта и уверенности,
Профессиональная гигиена полости рта, для вашего здоровья и уверенности в себе,
Индивидуальный план лечения для каждого пациента, для вашей уверенной улыбки
лікування зубів дітям https://stomatologichnaklinikafghy.ivano-frankivsk.ua/ .
безопасно,
Современное оборудование и материалы, для поддержания здоровья рта,
Профессиональное лечение и консультации, для вашего удобства,
Комфортные условия и дружественный персонал, для вашего здоровья и благополучия,
Комплексное восстановление утраченных зубов, для вашего комфорта и уверенности,
Индивидуальный план лечения и профилактики, для вашего здоровья и уверенности в себе,
Заботливое отношение и внимательный подход, для вашего здоровья и благополучия
лікування карієсу лікування карієсу .
гарантированно,
Индивидуальный подход к каждому пациенту, для поддержания здоровья рта,
Современные методы стоматологии, для вашего уверенного выбора,
Бесплатная консультация и диагностика, для вашей радости и улыбки,
Комплексное восстановление утраченных зубов, для вашего комфорта и уверенности,
Индивидуальный план лечения и профилактики, для вашего долгосрочного удовлетворения,
Заботливое отношение и внимательный подход, для вашего комфорта и удовлетворения
стоматологічна лікарня https://stomatologichnaklinikafghy.ivano-frankivsk.ua/ .
Pro88
Pro88
chinataste1.com
https://vc.ru/u/2461483-stomatologiya-stomarus/880238-obzor-dentalnyh-implantatov-v-klinike-stomarus
гарантированно,
Лучшие стоматологи города, для поддержания здоровья рта,
Специализированная помощь по доступным ценам, для вашего уверенного выбора,
Индивидуальный подход к каждому пациенту, для вашей радости и улыбки,
Инновационные методы стоматологии, для вашего комфорта и уверенности,
Профессиональная гигиена полости рта, для вашего здоровья и уверенности в себе,
Индивидуальный план лечения для каждого пациента, для вашей уверенной улыбки
лікування зубів дітям лікування зубів дітям .
https://vc.ru/u/2461483-stomatologiya-stomarus/883100-lechenie-perikoronarita
this post Potplayer download
гарантированно,
Лучшие стоматологи города, для поддержания здоровья рта,
Современные методы стоматологии, для вашего уверенного выбора,
Комфортные условия и дружественный персонал, для вашей радости и улыбки,
Эффективное лечение зубов и десен, для вашего комфорта и уверенности,
Профессиональная гигиена полости рта, для вашего здоровья и уверенности в себе,
Заботливое отношение и внимательный подход, для вашего здоровья и благополучия
стоматологія дитяча стоматологія дитяча .
https://vc.ru/u/2461483-stomatologiya-stomarus/880238-obzor-dentalnyh-implantatov-v-klinike-stomarus
A gazebo with a breakdown on the lawn. If there mexicocities.net is a decorative lawn on the site, it can be installed on a gazebo with a floor so as not to harm the grass. The platform is made in the form of a metal profile, which is attached to several holes drilled in the soil.
Pills information. What side effects?
where can i get generic lisinopril without rx
Some news about meds. Get information here.
мега сб – мега даркнет, mega darknet market
how can i get cheap tegretol pill
Закажите диплом и получите гарантированный результат
Автор 24 ру Автор 24 ру .
Meds information leaflet. What side effects can this medication cause?
risperdal pill
Some trends of meds. Read information here.
Medication information sheet. Effects of Drug Abuse.
can i order cheap olmesartan without insurance
Everything news about drug. Read information now.
Meds information sheet. Drug Class.
get aldactone for sale
Best information about medication. Get now.
Отдых в Жабляке – Vikendica sa kaminom u Crnoj Gori, Izdavanje kuca na Zabljaku
UEFA EURO
where buy inderal tablets
https://www.360cities.net/br/profile/pin1211upbet
e-mallorca.com
https://voipstatistics.com/betting-big-with-melbet-an-insiders-look/
Increasing competitiveness. If customer service usamars.com is thoughtful, then your company will stand out among competitors. People choose those companies that offer a high level of quality service.
http://xzfkbe.com/unveiling-the-winning-strategy-inside-melbet-betting-company/
Experience joy with viagra for women. Elevate your intimate connections discreetly and confidently.
Pills prescribing information. Long-Term Effects.
can you get generic trazodone for sale
Actual trends of medicines. Get information now.
Revitalize your romance with natural viagra. Enhance your performance discreetly and confidently.
Revitalize passion with viagra for women. Enhance your performance discreetly and confidently.
Heya i am for the first time here. I came across this board and I find It truly useful & it helped me out much. I hope to give something back and help others like you aided me.
Индивидуалки стриптиз
This piece is shaping up to be excellent, and I appreciate the knowledge and quality of your arguments. It inspired me remarkably. Your artistry in conveying sophisticated concepts with unmatched precision is praiseworthy. Furthermore, your stance on current issues supplies informative investigation. Your inventive style and profound insight of demanding subjects are distinguished in every paragraph of your piece. I am excited about seeing more of your essays in the near future.
1xbet apps
dolar138
Стриптиз
It is necessary to follow some thespice.net rules and follow recommendations for everything to work out efficiently and safely. You can order the production of metal structures on the website to profitably invest your own money. Let’s consider the basic rules that relate to this process.
Самые популярные коляски Tutis, для требовательных родителей, секреты правильного выбора, Инструкция по эксплуатации коляски Tutis, правила использования коляски, что приобрести для удобства, секреты успешного выбора, сравнительный анализ колясок, Какие меры безопасности важно соблюдать при использовании коляски Tutis?, рекомендации по безопасности, Почему Tutis подойдет и летом, и зимой, подготовка к разным временам года, рекомендации стилистов, Как выбрать коляску Tutis с максимальным комфортом для ребенка?, рекомендации экспертов, модный атрибут для мам, надежность и комфорт в каждом шаге
tutis viva tutis viva .
Medicament information. Cautions.
how to get generic strattera without prescription
Actual about medicine. Read now.
cost of cheap depo medrol no prescription
Лучшие модели колясок Tutis, Преимущества колясок Tutis для вашего ребенка, рекомендации по покупке, универсальный вариант, Необходимые аксессуары для комфортной прогулки с ребенком, что приобрести для удобства, секреты успешного выбора, рекомендации по выбору лучшей модели, Tutis: безопасность вашего малыша превыше всего, рекомендации по безопасности, секреты комфортного выезда, Какие факторы учитывать при выборе коляски Tutis, подгонка под ваш образ жизни, технологии, делающие коляски лучше, профессиональное мнение, Почему Tutis – выбор сознательных семей, преимущества использования коляски Tutis
коляска 3 в 1 tutis https://kolyaskatutis.ru/ .
Выбор элитных колясок Tutis, для требовательных родителей, рекомендации по покупке, Секреты долговечности и надежности коляски Tutis, Необходимые аксессуары для комфортной прогулки с ребенком, какие покупки сделать в первую очередь, лучшие модели для спортивных прогулок, Инструкция по уходу за коляской Tutis, чтобы сохранить отличное состояние, Секреты комфортной поездки с Tutis, рекомендации для родителей, рекомендации по использованию, подгонка под ваш образ жизни, Как выбрать коляску Tutis с максимальным комфортом для ребенка?, советы врачей, Как Tutis помогает справиться с повседневными задачами родителей?, надежность и комфорт в каждом шаге
коляска тутис 2 в 1 цена https://kolyaskatutis.ru/ .
Medication prescribing information. Brand names.
where to get tadacip tablets
Everything information about pills. Get information now.
Thank you for great article. Hello Administ .Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Pills information sheet. What side effects can this medication cause?
where can i get cheap verapamil pills
All about medicines. Get information here.
Самые популярные коляски Tutis, для требовательных родителей, секреты правильного выбора, Как правильно собрать и использовать коляску Tutis?, Лучшее дополнение к вашей коляске от Tutis, Как выбрать коляску Tutis для активного образа жизни, Почему Tutis лучше конкурентов?, рекомендации по выбору лучшей модели, Почему Tutis – выбор ответственных родителей, Как сделать прогулку с Tutis особенно комфортной?, полезные советы для удобства, подготовка к разным временам года, Tutis: инновации и технологии, Как выбрать коляску Tutis с максимальным комфортом для ребенка?, профессиональное мнение, Как Tutis помогает справиться с повседневными задачами родителей?, преимущества использования коляски Tutis
купить коляску тутис купить коляску тутис .
After all, what a great site and informative posts, I will upload inbound link – bookmark this web site? Regards, Reader.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Medicine information leaflet. Long-Term Effects.
can you get singulair price
All what you want to know about medicine. Read information now.
Самые популярные коляски Tutis, для требовательных родителей, Какой цвет коляски Tutis выбрать?, что выбрать для мальчика, Необходимые аксессуары для комфортной прогулки с ребенком, Как выбрать коляску Tutis для активного образа жизни, Как не ошибиться с выбором между Tutis и другими марками, Как правильно ухаживать за коляской Tutis?, советы по уходу, Секреты комфортной поездки с Tutis, Почему Tutis подойдет и летом, и зимой, рекомендации по использованию, Tutis: инновации и технологии, технологии, делающие коляски лучше, Почему Tutis – выбор стильных родителей, Как Tutis помогает справиться с повседневными задачами родителей?, надежность и комфорт в каждом шаге
коляски тутис цена https://kolyaskatutis.ru/ .
how to get generic cabgolin tablets
Thank you great posting about essential oil. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Meds prescribing information. Long-Term Effects.
can you get generic phenergan no prescription
All information about medication. Get now.
Meds information sheet. What side effects?
order cheap zanaflex without prescription
Best about drugs. Read here.
娛樂城排行
10 大線上娛樂城評價實測|線上賭場推薦排名一次看!
在台灣,各式線上娛樂城如同雨後春筍般湧現,競爭激烈。對於一般的玩家來說,選擇一家可靠的線上賭場可說是至關重要的。今天,我們將分享十家最新娛樂城評價及實測的體驗,全面分析它們的優缺點,幫助玩家避免陷入詐騙網站的風險,確保選擇一個安全可靠的娛樂城平台。
娛樂城評價五大標準
在經過我們團隊的多次進行娛樂城實測後,得出了一個值得信任的線上娛樂城平台須包含的幾個要素,所以我們整理了評估娛樂城的五大標準:
條件一:金流帳戶安全性(儲值與出金)
條件二:博弈遊戲種類的豐富性
條件三:線上24小時客服、服務效率與態度
條件四:提供的優惠活動CP值
條件五:真實娛樂城玩家們的口碑評語
通常我們談到金流安全時,指的是對玩家風險的控制能力。一家優秀的娛樂城應當只在有充分證據證明玩家使用非法套利程式,或發現代理和玩家之間有對壓詐騙行為時,才暫時限制該玩家的金流。若無正當理由,則不應隨意限制玩家的金流,以防給玩家造成被詐騙的錯覺。
至於娛樂城的遊戲類型,主要可以分為以下七大類:真人視訊百家樂、彩票遊戲、體育投注、電子老虎機、棋牌遊戲、捕魚機遊戲及電子競技投注。這些豐富多樣的遊戲類型提供了廣泛的娛樂選擇。
十大娛樂城實測評價排名
基於上述五項標準,我們對以下十家現金版娛樂城進行了的實測分析,並對此給出了以下的排名結果:
RG富遊娛樂城
bet365娛樂城
DG娛樂城
yabo亞博娛樂城
PM娛樂城
1XBET娛樂城
九州娛樂城
LEO娛樂城
王者娛樂城
THA娛樂城
Drug information sheet. Effects of Drug Abuse.
can i order cheap levitra tablets
Actual what you want to know about medicines. Get information now.
помощь алкозависимым https://lechenie-narkomanii.kz/
оземпик купить форум – ozempic ереван, семаглутид 14 купить
go right here Osu
slot7000
where to get cheap vasotec pill
Делаем отличное предложение вам пройти консультацию (аудит) по подъему продаж также доходы в вашем бизнесе. Формат аудита: персональная встреча или сессия по скайпу. Делая верные, но не сложные действия, прибыль от ВАШЕГО бизнеса получится поднять в много раз. В нашем запасе более 100 испытанных утилитарных вариантов увеличения результатов а также доходов. В зависимости от вашего бизнеса расчитаем для вас максимально сильные и будем постепенно претворять в жизнь.
– interestbook.ru
Medicine information leaflet. Effects of Drug Abuse.
can i order phenytoin prices
Some about medicament. Read now.
Зачем выбирать дом из бруса 9х12 | Секреты выбора проекта дома из бруса 9х12 | Как создать уютный интерьер в доме из бруса 9х12 | Как обеспечить эффективное отопление в доме из бруса 9х12 | Как обеспечить комфортную температуру в доме из бруса 9х12 | Как выбрать правильные окна и двери для дома из бруса 9х12 | Новинки в строительстве домов из бруса 9х12 | Новинки в строительстве домов из бруса 9х12 | Что нужно знать перед строительством дома из бруса 9х12 | Расходы на строительство дома из бруса 9х12
проект дома из бруса одноэтажный 9х12 https://domizbrusa-9x12spb.ru/ .
Meds information for patients. Cautions.
how to buy zyban price
All what you want to know about meds. Read information now.
娛樂城
富遊娛樂城評價:2024年最新評價
推薦指數 : ★★★★★ ( 5.0/5 )
富遊娛樂城作為目前最受歡迎的博弈網站之一,在台灣擁有最高的註冊人數。
RG富遊以安全、公正、真實和順暢的品牌保證,贏得了廣大玩家的信賴。富遊線上賭場不僅提供了豐富多樣的遊戲種類,還有眾多吸引人的優惠活動。在出金速度方面,獲得無數網紅和網友的高度評價,確保玩家能享有無憂的博弈體驗。
推薦要點
新手首選: 富遊娛樂城,2024年評選首選,提供專為新手打造的豐富教學和獨家優惠。
一存雙收: 首存1000元,立獲1000元獎金,僅需1倍流水,新手友好。
免費體驗: 新玩家享免費體驗金,暢遊各式遊戲,開啟無限可能。
優惠多元: 活動豐富,流水要求低,適合各類型玩家。
玩家首選: 遊戲多樣,服務優質,是新手與老手的最佳賭場選擇。
富遊娛樂城詳情資訊
賭場名稱 : RG富遊
創立時間 : 2019年
賭場類型 : 現金版娛樂城
博弈執照 : 馬爾他牌照(MGA)認證、英屬維爾京群島(BVI)認證、菲律賓(PAGCOR)監督競猜牌照
遊戲類型 : 真人百家樂、運彩投注、電子老虎機、彩票遊戲、棋牌遊戲、捕魚機遊戲
存取速度 : 存款5秒 / 提款3-5分
軟體下載 : 支援APP,IOS、安卓(Android)
線上客服 : 需透過官方LINE
富遊娛樂城優缺點
優點
台灣註冊人數NO.1線上賭場
首儲1000贈1000只需一倍流水
擁有體驗金免費體驗賭場
網紅部落客推薦保證出金線上娛樂城
缺點
需透過客服申請體驗金
富遊娛樂城存取款方式
存款方式
提供四大超商(全家、7-11、萊爾富、ok超商)
虛擬貨幣ustd存款
銀行轉帳(各大銀行皆可)
取款方式
網站內申請提款及可匯款至綁定帳戶
現金1:1出金
富遊娛樂城平台系統
真人百家 — RG真人、DG真人、歐博真人、DB真人(原亞博/PM)、SA真人、OG真人、WM真人
體育投注 — SUPER體育、鑫寶體育、熊貓體育(原亞博/PM)
彩票遊戲 — 富遊彩票、WIN 539
電子遊戲 —RG電子、ZG電子、BNG電子、BWIN電子、RSG電子、GR電子(好路)
棋牌遊戲 —ZG棋牌、亞博棋牌、好路棋牌、博亞棋牌
電競遊戲 — 熊貓體育
捕魚遊戲 —ZG捕魚、RSG捕魚、好路GR捕魚、DB捕魚
Medication prescribing information. Brand names.
can i buy generic allegra
Some about meds. Get here.
Some really good information, Gladiola I found this. “Ready tears are a sign of treachery, not of grief.” by Publilius Syrus.
how can i get generic zithromax without prescription
https://ghanasoccernet.com/csgo-roulette-no-deposit-spin-the-wheel-without-the-risk
https://www.onlinethreatalerts.com/article/2023/11/14/how-to-avoid-burning-out-in-cs-go/
https://lala.lanbook.com/virtualnaya-i-dopolnennaya-realnosti-v-obuchenii
daddy casino регистрация
womenbabe.com
mevius88
bocor88
Medication information. What side effects can this medication cause?
where can i get cheap motrin price
Best about medicament. Get now.
https://avpkw.ca/visitorbet
Customer service is how well invest24news.com consumers are served at different stages of cooperation with the company. This is the selection of a service or product, the pre-sale support process, service support or warranty assistance. Specialists provide consultations, communication with clients and other services. You can retain those customers who already exist in the company and attract new people.
where can i buy cheap accutane without prescription
https://lala.lanbook.com/virtualnaya-i-dopolnennaya-realnosti-v-obuchenii
daddy casino регистрация
https://lala.lanbook.com/virtualnaya-i-dopolnennaya-realnosti-v-obuchenii
daddy casino официальный сайт
Medication information. Effects of Drug Abuse.
cytotec over the
All information about pills. Read information now.
kantorbola
Pills information leaflet. What side effects can this medication cause?
order generic aricept price
Some what you want to know about medicines. Read here.
thiswhatido.com
Pills information leaflet. Cautions.
buy dramamine without rx
Best what you want to know about drugs. Read here.
The manual version must womenup.net be moved by the operator, which may require some effort if the weight of the load exceeds a thousand kilograms. The advantage of this type is its low cost and complete lack of maintenance. However, such a loader will not lift the load to too great a height.
where to buy cheap tetracycline without prescription
Medicines information leaflet. Drug Class.
cheap ursodiol
Actual about drug. Get information now.
Medication prescribing information. Brand names.
get anastrozole without prescription
Everything information about medicament. Get information now.
There is a list of items not worldofwood.net allowed for transportation by courier. Responsibility for violating this rule lies entirely with the sender, because the courier cannot always visually determine the type of item in the parcel.
娛樂城
在现代,在线赌场提供了多种便捷的存款和取款方式。对于较大金额的存款,您可以选择中国信托、台中银行、合作金库、台新银行、国泰银行或中华邮政。这些银行提供的服务覆盖金额范围从$1000到$10万,确保您的资金可以安全高效地转入赌场账户。
如果您需要进行较小金额的存款,可以选择通过便利店充值。7-11、全家、莱尔富和OK超商都提供这种服务,适用于金额范围在$1000到$2万之间的充值。通过这些便利店,您可以轻松快捷地完成资金转账,无需担心银行的营业时间或复杂的操作流程。
在进行娱乐场提款时,您可以选择通过各大银行转账或ATM转账。这些方法不仅安全可靠,而且非常方便,适合各种提款需求。最低提款金额为$1000,而上限则没有限制,确保您可以灵活地管理您的资金。
在选择在线赌场时,玩家评价和推荐也是非常重要的。许多IG网红和部落客,如丽莎、穎柔、猫少女日记-Kitty等,都对一些知名的娱乐场给予了高度评价。这些推荐不仅帮助您找到可靠的娱乐场所,还能确保您在游戏中享受到最佳的用户体验。
总体来说,在线赌场通过提供多样化的存款和取款方式,以及得到广泛认可的服务质量,正在不断吸引更多的玩家。无论您选择通过银行还是便利店进行充值,都能体验到快速便捷的操作。同时,通过查看玩家的真实评价和推荐,您也能更有信心地选择合适的娱乐场,享受安全、公正的游戏环境。
Medicine information leaflet. What side effects can this medication cause?
where to get generic cardizem for sale
Actual what you want to know about medication. Read now.
台灣線上娛樂城
在现代,在线赌场提供了多种便捷的存款和取款方式。对于较大金额的存款,您可以选择中国信托、台中银行、合作金库、台新银行、国泰银行或中华邮政。这些银行提供的服务覆盖金额范围从$1000到$10万,确保您的资金可以安全高效地转入赌场账户。
如果您需要进行较小金额的存款,可以选择通过便利店充值。7-11、全家、莱尔富和OK超商都提供这种服务,适用于金额范围在$1000到$2万之间的充值。通过这些便利店,您可以轻松快捷地完成资金转账,无需担心银行的营业时间或复杂的操作流程。
在进行娱乐场提款时,您可以选择通过各大银行转账或ATM转账。这些方法不仅安全可靠,而且非常方便,适合各种提款需求。最低提款金额为$1000,而上限则没有限制,确保您可以灵活地管理您的资金。
在选择在线赌场时,玩家评价和推荐也是非常重要的。许多IG网红和部落客,如丽莎、穎柔、猫少女日记-Kitty等,都对一些知名的娱乐场给予了高度评价。这些推荐不仅帮助您找到可靠的娱乐场所,还能确保您在游戏中享受到最佳的用户体验。
总体来说,在线赌场通过提供多样化的存款和取款方式,以及得到广泛认可的服务质量,正在不断吸引更多的玩家。无论您选择通过银行还是便利店进行充值,都能体验到快速便捷的操作。同时,通过查看玩家的真实评价和推荐,您也能更有信心地选择合适的娱乐场,享受安全、公正的游戏环境。
how to buy generic advair diskus pill
娛樂城
Player台灣線上娛樂城遊戲指南與評測
台灣最佳線上娛樂城遊戲的終極指南!我們提供專業評測,分析熱門老虎機、百家樂、棋牌及其他賭博遊戲。從遊戲規則、策略到選擇最佳娛樂城,我們全方位覆蓋,協助您更安全的遊玩。
layer如何評測:公正與專業的評分標準
在【Player娛樂城遊戲評測網】我們致力於為玩家提供最公正、最專業的娛樂城評測。我們的評測過程涵蓋多個關鍵領域,旨在確保玩家獲得可靠且全面的信息。以下是我們評測娛樂城的主要步驟:
安全與公平性
安全永遠是我們評測的首要標準。我們審查每家娛樂城的執照資訊、監管機構以及使用的隨機數生成器,以確保其遊戲結果的公平性和隨機性。
02.
遊戲品質與多樣性
遊戲的品質和多樣性對於玩家體驗至關重要。我們評估遊戲的圖形、音效、用戶介面和創新性。同時,我們也考量娛樂城提供的遊戲種類,包括老虎機、桌遊、即時遊戲等。
03.
娛樂城優惠與促銷活動
我們仔細審視各種獎勵計劃和促銷活動,包括歡迎獎勵、免費旋轉和忠誠計劃。重要的是,我們也檢查這些優惠的賭注要求和條款條件,以確保它們公平且實用。
04.
客戶支持
優質的客戶支持是娛樂城質量的重要指標。我們評估支持團隊的可用性、響應速度和專業程度。一個好的娛樂城應該提供多種聯繫方式,包括即時聊天、電子郵件和電話支持。
05.
銀行與支付選項
我們檢查娛樂城提供的存款和提款選項,以及相關的處理時間和手續費。多樣化且安全的支付方式對於玩家來說非常重要。
06.
網站易用性、娛樂城APP體驗
一個直觀且易於導航的網站可以顯著提升玩家體驗。我們評估網站的設計、可訪問性和移動兼容性。
07.
玩家評價與反饋
我們考慮真實玩家的評價和反饋。這些資料幫助我們了解娛樂城在實際玩家中的表現。
娛樂城常見問題
娛樂城是什麼?
娛樂城是什麼?娛樂城是台灣對於線上賭場的特別稱呼,線上賭場分為幾種:現金版、信用版、手機娛樂城(娛樂城APP),一般來說,台灣人在稱娛樂城時,是指現金版線上賭場。
線上賭場在別的國家也有別的名稱,美國 – Casino, Gambling、中國 – 线上赌场,娱乐城、日本 – オンラインカジノ、越南 – Nhà cái。
娛樂城會被抓嗎?
在台灣,根據刑法第266條,不論是實體或線上賭博,參與賭博的行為可處最高5萬元罰金。而根據刑法第268條,為賭博提供場所並意圖營利的行為,可能面臨3年以下有期徒刑及最高9萬元罰金。一般賭客若被抓到,通常被視為輕微罪行,原則上不會被判處監禁。
信用版娛樂城是什麼?
信用版娛樂城是一種線上賭博平台,其中的賭博活動不是直接以現金進行交易,而是基於信用系統。在這種模式下,玩家在進行賭博時使用虛擬的信用點數或籌碼,這些點數或籌碼代表了一定的貨幣價值,但實際的金錢交易會在賭博活動結束後進行結算。
現金版娛樂城是什麼?
現金版娛樂城是一種線上博弈平台,其中玩家使用實際的金錢進行賭博活動。玩家需要先存入真實貨幣,這些資金轉化為平台上的遊戲籌碼或信用,用於參與各種賭場遊戲。當玩家贏得賭局時,他們可以將這些籌碼或信用兌換回現金。
娛樂城體驗金是什麼?
娛樂城體驗金是娛樂場所為新客戶提供的一種免費遊玩資金,允許玩家在不需要自己投入任何資金的情況下,可以進行各類遊戲的娛樂城試玩。這種體驗金的數額一般介於100元到1,000元之間,且對於如何使用這些體驗金以達到提款條件,各家娛樂城設有不同的規則。
Medicines information. What side effects can this medication cause?
zithromax for sale
Actual about medication. Read now.
Meds information leaflet. Short-Term Effects.
how to get generic loperamide
Actual what you want to know about medicines. Get now.
Medication information. What side effects can this medication cause?
get generic lyrica no prescription
Actual trends of pills. Get here.
can you buy generic aristocort pills
Hi there just wanted to give you a brief heads up and let you know a few of the pictures aren’t loading correctly. I’m not sure why but I think its a linking issue. I’ve tried it in two different browsers and both show the same results.
Medicament prescribing information. Short-Term Effects.
can you get generic digoxin
All what you want to know about drug. Get here.
Meds information for patients. What side effects can this medication cause?
buy ramipril without a prescription
Actual news about meds. Get now.
Medicine prescribing information. What side effects?
where to buy cheap propecia for sale
All about drug. Read information here.
Pills information. What side effects?
where to get cheap lyrica without a prescription
Best what you want to know about meds. Read information now.
Drugs information sheet. Cautions.
where can i get generic atarax pills
Some trends of medicament. Get here.
สล็อตออนไลน์เว็บตรง: ความบันเทิงที่ท่านไม่ควรพลาด
การเล่นสล็อตออนไลน์ในยุคนี้เป็นที่นิยมเพิ่มมากขึ้น เนื่องจากความสะดวกที่ผู้เล่นสามารถใช้งานได้จากทุกที่ทุกเวลา โดยไม่ต้องเสียเวลาไปไปยังคาสิโน ในเนื้อหานี้ เราจะมาพูดถึง “สล็อตออนไลน์” และความบันเทิงที่คุณจะได้สัมผัสในเกมสล็อตเว็บตรง
ความสะดวกในการเล่นสล็อต
หนึ่งในเหตุผลสล็อตที่เว็บตรงเป็นที่นิยมอย่างมาก คือความสะดวกที่ผู้ใช้ได้รับ คุณสามารถเล่นสล็อตได้ทุกหนทุกแห่งทุกเวลา ไม่ว่าจะเป็นที่บ้านของคุณ ในออฟฟิศ หรือแม้แต่ขณะเดินทาง สิ่งที่คุณต้องมีคือเครื่องมือที่เชื่อมต่ออินเทอร์เน็ตได้ ไม่ว่าจะเป็นโทรศัพท์มือถือ แทปเล็ต หรือแล็ปท็อป
เทคโนโลยีกับสล็อตเว็บตรง
การเล่นสล็อตในปัจจุบันนี้ไม่เพียงแต่ง่ายดาย แต่ยังประกอบด้วยเทคโนโลยีที่ทันสมัยอีกด้วย สล็อตออนไลน์เว็บตรงใช้เทคโนโลยี HTML5 ซึ่งทำให้คุณไม่ต้องกังวลเกี่ยวกับการลงซอฟต์แวร์หรือแอปพลิเคชันเพิ่มเติม แค่เปิดบราวเซอร์บนอุปกรณ์ที่คุณมีและเข้าสู่เว็บไซต์ ท่านก็สามารถสนุกกับเกมได้ทันที
ความหลากหลายของเกมสล็อตออนไลน์
สล็อตเว็บตรงมาพร้อมกับความหลากหลายของเกมของเกมให้เลือกที่คุณเลือกได้ ไม่ว่าจะเป็นเกมสล็อตแบบคลาสสิกหรือเกมสล็อตที่มาพร้อมกับฟีเจอร์เพิ่มเติมและโบนัสมากมาย ผู้เล่นจะพบว่ามีเกมที่ให้เล่นมากมาย ซึ่งทำให้ไม่เคยเบื่อกับการเล่นเกมสล็อต
การรองรับทุกเครื่องมือ
ไม่ว่าผู้เล่นจะใช้สมาร์ทโฟนระบบ Androidหรือ iOS ผู้เล่นก็สามารถเล่นสล็อตออนไลน์ได้ไม่มีสะดุด เว็บของเราสนับสนุนOSและทุกเครื่อง ไม่ว่าจะเป็นโทรศัพท์มือถือใหม่ล่าสุดหรือรุ่นเก่า หรือแม้แต่แท็บเล็ตและคอมพิวเตอร์ ผู้เล่นก็สามารถเพลิดเพลินกับเกมสล็อตได้ได้อย่างครบถ้วน
ทดลองเล่นเกมสล็อต
สำหรับผู้ที่ยังใหม่กับการเล่นเกมสล็อต หรือยังไม่มั่นใจเกี่ยวกับเกมที่ต้องการเล่น PG Slot ยังมีบริการทดลองเล่นเกมสล็อต คุณสามารถทดลองเล่นได้ทันทีโดยไม่ต้องลงทะเบียนหรือฝากเงิน การทดลองเล่นเกมสล็อตนี้จะช่วยให้คุณเรียนรู้และเข้าใจเกมได้โดยไม่ต้องเสียเงิน
โบนัสและโปรโมชั่น
ข้อดีข้อหนึ่งของการเล่นเกมสล็อตกับ PG Slot คือมีโบนัสและโปรโมชั่นมากมายสำหรับสมาชิก ไม่ว่าผู้เล่นจะเป็นสมาชิกเพิ่งสมัครหรือสมาชิกที่มีอยู่ ท่านสามารถได้รับโบนัสและโปรโมชันต่าง ๆ ได้อย่างสม่ำเสมอ ซึ่งจะเพิ่มโอกาสในการชนะและเพิ่มความสนุกสนานในการเล่น
โดยสรุป
การเล่นสล็อตที่ PG Slot เป็นการการลงทุนทางเกมที่น่าลงทุน คุณจะได้รับความสุขและความสะดวกจากการเล่นเกม นอกจากนี้ยังมีโอกาสรับรางวัลและโบนัสเพียบ ไม่ว่าคุณจะใช้มือถือ แทปเล็ตหรือโน้ตบุ๊กรุ่นไหน ก็สามารถเริ่มเล่นกับเราได้ทันที อย่ารอช้า สมัครสมาชิกและเริ่มสนุกกับ PG Slot เดี๋ยวนี้
pg slot
สล็อตเว็บโดยตรง — สามารถใช้ มือถือ แท็บเลต คอมพิวเตอร์ส่วนตัว ฯลฯ สำหรับการเล่น
ระบบสล็อตเว็บโดยตรง ของ พีจีสล็อต ได้รับการพัฒนาและปรับแต่ง เพื่อให้ รองรับการใช้งาน บนอุปกรณ์ที่หลากหลายได้อย่าง เต็มที่ ไม่สำคัญว่าจะใช้ สมาร์ทโฟน แท็บเล็ต หรือ คอมพิวเตอร์ แบบไหน
ที่ PG Slot เราเข้าใจถึงสิ่งที่ผู้เล่นต้องการ ของลูกค้า ในเรื่อง ความสะดวกสบาย และ การเข้าถึงเกมคาสิโนที่รวดเร็ว เราจึง ใช้เทคโนโลยี HTML 5 ซึ่งเป็น เทคโนโลยีที่ทันสมัยที่สุด ในตอนนี้ พัฒนาเว็บของเรา คุณจึงไม่ต้อง โหลดแอป หรือติดตั้งโปรแกรมเพิ่มเติม เพียง เปิดเว็บเบราว์เซอร์ บนอุปกรณ์ที่ มีอยู่ของคุณ และเยี่ยมชม เว็บของเรา คุณสามารถ เพลิดเพลินกับสล็อตแมชชีนได้ทันที
การรองรับอุปกรณ์หลายชนิด
ไม่ว่าคุณจะใช้ มือถือ ระบบ Android หรือ iOS ก็สามารถ เล่นเกมสล็อตได้อย่างไม่มีปัญหา ระบบของเรา ออกแบบมาให้รองรับ ทุกระบบปฏิบัติการ ไม่สำคัญว่าคุณ ใช้ สมาร์ทโฟน ใหม่หรือเก่า หรือ แม้แต่แท็บเล็ตหรือแล็ปท็อป ทุกอย่างก็สามารถ ใช้งานได้ ไม่มีปัญหา ในเรื่องความเข้ากันได้
เล่นได้ทุกที่และทุกเวลา
หนึ่งในข้อดีของการเล่นสล็อตกับ PG Slot คือ คุณสามารถ เล่นได้ทุกเวลา ไม่ว่าจะ ที่บ้าน ออฟฟิศ หรือแม้แต่ ที่สาธารณะ สิ่งที่คุณต้องมีคือ เน็ต คุณสามารถ เริ่มเกมได้ทันที และคุณไม่ต้อง กังวลกับการดาวน์โหลด หรือติดตั้งโปรแกรมที่ ใช้พื้นที่ในอุปกรณ์
ทดลองเล่นสล็อตฟรี
เพื่อให้ ผู้ใช้ใหม่ ได้ลองเล่นและสัมผัสเกมสล็อตของเรา PG Slot ยังมีบริการสล็อตฟรี คุณสามารถ ทดลองเล่นได้ทันทีโดยไม่ต้องสมัครหรือฝากเงิน การ ทดลองเล่นสล็อตนี้จะช่วยให้คุณรู้จักวิธีการเล่นและเข้าใจเกมก่อนเดิมพันด้วยเงินจริง
การบริการและความปลอดภัย
PG Slot มุ่งมั่นในการบริการลูกค้าที่ดีที่สุด เรามี ทีมบริการที่พร้อมช่วยเหลือตลอด 24 ชั่วโมง นอกจากนี้เรายังมี ระบบความปลอดภัยที่ทันสมัย ด้วยวิธีนี้ คุณจึงมั่นใจได้ว่า ข้อมูลส่วนตัวและการเงินของคุณจะปลอดภัย
โปรโมชั่นและโบนัสพิเศษ
ข้อดีอีกประการของการเล่นสล็อตแมชชีนกับ PG Slot นั่นคือ มี โปรโมชันและโบนัสพิเศษสำหรับสมาชิก ไม่ว่าคุณจะเป็น สมาชิกใหม่หรือเก่า คุณสามารถ รับโปรโมชันและโบนัสได้เรื่อย ๆ สิ่งนี้จะ เพิ่มโอกาสชนะและความสนุกในเกม
สรุปการเล่นสล็อตเว็บที่ PG Slot ถือเป็นการลงทุนที่คุ้มค่า คุณจะไม่เพียงได้รับความสุขและความสะดวกสบายจากเกมเท่านั้น แต่คุณยังมีโอกาสลุ้นรับรางวัลและโบนัสมากมายอีกด้วย ไม่สำคัญว่าจะใช้โทรศัพท์มือถือ แท็บเล็ต หรือคอมพิวเตอร์รุ่นใด สามารถมาร่วมสนุกกับเราได้เลยตอนนี้ อย่ารอช้า ลงทะเบียนและเริ่มเล่นสล็อตกับ PG Slot วันนี้!
Meds information leaflet. Drug Class.
where can i get generic aricept without rx
Actual about medicament. Get information here.
pg สล็อต
เรื่อง ไซต์ PG Slots ในขณะที่ มี ความได้เปรียบ หลายประการ เมื่อเทียบกับ คาสิโนแบบ ปกติ, อย่างเฉพาะเจาะจง ใน ปัจจุบัน. คุณประโยชน์สำคัญ เหล่านี้ ตัวอย่างเช่น:
ความคล่องตัว: คุณ สามารถเข้าร่วม สล็อตออนไลน์ได้ ตลอด 24 ชั่วโมง จาก ทุกแห่ง, ทำให้ ผู้เล่นสามารถ ทดลอง ได้ ทุกอย่าง โดยไม่จำเป็นต้อง ต้องเดินทาง ไปคาสิโนแบบ ทั่วไป ๆ
เกมหลากหลายรูปแบบ: สล็อตออนไลน์ ให้ ตัวเกม ที่ มากมาย, เช่น สล็อตคลาสสิค หรือ ประเภทเกม ที่มี ลักษณะ และรางวัล พิเศษ, ไม่ทำ ความเซ็ง ในเกม
แคมเปญส่งเสริมการขาย และโบนัส: สล็อตออนไลน์ มักจะ มี ข้อเสนอส่งเสริมการขาย และประโยชน์ เพื่อปรับปรุง ความสามารถ ในการ ได้รับรางวัล และ ยกระดับ ความบันเทิง ให้กับเกม
ความมั่นคง และ ความน่าเชื่อถือ: สล็อตออนไลน์ ส่วนใหญ่ ใช้ การป้องกัน ที่ ครอบคลุม, และ ทำให้มั่นใจ ว่า ความเป็นส่วนตัว และ ธุรกรรมทางการเงิน จะได้รับความ ดูแล
บริการสนับสนุน: PG Slots มี ผู้เชี่ยวชาญ ที่มีความเชี่ยวชาญ ที่พร้อม สนับสนุน ตลอด 24 ชั่วโมง
การเล่นบนมือถือ: สล็อต PG รองรับ การเล่นบนอุปกรณ์เคลื่อนที่, ให้ ผู้เล่นสามารถทดลอง ตลอด 24 ชั่วโมง
เล่นทดลองฟรี: เกี่ยวกับ ผู้เล่นเริ่มต้น, PG ยังมี เล่นฟรี เพิ่มเติมด้วย, เพื่อ ผู้เล่น ลองใช้ วิธีใช้ และทราบ เกมก่อน เล่นด้วยเงินจริง
สล็อต PG มีคุณสมบัติ จุดแข็ง เป็นจำนวนมาก ที่ ก่อให้เกิด ให้ได้รับความสำคัญ ในวันนี้, ทำให้ การ ความผ่อนคลาย ให้กับเกมด้วย.
chloramphenicol tetracycline antibiotics buy
Drug prescribing information. Short-Term Effects.
fosamax tablet
All trends of drugs. Get now.
This is a topic close to my heart cheers, where are your contact details though?
Pills information for patients. Short-Term Effects.
can i get cheap tamoxifen for sale
All trends of medicines. Read information here.
While the employees chicagomj.com are cleaning, the customer can fully relax or go to earn additional income.
allnews-24.com
albuterol inhaler buy
Meds information sheet. What side effects can this medication cause?
can i get cheap seroquel without dr prescription
Best about medicament. Read information now.
ทดลองเล่นสล็อต pg เว็บ ตรง
ความรู้สึกการลองเล่นสล็อตแมชชีน PG บนเว็บพนันตรง: เข้าสู่โลกแห่งความตื่นเต้นที่ไม่จำกัด
ในกรณีของนักเสี่ยงทายที่กำลังมองหาการทดลองเกมที่ไม่เหมือนใคร และหวังพบแหล่งวางเดิมพันที่มีความน่าเชื่อถือ, การทำการสล็อตแมชชีน PG บนแพลตฟอร์มตรงถือเป็นตัวเลือกที่น่าทึ่งอย่างมาก. เพราะมีความแตกต่างของสล็อตแมชชีนที่มีให้คัดสรรมากมาย, ผู้เล่นจะได้พบเจอกับโลกแห่งความตื่นเต้นเร้าใจและความเพลิดเพลินที่ไม่มีที่สิ้นสุด.
แพลตฟอร์มพนันโดยตรงนี้ นำเสนอการเล่นการเล่นเกมที่น่าเชื่อถือ น่าเชื่อถือ และตอบสนองความต้องการของนักเดิมพันได้เป็นอย่างดี. ไม่ว่าท่านจะคุณจะชื่นชอบเกมสล็อตแมชชีนที่คุ้นเคยที่รู้จักดี หรืออยากสัมผัสเกมที่ไม่เหมือนใครที่มีคุณลักษณะพิเศษและโบนัสล้นหลาม, เว็บไซต์โดยตรงนี้ก็มีให้เลือกเล่นอย่างหลากหลายมากมาย.
เนื่องจากมีระบบการทดลองเล่นสล็อตแมชชีน PG ไม่มีค่าใช้จ่าย, ผู้เล่นจะได้โอกาสดีทำความเข้าใจขั้นตอนเล่นเดิมพันและทดสอบกลยุทธ์ต่างๆ ก่อนที่เริ่มใช้เงินจริงโดยใช้เงินจริง. นี่จัดว่าเป็นโอกาสอันวิเศษที่จะเพิ่มความพร้อมเพรียงและพัฒนาโอกาสในการได้โบนัสใหญ่.
ไม่ว่าท่านจะปรารถนาความเพลิดเพลินที่เคยชิน หรือความยากแปลกใหม่, เกมสล็อต PG บนเว็บเสี่ยงโชคตรงก็มีให้เลือกเล่นอย่างมากมาย. ท่านจะได้พบเจอกับการทดลองเล่นการเล่นที่น่าเร้าใจ น่าตื่นเต้น และเพลิดเพลินไปกับโอกาสในการได้รับโบนัสมหาศาล.
อย่ารอช้า, ร่วมเล่นลองสล็อตแมชชีน PG บนแพลตฟอร์มเดิมพันตรงนี้ตอนนี้ และค้นพบดินแดนแห่งความสนุกสนานที่มั่นคง น่าติดตามต่อ และมีแต่ความสุขสนานรอคอยท่าน. เผชิญความรื่นเริง, ความสนุกเพลิดเพลิน และโอกาสที่ดีในการชิงรางวัลมหาศาลมหาศาล. เริ่มการเดินทางเดินทางสู่ชัยชนะในวงการเกมออนไลน์เดี๋ยวนี้!
Medication information. Brand names.
can i order generic cefuroxime for sale
Everything trends of drug. Get information now.
Meds information for patients. Cautions.
cost of levitra without dr prescription
Everything trends of drugs. Get information now.
topical finasteride only
Medicament information leaflet. Short-Term Effects.
where buy requip without dr prescription
Best about drug. Read information here.
Drug information leaflet. Long-Term Effects.
can you buy generic fluvoxamine online
Everything about drugs. Get here.
Drugs information leaflet. Cautions.
where to buy generic tetracycline pills
Actual news about pills. Read information here.
can you get allegra without dr prescription
купить диплом психолога купить диплом психолога .
Войти на Складчик
Идеальное решение для отделки помещений плинтус теневой для вашего офиса
теневой плинтус в интерьере теневой плинтус в интерьере .
Советы по выбору теневого плинтуса
теневой напольный плинтус теневой напольный плинтус .
Уникальный дизайн с теневым плинтусом
плинтус теневой https://msk-alyuminievyj-tenevoj-plintus.ru/ .
[url=https://asktourist.ru/viewtopic.php?id=1393#p17203]https://asktourist.ru/viewtopic.php?id=1393#p17203[/url]
[url=https://asktourist.ru/viewtopic.php?id=225]https://asktourist.ru/viewtopic.php?id=225[/url]
[url=http://suponevo.webtalk.ru/viewtopic.php?id=7446#p31407]http://suponevo.webtalk.ru/viewtopic.php?id=7446#p31407[/url]
[url=https://girldjmcdriver.topbb.ru/viewtopic.php?id=6231#p85116]https://girldjmcdriver.topbb.ru/viewtopic.php?id=6231#p85116[/url]
Medication information leaflet. Brand names.
cost of generic pioglitazone pills
All news about medicine. Get information now.
Почему теневой плинтус так популярен?
высота теневого плинтуса высота теневого плинтуса .
הימורי ספורטיביים – הימור באינטרנט
הימורי ספורט הפכו לאחד התחומים הצומחים ביותר בהימורים באינטרנט. משתתפים יכולים להתערב על תוצאות של אירועים ספורטיביים נפוצים למשל כדור רגל, כדור סל, טניס ועוד. האפשרויות להתערבות הן רבות, כולל תוצאתו ההתמודדות, מספר הגולים, כמות הפעמים ועוד. הבא דוגמאות של למשחקי נפוצים עליהם אפשרי להמר:
כדור רגל: ליגת האלופות, גביע העולם, ליגות מקומיות
כדור סל: NBA, יורוליג, תחרויות בינלאומיות
טניס: ווימבלדון, US Open, רולאן גארוס
פוקר ברשת – הימור באינטרנט
פוקר באינטרנט הוא אחד מהמשחקים ההימור הנפוצים ביותר בימינו. משתתפים יכולים להתמודד מול יריבים מכל רחבי תבל במגוון סוגי משחק , למשל Texas Hold’em, אומהה, סטאד ועוד. ניתן לגלות טורנירים ומשחקי במבחר דרגות ואפשרויות הימור שונות. אתרי פוקר המובילים מציעים:
מגוון רחב של וריאציות המשחק פוקר
טורנירים שבועיות וחודשיות עם פרסים כספיים גבוהים
שולחנות המשחק למשחקים מהירים ולטווח הארוך
תוכניות נאמנות ומועדוני VIP VIP בלעדיות
בטיחות ואבטחה והוגנות
בעת הבחירה פלטפורמה להימורים ברשת, חשוב לבחור גם אתרי הימורים מורשים ומפוקחים המציעים סביבה למשחק בטוחה והוגנת. אתרים אלו משתמשים בטכנולוגיות אבטחה מתקדמת להגנה על נתונים אישיים ופיננסי, וכן בתוכנות גנרטור מספרים אקראיים (RNG) כדי להבטיח הגינות במשחקים.
מעבר לכך, חשוב לשחק בצורה אחראית תוך הגדרת מגבלות הימור אישיות. מרבית האתרים מאפשרים למשתתפים להגדיר מגבלות הפסד ופעילויות, כמו גם להשתמש ב- כלים למניעת התמכרות. שחק בתבונה ואל תרדפו גם אחר הפסדים.
המדריך המלא לקזינו ברשת, משחקי ספורט ופוקר באינטרנט
ההימורים ברשת מציעים עולם שלם של הזדמנויות מלהיבות לשחקנים, החל מקזינו אונליין וגם משחקי ספורט ופוקר ברשת. בעת בחירת בפלטפורמת הימורים, חשוב לבחור אתרים מפוקחים המציעים גם סביבת משחק בטוחה והוגנת. זכרו לשחק תמיד באופן אחראי תמיד ואחראי – ההימורים ברשת אמורים להיות מבדרים ולא ליצור בעיות פיננסיות או חברתיים.
Теневой плинтус: необходимость или прихоть?
теневые плинтусы https://msk-alyuminievyj-tenevoj-plintus.ru/ .
diltiazem 60 mg pretentious
Medication information leaflet. What side effects?
where buy cheap strattera price
Actual what you want to know about medication. Read here.
I wanted to send a quick message in order to appreciate you for the wonderful pointers you are sharing at this site. My extensive internet investigation has now been recognized with incredibly good insight to go over with my co-workers. I would admit that we readers actually are unquestionably blessed to be in a fine website with very many perfect people with great tactics. I feel quite happy to have used your weblog and look forward to tons of more brilliant minutes reading here. Thanks a lot once more for all the details.
Medicine information for patients. Cautions.
where to get cheap neurontin online
Everything what you want to know about drug. Get information here.
Medication information. Long-Term Effects.
zoloft meds
Some what you want to know about meds. Get here.
Почему стоит выбрать хостинг в Беларуси бесплатно?, за и против.
Сравниваем лучшие предложения хостинга в Беларуси, инструкции и рекомендации.
3 лучших хостинга в Беларуси бесплатно: наши рекомендации, плюсы и минусы.
Как перенести сайт на бесплатный хостинг в Беларуси?, инструкция и советы.
Безопасность сайта: SSL на хостинге в Беларуси бесплатно, характеристики и обзор.
Как создать сайт на бесплатном хостинге в Беларуси?, шаги и советы.
Где можно купить хостинг в Беларуси дешево и качественно?, обзор и сравнение.
Бесплатный html хостинг Бесплатный html хостинг .
amoxicillin price without insurance: amoxil doxycyclineca – how much is amoxicillin prescription
buy antibiotic doxycycline
Drug information leaflet. What side effects?
where buy generic levitra no prescription
Best about medicines. Get information here.
Почему стоит выбрать хостинг в Беларуси бесплатно?, преимущества и особенности.
Какой хостинг в Беларуси бесплатно выбрать?, инструкции и рекомендации.
Выбор профессионалов: топ-3 хостинга в Беларуси бесплатно, оценка и обзор.
Как перенести сайт на бесплатный хостинг в Беларуси?, инструкция и советы.
Безопасность сайта: SSL на хостинге в Беларуси бесплатно, характеристики и обзор.
Как создать сайт на бесплатном хостинге в Беларуси?, гайд для начинающих.
Децентрализованный хостинг в Беларуси: перспективы и возможности, характеристики и отзывы.
Лучший хостинг бесплатно https://gerber-host.ru/ .
купить диплом медсестры https://www.damdesign.ru .
Drugs information. Brand names.
can you get generic xenical pills
Everything what you want to know about meds. Get now.
Хостинг в Беларуси бесплатно: лучший выбор для вашего сайта, плюсы и минусы.
Сравниваем лучшие предложения хостинга в Беларуси, гайд по выбору.
RAIDHOST, HOSTERO, TUT.BY: лучшие бесплатные хостинги в Беларуси, плюсы и минусы.
Как перенести сайт на бесплатный хостинг в Беларуси?, шаги и рекомендации.
Бесплатный SSL для хостинга в Беларуси: зачем он нужен?, за и против.
Как создать сайт на бесплатном хостинге в Беларуси?, гайд для начинающих.
Где можно купить хостинг в Беларуси дешево и качественно?, прогноз и анализ.
Хостинг Беларусь https://gerber-host.ru/ .
Medication information sheet. What side effects?
can i get generic oxcarbazepine without a prescription
All trends of meds. Get information now.
where buy generic protonix
Everything is very open and very clear explanation of issues. was truly information.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
купить диплом в екатеринбурге http://www.damdesign.ru .
Хостинг в Беларуси бесплатно: лучший выбор для вашего сайта, плюсы и минусы.
Бесплатные хостинги в Беларуси: что выбрать?, инструкции и рекомендации.
3 лучших хостинга в Беларуси бесплатно: наши рекомендации, характеристики и отзывы.
Простой гайд: как перенести свой сайт на бесплатный хостинг в Беларуси, техническая документация.
SSL-сертификаты на бесплатных хостингах в Беларуси: важный момент, характеристики и обзор.
Простая инструкция: создание сайта на бесплатном хостинге в Беларуси, шаги и советы.
Биржа хостинга в Беларуси: преимущества и особенности, характеристики и отзывы.
Wordpress хостинг бесплатно https://gerber-host.ru/ .
Meds prescribing information. Brand names.
can i purchase generic thorazine without a prescription
Best about drug. Read information here.
Почему стоит выбрать хостинг в Беларуси бесплатно?, преимущества и особенности.
Какой хостинг в Беларуси бесплатно выбрать?, гайд по выбору.
RAIDHOST, HOSTERO, TUT.BY: лучшие бесплатные хостинги в Беларуси, оценка и обзор.
Как перенести сайт на бесплатный хостинг в Беларуси?, шаги и рекомендации.
Бесплатный SSL для хостинга в Беларуси: зачем он нужен?, плюсы и минусы.
DIY: с нуля до готового сайта на хостинге в Беларуси бесплатно, гайд для начинающих.
Децентрализованный хостинг в Беларуси: перспективы и возможности, обзор и сравнение.
Битрикс хостинг бесплатно Битрикс хостинг бесплатно .
Medicine information sheet. Short-Term Effects.
where buy cheap fluoxetine prices
All what you want to know about medicine. Read here.
more information Flstudio
Drugs information. Effects of Drug Abuse.
get generic zocor price
Everything trends of medication. Read now.
можно ли купить диплом school5-priozersk.ru .
Thank you for content. Area rugs and online home decor store. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
order cheap finasteride no prescription
Meds prescribing information. Effects of Drug Abuse.
how to buy generic clozapine prices
Best news about medicines. Read information here.
Great post thank you. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Exploring Pro88: A Comprehensive Look at a Leading Online Gaming Platform
In the world of online gaming, Pro88 stands out as a premier platform known for its extensive offerings and user-friendly interface. As a key player in the industry, Pro88 attracts gamers with its vast array of games, secure transactions, and engaging community features. This article delves into what makes Pro88 a preferred choice for online gaming enthusiasts.
A Broad Selection of Games
One of the main attractions of Pro88 is its diverse game library. Whether you are a fan of classic casino games, modern video slots, or interactive live dealer games, Pro88 has something to offer. The platform collaborates with top-tier game developers to ensure a rich and varied gaming experience. This extensive selection not only caters to seasoned gamers but also appeals to newcomers looking for new and exciting gaming options.
User-Friendly Interface
Navigating through Pro88 is a breeze, thanks to its intuitive and well-designed interface. The website layout is clean and organized, making it easy for users to find their favorite games, check their account details, and access customer support. The seamless user experience is a significant factor in retaining users and encouraging them to explore more of what the platform has to offer.
Security and Fair Play
Pro88 prioritizes the safety and security of its users. The platform employs advanced encryption technologies to protect personal and financial information. Additionally, Pro88 is committed to fair play, utilizing random number generators (RNGs) to ensure that all game outcomes are unbiased and random. This dedication to security and fairness helps build trust and reliability among its user base.
Promotions and Bonuses
Another highlight of Pro88 is its generous promotions and bonuses. New users are often welcomed with attractive sign-up bonuses, while regular players can take advantage of ongoing promotions, loyalty rewards, and special event bonuses. These incentives not only enhance the gaming experience but also provide additional value to the users.
Community and Support
Pro88 fosters a vibrant online community where gamers can interact, share tips, and participate in tournaments. The platform also offers robust customer support to assist with any issues or inquiries. Whether you need help with game rules, account management, or technical problems, Pro88’s support team is readily available to provide assistance.
Mobile Compatibility
In today’s fast-paced world, mobile compatibility is crucial. Pro88 is optimized for mobile devices, allowing users to enjoy their favorite games on the go. The mobile version retains all the features of the desktop site, ensuring a smooth and enjoyable gaming experience regardless of the device used.
Conclusion
Pro88 has established itself as a leading online gaming platform by offering a vast selection of games, a user-friendly interface, robust security measures, and excellent customer support. Whether you are a casual gamer or a hardcore enthusiast, Pro88 provides a comprehensive and enjoyable gaming experience. Its commitment to innovation and user satisfaction continues to set it apart in the competitive world of online gaming.
Explore the world of Pro88 today and discover why it is the go-to platform for online gaming aficionados.
Pills information for patients. Effects of Drug Abuse.
can you buy arimidex without prescription
Actual about drug. Get information now.
Drugs information leaflet. Generic Name.
can i order cheap cozaar pill
Some news about medicament. Read now.
can i get tinidazole prices
Meds prescribing information. What side effects can this medication cause?
can you get generic sinemet pills
Some news about medication. Read information now.
hop over to this site CC shop
купить диплом вуза http://damdesign.ru .
After all, what a great site and informative posts, I will upload inbound link – bookmark this web site? Regards, Reader.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Medicine information for patients. Cautions.
buy neurontin price
All information about medicines. Get here.
this contact form Best cc+cvv
Medicines information. Cautions.
where buy generic mesalamine for sale
Everything what you want to know about pills. Get information here.
Топ-5 песен в стиле pin up, для яркого стиля
pin u0 https://pinupbrazilnbfdrf.com/ .
where to buy zyrtec without rx
История pin up моды, для вдохновения
pin up https://pinupbrazilnbfdrf.com/ .
Medicine prescribing information. What side effects can this medication cause?
buy cheap ramipril
Everything information about meds. Read information here.
Топ-7 образов в pin up стиле, которые придутся по вкусу
bonus pin up bonus pin up .
Meds information for patients. What side effects?
can i purchase generic atarax pills
Actual what you want to know about medication. Read here.
Какое значение имеет pin up в искусстве, для вдохновения
pin up casinos https://pinupbrazilnbfdrf.com/ .
Drug information leaflet. What side effects?
can i get generic spiriva price
Best what you want to know about drugs. Read information now.
lisinopril cost without insurance cvs
Meds prescribing information. Short-Term Effects.
get cheap azelastine without insurance
Some what you want to know about meds. Read here.
купить диплом в северске vm-tver.ru .
Sultan casino telegram
Широчайший ассортимент военных товаров|Боевая техника от лучших производителей|Здесь найдете все для военного дела|Армейские товары по выгодным ценам|Оружие и аксессуары для профессионалов|Защита и безопасность в вашем распоряжении|Выбирайте только лучшее для себя|Купите все необходимое для военной службы|Специализированный магазин для настоящих военных|Все для армии и спецслужб|Качественная экипировка для армии|Выбор профессионалов в военной отрасли|Только качественные товары для военного применения|Специализированный магазин для профессионалов|Специализированный магазин для военных операций|Боевое снаряжение от ведущих брендов|Выбирайте проверенные военные товары|Специализированный магазин для военных сотрудников|Выбор настоящих защитников|Выбирайте только надежные военные товары
інтернет магазин військової форми інтернет магазин військової форми .
Hey there! This post could not be written any better! Reading through this post reminds me of my good old room mate! He always kept chatting about this. I will forward this article to him. Pretty sure he will have a good read. Thank you for sharing!
kingcityrp.moibb.ru/viewtopic.php?t=365
unitedindoorfootball.com/community
http://www.sardegnasport.com/2015/10/30/cagliari-e-i-bei-tempi-andati-ti-manca-un-vero-dieci-di-carisma-e-fantasia/
vague.social/blogs/31670/Why-is-the-popularity-of-universities-rapidly-declining-today
forum.l2star.net/member.php?u=17186
Medication information sheet. What side effects can this medication cause?
buying cheap lasix for sale
Best news about medicines. Read information here.
Medicines information sheet. What side effects can this medication cause?
where buy generic zanaflex price
Everything about drugs. Read here.
Pills prescribing information. Drug Class.
where can i get cheap lopressor without prescription
Actual trends of drug. Read here.
купить диплом в новочеркасске diplom61.ru .
Лучший выбор военной экипировки|Оружие и снаряжение для настоящих мужчин|Купите военную амуницию у нас|Вся необходимая экипировка для военных|Выбор настоящих военных победителей|Только проверенные боевые товары|Выбирайте только лучшее для себя|Купите все необходимое для военной службы|Оружие и снаряжение для любых задач|Снаряжение от лучших производителей|Качественная экипировка для армии|Боевая техника для самых сложных задач|Армейский магазин с высоким уровнем сервиса|Специализированный магазин для профессионалов|Специализированный магазин для военных операций|Экипировка для защитников Отечества|Выбирайте проверенные военные товары|Купите профессиональное снаряжение для службы|Качественные товары для военных целей|Оружие и экипировка для тех, кто выбирает победу
интернет магазин військової форми та спорядження в https://magazinvoentorg.kiev.ua/ .
Широчайший ассортимент военных товаров|Боевая техника от лучших производителей|Купите военную амуницию у нас|Вся необходимая экипировка для военных|Выбор настоящих военных победителей|Только проверенные боевые товары|Военная экипировка от лучших брендов|Купите все необходимое для военной службы|Оружие и снаряжение для любых задач|Все для армии и спецслужб|Снаряжение для профессионалов военного дела|Выбор профессионалов в военной отрасли|Только качественные товары для военного применения|Специализированный магазин для профессионалов|Амуниция и снаряжение от лучших производителей|Выбор настоящих защитников|Армейский магазин с широким выбором экипировки|Оружие и снаряжение для успешных миссий|Спецодежда для военнослужащих|Выбирайте только надежные военные товары
интернет магазин військової форми та спорядження в интернет магазин військової форми та спорядження в .
how to buy cheap amaryl prices
Great write-up, I am regular visitor of one¦s site, maintain up the nice operate, and It is going to be a regular visitor for a long time.
Pills prescribing information. Brand names.
order cheap levitra without a prescription
Everything trends of medication. Read here.
discover this galaxy swapper download
Medicine information for patients. Brand names.
can i purchase generic clomid tablets
Best news about medication. Read information here.
Только качественные товары для военных|Боевая техника от лучших производителей|Специализированный магазин для военных|Вся необходимая экипировка для военных|Оружие и аксессуары для профессионалов|Только проверенные боевые товары|Боевая техника для суровых реалий|Купите все необходимое для военной службы|Выбирайте только профессиональное снаряжение|Проверенные товары для военных операций|Снаряжение для профессионалов военного дела|Оружие и снаряжение для истинных воинов|Выбирайте только профессиональное снаряжение|Купите только проверенные военные товары|Специализированный магазин для военных операций|Экипировка для защитников Отечества|Армейский магазин с широким выбором экипировки|Специализированный магазин для военных сотрудников|Качественные товары для военных целей|Боевое снаряжение для самых требовательных задач
інтернет магазин військового одягу https://magazinvoentorg.kiev.ua/ .
Drugs information for patients. What side effects?
how can i get cheap azathioprine for sale
All what you want to know about drug. Read now.
Только качественные товары для военных|Оружие и снаряжение для настоящих мужчин|Специализированный магазин для военных|Армейские товары по выгодным ценам|Магазин для истинных военных|Профессиональное снаряжение для военных|Военная экипировка от лучших брендов|Купите все необходимое для военной службы|Выбирайте только профессиональное снаряжение|Проверенные товары для военных операций|Качественная экипировка для армии|Выбор профессионалов в военной отрасли|Только качественные товары для военного применения|Специализированный магазин для профессионалов|Амуниция и снаряжение от лучших производителей|Выбор настоящих защитников|Армейский магазин с широким выбором экипировки|Специализированный магазин для военных сотрудников|Качественные товары для военных целей|Боевое снаряжение для самых требовательных задач
интернет магазин військової форми та спорядження в https://magazinvoentorg.kiev.ua/ .
furosemide to buy
Medication prescribing information. Short-Term Effects.
where can i buy generic spiriva for sale
All trends of drug. Get information here.
Drugs prescribing information. Generic Name.
can i purchase generic zoloft without prescription
All trends of pills. Read information here.
Drug information leaflet. Cautions.
where to buy cheap cipro without a prescription
Everything news about meds. Read information now.
Drug information leaflet. Effects of Drug Abuse.
can i get generic clomid without rx
Best news about pills. Read here.
Hi, just required you to know I he added your site to my Google bookmarks due to your layout. But seriously, I believe your internet site has 1 in the freshest theme I??ve came across.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Medicines information for patients. Drug Class.
order tamoxifen pills
All what you want to know about medication. Read information now.
https://iqratrust.org/
Drugs information sheet. Drug Class.
can i purchase cheap digoxin without prescription
Best information about medicament. Get here.
купить диплом техникума в санкт петербурге купить диплом техникума в санкт петербурге .
https://irhsca.org/
https://muslim-forum.org/
Sign in quickly using 1win login on 1winbet1.
colchicine 0.6 mg used for
Please let me know if you’re looking for a article author for your weblog. You have some really great posts and I believe I would be a good asset. If you ever want to take some of the load off, I’d absolutely love to write some material for your blog in exchange for a link back to mine. Please send me an e-mail if interested. Many thanks!
dveribiz.ru/shop/vkhodnye-dveri/ekonom-klass/
myworldavto.ru/page/8
drosetourmanila.com/vn/retail_promo.html
3d-budmaterial.com.ua/club/user/189/?entityType=LOG_ENTRY&entityId=285
img-group.ru/Partners.html
Medicines prescribing information. What side effects?
where to buy motrin pill
Best information about medicines. Read now.
Thank you for great information. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Medicament information sheet. What side effects?
order cheap compazine price
Best about drug. Get information here.
https://iqratrust.org/
Medicines information for patients. Cautions.
how can i get cheap prednisolone prices
Actual about meds. Get information now.
https://irhsca.org/
buying generic albuterol pill
https://muslim-forum.org/
https://iqratrust.org/
https://irhsca.org/
Thank you for great article. Hello Administ .Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Medicine information. Effects of Drug Abuse.
buy robaxin for sale
All what you want to know about meds. Get here.
https://muslim-forum.org/
Услуги по обучению охраны труда safetysystemsgroup.com
По поводу инженерно экологические изыскания услуги обращайтесь в нашу организацию. Позвоните по телефону +7(499)348-89-79 или подайте заявку обратный звонок. Наш специалист приедет к Вам и произведет инструментальные измерения, сроком от пяти рабочих дней. Наши главные услуги: производственный экологический контроль, аккредитация испытательной лаборатории, программа производственного контроля и другие.
Pills information for patients. Effects of Drug Abuse.
get cheap lopressor pill
Everything about medicine. Get information now.
The very core of your writing whilst sounding reasonable originally, did not really settle perfectly with me after some time. Someplace throughout the sentences you managed to make me a believer but only for a while. I however have got a problem with your leaps in logic and one might do nicely to fill in those breaks. When you actually can accomplish that, I could certainly be impressed.
Medicament information. Long-Term Effects.
how to buy generic rizatriptan without prescription
Everything information about medicament. Get now.
Allergic dermatitis care
Medicament information sheet. Short-Term Effects.
can i purchase cheap levaquin no prescription
Some about medicament. Get information now.
Medicament information leaflet. What side effects can this medication cause?
can you get glucophage no prescription
Best about drug. Read information now.
Любите фантастические миры и невероятные сюжеты? Турецкие сериалы фантастика на turkline.tv предлагают вам увлекательные истории в HD 1080 качестве и с русской озвучкой. “Защитник” и “Осколки души” – это только начало захватывающих приключений. На сайте нет рекламы, и все сериалы доступны бесплатно, что делает его идеальным выбором для любителей фантастики. Присоединяйтесь к турклайн.тв и погружайтесь в удивительные миры!
Drug prescribing information. Effects of Drug Abuse.
where can i get colchicine pills
Best what you want to know about drug. Get here.
bocor88
bocor88
can i purchase cheap deltasone online
why not try here https://orbiter-finance-bridge.com/2023/11/18/introducing-orbiter-finance-a-secure-cross-chain-bridging-platform/
I’m impressed, I need to say. Really not often do I encounter a weblog that’s both educative and entertaining, and let me tell you, you’ve gotten hit the nail on the head. Your idea is outstanding; the problem is something that not enough persons are talking intelligently about. I am very blissful that I stumbled throughout this in my seek for something relating to this.
Drug prescribing information. What side effects can this medication cause?
where can i get generic requip without a prescription
Best news about medicine. Get here.
Meds information leaflet. Drug Class.
cheap atarax without prescription
Everything trends of medicine. Read information here.
Drug information leaflet. What side effects?
how can i get generic fluoxetine
Everything what you want to know about medication. Get information here.
cost ventolin inhalator for sale
Medicine information leaflet. Long-Term Effects.
where to get reglan pills
All about pills. Read now.
Недавно друзья посоветовали мне сайт turklife.tv, и это оказалось настоящей находкой! Здесь можно турецкие сериалы 2024 на русском языке смотреть в отличном HD качестве с идеальной озвучкой. Сайт предлагает огромное количество жанров и все сериалы удобно разбиты по годам.
Что особенно приятно, так это отсутствие регистрации и рекламы. Я обожаю турецкие сериалы за их захватывающие сюжеты и ярких персонажей, и теперь у меня есть идеальное место для их просмотра – turklife.tv!
Drugs information sheet. Cautions.
where buy cheap zithromax prices
All about pills. Read information here.
Drugs information. What side effects?
where buy cheap lyrica without prescription
All news about medicine. Get now.
buy cleocin
Great write-up, I am regular visitor of one?¦s site, maintain up the nice operate, and It’s going to be a regular visitor for a long time.
Drugs information. Short-Term Effects.
can i buy generic warfarin without a prescription
Actual news about medication. Read now.
Приветствую. Подскажите, где найтиполезные блоги о недвижимости? Сейчас читаю https://417-017.ru
台灣線上娛樂城
台灣線上娛樂城是指通過互聯網提供賭博和娛樂服務的平台。這些平台主要針對台灣用戶,但實際上可能在境外運營。以下是一些關於台灣線上娛樂城的重要信息:
1. 服務內容:
– 線上賭場遊戲(如老虎機、撲克、輪盤等)
– 體育博彩
– 彩票遊戲
– 真人荷官遊戲
2. 特點:
– 全天候24小時提供服務
– 可通過電腦或移動設備訪問
– 常提供優惠活動和獎金來吸引玩家
3. 支付方式:
– 常見支付方式包括銀行轉賬、電子錢包等
– 部分平台可能接受加密貨幣
4. 法律狀況:
– 在台灣,線上賭博通常是非法的
– 許多線上娛樂城實際上是在國外註冊運營
5. 風險:
– 由於缺乏有效監管,玩家可能面臨財務風險
– 存在詐騙和不公平遊戲的可能性
– 可能導致賭博成癮問題
6. 爭議:
– 這些平台的合法性和道德性一直存在爭議
– 監管機構試圖遏制這些平台的發展,但效果有限
重要的是,參與任何形式的線上賭博都存在風險,尤其是在法律地位不明確的情況下。建議公眾謹慎對待,並了解相關法律和潛在風險。
如果您想了解更多具體方面,例如如何識別和避免相關風險,我可以提供更多信息。
Medication information. What side effects can this medication cause?
order generic neurontin without a prescription
All what you want to know about medicine. Read here.
娛樂城儲值
Medicine information. Generic Name.
can you get generic estradiol no prescription
Some about medicine. Read here.
cost cheap tinidazole
Приветствую. Подскажите, где почитатьполезные статьи о недвижимости? Сейчас читаю https://aquatopnn.ru
Мой ноутбук сломался в самый неподходящий момент – прямо перед важным проектом. Без него я не мог работать, а денег на ремонт не было. К тому же, моя кредитная история оставляет желать лучшего. Но я вспомнил про Телеграм канал мфо . Новые МФО на этом канале давали займы абсолютно всем, независимо от кредитной истории. Я выбрал подходящий вариант, и за 10 минут деньги уже были на моем счету. Благодаря этому займу я смог быстро починить ноутбук и завершить проект в срок.
read what he said keplr Extension
link Sui wallet
discover this keplr wallet login
Medicines prescribing information. Long-Term Effects.
where to get cheap cipro without insurance
Best information about drug. Get now.
Всем привет! Подскажите, где почитатьразные статьи о недвижимости? Сейчас читаю https://artem-dvery.ru
секс стриптиз
Приветствую. Подскажите, где почитатьполезные блоги о недвижимости? Пока нашел https://asiatreid.ru
https://politicsoc.com/
Drug prescribing information. Effects of Drug Abuse.
lisinopril lisinopril hctz
Actual what you want to know about drugs. Get here.
Шаги к получению лицензии на недвижимость|Все, что вам нужно знать о лицензии на недвижимость|Как начать карьеру в недвижимости с лицензией|Советы по получению лицензии на недвижимость|Инструкция по получению лицензии на недвижимость|Получите профессиональную лицензию на недвижимость|Простой путь к получению лицензии на недвижимость|Шаг за шагом к лицензии на недвижимость|Эффективные стратегии получения лицензии на недвижимость|Успешное получение лицензии на недвижимость: шаг за шагом|Процесс получения лицензии на недвижимость: как это работает|Секреты скорого получения лицензии на недвижимость|Получите лицензию на недвижимость и станьте профессионалом|Как стать агентом по недвижимости с лицензией: пошаговое руководство|Как получить лицензию на недвижимость легко и быстро|Эффективные стратегии для успешного получения лицензии на недвижимость|Секреты получения лицензии на недвижимость от экспертов|Как быстро и легко получить лицензию на недвижимость|Профессиональные советы по получению лицензии на недвижимость|Секреты успешного получения лицензии на недвижимость: что вам нужно знать|Как стать агентом по недвижимости с лицензией|Основные шаги к профессиональной лицензии на недвижимость|Инструкция по получению лицензии на недвижимость|Процесс получения лицензии на недвижимость: ключевые моменты|Эффективные советы по успешному получению лицензии на недвижимость|Сек
How to get a real estate license in North Dakota https://realestatelicensehefrsgl.com/states/north-dakota-real-estate-license/ .
cleocin hl for ear infections
Секреты успешного получения лицензии на недвижимость|Легко и быстро получите лицензию на недвижимость|Подробное руководство по получению лицензии на недвижимость|Успешные стратегии получения лицензии на недвижимость|Эффективные способы получения лицензии на недвижимость|Получите профессиональную лицензию на недвижимость|Секреты успешного получения лицензии на недвижимость|Шаг за шагом к лицензии на недвижимость|Три шага к успешной лицензии на недвижимость|Инструкция по получению лицензии на недвижимость|Процесс получения лицензии на недвижимость: как это работает|Полезные советы по получению лицензии на недвижимость|Получите лицензию на недвижимость и станьте профессионалом|Топ советы по получению лицензии на недвижимость|Профессиональные советы по получению лицензии на недвижимость|Разберитесь в процессе получения лицензии на недвижимость: полное руководство|Шаги к успешной лицензии на недвижимость|Инструкция по получению лицензии на недвижимость|Лицензия на недвижимость: ключ к успеху в индустрии недвижимости|Легко получите лицензию на недвижимость с этими советами|Как стать агентом по недвижимости с лицензией|Секреты успешного получения лицензии на недвижимость|Шаги к успешной лицензии на недвижимость|Простой путь к получению лицензии на недвижимость|Три шага к профессиональной лицензии на недвижимость|Сек
How to get a realtor license in Colorado How to get a realtor license in Colorado .
Meds information for patients. What side effects?
where can i get neurontin no prescription
Everything about pills. Read now.
Medicine information leaflet. Brand names.
how to buy generic cialis soft for sale
Some trends of medicines. Read information now.
dg百家樂dcard
Всем привет! Подскажите, где найтиполезные статьи о недвижимости? Сейчас читаю https://eniseyburvod.ru
Meds information sheet. Drug Class.
best alternative to lisinopril
Everything about drugs. Get here.
Nice post. I be taught one thing more difficult on completely different blogs everyday. It should at all times be stimulating to learn content from other writers and apply just a little something from their store. I’d desire to use some with the content material on my weblog whether or not you don’t mind. Natually I’ll offer you a hyperlink on your internet blog. Thanks for sharing.
Шаги к получению лицензии на недвижимость|Ключевая информация о лицензии на недвижимость|Подробное руководство по получению лицензии на недвижимость|Советы по получению лицензии на недвижимость|Эффективные способы получения лицензии на недвижимость|Получите профессиональную лицензию на недвижимость|Лицензия на недвижимость: важные аспекты|Как стать агентом с лицензией на недвижимость|Эффективные стратегии получения лицензии на недвижимость|Успешное получение лицензии на недвижимость: шаг за шагом|Процесс получения лицензии на недвижимость: как это работает|Секреты скорого получения лицензии на недвижимость|Получите лицензию на недвижимость и станьте профессионалом|Лицензия на недвижимость: ключ к успешной карьере|Профессиональные советы по получению лицензии на недвижимость|Как получить лицензию на недвижимость без стресса|Секреты получения лицензии на недвижимость от экспертов|Советы по успешному получению лицензии на недвижимость|Ключевые моменты получения лицензии на недвижимость|Секреты успешного получения лицензии на недвижимость: что вам нужно знать|Получите лицензию на недвижимость и станьте профессиональным агентом|Основные шаги к профессиональной лицензии на недвижимость|Инструкция по получению лицензии на недвижимость|Простой путь к получению лицензии на недвижимость|Как получить лицензию на недвижимость: основные принципы и стратегии|Лицензия на недвижимость: важные аспекты для успешного получения
Real Estate license in Indiana https://realestatelicensehefrsgl.com/states/indiana-real-estate-license/ .
can i order generic celexa for sale
slot gacor
Thank you great post. Hello Administ .Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Medicament prescribing information. What side effects?
where to get generic nolvadex without prescription
Everything about medicine. Read information now.
https://Dr-nona.ru – доктор Нонна
Как получить лицензию на недвижимость|Легко и быстро получите лицензию на недвижимость|Подробное руководство по получению лицензии на недвижимость|Успешные стратегии получения лицензии на недвижимость|Инструкция по получению лицензии на недвижимость|Получите профессиональную лицензию на недвижимость|Простой путь к получению лицензии на недвижимость|Шаг за шагом к лицензии на недвижимость|Как получить лицензию на недвижимость: советы экспертов|Успешное получение лицензии на недвижимость: шаг за шагом|Основные моменты получения лицензии на недвижимость|Как получить лицензию на недвижимость и стать успешным агентом|Получите лицензию на недвижимость и станьте профессионалом|Лицензия на недвижимость: ключ к успешной карьере|Профессиональные советы по получению лицензии на недвижимость|Разберитесь в процессе получения лицензии на недвижимость: полное руководство|Секреты получения лицензии на недвижимость от экспертов|Инструкция по получению лицензии на недвижимость|Лицензия на недвижимость: ключ к успеху в индустрии недвижимости|Легко получите лицензию на недвижимость с этими советами|Простой путь к получению лицензии на недвижимость|Как получить лицензию на недвижимость быстро и легко|Шаги к успешной лицензии на недвижимость|Процесс получения лицензии на недвижимость: ключевые моменты|Эффективные советы по успешному получению лицензии на недвижимость|Лицензия на недвижимость: важные аспекты для успешного получения
Real Estate Agent License in Oregon https://realestatelicensehefrsgl.com/states/oregon-island-real-estate-license/ .
https://vyzov-santehnika-na-dom.ru.
Medication information sheet. What side effects can this medication cause?
where can i get ziprasidone pill
Best about medicament. Get now.
Всем привет! Может кто знает, где найтиразные блоги о недвижимости? Сейчас читаю https://floor-ashton.ru
мунджаро купить +в аптеке – mounjaro купить +в турции, tirzepatide цена
Medicines information. Cautions.
how can i get cheap anastrozole
All about drug. Read information here.
I really love to read such an excellent article. Helpful article. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Всем привет! Подскажите, где почитатьразные статьи о недвижимости? Сейчас читаю https://gismt72.ru
bocor88
bocor88
I truly enjoy examining on this site, it holds fantastic blog posts.
Ищете турецкие сериалы новинки онлайн? Добро пожаловать на turkhit.tv! Мы лидируем в Google и Yandex благодаря нашему широкому выбору свежих сериалов. Каждый день добавляются новые серии, все в HD качестве и с отличной русской озвучкой.
У нас нет назойливой рекламы, что делает просмотр комфортным и приятным. Разнообразие жанров, удобный интерфейс и постоянные обновления – всё это ждет вас на turkhit.tv. Присоединяйтесь и наслаждайтесь новейшими турецкими сериалами!
Thank you great posting about essential oil. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Drugs information sheet. Drug Class.
where can i buy cheap cialis soft no prescription
Actual information about medicament. Get information here.
Приветствую. Может кто знает, где почитатьразные блоги о недвижимости? Пока нашел https://kait-volga.ru
Приветствую. Может кто знает, где найтиразные блоги о недвижимости? Пока нашел https://kaluga-elite.ru
Хотите быть в курсе всех важных тем в мире недвижимости?
На нашем сайте вы найдете множество полезных статей о [url=https://starextorg.ru]квартирах от застройщика[/url], а также о [url=https://starextorg.ru]регистрации квартиры[/url].
Узнайте все, что вам нужно для успешных сделок и принятия важных решений в сфере недвижимости.
Drug prescribing information. Short-Term Effects.
order synthroid pill
Some trends of pills. Get here.
https://Dr-Nona.ru – Доктор нона
Приветствую. Может кто знает, где почитатьразные блоги о недвижимости? Пока нашел https://kmzperm.ru
Секс-работа в городе Москве существует как запутанной и сложноустроенной проблемой. Хотя это запрещается правилами, данная сфера является существенным нелегальным сектором.
Контекст в прошлом
В Союзные времена секс-работа существовала незаконно. После распада Советской империи, в условиях рыночной нестабильной ситуации, секс-работа оказалась более заметной.
Современная обстановка
В настоящее время коммерческий секс в городе Москве представляет собой различные формы, от элитных эскорт-услуг и заканчивая уличного уровня секс-работы. Высококлассные услуги обычно осуществляются через сеть, а улицы проституция сосредоточена в конкретных областях городской территории.
Социально-экономические аспекты
Множество женщины вступают в эту деятельность вследствие материальных неурядиц. Интимные услуги может быть интересной из-за шансом мгновенного заработка, но эта деятельность влечет за собой вред для здоровья и жизни.
Правовые Вопросы
Интимные услуги в России нелегальна, и за эту деятельность организацию состоят серьезные штрафы. Коммерческих секс-работников часто задерживают к дисциплинарной вине.
Таким способом, невзирая на запреты, коммерческий секс существует как сегментом теневой экономики российской столицы с существенными социально-правовыми последствиями.
Drugs prescribing information. Effects of Drug Abuse.
how to buy cheap levaquin for sale
Some information about meds. Read information now.
Приветствую. Подскажите, где почитатьполезные блоги о недвижимости? Пока нашел https://kmzperm.ru
Medicine information sheet. Effects of Drug Abuse.
can you get cheap fluvoxamine for sale
Actual news about medicament. Read information now.
Приветствую. Может кто знает, где найтиполезные блоги о недвижимости? Пока нашел https://kovry159.ru
Всем привет)
Будучи студентом, я наслаждался учебой до тех пор, пока не пришло время писать диплом. Но паниковать не стоило, ведь существуют компании, которые помогают с написанием и защитой диплома на отличные оценки!
Изначально я искал информацию по теме: купить диплом строителя, купить диплом в ленинск-кузнецком, старые дипломы купить, купить диплом средне техническое, купить диплом вуза, затем наткнулся на https://forum.qwas.ru/prodaja-podlinnih-diplomov-poluchite-kachestvennoe-obrazovani-t16253.html, где все мои учебные вопросы были решены!
Удачи!
Medicament information for patients. Brand names.
cost of lyrica generic
All information about drug. Get information now.
Lottery Defeater Software: What is it? Lottery Defeater Software is a completely automated plug-and-play lottery-winning software. The Lottery Defeater software was developed by Kenneth.
Ищете, где посмеяться от души? Заходите на turklife.tv и смотрите турецкие сериалы комедии! Здесь собраны самые смешные и популярные комедийные сериалы в HD 1080 качестве с профессиональной русской озвучкой. Удобное разделение по жанрам и годам позволяет легко найти нужный сериал.
Каждый день появляются новые серии, и всё это абсолютно бесплатно и без рекламы. Turklife.tv – ваш идеальный выбор для просмотра турецких комедий. Присоединяйтесь и наслаждайтесь лучшими комедиями прямо сейчас!
Привет Друзья!
Всегда думал что купить диплом о высшем образовании это миф и нереально, но все оказалось не так, изначально искал информацию про: купить диплом магистра, купить диплом во владимире, купить диплом в рубцовске, купить диплом в дербенте, купить диплом в ижевске, потом про дипломы вузов, подробнее здесь https://www.globemw.net/%d0%ba%d1%83%d0%bf%d0%b8%d1%82%d1%8c-%d0%b4%d0%b8%d0%bf%d0%bb%d0%be%d0%bc-%d0%bc%d0%b3%d0%b8%d0%bc%d0%be-%d0%b8%d0%bb%d0%b8-%d0%bb%d1%8e%d0%b1%d0%be%d0%b3%d0%be-%d0%b2%d1%83%d0%b7%d0%b0-%d1%80%d0%be/
Оказалось все возможно, официально со специальными условия по упрощенным программам, так и сделал и теперь у меня есть диплом вуза Москвы нового образца, что советую и вам!
Хорошей учебы!
Всем привет! Подскажите, где найтиполезные блоги о недвижимости? Сейчас читаю https://krepegmaster.ru
https://win-line.net/ווינר-ליין-ווינר-אונליין/
להעביר, תימוכין לדבריך.
ההמרה באינטרנט הפכה לנישה פופולרי מאוד בשנים האחרונות, המכיל אפשרויות מגוונות של אופציות משחק, לדוגמה משחקי פוקר.
בסקירה זה נסקור את תופעת ההתמודדות המקוונת ונייעץ לכם נתונים חשובים שיתרום לכם לנתח בתופעה מרתק זה.
הימורי ספורט – הימורים באינטרנט
הימורי ספורט מכיל אלטרנטיבות רבות של אירועים קלאסיים כגון רולטה. ההתמודדות באינטרנט מספקים למבקרים לחוות מחווית משחק אותנטית בכל עת ומקום.
המשחקים תיאור קצר
מכונות מזל משחקי מזל עם גלגלים
הימורי רולטה הימור על פרמטרים על גלגל מסתובב
משחק הקלפים בלאק ג’ק משחק קלפים בו המטרה היא 21 נקודות
פוקר משחק קלפים מורכב
באקרה משחק קלפים מהיר וקצר
התמרמרות ספורטיבית – התמודדות באינטרנט
הימורים על אירועי ספורט מייצגים אחד האזורים המתפתחים המרכזיים ביותר בפעילות באינטרנט. משתתפים מורשים לסחור על ביצועים של משחקי ספורט מבוקשים כגון טניס.
ההימורים ניתן לתמוך על תוצאת התחרות, מספר האירועים ועוד.
סוג הפעילות תיאור משחקי ספורט מרכזיים
ניחוש תוצאה ניחוש התוצאה הסופית של המשחק כדורגל, כדורסל, אמריקאי
הפרש תוצאות ניחוש ההפרש בתוצאות בין הקבוצות כל ענפי הספורט
מספר שערים/נקודות ניחוש כמות הסקורים בתחרות כדורגל, כדורסל, טניס
הצד המנצח ניחוש מי יהיה הזוכה (ללא קשר לתוצאה) כל ענפי הספורט
הימורים דינמיים הימורים במהלך המשחק בזמן אמת כדורגל, טניס, הוקי
התמרמרות מגוונת שילוב של מספר פעילויות מרבית ענפי הספורט
משחקי קלפים אונליין – התמודדות באינטרנט
פעילות פוקר מקוונת מהווה אחד מענפי הקזינו הפופולריים המשפיעים ביותר בשנים האחרונות. משתתפים מורשים להשתתף כנגד שחקנים אחרים מכל רחבי הכדור הארצי במגוון
Medicament information sheet. What side effects?
can i buy zyban price
Actual news about drug. Get information now.
[url=https://muhammad-ali.com.az]muhammad ali casino[/url]
best boxer in the world Muhammad Ali
muhammad ali
Pills information. Short-Term Effects.
can you get cheap phenytoin without prescription
Best what you want to know about medicine. Get information here.
Всем привет! Может кто знает, где найтиразные статьи о недвижимости? Пока нашел https://kuler-tsentr.ru
Pills information leaflet. Cautions.
rizatriptan cost
Some about pills. Read information now.
Приветствую. Может кто знает, где найтиразные блоги о недвижимости? Пока нашел https://kuler-tsentr.ru
Drugs information for patients. Cautions.
cost cheap minocycline no prescription
All about medicament. Get now.
Loving the info on this site, you have done great job on the content.
Приветствую. Может кто знает, где почитатьполезные статьи о недвижимости? Пока нашел https://liem-com.ru
Ищете смотреть турецкие сериалы 2024 онлайн на русском языке? На turkhit.tv вы найдете всё, что вам нужно! Бесплатный доступ к новинкам 2024 года в HD качестве и с отличной русской озвучкой, множество жанров и сезонов.
Каждый день на сайте появляются новые серии, позволяя вам быть в курсе всех новинок. Всё, что вы ждали, уже доступно на русском языке. Заходите на turkhit.tv и наслаждайтесь лучшими турецкими сериалами 2024 года без лишних хлопот и рекламы!
Drugs information sheet. Generic Name.
where can i buy levonorgestrel no prescription
All trends of pills. Get information now.
Приветствую. Подскажите, где почитатьполезные статьи о недвижимости? Сейчас читаю https://oscltd.ru
Medicament prescribing information. What side effects?
cost of cheap nortriptyline prices
Actual trends of meds. Read here.
Drug information for patients. What side effects?
buy generic prevacid without a prescription
All what you want to know about drugs. Read here.
Всем привет! Может кто знает, где почитатьполезные блоги о недвижимости? Сейчас читаю https://ppu-odk.ru
Pills information. Drug Class.
how to buy generic oxcarbazepine without insurance
Actual trends of medicament. Read information here.
[b]Здравствуйте[/b]!
Задался вопросом: можно ли на самом деле купить диплом государственного образца в Москве? Был приятно удивлен — это реально и легально!
Сначала искал информацию в интернете на тему: купить диплом строителя, купить диплом воспитателя, купить диплом электрика, купить диплом монтажника, купить диплом в артеме и получил базовые знания. В итоге остановился на материале: https://bookmarkleader.com/story17326005/%D0%BF%D0%BE%D0%BB%D1%83%D1%87%D0%B8%D1%82%D1%8C-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC-%D1%8D%D0%BA%D1%81%D0%BF%D0%B5%D1%80%D1%82%D0%B0
Хорошей учебы!
[url=https://muhammad-ali.com.az]muhammad ali apk[/url]
best boxer in the world Muhammad Ali
muhammad ali
Drug prescribing information. What side effects?
cost generic levaquin pills
All what you want to know about medicament. Get information here.
Я большой поклонник турецких сериалов, и недавно друзья в соцсетях порекомендовали сайт turklife.tv. Здесь можно турецкие сериалы 2024 смотреть бесплатно и без регистрации. На сайте много жанров, а сериалы удобно разбиты по годам.
Качество видео всегда на высоте, HD 1080, и русская озвучка просто отличная. Каждое утро я нахожу новые серии любимых сериалов. Turklife.tv – это идеальное место для всех любителей турецких сериалов, включая меня!
Всем привет! Может кто знает, где почитатьполезные статьи о недвижимости? Сейчас читаю https://redglade-nn.ru
Meds prescribing information. Cautions.
cost generic abilify without rx
All information about medicines. Read here.
https://win-line.net/קזינו-אונליין-ישראל/
להגיש, ראיה לדבריך.
ההתמודדות באינטרנט הפכה לענף מושך מאוד לאחרונה, המספק מבחר רחב של אלטרנטיבות הימורים, לדוגמה קזינו אונליין.
במאמר זה נפרט את תופעת הקזינו המקוון ונמסור לכם פרטים חשובים שיסייע לכם לנתח בתופעה מרתק זה.
קזינו אונליין – קזינו באינטרנט
משחקי פוקר מאפשר אופציות שונות של פעילויות מסורתיים כגון רולטה. הפעילות באינטרנט נותנים למשתתפים להשתתף מאווירת הימורים אותנטית מכל מקום ובכל זמן.
האירוע פירוט קצר
מכונות שלוט הימורים עם גלגלים
גלגל הרולטה הימור על מספרים וצבעים על גלגל מסתובב
משחק הקלפים בלאק ג’ק משחק קלפים בו המטרה היא 21 נקודות
פוקר משחק קלפים מבוסס אסטרטגיה
התמודדות בבאקרה משחק קלפים מהיר וקצר
הימורי ספורט – פעילות באינטרנט
הימורי ספורט מהווים חלק מ אחד התחומים המשגשגים ביותר בקזינו באינטרנט. שחקנים יכולים להתמודד על תוצאות של אתגרי ספורט מושכים כגון כדורגל.
ההימורים ניתן לתמוך על תוצאת התחרות, מספר השערים ועוד.
אופן ההתמודדות ניתוח ענפי ספורט נפוצים
ניחוש התפוקה ניחוש הביצועים הסופיים בתחרות כדורגל, כדורסל, אמריקאי
הפרש סקורים ניחוש הפרש הנקודות בין הקבוצות כדורגל, כדורסל, אמריקאי
כמות התוצאות ניחוש כמות התוצאות בתחרות כדורגל, כדורסל, הוקי קרח
הצד המנצח ניחוש מי יזכה בתחרות (ללא קשר לביצועים) מספר ענפי ספורט
התמרמרות בזמן אמת הימורים במהלך המשחק בזמן אמת מגוון ענפי ספורט
התמרמרות מגוונת שילוב של מספר הימורים שונים מגוון ענפי ספורט
התמודדות בפוקר מקוון – קזינו באינטרנט
פעילות פוקר מקוונת הוא אחד מסוגי הפעילות המובילים המובהקים ביותר כיום. משתתפים יכולים להתמודד מול שחקנים אחרים מרחבי הגלובוס במגוון
Medicines information. Generic Name.
donde conseguir precios genericos de flibanserina
Best about drug. Read information here.
Приветствую. Может кто знает, где почитатьполезные блоги о недвижимости? Сейчас читаю https://santam1.ru
Здравствуйте!
Хочу поделиться своим опытом по заказу аттестата ПТУ. Думал, что это невозможно, и начал искать информацию в интернете по теме: купить диплом в нефтеюганске, купить диплом биолога, купить диплом в брянске, купить диплом в ростове-на-дону, купить диплом преподавателя. Постепенно углубляясь в тему, нашел отличный ресурс здесь: https://chaosandlight.rolka.me/viewtopic.php?id=685#p12839 и остался очень доволен!
Теперь у меня есть диплом сварщика о среднем специальном образовании, и я обеспечен на всю жизнь!
Успехов в учебе!
What Is ZenCortex? ZenCortex is a natural supplement that promotes healthy hearing and mental tranquility. It’s crafted from premium-quality natural ingredients, each selected for its ability to combat oxidative stress and enhance the function of your auditory system and overall well-being.
Medication information. Cautions.
can i purchase divalproex price
Everything trends of medication. Get information now.
Всем привет! Может кто знает, где почитатьполезные статьи о недвижимости? Сейчас читаю https://sibarit54.ru
Коммерческий секс в городе Москве существует как комплексной и многоаспектной вопросом. Невзирая на это противозаконна правилами, эта деятельность остаётся важным нелегальным сектором.
Контекст в прошлом
В советские эру коммерческий секс процветала нелегально. После Союза, в ситуации финансовой нестабильной ситуации, эта деятельность стала быть более видимой.
Сегодняшняя Ситуация
Сейчас коммерческий секс в Москве представляет собой разные виды, начиная с высококлассных эскорт-услуг и заканчивая публичной проституции. Люксовые обслуживание зачастую организуются через сеть, а уличная интимные услуги сконцентрирована в определённых областях города.
Социальные и Экономические Аспекты
Множество представительницы слабого пола вступают в данную сферу ввиду материальных неурядиц. Коммерческий секс является интересной из-за шанса быстрого дохода, но эта деятельность влечет за собой рисками для здоровья и безопасности.
Юридические аспекты
Интимные услуги в стране запрещена, и за ее организацию существуют серьёзные меры наказания. Проституток часто привлекают к к дисциплинарной отчетности.
Таким образом, невзирая на запреты, интимные услуги является частью теневой экономики столицы с большими социально-правовыми последствиями.
Good info. Lucky me I reach on your website by accident, I bookmarked it. Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Medicament information leaflet. Generic Name.
can i buy cheap macrobid online
Best what you want to know about medication. Read here.
Приветствую. Может кто знает, где найтиполезные блоги о недвижимости? Сейчас читаю https://stroyproektm.ru
Drug information leaflet. Effects of Drug Abuse.
order singulair without prescription
All news about medicine. Read here.
[url=https://santex-service.ru]https://santex-service.ru[/url] вызов сантехника.
вызов сантехника [url=https://santex-service.ru]https://santex-service.ru[/url].
срочный вызов сантехника [url=https://santex-service.ru]https://santex-service.ru[/url].
сантехник вызов [url=https://santex-service.ru]https://santex-service.ru[/url].
[url=https://santex-service.ru]https://santex-service.ru[/url] сантехник на дом.
Medicament information leaflet. Effects of Drug Abuse.
where can i buy reglan tablets
Some news about drug. Read information now.
Приветствую. Может кто знает, где почитатьразные статьи о недвижимости? Пока нашел https://tent44.ru
Medicines information sheet. What side effects?
can i order generic plan b for sale
Best trends of meds. Read here.
Medication prescribing information. What side effects?
buying ropinirole
Some information about drugs. Get information now.
Всем привет! Подскажите, где найтиполезные статьи о недвижимости? Сейчас читаю https://universal37.ru
Здравствуйте!
Задался вопросом: можно ли на самом деле купить диплом государственного образца в Москве? Был приятно удивлен — это реально и легально!
Сначала искал информацию в интернете на тему: купить диплом электромонтажника, купить диплом в тюмени, купить диплом мастера маникюра и педикюра, купить диплом в невинномысске , купить диплом в москве и получил базовые знания. В итоге остановился на материале: http://schwerkraft.net/contact/#comment-33331
Успешной учебы!
Medicines information leaflet. Brand names.
cheap indomethacin without rx
Everything what you want to know about drugs. Get now.
Pills information. Drug Class.
can i order reglan without insurance
All news about medicine. Get here.
Pills information sheet. Short-Term Effects.
can i get generic sinemet prices
All about meds. Read now.
Всем привет! Может кто знает, где почитать разные статьи о недвижимости? Пока нашел https://1eve1.ru
cost of generic caduet price
Kylian Mbappe is a French professional footballer who plays as a forward for Paris Saint-Germain and the French national team. Renowned for his speed, dribbling, and finishing, Mbappe has won numerous titles, including multiple Ligue 1 championships and the FIFA World Cup in 2018. Find out more about him here – https://kylianmbappe.paris-saint-germain-ar.com/
Drug information sheet. Effects of Drug Abuse.
seroquel xr 50 mg
Some information about medication. Read now.
Medicines information. Cautions.
dutasteride no prescription
Everything information about drug. Get here.
Kylian Mbappe is a French professional footballer who plays as a forward for Paris Saint-Germain and the French national team. Renowned for his speed, dribbling, and finishing, Mbappe has won numerous titles, including multiple Ligue 1 championships and the FIFA World Cup in 2018. Find out more about him here – https://kylianmbappe.paris-saint-germain-ar.com/
Приветствую. Может кто знает, где почитать полезные статьи о недвижимости? Пока нашел https://1eve1.ru
call centers bpo
Ways Could A Outsourcing Firm Secure At A Minimum Of One Transaction From Ten Appointments?
Outsourcing firms might enhance their conversion rates by concentrating on a several important approaches:
Understanding Customer Requirements
Ahead of meetings, conducting detailed research on prospective clients’ companies, issues, and unique requirements is crucial. This preparation enables BPO organizations to tailor their solutions, making them more enticing and pertinent to the customer.
Transparent Value Offer
Providing a compelling, convincing value statement is crucial. Outsourcing firms should highlight the ways in which their offerings provide cost reductions, improved efficiency, and expert skills. Evidently demonstrating these advantages assists customers comprehend the measurable value they would receive.
Building Reliability
Trust is a key element of successful sales. BPO companies might create trust by showcasing their track record with case examples, endorsements, and industry credentials. Verified success narratives and endorsements from satisfied customers might notably enhance credibility.
Productive Follow-Up
Steady follow-up subsequent to sessions is crucial to keeping interaction. Customized follow through messages that recap important subjects and address any questions enable maintain client interest. Employing customer relationship management tools guarantees that no potential client is overlooked.
Unconventional Lead Generation Approach
Innovative strategies like content marketing can establish outsourcing organizations as industry leaders, drawing in potential clients. Networking at sector events and leveraging social media platforms like business social media might extend impact and create valuable contacts.
Advantages of Contracting Out IT Support
Contracting Out IT support to a outsourcing organization could lower spending and provide availability of a skilled workforce. This allows businesses to concentrate on core functions while maintaining top-notch support for their clients.
Application Development Best Practices
Implementing agile methodologies in software development ensures faster completion and step-by-step advancement. Interdisciplinary teams improve collaboration, and continuous feedback assists identify and resolve challenges early.
Relevance of Individual Employee Brands
The personal brands of staff boost a outsourcing firm’s trustworthiness. Known industry experts within the firm pull in customer confidence and increase a positive image, helping with both client acquisition and talent retention.
Global Impact
These tactics help outsourcing organizations by driving efficiency, boosting client relationships, and fostering Ways Can A Outsourcing Organization Secure At A Minimum Of One Transaction From Ten Appointments?
Outsourcing companies could boost their conversion conversion rates by focusing on a several important approaches:
Grasping Customer Requirements
Before appointments, carrying out detailed investigation on possible customers’ companies, pain points, and particular requirements is essential. This readiness enables outsourcing companies to tailor their offerings, thereby making them more enticing and pertinent to the client.
Clear Value Proposition
Presenting a clear, compelling value offer is crucial. BPO organizations should highlight how their offerings provide cost reductions, improved effectiveness, and niche expertise. Clearly illustrating these benefits assists customers understand the measurable benefit they would receive.
Creating Reliability
Trust is a cornerstone of successful transactions. BPO firms can create reliability by showcasing their track record with case examples, endorsements, and market certifications. Demonstrated success accounts and testimonials from satisfied customers can significantly strengthen reputation.
Effective Post-Meeting Communication
Consistent follow-up following appointments is key to retaining engagement. Personalized follow through communications that reiterate important discussion points and answer any queries enable keep the client interested. Employing CRM tools makes sure that no lead is overlooked.
Innovative Lead Generation Approach
Original tactics like content marketing might place BPO organizations as industry leaders, attracting potential clients. Interacting at market events and leveraging online platforms like business social media could extend reach and create important contacts.
Pros of Outsourcing IT Support
Delegating IT support to a BPO firm could reduce costs and provide availability of a talented workforce. This allows enterprises to prioritize core functions while ensuring top-notch service for their users.
Application Development Best Practices
Embracing agile methodologies in application development guarantees more rapid deployment and iterative progress. Multidisciplinary teams improve collaboration, and continuous feedback aids detect and resolve issues early.
Relevance of Employee Personal Brands
The individual brands of staff improve a BPO firm’s reputation. Recognized industry experts within the organization pull in client trust and contribute to a positive reputation, aiding in both client acquisition and talent retention.
Worldwide Impact
These methods aid BPO companies by pushing efficiency, enhancing customer relations, and fostering
Kylian Mbappe is a French professional footballer who plays as a forward for Paris Saint-Germain and the French national team. Renowned for his speed, dribbling, and finishing, Mbappe has won numerous titles, including multiple Ligue 1 championships and the FIFA World Cup in 2018. Find out more about him here – https://kylianmbappe.paris-saint-germain-ar.com/
Секреты ухода за зубами, рекомендуем.
Современные технологии в стоматологии, эффективный уход за зубами.
Эффективные способы обезболивания, предлагаем.
Мифы о стоматологии, в которые верят все, эффективные советы стоматолога.
Секреты крепких и белоснежных зубов, предлагаем.
Как выбрать хорошего стоматолога, профессиональные методики стоматологии.
Как правильно чистить зубы: секреты здоровой улыбки, ознакомиться.
стоматологія зуби стоматологія зуби .
Drug information for patients. Brand names.
how to buy promethazine
Some information about pills. Read now.
Всем привет! Может кто знает, где найти полезные статьи о недвижимости? Сейчас читаю https://an72.ru
Привет, друзья!
Всегда считал, что покупка диплома о высшем образовании — это миф. Но, оказалось, что все возможно! Сначала искал информацию по теме: купить диплом педагога, купить диплом в воронеже, купить диплом в вольске, купить новый диплом, купить диплом для иностранцев, а затем перешел на дипломы вузов. Подробнее можно узнать здесь: http://38.104.231.181/doku.php?id=landsdiploms
Оказалось, что все возможно и официально, с упрощенными программами обучения. Теперь у меня диплом московского вуза нового образца, и я рекомендую вам воспользоваться этим шансом!
Удачи!
Проститутки Тюмени
Всем привет! Может кто знает, где найти полезные блоги о недвижимости? Сейчас читаю https://armid44.ru
Секреты ухода за зубами, изучить.
Уникальные методики лечения зубов, качественный уход за зубами.
Эффективные способы обезболивания, предлагаем.
Самые популярные заблуждения о зубах, эффективные советы стоматолога.
Секреты крепких и белоснежных зубов, рекомендуем.
Лечение зубов без боли: реальность или миф?, профессиональные методики стоматологии.
Как избежать неприятного запаха изо рта, прочитать.
дитяча стоматологія дитяча стоматологія .
toto 4d
Всем привет! Может кто знает, где почитать полезные блоги о недвижимости? Пока нашел https://azimut-irkutsk.ru
Секреты ухода за зубами, предлагаем.
Уникальные методики лечения зубов, качественный уход за зубами.
Основные причины зубной боли, ознакомиться.
Что нужно знать о здоровье полости рта, профессиональные советы стоматолога.
Как сохранить здоровье зубов на долгие годы, изучить.
Как выбрать хорошего стоматолога, профессиональные методики стоматологии.
Как избежать неприятного запаха изо рта, советуем.
послуги стоматології послуги стоматології .
Индивидуалки Тюмень
Секреты ухода за зубами, советуем.
Современные технологии в стоматологии, качественный уход за зубами.
Эффективные способы обезболивания, ознакомиться.
Что нужно знать о здоровье полости рта, профессиональные советы стоматолога.
Как избежать проблем с зубами, ознакомиться.
Лечение зубов без боли: реальность или миф?, эффективные методики стоматологии.
Как правильно чистить зубы: секреты здоровой улыбки, ознакомиться.
якісна стоматологія https://klinikasuchasnoistomatologii.vn.ua/ .
Всем привет! Может кто знает, где почитать полезные статьи о недвижимости? Пока нашел https://ecn-novodom.ru
Medication prescribing information. Drug Class.
lisinopril without precription
Actual about medication. Read information now.
Проститутки Тюмени
Приветствую. Подскажите, где найти разные статьи о недвижимости? Пока нашел https://germes-alania.ru
Drugs information for patients. Cautions.
cheap estradiol price
Actual news about medication. Read here.
where to get cheap cabgolin pill
This is very interesting, You’re a very skilled blogger. I’ve joined your rss feed and look forward to seeking more of your magnificent post. Also, I have shared your web site in my social networks!
https://win-line.net/rabet777-ראבט777/
להעביר, תימוכין לדבריך.
ההמרה באינטרנט הפכה לענף נחשק מאוד לאחרונה, המספק אפשרויות שונות של אפשרויות התמודדות, החל מ הימורי ספורט.
בסקירה זה נבדוק את עולם ההימורים המקוונים ונמסור לכם פרטים חשובים שיתרום לכם לחקור בתחום מעניין זה.
הימורי ספורט – הימורים באינטרנט
הימורי ספורט מאפשר מבחר מגוון של אירועים מוכרים כגון בלאק ג’ק. ההימורים באינטרנט מאפשרים למבקרים להשתתף מחווית הימורים אותנטית מכל מקום.
המשחקים סיכום קצר
מכונות מזל הימורים עם גלגלים
רולטה הימור על תוצאות על גלגל מסתובב
בלאק ג’ק משחק קלפים בו המטרה היא 21 נקודות
התמודדות בפוקר משחק קלפים מורכב
משחק קלפים באקרה משחק קלפים פשוט וזריז
הימורים על אירועי ספורט – התמודדות באינטרנט
הימורי ספורט מהווים אחד האזורים המשגשגים הגדולים ביותר בהימורים באינטרנט. שחקנים רשאים לסחור על ביצועים של אירועי ספורט מושכים כגון ועוד.
השקעות ניתן לתמוך על תוצאת התחרות, מספר הנקודות ועוד.
אופן ההתמודדות פירוט משחקי ספורט מרכזיים
ניחוש תוצאה ניחוש הביצועים הסופיים בתחרות כדורגל, כדורסל, אמריקאי
הפרש סקורים ניחוש ההפרש בביצועים בין הקבוצות כל ענפי הספורט
כמות הביצועים ניחוש כמות הביצועים בתחרות כדורגל, כדורסל, הוקי קרח
הצד המנצח ניחוש מי יסיים ראשון (ללא קשר לניקוד) מגוון ענפי ספורט
הימורי חי הימורים במהלך המשחק בזמן אמת כדורגל, טניס, קריקט
הימורים משולבים שילוב של מספר סוגי התמרמרות מספר ענפי ספורט
פוקר אונליין – פעילות באינטרנט
התמודדות בפוקר מקוון מכיל אחד ממשחקי ההימורים המשגשגים הגדולים ביותר בשנים האחרונות. משתתפים מורשים להשקיע עם מתמודדים אחרים מאזורי הגלובליזציה במגוון
Medicine information for patients. Short-Term Effects.
buying generic zocor pill
All information about drugs. Read here.
באקרה
Drugs information sheet. Effects of Drug Abuse.
where to get cheap ropinirole prices
Actual news about medicines. Read here.
I genuinely enjoy reading through on this internet site, it contains great articles. “Words are, of course, the most powerful drug used by mankind.” by Rudyard Kipling.
Medication information for patients. Cautions.
where can i buy generic abilify
Best information about medication. Read information now.
Exceptional post however , I was wondering if you could write a litte more on this topic? I’d be very thankful if you could elaborate a little bit further. Bless you!
get deltasone pills
[url=https://sps134.ru]https://sps134.ru[/url] вызов сантехника.
вызов сантехника [url=https://sps134.ru]https://sps134.ru[/url].
срочный вызов сантехника [url=https://sps134.ru]https://sps134.ru[/url].
сантехник вызов [url=https://sps134.ru]https://sps134.ru[/url].
[url=https://sps134.ru]https://sps134.ru[/url] сантехник на дом.
[url=https://sps134.ru]https://sps134.ru[/url] сантехнические работы.
[url=https://sps134.ru]https://sps134.ru[/url] сантехнические услуги.
сантехнические работы вызвать мастера [url=https://sps134.ru]https://sps134.ru[/url] .
мастер сантехник [url=https://sps134.ru]https://sps134.ru[/url] .
Drug information for patients. Effects of Drug Abuse.
get cheap lyrica without a prescription
Actual information about drugs. Get now.
Если хотите смотреть турецкие сериалы на русском языке онлайн, заходите на turkhit.tv. Здесь ежедневно добавляются новые серии, все в отличном качестве с идеальной русской озвучкой. Вас ждет разнообразие жанров: драмы, комедии, боевики и фэнтези. Платформа удобна в использовании и не содержит назойливой рекламы.
Вы сможете наслаждаться как новыми, так и популярными сериалами, такими как “Основание Осман” и “Кровавые цветы”. Сайт не требует регистрации и оплаты, что делает просмотр еще более приятным. Посетите turkhit.tv и погружайтесь в мир турецких сериалов.
borju89 link alternatif
ремонт телефонов рядом
Meds information for patients. What side effects?
where buy cheap phenytoin online
Everything what you want to know about medicament. Get here.
본즈 카지노 앱을 다운로드하여 모바일에서 게임을 즐기세요. BONS CASINO 더 많은 혜택을 누리세요. BONS모바일 앱으로 언제 어디서나 게임을 즐길 수 있습니다. 손쉽게 사용할 수 있는 인터페이스로 게임을 더욱 편리하게 즐길 수 있습니다. bons카지노
Bons Casino는 간편한 로그인 절차와 다양한 보너스를 제공합니다. 본즈에 가입하고 본즈 보너스 코드를 입력하여 추가 혜택을 누리세요. 슬롯 게임도 다양하게 제공되어 선택의 폭이 넓습니다. Bons Casino는 항상 새로운 보너스와 이벤트를 준비하고 있어 지루할 틈이 없습니다. 또한, 정기적으로 업데이트되는 프로모션을 통해 더 많은 보상을 받을 수 있습니다. https://derekpowens.com/login/
cost generic avodart without prescription
ремонт мобильных телефонов в москве рядом
I really love to read such an excellent article. Helpful article. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
ремонт мобильных телефонов рядом
Drug information. Short-Term Effects.
where to get generic xenical without insurance
All about medicament. Read now.
Откройте тайны берців зсу, значение, освойте, истории, рассмотрите, загляните в, найдите, энергией, изучите, в мир, анатомію, значення
військові берці зсу військові берці зсу .
Drug prescribing information. What side effects can this medication cause?
where can i buy generic allegra pills
Some trends of medicament. Get now.
Погрузитесь в мир берців зсу, Почему берці зсу так важны для культуры?, изучите, погрузитесь в, тайны, сакральное значение, Берці зсу: сакральное оружие, погрузитесь, Берці зсу: подвиги и традиции, в душу, освійте, значення
берці тактичні зсу берці тактичні зсу .
Medicines information for patients. Generic Name.
how to buy norvasc without insurance
Best information about medicament. Get information now.
how to buy caduet
Medicines information. What side effects?
se puede conseguir flibanserina generico sin seguro
Best information about drug. Get here.
Medication information. Cautions.
can you get colchicine
Best information about drug. Read here.
Medicament information leaflet. Cautions.
can i order minocycline pill
All news about meds. Read information here.
Высокий профессионализм и чуткое отношение сотрудников https://complex-ritual.ru/. В тяжелый период они окружили нас заботой и вниманием, взяв на себя все организационные вопросы. Качественные услуги за умеренную плату. Советую эту компанию всем, кто ищет надежного ритуального партнера в Казани.
Medicament information for patients. Long-Term Effects.
cost generic cardizem without a prescription
All about medication. Get information now.
Защо да пазарувате при нашият онлайн магазин?
Богат номенклатура
Ние доставяме разнообразен разнообразие от резервни части и аксесоари за таблети.
Изгодни ценови условия
Ценовите предложения са изключително конкурентоспособни на деловата среда. Ние работим да доставяме висококачествени стоки на най-ниските ставки, за да получите най-доброто съотношение за вашите пари.
Бърза логистично обслужване
Всички Ваши заявки осъществени до предобедните часове се изпращат и получавате бързо. Така осигуряваме, че ще се сдобиете с търсените резервни части максимално най-бързо.
Прецизно пазаруване
Нашият онлайн магазин е проектиран да бъде интуитивен за ориентиране. Вие имате възможност да търсите стоки по модел, което улеснява идентифицирането на подходящия продукт за вашите изисквания.
Съдействие на високо качество
Нашият персонал с необходимата експертиза непрекъснато на готовност, за да помогнат на клиентските запитвания и да насътрудничат да идентифицирате подходящите продукти според вашите изисквания. Ние се стремим да постигнем непрекъснато грижа, за да останете щастливи от покупката си с нас.
Основна номенклатура:
Фабрични дисплеи за мобилни устройства: Гарантирани екрани, които гарантират превъзходно визуализация.
Резервни части за мобилни устройства: От захранващи източници до други компоненти – желаните за поддръжката на вашия таблет.
GSM сервиз: Компетентни ремонтни дейности за ремонт на вашата техника.
Спомагателни артикули за мобилни устройства: Богата гама от зарядни устройства.
Компоненти за електронни комуникации: Пълната гама аксесоари за модификация на Потребителски системи.
Предпочетете към нас за Необходимите изисквания от аксесоари за портативни устройства, и получете максимум на надеждни продукти, конкурентни цени и непрекъснато обслужване.
After all, what a great site and informative posts, I will upload inbound link – bookmark this web site? Regards, Reader.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Thank you great posting about essential oil. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Meds prescribing information. What side effects can this medication cause?
where buy generic aldactone pills
Everything trends of drugs. Read now.
Medicament information. Cautions.
how to get cheap coumadin for sale
Actual trends of drug. Get information here.
Medicine information leaflet. Cautions.
buying generic paxil online
All news about medicament. Read here.
https://e-porn.net free xxx tube videos webcams dating,
онлайн камеры, знакомства
Ваша любовь к загадкам и тайнам найдет удовлетворение на turkishclub.tv, где доступны турецкие сериалы детективы. Здесь каждый эпизод – это новое расследование, полное интриг и неожиданных поворотов. Наши сериалы в высоком 720 HD качестве и с русским переводом помогут вам погрузиться в мир детективных историй, где каждая деталь имеет значение.
Конечно, что может быть лучше, чем наслаждаться этими расследованиями без рекламы? На turkishclub.tv вы можете смотреть детективы бесплатно и без перерывов. Новые серии появляются каждый день, чтобы вы всегда были в курсе свежих событий. Откройте для себя мир турецких детективов прямо сейчас и ощутите настоящий драйв!
Thank you for great information. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
I really love to read such an excellent article. Helpful article. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
After all, what a great site and informative posts, I will upload inbound link – bookmark this web site? Regards, Reader.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Hi, just required you to know I he added your site to my Google bookmarks due to your layout. But seriously, I believe your internet site has 1 in the freshest theme I??ve came across.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Thank you for content. Area rugs and online home decor store. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Pills information leaflet. Effects of Drug Abuse.
how to buy generic sumatriptan without prescription
Some about meds. Read information now.
Medication information. What side effects?
how to buy cheap norvasc tablets
All news about medicines. Get information here.
Medicine prescribing information. Long-Term Effects.
can i get generic tolterodine online
Best trends of medicines. Read information now.
Medicine information for patients. Effects of Drug Abuse.
can i get generic keflex for sale
Everything about meds. Get now.
Drugs information for patients. What side effects can this medication cause?
buy generic ropinirole pill
Everything trends of pills. Get here.
Medicines information. Cautions.
order generic coumadin online
Actual about medication. Get information here.
Pills prescribing information. Cautions.
cost of cheap inderal
Best information about meds. Get information now.
Medicines information for patients. Cautions.
zofran price
All about pills. Read information now.
Приветствую. Может кто знает, где найти разные статьи о недвижимости? Сейчас читаю https://ste96.ru
Всем привет! Может кто знает, где почитать разные статьи о недвижимости? Сейчас читаю https://ste96.ru
Всем привет! Может кто знает, где найти разные блоги о недвижимости? Сейчас читаю https://ste96.ru
Medication information. Generic Name.
can i purchase generic zyban pills
Some news about medicine. Get information here.
can i order generic furosemide tablets
Оформете превъзходен отель веднага безотлагателно
Идеальное место за почивка с конкурентна такса
Резервирайте водещи възможности хотели и квартири прямо сейчас с гаранция на нашия обслужване заявяване. Намерете за ваша полза специални варианти и уникални промоции за заявяване настаняване по всему земен кръг. Независимо от того, планируете предприемате почивка до плаж, деловую поездку или любовен уикенд, в нашия магазин ще намерите превъзходно място для проживания.
Подлинные кадри, рейтинги и коментари
Преглеждайте реални снимки, цялостни отзиви и правдиви коментари за настаняванията. Осигуряваме обширен набор възможности настаняване, за да можете выбрать съответния, който най-пълно покрива вашите средства и изисквания дейност. Нашето обслужване осигурява достъпно и сигурност, предоставляя вам всю необходимую сведения для принятия успешен подбор.
Лекота и безопасность
Забудьте за сложните разглеждания – заявете незабавно безпроблемно и сигурно в нашия магазин, с возможностью заплащане при пристигане. Нашата система заемане лесен и безопасен, даващ Ви възможност сосредоточиться на планировании на вашето пътуване, без по детайли.
Ключови туристически дестинации мира за посещение
Найдите перфектното место за нощуване: настаняване, гостевые дома, бази – все под рукой. Более два милиона опции за Ваше решение. Инициирайте Вашето изследване: оформете места за отсядане и откривайте водещите дестинации по всему миру! Нашата платформа осигурява най-добрите предложения за престой и богат набор дестинации за всеки степен средства.
Опознайте для себя Стария континент
Разследвайте города Европейската география за намиране на хотели. Разкрийте для себя опции за престой в Европе, от крайбрежни на Средиземном море до планински убежища в Алпийския регион. Нашите насоки ще ви насочат к лучшим оферти престой в стария регион. Безпроблемно отворете връзките ниже, чтобы найти дестинация в выбранной вами европейска държава и начать свое европейское приключение
Обобщение
Резервирайте отлично локация для отдыха по выгодной ставка безотлагателно
Оформете превъзходен мотел незабавно безотлагателно
Перфектно пункт за туризъм с атрактивна такса
Заявете най-добри оферти подслон и престой прямо сейчас с увереност на нашата обслужване заявяване. Разгледайте за ваше удоволствие неповторими предложения и специални намаления на бронирование хотели по всему миру. Независимо желаете ли вы пътуване на пляже, професионална пътуване или романтический уикенд, при нас вы найдете превъзходно място за настаняване.
Подлинные снимки, оценки и отзывы
Преглеждайте реални фотографии, детайлни ревюта и обективни отзывы за настаняванията. Осигуряваме широкий асортимент възможности отсядане, за да имате възможност подберете съответния, който най-пълно отговаря вашите бюджет и стилю путешествий. Нашето обслужване предоставя достъпно и доверие, осигурявайки Ви цялата нужна подробности для принятия правильного решения.
Простота и надеждност
Отхвърлете за сложните поисках – забронируйте сейчас удобно и безопасно в нашата компания, с избор плащане в настаняването. Наш процесс заемане лесен и надежден, даващ Ви възможност да се отдадете върху планирането на вашето пътуване, без необходимост в тях.
Водещи туристически дестинации земното кълбо за посещение
Найдите перфектното обект для проживания: хотели, вили, хостелы – всичко наблизо. Над 2 000 000 възможности на ваш выбор. Инициирайте Вашето пътуване: забронируйте хотели и опознавайте най-добрите места на територията на земното кълбо! Нашето предложение предлагает водещите възможности за подслон и разнообразный номенклатура оферти за всеки вид средства.
Опознайте для себя Стария континент
Разглеждайте города Европы в поисках отелей. Запознайте се обстойно варианти за настаняване на Европейския континент, от курортов на Средиземном море до планински прибежища в Алпийския регион. Наши указания ще ви доведат към подходящите възможности настаняване в континентален регион. Лесно нажмите линковете под това, с цел намиране на място за настаняване във Вашата предпочитана европейска локация и стартирайте Вашето европейско приключение
В заключение
Заявете отлично дестинация для отдыха по выгодной такса веднага
Medication information leaflet. Drug Class.
generic zoloft
Best what you want to know about pills. Get here.
Приветствую. Может кто знает, где найти разные блоги о недвижимости? Пока нашел https://kran-rdk.ru
Drugs information sheet. Brand names.
buy generic aldactone prices
All information about medicament. Read information here.
Приветствую. Может кто знает, где найти разные блоги о недвижимости? Пока нашел https://mart-posters.ru
Pills prescribing information. Brand names.
cost generic digoxin pill
Everything what you want to know about drugs. Get here.
Drug information for patients. Generic Name.
can i buy cheap risperdal for sale
Best information about medicines. Read now.
Приветствую. Может кто знает, где найти полезные статьи о недвижимости? Пока нашел https://metrazhi-omsk.ru
Drug information sheet. Generic Name.
puedo conseguir flibanserina a la venta
Everything information about medicament. Read now.
Приветствую. Может кто знает, где найти полезные статьи о недвижимости? Пока нашел https://mik-dom.ru
Medication information for patients. Generic Name.
can i purchase cheap elavil tablets
Everything what you want to know about medicament. Read now.
Pills information for patients. Drug Class.
can you buy cheap levitra without prescription
All news about medicament. Read information now.
Приветствую. Может кто знает, где почитать полезные блоги о недвижимости? Пока нашел https://miro-teh-ural.ru
Hi! what is a reputable pharmacy excellent web site.
tuan88
buy motilium without insurance
Drugs prescribing information. What side effects can this medication cause?
cost of generic propecia online
Some information about meds. Read information now.
Приветствую. Может кто знает, где найти разные блоги о недвижимости? Сейчас читаю https://mzhk-stroy.ru
Medicament information sheet. Short-Term Effects.
generique zoloft
Best information about drugs. Get information now.
Medicines information for patients. Generic Name.
can you buy generic compazine online
Some news about medication. Read information now.
Всем привет! Подскажите, где найти разные статьи о недвижимости? Пока нашел https://nagaevodom.ru
Meds information for patients. Long-Term Effects.
where to get singulair no prescription
Some trends of meds. Get information here.
Приветствую. Может кто знает, где найти полезные статьи о недвижимости? Сейчас читаю https://potolkinomer1.ru
Drugs information for patients. Long-Term Effects.
cipro generics
All information about drugs. Read information now.
Medication information leaflet. Short-Term Effects.
cost of nolvadex online
Everything information about drug. Read here.
Приветствую. Может кто знает, где найти полезные блоги о недвижимости? Пока нашел https://promresmag.ru
Всем привет! Может кто знает, где найти разные статьи о недвижимости? Пока нашел https://santech31.ru
Medicine information leaflet. What side effects can this medication cause?
cost of generic tadacip online
All trends of meds. Read information now.
моунжаро – mounjaro, мунжаро купить +в москве
Хотите делать ставки на спорт в любое время и в любом месте? Тогда ссылка на скачивание приложения Фонбет – это именно то, что вам нужно. Приложение Фонбет предоставляет пользователям удобный интерфейс, быстрый доступ к результатам матчей и актуальным новостям из мира спорта. Скачайте приложение и начните делать ставки прямо сейчас.
Medicine information leaflet. Cautions.
where buy erythromycin without rx
Everything information about medicament. Read information now.
Приветствую. Подскажите, где найти разные статьи о недвижимости? Пока нашел https://santex-expert.ru
Drugs information for patients. Brand names.
how can i get chlorpromazine for sale
Best what you want to know about pills. Read now.
cost tetracycline without a prescription
Всем привет! Подскажите, где почитать полезные блоги о недвижимости? Сейчас читаю https://schuconvr.ru
Meds information. Brand names.
synthroid tablets
All what you want to know about medicament. Get information now.
Всем привет! Подскажите, где найти полезные статьи о недвижимости? Пока нашел https://simposad.ru
Drugs information for patients. What side effects can this medication cause?
how to get generic zoloft
Everything news about medicament. Get here.
Medicines information. Brand names.
can i get cheap imitrex prices
Some trends of medication. Read here.
Для любителей ставок на спорт, Фонбет мобильная предлагает отличное решение. Скачав это приложение, вы сможете делать ставки на различные спортивные события прямо с вашего телефона. Приложение Фонбет отличается простым и интуитивно понятным интерфейсом, а также быстрым доступом к результатам матчей и актуальным новостям из мира спорта. Откройте для себя новый уровень ставок с Фонбет.
Всем привет! Может кто знает, где почитать полезные статьи о недвижимости? Пока нашел https://smgarant.ru
Всем привет! Подскажите, где почитать разные статьи о недвижимости? Сейчас читаю https://stilnyjpol.ru
Medicine information for patients. Drug Class.
how to get cheap clozapine without a prescription
Best about meds. Get here.
Приветствую. Подскажите, где почитать полезные блоги о недвижимости? Сейчас читаю https://tc-all.ru
Medicament information for patients. Drug Class.
can i get generic promethazine prices
Some information about pills. Get here.
Приветствую. Может кто знает, где почитать полезные блоги о недвижимости? Пока нашел https://teplohod-denisdavidov.ru
Everything is very open and very clear explanation of issues. was truly information.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Магазин заготовок изо разноцветных а также чёрных металлов “STORM”
https://stormbrand.ru/
Всем привет! Подскажите, где найти разные блоги о недвижимости? Пока нашел https://titovloft.ru
colchicine description
外送茶
外送茶是什麼?禁忌、價格、茶妹等級、術語等..老司機告訴你!
外送茶是什麼?
外送茶、外約、叫小姐是一樣的東西。簡單來說就是在通訊軟體與茶莊聯絡,選好自己喜歡的妹子後,茶莊會像送飲料這樣把妹子派送到您指定的汽車旅館、酒店、飯店等交易地點。您只需要在您指定的地點等待,妹妹到達後,就可以開心的開始一場美麗的約會。
外送茶種類
學生兼職的稱為清新書香茶
日本女孩稱為清涼綠茶
俄羅斯女孩被稱為金酥麻茶
韓國女孩稱為超細滑人參茶
外送茶價格
外送茶的客戶相當廣泛,包括中小企業主、自營商、醫生和各行業的精英,像是工程師等等。在台北和新北地區,他們的消費指數大約在 7000 到 10000 元之間,而在中南部則通常在 4000 到 8000 元之間。
對於一般上班族和藍領階層的客人來說,建議可以考慮稍微低消一點,比如在北部約 6000 元左右,中南部約 4000 元左右。這個價位的茶妹大多是新手兼職,但有潛力。
不同地區的客人可以根據自己的經濟能力和喜好選擇適合自己的價位範圍,以免感到不滿意。物價上漲是一個普遍現象,受到地區和經濟情況等因素的影響,茶莊的成本也在上升,因此價格調整是合理的。
外送茶外約流程
加入LINE:加入外送茶官方LINE,客服隨時為你服務。茶莊一般在中午 12 點到凌晨 3 點營業。
告知所在地區:聯絡客服後,告訴他們約會地點,他們會幫你快速找到附近的茶妹。
溝通閒聊:有任何約妹問題或需要查看妹妹資訊,都能得到詳盡的幫助。
提供預算:告訴客服你的預算,他們會找到最適合你的茶妹。
提早預約:提早預約比較好配合你的空檔時間,也不用怕到時候約不到你想要的茶妹。
外送茶術語
喝茶術語就像是進入茶道的第一步,就像是蓋房子打地基一樣。在這裡,我們將這些外送茶入門術語分類,讓大家能夠清楚地理解,讓喝茶變得更加容易上手。
魚:指的自行接客的小姐,不屬於任何茶莊。
茶:就是指「小姐」的意思,由茶莊安排接客。
定點茶:指由茶莊提供地點,客人再前往指定地點與小姐交易。
外送茶:指的是到小姐到客人指定地點接客。
個工:指的是有專屬工作室自己接客的小姐。
GTO:指雞頭也就是飯店大姊三七茶莊的意思。
摳客妹:只負責找客人請茶莊或代調找美眉。
內機:盤商應召站提供茶園的人。
經紀人:幫內機找美眉的人。
馬伕:外送茶司機又稱教練。
代調:收取固定代調費用的人(只針對同業)。
阿六茶:中國籍女子,賣春的大陸妹。
熱茶、熟茶:年齡比較大、年長、熟女級賣春者(或稱阿姨)。
燙口 / 高溫茶:賣春者年齡過高。
台茶:從事此職業的台灣小姐。
本妹:從事此職業的日本籍小姐。
金絲貓:西方國家的小姐(歐美的、金髮碧眼的那種)。
青茶、青魚:20 歲以下的賣春者。
乳牛:胸部很大的小姐(D 罩杯以上)。
龍、小叮噹、小叮鈴:體型比較肥、胖、臃腫、大隻的小姐。
Приветствую. Подскажите, где найти полезные статьи о недвижимости? Сейчас читаю https://toadmarket.ru
Hi, just required you to know I he added your site to my Google bookmarks due to your layout. But seriously, I believe your internet site has 1 in the freshest theme I??ve came across.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Pills information for patients. Generic Name.
can i get cheap rogaine without rx
All about medicines. Read information now.
Thank you for great article. Hello Administ .Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Nice article inspiring thanks. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
After all, what a great site and informative posts, I will upload inbound link – bookmark this web site? Regards, Reader.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Thank you for great article. Hello Administ .Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
I really love to read such an excellent article. Helpful article. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Nice article inspiring thanks. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Приветствую. Может кто знает, где найти разные блоги о недвижимости? Пока нашел https://u-mechanik.ru
Thank you for great information. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Приветствую. Подскажите, где почитать разные статьи о недвижимости? Сейчас читаю https://utc96.ru
https://aoseulado.net/
Meds information for patients. What side effects?
where can i get cheap tetracycline without rx
Some about medication. Read information now.
перечень документов необходимых для оформления внж цифрового кочевника https://vnzh24.ru/
Everything is very open and very clear explanation of issues. was truly information.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Great post thank you. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Good info. Lucky me I reach on your website by accident, I bookmarked it. Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
After all, what a great site and informative posts, I will upload inbound link – bookmark this web site? Regards, Reader.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Hi, just required you to know I he added your site to my Google bookmarks due to your layout. But seriously, I believe your internet site has 1 in the freshest theme I??ve came across.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Hello! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me.Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
Thank you for content. Area rugs and online home decor store. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
диплом с занесением в реестр диплом с занесением в реестр .
можно купить диплом техникума ast-diplom.com .
Всем привет! Может кто знает, где найти разные блоги о недвижимости? Сейчас читаю https://vortex-los.ru
Nice article inspiring thanks. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
sunmory33
Glory Casino
Medicines prescribing information. Short-Term Effects.
how to get proscar
Actual about drugs. Get information now.
Для тех, кто ищет надежное приложение для ставок на спорт, ссылка предоставляет доступ к лучшему букмекерскому сервису. Скачайте приложение и наслаждайтесь удобным интерфейсом, быстрым доступом к различным спортивным событиям и возможностью делать ставки в любое время и в любом месте. Фонбет предлагает широкий выбор спортивных событий и привлекательные бонусы для своих пользователей.
Приветствую. Может кто знает, где найти разные статьи о недвижимости? Пока нашел https://yah-bomag.ru
Drugs information leaflet. Effects of Drug Abuse.
can i order aricept tablets
All information about drugs. Read now.
Glory Casino
https://aoseulado.net/
Приветствую. Подскажите, где найти разные блоги о недвижимости? Пока нашел https://yaoknaa.ru
https://aoseulado.net/
Всем привет! Подскажите, где почитать полезные блоги о недвижимости? Пока нашел https://yaoknaa.ru
Всем привет! Может кто знает, где почитать полезные блоги о недвижимости? Сейчас читаю https://yaoknaa.ru
внж по учебе в испании https://vnzh24.ru/
can you buy cheap tetracycline without insurance
Приветствую. Может кто знает, где почитать разные блоги о недвижимости? Сейчас читаю https://zt365.ru
https://www.wildberries.ru/catalog/217171028/detail.aspx
Всем привет! Подскажите, где найти разные блоги о недвижимости? Пока нашел https://astali.ru
Medicament information leaflet. Brand names.
how to get cheap rogaine without a prescription
Some about medicines. Get here.
seo москва
Всем привет! Подскажите, где почитать разные блоги о недвижимости? Сейчас читаю https://batstroimat24.ru
https://www.wildberries.ru/catalog/217171028/detail.aspx/
Medicines information sheet. Effects of Drug Abuse.
where to buy cheap neurontin without rx
Some about meds. Read information here.
[u][b] Привет, друзья![/b][/u]
Купить диплом о высшем образовании
[b]Наши специалисты предлагают[/b] быстро и выгодно заказать диплом, который выполняется на оригинальном бланке и заверен печатями, водяными знаками, подписями. Документ способен пройти любые проверки, даже при использовании профессиональных приборов. Достигайте цели максимально быстро с нашими дипломами.
[b]Где приобрести диплом по нужной специальности?[/b]
http://onlinekinospace.ru/byistroe-oformlenie-diploma-nadezhno-i-konfidentsialno
[u][b] Будем рады вам помочь![u][b].
https://www.wildberries.ru/catalog/217171028/detail.aspx
Всем привет! Подскажите, где почитать полезные блоги о недвижимости? Пока нашел https://bdrsu-2.ru
Pills information sheet. What side effects can this medication cause?
can i get generic elavil for sale
Everything trends of drugs. Get information now.
Приветствую. Может кто знает, где найти разные статьи о недвижимости? Сейчас читаю https://centro-kraska.ru
комплексное продвижение в интернете москва
заказать seo продвижение сайтов
Приветствую. Подскажите, где почитать разные статьи о недвижимости? Сейчас читаю https://cvetkrovli.ru
cost of theo 24 cr tablets
Приветствую. Может кто знает, где почитать разные статьи о недвижимости? Сейчас читаю https://deon-stroy.ru
Meds information sheet. What side effects can this medication cause?
where can i buy generic prochlorperazine pill
Actual news about drugs. Get information now.
Всем привет! Может кто знает, где почитать полезные блоги о недвижимости? Сейчас читаю https://dom-vasilevo.ru
потолки армстронг https://armstrong-ceiling24.ru/
зайти на сайт биткоин24
Meds prescribing information. Generic Name.
how can i get levitra
Best news about drug. Read information now.
Обязательно попробуйте обратиться к Mihaylov digital, их основная сфера это seo в яндекс, а также контекстная реклама.
Meds information. What side effects?
trazodone cost walmart
Everything what you want to know about medicine. Read information here.
low dose colchicine for gout
Meds information. Brand names.
buy cheap xenical without a prescription
All about medicament. Read now.
Thank you for great article. Hello Administ .Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
плиты армстронг https://armstrong-ceiling24.ru/
Drugs information sheet. Long-Term Effects.
how to get cheap esomeprazole pill
All news about medicine. Read now.
Medicine prescribing information. Drug Class.
cost of cefuroxime without rx
Best information about medication. Get information here.
плиты армстронг https://armstrong-ceiling24.ru/
этот контент электрик томск
Крайне рекомендую Mihaylov digital, их специализация это продвижение сайтов в Yandex, а еще разработка сайтов
Medicament information sheet. What side effects?
cost cheap fosamax without prescription
Actual information about medication. Read here.
Pills information for patients. Generic Name.
where to get generic lisinopril online
Actual information about medication. Read here.
Предлагаю компанию Mihaylov digital, их направление деятельности это seo в Google и Yandex, а еще контекстная реклама!
smartblip home gadgets https://smartblip.com best price
Drug information for patients. What side effects can this medication cause?
buying cheap zoloft price
Some trends of pills. Read now.
My friend advised me to study your articles. https://thatsnotmyneighbor.com And I thirst for to suggest that I really liked your idea. I choose definitely reckon this site to the bookmarks.
Medicines information for patients. Cautions.
does celebrex come in tablets
All news about meds. Get now.
Gerakl24: Профессиональная Реставрация Фундамента, Венцов, Полов и Перенос Строений
Организация Gerakl24 занимается на оказании всесторонних услуг по смене основания, венцов, покрытий и перемещению зданий в городе Красноярске и за пределами города. Наша группа опытных мастеров обещает превосходное качество исполнения всех типов восстановительных работ, будь то из дерева, каркасные, кирпичные или бетонные конструкции дома.
Преимущества услуг Gerakl24
Профессионализм и опыт:
Каждая задача осуществляются лишь опытными специалистами, с обладанием многолетний опыт в направлении строительства и реставрации домов. Наши специалисты профессионалы в своем деле и реализуют работу с максимальной точностью и вниманием к мелочам.
Полный спектр услуг:
Мы осуществляем разнообразные услуги по восстановлению и восстановлению зданий:
Смена основания: укрепление и замена старого фундамента, что гарантирует долговечность вашего здания и избежать проблем, связанные с оседанием и деформацией.
Замена венцов: восстановление нижних венцов деревянных зданий, которые обычно подвергаются гниению и разрушению.
Смена настилов: установка новых полов, что существенно улучшает внешний вид и практическую полезность.
Перемещение зданий: качественный и безопасный перенос строений на другие участки, что обеспечивает сохранение строения и избегает дополнительных затрат на строительство нового.
Работа с любыми типами домов:
Дома из дерева: восстановление и защита деревянных строений, обработка от гниения и насекомых.
Каркасные строения: усиление каркасных конструкций и замена поврежденных элементов.
Кирпичные строения: реставрация кирпичной кладки и укрепление стен.
Бетонные строения: реставрация и усиление бетонных элементов, ремонт трещин и дефектов.
Качество и прочность:
Мы используем лишь качественные материалы и передовые технологии, что обеспечивает долгий срок службы и надежность всех выполненных работ. Каждый наш проект проходят тщательную проверку качества на каждой стадии реализации.
Индивидуальный подход:
Каждому клиенту мы предлагаем индивидуальные решения, учитывающие ваши требования и желания. Мы стремимся к тому, чтобы конечный результат соответствовал ваши ожидания и требования.
Почему выбирают Геракл24?
Обратившись к нам, вы найдете надежного партнера, который берет на себя все заботы по восстановлению и ремонту вашего здания. Мы обеспечиваем выполнение всех работ в установленные сроки и с соблюдением всех строительных норм и стандартов. Выбрав Геракл24, вы можете быть спокойны, что ваше здание в надежных руках.
Мы всегда готовы проконсультировать и ответить на все ваши вопросы. Свяжитесь с нами, чтобы обсудить ваш проект и узнать больше о наших услугах. Мы поможем вам сохранить и улучшить ваш дом, сделав его уютным и безопасным для долгого проживания.
Gerakl24 – ваш партнер по реставрации и ремонту домов в Красноярске и окрестностях.
https://gerakl24.ru/передвинуть-дом-красноярск/
Medication information. Long-Term Effects.
can you get minocycline price
Best information about medicament. Read now.
диплом фармацевта с занесением в реестр дистанционного обучения asxdiplomik24.ru .
how to get mentat pill
Drug information sheet. Long-Term Effects.
order azathioprine prices
Best what you want to know about meds. Get information here.
Drug information sheet. What side effects can this medication cause?
get singulair prices
Everything information about medicine. Get information now.
Medication prescribing information. What side effects?
can i buy pioglitazone for sale
Best about drug. Read information now.
Medicines information for patients. What side effects can this medication cause?
where can i get generic cephalexin without rx
Best what you want to know about medicine. Read now.
Medicine information leaflet. Short-Term Effects.
where can i buy cheap oxcarbazepine online
Everything information about medication. Get information here.
диплом о высшем образовании государственного образца купить диплом о высшем образовании государственного образца купить .
Pills information. What side effects?
zithromax oral
Everything about medicament. Read information here.
Medicines information. Long-Term Effects.
get generic acyclovir pill
Some trends of meds. Read information here.
get prednisone no prescription
Всем привет! Может кто знает, где почитать разные блоги о недвижимости? Пока нашел https://2204000.ru
Pills information for patients. Brand names.
where buy cheap synthroid without prescription
Best what you want to know about medicine. Read information here.
Приветствую. Подскажите, где найти полезные статьи о недвижимости? Пока нашел https://adeldv.ru
Medication information for patients. Drug Class.
can i get generic dutasteride
Some trends of pills. Get here.
Приветствую. Может кто знает, где почитать разные блоги о недвижимости? Сейчас читаю https://eniseynev.ru
Pills information leaflet. What side effects can this medication cause?
can you get paxil prices
Everything information about drug. Read information here.
Приветствую. Подскажите, где почитать разные статьи о недвижимости? Сейчас читаю https://fuseitdecore.ru
Всем привет! Может кто знает, где найти разные статьи о недвижимости? Пока нашел https://galastroy-sk.ru
Medicament information leaflet. Drug Class.
where to buy cheap ampicillin for sale
Best information about medicines. Read now.
Приветствую. Подскажите, где найти разные статьи о недвижимости? Пока нашел https://ggs45.ru
Всем привет! Подскажите, где почитать полезные блоги о недвижимости? Сейчас читаю https://glwin.ru
Drugs prescribing information. What side effects?
glucophage online
Everything about medication. Read information now.
Приветствую. Подскажите, где почитать разные блоги о недвижимости? Пока нашел https://gor-bur.ru
Medicines information leaflet. Short-Term Effects.
puedes conseguir flibanserina online
Best about drug. Read information now.
Приветствую. Подскажите, где найти разные статьи о недвижимости? Сейчас читаю https://gor-bur.ru
купить медицинскую справку
купить медицинскую справку
Всем привет! Может кто знает, где почитать полезные статьи о недвижимости? Пока нашел https://hameleon1.ru
how can i get cheap valtrex without rx
Всем привет! Может кто знает, где почитать разные блоги о недвижимости? Пока нашел https://iskrb.ru
Pills prescribing information. Short-Term Effects.
buying generic nortriptyline without dr prescription
Best trends of medication. Read information now.
купить мед справку
Здравствуйте!
Где купить диплом специалиста?
bery-optom.ru/forum/?PAGE_NAME=profile_view&UID=11289
Удачи!
купить диплом в новотроицке asxdiplomik24.ru .
Привет!
Мы предлагаем быстро заказать диплом, который выполняется на оригинальном бланке и заверен мокрыми печатями, штампами, подписями должностных лиц. Данный диплом пройдет любые проверки, даже с использованием специально предназначенного оборудования. Достигайте своих целей быстро и просто с нашими дипломами.
vk.com/id734172901?w=wall734172901_627
Удачи!
Всем привет! Может кто знает, где почитать разные блоги о недвижимости? Сейчас читаю https://juzhnybereg24.ru
сделать справку
купить справку о болезни
Drug prescribing information. Short-Term Effects.
order cheap glucophage without rx
Everything news about meds. Get information here.
безопасные препараты +для похудения +для женщин – тирзепатид купить +в спб, препараты +для похудения эффективные +для женщин
купить справку
Приветствую. Может кто знает, где почитать разные статьи о недвижимости? Пока нашел https://klimat-hck.ru
Drug prescribing information. Effects of Drug Abuse.
how to buy cheap lyrica without prescription
Actual about drugs. Read now.
Всем привет! Подскажите, где почитать полезные статьи о недвижимости? Сейчас читаю https://kolahouse.ru
Если вам нужна доставка грузов между Москвой и Санкт-Петербургом, посетите сайт для получения информации о стоимости и услугах.
Новости Бреста также Брестской сфере а также слое, наиболее эксплуатационная информация: темы дня, обзоры, крайние случая а также события городка, оповещения что касается ДТП
https://elnet.by/
купить дипл diplomyx.com .
Приветствую. Может кто знает, где найти разные статьи о недвижимости? Сейчас читаю https://komdizrem.ru
Узнайте больше о доставка грузов Москва Петербург на нашем сайте и закажите услуги профессионалов.
Триколорный ярмарка новых каров обнаруживает разнонаправленную динамику цен. Одни модификации значительно упали в цене, на то время яко часть, наоборот
https://avgrodno.by/
Новости Гор и Могилева, наиболее живая информация: темы дня, обзоры, крайние действия города. https://roogorki.by/
Новинки Беларуси на Kapital.by · Каковы успехи дощечки оглашений https://kapital.by/ Совета по подбору и еще доставанию квартиры
срочно отремонтировать телефон
Всем привет! Может кто знает, где найти разные статьи о недвижимости? Пока нашел https://konditsioneri-shop.ru
where can i buy fml forte for sale
Приветствую. Подскажите, где найти полезные статьи о недвижимости? Сейчас читаю https://glatt-nsk.ru
срочный ремонт смартфонов
ремонт телефонов
ремонт телефонов рядом
Drugs information sheet. What side effects can this medication cause?
generic imodium for sale
Some what you want to know about drug. Read here.
Всё, что нужно знать о покупке аттестата о среднем образовании
frank-shkola.ru/forum/messages/forum1/topic430/message443/?result=new#message443
ремонт телефонов адреса
I regard something truly interesting about your weblog so I saved to my bookmarks.
Real excellent information can be found on website.
купить диплом о среднем образовании в курске ast-diploms.com .
починить смартфон в москве
Добрый день!
Диплом техникума купить официально с упрощенным обучением в Москве
newsbig.fotosdefrases.com/rekomendacii-po-priobreteniu-dokumenta-v-internete
https://zenit-bk-apk.ru/
bonus code Keydrop
срочный ремонт мобильных телефонов
Здравствуйте!
Наши специалисты предлагают максимально быстро приобрести диплом, который выполнен на оригинальной бумаге и заверен мокрыми печатями, штампами, подписями официальных лиц. Данный документ способен пройти лубую проверку, даже при использовании специальных приборов. Достигайте свои цели быстро и просто с нашими дипломами.
b98415ql.bget.ru/index.php?subaction=userinfo&user=yfaquvy
Успешной учебы!
приложение бк зенит
ремонт сотовых в москве рядом
Здравствуйте!
Заказать диплом о высшем образовании.
http://www.hebergementweb.org/threads/kupit-diplom-prevratite-svoi-mechty-v-realnost.1248684/
Успехов в учебе!
Привет, друзья!
Купить диплом любого университета.
azclan.ru/forums/users/iygorefremmv
Удачи!
Привет!
Купить диплом любого ВУЗа.
twikkers.nl/blogs/208073/?????????-?????-????????-?-????????????????-????????
Удачи!
Добрый день!
Заказать диплом любого ВУЗа.
http://www.tandem.edu.co/cierre-de-semestre
Успехов в учебе!
https://zenit-bk-app.ru/
Привет, друзья!
Всё, что нужно знать о покупке аттестата о среднем образовании
dom-nam.ru/index.php/forum/stroitelnye-kompanii/50337-kupit-diplom#81222
Поможем вам всегда!.
Thank you for great information. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
I really love to read such an excellent article. Helpful article. Hello Administ . Seo Paketi Skype: By_uMuT@KRaLBenim.Com -_- live:by_umut
ремонт телефонов рядом
отремонтировать телефон в москве
центр ремонта телефонов
Привет!
Мы предлагаем выгодно и быстро заказать диплом, который выполняется на оригинальной бумаге и заверен мокрыми печатями, штампами, подписями. Наш документ пройдет любые проверки, даже при помощи специфических приборов. Решайте свои задачи быстро с нашей компанией.
service-in.ru/forum/user/6215/
Успешной учебы!
Привет, друзья!
Мы изготавливаем дипломы психологов, юристов, экономистов и прочих профессий по невысоким тарифам. Цена будет зависеть от определенной специальности, года выпуска и университета. Стараемся поддерживать для покупателей адекватную ценовую политику. Важно, чтобы документы были доступны для подавляющей массы граждан.
http://www.pawsarl.es/blog/ильдус.html
Привет, друзья!
Приобрести диплом любого ВУЗа.
kome.maxbb.ru/viewtopic.php?f=22&t=2223
Meds information. Brand names.
cost of cheap ropinirole price
Some trends of pills. Read now.
Companies with high welcomelady.net levels of customer service usually have an excellent reputation and positive reviews.
Medicament information leaflet. What side effects?
where can i get minocycline pill
Best about medicine. Get now.
ремонт сотовых адреса
Meds information. Cautions.
can i buy generic levitra prices
Best trends of meds. Get now.
http://ractis.ru/forums/index.php?autocom=gallery&req=si&img=2512
Лучшие варианты лебедок для занятий спортом, которые подойдут для профессиональных тренировок.
Выберите идеальную лебедку для себя, для достижения новых спортивных целей.
Какую лебедку выбрать для оптимальных результатов, и достигнуть максимальной эффективности в тренировках.
Известные производители лебедок для спортивных занятий, которые заслужили доверие спортсменов.
Подсказки по определению размера лебедки для комфортной тренировки, и избежать травм и неприятных ощущений.
Популярные материалы для изготовления лебедок для спортивных занятий, и какой материал предпочтителен для длительной эксплуатации и безопасности.
Советы по безопасному и эффективному использованию спортивной лебедки, для успешного тренировочного процесса и предупреждения травм.
Спортивная серия лебедок https://goldenpower4x4.ru/lebedki/sportivnaya-seriya.html .
Оценка вредных условий труда
Процедура специальной оценки условий труда включает основные этапы. Первый этап – подготовка и сбор документации, затем специалисты оценивают рабочие места и идентифицируют потенциальные риски. Заключительный этап – оформление отчета, который содержит рекомендации по улучшению условий труда. СОУТ специальная оценка условий труда цена не только помогает соблюсти законодательные нормы, и улучшает доверие работников к организации.
Drug information. Cautions.
can you get generic fosamax without prescription
Best information about medication. Get information now.
Drug information. What side effects can this medication cause?
can i get zanaflex online
Everything news about pills. Get now.
https://hunting-movie.ru/gallery/image/659-reshili-snyat-zhile-na-sutki-zhdem-vas/
ремонт телефонов адреса
Medication information for patients. What side effects?
order generic glucophage pill
Some what you want to know about medicines. Read now.
Drug prescribing information. Generic Name.
how to buy generic zithromax no prescription
Best what you want to know about medication. Read information here.
Medicament prescribing information. Effects of Drug Abuse.
can you buy generic xenical prices
Everything trends of pills. Read information here.
Привет!
Мы предлагаем дипломы психологов, юристов, экономистов и любых других профессий по приятным тарифам.
weekinato.ru/diplomyi-ot-luchshih-vuzov/
Medicament information leaflet. Cautions.
how can i get zithromax tablets
Everything news about meds. Read here.
Обеспечьте конфиденциальность с резидентскими прокси, прибегнуть к этим инструментом.
Какие преимущества у резидентских прокси?, ознакомьтесь с подробностями.
Советы по выбору резидентского прокси, рекомендации для пользователей.
Для каких целей используют резидентские прокси?, ознакомьтесь с возможностями.
В чем преимущество безопасности резидентских прокси?, обзор функций безопасности.
Защита от каких угроз обеспечивает резидентский прокси?, разберем важные аспекты.
Как резидентский прокси помогает повысить эффективность?, проанализируем основные плюсы.
Как быстрее работать в сети с резидентским прокси?, рекомендации для оптимизации работы.
Каким образом ускорить процесс парсинга с помощью резидентского прокси, разбор возможностей для парсеров.
Секреты анонимности с резидентским прокси, практические шаги к безопасности онлайн.
Секреты эффективной работы в соцсетях с резидентским прокси, подробный обзор функционала.
Как сэкономить время с помощью аренды резидентского прокси?, сравним лучшие варианты.
Как использовать резидентские прокси для защиты от DDoS-атак, анализируем меры безопасности.
Почему резидентские прокси пользуются популярностью, проанализируем основные факторы.
Какие прокси лучше: резидентские или дата-центры?, подсказки для выбора.
купить резидентские прокси листы https://rezidentnieproksi.ru/ .
Привет, друзья!
Приобретение диплома ВУЗа с сокращенной программой обучения в Москве.
Приобрести диплом о высшем образовании.
gaeloxeparo.lucialpiazzale.com/podrobnoe-opisanie-priobretenia-attestata-v-magazine
Medicines information. Generic Name.
where can i buy generic phenytoin without prescription
Best trends of medicament. Get information now.
Защитите свои данные с помощью резидентских прокси, использовать этим инструментом.
Как работают резидентские прокси?, прочитайте подробностями.
Советы по выбору резидентского прокси, инструкция для пользователей.
Какие задачи решают резидентские прокси?, ознакомьтесь с возможностями.
В чем преимущество безопасности резидентских прокси?, обзор функций безопасности.
Какие риски может предотвратить резидентский прокси?, анализируем важные аспекты.
Как резидентский прокси помогает повысить эффективность?, проанализируем основные плюсы.
Как быстрее работать в сети с резидентским прокси?, рекомендации для оптимизации работы.
Почему резидентский прокси стоит использовать для парсинга, обзор возможностей для парсеров.
Секреты анонимности с резидентским прокси, шаги к безопасности онлайн.
Как улучшить работу в социальных сетях с резидентским прокси, рекомендации функционала.
Зачем арендовать резидентские прокси и какие бонусы?, сравним лучшие варианты.
Способы защиты от DDoS с помощью резидентского прокси, подробно изучим меры безопасности.
Почему резидентские прокси пользуются популярностью, рассмотрим основные факторы.
Как выбрать между резидентским и дата-центровым прокси?, рекомендации для выбора.
резидентные proxy https://rezidentnieproksi.ru/ .
Pills information for patients. Cautions.
can i buy aricept pill
Actual what you want to know about drugs. Read information now.
купить диплом о высшем образовании за 5000 asxdiplomik24.ru .
Medicament information for patients. What side effects can this medication cause?
buy generic effexor price
Some news about medicament. Get now.
Безопасность данных с резидентскими прокси, для чего это нужно.
Получите доступ к контенту из других стран с резидентскими прокси, и наслаждайтесь контентом.
Получите быстрый и надежный интернет с резидентскими прокси, как это работает.
Скройте свой реальный IP-адрес от хакеров с резидентскими прокси, и будьте уверены в своей безопасности.
Сделайте свои онлайн-активности невидимыми благодаря резидентским прокси, и чувствуйте себя невидимкой.
Скачивайте файлы анонимно через резидентские прокси, и не бойтесь за свою приватность.
резидентные proxy https://rezidentnie-proksi.ru/ .
Безопасность данных с резидентскими прокси, преимущества.
Получите доступ к контенту из других стран с резидентскими прокси, широким контентом.
Получите быстрый и надежный интернет с резидентскими прокси, в чем преимущество.
Скройте свой реальный IP-адрес от хакеров с резидентскими прокси, и будьте уверены в своей безопасности.
Прячьте свою локацию и IP-адрес с резидентскими прокси, и чувствуйте себя невидимкой.
Используйте резидентские прокси для безопасного серфинга в интернете, и не бойтесь за свою приватность.
сервис резидентных прокси https://rezidentnie-proksi.ru/ .
Здравствуйте!
Мы изготавливаем дипломы любых профессий по выгодным ценам.
weekinato.ru/diplomyi-ot-luchshih-vuzov/
Medicament information leaflet. Effects of Drug Abuse.
tadacip pills
Everything news about drugs. Get here.
Drugs information leaflet. What side effects?
can i get cheap elavil tablets
Some what you want to know about drugs. Read here.
Drugs information. What side effects?
can you get generic macrobid tablets
Some about medicine. Get information now.
Привет, друзья!
Мы изготавливаем дипломы любой профессии по приятным ценам.
newmedtime.ru/vyisshee-obrazovanie-za-sutki-legalno-i-nadezhno
Добрый день!
Мы можем предложить дипломы любой профессии по разумным тарифам.
yiwulist.com/рамка-для-диплома-купить-в-москве/
Здравствуйте!
Мы можем предложить дипломы любой профессии по приятным тарифам.
mytenerji.com/2024/07/14/диплом-автоэлектрика-купить/
Drug information sheet. Brand names.
cost cheap azathioprine without rx
Best trends of drug. Get information here.
Добрый день!
Где заказать диплом специалиста?
Мы изготавливаем дипломы любой профессии по доступным тарифам. Цена будет зависеть от определенной специальности, года получения и ВУЗа. Стараемся поддерживать для заказчиков адекватную политику тарифов. Важно, чтобы дипломы были доступными для большого количества наших граждан.
Для вас предлагаем дипломы любых профессий по выгодным ценам.
africastudygate.com/диплом-купить-самара-будьте/
Будем рады вам помочь!.
Привет, друзья!
Где приобрести диплом по нужной специальности?
Мы изготавливаем дипломы психологов, юристов, экономистов и прочих профессий по доступным тарифам. Цена может зависеть от той или иной специальности, года выпуска и образовательного учреждения. Стараемся поддерживать для покупателей адекватную политику цен. Для нас очень важно, чтобы документы были доступными для большого количества граждан.
Для вас можем предложить дипломы любых профессий по приятным ценам.
datafornix.com/куплю-диплом-вуза-будут/
Всегда вам поможем!.
Всем привет! Может кто знает, где найти разные статьи о недвижимости? Сейчас читаю https://glatt-nsk.ru
Ищете качественную мебель для офиса? Рекомендую обратить внимание на мебель для офиса замм. Этот бренд предлагает широкий ассортимент офисной мебели, включая стильные и функциональные офисные столы. Продукция zamm отличается высоким качеством, долговечностью и современным дизайном. Идеально подходит для создания комфортного и продуктивного рабочего пространства. В ассортименте вы найдете всё, что нужно для организации современного офиса. Отличный выбор для тех, кто ценит надежность и стиль! С уважением, Zamm мебель.
Привет, друзья!
Мы можем предложить документы техникумов, расположенных в любом регионе РФ. Можно приобрести качественный диплом от любого заведения, за любой год, указав актуальную специальность и оценки за все дисциплины. Дипломы и аттестаты выпускаются на бумаге высшего качества. Это дает возможности делать государственные дипломы, которые не отличить от оригинала. Они заверяются необходимыми печатями и штампами.
aquarium.zone/read-blog/1046
ремонт смартфонов в москве адреса
срочно отремонтировать телефон
мастерская по ремонту телефонов
лучшее порево бесплатно лучшее порево бесплатно .
Если вам нужны профессионалы в области продвижения сайтов и разработки, обратите внимание на ООО”МД”. Они предлагают полный спектр услуг: от SEO и SEM до работы с Яндекс.Директ. Команда специализируется на создании эффективных стратегий, которые помогают привлечь целевую аудиторию и увеличить видимость вашего бизнеса в интернете. Их профессионализм и подход к каждому клиенту гарантируют отличные результаты. Рекомендую Mihaylov Digital как надежного партнера в цифровом маркетинге! С уважением, Mihaylov Digital.
Если вам нужны профессионалы в области продвижения сайтов и разработки, обратите внимание на ООО”МД”. Они предлагают полный спектр услуг: от SEO и SEM до работы с Яндекс.Директ. Команда специализируется на создании эффективных стратегий, которые помогают привлечь целевую аудиторию и увеличить видимость вашего бизнеса в интернете. Их профессионализм и подход к каждому клиенту гарантируют отличные результаты. Рекомендую MD как надежного партнера в цифровом маркетинге! С уважением, Mihaylov Digital.
Tezfiles Premium provides extensive perks at a budget-friendly price. This upgrade significantly enhances the service and includes more perks that free account users can also enjoy.
Tezfiles.
Заработайте крупный выигрыш на Вавада казино, огромный выбор игр, Вавада казино – ваш путь к богатству, получайте крупные выигрыши, широкий выбор азартных игр, Получайте выигрыши в Вавада казино, сделайте ставку на удачу, Вавада казино – лучший выбор для азартных игроков, высокие шансы на успех, Откройте для себя мир азарта на Вавада казино, Станьте частью мира азарта на Вавада казино, Сделайте ставку на победу в Вавада казино, выигрывайте крупнейшие джекпоты, стремитесь к успеху в Вавада казино
vavada casino официальный сайт вход
купить газоблоки цена https://gazobeton-moskow.ru/
locowin-casino.site
Sweet blog! I found it while browsing on Yahoo News. Do you have any tips on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there! Appreciate it
газобетонный блок d600 b5 https://gazobeton-moskow.ru/
Locowin en España
Привет!
Мы готовы предложить дипломы любых профессий по разумным ценам.
stlvolleyball.com/купить-диплом-высшее-какие/
Всем привет! Может кто знает, где найти разные блоги о недвижимости? Пока нашел https://gor-bur.ru
יש לך יותר מידי דאגות בראש? זהו בדיוק הזמן להרים את הטלפון ולהזמין נערות ליווי בתל אביב. ניתן להזמין אותן לדירתך או לבית המלון לשכוח מכל הדאגות עם נערות ליווי בתל אביב אז מה לעשות באותם הרגעים בהם אתה מרגיש כי החיים לוחצים עלייך יותר מידי? מה לעשות כאשר סקס דיסקרטי
Привет, друзья!
Купить диплом любого университета.
fishjines.mn.co/posts/61724301
Добрый день!
Купить диплом любого ВУЗа.
naturetour.ru/club/user/19/blog/1608/
Всем привет! Может кто знает, где почитать разные блоги о недвижимости? Пока нашел https://konditsioneri-shop.ru
או אולי גברים המחפשים קצת אטרקציות למסיבת הרווקים. לכל אחד יש את הסיבות שלו, אבל האמת שזה לא ממש משנה. נערות ליווי בחיפה לא כל סודות הגוף והן יגרמו לך להנאה רבה. אתה תרגיש את הגבריות שלך בשיא עצמתה, ובעודך נהנה מהנשיות המושלמת של הנערות. גופך ינוע user-pic
Как увеличить доход с помощью арбитража трафика, для увеличения вашего дохода.
Как начать зарабатывать на арбитраже трафика с нуля, без опыта в онлайн-бизнесе.
Как выбрать подходящие источники трафика для арбитража, чтобы минимизировать риски и максимизировать прибыль.
Как создать высокоэффективные рекламные кампании для арбитража трафика, для успешного монетизации трафика.
Способы заработка на арбитраже трафика без рисков и потерь, благодаря эффективным стратегиям и инструментам.
pop ads https://traffic-arbitrage.com .
הגברים של העיר, החיילים המשרתים בסביבה וכל מי שאוהב עיסויים אירוטיים ופינוקים אינטימיים. דירות דיסקרטיות בבאר שבע מציעות אם אתה גבר נשוי או פרופסור מהטכניון – כאן כולם אורחים רצויים. כאן מקבלים פינוק שעושה טוב לכולם, והכל בדיסקרטיות מלאה. מבלים this site
Glory Casino
חוויית אירוח בלתי נשכחת. תוכל להתארח בדירות ממוזגות, נקיות ונעימות בהן מתגוררות נערות קסומות המארחות גברים בביתן. אם בא לך בלילה סוער או בכל רגע שבא לך לעצור את הבלאגן של בחיים. הנערות יפנקו אותך ויגרמו לך להשקיט את כל הדאגות. במקום זאת תוכל להיות top article
שיגרום לשניכם להתנשף ולהתרגש מרוב אושר. הנערה יודעת כיצד לפנק את גוף הגבר. היא יודעת היכן לגעת והיכן ללחוץ, והיא תעשה זאת עד עצמינו. ויש גם את הרגעים שבהם אנו שמחים ומאושרים, ורוצים עוד יותר להרים את מצב הרוח. נראה כי בשני המקרים תרצו לבלות עם נערות נערות ליווי בחדרה
שכל אחת מציגה גוף מהסרטים, היא גם יודעת להפוך אותך לכוכב של הסרט. אתה תוכל לעשות מה שאתה רוצה והנערה תזרום איתך. ולא משנה מה ליווי זמינות 24 שעות ביממה, והן רק מחכות שתזמין אותן לבית המלון או לדירתך. ושם בין הסדינים הן יעניקו לך בילוי אינטימי מפנק try this web-site
לביתו, יכול לבוא לבלות כאן. דירות דיסקרטיות בחיפה זה גם מקום בילוי, וזה גם בחורה לבלות איתה. הכל בחבילה אחת. לא יכול להיות עליו – זהו לא עניין של אף אחד. ועל מנת שגברים נשואים, גברים דתיים, אנשי עסקים ובעצם כולם יוכלו ליהנות בחופשיות – חייבים לשמור מסאג אירוטי בחיפה
Glory Casino
והן יעניקו לך בילוי ללא דאגות. השירות זמין 24 שעות ביממה ו – 7 ימים בשבוע. תמיד יש לך על מי לסמוך. תמיד ניתן להזמין מישהי מרוכז בתחושת הנעימות של הגוף. אז אם בא לך ליהנות הלילה, ולהרגיש חלק מאותו מועדון אקסקלוסיבי של גברים אשר יודעים ליהנות מהחיים, click here for more info
Выкуп авто дтп
Продать битую машину
Привет!
Где приобрести диплом по нужной специальности?
http://www.leenkup.com/read-blog/16408
coindarwin crypto news
The Story Behind Solana’s Architect Toly’s Accomplishment
Subsequent to A Pair of Mugs of Coffee plus a Pint
Yakovenko, the visionary the mastermind behind Solana, initiated his quest with a routine ritual – two coffees and a brew. Little did he realize, these instances would ignite the machinery of his journey. Currently, Solana remains as a formidable contender in the digital currency sphere, having a market value of billions.
Ethereum ETF First Sales
The Ethereum ETF lately started with a substantial volume of trades. This milestone event experienced various spot Ethereum ETFs from different issuers be listed on American exchanges, creating extraordinary activity into the usually calm ETF trading environment.
Ethereum ETF Approval by SEC
The Commission has formally approved the spot Ethereum ETF for being listed. Being a cryptographic asset with smart contracts, Ethereum is anticipated to deeply influence the blockchain sector due to this approval.
Trump and Bitcoin
As the election approaches, Trump portrays himself as the ‘Cryptocurrency President,’ constantly highlighting his backing of the digital currency sector to gain voters. His strategy varies from Biden’s approach, seeking to capture the interest of the cryptocurrency community.
Elon Musk’s Influence
Elon Musk, a prominent figure in the cryptocurrency space and a backer of Trump, shook things up once again, driving a meme coin associated with his antics. His participation keeps influencing the market landscape.
Binance Developments
A subsidiary of Binance, BAM, is now allowed to allocate customer funds in U.S. Treasury securities. Furthermore, Binance noted its 7th year, emphasizing its progress and acquiring multiple compliance licenses. At the same time, the corporation also disclosed plans to delist several significant crypto trading pairs, altering the market landscape.
Artificial Intelligence and Economic Outlook
Goldman Sachs’ top stock analyst recently commented that artificial intelligence won’t trigger an economic transformation
Discover your perfect stay with WorldHotels-in.com, your ultimate destination for finding the best hotels worldwide! Our user-friendly platform offers a vast selection of accommodations to suit every traveler’s needs and budget. Whether you’re planning a luxurious getaway or a budget-friendly adventure, we’ve got you covered with our extensive database of hotels across the globe. Our intuitive search features allow you to filter results based on location, amenities, price range, and guest ratings, ensuring you find the ideal match for your trip. We pride ourselves on providing up-to-date information and competitive prices, often beating other booking sites. Our detailed hotel descriptions, high-quality photos, and authentic guest reviews give you a comprehensive view of each property before you book. Plus, our secure booking system and excellent customer support team ensure a smooth and worry-free experience from start to finish. Don’t waste time jumping between multiple websites – http://www.WorldHotels-in.com brings the world’s best hotels to your fingertips in one convenient place. Start planning your next unforgettable journey today and experience the difference with WorldHotels-in.com!
Привет, друзья!
Как избежать рисков при покупке диплома колледжа или ПТУ в России
landik-diploms-srednee.ru/kupit-diplom-v-novosibirske В
Добрый день!
Официальная покупка диплома вуза с сокращенной программой в Москве
landik-diploms-srednee.ru/kupit-diplom-v-omske В
Добрый день!
Заказать документ института
diploms-x.com/kupit-diplom-o-srednem-obrazovanii
Добрый день!
Купить документ о получении высшего образования
ast-diplomas.com/kupit-diplom-voronezh
Добрый день!
Заказать документ института
ast-diplom.com/kupit-diplom-vracha
Привет, друзья!
Приобрести документ о получении высшего образования
ast-diplom.com/kupit-diplom-krasnoyarsk
Привет!
Приобрести документ о получении высшего образования
diplomyx24.ru/kupit-diplom-sankt-peterburg
https://indexcall.com/hot-telecom/ip-telephony/
https://www.trn-news.ru/digest/195264
ונעים שאתה לעולם לא נשכח. נערות ליווי מכירות את כל הסודות של הגוף הגברי והן לא מפחדות להראות לך מה הן יודעות לעשות. אם תרצה בילוי אחד ויחיד שמאפשר לגבר להירגע. את אותו בילוי שמשקיט את המחשבות ומרפא את הגוף. כלומר זוהי הזדמנות למצוא גם סביבת בילוי מכון ליווי בראשון לציון שמתאים לכל אחד
Привет!
Мы предлагаем дипломы психологов, юристов, экономистов и прочих профессий по приятным ценам.
sydplatinum.com/купить-диплом-рф/
женская одежда магазин – купить танкини купальник, мультиколор купальники цена
система для конференц зала https://oborudovanie-konferenc-zalov.ru .
ליווי זמינות ברגע זה אתה לא צריך לחלום על בילויים אינטימיים עם נערות מדהימות, אתה רק צריך להתקשר ולקבוע עם הנערות. נערות דירות דיסקרטיות בחיפה הן לא סתם מקום שאתה רוצה להיות בו. זהו המקום שבו אתה פשוט חייב להיות. נערות ליווי בתל אביב להנאה this post
מהם. אבל יש רק סוג אחד של בילוי שבאמת גורם לגבר להיות רגוע. יש רק בילוי אחד שיודע לנקות את הראש ממחשבות, ולהרפות את הגוף. בדירות הדיסקרטיות תוכל למצוא נערות בעלות מראה שיגרום לך להתרגש. לכולן גוף סקסי ומפתה, מהסוג שאתה רגיל לראות רק בסרטים. ולא רק נערת ליווי בחיפה
The Hidden Account Concerning Solana’s Founder Yakovenko’s Achievement
Subsequent to A Pair of Portions of Java and a Pint
Yakovenko, the mastermind behind Solana, commenced his path with a modest routine – two coffees and a brew. Unaware to him, these instances would ignite the wheels of fate. Currently, Solana stands as a significant participant in the blockchain realm, boasting a market cap in the billions.
Ethereum ETF First Sales
The Ethereum ETF lately launched with an impressive trade volume. This milestone event saw numerous spot Ethereum ETFs from multiple issuers start trading on U.S. exchanges, injecting unseen activity into the typically steady ETF trading space.
Ethereum ETF Approval by SEC
The SEC has officially approved the Ethereum Spot ETF to be listed. As a digital asset with smart contracts, Ethereum is projected to majorly affect the digital currency industry due to this approval.
Trump’s Crypto Maneuver
As the election approaches, Trump frames himself as the “Crypto President,” frequently displaying his advocacy for the digital currency sector to gain voters. His method is different from Biden’s method, aiming to capture the attention of the digital currency community.
Musk’s Influence on Crypto
Musk, a famous figure in the blockchain world and a supporter of the Trump camp, shook things up yet again, boosting a meme coin associated with his antics. His involvement keeps shaping market trends.
Binance Updates
A subsidiary of Binance, BAM, has been permitted to use customer funds into U.S. Treasuries. Moreover, Binance noted its seventh anniversary, emphasizing its journey and obtaining various compliance licenses. Simultaneously, the company also revealed plans to remove several notable cryptocurrency trading pairs, affecting different market players.
Artificial Intelligence and Economic Outlook
Goldman Sachs’ top stock analyst recently mentioned that artificial intelligence won’t lead to a major economic changeHere’s the spintax version of the provided text with possible synonyms
https://derbayerischelowe.info/
создание и раскрутка сайта цена https://razrabotka-sajtov-pod-klyuch.ru/
https://derbayerischelowe.info/
RGBET trang chủ
RGBET trang chủ với hệ thống game nhà cái đỉnh cao – Nhà cái uy tín số 1 Việt Nam trong lĩnh vực cờ bạc online
RG trang chủ, RG RICH GAME, Nhà Cái RG
RGBET Trang Chủ Và Câu Chuyện Thương Hiệu
Ra đời vào năm 2010 tại Đài Loan, RGBET nhanh chóng trở thành một trang cá cược chất lượng hàng đầu khu vực Châu Á. Nhà cái được cấp phép hoạt động hợp pháp bởi công ty giải trí trực tuyến hợp pháp được ủy quyền và giám sát theo giấy phép Malta của Châu Âu – MGA. Và chịu sự giám sát chặt chẽ của tổ chức PAGCOR và BIV.
RGBET trang chủ cung cấp cho người chơi đa dạng các thể loại cược đặc sắc như: thể thao, đá gà, xổ số, nổ hũ, casino trực tuyến. Dịch vụ CSKH luôn hoạt động 24/7. Với chứng chỉ công nghệ GEOTRUST, nhà cái đảm bảo an toàn cho mọi giao dịch của khách hàng. APP RG thiết kế tối ưu giải quyết mọi vấn đề của người dùng IOS và Android.
Là một nhà cái đến từ đất nước công nghệ, nhà cái luôn không ngừng xây dựng và nâng cấp hệ thống game và dịch vụ hoàn hảo. Mọi giao dịch nạp rút được tự động hoá cho phép người chơi hoàn tất giao dịch chỉ với 2 phút vô cùng nhanh chóng
RGBET Lớn Nhất Uy Tín Nhất – Giá Trị Cốt Lõi
Nhà Cái RG Và Mục Tiêu Thương Hiệu
Giá trị cốt lõi mà RGBET mong muốn hướng đến đó chính là không ngừng hoàn thiện để đem đến một hệ thống chất lượng, công bằng và an toàn. Nâng cao sự hài lòng của người chơi, đẩy mạnh hoạt động chống gian lận và lừa đảo. RG luôn cung cấp hệ thống kèo nhà cái đặc sắc, cùng các sự kiện – giải đấu hàng đầu và tỷ lệ cược cạnh tranh đáp ứng mọi nhu cầu khách hàng.
Thương hiệu cá cược RGBET cam kết đem lại cho người chơi môi trường cá cược công bằng, văn minh và lành mạnh. Đây là nguồn động lực to lớn giúp nhà cái thực tế hóa các hoạt động của mình.
RGBET Có Tầm Nhìn Và Sứ Mệnh
Đổi mới và sáng tạo là yếu tố cốt lõi giúp đạt được mục tiêu dưới sự chuyển mình mạnh mẽ của công nghệ. Tầm nhìn và sứ mệnh của RGBET là luôn tìm tòi những điều mới lạ, đột phá mạnh mẽ, vượt khỏi giới hạn bản thân, đương đầu với thử thách để đem đến cho khách hàng sản phẩm hoàn thiện nhất.
Chúng tôi luôn sẵn sàng tiếp thu ý kiến và nâng cao bản thân mỗi ngày để tạo ra sân chơi bổ ích, uy tín và chuyên nghiệp cho người chơi. Để có thể trở thành nhà cái phù hợp với mọi khách hàng.
Khái Niệm Giá Trị Cốt Lõi Nhà Cái RGBET
Giá trị cốt lõi của nhà cái RG luôn gắn kết chặt chẽ với nhau giữa 5 khái niệm: Chính trực, chuyên nghiệp, an toàn, đổi mới, công nghệ.
Chính Trực
Mọi quy luật, cách thức của trò chơi đều được nhà cái cung cấp công khai, minh bạch và chi tiết. Mỗi tựa game hoạt động đều phải chịu sự giám sát kỹ lưỡng bởi các cơ quan tổ chức có tiếng về sự an toàn và minh bạch của nó.
Chuyên Nghiệp
Các hoạt động tại RGBET trang chủ luôn đề cao sự chuyên nghiệp lên hàng đầu. Từ giao diện đến chất lượng sản phẩm luôn được trau chuốt tỉ mỉ từng chi tiết. Thế giới giải trí được xây dựng theo văn hóa Châu Á, phù hợp với đại đa số thị phần khách Việt.
An Toàn
RG lớn nhất uy tín nhất luôn ưu tiên sử dụng công nghệ mã hóa hiện đại nhất để đảm bảo an toàn, riêng tư cho toàn bộ thông tin của người chơi. Đơn vị cam kết nói không với hành vi gian lận và mua bán, trao đổi thông tin cá nhân bất hợp pháp.
Đổi Mới
Nhà cái luôn theo dõi và bắt kịp xu hướng thời đại, liên tục bổ sung các sản phẩm mới, phương thức cá cược mới và các ưu đãi độc lạ, mang đến những trải nghiệm thú vị cho người chơi.
Công Nghệ
RGBET trang chủ tập trung xây dựng một giao diện game sắc nét, sống động cùng tốc độ tải nhanh chóng. Ứng dụng RGBET giải nén ít dung lượng phù hợp với mọi hệ điều hành và cấu hình, tăng khả năng sử dụng của khách hàng.
RGBET Khẳng Định Giá Trị Thương Hiệu
Hoạt động hợp pháp với đầy đủ giấy phép, chứng chỉ an toàn đạt tiêu chuẩn quốc tế
Hệ thống game đa màu sắc, đáp ứng được mọi nhu cầu người chơi
Chính sách bảo mật RG hiện đại và đảm bảo an toàn cho người chơi cá cược
Bắt tay hợp tác với nhiều đơn vị phát hành game uy tín, chất lượng thế giới
Giao dịch nạp rút RG cấp tốc, nhanh gọn, bảo mật an toàn
Kèo nhà cái đa dạng với bảng tỷ lệ kèo cao, hấp dẫn
Dịch Vụ RGBET Casino Online
Dịch vụ khách hàng
Đội ngũ CSKH RGBET luôn hoạt động thường trực 24/7. Nhân viên được đào tạo chuyên sâu luôn giải đáp tất cả các khó khăn của người chơi về các vấn đề tài khoản, khuyến mãi, giao dịch một cách nhanh chóng và chuẩn xác. Hạn chế tối đa làm ảnh hưởng đến quá trình trải nghiệm của khách hàng.
Đa dạng trò chơi
Với sự nhạy bén trong cập nhật xu thế, nhà cái RGBET đã dành nhiều thời gian phân tích nhu cầu khách hàng, đem đến một kho tàng game chất lượng với đa dạng thể loại từ RG casino online, thể thao, nổ hũ, game bài, đá gà, xổ số.
Khuyến mãi hấp dẫn
RGBET trang chủ liên tục cập nhật và thay đổi các sự kiện ưu đãi đầy hấp dẫn và độc đáo. Mọi thành viên bất kể là người chơi mới, người chơi cũ hay hội viên VIP đều có cơ hội được hưởng ưu đãi đặc biệt từ nhà cái.
Giao dịch linh hoạt, tốc độ
Thương hiệu RGBET luôn chú tâm đến hệ thống giao dịch. Nhà cái cung cấp dịch vụ nạp rút nhanh chóng với đa dạng phương thức như thẻ cào, ví điện tử, ngân hàng điện tử, ngân hàng trực tiếp. Mọi hoạt động đều được bảo mật tuyệt đối bởi công nghệ mã hóa tiên tiến.
App cá độ RGBET
App cá độ RGBET là một ứng dụng cho phép người chơi đăng nhập RG nhanh chóng, đồng thời các thao tác đăng ký RG trên app cũng được tối ưu và trở nên đơn giản hơn. Tham gia cá cược RG bằng app cá độ, người chơi sẽ có 1 trải nghiệm cá cược tuyệt vời và thú vị.
RGBET Có Chứng Nhận Cá Cược Quốc Tế
Nhà cái RGBET hoạt động hợp pháp dưới sự cấp phép của hai tổ chức thế giới là PAGCOR và MGA, tính minh bạch và công bằng luôn được giám sát gắt gao bởi BIV. Khi tham gia cược tại đây, người chơi sẽ được đảm bảo quyền và lợi ích hợp pháp của mình.
Việc sở hữu các chứng nhận quốc tế còn cho thấy nguồn tài chính ổn định, dồi dào của RGBET. Điều này cho thấy việc một nhà cái được công nhận bởi các cơ quan quốc tế không phải là một chuyện dễ.
Theo quy định nhà cái RGBET, chỉ người chơi từ đủ 18 tuổi trở lên mới có thể tham gia cá cược tại RGBET
MGA (Malta Gaming Authority)
Tổ chức MGA đảm bảo tính vẹn toàn và ổn định của các trò chơi. Có các chính sách bảo vệ nguồn tài chính và quyền lợi của người chơi. Chứng nhận một nhà cái hoạt động có đầy đủ pháp lý, tuân thủ nghiêm chỉnh luật cờ bạc.
Chứng nhận Quần đảo Virgin Vương quốc Anh (BIV)
Tổ chứng chứng nhận nhà cái có đầy đủ tài chính để hoạt động kinh doanh cá cược. Với nguồn ngân sách dồi dào, ổn định nhà cái bảo đảm tính thanh khoản cho người chơi, mọi quyền lợi sẽ không bị xâm phạm.
Giấy Phép PAGCOR
Tổ chức cấp giấy phép cho nhà cái hoạt động đạt chuẩn theo tiêu chuẩn quốc tế. Cho phép nhà cái tổ chức cá cược một cách hợp pháp, không bị rào cản. Có chính sách ngăn chặn mọi trò chơi có dấu hiệu lừa đảo, duy trì sự minh bạch, công bằng.
Nhà Cái RGBET Phát Triển Công Nghệ
Nhà cái RGBET hỗ trợ trên nhiều thiết bị : IOS, Android, APP, WEB, Html5
RG và Trách Nhiệm Xã Hội
RGBET RichGame không đơn thuần là một trang cá cược giải trí mà nhà cái còn thể hiện rõ tính trách nhiệm xã hội của mình. Đơn vị luôn mong muốn người chơi tham gia cá cược phải có trách nhiệm với bản thân, gia đình và cả xã hội. Mọi hoạt động diễn ra tại RGBET trang chủ nói riêng hay bất kỳ trang web khác, người chơi phải thật sự bình tĩnh và lý trí, đừng để bản thân rơi vào “cạm bẫy của cờ bạc”.
RGBET RichGame với chính sách nghiêm cấm mọi hành vi xâm phạm thông tin cá nhân và gian lận nhằm tạo ra một môi trường cá cược công bằng, lành mạnh. Nhà cái khuyến cáo mọi cá nhân chưa đủ 18 tuổi không nên đăng ký RG và tham gia vào bất kỳ hoạt động cá cược nào.
rgbet 3baa365
продвижение раскрутка веб сайтов https://razrabotka-sajtov-pod-klyuch.ru/
RGBET trang chủ
RGBET trang chủ với hệ thống game nhà cái đỉnh cao – Nhà cái uy tín số 1 Việt Nam trong lĩnh vực cờ bạc online
RG trang chủ, RG RICH GAME, Nhà Cái RG
RGBET Trang Chủ Và Câu Chuyện Thương Hiệu
Ra đời vào năm 2010 tại Đài Loan, RGBET nhanh chóng trở thành một trang cá cược chất lượng hàng đầu khu vực Châu Á. Nhà cái được cấp phép hoạt động hợp pháp bởi công ty giải trí trực tuyến hợp pháp được ủy quyền và giám sát theo giấy phép Malta của Châu Âu – MGA. Và chịu sự giám sát chặt chẽ của tổ chức PAGCOR và BIV.
RGBET trang chủ cung cấp cho người chơi đa dạng các thể loại cược đặc sắc như: thể thao, đá gà, xổ số, nổ hũ, casino trực tuyến. Dịch vụ CSKH luôn hoạt động 24/7. Với chứng chỉ công nghệ GEOTRUST, nhà cái đảm bảo an toàn cho mọi giao dịch của khách hàng. APP RG thiết kế tối ưu giải quyết mọi vấn đề của người dùng IOS và Android.
Là một nhà cái đến từ đất nước công nghệ, nhà cái luôn không ngừng xây dựng và nâng cấp hệ thống game và dịch vụ hoàn hảo. Mọi giao dịch nạp rút được tự động hoá cho phép người chơi hoàn tất giao dịch chỉ với 2 phút vô cùng nhanh chóng
RGBET Lớn Nhất Uy Tín Nhất – Giá Trị Cốt Lõi
Nhà Cái RG Và Mục Tiêu Thương Hiệu
Giá trị cốt lõi mà RGBET mong muốn hướng đến đó chính là không ngừng hoàn thiện để đem đến một hệ thống chất lượng, công bằng và an toàn. Nâng cao sự hài lòng của người chơi, đẩy mạnh hoạt động chống gian lận và lừa đảo. RG luôn cung cấp hệ thống kèo nhà cái đặc sắc, cùng các sự kiện – giải đấu hàng đầu và tỷ lệ cược cạnh tranh đáp ứng mọi nhu cầu khách hàng.
Thương hiệu cá cược RGBET cam kết đem lại cho người chơi môi trường cá cược công bằng, văn minh và lành mạnh. Đây là nguồn động lực to lớn giúp nhà cái thực tế hóa các hoạt động của mình.
RGBET Có Tầm Nhìn Và Sứ Mệnh
Đổi mới và sáng tạo là yếu tố cốt lõi giúp đạt được mục tiêu dưới sự chuyển mình mạnh mẽ của công nghệ. Tầm nhìn và sứ mệnh của RGBET là luôn tìm tòi những điều mới lạ, đột phá mạnh mẽ, vượt khỏi giới hạn bản thân, đương đầu với thử thách để đem đến cho khách hàng sản phẩm hoàn thiện nhất.
Chúng tôi luôn sẵn sàng tiếp thu ý kiến và nâng cao bản thân mỗi ngày để tạo ra sân chơi bổ ích, uy tín và chuyên nghiệp cho người chơi. Để có thể trở thành nhà cái phù hợp với mọi khách hàng.
Khái Niệm Giá Trị Cốt Lõi Nhà Cái RGBET
Giá trị cốt lõi của nhà cái RG luôn gắn kết chặt chẽ với nhau giữa 5 khái niệm: Chính trực, chuyên nghiệp, an toàn, đổi mới, công nghệ.
Chính Trực
Mọi quy luật, cách thức của trò chơi đều được nhà cái cung cấp công khai, minh bạch và chi tiết. Mỗi tựa game hoạt động đều phải chịu sự giám sát kỹ lưỡng bởi các cơ quan tổ chức có tiếng về sự an toàn và minh bạch của nó.
Chuyên Nghiệp
Các hoạt động tại RGBET trang chủ luôn đề cao sự chuyên nghiệp lên hàng đầu. Từ giao diện đến chất lượng sản phẩm luôn được trau chuốt tỉ mỉ từng chi tiết. Thế giới giải trí được xây dựng theo văn hóa Châu Á, phù hợp với đại đa số thị phần khách Việt.
An Toàn
RG lớn nhất uy tín nhất luôn ưu tiên sử dụng công nghệ mã hóa hiện đại nhất để đảm bảo an toàn, riêng tư cho toàn bộ thông tin của người chơi. Đơn vị cam kết nói không với hành vi gian lận và mua bán, trao đổi thông tin cá nhân bất hợp pháp.
Đổi Mới
Nhà cái luôn theo dõi và bắt kịp xu hướng thời đại, liên tục bổ sung các sản phẩm mới, phương thức cá cược mới và các ưu đãi độc lạ, mang đến những trải nghiệm thú vị cho người chơi.
Công Nghệ
RGBET trang chủ tập trung xây dựng một giao diện game sắc nét, sống động cùng tốc độ tải nhanh chóng. Ứng dụng RGBET giải nén ít dung lượng phù hợp với mọi hệ điều hành và cấu hình, tăng khả năng sử dụng của khách hàng.
RGBET Khẳng Định Giá Trị Thương Hiệu
Hoạt động hợp pháp với đầy đủ giấy phép, chứng chỉ an toàn đạt tiêu chuẩn quốc tế
Hệ thống game đa màu sắc, đáp ứng được mọi nhu cầu người chơi
Chính sách bảo mật RG hiện đại và đảm bảo an toàn cho người chơi cá cược
Bắt tay hợp tác với nhiều đơn vị phát hành game uy tín, chất lượng thế giới
Giao dịch nạp rút RG cấp tốc, nhanh gọn, bảo mật an toàn
Kèo nhà cái đa dạng với bảng tỷ lệ kèo cao, hấp dẫn
Dịch Vụ RGBET Casino Online
Dịch vụ khách hàng
Đội ngũ CSKH RGBET luôn hoạt động thường trực 24/7. Nhân viên được đào tạo chuyên sâu luôn giải đáp tất cả các khó khăn của người chơi về các vấn đề tài khoản, khuyến mãi, giao dịch một cách nhanh chóng và chuẩn xác. Hạn chế tối đa làm ảnh hưởng đến quá trình trải nghiệm của khách hàng.
Đa dạng trò chơi
Với sự nhạy bén trong cập nhật xu thế, nhà cái RGBET đã dành nhiều thời gian phân tích nhu cầu khách hàng, đem đến một kho tàng game chất lượng với đa dạng thể loại từ RG casino online, thể thao, nổ hũ, game bài, đá gà, xổ số.
Khuyến mãi hấp dẫn
RGBET trang chủ liên tục cập nhật và thay đổi các sự kiện ưu đãi đầy hấp dẫn và độc đáo. Mọi thành viên bất kể là người chơi mới, người chơi cũ hay hội viên VIP đều có cơ hội được hưởng ưu đãi đặc biệt từ nhà cái.
Giao dịch linh hoạt, tốc độ
Thương hiệu RGBET luôn chú tâm đến hệ thống giao dịch. Nhà cái cung cấp dịch vụ nạp rút nhanh chóng với đa dạng phương thức như thẻ cào, ví điện tử, ngân hàng điện tử, ngân hàng trực tiếp. Mọi hoạt động đều được bảo mật tuyệt đối bởi công nghệ mã hóa tiên tiến.
App cá độ RGBET
App cá độ RGBET là một ứng dụng cho phép người chơi đăng nhập RG nhanh chóng, đồng thời các thao tác đăng ký RG trên app cũng được tối ưu và trở nên đơn giản hơn. Tham gia cá cược RG bằng app cá độ, người chơi sẽ có 1 trải nghiệm cá cược tuyệt vời và thú vị.
RGBET Có Chứng Nhận Cá Cược Quốc Tế
Nhà cái RGBET hoạt động hợp pháp dưới sự cấp phép của hai tổ chức thế giới là PAGCOR và MGA, tính minh bạch và công bằng luôn được giám sát gắt gao bởi BIV. Khi tham gia cược tại đây, người chơi sẽ được đảm bảo quyền và lợi ích hợp pháp của mình.
Việc sở hữu các chứng nhận quốc tế còn cho thấy nguồn tài chính ổn định, dồi dào của RGBET. Điều này cho thấy việc một nhà cái được công nhận bởi các cơ quan quốc tế không phải là một chuyện dễ.
Theo quy định nhà cái RGBET, chỉ người chơi từ đủ 18 tuổi trở lên mới có thể tham gia cá cược tại RGBET
MGA (Malta Gaming Authority)
Tổ chức MGA đảm bảo tính vẹn toàn và ổn định của các trò chơi. Có các chính sách bảo vệ nguồn tài chính và quyền lợi của người chơi. Chứng nhận một nhà cái hoạt động có đầy đủ pháp lý, tuân thủ nghiêm chỉnh luật cờ bạc.
Chứng nhận Quần đảo Virgin Vương quốc Anh (BIV)
Tổ chứng chứng nhận nhà cái có đầy đủ tài chính để hoạt động kinh doanh cá cược. Với nguồn ngân sách dồi dào, ổn định nhà cái bảo đảm tính thanh khoản cho người chơi, mọi quyền lợi sẽ không bị xâm phạm.
Giấy Phép PAGCOR
Tổ chức cấp giấy phép cho nhà cái hoạt động đạt chuẩn theo tiêu chuẩn quốc tế. Cho phép nhà cái tổ chức cá cược một cách hợp pháp, không bị rào cản. Có chính sách ngăn chặn mọi trò chơi có dấu hiệu lừa đảo, duy trì sự minh bạch, công bằng.
Nhà Cái RGBET Phát Triển Công Nghệ
Nhà cái RGBET hỗ trợ trên nhiều thiết bị : IOS, Android, APP, WEB, Html5
RG và Trách Nhiệm Xã Hội
RGBET RichGame không đơn thuần là một trang cá cược giải trí mà nhà cái còn thể hiện rõ tính trách nhiệm xã hội của mình. Đơn vị luôn mong muốn người chơi tham gia cá cược phải có trách nhiệm với bản thân, gia đình và cả xã hội. Mọi hoạt động diễn ra tại RGBET trang chủ nói riêng hay bất kỳ trang web khác, người chơi phải thật sự bình tĩnh và lý trí, đừng để bản thân rơi vào “cạm bẫy của cờ bạc”.
RGBET RichGame với chính sách nghiêm cấm mọi hành vi xâm phạm thông tin cá nhân và gian lận nhằm tạo ra một môi trường cá cược công bằng, lành mạnh. Nhà cái khuyến cáo mọi cá nhân chưa đủ 18 tuổi không nên đăng ký RG và tham gia vào bất kỳ hoạt động cá cược nào.
rgbet d14_dcb